
使用服務隔離方法提高系統可用性
2015-05-30 10:48:04營春曉
計算機時代 2015年4期
營春曉

摘 要: 在大型網站和軟件系統中,由于業務的復雜性,常采用服務組件化的架構策略來達到解耦和可擴展的目的。在服務按業務功能切分后,如何提高整個系統的可用性是一個非常重要的問題。文章在對大型網站服務組件化設計架構研究的基礎上,結合服務組件之間強弱依賴關系的特點與典型場景,總結了服務隔離技術的基本思想和維度,提供了服務調用解耦與隔離方法、容器級別服務故障隔離方法、組件服務間接依賴故障隔離方法等來提高系統的可用性。
關鍵詞: 系統高可用性; 強弱依賴; 故障隔離; 服務組件化
中圖分類號:TP391.12 文獻標志碼:A 文章編號:1006-8228(2015)04-21-02
Abstract: Because of the complexity of business, the large web sites and software system use service component architecture to get ultra-scalable and highly decoupling purpose. According to the business service functional segmentation, how to improve availability of the whole system is a very important problem. Based on the research of large web site service component architecture, combined with the characteristics of strong-weak dependence and typical scene, this paper provides the service call decoupling method, the container services fault isolation method and the component services fault isolation method to improve the system availability.
Key words: high availability; strong-weak dependency; fault isolation; service component
0 引言
大型網站及軟件系統,其高可用性直接影響客戶體驗,這是大型網站都需要面對的基礎性課題。高可用性涉及到IT基礎設施、軟硬件架構、開發測試、運維等各個方面。目前,大型網站通常是領域業務多元化,面臨高并發、高流量的挑戰。為了獲得更好的性能和可擴展性,按照服務組件化設計思想,以領域業務為功能單元做垂直切分,各模塊之間提供服務接口關聯起來,這樣可以提高整個系統的可用性。然后隨著應用規模的擴大,服務之間的依賴關系更為復雜,如何在系統出現故障或異常時,避免由“點故障”到“面故障”的擴散,避免不同領域業務相互影響,避免非核心影響核心,是開發者在做應用架構設計與物理部署架構設計時必須要考慮的問題。
本文結合日常項目中的實踐經驗,提出在服務組件化的過程中,如何做服務級故障隔離的原則和方法,提升網站可用性這一需求。
1 服務級隔離基本思想
形式上,系統與系統之間,服務與服務之間(無論是兩個服務是否為同一業務組件)存在以下兩種依賴關系。
⑴ 強依賴。所謂A系統強依賴于B系統是指,A系統必須依賴B系統的處理結果,才能正常的完成邏輯;簡單的來說,如果B不能提供服務,A也無法正常工作。從高可用性設計的角度出發,在這種依賴關系下,A與B系統需要達到如下幾點目標:對于B系統,A直接RPC調用,B在承諾的SLA基礎上,做好自我保護;B系統宕機時,A盡管不能使用,但要保證機器不掛掉;B系統故障恢復時,A可以自動快速恢復;B故障時,A可以自動檢測,自動降低或關閉對B的訪問,防止情況惡化。
⑵ 弱依賴。所謂A系統弱依賴于B系統,是指B系統如果發生了故障,A系統可以繼續提供正常的服務。弱依賴通常有這些特點:可以不等待B結果的返回(比如發送消息、ajax區域加載);B是非核心功能,結果不返回不影響A的關鍵流程(合理超時時間的控制),A、B的調用可以是異步(隊列、線程的FutureTask、協程akka);對B的服務調用可通過功能開關實現降級。
針對強依賴與弱依賴的不同特點,在架構和設計時,為避免故障或異常時由“點故障”到“面故障”的擴散,我們考慮在區分核心與非核心(服務、組件、產品重要度分級)、按功能組與后臺依賴隔離、同一容器內服務間隔離、按客戶群體DNS層隔離、引入異步模式隔離服務調用者與提供者等層面和場景下提供服務故障隔離策略和方法。
2 具體隔離策略與方法的設計
本節根據服務之間的依賴關系以及物理部署結構等特點,總結服務間如何做隔離和解耦的策略和方法。
2.1 服務間依賴隔離與解耦
在服務A與B存在強依賴的情況下(如圖1所示),描述RPC與基于Queue兩種方式的區別。
正常情況:A系統對外承諾500的TPS,系統的平均響應時間為100ms,這時候只需要50個線程并行即可支撐。
故障情況:B系統變慢,導致A的平均響應時間變為1000ms,現在A系統的線程數是500。
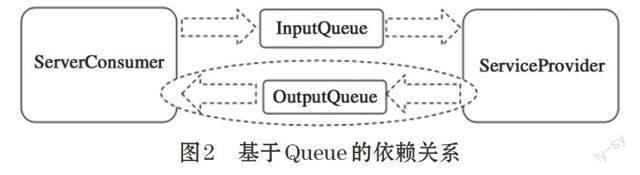
