一種融合聚類和時間信息的微博排序新方法
2015-04-21 08:33:46衛冰潔
中文信息學報 2015年3期
衛冰潔,史 亮,王 斌
(1. 中國科學院 計算技術研究所,北京 100190;2. 中國科學院 信息工程研究所,北京 100093;3. 國家計算機網絡應急技術處理協調中心,北京 100029)
?
一種融合聚類和時間信息的微博排序新方法
衛冰潔1,3,史 亮3,王 斌2
(1. 中國科學院 計算技術研究所,北京 100190;2. 中國科學院 信息工程研究所,北京 100093;3. 國家計算機網絡應急技術處理協調中心,北京 100029)
隨著微博的快速發展,微博檢索已經成為近年來研究領域的熱點之一。微博檢索與傳統文本檢索在兩個方面明顯不同: 一是微博具有自己的特點,表現在文本短和內容中具有主題概括詞(稱為Hashtag);二是微博排序中除了考慮文本和語義相似度,還需考慮時間信息。根據這兩點區別,該文在統計語言模型的基礎上,使用聚類進行文本擴展,并將Hashtag信息運用到聚類過程中。同時,因為微博數據集中具有Hashtag的微博個數不超過13%,針對這一現象,該文還提出了一種擴展微博Hashtag的方法,最終提出了基于聚類的三個模型。然后通過定義文檔先驗將時間信息加入到提出的三個檢索模型中,得到融入聚類和時間信息的三個模型。最后基于TREC Microblog數據的實驗結果證明,融合聚類信息和時間信息的模型在MAP和P@30上有明顯提高,分別提高7.1%和11.6%。
微博檢索;Hashtag;聚類;時間;語言模型
1 引言
微博,即微型博客(Microblog),是區別于傳統博客的一種互聯網產品。用戶通過網絡、客戶端等即時發布信息,通常要求文本字數不超過140個字,用戶也可以獲取他人發布的信息,實現信息的共享。目前全世界已有多個成熟的微博平臺,例如,Twitter、新浪微博、騰訊微博等。由于其所具有的便捷性、實時性,微博已經成為了近年來最熱門的互聯網應用之一。
隨著微博的廣泛流行,微博的用戶量和數據量均呈現爆發式的增長。據CNNIC發布的第29次中國互聯網絡發展狀況統計報告得知,目前國內有近半數的網民在使用微博,約2.5億人。同時,Twitter、新浪微博、騰訊微博的注冊用戶總數也已超過3億。在如此巨大的用戶量的背景下,微博數據量也呈現指數級增長。據報道指出,微博網站每日微博數量已經達到億級別。在海量微博數據的背景下,用戶獲得所需信息的困難度日益增大,微博搜索的重要性不言而喻,是近年來研究領域的熱點之一。
微博搜索雖然屬于文本搜索的范疇,但是卻不同于傳統的文本搜索,它具有自己的特點,表現在兩個方面,第一個是搜索數據不同,第二個是排序原則不同。本文基于這兩方面區別深入對微博搜索進行研究。
微博搜索面向的數據是微博。相較于傳統文本,微博具有文本短、含有主題詞(即Hashtag)等特點。聚類是解決文本短、信息量不足的傳統方法之一[1]。 在統計語言檢索模型的基礎上,將聚類結果以平滑方式加入到文檔概率計算公式中,修訂了文檔原有詞概率,擴展了文檔未有詞概率,通過在TREC多個數據集上進行實驗,證明了加入聚類信息對檢索效果有提高。與此同時,Hashtag是用戶為了表明該微博的主題而用兩個“#”號括起來的詞匯,統稱為Hashtag,是微博的特征之一(圖1)。文獻[2-5]均表明Hashtag是微博檢索中有效的特征之一,加入Hashtag信息的檢索模型效果普遍優于沒有加入Hashtag信息的檢索模型。
