基于邊分類的SVM模型在社區發現中的研究
2015-10-12 02:19:04王鵬高鋮楊華民
長春理工大學學報(自然科學版) 2015年5期
王鵬,高鋮,楊華民
(長春理工大學 計算機科學技術學院,長春 130022)
基于邊分類的SVM模型在社區發現中的研究
王鵬,高鋮,楊華民
(長春理工大學計算機科學技術學院,長春130022)
社區發現是復雜網絡研究的重要內容,也是分析網絡結構的重要途徑。分析了社區發現研究中存在的問題,提出了一種基于邊分類的SVM模型。通過邊頂點相似度和邊介數來表示邊的特征,從而構造分類函數。利用LFR生成社區結構已知的人工網絡,通過人工網絡數據訓練基于邊分類的SVM模型,對分類函數的參數進行估計,利用訓練模型對真實網絡進行社區分類并通過標準化互信息(NMI)和整體準確度來評價分類效果。實驗得到了較高的整體準確度和NMI值。實驗表明基于邊分類的SVM訓練模型對真實網絡數據的社區劃分有較高的準確度,表明該方法是可行的。
社區發現;邊分類;SVM模型;LFR
現實世界中的很多復雜系統都可以通過將實體抽象為節點,實體之間的聯系抽象為邊的復雜網絡來表示。社區結構是復雜網絡的一個重要特征,刻畫了網絡中節點連接關系的局部聚集特性,對揭示復雜網絡的結構和功能之間的聯系有著十分重要的作用。對社區結構的研究主要有社區發現、社區演化分析、社區網絡動力學分析等[1],其中,社區發現是結構分析的一個基本任務。
社區發現的基本思路就是識別網絡中的節點集合,使集合內的節點之間連接緊密,集合間的聯結比較稀疏。基于這個思路,2002年Girvan和Newman提出了基于邊介數劃分的GN(Girvan-Newman)算法[2],該算法通過計算邊介數,識別社區間連接,從而切斷社區間連接劃分社區,但該算法具有很高的時間復雜度,不適合處理大規模網絡。為了度量社區內的緊密程度,2004年Newman提出了基于模塊性的FN(Fast Newman)算法[3],該算法定義模塊度函數Q[4],將使函數Q值增加或者減小最少的社區合并,從而選擇對應Q值最大的社區劃分作為聚類結果,同樣該算法的計算開銷較大。2007年Raghavan等人提出了標簽傳播算法(Label Propagation Algorithm,LPA)[5],該算法通過節點的鄰居節點標簽來更新自身標簽,通過標簽來確定節點社區,該算法收斂速度較快,聚類精度有待提高。在前人研究的基礎上,本文提出了一種基于邊劃分的機器學習方法,通過建立基于邊劃分的支持向量機模型(Support Vector Machine,SVM[8])利用人工網絡數據進行機器學習,進而對真實網絡數據進行分析實驗來提高社區發現的準確度,并利用標準化互信息(Normalized Mutual information,NMI[10])和整體準確率來衡量結果的優劣,實驗結果表明該方法是可行的。
1 基于邊分類的SVM模型
復雜網絡的抽象表示是由節點和連接節點的邊構成的網絡結構,在圖論中即可表示為G=(V,E),V表示網絡中的節點集合,E表示網絡中邊的集合[6]。那么社區發現問題即可表述為:對于任意一條邊ab∈E,節點a,b是否屬于同一個社區。對于二元分類問題,本文構造分類器函數h,對于邊ab的特征Xab,通過計算分類函數h( )Xab的值來判斷節點a,b是否屬于同一個社區,遍歷網絡中的每一條邊,由此對網絡中的邊進行切割,最終得到社區集合。算法流程圖如圖1所示。

