搜索日志中中文人名自動識別
2015-04-21 08:43:48呂學強
中文信息學報 2015年3期
王 玥,呂學強,李 卓,舒 燕
(1. 北京信息科技大學 網絡文化與數字傳播北京市重點實驗室,北京 100101;2. 北京拓爾思信息技術股份有限公司,北京 100101)
?
搜索日志中中文人名自動識別
王 玥1,呂學強1,李 卓1,舒 燕2
(1. 北京信息科技大學 網絡文化與數字傳播北京市重點實驗室,北京 100101;2. 北京拓爾思信息技術股份有限公司,北京 100101)
搜索日志中人名識別一直是日志挖掘中的一個重點和難點,其結果好壞直接關系搜索引擎的檢索效率和準確率。由于分析了長文本中人名識別方法在搜索日志中使用存在很多困難與不足,因而該文提出了一種在搜索日志中識別中文人名的方法。該方法將搜索日志中人名內部用字的概率特征引入條件隨機場,再根據搜索日志的特點計算人名可信度提取搜索日志中的中文人名。在搜狗查詢日志上進行實驗,正確率平均達到了81.97%、召回率平均達到了85.81%,綜合指標F值平均達到了83.79%。
人名識別;搜索日志;條件隨機場;可信度
1 引言
近幾年,隨著互聯網的飛速發展,搜索引擎的地位也在不斷的上升,對于搜索日志的研究也逐漸成了學術界的熱點問題。搜索日志中命名實體識別一直是日志挖掘中的一個重點和難點,其結果好壞直接關系搜索引擎的檢索效率和檢索準確率。命名實體識別主要包括: 人名、地名、機構名等實體。從近幾年Dou Shen、Javier Artiles、張磊[1-4]等人的研究來看,人名在搜索引擎的查詢結果中占很大的比例,如果能從搜索日志中自動挖掘出人名實體,那么就能夠獲得大量具有時效性和實用性的信息。
現有的人名識別方法可以歸結為基于規則的方法和基于統計的方法兩大類。基于規則的方法準確率相對較高,但是制定規則耗時耗力,且通用性和可移植性不高[5-8];基于統計的方法靈活性和魯棒性較好,不需要太多人工干預,只要存在大規模的已標注并且校對好的語料庫進行訓練即可[9-15]。由于搜索日志具有簡短、缺少上下文、內容多次重復出現、語句跳躍性強等特點,與長文本存在差異性,長文本中的人名識別方法很難直接應用于搜索日志進行人名識別。Marius Pasc等[16]人嘗試使用提取模板的方法在英文的查詢日志中中進行了命名實體識別。然而,由于中文本身存在的復雜性,上述的方法并不能被直接用于搜索日志中文人名的識別。因此,本文提出一種基于條件隨機場的搜索日志中中文人名識別方法,主要解決搜索日志中中文人名的識別問題。
2 搜索日志中人名的特點
