特征融合在微博數(shù)據(jù)挖掘中的應(yīng)用研究
2015-08-17 05:30:12王和勇
現(xiàn)代情報 2015年5期
王和勇 洪 明
(華南理工大學(xué)電子商務(wù)系 ,廣東 廣州510006)
特征融合在微博數(shù)據(jù)挖掘中的應(yīng)用研究
王和勇洪明
(華南理工大學(xué)電子商務(wù)系 ,廣東 廣州510006)
針對傳統(tǒng)的微博聚類分析中,只單獨針對微博閱讀數(shù)、評論數(shù)等數(shù)據(jù) (下稱微博結(jié)構(gòu)化數(shù)據(jù))進行分類或者單獨針對由微博內(nèi)容進行文本分詞得到的分詞數(shù)據(jù) (下稱微博分詞)進行分類的問題,本文采用了Kohonen聚類,研究結(jié)合微博結(jié)構(gòu)化數(shù)據(jù)和微博分詞的融合數(shù)據(jù)聚類的效果是否比單獨對微博結(jié)構(gòu)化數(shù)據(jù)或?qū)ξ⒉┓衷~聚類有所提高。實證數(shù)據(jù)實驗結(jié)果顯示 ,微博結(jié)構(gòu)化數(shù)據(jù)單獨聚類會出現(xiàn)一個類的標準差特別大 (本文稱為離群類),而對融合數(shù)據(jù)聚類 ,微博結(jié)構(gòu)化數(shù)據(jù)則不會出現(xiàn)離群類;融合數(shù)據(jù)聚類結(jié)果對微博分詞的影響不顯著。
微博 ;聚類;融合數(shù)據(jù)
微博是當今流行的信息發(fā)布和交流的工具,微博蘊含著大量的信息資源,成為數(shù)據(jù)分析的重要數(shù)據(jù)來源。微博數(shù)據(jù)可以分為兩類 ,一類是結(jié)構(gòu)化數(shù)據(jù),微博的用戶名、閱讀數(shù)、轉(zhuǎn)播數(shù)、發(fā)表日期等微博相關(guān)的信息 (下稱 “微博結(jié)構(gòu)化數(shù)據(jù)”);另一類是非結(jié)構(gòu)化數(shù)據(jù)即微博用戶發(fā)表微博內(nèi)容的文本數(shù)據(jù) (下稱 “微博內(nèi)容”)。
在微博研究中,往往需要對微博數(shù)據(jù)進行分類以發(fā)現(xiàn)某些數(shù)據(jù)間有趣的規(guī)律和模式。而從微博中收集的現(xiàn)實數(shù)據(jù)往往沒有預(yù)先定義的分類 ,由于微博數(shù)據(jù)龐大 ,無法進行手工分類,必須采用一些分類方法進行處理。由于微博非結(jié)構(gòu)化數(shù)據(jù)都是經(jīng)過文本分詞轉(zhuǎn)化為結(jié)構(gòu)化數(shù)據(jù)進行有關(guān)分類研究,由微博內(nèi)容轉(zhuǎn)化成的結(jié)構(gòu)化數(shù)據(jù)下文稱為“微博分詞”。
