基于Spark的遙感數據分析方法
2015-07-26 02:29:50陳峰科孫眾毅池明旻
微型電腦應用 2015年8期
關鍵詞:實驗
陳峰科,孫眾毅,池明旻
基于Spark的遙感數據分析方法
陳峰科,孫眾毅,池明旻
隨著遙感技術的快速發展,遙感數據呈爆炸式增長,給遙感數據計算帶來巨大的挑戰。采用基于內存計算的Spark分布式計算框架以克服該問題,并選擇YARN作為資源調度系統和采用HDFS為分布式存儲系統。Spark是一個開源的分布式計算框架,基于彈性分布式數據集(RDD)概念,采用先進的有向無環圖執行機制以支持循環數據流操作,通過一次數據導入內存就可以完成多次迭代運算。因而,特別適合基于多次迭代的大數據計算分析方法,相較于每輪迭代需把數據導入內存的MapReduce有更大的優勢。將該計算框架應用于海量遙感數據分析,驗證需要多次迭代的奇異值分解(SVD)算法在該數據分析中的有效性。實驗表明,隨著迭代次數增加,基于Spark的SVD運算效率相對于MapReduce有明顯提高,通常可提高一個數量級。
大數據計算;遙感數據;Hadoop;Spark;MapReduce
0 引言
目前,世界上有超過1000個正在工作的衛星實現對地觀測的任務[1]。其中,大量的衛星用于民用工程,數據全球可共享,為科學研究提供有力的數據保障。隨著遙感技術的飛速發展,遙感圖像的空間和光譜分辨率也越來越高,可以獲取的遙感數據量也迅猛增長。通常,機器學習、模式識別和數據挖掘方法用來分析和理解遙感圖像。其中,大量的算法需要大量迭代運算,比如用于分類的邏輯回歸方法、用于特征提取的SVD(Singular Value Decomposition)等。而遙感數據爆炸性增長給這類方法帶來巨大的計算挑戰。為了解決該問題,目前常用的方法有基于GPU加速的高性能計算系統和基于Hadoop的分布式集群。
CUDA[2]和OpenCL[3]是基于圖形處理器(GPU)的并行計算編程模型,適合需要大量計算的應用,以此為基礎的傳統高性能計算系統被廣泛用于研究領域。GPUs在浮點運算和并行計算方面相對于 CPUs有著巨大的優勢,使得使用GPU可以大幅提高計算速度。深度學習是一種需要大量計算的多次迭代算法,英偉達在[4]中提出了基于CUDA的深度神經網絡包CUDNN(CUDA Deep Neural Network library),實驗結果顯示深度學習框架利用cuDNN加速后獲得了36%的速度提升。但是,雖然GPU加速能提高計算速度,卻對于數據密集型計算效率不高,而且代碼編寫調試復雜。
Hadoop[5,6]的核心分為兩部分:HDFS分布式文件系統[4]和MapReduce計算框架[5]。在處理大量文件時,相對于傳統的本地文件系統,HDFS在吞吐率和穩定性方面有很大的優勢。除此之外,[7-8]中工作證明,基于 MapReduce實現的分布式算法能夠在批量處理數據的任務中相對于單機實現的算法有極大的性能優勢。然而,在許多迭代進行的計算任務中因為在每一輪迭代過程中,中間數據集都需要從硬盤中加載,如此的 IO操作會消耗大量的時間,限制了基于MapReduce在如機器學習等多次迭代算法上的速度性能優勢。Hadoop和 GPU加速技術的結合(CUDA+Hadoop[9], OpenCL + Hadoop[10]),在一定程度上能夠提高計算速度,但在涉及多次迭代機器學習算法時候,依然受 MapReduce每輪中間數據集讀寫時間的掣肘。Mahout是基于MapReduce的機器學習包,2014年4月份Mahout社區宣布,Mahout不再接受基于MapReduce實現的算法,轉向Spark[11]。