基于觀點(diǎn)袋模型的汽車評(píng)論情感極性分類
2015-04-21 08:43:45王素格李德玉
中文信息學(xué)報(bào) 2015年3期
廖 健,王素格,2,李德玉,2,張 鵬
(1. 山西大學(xué) 計(jì)算機(jī)與信息技術(shù)學(xué)院,太原 030006;2. 山西大學(xué) 計(jì)算智能與中文信息處理教育部重點(diǎn)實(shí)驗(yàn)室,太原 030006)
?
基于觀點(diǎn)袋模型的汽車評(píng)論情感極性分類
廖 健1,王素格1,2,李德玉1,2,張 鵬1
(1. 山西大學(xué) 計(jì)算機(jī)與信息技術(shù)學(xué)院,太原 030006;2. 山西大學(xué) 計(jì)算智能與中文信息處理教育部重點(diǎn)實(shí)驗(yàn)室,太原 030006)
該文針對(duì)網(wǎng)絡(luò)評(píng)論傾向分級(jí)問(wèn)題,提出了一種基于觀點(diǎn)袋模型和語(yǔ)言學(xué)規(guī)則的多級(jí)情感分類方法。通過(guò)分析句子中的詞性搭配關(guān)系,設(shè)計(jì)了12種抽取特征-觀點(diǎn)搭配模式,并對(duì)存在問(wèn)題給出了解決策略。依據(jù)漢語(yǔ)用詞特點(diǎn)和詞匯在汽車領(lǐng)域的特殊用法,提出搭配四元組的情感傾向極性值計(jì)算方法。在此基礎(chǔ)上,利用獲取的搭配四元組及其情感傾向極性,建立文本的向量化表示,并構(gòu)造了權(quán)重計(jì)算公式。最后,利用文本余弦相似度計(jì)算方法實(shí)現(xiàn)對(duì)評(píng)論文本的五級(jí)情感極性分類。通過(guò)在COAE2012任務(wù)3的汽車數(shù)據(jù)集上進(jìn)行的測(cè)試,取得了較好的分類結(jié)果。
情感分類;觀點(diǎn)袋模型;詞性搭配
1 引言
隨著互聯(lián)網(wǎng)的快速發(fā)展,普通網(wǎng)絡(luò)用戶已經(jīng)從單純的信息接受者逐漸變成信息生產(chǎn)者,各類微博、論壇、電商中存在大量具有評(píng)論性和主觀傾向性的文本,例如商品評(píng)價(jià)、跟帖等。據(jù)統(tǒng)計(jì),44%新聞文本包含觀點(diǎn)信息[1]。通過(guò)分析商品評(píng)論,可以讓普通用戶更容易了解某些產(chǎn)品的主流市場(chǎng)評(píng)價(jià),方便用戶做出更正確的消費(fèi)決定,對(duì)商家而言,也能利用這類結(jié)果來(lái)獲得最直觀的市場(chǎng)反饋,據(jù)此做出更有針對(duì)性的市場(chǎng)決策。
篇章級(jí)文本通常包含了作者的多種觀點(diǎn),特別是關(guān)于產(chǎn)品的評(píng)論可能涉及到產(chǎn)品的多個(gè)方面,這些方面的傾向性有時(shí)并不一致。例如,“路虎的動(dòng)力強(qiáng)勁,但油耗太大。”,分別從動(dòng)力和油耗兩個(gè)方面表達(dá)了完全相反的情感傾向。因此,綜合考慮產(chǎn)品的各方面的評(píng)價(jià)觀點(diǎn)是進(jìn)行篇章級(jí)文本的傾向分類研究的基礎(chǔ)。