文獻中,馬彬、洪宇、陸劍江、姚建民和朱巧明(2012)利用線索樹雙層聚類過濾垃圾微博,進而實現(xiàn)微博話題檢測 (微博分詞聚類)[1];張國安和鐘紹輝 (2012)分析用戶數(shù)據(jù),利用K均值聚類研究微博用戶分類 (微博結(jié)構(gòu)化數(shù)據(jù)聚類)[2];路榮、項亮、劉明榮和楊青 (2012)利用兩層K均值和層次聚類的混和聚類方法對微博文本進行聚類從而檢測出新聞話題 (微博分詞聚類)[3];潘大慶(2012)利用層次聚類以敏感話題為單位對微博進行分類(微博分詞聚類)[4];熊祖濤 (2013)基于文本稀疏性問題,描述了多種微博文本聚類的方法 (微博分詞聚類)[5];英文文獻中,Yang C,Ding H,Yang J等 (2012)利用K-均值聚類算法發(fā)現(xiàn)微博中的用戶社區(qū) (微博分詞聚類)[6];Olariu A.(2013)利用層次聚類對Twitter的文本進行分類從而提高微博流匯總算法的有效性(微博分詞聚類)[7];Muhammad Atif Qureshi,Colm O'Riordan,Gabriella Pasi(2013)利用聚類分析來檢測Twitter上公司的聲望 (微博分詞聚類)[8];Huang B、Yang Y、Mahmood A等 (2013)利用單遍聚類方法來發(fā)現(xiàn)微博話題 (微博分詞聚類)[9];Elena Baralis、Tania Cerquitelli、Silvia Chiusano等 (2013)對Twitter同一話題發(fā)表內(nèi)容的用戶進行聚類以發(fā)現(xiàn)相似的群組 (微博分詞聚類)[10]。目前的文獻都只是單獨針對微博結(jié)構(gòu)化數(shù)據(jù)或者單獨針對微博分詞進行聚類分析,得到一個分類,本文將微博結(jié)構(gòu)化數(shù)據(jù)和微博分詞結(jié)合起來形成融合數(shù)據(jù),研究對融合數(shù)據(jù)進行聚類的分類效果是否比單獨對微博結(jié)構(gòu)化數(shù)據(jù)或微博分詞聚類的分類效果有所優(yōu)化。
通過軟件抓取騰訊微博 “房價”話題的數(shù)據(jù) ,首先提取出用戶名,閱讀數(shù)等微博結(jié)構(gòu)化數(shù)據(jù)和微博內(nèi)容的文本 ,對微博內(nèi)容的文本進行文本分詞形成微博分詞,然后將微博結(jié)構(gòu)化數(shù)據(jù)和微博分詞結(jié)合形成包含微博結(jié)構(gòu)化數(shù)據(jù)和微博分詞的融合數(shù)據(jù)。聚類實驗部分分別進行對微博結(jié)構(gòu)化數(shù)據(jù)、微博分詞和融合數(shù)據(jù)所有字段的Kohonen神經(jīng)網(wǎng)絡(luò)聚類分析,通過字段聚類后的標準差比較聚類結(jié)果的相對好壞,驗證融合了微博結(jié)構(gòu)化數(shù)據(jù)和微博分詞的數(shù)據(jù)是否比單獨的微博結(jié)構(gòu)化數(shù)據(jù)和單獨的微博分詞聚類效果有所提高。
