面向在線顧客點評的屬性依賴情感知識學習
2015-04-21 08:43:46徐學可譚松波程學旗吳瓊
中文信息學報 2015年3期
徐學可,譚松波,劉 悅,程學旗,吳瓊
(1. 中國科學院計算技術研究所,網絡數據科學與技術重點實驗室,北京 100190;2. 中國科學院大學,北京 100190)
?
面向在線顧客點評的屬性依賴情感知識學習
徐學可1,2,譚松波1,劉 悅1,程學旗1,吳瓊1
(1. 中國科學院計算技術研究所,網絡數據科學與技術重點實驗室,北京 100190;2. 中國科學院大學,北京 100190)
該文研究屬性依賴情感知識學習。首先提出了一個新穎的話題模型,屬性觀點聯合模型(Joint Aspect/Opinion model, JAO),來同時抽取評論實體屬性及屬性相關觀點詞信息。在此基礎上,對于各個屬性,構造屬性依賴的詞關系圖,并在該圖上應用馬爾科夫隨機行走過程來計算觀點詞到少量褒、貶種子詞的游走時間(Hitting Time),進而估計這些詞的屬性依賴的情感極性分值。在餐館點評數據上的實驗表明所提出的方法能有效抽取屬性相關觀點詞,同時有效估計其屬性依賴的情感極性分值。
顧客點評;屬性觀點聯合模型;游走時間;屬性依賴情感知識
引言
隨著Web 2.0的迅猛發展,越來越多的顧客通過Amazon、京東等在線電子商務平臺對各種產品或服務發表個人觀點。這些在線顧客點評中蘊含著巨大的商業價值。同時由于其爆炸式的增長,我們迫切需要情感分析工具,來自動高效地抽取、分析及歸納其中的情感信息[1-11]。通常而言,顧客總是針對評論實體的特定屬性(aspect)(如餐館的環境、服務等)發表觀點;另一方面,不同的用戶往往關注不同的屬性。因此面向點評的情感分析應該細化到屬性層次。在屬性層次情感分析應用中,高質量的情感知識資源起著基礎性作用[12]。然而由于顧客情感表達往往具有屬性依賴性[12-13],通用情感知識往往并不適合,屬性依賴(aspect-dependent)的情感知識有助于屬性層次情感分析應用,具體而言: 針對特定屬性,顧客通常使用專門的觀點詞來傳達情感。例如,人們使用“舒適”、“浪漫”來形容餐館的環境,使用“友好”、“熱情”來描繪餐館服務。相對于通用觀點詞,這些專屬的觀點詞可以幫助人們從評論文本中抽取屬性相關的更有意義的情感信息[13]。
觀點詞的褒貶情感極性往往是屬性依賴的。同個觀點詞在描繪不同屬性時,往往傳達不同的情感極性。例如,在酒店評論中,人們喜歡房間“大”,卻厭惡噪音“大”。此外,很多觀點詞僅僅對特定屬性有情感極性,如“private”一般來講是中性的,但對于餐館的環境來說,卻是褒義的。識別屬性依賴的情感極性有助于屬性層次情感分類任務[12]。
因此,本文研究屬性依賴情感知識學習,也就是說,我們從給定領域的顧客點評(如餐館點評)中抽取顧客經常點評的重要實體屬性;對各個屬性,抽取屬性相關的觀點詞,同時估計其屬性依賴的情感極性分值。針對這一任務,本文提出了一個兩階段方法。在第一個階段,我們對LDA(Latent Dirichlet Allocation)[14]模型進行擴展,提出了一個新穎的話題模型,屬性觀點聯合模型(Joint Aspect/Opinion model, JAO),來同時抽取實體屬性及屬性相關觀點詞信息。相對于現有模型[13],JAO不需要任何領域知識或者人工標注數據,具有更好的領域適應性。在第一階段基礎上,對于各個屬性,我們構造屬性專屬(aspect-specific)的詞關系圖,在該圖上,應用馬爾科夫隨機行走過程來計算觀點詞到褒、貶種子詞的游走時間(Hitting Time)[15],進而估計觀點詞的屬性依賴情感極性分值。相對于現有方法,我們方法僅僅需要淺層次的詞共現信息,不需要深層自然語言處理[12]或者人工提供的信息[16],因而具有更高的語言獨立性和領域適應性。