搭配通常被認(rèn)為是一種具有任意性和可重復(fù)性的詞語(yǔ)組合[2-3],大量的研究表明,搭配是一種行之有效的文本表示形式[4-5]。Qu等人[6]提出了觀點(diǎn)袋(bag-of-opinions)模型對(duì)商品評(píng)論自動(dòng)進(jìn)行評(píng)價(jià)極性分類,他們將文本轉(zhuǎn)化成基準(zhǔn)詞(root word)與修飾詞(modifier word)的搭配,并使用嶺回歸(ridge regression)模型對(duì)每個(gè)觀點(diǎn)詞進(jìn)行打分,但僅考慮到了否定副詞對(duì)情感搭配的反轉(zhuǎn)作用,沒(méi)有考慮到程度副詞對(duì)于情感極性的影響。Thet等人[7]使用句法依賴將句子轉(zhuǎn)換為子句,通過(guò)構(gòu)造一系列規(guī)則計(jì)算各子句的情感極性,依照子句歸屬計(jì)算各方面極性值,他們據(jù)此構(gòu)造分類器對(duì)電影評(píng)論文本分類,取得理想的效果。王素格等[8]提出了一種混合語(yǔ)言信息的詞語(yǔ)搭配的傾向判別方法,她們使用詞性匹配模式抽取詞語(yǔ)搭配,總結(jié)出了六種搭配模式并確定各自的概率潛在語(yǔ)義模型,以此判別搭配的情感傾向。
第四屆中文傾向性分析評(píng)測(cè)(COAE2012)[9]首次要求對(duì)于篇章的觀點(diǎn)傾向極性進(jìn)行打分。文獻(xiàn)[10]利用篇章中正負(fù)面句子數(shù)將文本向量化表示后計(jì)算余弦相似度文獻(xiàn)。文獻(xiàn)[11]采用欠采樣集成學(xué)習(xí)的方法,構(gòu)建了SVM、樸素貝葉斯、最大熵三種分類器并予以綜合。文獻(xiàn)[12]基于語(yǔ)言學(xué)特征,重點(diǎn)關(guān)注了篇章中的歸總句對(duì)篇章極性的影響。文獻(xiàn)[13]通過(guò)建立情感詞典和基于情感文本訓(xùn)練語(yǔ)料來(lái)獲取句子中的情感要素,通過(guò)將單一情感要素和復(fù)合情感要素匯總計(jì)算,作為情感極性判斷的依據(jù)。文獻(xiàn)[14-15]均采用建立情感詞典或觀點(diǎn)詞詞典的方法,統(tǒng)計(jì)觀點(diǎn)詞的詞頻和極性。其中,文獻(xiàn)[15]以特征-觀點(diǎn)詞對(duì)的形式表示文本,但沒(méi)有更細(xì)致地考慮副詞對(duì)極性的加強(qiáng)或減弱作用。同時(shí),對(duì)于搭配的情感傾向僅考慮了觀點(diǎn)詞的極性,而沒(méi)有對(duì)整個(gè)搭配進(jìn)行綜合考量。
本文對(duì)汽車領(lǐng)域的評(píng)論文本開展研究,利用已有的資源,建立了汽車方面特征詞典和情感詞詞典。考慮了12種模式的詞語(yǔ)詞性搭配,利用建立的語(yǔ)言學(xué)規(guī)則自動(dòng)對(duì)抽取出的搭配四元組進(jìn)行極性分類,以此將特征值建立文本的向量化表示,并進(jìn)行五級(jí)情感極性分類。
2 汽車評(píng)論文本搭配抽取
本文利用詞語(yǔ)搭配模式抽取文本句子中特征、程度、觀點(diǎn)、反轉(zhuǎn),以此建立四元組,其中,每個(gè)四元組表示一個(gè)觀點(diǎn),這樣可對(duì)文本建立觀點(diǎn)袋模型。
2.1觀點(diǎn)袋模型
Qu等人[6]最早提出了觀點(diǎn)袋(bag-of-opinions)模型,該文將文本表示成為(root,modifier,negator)三元組。在此基礎(chǔ)上,本文考慮到漢語(yǔ)的用詞特點(diǎn)以及副詞對(duì)觀點(diǎn)傾向的加強(qiáng)或減弱影響,將文本表示為特征-觀點(diǎn)的觀點(diǎn)袋模型,即
其中,opi表示第i個(gè)觀點(diǎn),用特征-觀點(diǎn)搭配四元組表示,fei,cdi,seni,ndi分別為特征詞、程度副詞、情感詞和否定副詞。N表示每篇文本中特征-觀點(diǎn)搭配四元組op的個(gè)數(shù)。
2.2 12種詞性搭配模式