1 數(shù)據(jù)收集與整理
1.1數(shù)據(jù)搜集
本文利用軟件搜集騰訊微博2011年11月8日 -2014年2月15日話題為 “房價”的數(shù)據(jù)共2 000條。搜集來的數(shù)據(jù)是HTML形式,需要進一步的處理提取出結(jié)構(gòu)化字段和微博的文本內(nèi)容,原始數(shù)據(jù)具體的情況如表1所示。

表1 R微博原始數(shù)據(jù)
1.2數(shù)據(jù)整理
采集的數(shù)據(jù)是HTML的形式,為半結(jié)構(gòu)化的數(shù)據(jù),因此需要提取出結(jié)構(gòu)化的字段微博結(jié)構(gòu)化數(shù)據(jù)和微博的內(nèi)容。經(jīng)過閱讀THML代碼,代碼中可以提取的結(jié)構(gòu)化字段名稱,含義及格式如表2所示。

表2 R微博結(jié)構(gòu)化數(shù)據(jù)
本文使用R語言提取HTML文件中的微博結(jié)構(gòu)化數(shù)據(jù)和微博內(nèi)容。提取的過程如圖1所示。

圖1 RR提取微博結(jié)構(gòu)化數(shù)據(jù)和微博內(nèi)容
用R語言提取出的結(jié)構(gòu)化數(shù)據(jù)存儲在EXCEL表格中,去掉重復(fù)的數(shù)據(jù)。在過程中發(fā)現(xiàn)有些微博的時間是 “今天10∶10”這樣沒有確切時間的數(shù)據(jù),將其作為缺失處理,用NULL補全數(shù)據(jù),因為不清楚發(fā)表日期,所以發(fā)表時間意義不大,因此發(fā)表日期為 NULL的條目發(fā)表時刻也設(shè)為NULL。微博內(nèi)容的文本數(shù)據(jù)存儲在文本文件中。去掉了重復(fù)的數(shù)據(jù)后,現(xiàn)存的數(shù)據(jù)有1 672條,如果去掉發(fā)表時間和發(fā)表時刻為NULL的數(shù)據(jù),則剩余1 399條。
微博內(nèi)容數(shù)據(jù)存放在TXT文本文件中,每一條微博為一行。
2 非結(jié)構(gòu)化化數(shù)據(jù)處理與數(shù)據(jù)融合
2.1文本分詞
文本屬于非結(jié)構(gòu)化數(shù)據(jù),非結(jié)構(gòu)化數(shù)據(jù)利用現(xiàn)有的技術(shù)無法直接處理,因此需要將文本轉(zhuǎn)化為結(jié)構(gòu)化數(shù)據(jù)。根據(jù)一個文本中詞語的意義將文本劃分為一個一系列的有意義的詞的向量并統(tǒng)計每個有意義詞在一個文本中出現(xiàn)的次數(shù)即詞頻,這樣就將一個文本有非結(jié)構(gòu)化數(shù)據(jù)轉(zhuǎn)化為結(jié)構(gòu)化數(shù)據(jù)。有意義的詞是字段,詞頻是字段的值。非結(jié)構(gòu)化文本數(shù)據(jù)轉(zhuǎn)化為結(jié)構(gòu)化數(shù)據(jù)的轉(zhuǎn)化過程如圖2所示。