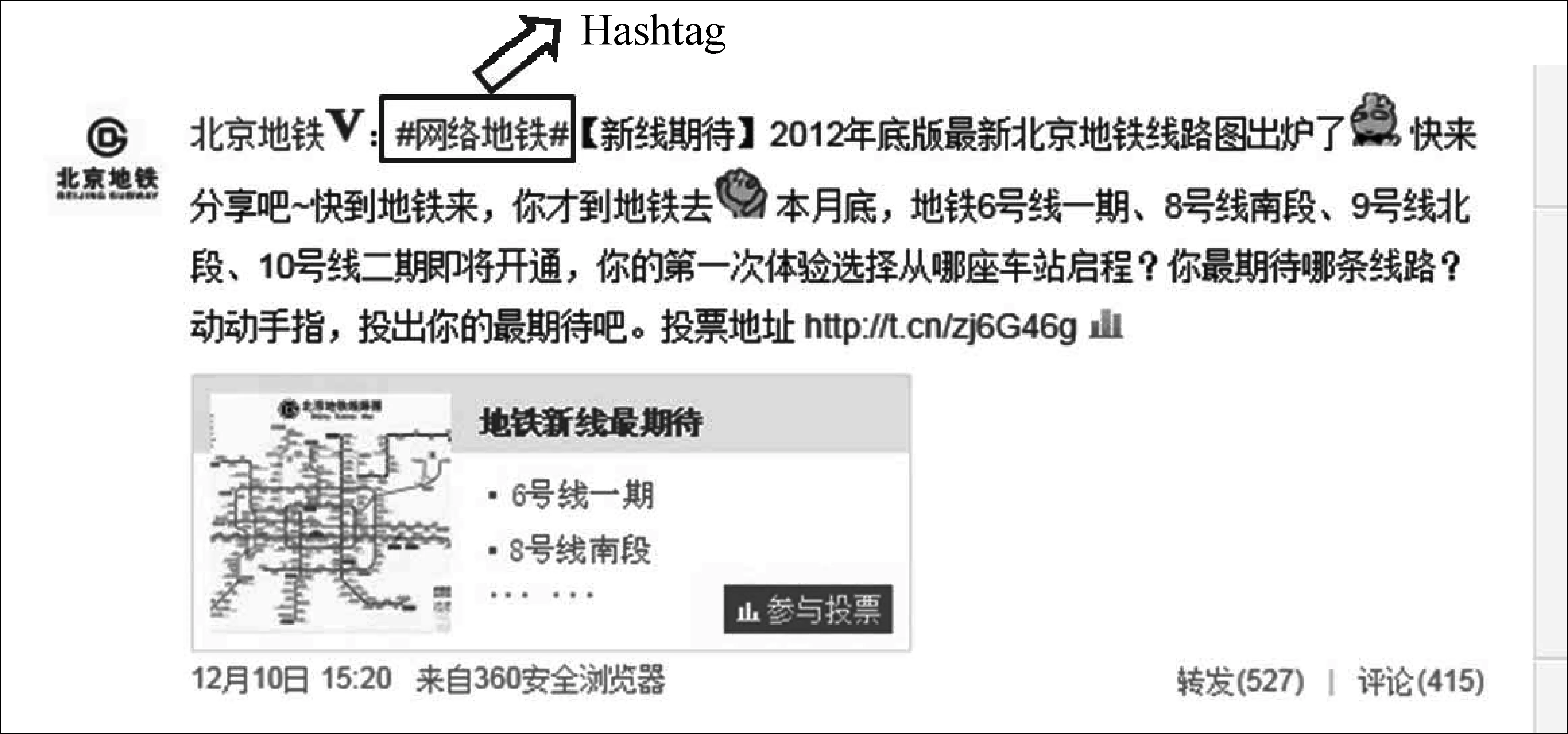
圖1 以“網絡地鐵”為Hashtag的微博
微博排序相對于傳統搜索排序,除了要考慮查詢和文本的語義相似度之外,還需要關注另一個因素即時間。Teevan, Ramage[6]對微博查詢和傳統查詢進行了多維度的統計對比,他指出用戶進行微博檢索時的搜索意圖均是跟時間有關的,也就是說微博查詢大多屬于時間敏感查詢。而傳統搜索排序無法很好地解決這類查詢的搜索需求,因此在針對微博搜索制定策略時,時間是不可忽略的因素。Li 和Croft[7]以及Efron 和Golovchinsky[8]等通過實驗證明,加入時間因素可以提高微博檢索的效果。
總結前人的工作,聚類是應對微博文本短的一個有效辦法,Hashtag是微博的顯著特征,時間是微博排序算法中應當考慮的因素,這三者對于微博搜索都非常重要。但是目前尚未有相關工作,在微博排序中同時考慮這三方面因素,因此本文以統計語言檢索模型為基礎,研究如何融合Hashtag、聚類、時間三因素于排序算法中,最終提出了一個融合聚類和時間信息的排序方法,并在TREC Microblog 數據集上進行實驗驗證,結果表明融合多因素對微博搜索效果有明顯的提高作用。本文的貢獻列舉如下: 1)針對微博數據集中Hashtag存在率低的情況,本文提出了一種將微博文本作為“偽查詢”,利用其搜索結果進行Hashtag補充和擴展的方法;2)本文證明了Hashtag和時間這兩個因素對于微博檢索的重要性,有利于提高檢索的性能。
文章內容組織如下: 第2節介紹相關工作;第3節介紹基于時間和聚類的語言檢索模型;實驗和結果分析將在第4節給出;第5節是對本文工作的總結和展望。
2 相關工作
統計語言檢索模型是利用了統計學和概率論理論的檢索模型,是三大信息檢索模型的一種,也是本文的研究基礎[9-11]。基于多項式分布的查詢似然模型(Query Likelihood Model)是語言檢索模型的熱門模型之一[11]。設q表示查詢,d表示文檔,w表示詞, Md表示根據d構建的語言模型[9],QL模型的排序函數如式(1)所示。
(1)
其中,p(d)是指文檔的先驗概率,tf(w,q)是指詞w在查詢q中的出現次數,稱為詞頻,p(w|Md)是指詞w在文檔d所代表語言中的分布概率,在一元語言模型的假設和采用極大似然估計方法下,得到的計算公式如式(2)所示。
(2)
同時為了避免零概率事件,Zhai 和Lafferty[10]提出了多種平滑方法,本文將采用Jelinek-Mercer(簡稱JM)平滑,加入平滑后的概率計算公式為:
(3)
其中λ是平滑參數,Pml(w|Mcollection) 是整個數據集的語言模型概率。
Liu和Croft[1]提出了一個基于聚類的統計語言檢索模型(CBLM,Cluster-BasedLanguageModel)。Liu和Croft首先對數據集進行聚類,然后使用該文檔所在的聚類信息對文檔進行平滑,由此給出了基于聚類的文檔語言模型(CBDM,Cluster-BasedDocumentModel),公式如下:
(4)
其中λ,β是平滑參數,Pml(w|Mcluster) 是該文檔所在聚類的語言模型概率。論文在TREC的多個數據集上的實驗證明加入聚類信息的檢索結果優于沒有加入聚類信息的檢索結果。下文簡稱該方法為CBLM。
微博具有不同于傳統文本的多項特征,Hashtag是其中一項。Efron[2]提出了一個利用微博Hashtag的查詢擴展方法。論文將微博語料庫中的Hashtag提取出來整合為Hashtag集合;然后通過含有該Hashtag的微博集合構建該Hashtag的一元語言模型,記為 Mhashtag。 設查詢q的語言模型為 Mq, 用KL距離表明該Hashtag和查詢的相關程度,由此選擇前k個作為查詢擴展詞。實驗證明融入Hashtag信息有利于微博檢索。文獻[3-5]也在檢索模型中運用到了Hashtag,并取得不錯的效果。由此可知,微博的Hashtag對于微博檢索而言是很有效的可利用因素。
將時間融入統計語言模型,其中一種方法為引入文本的時間先驗[7-8, 12]。Li和Croft[7]提出假設“文檔越新,其重要度越高”,由此定義以時間為輸入的指數分布來表示文檔的時間先驗分值,公式如下:
(5)
其指數分布參數為α, 為人工給定,其中td代表文本的時間,tcollection代表文本集中的最新時間。最終論文通過在TREC新聞語料集上做驗證證明加入時間提高了搜索效果。Efron和Golovchinsky[8]在Li和Croft的基礎上進行改進,引入了查詢信息,通過查詢的偽相關反饋文檔計算指數分布的參數,公式如下:
(6)
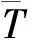
(7)
衛冰潔和王斌[12]在微博數據的背景下,對文獻[7]和文獻[8]進行了更深入的研究。通過分析微博查詢的時間分布圖,定義了查詢的熱門時刻,給出新假設“文檔時間距熱門時刻越相近,文檔越重要”,提出基于熱門時刻的語言模型(Hot-TimeLanguageModel,HTLM)。本文將已有工作分為兩類,一類是與查詢無關模型P(dt), 即Li和Croft提出的模型,一類是查詢有關模型P(dqt), 即Efron和Golovchinsky提出的模型以及HTLM模型,通過引入平滑思想,最終提出一個混合文檔先驗計算方法,公式如下:
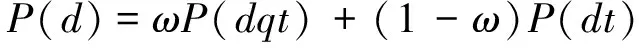
(8)
其中ω是平滑參數,取值為0~1。論文在TRECMicroblog數據集上進行了實驗驗證,結果表明,HTLM模型優于已有工作,混合模型優于單一模型。
綜上所述,聚類有利于檢索效果的提高,融入Hashtag信息或者加入時間的排序模型在微博數據集上效果好于原有模型。但是加入聚類信息是否利于微博搜索、如何將Hashtag信息融入聚類中、如何克服只有少量微博具有Hashtag的困難、聚類和時間融合是否將促進檢索效果的提升等還尚未得到驗證,本文將就這些問題進行深入研究和驗證,最終提出一個利用時間信息和聚類信息的語言檢索模型。
3 融合時間和聚類信息的檢索模型
3.1 針對微博檢索的分析
檢索數據和用戶查詢是一個檢索過程的基本組成,這二者的特點也決定了檢索模型的選擇。那么我們分別從這兩方面詳細說明微博檢索相對于傳統檢索的不同。
