基于SVM和KNN的文本分類研究
2015-08-17 05:30:14張華鑫龐建剛
現代情報 2015年5期
張華鑫 龐建剛
(西南科技大學經濟管理學院 ,四川 綿陽621000)
基于SVM和KNN的文本分類研究
張華鑫龐建剛
(西南科技大學經濟管理學院 ,四川 綿陽621000)
本文在詳細介紹文本自動分類流程的基礎上 ,通過實驗對SVM和KNN兩種算法進行比較研究,實驗結果表明 :SVM算法使用多項式核函數的分類準確性高于使用徑向基核函數的分類準確性 ,且多項式核函數的分類準確性隨著參數q的增大而提高;SVM采用多項式核函數進行分類的準確性普遍高于采用KNN的分類準確性;采用多項式核函數的SVM和KNN兩種算法對短文本的召回率高于對長文本的召回率。
文本分類 ;KNN;支持向量機 ;核函數
將文本信息進行分類能夠滿足人們在海量數據中查找數據的需求,但是隨著網絡技術的高速發展與廣泛應用,電子文本信息呈級數增長,用人工方式對文本進行分類將是一項繁重的工作,因此需要借助計算機對文本進行自動分類。20世紀50年代末,H.P.Lunhn首次在該領域提出將詞頻統計思想用于文本自動分類的研究。20世紀90年代以后,研究者將機器學習算法用于文本自動分類,主要的機器學習算法有決策樹 (Decision Tree)、Rocchio算法、KNN算法和支持向量機 (Support Vector Machine,SVM)等。錢慶等[1]將KNN算法應用于醫藥衛生體制改革輿情監測系統中,構建了醫藥衛生體制改革主體模型,利用該模型能夠有效提高醫藥衛生體制改革輿情監測系統主題信息自動獲取、自動分類的效率,但是該模型在進行特征加權的時候采用的是TF-IDF方法,該方法的缺點在于低估了在一個類中頻繁出現的詞條,這樣的詞條能夠代表這個類的文本特征的,應該賦予其較高的權重而不是與其他詞語同等對待。牛強等[2]在Web文本分類中引入KNN算法,利用 χ2統計量作為特征選擇評分函數,盡管該方法能夠取得不錯的分類效果 ,在一定程度上滿足Web知識的需求,但是該方法在對類別差異不大的類別的識別能力較弱。張愛麗等[3]利用SVM算法構造多類別的識別器,該分類器能較好地把大類別分類問題,有效地轉化為小類別識別問題的組合 ,降低錯誤識別率。上述研究都側重于單一使用KNN算法或SVM算法 ,沒有對兩種算法進行橫向比較 ,本文著重通過實驗比較KNN和SVM兩種算法在中文文本分類中的性能差異。