1 相關工作
1.1 屬性抽取
部分工作抽取點評中的評價對象作為屬性。抽取方法主要包括NLP[9,17]、Data Mining[17]、基于模板的方法[6]、基于規則的方法[18]等。
近年來,統計話題模型如PLSA(Probabilistic Latent Semantic Analysis)[19]、LDA[14]及其變種在屬性抽取中得到廣泛應用。在這些工作中,屬性視為隱含話題,表示為詞空間上的概率分布。這樣所抽取的每個屬性具有完備一致的語義表示。 Titov 等人[20]提出多粒度的話題模型(MG-LDA),利用句子滑動窗口層次的詞共現信息,從產品點評中抽取局部話題(local topics)以對應實體的不同屬性。Ling等人[21]用少量的關鍵詞來預定義屬性,分別利用Dirichlet 先驗或正則約束來引導屬性的抽取,使得抽取的屬性與預定義屬性對齊。不同于這些模型,我們提出的JAO模型不僅抽取屬性,同時能抽取屬性相關觀點詞。
1.2 屬性情感知識學習
Brody 等人[16]提出了一個兩階段方法來學習屬性情感知識。首先,采用Local LDA模型抽取屬性。然后抽取修飾屬性相關名稱的形容詞作為觀點詞,利用情感極性圖的標簽擴散方法學習這些觀點詞的屬性依賴情感極性分值。不同于他們的方法,我們在第一階段同時抽取屬性及屬性相關觀點詞。MaxEnt-LDA模型[13]是第一個同時抽取屬性及屬性相關觀點詞的一體化模型。該模型整合了一個使用標注數據學習的最大熵分類器來區分觀點詞跟客觀詞,但并沒有進一步考慮觀點詞的情感極性。Lu等人[12]提出了基于優化學習框架的屬性依賴情感極性學習方法。其優化目標函數中整合了多種關于情感極性的約束知識。但該方法依賴通常難以獲得的情感等級評分等人工給定信息。此外該方法中屬性是預先定義的,并且表示為人工指定的少量關鍵詞。所有這些限制了該方法在不同領域的應用。
1.3 其他相關工作
還有不少工作雖然不是直接針對屬性情感知識學習,但也與本文工作相關。Hassan等人[22]考慮利用隨機行走計算不考慮任何屬性的通用情感極性。由于許多觀點詞的褒貶情感極性依屬性不同而變化,該方法不可能準確反映這些觀點詞的情感極性。此外,該方法利用WordNet這個英語本體知識庫來構造詞關系圖,這限制了該方法在其他語言上的應用。Lin等人[23]提出了JST模型,針對不同情感(褒或貶)抽取相應情感傾向的話題。Jo等人[24]提出ASUM模型,來對JST進行了改進,使得抽取的話題對應于實體的屬性。類似JST,ASUM沒有顯式地學習屬性相關的情感知識,而是針對不同情感(褒或貶),抽取帶相應情感傾向的屬性,所抽取的情感傾向的屬性沒有顯式地區分觀點與客觀信息,而是二者高度混雜。
2 屬性觀點聯合模型
2.1 模型描繪