Spark是一個基于內存計算的開源分布式計算框架,其是一個快速且易于使用的計算框架,核心數據結構為彈性分布式數據集(RDD),擁有先進的有向無環圖(DAG,Directed Acyclic Graph)執行引擎,能夠有效處理循環數據流。當集群內存充足時,基于Spark的多次迭代機器學習算法只需要在第一次迭代時將數據從硬盤中導入內存,相對于基于MapReduce的多次迭代算法來說,節省了中間數據集硬盤讀寫的時間。這些特有的性質,使得Spark特別適用于機器學習與數據挖掘算法,基于Spark的多次迭代算法能夠在保持高可靠性和容錯性的情況下相對于基于MapReduce算法擁有更強的速度性能優勢。在許多實際任務中,基于Spark的多次迭代算法比基于MapReduce實現的算法在時間上可以快10倍以上。
本文提出了一個基于Spark的遙感數據處理平臺,能夠有效應對遙感數據日益增長對于相關算法處理數據帶來的挑戰。該平臺由兩部分組成:分布式存儲系統和分布式計算框架。在該平臺中,選擇了Hadoop的分布式文件系統(HDFS)作為分布式存儲。分布式計算框架由傳統的MapReduce和基于內存的Spark組成,其中Spark由于其能高效實現機器學習等多輪迭代算法而被選為平臺核心框架。基于MapReduce實現的機器學習包Mahout和基于Spark實現的機器學習包MLlib在該平臺上都可以使用,里面包含了大部分主流的機器學習算法,可以為遙感大數據的處理提供支撐。為驗證平臺的有效性,并評估不同計算框架的性能,本文在構建的平臺上對于兩個公開數據集,分別基于 Spark和MapReduce實現了奇異值分解(SVD)。SVD是一種多次迭代算法,是許多遙感數據處理算法的重要組成部分。實驗結果顯示,隨著迭代次數的增加,Mahout中基于MapReduce實現的SVD和MLlib中基于Spark實現的SVD運行速度上的差距逐漸增大。當迭代輪數到達一定數量之后,基于Spark實現的SVD比基于MapReduce實現的SVD有十倍以上的性能優勢。
1 數據處理平臺介紹
隨著可利用的遙感數據量日益增長,即使是使用GPUs加速,單機也越來越難滿足需要。開發能夠快速有效處理遙感數據的分布式平臺顯得愈發緊迫與重要。數據處理平臺通常分為兩個部分:分布式存儲系統和分布式計算框架。以HDFS、Hbase為代表的分布式存儲系統已經被廣泛應用于各個領域的大數據存儲系統之中。MapReduce因其在數據密集型計算方面的巨大優勢,是目前大部分應用中分布式平臺的最主要選擇。在本文提出的平臺中,分布式存儲系統采用了以GFS[12]為基礎的HDFS分布式文件系統。在使用平臺對數據進行處理之前,遙感數據需要首先導入到HDFS中。基于內存計算的Spark,被選擇作為主要的分布式計算框架。平臺同時整合了Hadoop的MapReduce計算框架。Apache YARN被選擇作為平臺的任務調度系統,YARN位于HDFS和分布式計算框架之間,為多個運行中的應用分配資源。YARN能夠支持Spark和MapReduce等多種計算框架,使得在平臺上,基于Spark的機器學習包MLlib和基MapReduce的機器學習包Mahout里面的算法皆可使用。本文提出的平臺,在滿足一般分布式平臺具有的存儲和批量處理遙感數據功能之外,還能實現迭代運算對數據的快速處理。在這一章剩下的部分,我們將對我們工作中涉及到的分布式技術做進一步的介紹。
1.1 Hadoop