圖2 RR文本數(shù)據(jù)轉(zhuǎn)化為結(jié)構(gòu)化數(shù)據(jù)過程
語料庫是匯總非結(jié)構(gòu)化文本 ,一個文檔就是一個獨立的文本,本文把每一條微博內(nèi)容作為一個文檔,文本庫是在語料庫的基礎(chǔ)上去掉了停用詞,數(shù)字等無用信息的非結(jié)構(gòu)化純文本,而且初始的非結(jié)構(gòu)化文本可能是HTML,XML等文件,因此由語料庫轉(zhuǎn)化為文本庫是必要的。文檔詞條矩陣是將每一個文檔分詞 ,然后統(tǒng)計每個文檔中詞條 (即前文說的有意義的詞)的詞頻,形成的一個以文檔為行,詞條為列的矩陣。文檔詞條矩陣是非結(jié)構(gòu)化文本的結(jié)構(gòu)化表現(xiàn)形式。
本文以R語言的tm包為基礎(chǔ),構(gòu)建語料庫和文本庫以及文檔詞條矩陣,使用Rwordseg包分詞。
2.2文本分詞實驗
利用本文數(shù)據(jù)和R語言進行文本分詞的過程如圖3所示。
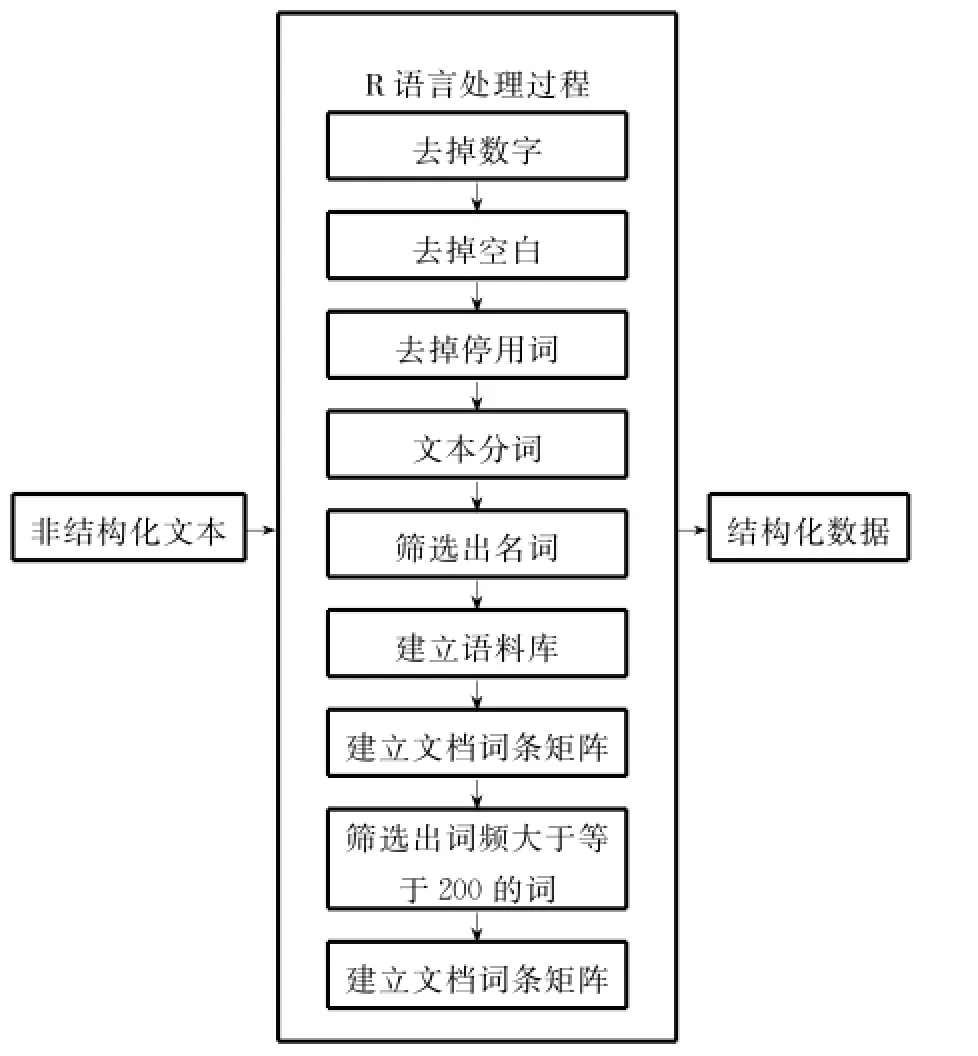
圖3 RRR語言文本分詞過程
在建立結(jié)構(gòu)化數(shù)據(jù)的過程中,對分詞進行了兩次篩選,第一次是篩選出分詞中的名詞,因為名詞的意義比較大 ,含義比較豐富。第二次是根據(jù)文檔詞條矩陣篩選出了詞頻大于200的詞,因為建立的矩陣稀疏,而且有些詞的詞頻很小,很難有代表性,因此人為選擇詞頻大于200的分詞。實驗過程中提取出詞頻100以上,200以上,300以上,400以上和500以上的詞。
實驗中發(fā)現(xiàn),詞頻大于100的詞太多,會導(dǎo)致文檔詞條矩陣過于稀疏,不利于進一步實驗,詞頻大于200的詞數(shù)量比較適中,而選擇詞頻大于300的詞數(shù)量稀少,因此選擇詞頻大于200的詞。在詞頻大于200的詞中,有些詞跟房價的關(guān)聯(lián)性不大,因此進一步人為篩選,人工去掉“價”,“房價”,“錢”,“人”,“問題”,“新聞”和 “中國”去掉,這些詞語跟房價沒有太大的關(guān)聯(lián)性。因此 ,整理后的微博文本結(jié)構(gòu)化數(shù)據(jù)的字段即微博分詞如表3所示。
2.3數(shù)據(jù)融合
在原來的結(jié)構(gòu)化數(shù)據(jù)的基礎(chǔ)上 ,把微博分詞融合到微博結(jié)構(gòu)化數(shù)據(jù)當中,形成一個新的數(shù)據(jù)表,該數(shù)據(jù)表的字段匯總?cè)绫?所示。

表3 R微博分詞字段

表4 R融合數(shù)據(jù)字段
3 Kohonen神經(jīng)網(wǎng)絡(luò)聚類實驗
