基于WEB新聞內容的信息抽取方法研究
2015-08-30 02:41:26沈娜
江科學術研究 2015年3期
沈 娜
(宿遷開放大學,江蘇 宿遷 223800)
基于WEB新聞內容的信息抽取方法研究
沈 娜
(宿遷開放大學,江蘇 宿遷 223800)
伴隨著互聯網的飛速發展,網絡上的信息資源呈現出井噴態勢,如何從海量的信息中抽取出自己需要的信息已經變得越發的困難。在研究網頁結構特性、分析HTMLDOM樹結構的基礎上,設計了一種基于文本標簽屬性的Web新聞信息抽取模型,針對由網頁腳本動態生成的內容的抽取,設計了一種腳本動態生成的網頁信息抽取模型。主要對兩種Web信息抽取技術的算法模型進行了描述,給出了信息抽取的具體實現過程,并選取了主流的新聞網站進行了抽取實驗,驗證了算法的可行性。
HTMLDOM樹;文本標簽屬性;Web新聞;信息抽取
互聯網的飛速發展使得WWW成為一個龐大的信息空間,為人們提供著豐富的信息資源。大量的信息資源通常是以網頁的形式呈現出來,網頁中存在著大量與我們所關注的內容無關的信息,如廣告信息、版權信息以及導航條等等,這些我們稱之為“網頁噪音”,通常以鏈接導航的形式出現在主題內容周圍或者主題內容的中間,這些“噪音”嚴重影響著人們對于信息的準確獲取,如何從網頁中抽取出正文內容,避開一些不相干的信息干擾,已經成為WEB智能領域中的一個重要課題。
1 H T ML簡介
HTML(HyperText Markup Language)是一種超文本標記語言,也是構成網頁文檔的主要語言,主要用來描述一些結構化的信息,HTML不需要編譯就可以在瀏覽器直接顯示出來,它提供了一種結構化文檔的創建方法,通過定義一套標簽來描述網頁的外觀。
以圖1所示的一個簡單HTML文件為例,HTML中的標簽可以分為以下幾類:
(1)呈現性標簽,用來描述文本的外觀。常用的標簽有〈b〉〈/b〉、〈i〉〈/i〉、〈strong〉〈/strong〉等,這類標簽中標示的通常是作者希望引起用戶注意的內容。例如:〈b〉Hello〈/b〉表示“Hello”在瀏覽器中顯示效果為粗體字;
(2)結構性標簽,用來描述文本的意圖。例如:〈body〉〈/body〉標示出HTML文檔的主體區;〈h1〉小例子〈/h1〉表示“小例子”為1級標題;〈br〉表示文檔換行;
(3)超文本鏈接標簽。例如:〈a href=”http://www.sqlele.com”〉宿遷樂樂網〈/a〉,用戶點擊“宿遷樂樂網”即可鏈接到此域名對應的頁面。
對于HTML網頁,最常用的結構表示方法是構造網頁的標簽樹,根據上面的HTML標簽,我們就可以將網頁表示成一棵樹,樹中每個節點包含了一對HTML標簽間的所有字符,節點名字即為對應的標簽名字,這也就是通常我們所說的DOM樹。HTML DOM是一種定義了訪問和操作HTML文檔的標準組件,可以將HTML文檔抽象成為由元素、屬性和文本構成的樹結構。由于HTML是一種標記語言,不能被計算機語言所獲取或編輯,我們可以通過解析HTML文檔,為HTML文檔建立一個邏輯樹模型,樹的每一個節點就是一個對象,多個這樣抽象出來的對象,就可使網頁中的元素也能夠被計算機語言所獲取和編輯。

圖1 一個簡單H T ML文件
2 基于文本標簽屬性的網頁信息抽取