搜索日志是由搜索引擎的查詢串構成的,在內容上與長文本存在一定的差異性。長文本是整句構成段落,段落再構成篇章而形成,搜索日志是由查詢串組成。查詢串形式具有多樣性的特點,主要由整句、多個關鍵詞、單獨詞語、單獨短語等構成。從長度上看,長文本長度各異,但是以長句為主,而搜索日志中查詢串的主要長度集中在2~35個字符范圍內,相對于長文本較短。從重復性上分析,長文本前后文整句重復的概率很小,而搜索日志中查詢串會出現大量的重復現象。
由于搜索日志和長文本有很大差異性,所以搜索日志與長文本中中文人名的存在形式也存在著很大的差別,如表1是搜索日志中中文人名的特點。

表1 搜索日志中中文人名特點
表1中列出的搜索日志中人名存在的各種特點,也正是導致長文本中人名識別方法在搜索日志中效果都不甚理想的原因之一。
3 搜索日志中中文人名識別方法
搜索日志中人名前后字詞之間存在一定的連續性,可以將搜索日志中人名識別的問題轉化成序列標記問題。而條件隨機場正是專門解決序列標記問題的模型,因此本文選用條件隨機場進行中文人名識別。
3.1 人名標記方法
本文采用四詞位標記法[17]作為文本中字的序列標注方法,如表2。

表2 特征標記及其意義
3.2 人名特征及其特征取值
由于搜索日志中人名存在很強烈的用字特征,因此,很有必要建立人名知識庫將用字特征引入條件隨機場。
3.2.1 人名用字知識庫的構建
本文使用的人名知識庫包括姓氏表、單名用字表、雙名首字表、雙名末字表。
姓氏表整理方法: 提取百家姓、維基百科[18]中中國姓氏表和2000年11月《人民日報》中不重復的姓氏構成詞表。單名用字表、雙名首字表、雙名末字表的整理方法: 將《人民日報》和“加加亞洲人名庫[19]”中包含姓氏表中姓氏的人名抽取出來,同時統計所有人名中,每類用字出現的頻次,然后將結果存儲下來構成這三個表。
3.2.2 姓氏特征及取值
姓氏在中文姓名用字中出現的頻度非常高,所以當前字是否在姓氏表中出現是中文人名識別的一個很重要的特征。
標注方法: 集合F{(k1,fk1),(k2,fk2),…(ki,fki)…(kn,fkn)}為姓氏用字集合,ki為第i個姓氏,fki為姓氏ki出現的頻次,xi為當前字。
如果(xi,fxi)∈F,則xi標記為Y;如果(xi,fxi)?F,則xi標記為N。
3.2.3 單字雙字人名特征及取值
中文人名用字本身就有明顯的特征,一些字在人名中大量重復出現。通過統計發現這些大量出現的字在單字人名、雙名首字、雙名末字中出現的概率也是相差很大的,所以本文加入人名用字特征。
將人名用字分為三類:
單字人名: “劉哲”中“哲”字;