3.1Kohonen神經(jīng)網(wǎng)絡(luò)聚類簡介
Kohonen神經(jīng)網(wǎng)絡(luò)聚類的原理大致是:當一條數(shù)據(jù)輸入到輸入層,輸入層將數(shù)據(jù)項的變量特征作為刺激信號傳遞給輸出層,輸出層中對該信號最為敏感的節(jié)點 “獲勝”,作為最能解釋該數(shù)據(jù)項的節(jié)點。對每條數(shù)據(jù)進行相同的操作,最后輸出層形成一個二維的結(jié)構(gòu),即是聚類的輸出結(jié)果。
Kohonen神經(jīng)網(wǎng)絡(luò)聚類的過程如下:
3.1.1確定聚類的初始中心
設(shè)有p個輸入節(jié)點,則在時刻 t第j個輸出節(jié)點和p個輸入節(jié)點的中心Wj(t)為:
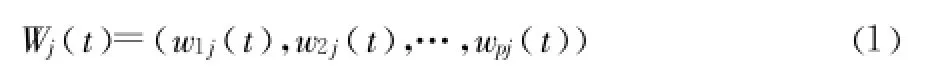
其中,w1j(t)(i=1,2,3,…,p)是連接的權(quán)值。剛開始時權(quán)值是隨機的,因此,剛開始的聚類中心也是隨機的。
3.1.2確定獲勝節(jié)點
在時刻 t,一條數(shù)據(jù)X(t)到達輸入層,根據(jù)X(t)屬性計算其與類中心的歐氏距離 d(t),最后選出d(t)最小的類中心Wc(t),Wc(t)便是獲勝節(jié)點。
3.1.3調(diào)整獲勝節(jié)點及其鄰居節(jié)點的類中心位置
當Wc(t)對一條數(shù)據(jù) X(t)勝出時,Wc(t)及其鄰居節(jié)點對輸入層節(jié)點的權(quán)值需要調(diào)整 ,也就調(diào)整了類中心。調(diào)整Wc(t)類中心的方法如下:
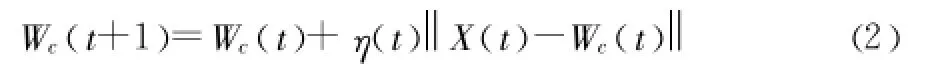
其中,η(t)表示時刻 t的學(xué)習(xí)率。
Wc(t)鄰居節(jié)點指的是以Wc(t)為圓心 ,指定半徑內(nèi)的節(jié)點,鄰居節(jié)點Wj(t)的調(diào)整方法如下:
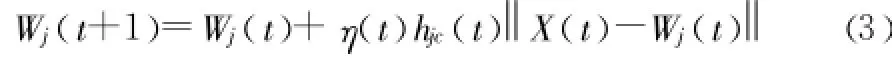
其中,hjc(t)是時刻Wj(t)和Wc(t)的距離的度量。hjc(t)的一種形式是切比雪夫距離:
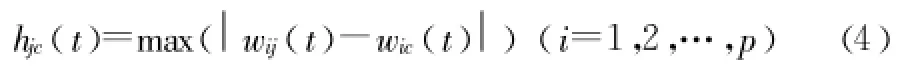
3.1.4判斷是否迭代終止
迭代終止的條件一般是權(quán)值基本穩(wěn)定或者到達預(yù)定義的迭代次數(shù),如果滿足條件,終止,否則回到第二步。
3.2Kohonen神經(jīng)網(wǎng)絡(luò)聚類實驗