本文使用中科院ICTCLAS[16]對(duì)文本進(jìn)行分詞,利用文獻(xiàn)[17]中的汽車領(lǐng)域中的特征詞典,對(duì)特征詞表進(jìn)行重新綁定以降低分詞錯(cuò)誤對(duì)結(jié)果的影響,并將其詞性標(biāo)注為fe。在此基礎(chǔ)上,本文依據(jù)詞性設(shè)計(jì)了12種搭配模式。
對(duì)于二元搭配,文獻(xiàn)[3]統(tǒng)計(jì)結(jié)果顯示候選搭配詞一般出現(xiàn)在目標(biāo)詞后三個(gè)詞長(zhǎng)度范圍內(nèi)。本文在此基礎(chǔ)上,將模式進(jìn)行了擴(kuò)展,通過(guò)實(shí)驗(yàn)考察了詞語(yǔ)之間窗口長(zhǎng)度對(duì)情感詞語(yǔ)搭配的影響。各搭配模式所對(duì)應(yīng)的詞窗口大小設(shè)置,如表1所示。
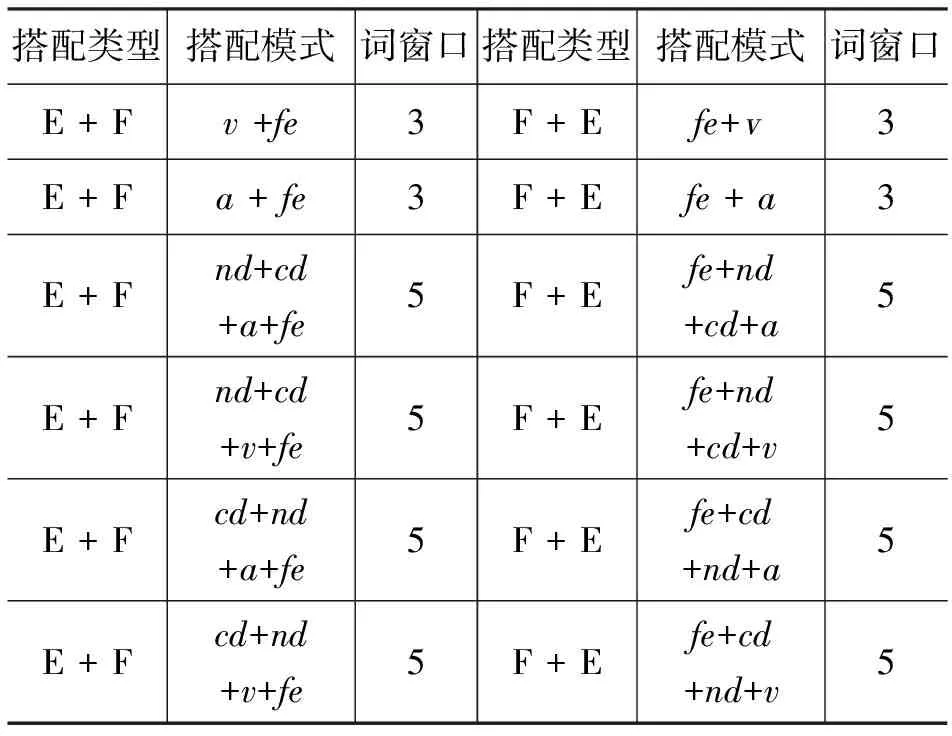
表1 情感搭配模式與窗口大小
其中,v、a、cd、nd分別表示動(dòng)詞、形容詞、程度副詞和否定副詞。詞窗口設(shè)置以特征詞為基準(zhǔn)向前、后各開辟三或五個(gè)詞長(zhǎng)。
2.3 最小支持度minsup
根據(jù) 2.2節(jié)設(shè)計(jì)的搭配模式,在抽取搭配過(guò)程中,對(duì)于出現(xiàn)頻率極小的搭配四元組,本文認(rèn)為其對(duì)文檔的情感傾向極性分類的作用不大。主要原因: ①搭配四元組確實(shí)是出現(xiàn)次數(shù)比較低; ②由于網(wǎng)絡(luò)不規(guī)范用語(yǔ)錯(cuò)誤所致。因此,本文引入了最小支持度minsup對(duì)抽取的搭配四元組進(jìn)行限制。對(duì)于搭配四元組opi,最小支持度計(jì)算見(jiàn)公式(1)所示。
(1)
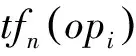
2.4 模式存在的問(wèn)題與解決策略
在抽取搭配四元組時(shí),有時(shí)會(huì)遇到模式?jīng)_突和情感詞并列的問(wèn)題。針對(duì)這些情況,給出如下解決策略。
(1) 模式?jīng)_突
① 對(duì)于v+fe、a+fe、fe+a、fe+v四種不含副詞的搭配模式,有時(shí)會(huì)出現(xiàn)與帶有副詞的搭配模式出現(xiàn)交集的情形。例如: “發(fā)動(dòng)機(jī)非常好”按照模式fe+a可以抽出(發(fā)動(dòng)機(jī),null,好,null),而按照f(shuō)e+nd+cd+a則會(huì)得到(發(fā)動(dòng)機(jī),非常,好,null)。
策略1: 當(dāng)同一子句中出現(xiàn)特征詞與情感詞相同的短搭配和長(zhǎng)搭配時(shí),舍去短搭配。
② 對(duì)于同一句子中同一個(gè)特征詞fe依表1中E+F和F+E類型均能抽取出搭配四元組。
策略2: 在保留最長(zhǎng)搭配的前提下,使用公式(2)計(jì)算op中特征與情感詞對(duì)(fe,sen)的互信息值,取互信息值最大的搭配作為該句子的抽取搭配四元組。
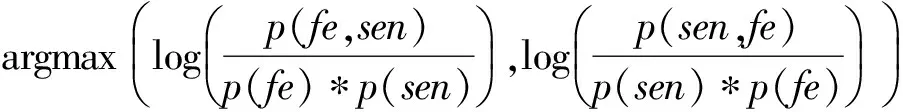
(2)
其中,p(fe,sen)和p(sen,fe)表示op中特征詞與情感詞對(duì)(fe,sen)和(sen,fe)同現(xiàn)的概率,p(fe)表示特征fe出現(xiàn)的概率,p(sen)表示情感詞sen出現(xiàn)的概率。
(2) 模式中情感詞并列
在漢語(yǔ)中,頓號(hào)“、”和“,”以及“和”,用于并列連用的單字、詞語(yǔ)[18]。