Hadoop包含一系列分布式存儲和處理數據技術,是一個由Apache基金會支持的開源項目,同時滿足容錯、可伸縮,并且易于擴展,易于學習。Hadoop的核心分為兩部分:分布式文件系統 HDFS和分布式計算框架 MapReduce。Hadoop的完善與普及,使得原本需要昂貴的超級計算機才能解決的數據任務在使用一般的服務器組成的集群中就能得到高效解決。通常情況下,隨著集群規模變大,硬件損壞頻率會越來越高,Hadoop容錯機制都能夠保證任務在一般硬件損壞情況下成功執行。如今,Hadoop已經能夠管理數千臺機器,對PB級別的數據進行存儲和處理。
1.2 Mahout
ApacheMahout是一個可擴展機器學習包,在ApacheHadoop項目的基礎上,基于MapReduce編程模型實現的。Mahout能從多個數據源中讀取數據,利用數據科學的工具分析挖掘數據。Mahout的目的在于使得算法處理過程速度更快,數據規模更加容易擴展。到目前為止,Mahout支持四種數據處理應用:協同過濾,聚類,分類和頻繁項集挖掘。大部分經典的機器學習算法在Mahout中都有實現。
1.3 Spark
ApacheSpark是一個Scala語言實現的基于內存計算用于處理大規模數據的快速通用引擎。雖然MapReduce模型在分布式批量處理任務的現實應用中取得巨大的成功,但卻不能滿足涉及到循環數據流應用的需要,而這種應用在機器學習與數據挖掘算法中是十分常見的。Spark技術的提出正因為此,在保證與MapReduce可以媲美的可擴展性和容錯性的基礎上,滿足循環數據流應用的需要。Spark基于其創造性的彈性分布式數據集(RDD)概念,使用先進的有向無環圖(DAG)執行機制,能夠支持循環數據流的應用和內存計算。在許多機器學習任務中,Spark能夠在執行速度上遠遠超越MapReduce。Spark被設計為可以獨立地運行,其也能夠與其它主流分布式存儲系統與任務調度系統合作工作。在本文提出的平臺之中,Spark被作為一種計算框架置于YARN之上,與MapReduce同時運行于集群之上。
1.4 Spark vsMapReduce
Spark與MapReduce相比,其有如下優勢:
基于內存計算。中間數據集保存于內存之中,無需反復讀取硬盤,適合于迭代計算任務。
DAG 執行引擎。Spark執行過程中沒有嚴格的Map/Reduce階段,通過其獨有的血緣機制,在保證容錯性下進一步減少硬盤讀寫操作。
容易編程。Spark是由函數式語言Scala實現的,可以通過Scala編寫創建任務,代碼編寫更加靈活。
Spark相比MapReduce更加適合于如機器學習與數據挖掘等迭代計算任務,而MapReduce在數據密集型計算中仍然保持了強大的競爭力。兩者互補已經成為當今主流分布式平臺構建時的共識。
2 實驗數據集和實驗設置
隨著遙感技術和互聯網技術的快速發展,可以獲取的遙感數據來源逐漸增多,越來越多的高光譜與高分辨率數據被應用于各類科學研究中。如何快速有效地處理遙感數據從未像現在一般迫切和重要。在本章的剩余部分,我們簡單我們實驗中涉及到的遙感數據集,并對實驗設定做一個詳細的描述。
2.1 實驗數據集
(1)Indian_pines:1992年AVARIS傳感器在IndianPine上空拍攝的高光譜遙感圖像。圖像大小為145*145像素,每個像素點有220個波長,分布在0.36到2.5μm之間的波段中。
(2)Pavia:由ROSIS-03衛星在Pavia上空獲取的高光譜高分辨率(1.3m)圖像,每個像素點有103個波長在0.43到0.86μm之間的波段。分為Pavia和PaviaU兩張圖像,圖像覆蓋地點分別為Pavia市區和Pavia大學。
2.2 集群配置
本文提出的平臺在實驗集群上實現。實驗集群由5臺服務器組成,每臺服務器內存為24GB,擁有四核處理器。服務器操作系統皆使用CentOS6.5,集群使用的分布式系統版本為Hadoop 2.5與Spark 1.0.1。