雙名首字: “劉亦菲”中“亦”字;
雙名末字: “趙忠祥”中“祥”字。
單字人名標記方法: 集合W{(w1,fw1),(w2,fw2)…(wi,fwi)…(wn,fwn)}表示單字人名表,其中wi表示集合W中的第i個字,fwi表示wi的出現的頻次,xi表示當前待標記字,函數Fre(W,xi)表示W集合中xi的詞頻。
如果Fre(W,xi)>0且pm
雙名首字、雙名末字的標記方法同單字人名,它們的不同之處就是查詢詞語的集合詞表不同,在進行標記的時候閾值參數的數值可能不同。
3.3 特征模板的選取
考慮到人名用字、訓練語料和姓氏用字之間的依存和共現關系,條件隨機場的特征模板要進行合理的設計。識別中使用的模板文件,每個特征項都設定了與其相關的復合模板關系。
由于人名的上下文對人名識別會產生一定影響,表3的模板選取就表示字的上下文關聯關系,從當前字開始,選取向前兩字向后兩字共五字的關聯特征。

表3 字特征應用的特征模板
表4至表7表示人名用字特征模板的選取方式,以及人名用字的內在關聯關系。
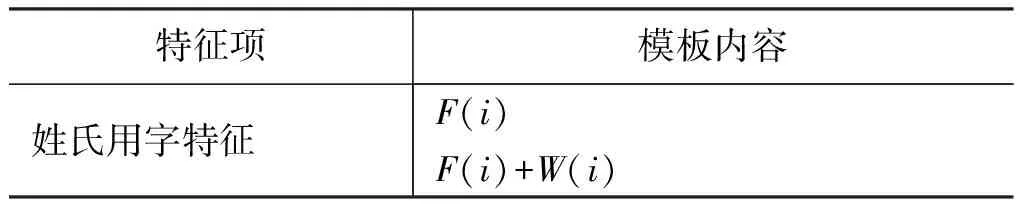
表4 姓氏用字特征應用的特征模板

表5 單名用字特征應用的特征模板

表6 雙名用字特征應用的特征模板

表7 雙名末字特征應用的特征模板
表3至表7中,i表示當前字所在位置,W(i)表示字i,F(i)字W(i)的姓氏特征標記,S(i)表示字W(i) 的單名用字特征標記,DF(i)表示字W(i)的雙名首字特征標記,DL(i)表示字W(i)的雙名用字特征標記。
3.4 訓練語料的重組
由于搜索日志中人名有上下文嚴重缺失的特點。而人民日報中的語料,絕大多數是完整的句子,人名存在上下文。如果使用原始格式的訓練語料加入條件隨機場進行學習,模型很難學習到搜索日志中人名的這一特點,所以本文中方法將訓練語料進行了修改和擴充。首先將訓練語料中所有的中文人名提取出來,以每一行為一個人名的形式加入到原始的人民日報語料中再進行特征標記處理,這樣條件隨機場在訓練的時候,既可以學習到有上下文的人名的標注形式,也能夠學習到上下文缺失的人名的標記方式,這樣使訓練語料更加符合搜索日志中搜索串的特點。
4 基于可信度的人名召回
4.1 人名可信度
由于訓練語料并不是基于搜索日志而是來源于人民日報的分詞語料,人民日報屬于新聞語料,并不能涵蓋搜索日志語料的所有特點。因此,在訓練的過程中,條件隨機場很難學習到搜索日志的全部特點,這將導致最終人名識別結果不夠完整。為此引入可信度的方法,對CRF漏識別的特定形式人名進行召回。