通過分析研究各大新聞網站的源碼,我們發現非新聞內容通常存在于新聞正文內容區域周圍或是新聞內容區域中間,由于新聞網頁的布局結構與風格基本相似,針對某一具體新聞網站的研究發現,新聞正文的HTML標簽非常相似,非新聞內容也具有相似的HTML標簽。因此,本文設計了一種基于文本標簽屬性的信息抽取模型,由用戶或是應用程序提交一個初始的URL作為輸入,最終將過濾后的HTML網頁內容返回。該模型是建立在一個簡單的網絡爬蟲[4-6]程序的基礎上的,首先通過爬蟲獲取新聞頁面的內容,然后根據網頁文本標簽的屬性對獲取的新聞內容進行處理、過濾,從而取得最終的抽取結果。
網絡爬蟲在實現中可借助于一些網頁分析工具對網頁進行遍歷和獲取頁面中的文本內容,本文使用的是HtmlParser[7-8]分析工具。HtmlParser通過對目標網頁建立其邏輯結構,然后采用HtmlParser過濾器定位指定的HTML節點的方式實現對網頁的信息提取。
以獲取網頁新聞內容為例,主要思路是:首先獲取新聞網頁中所有的新聞標題和新聞鏈接;然后根據新聞鏈接去獲取新聞正文內容。具體的操作過程分成三步:
第一步,輸入一個URL作為一個Parser,使用這個Parser作為一個Visitor;
第二步,進行節點的遍歷,并獲取Visitor遍歷后得到的數據。這個過程主要通過
Parser.visitAllNodeWith(Visitor)語句實現,Visitor通過visitor.beginParsing()做解析之前的事情,每取到一個節點Node,都會讓該節點接受該Visitor?;
第三步,Visitor通過visitor.finishedParsing()做解析后的事情。
抽取頁面新聞鏈接的關鍵代碼如下:


由于提取新聞鏈接需要過濾掉非鏈接的部分,留下鏈接的內容,因此在做Parser時需要通過TagNameFilter filter=new TagNameFilter("A")過濾掉非鏈接的內容。由于頁面中的鏈接并非都是新聞鏈接,可能會出現廣告鏈接等一些噪音信息,需要進一步對獲取的鏈接進行過濾。
2.1 基于文本標簽屬性的信息抽取模型
基于文本標簽屬性的信息抽取模型如圖2所示,其運行的步驟描述如下:
步驟1遍歷給定的HTML網頁,分析并得到HTML頁面的所有節點;
步驟2將節點抽象成HTMLDOM樹,根據Tag進行節點類型的劃分,例如經過劃分可以得到LinkTag,ImageTag,ParagraphTag,InputTag,FrameTag等等;
步驟3分析給定網站,找出新聞正文與非新聞正文的HTML節點的屬性,根據找到的屬性定制網站,過濾掉與新聞正文無關的部分;
步驟4存儲新聞正文文本。
本模型的關鍵在于通過對特定網頁新聞正文的標簽屬性的分析,定制針對具體網頁的正文抽取算法,由于是針對具體網頁進行定制,該模型的執行正確率達到100%,缺點是定制不具有普遍適用性,針對不同的網頁都要進行分析進而獲得準確的標簽,對定制人員的要求比較高。
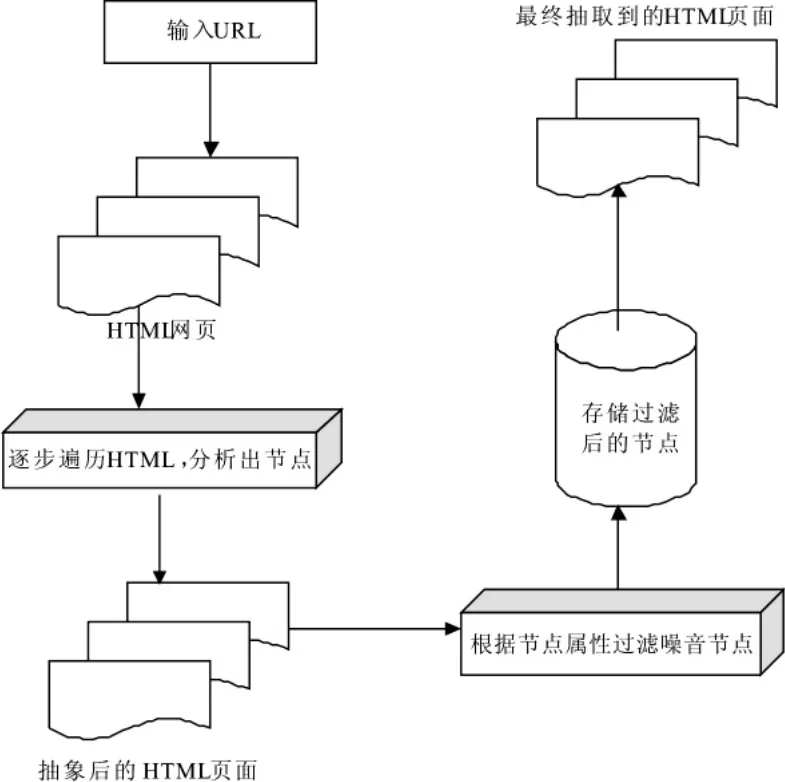
圖2 基于文本標簽的信息抽取模型
2.2 基于文本標簽屬性的信息抽取算法
該算法的核心思想是:確定要抽取的HTML標簽屬性,針對具體的網頁進行定制。實現過程中需要對網頁文檔解析樹進行分析,根據抽象HTML文檔解析樹的節點屬性,做進一步的抽取。具體的實現過程如下:
第一步,分析網頁HTML源碼[10]。