1 文本預處理
1.1中文分詞
由于中文句子的詞與詞之間沒有空格,因此在進行文本分類的時候首先需要把句子分割成詞語。現有的中文分詞算法主要分為四大類:基于字符串匹配的分詞方法、基于理解的分詞方法、基于統計的分詞方法和基于語義的分詞方法。
1.2文本表示
文本信息是非結構化數據,因此需要用數學模型把文本數據表示為計算機能夠處理的形式。常用的文本表示模型有布爾邏輯、概率模型 ,向量空間模型。其中向量空間模型是應用較多且效果很好的模型。本文采用向量空間模型表示文本。向量空間模型的基本思想是將文本 di映射為空間中的一個特征向量V(di),V(di)={(ti1,wi1),(ti2,wi2),…,(tin,win)},其中 tik為文檔di第k個特征項 ,wik為文檔di第k個特征項對應的權重。本文采用TF-IDF方法作為特征加權的方法。TF-IDF方法的基本思想是:如果一個特征在特定的文本中出現的頻率越高,說明它區分該文本內容屬性的能力越強;如果一個特征在文本中出現的范圍越廣,即該特征等概率出現在各個類別中,說明該特征區分內容屬性的能力越低。
TF-IDF權重計算公式如下:
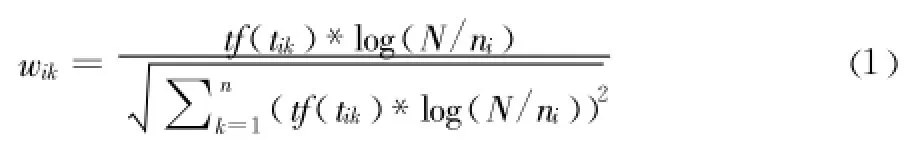
其中 ,tf(tik)表示特征項 tik出現在文檔di中的頻數 ,N為文本總數,ni為訓練集中出現tik的文檔數。
但是該方法的缺陷在于如果一個詞條在一個類的文檔中頻繁出現,則說明該詞條能夠很好代表這個類的文本的特征,這樣的詞條應該給它們賦予較高的權重,以此區別與其它類文檔。本研究在計算特征項的時候引入條件概率 ,改進后TF-IDF公式如下:表示文檔 d中出現特征項tik時該文檔屬于Ci的概率,從改進的公式可以看出如果某一個類 Ci中包含詞條tik的文檔數量大,而在其它類中包含詞條 t的文檔數量小的話,則 tik能夠代表Ci類的特征,該公式賦予該特征較高的權重。
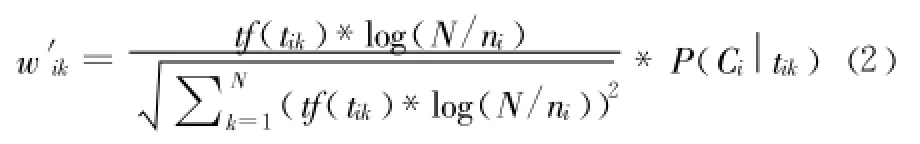
2 特征降維
一篇文檔進行分詞之后,特征項的維數一般在幾萬維以上,而大多數的特征項是冗余的或者不相關的,如何在保持分類準確率變化不大的前提下降低特征維數是文本分類研究的一個重點領域。常用的特征選擇算法包括交互信息、χ2統計量、文檔頻率、幾率比、信息增益、期望交叉熵等。