本文使用SPSSClementine軟件作為實驗環(huán)境,以6種比例的訓(xùn)練集來進行實驗,分別使用50% ,60% ,70% ,80% ,90%和100%的數(shù)據(jù)進行聚類實驗。利用融合數(shù)據(jù)隨機篩選出上述比例的數(shù)據(jù),實驗時分別提取出融合數(shù)據(jù)的結(jié)構(gòu)化數(shù)據(jù),文本結(jié)構(gòu)化數(shù)據(jù)分別進行聚類實驗,最后再進行融合數(shù)據(jù)聚類實驗。實驗中剔除 “用戶名”、“發(fā)表日期”和 “發(fā)表時刻”以確保所有字段都是數(shù)字類型,使得微博結(jié)構(gòu)化數(shù)據(jù)的字段和文微博分詞的字段具有可比性。具體的實驗步驟如圖4所示。
3.3實驗結(jié)果對比分析
按照實驗步驟對各個比例的融合數(shù)據(jù)分別進行微博結(jié)構(gòu)化數(shù)據(jù)聚類,微博分詞聚類以及融合數(shù)據(jù)聚類。聚類結(jié)果顯示,在6個不同比例的訓(xùn)練集實驗數(shù)據(jù)下,微博結(jié)構(gòu)化數(shù)據(jù)聚類,微博分詞聚類,融合數(shù)據(jù)聚類都分為12類。
評判聚類效果的方法很多,本文使用標準差來評價聚類的相對好壞,1個類中相同字段的標準差越小,說明該字段的值相差越小,也就越相似。用函數(shù) std(字段)表示在聚類結(jié)果中1個字段的12個類的標準差的匯總折線,如std(閱讀數(shù))表示一個聚類結(jié)果中閱讀數(shù)的12個類的標準差的匯總折線。比較兩組結(jié)果:微博結(jié)構(gòu)化數(shù)據(jù)聚類和融合數(shù)據(jù)聚類 ,微博分詞聚類和融合數(shù)據(jù)聚類,通過匯總折線的比較,評價聚類的效果的相對好壞,兩組比較具體的比較內(nèi)容如表所示。對于微博結(jié)構(gòu)化數(shù)據(jù)聚類,只需要把3個結(jié)構(gòu)化字段的12個類的標準差折線和融合數(shù)據(jù)聚類中對應(yīng)的字段的標準差折線分別比較,對于微博分詞數(shù)據(jù),則要比較9個字段。具體如表5所示。
圖4 RR聚類實驗過程

表5 R實驗結(jié)果比較方法
3.3.1微博結(jié)構(gòu)化數(shù)據(jù)聚類和融合數(shù)據(jù)聚類比較
將微博結(jié)構(gòu)化數(shù)據(jù)聚類結(jié)果和融合數(shù)據(jù)聚類結(jié)果中微博結(jié)構(gòu)化數(shù)據(jù)和融合數(shù)據(jù)共有的3個字段——閱讀數(shù),評論數(shù)和轉(zhuǎn)播數(shù)的12個類的標準差繪制成折線圖,選擇80%訓(xùn)練集的實驗結(jié)果展示如下 ,其他比例下的訓(xùn)練集實驗結(jié)果類似 (fusion表示融合數(shù)據(jù),structured表示微博結(jié)構(gòu)化數(shù)據(jù)數(shù)據(jù))。
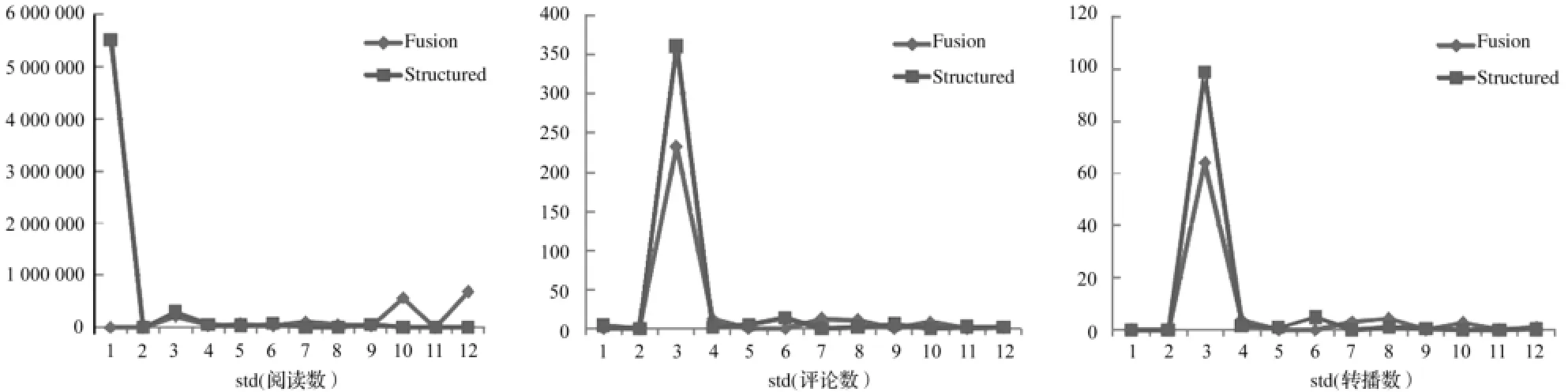
圖5 RR80%實驗數(shù)據(jù)3個字段的比較