傳統LDA模型主要利用文檔層次的詞共現信息來抽取全局性的隱含話題。由于一篇評論文檔往往涉及到實體的多個屬性,所抽取話題往往不能對應于屬性[20]。由于一個短句往往只涉及一個屬性[25]。因此為了讓抽取的話題對應于屬性,我們可以利用短句層次的詞共現信息。然而,直接在短句集合上進行挖掘,往往受到短句數據稀疏性影響。為此,我們引入虛擬文檔(Virtual Document),每個虛擬文檔對應一個詞,我們將出現該詞的所有短句連接構造相應的虛擬文檔。我們的模型應用到虛擬文檔集上而不是短句集或點評文檔集上。這樣,我們就可以充分利用短句層次詞共現信息,同時克服短句的數據稀疏性問題,來更好地抽取屬性。除了抽取屬性信息,我們的模型進一步整合觀點詞典知識來顯式地區分觀點詞與客觀詞, 進而抽取屬性相關觀點詞。
給定特定領域顧客點評集,其中點評中每個短句視為一個詞序列,我們可以構造D個虛擬文檔,每個虛擬文檔視為相應短句的詞序列連接構成的一個大詞序列,而每個詞是一個詞典中的一個項目,這里詞典中包含V個詞,分別記為w=1,...,V。虛擬文檔vd中的第n個詞wvd,n與兩個變量關聯: zvd,n和ζd,s,n。其中,zvd,n表示屬性;ζd,s,n為主客觀標簽(subjectivitylabel),表示該詞是傳達情感(褒或貶)的觀點詞(ζd,s,n=opn)還是不傳達情感的客觀詞(ζd,s,n=fact)。根據JAO模型,虛擬文檔集的產生過程如下。

1.對于每個屬性z:(a)對主客觀標簽opn跟fact,分別從參數為β的Dirichlet分布中選擇一個詞分布:Φz,fact~Dir(β);Φz,opn~Dir(β).2.對每個虛擬文檔vd(a)從參數為α的Dirichlet分布選擇一個屬性分布:θvd~Dir(α)(b)對vd中的每個詞wvd,n:(i)按屬性分布θvd采樣一個屬性:zvd,n~θvd(ii)按主客觀標簽分布vvd,n選擇一個主客觀標簽:ζvd,n~vvd,n(1)如果ζd,s,n=opn,按詞分布Φzvd,n,opn產生wvd,n:wvd,n~Φzvd,n,opn(2)否則,按詞分布Φzvd,n,fact產生wvd,n:wvd,n~Φzvd,n,fact
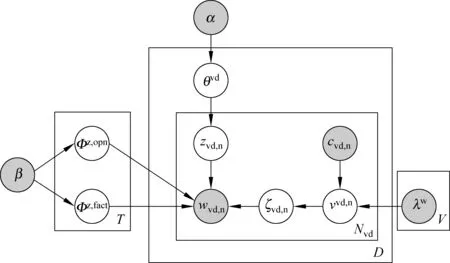
圖1 虛擬文檔集產生過程的圖形表示
2.2 如何區分觀點詞跟客觀詞

(1)

這樣,主客觀標簽ζvd,n的賦值很大程度上由wvd,n是否出現在觀點詞典中決定。我們的方法雖然簡單,但效果很好,實驗表明優于需要標注數據的MaxEnt-LDA模型[13]。
值得注意的是,我們的模型可以通過將不同來源的知識(如觀點詞典、觀點表達語法模式)應用到詞wvd,n的上下文特征cvd,n來設置νvd,n,來更好識別觀點詞。這是我們將來工作的重點。
2.3 模型參數估計
我們采用collapsedGibbssampling[26]方法來對所有zvd,n及ζvd,n變量的賦值進行后驗估計。根據collapsedGibbssampling,變量賦值按一個給定所有其他變量賦值及觀察數據下的條件概率分布依序選擇產生。這里,zvd,n和ζvd,n的賦值根據公式(2)的條件概率分布聯合選擇產生:
(2)
其中w是虛擬文檔集的總詞序列;T是事先指定的屬性個數;z及ζ分別是這個詞序列(除了vd中第n個詞外)上詞的屬性及主客觀標簽賦值序列;是vd中詞的個數。是vd中詞被賦值為屬性t的次數。)w上任何詞(或者詞w)賦值為屬性t及主客觀標簽l的次數。以上所有次數統計都排除vd的第n個詞。
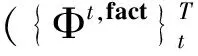
(3)
其中Φt,fact體現了屬性t的客觀語義,而Φt,opn中的高概率詞是屬性t相關觀點詞。
3 情感極性分值學習