可信度是用來描述幾個連續的中文字符構成人名的可能性的一種概率。本文將中文人名可信度定義為

(1)
其中,P(FirstName)表示姓氏用字可信度,P(Word)表示名字用字可信度。
姓氏用字可信度定義如下:
(2)
其中,fki表示姓氏表集合F中第i個姓氏ki的頻次。
如果是單字名,名字用字可信度定義如下:
(3)
其中,fwi表示單名用字集合W中第i個人名用字wi的頻次。
如果是雙字名,名字用字可信度定義如下:
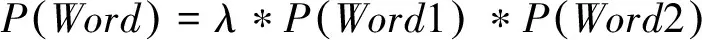
(4)
其中,fui表示雙名首字用字集合U中第i個人名用字ui的頻次,fvi表示雙名末字用字集合V中第i個人名用字vi的頻次,λ表示雙名調節系數。
4.2 基于可信度的人名連詞特征召回
搜索日志中大量出現“其他詞語+人名1+連詞+人名2+其他詞語”這種形式的查詢串,而識別的時候經常會出現“人名1”和“人名2”中只有一個被識別出來,本文通過如下方法將另一個人名也識別出來。
首先,從訓練語料中抽取連詞詞表,將前后都為人名的連詞抽取出來組成一個詞表Q{q1,q2,...,qi,...,qn},其中qi表示抽取出的第i個連詞。
其次,設R{r1,r2,...,ri,...,rn}是條件隨機場識別后的查詢日志,ri表示第i個查詢串,ri[j]表示查詢串ri中第j個字。如果ri[j]∈Q且(ri[j-m],...,ri[j-1])(m=2,3)是之前條件隨機場識別出的人名,那么將(ri[j-2],ri[j-1])、(ri[j-3],ri[j-2],ri[j-1])分別計算人名可信度P(ri[j-2],ri[j-1])、P(ri[j-3],ri[j-2],ri[j-1]),取兩者中較大的,如果較大的可信度達到一定閾值P1,那么將其標記為人名;如果ri[j]∈Q且(ri[j+1],...,ri[j+m])(m=2,3)是之前條件隨機場識別出的人名,那么同理將(ri[j+1],ri[j+2])、(ri[j+1],ri[j+2],ri[j+3])分別計算人名可信度P(ri[j+1],ri[j+2])、P(ri[j+1],ri[j+2],ri[j+3]),取兩者中較大的,如果較大的人名可信度達到一定閾值P1,那么將其標記為人名。
4.3 基于可信度的人名模板召回
由于搜索日志中人名出現位置有重復度高的特點,例如,[高圓圓]泳裝圖片、[郭晶晶]泳裝圖片,這兩個搜索串中人名只要識別出一個另一個就可以通過抽取的模板進行匹配,從而將另一個識別出來。