以騰訊新聞網頁為例,通過分析網頁正文,我們發現新聞正文的內容是在“〈div id="Cnt-Main-Article-QQ"bossZone="content"〉”“〈/div〉”之間,根據“Cnt-Main-Article-QQ”div標簽的id屬性就可以定位到騰訊新聞正文所在位置。但是騰訊新聞的正文中除了文本內容外,還可能存在圖片或視頻等內容,為了區分這些內容,可以再進一步分析div下面的標簽,通過分析,純文本內容是在標簽“〈P〉”“〈/P〉”之間,而圖片內容是在〈img〉標簽下顯示。由于騰訊新聞的標題是在“〈h1〉”“〈/h1〉”之間,通過過濾掉除〈h1〉之外的標簽可以獲得新聞的標題。
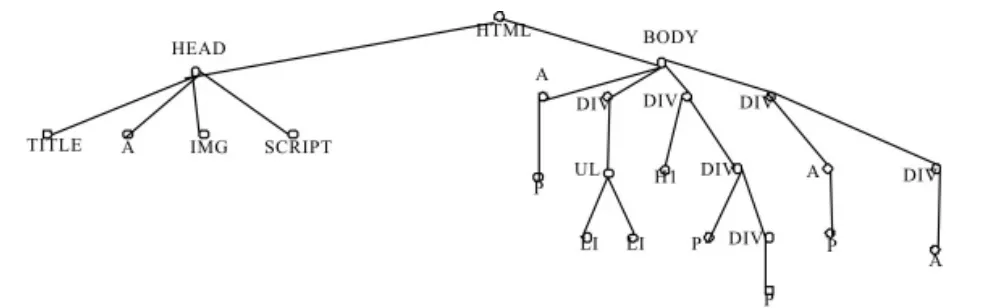
圖3 網頁文檔解析樹
第二步,抽象HTML節點。
根據網頁的HTML標記,將網頁表示成一棵樹型結構,可以將任何一個WEB網頁的HTML標簽抽象成一棵網頁文檔解析樹,每個文本標簽都可以看成是樹中的一個節點,如圖3所示。
本模型暫時忽略各個標簽間的差異,將所有的HTML標簽都抽象成節點Node,當需要進行節點過濾的時候,再按照類型對節點進行分類,劃分得到LinkTag,ImageTag,ParagraphTag,InputTag,SelectTag和FrameTag等類,進而得到具有特定屬性特征的Tag,最后對抽象得到的Tag屬性進行過濾操作。
第三步,定制網頁抽取算法。
具體的實現方法描述如下:
步驟1用一個?URL或是頁面?String做一個?Parser;
步驟2用這個?Parser?做一個?Visitor;
步驟3使用Parser.visitAllNodeWith(Visitor)遍歷節點,并獲取Visitor遍歷得到的數據;
步驟4根據標簽類型的不同抽象節點類型;
步驟5根據標簽屬性的不同定制過濾參數。
例如:

這段代碼的功能是獲得類型為H1的節點,過濾的條件有兩點:一是標簽名稱為H1;二是標簽的id屬性不為空且必須是“artibodyTitle”,使用這個過濾算法便可以將新浪新聞的正文標題抽取出來。
3 針對由腳本動態生成的網頁的信息抽取
網頁中的內容有的是前臺靜態生成的,有的是后臺數據庫動態生成的,還有的是調用腳本執行后生成,我們可以通過一般的方法,如根據文本標簽屬性過濾得到前兩類網頁的內容,但卻無法抽取由JavaScript腳本執行后得到的網頁內容,因為基于文本標簽屬性的抽取算法只能抽取腳本的內容,不能對腳本進行執行。因此,對于抽取像新聞網頁的評論數這類由腳本執行后生成的內容,必須要模擬執行腳本后才能抽取內容,否則抽取的結果將會出現錯誤。此時要做的工作就是要模擬一個瀏覽器,執行腳本之后將HTML內容返回給用戶,然后再將腳本執行后的結果進行過濾得到需要的內容。
3.1 腳本動態生成的網頁信息抽取模型
腳本動態生成的信息抽取模型如圖4所示,其運行的步驟描述如下:
步驟1輸入網頁URL后先提交模擬瀏覽器執行網頁腳本,得到網頁腳本執行后的HTML內容;
步驟2將腳本執行后的HTML進行遍歷,分析并得到整個HTML頁面的所有節點;
步驟3把得到的節點進行抽象得到HTML DOM樹,并根據Tag劃分節點類型;
步驟4通過分析給定網站,并結合網站的情況找出需要抽取的元素HTML節點的屬性,通過找到的屬性對網站進行定制,過濾掉與所要內容無關的內容;
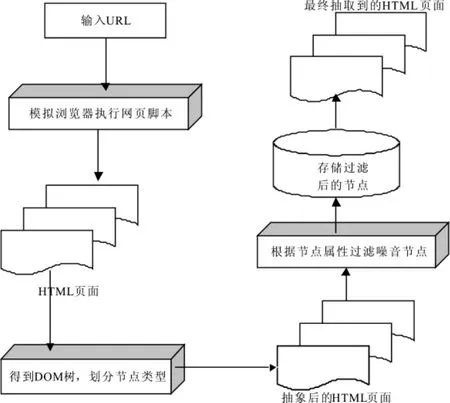