給定一個屬性,我們首先構造屬性專屬的詞關系圖;然后計算觀點詞到少量褒、貶種子詞的游走時間來估計這些詞的屬性依賴情感極性分值。
3.1 詞關系圖構造
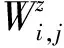
(4)
這里|S|為語料中子句的總數;cz(wi)出現詞i的所有短句的帶權個數和;cz(wi,wj)為同時出現詞i及j的所有短句的帶權個數和。 每個“個數”的權重為相應短句的屬性相關度。 短句s的屬性相關度按公式(5)計算。
(5)
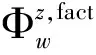
3.2 游走時間計算
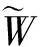
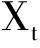
(6)

(7)
對于上式的第一項:
(8)
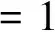
(9)
顯然對于i∈S有hz(i|S)=0。最終我們得到計算游走時間的如下線性系統:
(10)
為了計算情感極性,我們分別有褒、貶種子觀點詞集:S+及S-。這里S+及S-來源于文獻[24]。相應的,給定圖中的一個詞i,我們可以分別有如下游走時間:hz(i|S+)及hz(i|S-)。這里hz(i|S+)值越低,表明詞i跟褒義種子觀點詞語義距離越小,因而也傾向于褒義。對于hz(i|S-)也同理。
最終我們計算屬性依賴情感極性分值如下:
(11)
該值靠近0是表明詞i相對屬性z傳達貶義極性,靠近1表明褒義。總的情感極性計算流程如下:

1 對每個詞,初始化hz0(i|S+)=0,hz0(i|S-)=02 迭代執行以下步驟,直到收斂2.1 對于每個圖中的詞(非褒義種子詞)i,i?S+,計算:hzt+1(i|S+)=∑j?S+Wzi,j×hzt(j|S+)+13 迭代執行以下步驟,直到收斂3.1 對于每個圖中的詞(非貶義種子詞)i,i?S-,計算:hzt+1(i|S-)=∑j?S-Wzi,j×hzt(j|S-)+14 令hz(i|S+)及hz(i|S-)為最終收斂游走時間值,則每個詞的情感極性分值計算如下polarity(z,i)=hz(i|S-)hz(i|S+)+hz(i|S-)
4 實驗結果及分析
我們使用一個公開的餐館點評集[27]。該數據集包含從CitySearch網站采集的52 264篇顧客點評。該數據集已經做了包括句子分割、詞性標注等預處理。對每個句子我們根據冒號和逗號進一步分割,得到短句,然后進一步去除停用詞。最終每個短句都轉化為帶詞性標注的詞序列。如 "the quality is good" 變換為 "quality_noun good_adj"
4.1 JAO評估
為了進行JAO的學習,我們需要構造虛擬文檔。我們僅僅選擇點評集中出現次數不少于20次的形容詞、名詞、動詞及副詞來構造虛擬文檔。出現次數過少的詞對應的虛擬文檔往往沒有充分的共現信息;而其他詞性的詞往往是一些不具備實義的沒有屬性區分能力的功能詞。對于每個選擇的詞,我們把出現該詞的所有短句的詞序列連接,構成相應虛擬文檔的詞序列。我們執行100輪Gibbs sampling迭代。JAO的參數設置如下: 根據文獻[16],屬性個數T設置為14;對于超參數,按照現有研究的慣例[26]設置α=50/T及β=0.1,沒有針對我們的數據進行專門調式。實驗中采用的觀點詞典(見2.2節)來源于兩個公開的知識庫:MPQASubjectivityLexicon*http://www.cs.pitt.edu/mpqa/與SentiWordNet*http://sentiwordnet.isti.cnr.it/