信息增益是一種有效的特征算法。Wang Bin等[4]通過實驗比較了幾率比、文檔頻率、信息增益3種特征選擇算法 ,結果表明信息增益相比前兩種算法能夠提取最優特征子集。本文實驗采用信息增益作為特征選擇方法,現將信息增益定義如下:
定義1:信息增益 (IG,Information Gain)是某一特征在文本中出現前后的信息熵之差。計算公式如下所示:
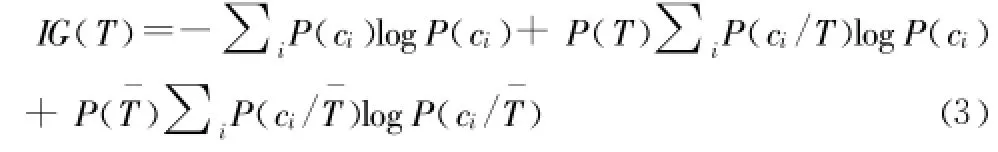
定義中 i表示類別總數,P(ci)表示類別 ci在所有文檔中出現的概率,P(T)表示特征 T在文檔中出現的概率,P(ci/T)表示當文檔中包含特征 T時屬于類別ci的概率,P(ˉT)表示文檔中不包含 T時的概率,P(ci/ˉT)表示文檔中不包含特征 T時屬于類別ci的概率。
在進行特征選擇時,一般設置一個閾值,剔除信息增益 (IG)的值小于閾值的特征項,保留大于閾值的特征值作為特征項。代六玲等[5]通過實驗表明在保持準確率變化很小的前提下可以保留原始特征空間維數的10%~20% ,剔除80%~90%的特征項。
3 文本分類算法
3.1支持向量機
支持向量機 (Support Vector Machine,SVM)是Vapnik 于20世紀90年代提出一種基于統計學習理論的分類算法。因為SVM算法是建立在統計學習理論VC維理論和結構風險最小化原理基礎上的一種新機器學習方法 ,該算法在解決小樣本、非線性和高維模式識別問題中表現出許多特有的優勢 ,并在很大程度上克服了 “維數災難”和 “過學習”等問題,1998年,Joachims率先將Vapnik提出的支持向量機 (Support Vector Machine,SVM)引入到文本分類中,并取得了不錯的效果。對于兩分類情況,SVM的基本思想可以用圖1來說明,空心點和實心點分別表示不同的類別,H為分割超平面,H1和 H2分別表示各類中離分割超平面最近且平行的平面。H1和 H2上的點被稱作支持向量,H1和 H2之間的間距被稱為分類間隔 (Margin)。最優分割超平面就是要求在正確分開不同類別的前提下 ,分類間隔最大 (Margin)。
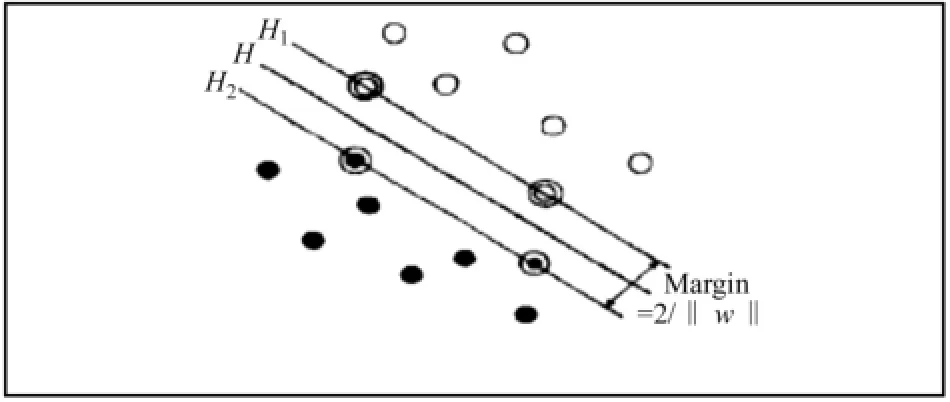
圖1 RR最優分割超平面簡圖
假設線性分類平面的形式為:

其中 w是分類權重向量,b是分類閾值。將判別函數進行歸一化處理,使判別函數對于兩類樣本都滿足,即
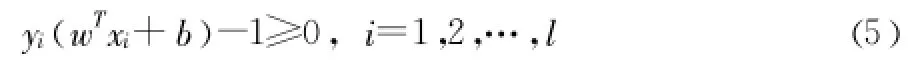