圖4 腳本動態生成的網頁信息抽取模型
步驟5存儲抽取的信息內容。
本模型的關鍵一步就是模擬瀏覽器執行腳本的過程,由于該模型主要針對的是通過腳本執行后得到的網頁內容,一般的信息抽取是不能夠執行腳本的,抽取得到的結果也會出錯。而通過模擬一個瀏覽器的瀏覽方式可以有效解決這個問題,但是由于要模擬瀏覽器執行,本模型的執行效率將有所下降。
要模擬執行網頁腳本需要用到JDIC開源項目中的WebBrowser組件,該組件主要提供了使用系統內置瀏覽器的接口,WebBrowser組件可以實現使用Swing應用程序將本地的瀏覽器嵌入到任何應用程序中,WebBrowser提供的是瀏覽器應用程序中的呈現部分,該組件并不包含狀態欄、地址欄等等常見瀏覽器的功能,這些功能可以通過程序來實現。
3.2 腳本動態生成的網頁信息抽取算法
要抽去由腳本動態生成的網頁,需要首先模擬一個瀏覽器,本算法使用的是JDIC開源項目的WebBrowser組件,該組件的使用方法如下:

其中在定義WebBrowserListener()時定義了一個在網頁全部加載完成后執行的接口,如下所示:

該接口表示在網頁加載完成后調用testDOMAPI這個函數,該函數如下:

該函數在網頁加載完成后即是當模擬調用的瀏覽器執行網頁腳本后得到了一個HTML數據,然后再通過調用WebBrowser組件的executeScript()執行腳本,通過執行“document.getElementById('cmtNum').innerHTML”這個腳本來實現抽取標簽ID為“cmtNum”的文本內容。這段代碼就是抽取騰訊新聞評論數的一個實際應用。
4 結語
本文研究的WEB新聞內容抽取技術主要針對兩類網頁內容進行分析研究:第一類是靜態的網頁內容;第二類是由網頁腳本執行后動態生成的網頁內容。文章主要分析了使用網絡爬蟲技術實現網頁新聞內容的獲取,描述了使用基于文本標簽屬性的信息抽取和過濾的方法,解決了針對網頁腳本動態生成的網頁內容抽取的難題。系統分別選取了新浪網、騰訊網、鳳凰網、人民網、搜狐網、環球網和網易新聞七大主流新聞網站進行了抽取實驗,針對不同網站正文的不同特征,系統定制了相應的抽取算法,實驗結果表明,正文抽取的正確率都能夠保持在95%以上。
[1]林子熠,沈備軍.基于統計的自動化Web新聞正文抽取[J].計算機應用與軟件.2010,27(12):232-235.
[2]顧韻華,田偉.基于DOM模型擴展的Web信息提取[J].計算機科學,2009,36(11):235-237.
[3]胡東東,孟小峰.一種基于樹結構的Web數據自動抽取方法[J].計算機研究與發展.2004,41(10):1607-1613.
[4]林樂彬.Inar網絡爬蟲的設計與實現[D].哈 爾濱:哈爾濱工業大學,2006.
[5]張志剛,陳靜,李曉明.一種 HTML網頁凈化方法[J].情報學報,2004(2).
[6]赫楓齡,左萬利.利用超鏈接信息改進網頁爬行器的搜索策略[J].吉林大學學報(信息科學版),2005,23(l):12-18.
[7]http://htm lparser.sourceforge.net/.
[8]章棟兵.互聯網輿情分析關鍵技術的研究與實現[D].武漢:武漢理工大學,2010.
[9]朱永盛,武港山.基于Web的新聞信息抽取[J].計算機工程,2006,32(10):74-76.