從圖5可以看出,微博結(jié)構(gòu)化數(shù)據(jù)聚類的結(jié)果往往出現(xiàn)一個這樣一個類,類中3個字段的標準差都很大,偏離平均水平很多,本文稱為 “離群類”。而融合數(shù)據(jù)的結(jié)果則能夠縮小離群類和其他類的差異性。微博結(jié)構(gòu)化數(shù)據(jù)的字段融入微博分詞聚類以后,能夠把 “離群類”的標準差的差異分攤到其他類,從而把 “離群類”拉回平均水平附近 ,這樣的代價是其他類的標準差會有所增加,但是整體的聚類效果得到提升,因為聚類中 “離群類”的與其他類的差異性變小,其他類的標準差影響不大。
3.3.2微博分詞聚類和融合數(shù)據(jù)聚類比較
將微博分詞聚類結(jié)果和融合數(shù)據(jù)聚類結(jié)果中共有的9個字段的12個類的標準差繪制成折線圖 ,選擇80%訓(xùn)練集的實驗結(jié)果展示如下,其他比例下的訓(xùn)練集實驗結(jié)果一致(Fusion表示融合數(shù)據(jù),Non-structured表微博分詞)。
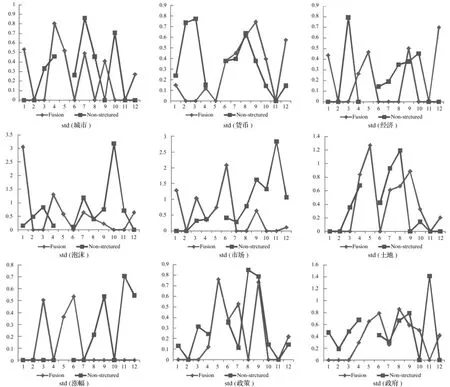
圖6 RR80%實驗數(shù)據(jù)9個字段的比較
從圖6可以看出,融入微博結(jié)構(gòu)化數(shù)據(jù)的字段聚類后,微博分詞字段的標準差沒有明顯下降,跟微博分詞單獨聚類沒有明顯差異,因此,融合數(shù)據(jù)對微博分詞聚類沒有明顯幫助。
4 結(jié) 論
傳統(tǒng)的微博聚類分析針對微博結(jié)構(gòu)化數(shù)據(jù) (結(jié)構(gòu)化字段)分類或者微博分詞 (通過某種方法轉(zhuǎn)化為結(jié)構(gòu)化字段)分類。本文采用Kohonen神經(jīng)網(wǎng)絡(luò)聚類,研究對結(jié)合了微博結(jié)構(gòu)化數(shù)據(jù)和微博分詞 (通過某種方法轉(zhuǎn)化為結(jié)構(gòu)化字段)的融合數(shù)據(jù)聚類的效果是否比單獨對結(jié)構(gòu)化字段或文本結(jié)構(gòu)化字段聚類有所提高。從數(shù)據(jù)中提取實證數(shù)據(jù)實驗結(jié)果顯示,結(jié)構(gòu)化字段單獨聚類會出現(xiàn)一個類的標準差特別大的 “離群類”,而對融合數(shù)據(jù)聚類,結(jié)構(gòu)化字段則不會出現(xiàn) “離群類”,融合了微博分詞一起分類后,結(jié)構(gòu)化字段的 “離群類”的標準差變小,被拉近標準
差的平均水平。另一方面,融合數(shù)據(jù)聚類對微博分詞的效果不太明顯,融合了微博結(jié)構(gòu)化數(shù)據(jù)再聚類和微博分詞單獨聚類,結(jié)果不太顯著。
[1]馬彬 ,洪宇 ,陸劍江 ,等 .基于線索樹雙層聚類的微博話題檢測 [J].中文信息學(xué)報 ,2012,26(6):121-128.
