基于個性化推薦的移動英語學習平臺設計
2015-05-30 16:45:49王東升王麗輝
中國新通信 2015年23期
王東升 王麗輝
【摘要】 個性化學習符合認知發展規律,移動學習提供泛在學習環境,兩者的結合將有力地促進英語教學。通過分析用戶信息和用戶學習行為建立偏好模型,在分析資源信息的基礎上,利用混合式推薦技術,實現個性化學習材料的主動推送,以構建基于個性化推薦的移動英語學習平臺。
【關鍵詞】 個性化推薦 移動學習 混合式推薦
近年來,我國英語教學經歷了一系列的改革,教學理念和教學方法都發生了巨大的變化,然而,大班教學的現狀卻始終未能改變。在大班條件下,有限的課堂時間使教師只能講授語言知識,而不能為學生提供充足的語料和運用英語的機會,學生的學習需求無法得到滿足。移動技術的發展為解決這一問題提供了一個契機。利用移動設備,學生可以隨時隨地從網上獲取大量的學習資源。然而,網上海量的資源卻容易造成“網絡迷航”和注意力分散現象。在這種情勢下,個性化推薦技術應運而生。
一、個性化學習理論
個性化學習是指學習者可以自主制定學習計劃、選擇學習內容,確定學習時間和學習地點的學習方式。個性化學習是在多元智能理論和元認知理論的基礎上提出的。多元認知理論認為人的智力是多元的,學習者之間個體差異巨大,因此,教師應了解并尊重個體間的差異。元認知理論認為每個學習者都有獨特的認知風格和認知方式,因此,教師應提供多樣化的學習資源,以滿足不同的認知需求。個性化學習具有學習資源的多維性、學習價值追求的多重性、學習風格的獨特性、學習過程的終身性和學習方式的自主性、合作性與探究性特征[1]。
二、個性化推薦
個性化推薦是指利用用戶以往的選擇或相似性關系發掘用戶潛在的興趣對象,通過過濾信息為用戶提供滿足個性化需求的產品。個性化推薦系統通常由3部分組成:用戶行為記錄模塊、用戶偏好模塊和推薦算法模塊。推薦算法主要包括基于內容的推薦、協同過濾推薦、基于網絡結構的推薦、基于知識的推薦、混合推薦等。
三、移動英語學習平臺設計
設計移動英語學習平臺是為了滿足學習者個性化的學習需求,因此首先要分析用戶的特點和用戶的偏好以及用戶間的相似關系。其次要對學習資源進行分析,包括資源的類型、特征、屬性等。在此基礎上利用混合式推薦,為學習者提供需要的學習材料。
3.1 平臺總體結構
個性化移動英語學習平臺主要由服務器和移動終端兩部分組成。服務器端包括web服務器和數據庫服務器。數據庫服務器用于存儲用戶信息和學習資源,Web服務器用于上傳資源和修改數據庫。移動終端是指接入互聯網,可以向Web服務器提出學習請求或接收資源的智能手機、平板電腦等設備。個性化移動英語學習平臺架構分為三層:數據層、業務層和表現層。具體如下圖所示: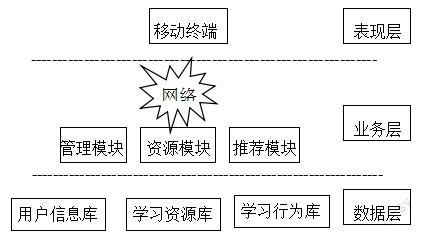
數據層采集、存儲學習者的基本信息和學習行為信息以及學習資源信息,并通過預加工為業務層提供信息。業務層是整個平臺最核心的一層,通過數據挖掘和數據分析,對數據層傳遞來的信息進行過濾、分析、加工、建模以建立用戶偏好模型。應用層接受用戶偏好模型,并為學習者推薦個性化的學習內容。
3.2用戶偏好模塊