2驗設置
實驗在兩個公開遙感數據集上對于 Spark實現的 SVD和基于MapReduce實現的SVD算法進行運行時間比較,以證明本文提出的平臺在性能上對于遙感數據的處理與傳統分布式平臺有極大提升。SVD是許多遙感數據相關操作的重要組成部分,對于SVD操作的快速計算可以大幅提高有關算法的性能。由于在實際情況下,SVD實驗運行時間與集群狀態擁有關聯性,集群內存或者集群網絡的占用都會影響到任務執行時間,單次實驗結果有一定隨機性。為保證實驗結果的科學與嚴謹,每次SVD實驗都重復10次,并取平均計算時間作為最終結果值。
3 實驗結果及分析
顯示了基于Spark實現的SVD和基于MapReduce實現的SVD在IndianPine和 Pavia數據集上面隨著奇異值的增大運算時間的變化情況。如圖1、圖2所示:
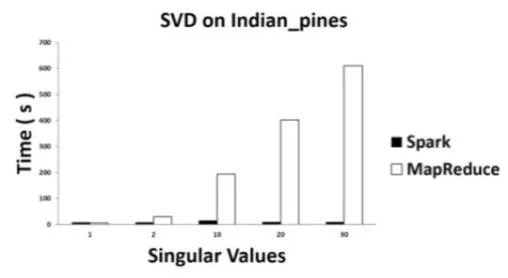
圖1 :Indian_pines遙感數據集上的SVD計算時間
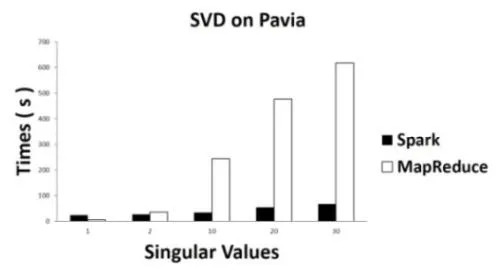
圖2 :Pavia遙感數據集上的SVD計算時間
在SVD的分布式實現中,當奇異值的個數小于總的特征數量的一半時,算法的迭代次數隨著奇異值數量的增大而提升。實驗中使用數據集的數據規模(樣本數量和每個樣本的特征個數)如表1所示:

表格1:數據集規模
從圖1、圖2的計算時間結果中可以看出,當奇異值為1時,Spark的SVD比MapReduce的SVD并沒有優勢。但是,從所有的數據集的實驗結果中我們可以看到,隨著奇異值數量的增大,算法的迭代次數增多,MapReduce的SVD運行時間迅速增加。相對而言,Spark的SVD的運行時間卻沒有隨著迭代次數的增加有快速提升。在相同數據集上,當奇異值超過30時,MapReduce SVD消耗的時間是Spark SVD消耗的時間的10倍以上。
無論基于何種計算框架,實驗數據皆需要在第一次迭代之前從硬盤中導入至內存中,基于 MapReduce的算法在每一輪迭代中都需要進行如第一輪中的硬盤讀寫操作。而對于基于內存計算的Spark框架而言,迭代計算的中間數據集可以存儲于內存中,無需進行反復的硬盤讀寫。這使得由Spark實現的算法中,后面的迭代相比第一次迭代消耗的時間要短許多。內存計算的特性為基于Spark的許多算法提供了無與倫比的性能優勢。
在SVD算法實際的運行過程中,無論是MapReduce還是Spark,每一次計算的時間都遠遠小于數據導入內存的時間,數據導入時間對于總體運行時間起到了決定性因素然而數據導入內存的時間因集群狀況,比如內存使用和CPU占用等影響很大,這使得數據導入時間在一定程度上有很大的隨機性,甚至可能會出現導入相同的數據消耗的時間相差10倍以上的情況。在實驗結果中,即使是使用10次實驗的平均計算時間作比較,也出現了隨著迭代次數的增加,計算時間反而出現了減少的情況。但是這并沒有影響基于Spark的SVD算法對于基于MapReduce算法的巨大性能優勢。
4 總結
本文提出基于Spark的分布式數據處理平臺。在該平臺中,HDFS作為分布式文件系統,YARN作為資源調度框架,Spark作為主要分布是計算框架。為了驗證該平臺的計算有效性,實驗采用需要多次迭代算法SVD提取海量遙感數據的特征。實驗結果表明,基于Spark的分布式多次迭代算法相對于基于MapReduce實現的在計算效率上有顯著的提升。與傳統的MapReduce數據處理平臺相比,該平臺更適合處理利用多次迭代的數據方法處理海量遙感數據。
[1] 姚禹,向晶.全球在軌衛星數量突破1000顆大關[J].中國無線電,2012, (11):77-77.