4.1.1JAO結果實例
表1給出了JAO在餐館點評集上的結果實例。對于每個屬性,我們按照Φt,fact及Φt,opn(見式(3))分別列出了排序靠前的客觀詞及觀點詞。這里我們僅僅列出了主要屬性的結果,忽略一些類似的或者比較瑣碎的屬性。從表中我們可以發現我們的模型能有效挖掘顧客經常評論的主要餐館屬性信息,如服務, 環境等。對于各個屬性,所抽取的客觀詞能很好的描繪該屬性的語義。更重要的是,大體上, 所抽取的屬性相關觀點詞與相應屬性緊密相聯,具有很好的屬性區分能力,同時能對該屬性提供非常有意義的情感信息。
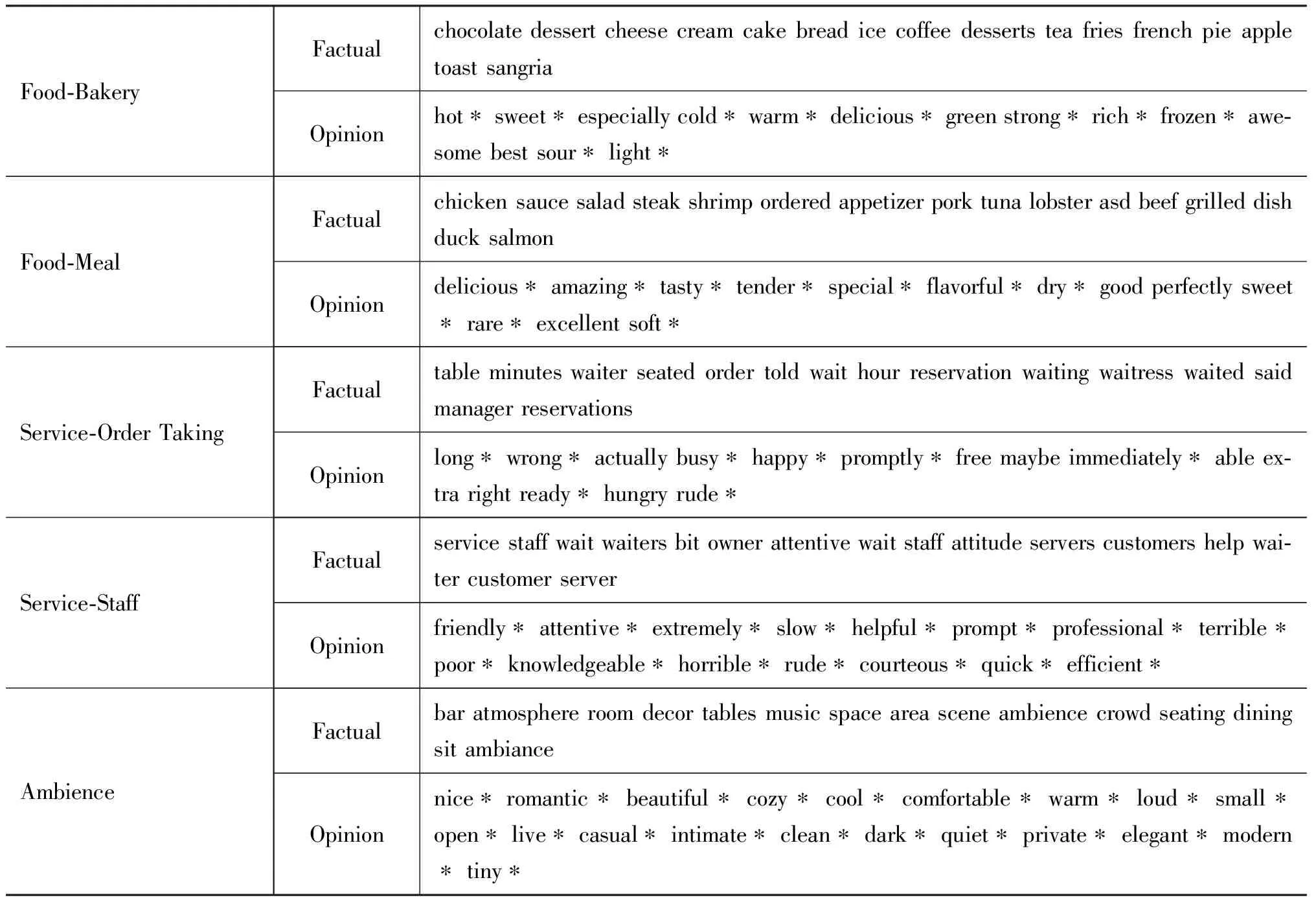
表1 JAO運行實例(為了增加可讀性我們去除了詞性標注,屬性相關觀點詞加標記*)
4.1.2 與MaxEnt-LDA比較
MaxEnt-LDA模型[13]是第一個抽取屬性及屬性相關觀點詞的一體化模型。該模型與JAO模型完成同樣地任務。 原文給出了MaxEnt-LDA在相同的餐館點評集上的運行實例,總共給出了四個屬性(“Food”, “Staff”, “Order Taking” 及“Ambience”) 上的結果。 我們請兩個標注人員來人工判別觀點詞是否跟相應屬性緊密相聯。表1給出了其中一人的評估結果(以* 標記屬性相關觀點詞)。平均二者結果,MaxEnt-LDA所挖掘觀點詞僅僅52.5%確實是屬性相關觀點詞,而JAO在對應的4個屬性上的結果是約80%。這表明JAO能更有效的抽取屬性相關觀點詞。此外MaxEnt-LDA整合了一個預先使用標注數據學習的最大熵分類器來區分觀點詞跟客觀詞,我們的模型并不需要標注數據,因而具有更好的領域適應性。
4.1.3 自動定量評估
直覺上,一個觀點詞跟某個屬性的關聯程度可以由多大程度上僅僅根據該觀點詞就能推斷出相應的屬性來度量。因此,我們可以通過利用屬性相關觀點詞進行屬性識別,來更加客觀準確評估JAO的屬性相關觀點詞抽取性能。餐館評論數據包含了大概3 400個帶屬性信息的人工標注句子。這里候選屬性集包括8個人工定義屬性{"Staff", "Food", "Ambience", "Price", "Anecdote", "Misc"}。參考文獻[13]的做法,我們從中選擇顧客經常評論的3個重要屬性: "Staff", "Food", "Ambience";忽略其他語義信息不明確的屬性如"Misc"。
具體而言,對于一個人工定義屬性a,我們根據自動學習的屬性觀點模型與句子語言模型的負KL距離來對所有標注句子進行排序。我們利用排序位置N上的準確率作為性能度量指標。我們這里句子語言模型由基于Dirichlet的極大似然估計方法學習。而對于a,相應的屬性觀點模型如下
(12)
這里Ta為JAO自動學習到的對應到a的屬性集*可能有多個JAO自動挖掘的屬性對應到一個人工屬性,如“Food-Meal”,“Food- Bakery”等對應到人工定義屬性“Food”。這是由于JAO能有效抽取細粒度的屬性。;VO為觀點詞典。對非觀點詞,我們將概率值設為0。這樣我們就可以只利用觀點詞來進行屬性識別。
作為比較,我們考慮以下方法估計屬性觀點模型:
Gen. 我們用通用觀點模型作為屬性觀點模型。每個觀點詞的概率值均等,不區分是否屬相相關。