模板分三種: 第一種,前置模板“美麗女人[陳好]”;第二種,是后置模板“[高圓圓]泳裝照片”;第三種,是包含模板“天王巨星[劉德華]的演唱會”。
處理策略: 首先在集合Q中將所有的查詢串中已識別的人名全部去掉,剩余部分單獨存儲即為模板,使用模板匹配Q集合中沒有識別出人名的查詢串,匹配過程查詢串的內容必須要完全包含模板中的內容,而且未包含部分只能為連續的二至三個漢字,匹配成功后將這個連續二至三個漢字的字符串計算人名可信度,達到一定閾值P2的即標記為人名。
4.4基于可信度的人名重復性召回
由于搜索日志有同一人名多次大量出現的特點,比如: [霍震霆]與[朱玲玲]照片、[霍震霆]等查詢串都出現了霍震霆,如果一個人名被識別,那么再次出現該人名的時候就可以直接判斷出當前詞語是不是已出現的人名。
處理策略: 將已識別的人名加入詞表,進行可信度計算,達到閾值P3的直接存入人名詞表,與原始搜索日志進行匹配,如果能夠匹配,直接標記為人名。
5 實驗結果與分析
對于統計方法,使用機器學習模型進行人名識別評測,往往需要一定規模的測試集。這種測試集一般可分為兩種,一種是只含人名的句子集合,另一種是完全真實的語料。前者沒有考慮到真實的語言環境,識別結果往往偏高。因為在真實語料中不含人名的句子大量存在,其中不是人名的成分可能會被錯誤識別出來而影響結果,但是這樣的句子可能會被人為去除掉,所以結果并不能體現真實的效果。另一種是使用大規模的訓練語料,在一個小規模的真實樣本中進行測試,大規模的訓練語料幾乎包含了小型測試語料的所有內容, 這樣的結果也并不客觀。
本文為避免上述情況,將實驗一共分五組,訓練語料是2000年11月的《人民日報》,測試語料分別是在2008年6月1日至2008年6月5日的搜狗搜索日志[20]。每天的搜索日志都分別先去重,然后得到五天無重復的搜索日志,對于無重復的搜索日志分別隨機抽取1 000條作為測試集。
本文中單名用字的閾值是8,雙名首字閾值為20,雙名末字為20。雙名調節系數λ取0.5。連詞特征人名可信度閾值取1.78*10-6。閾值P2取1.6*10-6。閾值P3取3.0*10-6。
5.1 評測指標
針對中文人名,本文采用了三個評測指標,即準確率(P)、召回率(R)和綜合指標F值(F),其定義如下:
準確率:
(5)
召回率:
(6)
F值:
(7)
其中β是準確率P和召回率R之間的權衡因子,這里,P和R同等重要,因此取β=1,此時F值稱為F1值。
5.2 結果分析
本文選用最新版ICTCLAS的人名識別結果和郭家清的一種基于條件隨機場的人名識別方法[21]作為對比試驗,表8是兩個對比實驗與本文中條件隨機場的識別方法的識別結果對比。