其中yi是樣本的類別標記,xi是相應的樣本。
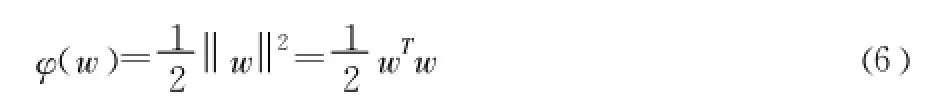
引入拉格朗日乘子 αi,根據Karush-Kuhn-Tucker (KKT)條件 ,上述問題可以轉化為在約束條件 (7)下使泛函w(α)最大化,泛函 w(α)的表達式如 (8)所示。
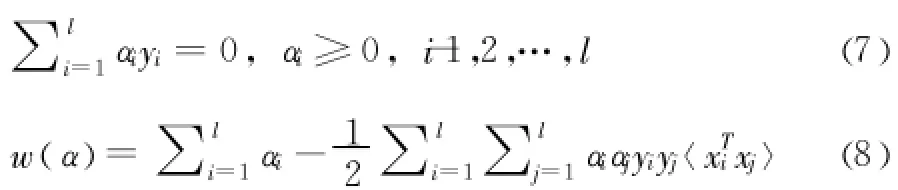
二次規劃可以求得αi,將αi帶入 (9)求得w

選擇不為零的αi,帶入 (10)中求得 b。

通過推導,決策函數變為以下式子
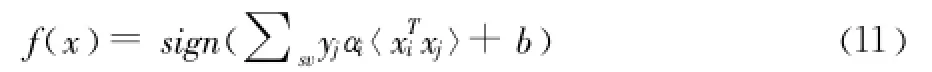
把測試樣本帶入 (11)中,如果f(x)=1則屬于該類,否則不屬于該類。
3.2KNN算法
KNN算法是Cover和Hart于1968年提出一種基于統計的學習方法。該算法的基本思想是先把文檔用向量空間表示出來,當對一篇待分類文檔進行分類時,將這篇文檔與訓練集中所有文檔進行相似度計算,然后把計算結果按降序進行排列,選取結果靠前K篇文檔,最后統計這 K篇文章所屬的類別,將所屬文章最多的類別作為待分類文檔的類別。
本文采用夾角余弦計算文本之間的相似度,KNN算法計算步驟如下:
(1)在文本分類訓練階段,把訓練集中的文本用向量空間模型表示為特征向量。
(2)將待分類樣本 di表示成和訓練集中文本一致的特征向量。
(3)根據夾角余弦公式計算待分類樣本 di和每個訓練集的距離 ,選擇與待分類樣本距離最近的 K個樣本作為di的K個最近鄰,余弦夾角公式如下所示:
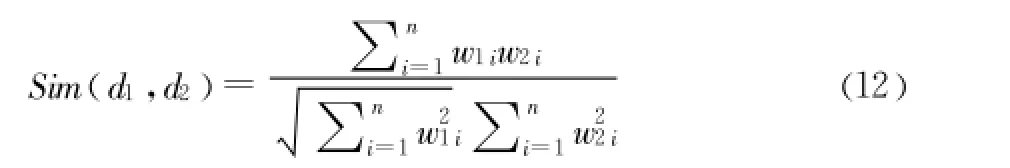
其中 ,w1i、w2i分別為文檔d1,d2向量中第 i個特征的權重值 ,Sim(d1,d2)的值越大說明兩個文本的相似度程度越高。
(4)統計每個類別所屬的文章數。
(5)將所屬文章最多的類別作為待分類文檔的類別
KNN算法的優點:該算法無須知道各個特征值的分布 ,并且該算法構建方法簡單,易于實現。
KNN算法的缺點:因為該算法是懶惰的學習算法,對兩個文本進行相似度計算的時候開銷比較大 ,分類速度不是特別理想。
總體而言,KNN算法在文本分類領域得到廣泛應用,并且KNN算法是目前眾多文本分類算法中分類效果較理想的算法之一。
4 文本評估方法