[2]張國安,鐘紹輝.基于K均值聚類的微博用戶分類的研究[J].電腦知識與技術(shù),2012,8(26):6273-6275.
[3]路榮,項亮 ,劉明榮,等.基于隱主題分析和文本聚類的微博客中新聞話題的發(fā)現(xiàn) [J].模式識別與人工智能,2012,25 (3):382-387.
[4]潘大慶 .基于層次聚類的微博敏感話題檢測算法研究 [J].廣西民族大學(xué)學(xué)報 ,2012,18(4):56-59.
[5]熊祖濤.基于稀疏特征的中文微博短文本聚類方法研究 [J].軟件導(dǎo)刊,2014,13(1):133-134.
[6]Changchun Yang,Hong Ding,Jing Yang,Hengxin Xue.Mining Microblog Community Based on Clustering Analysis[C]∥Proceedings of the International Conference on Information Engineering and Applications(IEA)2012.Springer London,2013:825-832.
[7]Olariu A.Hierarchical clustering in improvingmicroblog stream summarization[M]∥Computational Linguistics and Intelligent Text Processing.Springer Berlin Heidelberg,2013:424-435.
[8]Muhammad Atif Qureshi,Colm O'Riordan,Gabriella Pasi.Clustering with Error-Estimation forMonitoring Reputation of Companieson Twitter[M]∥Information Retrieval Technology Lecture Notes in Computer Science,2013:170-180.
[9]Bo Huang,Yan Yang,Amjad Mahmood,Hongjun Wang.Microblog topic detection based on LDA model and single-pass clustering[C]∥Rough Sets and Current Trends in Computing.Springer Berlin Heidelberg,2012:166-171.
[10]Elena Baralis,Tania Cerquitelli,Silvia Chiusano,Luigi Grimaudo,Xin Xiao.Analysis of Twitter Data Using a Multiple-level Clustering Strategy[C]∥Model and Data Engineering Lecture Notes in Computer Science,2013:13-24.
[11]Jiawei Han,M icheline Kamber.數(shù)據(jù)挖掘概念與技術(shù) [M].北京 :機械工業(yè)出版社,2008:283-284.
(本文責任編輯:郭沫含)
The Study of M icroblog Data M ining Using Feature Fusion
Wang Heyong Hong Ming
(Departmentof E-Business,South China University of Technology,Guangzhou 510006,China)
This paper focused the problem that traditional clustering analysis have focused on only structured data such as microblog reading numbers andmicroblog commentnumbers(microblog segmentation)oronlymicroblog text.In thispaper,microblogmetadata are combinedwithmicroblog text to form fusion data and Kohonen Network Clustering is applied to test if fusion data clustering is better thanmicroblogmetadata clustering and thanmicroblog text clustering.Experiments indicates thatmicroblog metadata clusteringmay causea classwith large standard deviation(outlier class)and on the contrary,fusion data clustering does not.Microblog text clustering performs aswell as fusion clustering.
microblog;clustering;fusion data
王和勇 (1973-),男,提前上崗教授,研究方向:數(shù)據(jù)挖掘、文本挖掘和大數(shù)據(jù)挖掘。
10.3969/j.issn.1008-0821.2015.05.013
G250.78
A
1008-0821(2015)05-0068-05
2015-03-05
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