策略3: 當(dāng)多個(gè)特征詞存在并列關(guān)系且搭配同一情感詞,或是多個(gè)并列情感詞均修飾同一特征時(shí),分別抽取所有的特征與情感詞搭配,而不受詞窗口長(zhǎng)度限制。例如: “駕駛很輕盈、很舒適”可以得到兩個(gè)搭配四元組(駕駛,很,輕盈,null)和(駕駛,很,舒適,null)。
3 搭配傾向與情感分類
本文參考漢語(yǔ)詞語(yǔ)搭配的特點(diǎn),結(jié)合汽車領(lǐng)域內(nèi)的特有形式,構(gòu)造了一系列規(guī)則計(jì)算搭配四元組的情感極性值,以此計(jì)算特征權(quán)重將文本向量化表示,并進(jìn)行情感極性分類。
3.1 建立情感詞典與副詞詞典
本文通過(guò)構(gòu)建情感詞詞典和副詞詞典為搭配四元組中的情感詞和副詞提供傾向極性,以便進(jìn)行搭配四元組的自動(dòng)情感傾向極性分類。
本文收集了漢語(yǔ)中常用的程度副詞cd以及否定副詞nd,建立了副詞詞典,共計(jì)196個(gè)。詞典的構(gòu)成如表2所示。

表2 副詞詞典
對(duì)于情感詞詞典,本文將山西大學(xué)中文評(píng)價(jià)詞詞表和大連理工大學(xué)信息檢索研究室的情感詞匯本體[19]合并建立情感詞詞典。詞典規(guī)模如表3所示。

表3 情感詞詞典構(gòu)成
3.2 搭配四元組的情感傾向極性
3.2.1 特征詞與情感詞分類
本文使用文獻(xiàn)[17]中的汽車領(lǐng)域特征詞作為本文的特征詞典。并對(duì)其進(jìn)行如下處理。
(1) 特征詞分類
在漢語(yǔ)中,有些詞帶有明顯的情感傾向,而有些詞語(yǔ)盡管本身是中性的,但在特定的語(yǔ)境中搭配上帶有情感傾向或中性的其他詞語(yǔ)時(shí),亦可表現(xiàn)出情感傾向[3]。我們分析了漢語(yǔ)用詞特點(diǎn),并考慮了汽車領(lǐng)域的一些特殊用法,本文使用的特征詞分類如表4所示。

表4 各類型特征詞集的規(guī)模
(2) 情感詞分類
對(duì)于一些描述物體的物理性質(zhì)的中性情感詞,雖然其本身并不具備情感傾向,但與不同的特征詞搭配會(huì)出現(xiàn)截然不同的情感傾向。本文選取了文獻(xiàn)[20]中歸納的部分中性形容詞,將最常見(jiàn)的12種中性詞單獨(dú)列出處理,即描述物體的體積、面積、長(zhǎng)度、質(zhì)量、數(shù)量等物理性質(zhì)的,表達(dá)“大”、“小”、“高”、“低”、“長(zhǎng)”、“短”、“軟”、“硬”、“輕”、“重”、“多”、“少”這12種概念的詞語(yǔ),并擴(kuò)展加入了這些形容詞的比較級(jí)和最高級(jí)形式。對(duì)這12種中性詞,再將其分為四類,如表5所示。
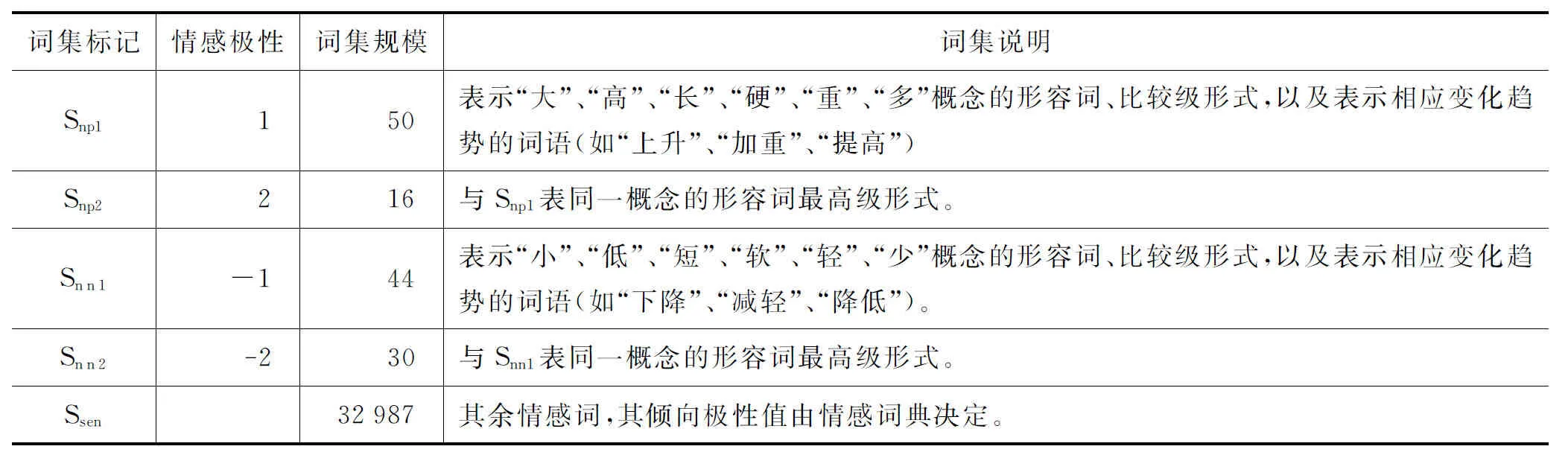
表5 各類型情感詞集的規(guī)模及其情感極性值
3.2.2 搭配四元組的情感傾向計(jì)算
為了計(jì)算搭配四元組op的情感極性值,假設(shè)s(op),s(cd),s(nd),s(sen)分別表示搭配四元組op、程度副詞cd、否定副詞nd以及情感詞sen的情感極性值,當(dāng)程度副詞或否定副詞出現(xiàn)缺省時(shí),極性值默認(rèn)值為1。對(duì)于特征詞和情感詞的不同類別,分三種情況計(jì)算搭配四元組op的情感極性值。
① 若op中的fe∈Sr且sen∈Snp1∨sen∈Snp2∨sen∈Snn1∨sen∈Snn2,則
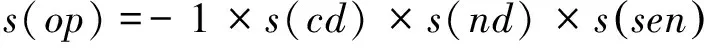
這類特征詞可與“大”、“高”等概念的中性情感詞搭配時(shí)具有極性反轉(zhuǎn)作用,例如,