本文使用準確率、查全率和綜合考慮準確率和查全率的綜合分類率F1作為文本分類性能的評價指標[6]。準確率是指在分類器判定屬于類別 Ci中 ,確實屬于類別 Ci的文檔數所占比例,其公式表示如下:

查全率是指分類器正確分類的文本占原本屬于類別 Ci的文檔數的比例,其公式計算如下:

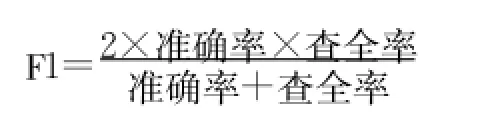
準確率和查全率反映了分類質量的兩個不同指標,兩者必須綜合考慮,不可偏廢,因此用綜合分類率F1綜合考慮準確率和查全率,其計算公式如下:
5 實驗結果與分析
本實驗使用Visual Studio 2013作為編程開發環境,采用ICTCLAS漢語分詞系統進行分詞,隨機的從復旦中文語料庫中選取Education、Agriculture、Economy、Politics 4類樣本各120篇,其中60篇作為訓練集、60篇作為測試集 ,4個類別的數據大小分別為70.8KB、706KB、825KB、1044KB,采用信息增益作為評分函數對文本進行特征選擇。
SVM核函數分別采用多項式核函數和徑向基核函數,多項式核函數的形式為K(x,xi)=[(x*xi)+1)]q,多項式核函數只有一個參數 q,當采用不同的 q時,文本分類的性能有所波動 ,另外隨著參數 q的增加,其訓練所需的時間也隨之增加,本實驗多項式的參數 q分別取為2、3、 4;徑向基核函數的形式為徑向基核函數中,也只有一個核參數 σ(在實驗中我們取的值),σ所代表的是徑向基的寬度 ,它反映了函數圖像的寬度,σ越小,寬度越窄,函數越具有選擇性,本實驗 σ2取0.01、0.09、0.6。SVM分別使用多項式核函數和徑向基核函數進行分類之后的結果如表1所示。KNN算法的 K值選擇為8,KNN分類結果如表2所示。
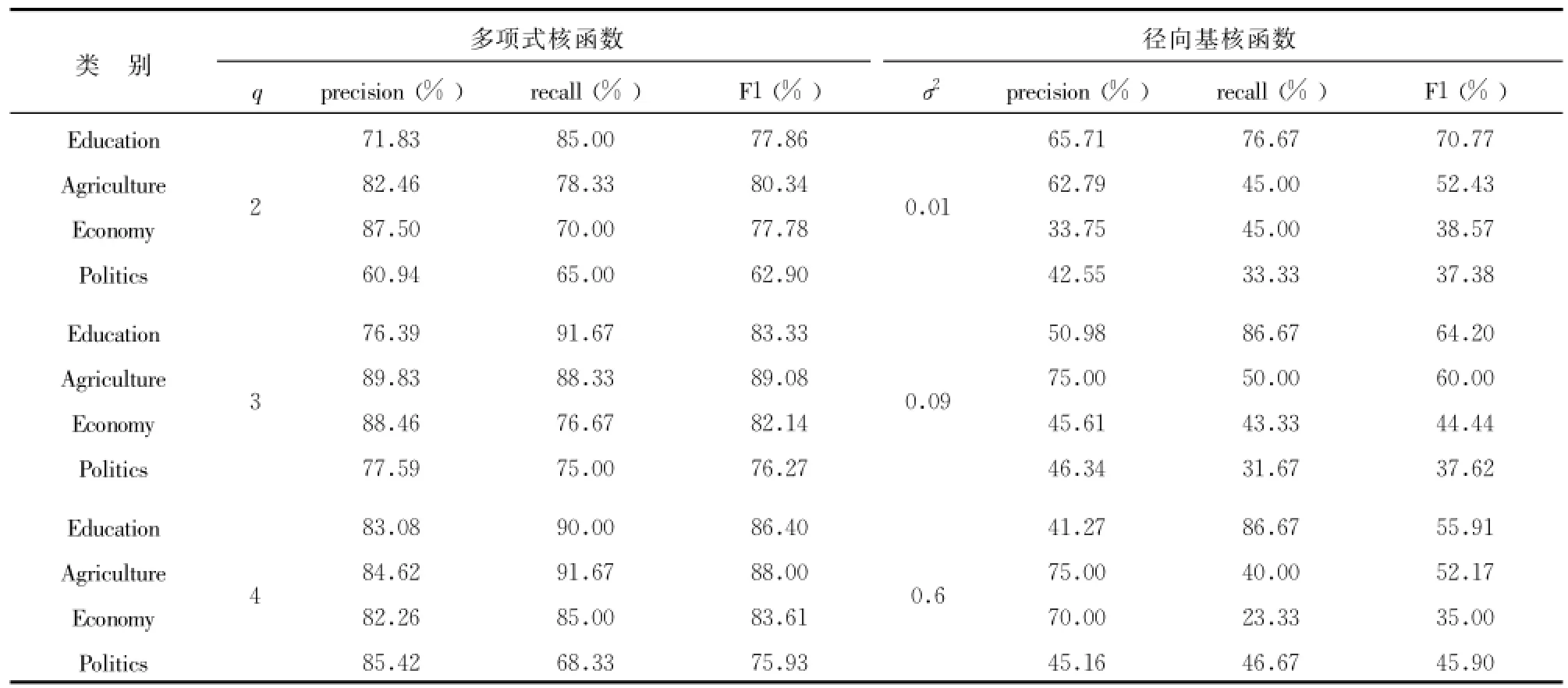
表1 RRSVM分類結果
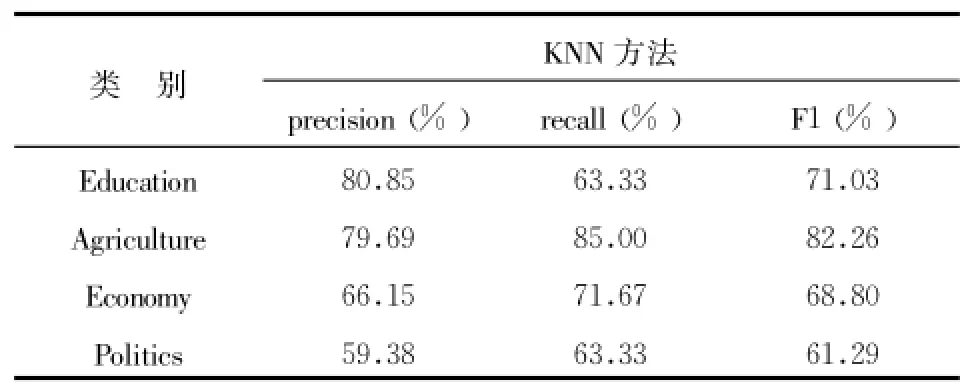
表2 RRKNN分類結果
由表1可知采用不同的核函數對于支持向量機的分類效果影響非常明顯,當使用多項式核函數時最高的分類準確率達到89.83%,最高的召回率達到91.67%,而采用徑向基函數時最高的分類準確率僅為65.71%,最高的召回率為86.67%,并且可以從表中明顯看出 ,支持向量機使用徑向基函數進行分類的效果非常不明顯,達不到人們預期的效果。因此當選擇支持向量機作為分類算法時,采用什么樣的核函數,核函數選擇什么樣的參數對于分類至關重要。