要建立用戶偏好模型首先要采集和整理用戶信息。用戶信息包括基本信息和學習行為信息。基本信息是指用戶在注冊時填寫的個人信息,學習行為信息是通過用戶的各種學習行為采集的信息,如點擊、瀏覽、搜索、下載、收藏、分享、評價等行為數據。服務器端對用戶信息進行數據分析和建模。對于新用戶基本信息的簡單處理可采用決策樹算法。該算法不需要了解用戶背景知識,只需要對用戶進行分類就可以初步預測用戶對學習材料的態度。例如,兒童可能對英語兒歌感興趣,高中生可能對語法知識感興趣。利用決策樹進行數據分類首先需用一組訓練數據集來訓練分類器,然后用已建好的分類器對真實用戶數據進行分類。在對用戶基本信息簡單處理后,通過對用戶的學習行為數據的分析,來建立用戶偏好模型。具體方法是用關鍵詞和相應的權值來表示偏好,對關鍵詞權值的計算有多種方法,其中TF-IDF(詞頻-逆文檔頻率)算法簡單且容易實現。
3. 3學習資源分析模塊
聽、說、讀、寫、譯是英語基本技能,其中說、寫屬于輸出性技能,聽、讀屬于輸入性技能,譯則是各種技能實現的基礎。為學生提供個性化推薦,主要是推薦輸入性的語言材料,即聽力材料和閱讀材料,同時為了提高寫作能力,教師也可為學生提供作文的范文。在為學生提供閱讀材料和作文范文前,教師首先要了解材料中詞匯的難度。詞匯的難度取決于詞匯的長度、音節數和使用頻率。Chin-Ming Chen總結了詞匯難度公式[2]:
bj =( Lj×0.7+Pj×0.3) ×Gj
其中, bj表示第j個詞匯的難度, Lj表示第j個詞匯的長度系數, Pj表示第j個詞匯的音節長度系數, Gj表示根據詞頻確定的第j個詞匯的難度系數。
詞匯的難度對文章難度有影響,文章的類別、主題對文章的難度也有影響。最常用的文本表示方法是向量空間模型。在向量空間模型中,每個特征項對分類有不同的貢獻,因此需要進行權重計算。為了使用戶描述文件和學習資源描述文件的表達方式一致,對學習資源文件也采用TF-IDF算法來計算。
同樣,在向學生推薦寫作范文時,也需要了解文檔的相似度,也可采用TF-IDF算法來進行相似度判斷[3]。為學習者提供聽力材料的過程較為復雜,由于計算機不具備人腦的智能,因此難以分析音、視頻材料的難度和主題。因此需要教師為聽力材料標注難度、主題、類型等,系統在結合用戶學習需求的基礎上為用戶提供個性化的聽力材料。
3.4個性化推薦模塊
由于移動終端數據存儲、處理能力有限,因此本平臺的個性化推薦模塊在服務器端實現。推薦算法選擇基于內容的推薦算法。該算法對用戶和學習資料分別建立配置文件,通過分析用戶瀏覽的內容,建立用戶的配置文件,通過比較用戶與學習資料的相似度,向用戶推薦與其最匹配的學習資料。基于內容的推薦可以處理冷啟動問題,而且本平臺的學習資料多為文本資料,多媒體資料經過標識,已便于計算機識別和處理,因此基于內容的推薦算法更為適用。
本文將個性化推薦技術應用于移動英語學習中。通過對學習者基本信息和學習行為信息的采集和處理,建立用戶偏好模型,通過對學習資料的分析建立學習資料模型,運用基于內容的推薦算法將用戶信息與學習資料信息相匹配,并將最匹配的材料發送至用戶的移動設備上。本平臺節約了學習者大量的資料搜索和選擇時間,緩解了“網絡迷航”狀況,提高了英語學習效率。
參 考 文 獻
[1]李廣,姜英杰.個性化學習的理論建構與特征分析[J].東北師大學報(哲學社會科學2005,(3):152
[2] Chih-Ming Chen, Ching-Ju Chung. Personalized mobile English vocabulary learning system based on item response theory and learning memory cycle[J].Computers &Education,2008(51):624-645.
[3]葛昊,葉艷,包西林,吳敏.基于主題模型的英語寫作批閱系統個性化推薦模塊設計與實現[J].科技和產業,2013(6):151-155