首先在微博搜索的背景下,數據不再是傳統網頁,而是新型數據: 微博。微博相較于以往的文本,具有很多獨有的特征,包括: 文本字數限制在140個字以內和具有特殊符號“#”(稱之為Hashtag)。文本字數的限制帶來的是信息量的不足,而大部分傳統的檢索模型的前提是信息量充足,比如BM25以及語言模型。因此進行微博內容的擴充是非常必要的,本文選擇聚類作為擴充方法。“#”在傳統網頁中并沒有特殊的含義,而它在微博中卻具有指定的意義: 用兩個“#”包圍著的詞通常為該用戶給出的關于這篇微博的主題詞,類似于某些用戶給傳統網頁所打的標簽。主題詞對于微博內容的確定有很大關系,如果該主題詞與查詢相關,那么該篇微博內容與主題相關的概率很高。但是在數據集中,具有Hashtag的微博個數非常少,是提出微博檢索方法時需要克服的問題之一。
其次,針對于微博查詢的特點,已有多項研究表明微博查詢具有時間敏感性[6, 8, 12]。面向時間敏感查詢的搜索,傳統的檢索原則,即計算查詢和文檔的語義相似度,是不夠的,需要在檢索過程中引入時間的因素,從而使得一個文檔的排名不僅僅側重于它的語義相似度而同時與它的時間有關。考慮微博查詢的時間特性,適用于微博的檢索模型需要引入時間信息。
基于上面從數據和查詢兩個角度分析微博的特點,本文分別設計了基于擴展標簽(Hashtag)的聚類語言模型和融合時間和聚類信息的微博檢索模型,以期得到更優的微博檢索效果。
3.2 基于擴展Hashtag的聚類語言模型
聚類算法是指將一系列文檔聚團成多個子集或簇(cluster),其目標是找出類內緊密、類間分散的多個簇。常用的聚類方法根據其簇之間是否有關系分為扁平聚類和層次聚類兩類。K-means算法[13]是扁平聚類算法的代表方法,其基本流程為: 當指定聚類個數為K時,首先從N個數據量中隨機挑選K個對象作為初始的聚類中心;然后計算N個數據量與K個聚類中心的距離,選擇最近的作為該對象所屬類別;接著根據新類別重新得到K個聚類中心;最后判斷是否達到停止條件,如果沒有則從第二步開始迭代進行。當被劃分數據為文本時,通常采用向量空間模型表示文本,tf*idf作為向量的每一維的權重,余弦相似度(cosinesimilarity)作為類別劃分標準。
在微博數據集中,由于微博內容短,且經過詞干還原和去除停用詞處理之后,剩余的有效詞個數很少,比如在TRECMicroblog數據中微博ID為29742094935392256(‘Jordansare’)、31907613243351040(‘JordanHasMe!’)、34773247190892544(‘IwantsomeJordans!’)最終文本都成為了“jordan”。在本文中,我們的目的是找到與微博內容相同或相似的結果,以此提高微博已有詞的權重并加入未有詞,也就是說這些微博之間是有共同詞匯的,因此我們假設其聚類形狀是以某個詞或某些詞為中心向外延伸的偏圓形,K-means聚類是針對這類型數據的很好的聚類方法。與此同時,由于微博文本短,所以它的向量維度不會過高;而其微博數量過大,我們采取減少數據集,即只選擇查詢的搜索結果中的前10 000篇微博構成新的文檔集,降低算法的運行時間。圖2是一個聚類結果的截圖,從圖中可以清晰的看出,這個結果是關于“Jordan”的微博集合。用該集合的語言模型平滑微博,可以提高“Jordan”的詞概率,同時加入michael,egypt等詞的概率,豐富了微博的原有信息,達到了我們最初的目的。也就是說當得到聚類結果之后,帶入式(3)到式(1)中,得到CBLM算法。