由表1、表2的實驗結果可見,當SVM選擇多項式作為核函數時,查全率、準確率、F1三個評價指標普遍高于采用傳統KNN分類之后的結果。
筆者分析可能有以下幾個原因:(1)支持向量機算法能夠將數據映射到高維空間,當數據映射到高維空間之后 ,就可以對原始空間不能線性分類的樣本進行分類,這就降低了樣本被誤分的概率 ;(2)本實驗沒有選擇合適數量的訓練樣本數量,因為如果訓練樣本過小,在測試階段出現的特征詞將不會出現在訓練階段選擇的特征項當中 ,但是如果訓練樣本過大,將會出現 “過學習”的現象,因此后期將會對樣本數量對兩種算法分類性能的影響進一步深入研究;(3)越靠近訓練樣本的測試樣本應該給予較重的權重 ,但是本實驗采用傳統的KNN算法,該算法給予前K個最近鄰同樣的權重 ,因此有必要對前 K個最近鄰樣本賦予不同的權重 ,且前 K個最近鄰樣本的權重進隨著距離的增大單調遞減。
傳統觀念認為小類別的信息量無法與大類別抗衡,其信息容易淹沒在大類別中 ,導致小類別文檔被大量誤分,通過本實驗結果可以發現在準確率相差不大的前提下,采用多項式核函數的SVM算法和KNN算法對于數據量最小的Education(70.8KB)分類的召回率和F1兩個指標均高于對數據量最大的Politics(1 044KB)進行分類之后的召回率和F1。通過查看訓練集和測試集的原始文本,Education類別的文檔長度普遍少于其他3個類別。很有可能是長文本包含了大量與類別無關的信息 ,從而導致類別相關的詞語被無關信息所淹沒,而在進行短文本編輯的時候,作者會選擇與類別最相關的詞進行寫作,因此在進行分類的時候 ,短文本的分類準確率高于長文本。
7 結 語
本文通過對SVM和KNN算法進行文本分類性能比較研究,核函數是影響SVM分類效果的一個重要因素,當SVM選擇多項式作為核函數時,分類的準確度優于KNN分類算法,同時本實驗發現兩種算法對短文本的分類準確率均高于對長文本的分類準確率。針對研究存在的不足,后期準備在以下3個方面進行改進:(1)針對常用的徑向基核函數和多項式核函數各自存在的優缺點,將二者結合構造新的核函數,并嘗試構建適合文本分類的核函數;(2)對KNN的算法的前 K個近鄰賦予不同的權重;(3)研究如何克服類別樣本數據量分布不均勻對分類準確率的影響。
[1]錢慶,安新穎 ,代濤.主體追蹤在醫藥衛生體制改革輿情監測系統中的應用 [J].圖書情報工作 ,2011,55(16):46-49.