B系統的異常,在直接RPC的調用情況會導致A系統宕機,同時B系統由于A系統的并發訪問數由50變為500,B系統進一步惡化。由此可見,在RPC的調用方式下,無論是同步調用還是異步調用,對于服務器端都是直接壓力傳導,在A與B是強依賴的情況下,如果是同步RPC調用,超時控制在異常時刻是決定性問題。在強依賴的情況下,除了需要在采用RPC調用的時候合理的設置超時外,在架構時可用采用基于消息隊列的方式,來達到服務間由于容量不匹配導致的強耦合(如圖2所示)。圖2中,如果調用者不需要服務方返回結果,則橢圓框的部分是不需要的。
與基于RPC的方式相比,隊列模式有如下特點。
⑴ 為服務調用者與服務提供者解耦,隊列模式尤其適合弱依賴情況下的異步單相消息模式。
⑵ 引入隊列中間層可以對任務做優先級、丟棄策略、持久化等,同時由于中間節點的存在,也引入了復雜性,從響應時間來看,與RPC方式相比會有所增加。
⑶ 在應對突發尖峰流量時,服務端可以實現壓力逐步釋放的目標,保持穩定吞吐率,達到“穩定消化能夠處理的量,快速丟掉不能消化的量”,客觀上達到了服務組件間解耦的目的。
2.2 同一容器內服務間線程隔離
在系統服務化的切分過程中,通常是以業務領域的切分為依據,屬于同一業務領域的服務在部署時基本部署在同一個容器中。由于各個服務對于資源的消耗不同,響應時間與關聯組件也不相同,導致在容器線程總數固定情況下,其中一個服務突然變慢會占用大量線程,導致線程耗盡。同時線程數飆升,引起Context Switch[1]加劇,在JAVA平臺下,還會引起對象生命周期變長,Full GC頻繁,CPU Load Average和Usage高企[2],最終容器整體宕機。
為解決容器內的服務線程隔離問題,在實踐中首先需要根據歷史訪問數據及系統容量規劃的數據,計算出每個服務的峰值與均值并發數、響應時間、交易吞吐率等,具體的數據采集與分析過程在本文中不作詳述。對于服務隔離策略的設計可以采用定額與彈性資源配置兩種方式。
⑴ 悲觀策略:對于每個服務設定固定的最大資源量,任何一種服務當訪問量達到最大時,即使總資源存在富余也不能使用。
⑵ 樂觀策略:在保證每種服務預留最低資源的情況下,允許任務依據一個彈性配額去爭搶線程資源,達到線程利用率的最大化。
2.3 核心與非核心服務隔離
組件A與組件B都強依賴于組件C,同時組件C強依賴于組件D。其中組件A屬于非核心業務組件,B屬于核心業務組件。由于C組件總體處理能力是固定有限的(假定平均響應時間100ms,最大TPS為3000/s),當A組件由于突發流量的影響,對C組件訪問量變大,或者A組件的某些請求會耗費C組件較多的資源時,導致C組件不能處理B組件的請求,級聯導致B系統出現故障的情況發生。在這個場景下,雖然A與B在物理部署上已經做了隔離,但是復雜的關聯組件依賴關系,間接導致因為非核心業務組件影響核心業務組件的事例。為避免上述問題的發生,可以考慮以下兩種隔離策略。
⑴ 如果C組件及其關聯組件水平伸縮后,可以支持更高的性能,推薦采用路由隔離方式進行,即A組件與B組件分別訪問不同C組件服務群組。
⑵ C系統不具備進一步水平擴展的能力(比如瓶頸點不在C,而在于C所依賴的系統D);這個時候可以在C系統上設置流量控制和功能開關標志位,在異常情況下可以限制或關閉非核心系統對C的訪問。
2.4 服務功能開關與降級的設計
在各種服務隔離策略中,當異常流量發生時,在了解全局服務依賴關系和服務重要度排列的基礎上,架構設計中通常使用功能開關和服務降級的策略來分解流量,達到“丟卒保車”的目的來應對突發狀況。在具體的實踐中主要考慮三個方面。
⑴ 管理全局性服務組件的依賴關系,識別各服務調用鏈中的關鍵路徑。在大型網站中,通常存在上千級別的組件,服務之間的依賴關系異常復雜,大部分網站都實現了基于Google的Dapper[3]系統的分布式系統監控與依賴分析系統。
⑵ 功能開關的設計。在設計實現時,存在單機與集群的區別。單機實現時,對于JAVA平臺建議使用JMX標準實現,這樣做的好處是可以納入統一的監控體系,使用JConsole等通用JMX Client可以處理;集群實現時,由于需要對大量節點統一管控,建議使用Zookeeper之類的配置管理系統來實現。
⑶ 自動降級與手動降級的設計與運用。自動功能開關的設計主要是首先確定判斷異常情況的閾值,比如單位時間內服務調用超時或失敗比例超過70%,或者連續失敗或超時達到20。此時系統可以把訪問窗口按指數降低,直到降為1;服務恢復類似于TCP的慢啟動[4],窗口逐漸打開。對于封閉點,應該盡可能提前;對于一些關鍵系統,如支付類系統,最好避免使用自動開關,在接到監控系統報警后,人工介入決定是否需要降級和關閉。
3 結束語
目前新華網要求整體可用性達到99.99%級別,這意味著全年計劃停機時間加上非計劃停機時間不到53分鐘。系統的高可用性是一個系統性工程,除了IT基礎設施外,在軟件層面要具備快速發現定位的監控系統,要擁有完善的容量規劃與評測方法,要有應對峰值流量的策略和手段等,這些會涉及到軟件過程與基礎軟件建設的各個方面。本文提出了在實踐中總結出來的方法與策略可以為有相似需求的系統提供參考與借鑒。
參考文獻:
[1] DANIELP.BOVET&MARCO CESATI.深入理解LINUX內核[M].中國電力出版社,2007.
[2] 林昊.分布式Java應用基礎與實踐[M].電子工業出版社,2011.
[3] SIGELM, N B, BARROSO L, BURROWS M, et al. Dapper, ALarge-Scale Distributed Systems TracingInfrastructure.[R].Google,2010.
[4] W.Richard Stevens.TCP/IP Illustrated Volume 1:The Protocols[M]. Boston: Addison-Wesley,December 15,1993(1):233-240