在確定了聚類算法之后,核心問題便是如何融入微博的Hashtag信息。雖然文獻[14]并非是針對微博排序的研究,但是可以借鑒其把Hashtag信息加入到聚類過程的方式。Ramage,Heymann[14]認為現有的很多網頁擁有用戶所標注的標簽,這些標簽便是對這些網頁的主題的表明。論文中給出了多種融合網頁原有文本和網頁標簽的方式,經過實驗驗證,原有文本和網頁標簽同時進行向量化的結合方式取得了較好的聚類結果。相較于微博數據,微博的Hashtag便是用戶給定的特定微博的主題詞,因此本文也采用這種方式進行微博文本的向量化,得到的模型稱為CBLM+Hashtag。
同時我們發現文獻[14]所做實驗的背景是網頁且都具有標簽,而據統計可知,在微博數據集中,具有Hashtag的微博個數僅占13%,并且存在內容相同的微博有的有Hashtag,有的沒有Hashtag。因此我們提出了一種擴展微博Hashtag的方法,設給定微博d,首先將微博d的文本內容作為查詢,在微博數據集中搜索前K篇相似文本, 構成其相似文檔集合,記為Rset。然后抽取Rset中每篇微博的Hashtag,作為微博d的擴展Hashtag。在本文的實驗中,K取值300。使用擴展后的微博數據集進行聚類,然后用來平滑原始微博的語言模型,進行微博排序,下文稱該算法為CBLM+ExpandHashtag。

圖2 微博數據集聚類截圖舉例說明
3.3 融入時間的統計語言模型
通過第2節對前人的工作介紹可知時間是微博檢索不同于傳統檢索的特征之一,將時間融入檢索模型的一種代表性工作便是作為文檔先驗。衛冰潔和王斌[12]在微博數據集的背景下,通過對微博查詢的分析,對文獻[7]和文獻[8]的工作進行了擴展研究,最終提出了一個混合時間文檔先驗計算方法。根據論文中的基于混合模型的實驗結果得知,當MAP最高時,P(dt) 選擇的是文獻[7]提出的模型;P(dqt) 選擇的是HTLM系列模型,帶入式(6)中得到最終先驗計算公式為:
(9)
其中涉及的參數取值分別為α1為0.3,α2為0.3,計算tqd過程中涉及的熱門時刻閾值參數取值為0.8,tcollection是數據集中的最新時間,取值為17。
3.4 融入聚類和時間信息的統計語言模型
在第1節中介紹了利用Hashtag的聚類語言模型,第2節中介紹了基于時間先驗的語言模型,針對式(1),前者修改的是p(w|Md) 的概率,后者修改的是P(d) 的取值,將計算公式帶入,得到了我們提出的融入聚類和時間信息的最終模型,分別記為CBLM+Time,CBLM+Hashtag+Time,CBLM+ExpandHashtag+Time。最后我們通過在數據集上驗證,證明加入時間之后的模型對檢索效果有進一步的提升。
4 實驗及分析
4.1 實驗數據及評價指標