[2]牛強,王志曉 .基于KNN的Web文本分類的研究 [J].計算機應用與軟件 ,2007,24(10):210-211.
[3]張愛麗 ,劉廣利 ,劉長宇 .基于SVM的多類文本分類研究[J].情報雜志 ,2004,(9):6-10.
[4]Wang Bin,JonesG JF,Pan Wen Feng.Using online Linear classifier to filter span emails[J].Pattern Analysis&Application,2006,(9):339-351.
[5]代六玲,黃河燕,陳肇雄 .中文文本分類中特征抽取方法的比較研究 [J].中文信息學報,2004,18(1):26-32.
[6]胡濤,劉懷亮 .中文文本分類中一種基于語義的特征降維方法[J].現代情報 ,2011,31(11):46-50.
[7]張小艷,宋麗平.論文本分類中特征選擇方法 [J].現代情報 ,2009,29(3):131-133.
[8]Cortes C,Vapnik V.Support-Vector Networks[J].Machine Learning,1995,(20):273-297.
[9]卜凡軍 ,錢雪忠 .基于向量投影的KNN文本分類算法 [J].計算機工程與設計 ,2009,30(21):4939-4941.
[10]趙輝.論文本分類中特征選擇方法[J].現代情報 ,2013,33(10):70-74.
[11]Sebastiani F.Machine learning in automated text categorization[J]. ACM Computing Surveys,2002,34(1):1-47.
[12]侯漢清.分類法的發展趨勢簡論 [M].北京 :中國人民大學出版社,1981.
[13]G.Salton.Introduction to Modern Information Retrieval.McGraw-Hill,1983.
(本文責任編輯:孫國雷)
Research on Text Classification Based on SVM and KNN
Zhang Huaxin Pang Jiangang
(College of Economy and Management,Southwest University of Science and Technoloy,Mianyang 621000,China)
This papermade a comparison between SVM and KNN on text classification after illustrating the procedures in text classification.The experimental results showed that the accuracy of SVM by using Polynomial kernel function is higher than thatby using Radial Basis function,besides,theaccuracy of the former increaseswhen the parameterq getsbigger;theaccuracy of SVM by using Polynomial kernel function isgenerally higher than thatby using KNN;the accuracy of SVM and KNN both have higher recallof short text than long text.
text-classification;KNN;SVM;kernel-function
張華鑫 (1991-),男,情報學碩士研究生,研究方向:數據挖掘、競爭情報。
10.3969/j.issn.1008-0821.2015.05.014
TP301.6
A
1008-0821(2015)05-0073-05
2014-12-02
本文系四川省社科基金項目 “產業技術創新戰略聯盟知識共享機制研究”(批準號 :SC13E012)和四川省教育廳項目 “眾包式網絡社區大眾協同創新項目”(批準號:12SB0258)研究成果之一。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