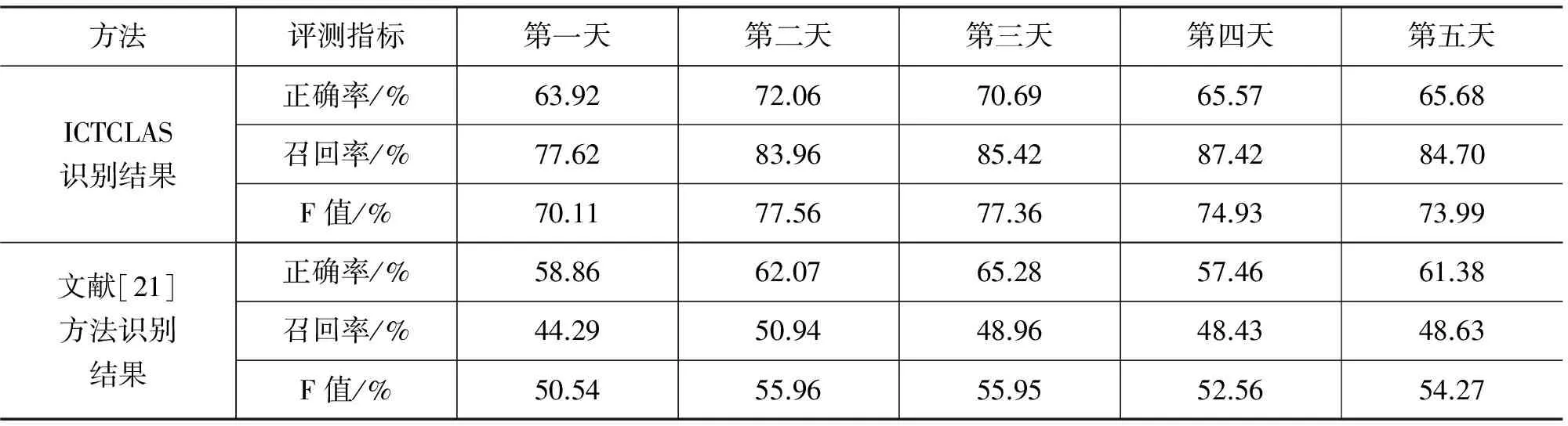
表8 ICTCLAS、文獻[21]與條件隨機場識別結果

續表
從表8可以看出在五天的搜索日志上,本文條件隨機場的識別方法正確率平均比ICTCLAS的識別結果高14.73%,召回率平均提高了0.01%,綜合效果F值平均提高了8.22%;比文獻[21]的方法正確率平均提高了21.31%,召回率平均提高了35.59%,綜合效果F值平均提高了29.16%。所以從總體效果上看,本文的方法在搜索日志中識別中文人名是有效的。
本文方法召回率在第三天的數據上低于ICTCLAS,是由于訓練語料只是用了一個月的人民日報,所以訓練集和測試集產生的數據稀疏非常嚴重,第三天的日志這種現象尤為明顯,所以召回率略有下降,經過補充訓練集,這種缺陷就可以被彌補。
表9是在條件隨機場的識別結果上加入人名可信度的方法的結果。
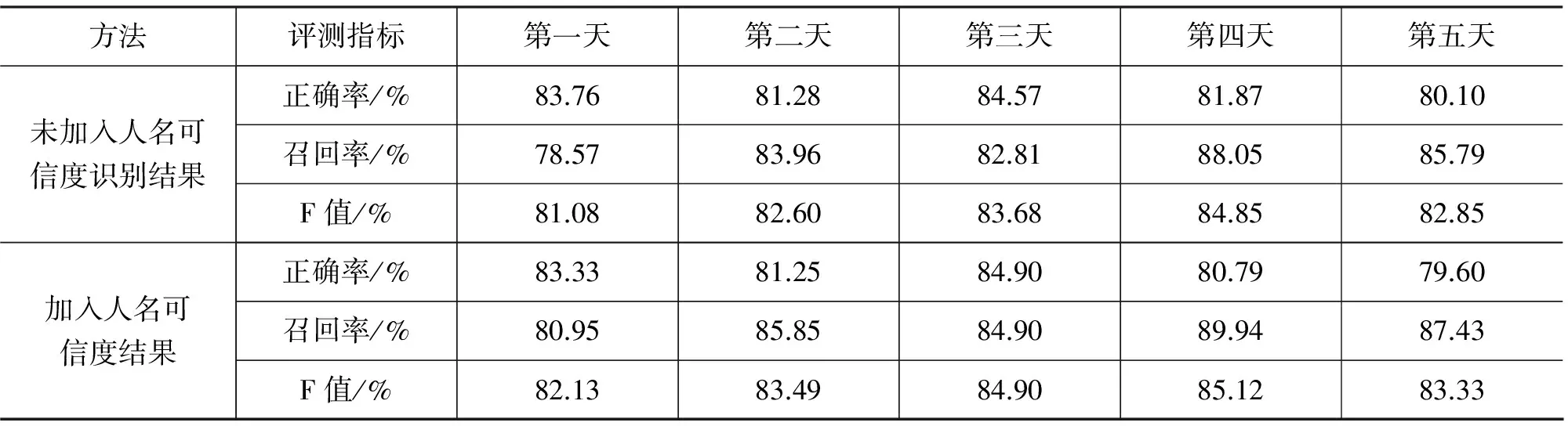
表9 加入人名可信度和不加入人名可信度的結果對比
從表9可以看出在五天的搜索日志上,加入人名可信度方法后,總體效果比條件隨機場直接識別出的結果又有所提升,綜合指標F值提升了0.78%,說明人名可信度方法也是行之有效的。
表10是本文方法的總體結果。
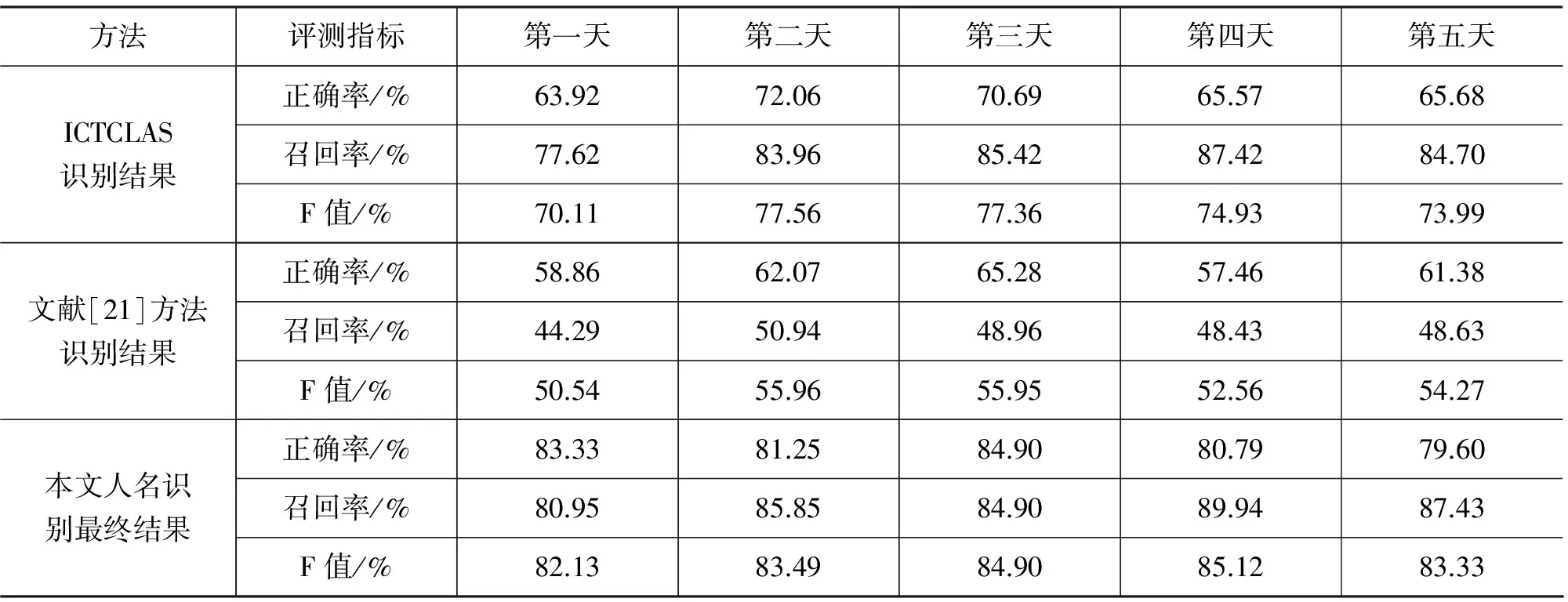
表10 Baseline方法與最終結果對比
從五天的結果來分析,本實驗中方法識別的結果,正確率平均比ICTCLAS要高14.39%,召回率平均高1.99%,綜合指標F值平均高 9.00%;與文獻[21]的方法相比,正確率平均高20.96%,召回率平均高37.56%,綜合指標F值平均高29.94%;無論單項還是總體識別效果都要優于對比方法。
在搜索日志中識別人名,正確率比召回率更重要。如果需要在搜索日志中挖出一個人名詞典,假設從一億條搜索日志中挖出了1 000萬條人名,這么龐大的數據量是不可能進行人工校對的,只有保證抽取結果有較高的正確率的情況下,識別結果才可以被直接應用,對于學術研究或工程應用才能夠產生價值。
6 結論
本文系統地闡述了中文人名在日志中的構成形式及其特點,分析了長文本中的人名識別方法應用在搜索日志中進行中文人名識別的缺陷和不足。而后,本文提出了一種基于條件隨機場的人名識別方法,利用日志中人名的特點,進行中文人名的識別。通過對五天去重的搜狗日志進行的實驗能看出,本文方法較大地提高了日志中人名識別的效果。