本文實驗所用的數據集為2011年TRECMicroblogTrack發布的從2011年1月23日至2011年2月8日共有17天的Twitter數據,我們對數據集進行了預處理,包括去除所有的非英文及轉發微博,處理過后的微博個數為9 679 710。然后對這部分數據集刪除了微博內容的@信息和url信息,提取出微博的Hashtag單獨存儲,同時對于微博文本和Hashtag詞進行了詞干還原和分詞處理。所用的查詢集為TRECMicroblogTrack于2011和2012年發布的共110個查詢及其標注的相關文檔集合,共有113 926篇微博被標注。表1列出的是本文模型涉及的參數取值。我們將110個查詢隨機分為10份,然后用其中3份用來訓練模型的參數,最后在整個數據集上進行效果驗證。
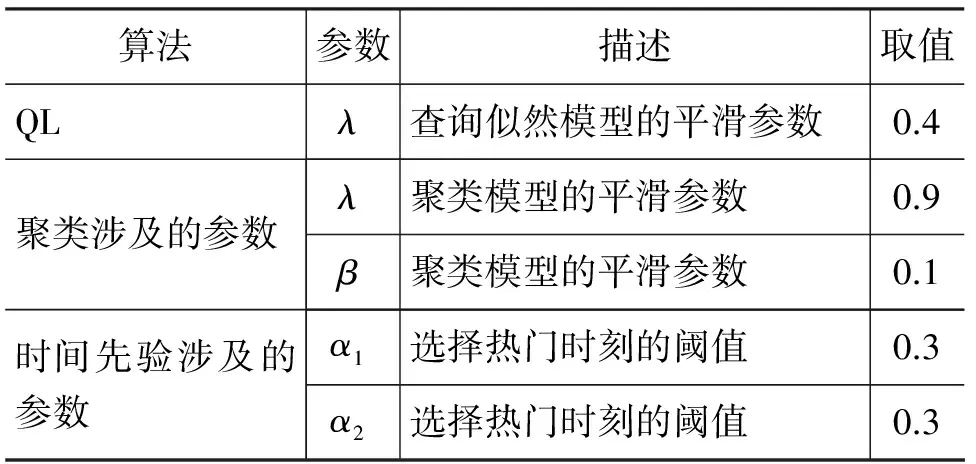
表1 根據評價指標選擇的最優結果參數取值
4.2 評價指標
本文選用信息檢索研究領域常用的評價指標P@k和MAP用來對我們提出的檢索模型進行性能評估。
P@k(Precision at k),是指前k個返回結果集的正確率,如k可取值5,10等,在本文實驗中,k取值為30。計算公式如下所示:
(10)
平均正確率(簡稱為AP)是指針對單個查詢而言,計算返回結果中在每篇相關文檔位置上的正確率的平均值[15]。MAP是指針對查詢集合的平均正確率的均值。設查詢記為qi,針對查詢的相關文檔集合為 {d1,d2…,dmi}, 設Rik是返回結果集中遇到dki時的全部文檔集合,本文的返回結果集為前1 000篇返回結果構成。則其AP計算公式為:
(11)
根據AP的計算公式,設查詢集合為Q,則其平均正確率均值(MAP)的計算公式為:
(12)
4.3 融合聚類和時間信息的語言模型實驗結果及分析
根據第3節的介紹可知,本文需要進行比較的模型共有8個模型,其中統計語言模型系列中的查詢似然模型是本文的基準模型,記為QL;同時本文也同基于統計語言模型使用TREC數據的模型ATM進行了對比[16],ATM模型是基于用戶信息構建的檢索模型,它使用用戶所發的微博構造用戶模型,以此達到擴充微博內容的目的,與本文使用聚類方法克服文本短具有對比性。表2列出了各個模型在TRECMicroblog數據集上的實驗結果,其中含有 “*”號標記的表示該結果與QL在成對T側上(P< 0.05)具有統計顯著性。
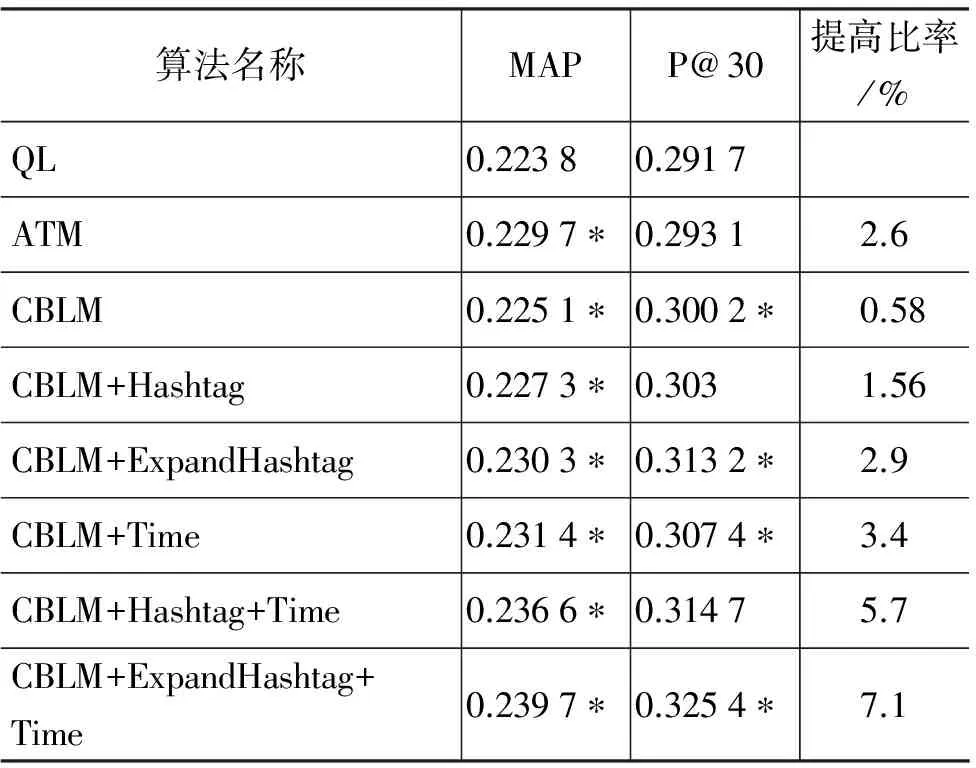
表2 在TREC 2011 Microblog數據集上的檢索結果
觀察表2可得到,本文提出的模型相比于QL(基準實驗),在MAP和P@30兩個指標上都有提高,表明了在微博檢索背景下,聚類信息和時間信息對于排序結果有提高作用。在上文描述中,可知微博排序和傳統文本排序的區別在于兩點,第一點是考慮微博特征,我們主要關注的是微博文本短和具有Hashtag;第二點是在排序原則中考慮時間性質。下面我們也根據這兩類進行具體分析。