s(油耗,很,高,null)=-1×s(很)×s(null)×s(高)= -1×2×1×1= -2;
② 若op中的fe∈Sd且sen∈Snp1∨sen∈Snp2∨sen∈Snn1∨sen∈Snn2,則
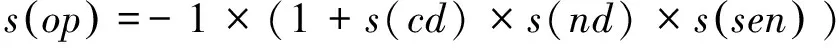
這類特征詞的出現(xiàn)通常意味著貶義傾向,且同樣對(duì)表示“大”、“高”等概念的中性情感詞具有反轉(zhuǎn)作用,例如,
s(側(cè)傾,非常,大,null)=-1×(1+s(非常) ×s(null) ×s(大))=-1×(1+(2×1)×1)=-3;
③ 若op不滿足①和②的條件時(shí),則
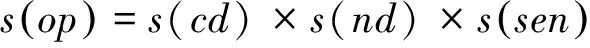
這類搭配四元組的情感極性主要由情感詞sen和副詞搭配決定,例如,
s(內(nèi)飾,null,漂亮,不)=s(null)×s(不)×s(漂亮)= 1×-1×1= -1。
對(duì)于搭配四元組op,為了使最終情感極性值滿足s*(op)∈{-2,-1,0,1,2},我們使用公式(3)對(duì)s(op)進(jìn)行修正。
(3)
3.3 文本情感極性分類過(guò)程
(1) 文本表示
通常的文本分類問(wèn)題將文本表示成特征為分量的向量空間模型。對(duì)于第i篇文本Di向量化表示為:
N表示特征詞總數(shù),這里wik表示第i篇文本的第k個(gè)特征feik的權(quán)重。當(dāng)一個(gè)特征feik存在多個(gè)搭配時(shí),采用各搭配的情感極性值的算術(shù)平均值作為feik的情感極性值。其權(quán)重wik計(jì)算見(jiàn)公式(4)。
(4)
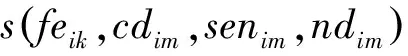
(2) 缺省值的補(bǔ)充
當(dāng)有些特征在某些篇章中缺失時(shí),說(shuō)明作者并未對(duì)該特征發(fā)表自己的看法,因此,不能簡(jiǎn)單將其傾向極性賦為0值。本文依據(jù)訓(xùn)練集中其他文檔的對(duì)應(yīng)傾向極性,將同一極性值下的所有文檔用于對(duì)這類缺失特征值進(jìn)行補(bǔ)充。
當(dāng)s(feik)=0時(shí),使用如下公式(5)~(7)對(duì)其進(jìn)行缺省值補(bǔ)充。
(5)
(6)
(7)

對(duì)于測(cè)試集中的文本極性值為0的特征項(xiàng),使用測(cè)試集中全部文檔的該特征項(xiàng)非0項(xiàng)的均值作為該特征極性值的補(bǔ)充。
(3) 文本相似度計(jì)算
為了對(duì)文本進(jìn)行情感極性分類,本文使用了文本相似度方法。對(duì)于訓(xùn)練集中第c類文檔集的類中心的第k個(gè)特征詞feck,其權(quán)重計(jì)算見(jiàn)公式(8)。
(8)
利用公式(8),得到第c類中心文檔如下:
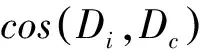
(9)
其中,wik表示第i篇文檔的第k個(gè)特征的權(quán)重。
4 實(shí)驗(yàn)結(jié)果及分析
4.1 實(shí)驗(yàn)數(shù)據(jù)與評(píng)價(jià)指標(biāo)
本文使用COAE2012任務(wù)3的汽車語(yǔ)料作為實(shí)驗(yàn)數(shù)據(jù),共計(jì)8 000篇。其中,訓(xùn)練集3 000篇,測(cè)試集5 000篇。分析發(fā)現(xiàn),評(píng)測(cè)數(shù)據(jù)存在較嚴(yán)重的不平衡性,訓(xùn)練集和測(cè)試集中中性文檔即極性值為3的文檔分別占總體的71.8%和72.96%。實(shí)驗(yàn)過(guò)程中我們也發(fā)現(xiàn),數(shù)據(jù)的這種不平衡性將對(duì)結(jié)果產(chǎn)生一定負(fù)面的影響。