Bol. 我們首先選取標注為相應屬性的句子,然后利用Bol詞權重計算模型,來計算每個觀點詞的在這些句子中的權重,反映該詞的屬性區分能力,進而推斷該詞在屬性觀點模型中的概率值。值得注意的是Bol直接利用了標注數據及一個高效的權重計算模型Bol[28]來進行訓練,而所用標注數據同時用來測試。因而Bol是個非常強的方法。可以作為無監督方法(比如我們方法)的所能達到的性能的上界。
此外,由于MaxEnt-LDA學習所需的標注數據不公開,我們沒辦法利用MaxEnt-LDA學習屬性觀點模型來進行比較。
圖2給出了,在三個屬性上,不同方法的準確率(Precision)隨排序位置N的變化曲線。我們看到,我們的方法遠遠優于Gen,同時非常接近Bol, 甚至
圖2 準確率(Precision)隨排序位置N的變化曲線
在staff屬性上超過Bol;同時當N較小時,準確率非常高。從中驗證了我們的方法所抽取觀點詞跟相應屬性緊密聯系。
4.2 情感極性分值評估
4.2.1 結果實例
表2給出了屬性依賴情感極性學習的實例,從中我們可以看出我們的基于游走時間的方法可以有效學習屬性相關觀點詞依賴于特定屬性的情感極性。例如,“heavy”對于MainDishes來說口味過重,是貶義詞;“private”一般來講是中性的,但對于餐館的氣氛屬性來說,卻是褒義的。
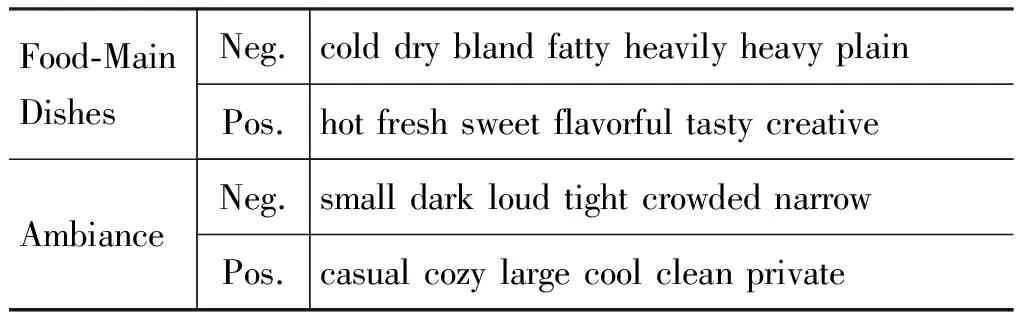
表2 屬性依賴情感極性學習的實例
4.2.2 自動定量評估
Brody等人[16]針對餐館點評數據集構造了屬性依賴情感極性分值的答案數據,該數據涉及8個標注屬性(見表3),對于每個屬性,有一系列屬性相關的形容詞,每個形容詞都由人工標注了專屬的情感極性分值,范圍為從-2到2。為了利用該數據對屬性依賴的情感極性分值學習進行定量評估,我們人工地將每個標注屬性對應到一個JAO自動學習的屬性,利用該自動屬性信息,構造詞關系圖,進而學習情感極性分值。
作為基準(baseline),我們采用不考慮屬性的游走時間方法,也就是在構造詞關系圖時,利用經典的逐點互信息方法來計算詞之間的關系權重。
屬性依賴情感極性學習的相關工作包括: Brody等人[16]利用基于情感極性圖的標簽擴散方法,判別屬性依賴的情感極性。 Lu等人[12]提出了優化學習的屬性依賴情感極性學習框架。但該方法依賴人工標注信息,如情感等級信息。而我們的數據中并沒有此類信息,不能采用該方法做比較。因此我們這里只采用Brody的方法作為基準(記做Brody)。
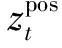

在表3中,Kendall’s tau 指標來度量根據不同自動方法產生的情感極性分值排序與跟人工分值給出的排序的吻合程度。表中Brody+是在Brody基礎上引入人工標注信息的變種[16],因而性能更好。Brody跟Brody+的結果直接來源于原文[16]。
1) 我們的方法在幾乎在所有屬性上顯著優于ASUM, 這是由于ASUM本身不是直接針對情感知識學習,因而并不能很好學習觀點詞的情感極性。
2) 平均來看,我們的方法顯著優于Brody跟Brody+。此外,我們的方法僅僅需要淺層的共現信息,不像Brody和Brody+需要進行深層自然語言處理,因而具有更高的效率和語言獨立性。
3) 我們方法相對于Brody及Brody+在不同屬性上性能非常穩定。這是由于我們的方法充分利用全局性詞關系信息,克服數據稀疏性問題,從而獲得更可靠情感極性分值。