但是由于國內外資源的限制,現在搜索日志中沒有已標記好的權威語料可以作為訓練集,而手動制作搜索日志的標記語料,費時費力。因此,本文選定通用語料人民日報并對其進行重組作為訓練集,目的是為了半自動地構建已標記的日志語料,為搜索日志的進一步研究工作奠定基礎。本文訓練語料的規模很小,如果能夠擴大訓練語料,最終識別結果還會有很大上升的空間。我們的下一步研究工作就是半自動地制作已標記的搜索日志語料,并將本文方法進一步細化,然后將已標記的搜索日志語料作為訓練集合,深入研究并推廣,使其應用在地名、機構名、術語、縮略語等其他搜索日志未登錄詞的識別中。
[1] Downey D,Broadhead M,Etzioni O.Locating complex named entities in Web text[C]//Proceedings of the 20th international joint conference on artifical intelligence.San Francisco,CA: Morgan Kaufmann Publishers Inc.2007: 2733-2739.
[2] Shen D,Walker T,Zheng Z,et al. Personal nameclassification in Web queries[C]//Proceedings of the international conference on Web search and web datamining. New York,NY: ACM,2008: 149-158.
[3] Artiles J,Gonzalo J,Verdejo F. A testbed for people searching strategies in the www[C]//Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retriev - al. New York,NY: ACM,2005: 569-570.
[4] 張磊,王斌,靖紅芳等.中文網頁搜索日志中的特殊命名實體挖掘[J].哈爾濱工業大學學報,2011,43(5):119-122.
[5] 羅智勇,宋柔.一種基于可信度的人名識別方法[J].中文信息學報,2005,19(3): 67-72,86.
[6] 宋柔.基于語料庫和規則庫的人名識別方法[M].計算語言學研究與應用,北京:北京語言學院出版社,1993年.
[7] 鄭家恒,李鑫,譚紅葉.基于語料庫的中文姓名識別方法研究[J].中文信息學報,2000, 14(1):7-12.