本文使用COAE2012任務(wù)3使用的兩個(gè)指標(biāo)進(jìn)行結(jié)果評(píng)價(jià): 精確率(accuracy)以及平均均方錯(cuò)誤率(Mean Square Error,MSE)。accuracy和MSE的計(jì)算方法如公式(10)及(11)所示。
(10)
(11)
公式(10)中,accuracy為分類正確的文檔數(shù)與測(cè)試集文檔總數(shù)的比值。公式(11)中,N表示測(cè)試樣本總數(shù),i表示樣本編號(hào),answeri表示答案中的每個(gè)樣本的打分,resulti為提交系統(tǒng)的答案中每個(gè)樣本的打分。
4.2 實(shí)驗(yàn)結(jié)果及分析
對(duì)于文本情感極性分類,按照3.3節(jié)文本情感極性分類過(guò)程,我們進(jìn)行了如下實(shí)驗(yàn)。
實(shí)驗(yàn)1: 最小支持度閾值確定
本實(shí)驗(yàn)利用第2.2節(jié)設(shè)計(jì)的搭配四元組抽取模式,以及第2.3節(jié)構(gòu)造的最小支持度minsup,選取了minsup在[5.0E-4,4.5E-3]之間跨度為2.0E-4的21個(gè)值分別對(duì)測(cè)試集文本進(jìn)行情感搭配抽取并進(jìn)行文檔傾向極性分類,實(shí)驗(yàn)結(jié)果見(jiàn)圖1、2。
(1) 圖1隨著minsup的增加,抽取的搭配四元組越來(lái)越少,minsup的取值與抽取出的搭配四元組數(shù)目成反比。當(dāng)在minsup≤5.0E-4時(shí)與不引入minsup進(jìn)行限制相比較,抽取出的搭配數(shù)完全一致,
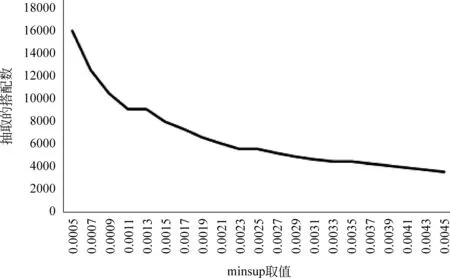
圖1 minsup的不同取值對(duì)搭配抽取的影響

圖2 極性分類實(shí)驗(yàn)結(jié)果
因此本文以5.0E-4作為minsup起始取值。而當(dāng)minsup值大于0.002 7時(shí),抽取出的搭配四元組已不足5 000個(gè),對(duì)部分文檔而言,搭配四元組已無(wú)法刻畫其整體情感極性傾向。
(2) 圖2是在minsup取不同值下抽取的21組搭配集合,分別對(duì)文檔進(jìn)行情感極性分類的結(jié)果。在minsup=0.000 9時(shí),情感極性分類達(dá)到最佳效果。當(dāng)minsup取值過(guò)小時(shí),抽取的搭配四元組包含大量無(wú)用或者無(wú)意義的搭配四元組,對(duì)準(zhǔn)確刻畫文檔情感傾向產(chǎn)生了干擾效果。當(dāng)minsup大于 0.002 7 后,由搭配四元組刻畫的文檔的情感傾向?qū)㈦S著minsup的增大趨向于中性即極性值為3,但由于數(shù)據(jù)較為嚴(yán)重的不平衡性,整體結(jié)果最終會(huì)穩(wěn)定在72.96%,即全部分類至第三類中。
實(shí)驗(yàn)2: 與COAE2012文檔傾向極性分類其他結(jié)果的比較
根據(jù)實(shí)驗(yàn)1中各種最小支持度得到的分類結(jié)果,本實(shí)驗(yàn)選取minsup=0.000 9,與COAE2012其它文檔傾向極性分類結(jié)果相比較,實(shí)驗(yàn)結(jié)果見(jiàn)表6。