圖1 算法流程圖
1.1分類函數
構造基于邊的分類器函數,需要首先確定邊的特征量。復雜網絡中對邊的特征度量主要有邊介數、邊聚集系數、邊兩端節點的度以及鄰近結點個數等。本文通過計算邊兩端節點的Jaccard相似度和邊介數來作為該條邊的特征度量,并根據特征量構造分類器函數。
1.1.1Jaccard相似度
節點的Jaccard相似性是根據兩節點的鄰居節點的交集節點數占并集節點數的比重定義的[7],其公式如下:
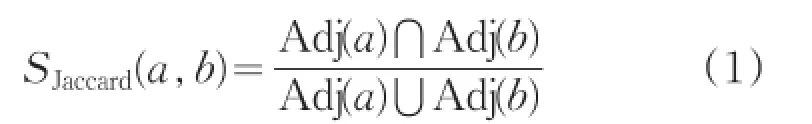
其中Adj()表示節點的鄰居節點,其相似性的取值范圍為[0,1]。傳統的Jaccard相似度節點的鄰居節點并不包含自身,但實際網絡中存在邊ab且。從相互關系來看,兩個節點相連接在某種程度上存在相似性,因此本文采用修正的Jaccard相似度,在節點的鄰居節點集合中并入自身節點。
1.1.2邊介數
根據社區發現的思想,社區與社區之間聯系稀疏,社區內聯系密切,可以發現連接社區間的邊成為社區之間溝通的主要橋梁。基于這個思想,Girvan 和Newman提出了邊介數的概念:一條邊的邊介數是網絡中任意兩點的最短路徑通過該邊的路徑數與最短路徑總和的比值[1]。定義公式如下:

其中gab表示通過邊ab的最短路徑數,gij表示網絡中任意兩點的最短路徑數。為了方便實驗處理,本文采用標準邊介數,即將邊介數做歸一化處理。
由邊的特征向量構造分類器,本文提出通過加權的節點相似度和邊介數得分來判斷邊的歸屬,從而進行切割劃分社區。得分公式定義如下:
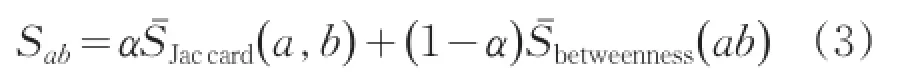
其中α為邊特征向量元素的權重,Sab的取值范圍為[0,1]。自然地,通過設定閾值來定義分類器函數,當Sab>τ???0<τ<1時,邊ab屬于社區內;相反當Sab≤τ時,邊ab屬于社區間,即節點a,b屬于不同社區。因此,分類器函數可以表示為:

1.2SVM模型及參數估計
對模型參數的估計實際上就是對邊特征向量所對應的權重向量的估計。對于社區結構已知的復雜網絡很容易得到邊的特征向量,同時還有邊的歸屬,即模型的響應變量,定義如下:

在自變量與響應變量已知的情況下,通過利用SVM模型進行參數估計,進而將訓練模型應用到社區結構未知的網絡,進行社區發現研究。SVM模型是一種機器學習方法,該算法基于統計學習理論采用結構風險最小化原則,使得分類準確率和預測能力都能達到較高水平。
假設存在線性可分的數據集(X,Y) ,則線性判別函數即可定義為g(X)=W·X+b,那么,存在一個超平面W·X+b=0,使得數據分布在該平面的兩側。對任意xi存在平行于超平的邊界面W·xi+b≥1或W·xi+b≤-1,最大化兩個平行超平面的距離,即。因此,最優分類面的求解,轉化為了求‖‖W的最小值,即求函數的最小值。這是一個二次優化問題,采用拉格朗日乘子法進行求解,定義Lagrange函數[9]:

其中αi>0是拉格朗日系數。在參數W,b下求Lagrange函數的極小值,關于Lagrange函數分別對W,b求偏導,得到原問題的對偶問題表達式:
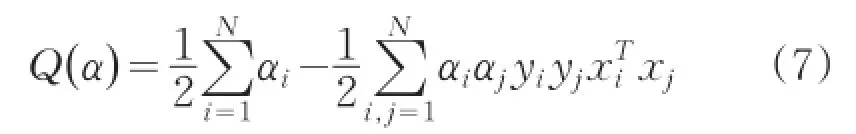

最后利用符號函數得到最優分類函數:
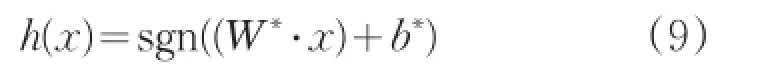
2 社區評價
對于社區結構已知的基準網絡,為了比較實驗結果與真實社區之間的相似程度,利用Lancichinetti提出的NMI指標來評價模型的優劣,同時本文也提出了一種新的評價指標整體準確率ρ。
2.1NMI指標
Normalized Mutual information(NMI[10],標準化互信息),是基于信息論和概率論提出的一種衡量聚類或分類效果的評價指標。NMI的值域為[0,1],其值越大說明實驗結果越接近真實情況。NMI的公式定義如下:

其中X,Y為兩個離散隨機變量,I(X;Y )表示兩個隨機變量的互信息,H(X),H(Y )表示兩個隨機變量的邊緣熵,p(x),p(y),p(x,y)分別表示隨機變量的概率分布和聯合概率分布。
2.2整體準確率
在社區發現試驗中,真實網絡的社區數量往往比實驗發現的社區數量少,觀察實驗結果發現,真實網絡社區往往被拆分成若干個子社區。在這種情況下NMI指標并不能很好的衡量算法的效果。因此文本提出了一種新的衡量指標:整體準確率ρ,其公式定義如下:
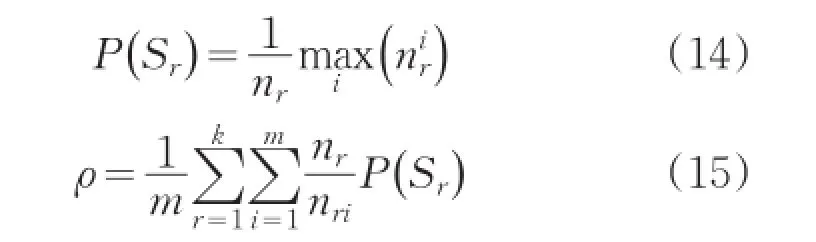
其中Sr表示實驗發現的社區,nr對應為社區的節點數,表示社區Sr中節點屬于第i個真實社區的個數,m為真實社區個數,k為實驗發現的社區個數,nri表示社區Sr中節點屬于真實社區最多的第i個真實社區的規模。
3 仿真實驗及結果分析
LFR[11]是由Lancichinetti和Fortunato提出的一種標準測試網絡。現實網絡中的節點度服從冪律分布,利用LFR生成的人工網絡節點度同樣服用冪律分布,因此利用LFR生成的網絡結構與現實網絡相似。本文利用LFR生成的數據訓練分類器,確定相應的分類器參數。為了構造具有特定性質的LFR網絡,需要一定的參數配置,其中N表示節點的個數;k表示節點的平均度;maxk表示最大節點度;minc表示最小社區的節點個數;maxc表示最大社區的節點個數;最為重要的是混合參數μ,它控制社區之間的關聯程度。當μ=0時,社區之間沒有連接,即社區之間相互獨立;當μ=1時,網絡中每一條邊的兩個節點分別屬于不同的兩個社區,社區之間聯系密切。
在不同混合參數μ下,對社區發現算法進行仿真實驗,實驗數據本文采用LFR生成的標準GN網絡,訓練數據利用LFR生成,參數設置為N=1000,k=10,maxk=30,minc=20,maxc=100,mu=0.5。實驗結果如圖2所示。
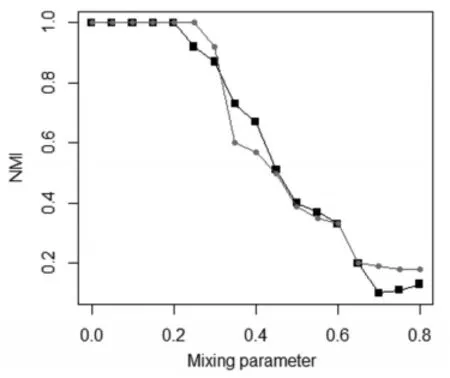
圖2 訓練模型與原始模型對標準GN網絡劃分結果比較
圖2中紅線表示訓練模型,黑線表示原始模型,可以看出訓練模型基本優于原始模型,特別是在混合參數不大的情況下,訓練模型對社區發現的精準度較高。
真實數據采用經典的Zachary空手道俱樂部網絡Karate、美國大學生足球賽網絡Football、海豚關系網絡Dolphins、美國政論著作網絡Polbooks,這三個真實網絡都有清晰的社區結構,方便與實驗結果進行比較分析。實驗結果如表1所示。
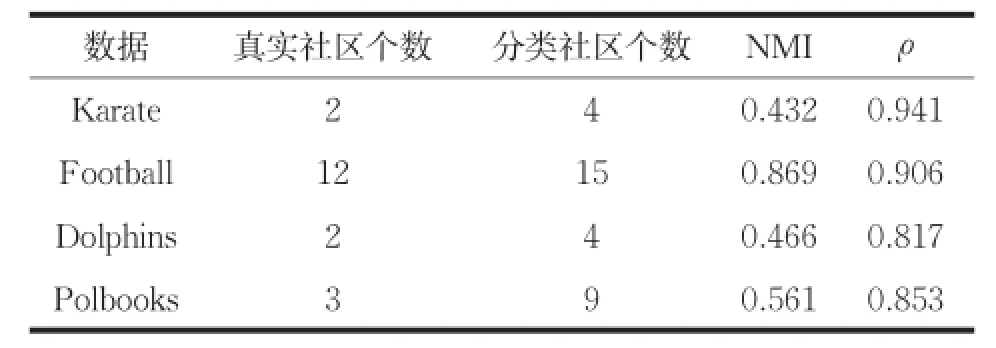
表1 真實數據的實驗結果
從上表可以看出訓練模型對真實網絡數據有較好的分類效果,真實社區個數與分類社區個數存在一定的差別,這與模型本身和模型的訓練程度有一定的關系,模型的精度可以進一步的提高。受分類社區個數影響,NMI值相對偏低,但整體準確率基本保持在較高水平,說明實驗分類社區中的節點純度很高。
4 結論
社區發現是復雜網絡研究的重要內容之一,許多專家學者對這方面做出了深入的研究,也取得了很大的成果。本文基于網絡中邊的特征,構造分類函數,利用LFR仿照現實網絡性質參數,生成一些社區結構已知的人工網絡,通過人工網絡數據訓練基于邊劃分的SVM模型,利用SVM模型進行參數估計,并利用訓練模型對未知網絡進行社區分類,通過NMI和整體準確度評價分類結果。實驗表明基于邊分類的SVM訓練模型對真實網絡數據的社區劃分有較高的準確度,說明文中的方法是可行的。
[1] 程學旗,沈華偉.復雜網絡的社區結構[J].復雜系統與復雜性科學,2011,08(1):57-70.
[2]Girvan M,Newman M E J.Community structure in social and biological networks[J].Proceedings of the National Academy of Sciences,2002,99(12):7821-7826.
[3] Newman M E J.Fast algorithm for detecting community structure in networks.[J].Phys Rev E Stat Nonlin Soft Matter Phys,2004,69(6):279-307.
[4] Newman M E J,Girvan M.Finding and evaluating community structure in networks[J].Physical Review E,2004,69(2):292-313.
[5]Raghavan U N,Albert R,Kumara S.Near linear timealgorithmtodetectcommunitystructuresin large-scale networks.[J].Phys Rev E Stat Nonlin Soft Matter Phys,2007,76(3):036106-036111.
[6] Lei Tang,Huan Liu著,文益民,閉應洲譯.社會計算:社區發現和社會媒體挖掘[M].北京:機械工業出版. 2012.