[8] 時迎超,王會珍,肖桐,胡明涵. 面向人名消歧任務的人名識別系統[J]. 中文信息學報,2011,25(3): 17-22.
[9] 李波,張蕾. 基于錯誤驅動學習和知網的中文人名識別[J]. 計算機工程,2012,38(12): 179-181.
[10] 張華平,劉群.基于角色標注的中國人名自動識別研究[J].計算機學報,2004,27(1): 85-91.
[11] 毛婷婷,李麗雙. 基于混合模型的中國人名自動識別[J].中文信息學報,2007,21(2): 22-28.
[12] 李中國,劉穎.邊界模板和局部統計相結合的中國人名識別[J].中文信息學報,2006,20(5): 44-50,57.
[13] Brown P, De Souza P,Mercer R, et al. Classbased n-gram models of natural language[J]. Journal Computational Linguistics,1992,18(4): 467-479.
[14] Chen H H,Ding Y W,Tsai S C,et al. Description of the NTU system used for MET2[C]//Proceedings of the 7th Message Understanding Conference.[S. l.]: [s. n.],1998.
[15] Joachims T. Text Categorization with support vector machines: Learning with many relevant features[J]. Springer, 1998,1398(23): 137-142.
[16] Pasca M. Weakly-supervised discovery of named entities using Web search queries[C]//Proceedings of the 16th International Conference on Information and Knowledge Management. New York, NY: ACM, 2007:683-690.
[17] 黃昌寧,趙海.由字構詞——中文分詞新方法; 中文信息處理前沿進展——中國中文信息學會二十五周年學術會議論文集[C]//中國中文信息學會二十五周年學術會議,2006.
[18] 維基百科.常見姓氏列表[OL].[2012].zh.wikipedia.org/wiki/常見姓氏列表.
[19] 姚勤智.亞洲人名詞庫[OL]. [2012] http://bbs.jjol.cn/showthread.php?t=2001.
[20] 搜狐研發中心.用戶查詢日志[OL]. [2012].www.sogou.com/labs/dl/q.html.
[21] 郭家清,蔡東風等.一種基于條件隨機場的人名識別方法[J].通訊和計算機,2007,4(2)27-30.
Automatic Identification of Chinese Names in Search Logs
WANG Yue1, LV Xueqiang1, LI Zhuo1, SHU Yan2
(1. Beijing Key Laboratory of Internet Culture and Digital Dissemination Research, Beijing Information Science and Technology University,Beijing 100101,China; 2. Beijing TRS Information Technology Co., Ltd, Beijing 100101,China)
Search log name recognition has been a focus in Log Mining, which has direct impact on search engine’s retrieval efficiency and accuracy. The paper analyzes the drawbacks of name identification methods for long texts when applied to search logs, and proposes a method to identify Chinese names in search logs. The method employs the name internal word probability extracted from search query logs by the Conditional Random Fields, then estimates the credibility of person name according to the characteristics in the search log. Experimental results on Sogou query logs show that our approach reaches 81.97%accuracyand 85.81% recall on average, yielding F-measure of 83.79% .
recognition of person names; search query logs; conditional random fields; reliability

王玥(1987—),碩士,研究實習員,主要研究領域為中文信息處理、大數據處理。E?mail:butcher20@163.com呂學強(1970—),博士,教授,主要研究領域為中文信息處理、多媒體信息處理。E?mail:lxq@bistu.edu.cn李卓(1983—),博士,講師,主要研究領域為移動互聯網。E?mail:lizhuo@bistu.edu.cn
1003-0077(2015)03-0162-07
2013-04-08 定稿日期: 2013-07-18
國家自然科學基金(61171159、61271304 );北京市教委科技發展計劃重點項目暨北京市自然科學基金B類重點項目(KZ201311232037);北京信息科技大學網絡文化與數字傳播北京市重點實驗室開放課題(ICDD201203 )
TP391
A
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