4) 我們的方法在不同屬性上幾乎一致優于不考慮屬性的游走時間方法(除了屬性Drinks*這是由于“Drinks”屬性的評論經常與其他屬性的混雜,因而不能有效地從語料中挖掘。我們僅僅從自動挖掘的屬性中選擇盡可能相關的對應到“Drinks”),這表明考慮在構造詞關系圖時利用屬性偏移的逐點互信息方法來計算詞之間的關系權重能獲得更加準確的屬性依賴的情感極性分值。

表3 不同方法在Kendall’s tau 指標上的比較
5 小結與展望
本文研究屬性依賴情感知識學習,提出了屬性觀點聯合模型及基于游走時間的情感極性計算方法。相比現有方法,我們的方法不依賴領域知識、人工標注及深層次的自然語言處理,因而具有更好的效率和領域適應性。在將來,對于JAO,我們計劃整合更多來源的各種知識來更好識別觀點詞。目前對于情感極性學習中的詞關系圖構造,我們目前主要利用共現信息來度量詞之間的關系。將來計劃引入更多的知識, 來更好地度量詞關系。
[1] 黃萱菁, 張奇,吳苑斌. 文本情感傾向分析[J]. 中文信息學報,2011, 25(6):118-126.
[2] 姚天昉, 程希文, 徐飛玉, 等. 文本意見挖掘綜述[J]. 中文信息學報, 2008, 22(5):71-80.
[3] 趙妍妍, 秦兵, 劉 挺. 文本情感分析[J]. 軟件學報, 2010, 21(8):1834-1848.
[4] 周立柱,賀宇凱,王建勇.情感分析研究綜述[J].計算機應用,2008,28(11):2725-2728.
[5] 吳瓊, 譚松波, 程學旗.中文情感傾向性分析的相關研究進展[J]. 信息技術快報, 2010,8(4):16-38.
[6] 宋曉雷, 王素格, 李紅霞.面向特定領域的產品評價對象自動識別研究[J]. 中文信息學報, 2010, 24(1): 89-93.
[7] 楊源, 馬云龍, 林鴻飛. 評論挖掘中產品屬性歸類問題研究[J]. 中文信息學報,2012, 26(3):104-108.
[8] 徐琳宏, 林鴻飛, 趙晶. 情感語料庫的構建和分[J]. 中文信息學報,2008, 22(1):116-122.
[9] 劉鴻宇, 趙妍妍, 秦兵, 等. 評價對象抽取及其傾向性分析[J]. 中文信息學報,2010, 24(1):84-88.
[10] 李壽山, 黃居仁. 基于Stacking組合分類方法的中文情感分類研究[J]. 中文信息學報,2010, 24(5):56-61.
[11] 謝麗星, 周明, 孫茂松. 基于層次結構的多策略中文微博情感分析和特征抽取[J]. 中文信息學報,2012, 26(1):73-83.
[12] Yue Lu, Malu Castellanos, Umeshwar Dayal, et al. Automatic Construction of a Context-Aware Sentiment Lexicon: An Optimization Approach[C]//Proceedings of WWW’11, 2011.
[13] Wayne Xin Zhao, Jing Jiang, Hongfei Yan, et al. Jointly modeling aspects and opinions with a MaxEnt-LDA hybrid[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, 2010: 56-65.