首先分析考慮微博特征的模型,即融入聚類和微博Hashtag。具體來看,CBLM是加入了聚類信息的模型,檢索效果優于沒有加入聚類信息的,這是因為聚類代表與該文檔相似的文檔集合的信息,用這些信息平滑文檔會同時加重文檔本身的信息補充文檔未有的信息。接下來我們運用微博的Hashtag特征,我們將微博的Hashtag加入到基于聚類的微博排序模型中(CBLM+Hashtag),效果較之CBLM模型效果更優,其原因是因為微博的Hashtag詞是用戶給出的關于該篇微博內容的主題概括詞,是對微博內容的高度總結,所以加入Hashtag信息后,是對微博內容的重要補充,由此該模型的檢索結果更好。但是,微博數據集中具有Hashtag的個數非常少,僅占整體數據集的13%,而Hashtag信息又如此重要,因此我們提出了一個擴展微博Hashtag的方法,得到模型CBLM+ExpandHashtag,經過實驗驗證,MAP和P@30均得到提高。
然后我們關注加入時間特征的模型。在我們的模型中,時間性質是通過定義文本先驗的方式加入統計語言模型的。通過表2中的數值可以看出來,在任何的原始模型上加入時間之后均比沒有加入時間的模型在效果上更好,再一次證明了時間對于微博檢索的重要性。加入時間之后,效果得到提高是因為微博查詢是時間敏感查詢,這部分查詢的相關文檔在某些時間段內的分布會高于其他時間段,因此加入時間先驗后,會提高重要時間段內微博的分值,由此提高評價指標的取值,得到更好的排序結果。
總體來說,針對于原始的查詢似然模型,在微博檢索的背景下,考慮微博文本特征和時間特性的模型取得了最優的效果。
5 總結及未來工作
近年來,隨著微博用戶量和數據量的蓬勃發展,用戶對微博檢索的精確度要求越來越高,微博檢索越來越重要。新型的數據給研究界帶來了新的挑戰。微博檢索不同于傳統文本檢索的特點表現在兩個方面: 第一個是面向的數據不同;第二個是排序原則不同。微博相對于傳統網頁,具有文本短的特點,并且微博內容中具有用戶給出的關于微博的主題詞,稱為Hashtag。同時微博檢索原則中除了考慮查詢和文本的語義相似度之外,還需要考慮時間特性。針對這兩點不同,首先本文提出運用Hashtag的聚類語言模型,并且由于微博數據集中具有Hashtag的微博僅占13%,我們也提出了一種擴展微博Hashtag的算法。然后我們在提出聚類的模型基礎上,通過定義文檔的時間先驗在檢索模型中加入時間信息,最終得到融合時間和聚類信息的排序新方法。最后我們在TREC Microblog數據集上進行性能驗證,相對于基準模型(查詢似然模型,簡稱為QL),分別證明了加入聚類信息和加入時間信息都比基準模型的效果更優,同時也驗證進行了微博Hashtag擴展之后的融合聚類和時間信息的模型在檢索效果上達到了最優,在MAP和P@30上分別提高了7.1%和11.6%。
本文工作還存在多個可以繼續研究的問題,包括: 1)時間信息除了通過文檔先驗方式以外,如何在聚類過程中融入時間信息?2)每篇微博的Hashtag的個數不同,不同的Hashtag個數是否會具有不同的文檔先驗,有待進行驗證。
[1] Liu X, W B Croft. Cluster-based retrieval using language models[C]//Proceedings of the 27th annual international ACM SIGIR conference on research and development in information retrieval, ACM: Sheffield, United Kingdom,2004: 186-193.