[2] CUDA, http://www.nvidia.com/object/cuda home new.html/.
[3] Xu J Y. OpenCL–The Open Standard for Parallel Programming of Heterogeneous Systems[J]. 2008.
[4] Chetlur S, Woolley C, Vandermersch P, et al. cudnn: Efficient primitives for deep learning[J]. arXiv preprint arXiv:1410.0759, 2014.
[5] Borthakur,D.“The hadoopdistributed file system: Architecture anddesign,” [J]Hadoop ProjectWebsite,2007, 21(11).
[6] Dean J and Ghemawat. S,“Mapreduce: simplified data processingon large clusters,” [C].Communications of the ACM,51(1):107–113, 2008.
[7] Golpayegani.N and Halem.M “Cloud computing for satellite dataprocessing on high end compute clusters,” [J] in Cloud Computing, 2009.CLOUD’09. IEEE International Conference on. IEEE, 2009:88-92.
[8] Pan.X and Zhang.S, “A remote sensing image cloud processingsystem based on hadoop,” [J] in Cloud Computing and Intelligent Systems(CCIS), 2012 IEEE 2nd International Conference on, vol. 1. IEEE,2012, pp. 492-494.
[9] Grossman M, Breternitz M, Sarkar V. HadoopCL: MapReduce on Distributed Heterogeneous Platforms through Seamless Integration of Hadoop and OpenCL[J]. Parallel and Distributed Processing Symposium Workshops & PhD Forum (IPDPSW), 2013 IEEE 27th International, 2013:1918-1927.
[10] Wang Z, Lv P, Zheng C. CUDA on Hadoop: A Mixed Computing Framework for Massive Data Processing[M]//Foundations and Practical Applications of Cognitive Systems and Information Processing. Springer Berlin Heidelberg,2014:253-260.
[11] Zaharia.M, Chowdhury.M, M. J. Franklin, S. Shenker, and I. Stoica,“Spark: cluster computing with working sets,” [C] in Proceedings of the2nd USENIX conference on Hot topics in cloud computing, 2010:10.
[12] Ghemawat S, Gobioff H, Leung S T. The Google file system[C]//ACM SIGOPS operating systems review. ACM, 2003, 37(5):29-4
V249 文獻標志碼:A
2015.01.21)
1007-757X(2015)08-0065-03
國家自然科學基金,(71331005)
陳峰科(1990-),男,江西,復旦大學計算機科學技術學院,上海市數據科學重點實驗室,碩士研究生,研究方向:數據科學、大數據上海,201203孫眾毅(1992-),男,上海,復旦大學計算機科學技術學院,上海市數據科學重點實驗室,碩士研究生,研究方向:數據科學、大數據,上海,201203池明旻(1977-),女,福建,復旦大學計算機科學技術學院,上海市數據科學重點實驗室,電磁波信息科學教育部重點實驗室,副教授,研究方向:數據科學、大數據, 上海,201203
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