[10]孫育華,韓中元,韓詠,李軍.中文信息檢索中多索引策略融合的研究[J].黑龍江工程學院學報(自然科學版),2009,23(4):25-26.
(責任編輯:陳 輝)
Research on Information Extraction Method Based on WEB News Content
SHEN Na
(Suqian Open University,Suqian 223800,China)
With the rapid development of Internet,the information resources of the network present a blowout situation,how to extract information you need from huge amounts of the information has become increasingly difficult.Based on the study of structural characteristics of web pages and the analysis of the HTML DOMtree structure,we have designed a Web news information extraction model based on text label attribute.On the web page script dynamically generated content extraction;we have designed a script dynamically generated Web information extraction model.This paper mainly describes the algorithm of two kinds of Web information extraction technology model,gives the specific implementation process of information extraction,describes the traversal algorithm of the filtering text labels based on DOMtree node,and chooses the mainstream news sites to carry out the extraction experiment to verify the feasibility of the algorithm.
HTMLDOMtree;text tag attributes;Web news;information extraction
TP274
A
123(2015)03-0025-05
2015-04-07
沈 娜(1984-),女,江蘇宿遷人,宿遷開放大學,講師,碩士。研究方向:數據庫技術,網絡安全與應用技術。
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
臺聲(2016年2期)2016-09-16 01:06:53
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