[14] David M Blei, Andrew Y Ng, Michael I. Jordan. Latent Dirichlet allocation [J]. Journal of Machine Learning Research, 2003,3(3): 993-1022.
[15] Qiaozhu Mei, Dengyong Zhou, Kenneth Church. Query suggestion using hitting time[C]//Proceedings of the 17th ACM conference on Information and knowledge management (CIKM ’08), 2008.
[16] Samuel Brody, Noemie Elhadad. An unsupervised aspect-sentiment model for online reviews[C]//Proceedings of Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics (HLT ’10), 2010.
[17] Minqing Hu, Bing Liu. Mining and summarizing customer reviews[C]//Proceedings of SIGKDD,2004: 168-177.
[18] L Zhuang, F Jing, X Zhu. Movie review mining and summarization[C]//Proceedings of CIKM ’06, 2006: 43-50.
[19] Thomas Hofmann. Probabilistic latent semantic indexing[C]//Proceedings of SIGIR ’99, 1999: 50-57.
[20] I Titov, R McDonald. Modeling online reviews with multi-grain topic models[C]//Proceeding WWW ’08,2008: 111-120.
[21] X Ling, Q Mei, C Zhai, et al. Mining multi-faceted overviews of arbitrary topics in a text collection[C]//Proceeding of the 14th ACM SIGKDD, 2008:497-505.
[22] A Hassan, D Radev. Identifying text polarity using random walks[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics (ACL ’10), 2010:395-403.
[23] C Lin, Y He. Joint sentiment/topic model for sentiment analysis[C]//Proceedings of the 18th ACM conference on Information and knowledge management (CIKM ’09), 2009: 375-384.
[24] Yohan Jo, Alice H. Oh. Aspect and sentiment unification model for online review analysis[C]//Proceedings of the fourth ACM international conference on Web search and data mining (WSDM ’11).2011: 815-824.
[25] J Zhu, H Wang, B. K. Tsou, et al. Multi-aspect opinion polling from textual reviews[C]//Proceeding of CIKM ’09, 2009: 1799-1802.
[26] Thomas L Griffiths, Mark Steyvers. Finding scientific topics [J]. Proceedings of the National Academy of Sciences,2004, 101(Suppl 1): 5228-5535.
[27] Gayatree Ganu, Noémie Elhadad, Amélie Marian. Beyond the stars: Improving rating predictions using review text content[C]//Proceedings of International Workshop on the Web and Databases, 2009.
[28] Ben He, Craig Macdonald, Jiyin He, et al. An effective statistical approach to blog post opinion retrieval[C]//Proceeding of CIKM 2008, 2008: 1063-1072.
Learning Aspect-Dependent Sentiment Knowledge for Online Customer Reviews
XU Xueke1,2,TAN Songbo1,LIU Yue1,CHENG Xueqi1,WU Qiong1
(1. Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China; 2. University of Chinese Academic of Sciences, Beijing 100190, China)
This paper addresses the problem of learning aspect-dependent sentiment knowledge. Specifically, a novel topic model, called Joint Aspect/Opinion Model (JAO), is proposed to detect aspects and aspect-specific opinion words simultaneoasly in an unsupervised manner. Then, we propose to infer aspect-dependent sentiment polarity scores for these opinion words based on the hitting times from the words to a handful of positive/negative seed words, by applying Markov random walks over an aspect-specific word relation graph. Experimental results on restaurant review data show the effectiveness of the proposed approaches.
online customer review; joint aspect/opinion model; hitting time; aspect-dependent sentiment knowledge

徐學可(1983—),博士,助理研究員,主要研究領域為Web觀點檢索與挖掘、文本分類及自然語言處理。E?mail:xuxueke@software.ict.ac.cn譚松波(1978—),博士,副研究員,主要研究領域為情感分析,文本分類,機器學習等。E?mail:tansongbo@software.ict.ac.cn劉悅(1971—),博士,副研究員,主要研究領域為信息檢索,社區挖掘與分析,分布式計算等。E?mail:liuyue@ict.ac.cn
1003-0077(2015)03-0121-09
2012-05-07 定稿日期: 2012-07-09
國家高技術研究發展計劃(863計劃)項目(2010AA012502、2010AA012503);國家自然科學基金資助項目(60933005、60903139、61100083)
TP391
A
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國生殖健康(2020年5期)2021-01-18 02:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中國生殖健康(2018年5期)2018-11-06 07:15:40
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