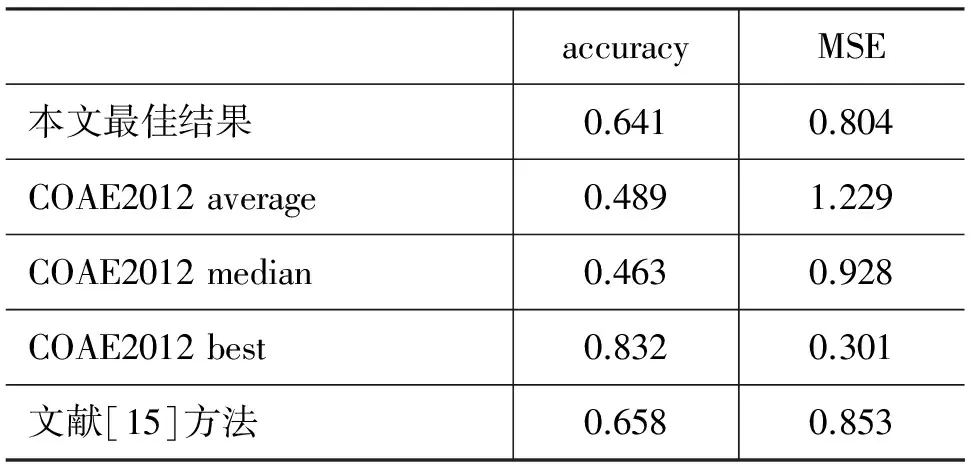
表6 實(shí)驗(yàn)結(jié)果與COAE2012其他結(jié)果的比較
由表6可以看出,COAE2012 best>文獻(xiàn)[15]方法結(jié)果>本文最佳結(jié)果>COAE2012 average>COAE2012 median,本文的方法處于中上水平。
通過(guò)分析各參評(píng)單位在COAE2012該任務(wù)中取得的結(jié)果,取得最好成績(jī)的是中國(guó)傳媒大學(xué)[12],他們利用了篇章中歸總句的特性進(jìn)行了分類,通過(guò)加大篇章中歸總句的權(quán)重對(duì)篇章進(jìn)行打分。文獻(xiàn)[15]采用的特征-觀點(diǎn)表示方法與本文類似,其accuracy結(jié)果與本文最好結(jié)果近似,但本文的MSE值較低,表明本文方法分類錯(cuò)誤的偏離程度較小,且本文無(wú)需訓(xùn)練分類器,所采用的特征詞表規(guī)模較文獻(xiàn)[15]的小,在低維特征下依然能對(duì)文本的情感進(jìn)行較準(zhǔn)確的刻畫,顯示出本文的方法具有一定的可行性與有效性。
5 結(jié)束語(yǔ)
本文考察了詞性間的搭配關(guān)系,設(shè)計(jì)了12種詞性搭配模式。對(duì)于不同類型的詞匯在特定領(lǐng)域下的特殊表達(dá),設(shè)計(jì)了一系列的規(guī)則函數(shù)自動(dòng)對(duì)抽取出的搭配四元組進(jìn)行情感傾向極性分類。為了從篇章級(jí)文本中抽取特征-觀點(diǎn)搭配四元組并建立觀點(diǎn)袋模型,過(guò)濾掉一些無(wú)意義搭配,引入最小支持度minsup對(duì)抽取搭配進(jìn)行限制,通過(guò)考察所有minsup取值對(duì)情感搭配關(guān)系抽取以及情感傾向極性分類的影響,確定minsup的最優(yōu)取值。為了檢驗(yàn)本文的方法對(duì)篇章級(jí)文本情感極性分類的有效性,使用了COAE2012任務(wù)3的汽車語(yǔ)料。利用訓(xùn)練集生成其類別中心文檔,在測(cè)試集上分別與各類別中心文檔計(jì)算余弦相似度,將測(cè)試集文檔分類到最相似的類別中。與COAE2012評(píng)測(cè)結(jié)果相比較,本文的方法處于中上水平,顯示其具有一定的可行性和有效性,然而本文的方法需要使用已有的領(lǐng)域本體特征,抽取的情感搭配無(wú)法覆蓋全部的文檔,同時(shí)沒(méi)有考慮歸總句對(duì)篇章極性的影響。因此,如何自動(dòng)建立領(lǐng)域本體知識(shí)庫(kù),引入對(duì)歸總句權(quán)重影響的研究,并對(duì)搭配模式進(jìn)一步細(xì)化將是我們今后深入研究的課題。
[1] Wiebe J, Bruce R, Bell M, et al. A corpus study of evaluative and speculative language[C]//Proceedings of the 2nd ACL SIGdial Workshop on Discourse and Dialogue. USA: ACL, 2001: 1-10.
[2] Xia Y Q, Xu R F, Wong K F, et al. The unified collocation framework for opinion mining[C]//Proceedings of Machine Learning and Cybernetics, 2007 International Conference on. IEEE, 2007, 2: 844-850.