[2] Efron M. Hashtag retrieval in a microblogging environment[C]//Proceedings of the 33rd international ACM SIGIR conference on research and development in information retrieval, ACM: Geneva, Switzerland,2010: 787-788.
[3] Rui Li B W, Kai Lu, Bin Wang. Author Model and Negative Feedback Methods on TREC 2011 Microblog Track[C]//Proceedings of the Text Retrieval Conference (TREC),2011.
[4] Donald Metzler C C. USC/ISI at TREC 2011: Microblog Track[C]//Proceedings of the Text Retrieval Conference (TREC),2011.
[5] Feng Liang R Q, Jianwu Yang. PKU_ICST at TREC 2011 Microblog Track[C]//Proceedings of the Text Retrieval Conference (TREC),2011.
[6] Teevan J, D Ramage. M R Morris. TwitterSearch: a comparison of microblog search and web search[C]//Proceedings of the fourth ACM international conference on Web search and data mining, ACM: Hong Kong, China. 2011: 35-44.
[7] Li X, W B Croft. Time-based language models[C]//Proceedings of the twelfth international conference on Information and knowledge management, ACM: New Orleans, LA, USA,2003: 469-475.
[8] Efron M, G Golovchinsky. Estimation methods for ranking recent information[C]//Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval, ACM: Beijing, China,2011: 495-504.
[9] Song F, W B Croft. A general language model for information retrieval[C]//Proceedings of the eighth international conference on Information and knowledge management, ACM: Kansas City, Missouri, United States,1999: 316-321.
[10] Zhai C, J Lafferty. Model-based feedback in the language modeling approach to information retrieval[C]//Proceedings of the tenth international conference on Information and knowledge management, ACM: Atlanta, Georgia, USA,2001: 403-410.
[11] Ponte J M, W B Croft. A language modeling approach to information retrieval[C]//Proceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval, ACM: Melbourne, Australia,1998: 275-281.
[12] 衛冰潔,王斌. 面向微博搜索的時間感知的混合語言模型[C]. 全國信息檢索學術會議(CCIR),2012.
[13] Berkhin P, A survey of clustering data mining techniques[C]//Proceedings of the Grouping Multidimensional Data: Recent Advances in Clustering. 2006: 25-71.
[14] Ramage D, et al., Clustering the tagged web[C]//Proceedings of the Second ACM International Conference on Web Search and Data Mining, ACM: Barcelona, Spain,2009: 54-63.
[15] 王斌. 信息檢索導論[M],北京: 人民郵電出版社,2010.
[16] 李銳,王斌. 一種基于作者建模的微博檢索模型[J]. 中文信息學報, 2014,28(2): 132-143.
Combining Cluster and Temporal Information for Microblog Search
WEI BingJie1,3, SHI Liang3, WANG Bin2
(1. Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China; 2. Institute of Information Engineering, Chinese Academy of Sciences, Beijing 100093, China; 3. National Computer Network Emergency Response Technical Team/Coondination Cente of China, Beijing 100029, China)
With the rapid development of microblog, microblog retrieval has become a hot research topic in recent years. In contrast to traditional text retrieval, microblog search significantly differs in two aspects. One is that microblog has its own text features, i.e. short text and Hashtag as the theme term. The other is that microblog search should consider the time information and text and semantic similarity. This paper addresses the above issue by clustering to expand text content. The hashtag is introduced into the clustering, and, to guarantee its effect, a method to enrich the Hashtag in a microblog is described. Finally we used the time information as the document’s prior and altogether three models are examined in the experments. Experiments on TREC Microblog dataset show that our models significantly improved MAP and P@30 with 7.1% and 11.6% increase separately.
microblog search; Hashtag; cluster; temporal; language model

衛冰潔(1987—),博士,工程師,主要研究領域為微博檢索及數據挖掘。E?mail:weibingjie1986@163.com史亮(1986—),博士,工程師,主要研究領域為信息檢索和數據壓縮。E?mail:shiliang@ict.ac.cn王斌(1972—),博士,研究員,主要研究領域為信息檢索及自然語言處理。E?mail:wangbin@iie.ac.cn
1003-0077(2015)03-0177-07
2012-12-28 定稿日期: 2013-03-12
科技支撐計劃(2012BAH46B02)。
TP391
A
猜你喜歡
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
文苑(2020年4期)2020-05-30 12:35:30
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
制造技術與機床(2019年10期)2019-10-26 02:48:08
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
電子制作(2018年18期)2018-11-14 01:48:06
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
兒童繪本(2018年5期)2018-04-12 16:45:32
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
小學教學參考(2015年20期)2016-01-15 08:44:38