[7]Laarhoven T V,Marchiori E.Network community detectionusingedgeclassifierstrainedonLFR graphs[C].ESANN 2013:21st European Symposium on Artificial Neural Networks,Computational IntelligenceAndMachineLearningBrugesApril 24-25-26,2013.Proceedings,2013.
[8] Guyon I,Weston J,Barnhill S,et al.Gene Selection for Cancer Classification using Support Vector Machines[J].Machine Learning,2002,46(1-3):389-422.
[9] 鞏知樂,張德賢,胡明明.一種改進的支持向量機的文本分類算法[J].計算機仿真,2009,26(7):164-167.
[10]Lancichinetti A,Fortunato S,Kertész J.Detecting the overlapping and hierarchical community structureincomplexnetworks[J].NewJournalof Physics,2009,11(15):19-44.
[11]Radicchi F,Castellano C,Cecconi F,et al.Defining and Identifying Communities in Networks[J]. Proceedings of the National Academy of Sciences of the United States of America,2004,101(9):2658-2663.
The SVM Model Based on Edge Classification Research in Community Detection
WANG Peng,GAO Cheng,YANG Huamin
(School of Computer Science and Technology,Changchun University of Science and Technology,Changchun 130022)
The community detection is an important part of the complex network research,and it is also the important way to analyze the network structure.In this paper,the problems existing in the community detection research are analyzed and a kind of SVM model based on the edge classification is proposed.Based on vertex similarity and edge betweenness the characteristics of the edge are represented,so the classification function is constructed.The artificial network of the known community structure is generated by LFR.Through artificial network data training based on edge classification of SVM model,the parameters of classification function are estimated and the real network community is simulated by using the trained model.The higher overall accuracy and NMI values are got in the experiment.Experiments show that the edge classification of SVM trained model have higher accuracy on real network data and the method is effective.
community detection;edge classification;SVM model;LFR
TP391
A
1672-9870(2015)05-0127-04
2015-06-08
王鵬(1973-),男,副教授,E-mail:635461179@qq.com
楊華民(1963-),男,博士,教授,博士生導師,E-mail:yhm@cust.edu.cn
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