[3] 王素格. 基于 Web 的評(píng)論文本情感分類問(wèn)題研究 [D]. 上海: 上海大學(xué), 2008.
[4] Smadja F. Retrieving collocations from text: Xtract[J]. Computational linguistics, 1993, 19(1): 143-177.
[5] 王素格, 楊軍玲, 張武. 自動(dòng)獲取漢語(yǔ)詞語(yǔ)搭配[J]. 中文信息學(xué)報(bào), 2006, 20(6): 31-37.
[6] Qu L, Ifrim G, Weikum G. The bag-of-opinions method for review rating prediction from sparse text patterns[C]//Proceedings of the 23rd International Conference on Computational Linguistics. Association for Computational Linguistics, 2010: 913-921.
[7] Thet T T, Na J C, Khoo C S G. Aspect-based sentiment analysis of movie reviews on discussion boards[J]. Journal of Information Science, 2010, 36(6): 823-848.
[8] 王素格, 楊安娜. 基于混合語(yǔ)言信息的詞語(yǔ)搭配傾向判別方法[J]. 中文信息學(xué)報(bào), 2010, 24(3): 69-74.
[9] 劉康, 王素格, 廖祥文,等. 第四屆中文傾向性分析評(píng)測(cè)總體報(bào)告[C]//Proceedings of the COAE2012, Nanchang, China,2012:1-33.
[10] 唐都鈺, 石秋慧,王沛,等. HITIRSYS:COAE2012情感分析系統(tǒng)[C]//Proceedings of the COAE2012, Nanchang, China, 2012: 44-52.
[11] 林莉媛, 蘇艷,戴敏,等. Suda_SAM_OMS情感傾向性分析技術(shù)報(bào)告[C]//Proceedings of the COAE2012, Nanchang, China, 2012:69-76.
[12] 程南昌, 侯敏,騰永林,等. 基于文本特征的語(yǔ)篇傾向性分析研究[C]//Proceedings of the COAE2012, Nanchang, China, 2012: 89-94.
[13] 劉楠, 賀飛艷,彭敏,等. 基于情感要素的否定句極性判別方法[C]//Proceedings of the COAE2012, Nanchang, China, 2012: 123-131.
[14] 魏現(xiàn)輝, 任巨偉,何文澤,等. DUTIR COAE2012評(píng)測(cè)報(bào)告[C]//Proceedings of the COAE2012, Nanchang, China,2012: 34-43.
[15] 崔安頎, 張永鋒,劉奕群,等. 基于情感詞典的中文傾向性分析[C]//Proceedings of the COAE2012, Nanchang, China,2012: 118-122.
[16] 計(jì)算所漢語(yǔ)詞法分析系統(tǒng)ICTCLAS. http://www.ictclas.cn/.
[17] 王素格, 尹學(xué)倩, 李茹, 等. 基于非完備信息系統(tǒng)的評(píng)價(jià)對(duì)象情感聚類[J]. 中文信息學(xué)報(bào), 2012, 26(4): 98-102.
[18] 寧鴻彬, 徐同. 新頒《標(biāo)點(diǎn)符號(hào)用法》通釋[M]. 教育科學(xué)出版社, 1992.
[19] 徐琳宏, 林鴻飛, 潘宇,等. 情感詞匯本體的構(gòu)造[J]. 情報(bào)學(xué)報(bào), 2008, 27(2): 180-185.
[20] 顧正甲, 姚天昉. 評(píng)價(jià)對(duì)象及其傾向性的抽取和判別[J]. 中文信息學(xué)報(bào), 2012, 26(4): 91-97.
The Bag-of-Opinions Method for Car Review Sentiment Polarity Classification
LIAO Jian1, WANG Suge1,2,LI Deyu1,2, ZHANG Peng1
(1. School of Computer & Information Technology, Shanxi University, Taiyuan, Shanxi 030006, China; 2. Key Laboratory of Computational Intelligence and Chinese Information Processing of Ministry of Education, Shanxi University, Taiyuan, Shanxi 030006, China)
Focused on the online review sentiment polarity classification problem, a multi-level sentiment classification method is proposed based on bag-of-opinion model and a set of linguistic rules. According to the part-of-speech of each word in the sentences, 12 patterns are designed for the feature-opinion pairs’ extraction, which enable to represent the whole text in a series of four-tuple of “feature, degree word, opinion word, negation word”. After designing the estimation of the sentiment priority of the four-tuple, the cosine similarity is further adopted for a 5-level sentiment polarity classification. Experiments on the dataset from COAE2012 Task 3 car dataset indicate a good result compared to the performances of the other runs in COAE.
sentiment classification; bag of opinion; POS collocation
1003-0077(2015)03-0113-08
2013-04-08 定稿日期: 2013-07-31
國(guó)家自然科學(xué)基金(61175067,61272095); 山西省自然科學(xué)基金(2010011021-1,2013011066-4); 山西省科技攻關(guān)項(xiàng)目(20110321027-02);山西省留學(xué)基金(2013-014)
TP391
A
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
