噪聲譜估計算法對語音可懂度的影響
2015-10-14 00:17:56張建偉陶亮周健王華彬
聲學(xué)技術(shù) 2015年5期
關(guān)鍵詞:信號
張建偉,陶亮,周健,王華彬
?
噪聲譜估計算法對語音可懂度的影響
張建偉,陶亮,周健,王華彬
(安徽大學(xué)計算智能與信號處理教育部重點(diǎn)實(shí)驗(yàn)室,安徽合肥230031)
噪聲譜估計是單通道語音增強(qiáng)算法的關(guān)鍵步驟,當(dāng)前大部分語音增強(qiáng)算法旨在提高語音質(zhì)量,提高語音可懂度的算法卻很少。在傳統(tǒng)的單通道語音增強(qiáng)算法中,語音質(zhì)量的提高往往是以犧牲語音的可懂度為代價的。對目前主流的幾種噪聲譜估計算法對語音可懂度影響進(jìn)行分析。在不同噪聲背景、不同信噪比情況下進(jìn)行噪聲譜估計,并采用譜減法對含噪語音信號作去噪處理,對比分析不同噪聲、不同信噪比下增強(qiáng)前后語音的短時客觀可懂度(Short-Time Objective Intelligibility, STOI)值,最后根據(jù)信噪比,對比分析了不同噪聲環(huán)境下,語音增強(qiáng)前后語音能量高于噪聲能量的時頻塊所占比例。實(shí)驗(yàn)表明,相比其他噪聲估計算法,最小統(tǒng)計(Minima Statistics, MS)算法由于保留了更多的以語音能量為主的時頻塊,使得去噪后的語音有較高的可懂度。
噪聲譜估計;譜減法;時頻塊;最小統(tǒng)計;短時客觀可懂度;語音可懂度
0 引言
語音增強(qiáng)算法在提高語音質(zhì)量方面已經(jīng)取得了很大的進(jìn)展[1-3],相反,提高語音可懂度的算法卻很少。Lim首次發(fā)現(xiàn),在-5~5 dB的白噪聲背景下,譜減法并未提高語音的可懂度[4]。Hu和Loizou也對語音可懂度作了研究,他們采用了8種不同的算法,對語音增強(qiáng)前和增強(qiáng)后的可懂度進(jìn)行比較,結(jié)果發(fā)現(xiàn),所有算法增強(qiáng)后的可懂度均小于增強(qiáng)前的可懂度[5]。研究者發(fā)現(xiàn),在傳統(tǒng)的語音增強(qiáng)算法中,語音質(zhì)量的提高往往是以犧牲語音的可懂度為代價的[6]。
研究者們提出了很多相關(guān)的噪聲譜估計算法,而且取得了一定的效果[7-11]。Hirsch[12]提出了一種不需要進(jìn)行語音端點(diǎn)檢測的噪聲譜估計方法,需要比較當(dāng)前窗的功率譜和前一窗的估計噪聲譜,使用一階遞歸平均來更新噪聲譜估計,該方法可以快速地適應(yīng)變化緩慢的噪聲。Martin[13]提出了一種基于最小統(tǒng)計(Minima Statistics, MS)的噪聲譜估計方法,即在一個有限窗口內(nèi)跟蹤平滑含噪語音譜的最小值,然后對其按幀平滑,并乘以一個偏置補(bǔ)償因子,即可獲得噪聲譜估計。Cohen和Berdugo[14]提出了一種最小受控遞歸平均算法(Minima Controlled Recursive Averaging, MCRA),該方法根據(jù)含噪語音的局部能量值與其待定時間窗內(nèi)的最小值的比值確定子帶中是否存在語音,如果給定幀的某個子帶中存在語音,那么該子帶內(nèi)的噪聲譜等于上一幀的噪聲譜,如果不存在,則根據(jù)含噪語音的功率譜更新噪聲譜。Cohen在2003年提出了改進(jìn)的最小控制遞歸平均方法(Improved Minima Controlled Recursive Averaging, IMCRA),主要從三個方面進(jìn)行了改進(jìn),即語音活躍期的最小值跟蹤、語音存在概率估計、提出偏置補(bǔ)償因子[15]。Sorensen等人在2005年提出了一種基于連接語音時頻域(Connected Time-Frequency Speech Presence Regions, Conn_freq)[16]的噪聲譜估計算法,該方法可連接時頻域的語音缺失段,將縮小的背景噪聲留在增強(qiáng)后的語音中,利用人的聽覺系統(tǒng)中的掩蔽機(jī)制,減少對語音段中噪聲的感知,消除語音缺失段的噪聲。
有研究者在噪聲譜估計算法的基礎(chǔ)上,提出了很多改進(jìn)算法,在語音質(zhì)量和可懂度方面有了一定程度的改善[17-20]。雖然這些噪聲譜估計方法得到廣泛應(yīng)用,但是其對于增強(qiáng)后語音可懂度的影響則至今未見相關(guān)報道。為此,本文討論上述5種不同的噪聲譜估計算法對語音可懂度的影響。為盡可能排除增強(qiáng)過程中其他因素對可懂度的影響,增強(qiáng)算法采用經(jīng)典的譜減法。論文首先回顧5種噪聲譜估計方法,并將其應(yīng)用于正常音的噪聲譜估計。為了評價這5種算法對語音可懂度的影響,計算經(jīng)增強(qiáng)后的語音可懂度,對增強(qiáng)前后的語音時頻譜中的語音能量為主的時頻塊的保留情況進(jìn)行分析,以探討不同噪聲譜估計方法對可懂度影響的原因。
1 噪聲譜估計及算法
1.1 信號模型
設(shè)表示時域含噪信號,表示干凈語音信號,表示非相關(guān)加性噪聲。對含噪信號作短時傅里葉變換(Short-time Fourier Transform, STFT),(,)、(,)、(,)分別是、、的變換系數(shù),我們得到時頻域信號

式(1)中:表示頻帶號;表示時幀號。
1.2 噪聲譜估計算法
單通道語音增強(qiáng)算法都需要從含噪語音中估計噪聲譜和先驗(yàn)信噪比,后者也建立在噪聲譜估計基礎(chǔ)上。
1.2.1 Hirsch算法
Hirsch提出計算所有頻域子帶的含噪語音幅度譜的權(quán)重和,然后按照式(2)對噪聲估計進(jìn)行一階遞歸:

該算法不需要進(jìn)行語音端點(diǎn)檢測,而且可以快速適應(yīng)變化緩慢的噪聲,語音存在段和語音缺失段都采用公式(2)更新噪聲譜,可以結(jié)合譜減法對語音作增強(qiáng)處理。
1.2.2 MS算法
最小值統(tǒng)計的方法依賴于兩點(diǎn),即(1) 語音信號和噪聲從統(tǒng)計意義上講是獨(dú)立的;(2) 含噪語音的功率會衰減至噪聲的功率水平。由于最小值總是小于平均值,因此最小值跟蹤方法需要偏差補(bǔ)償。為了能更快地跟蹤并更新局部最小值和頻譜最小值,作者把滑動窗口分為多個子窗口,在每個子窗口內(nèi)更新估計噪聲譜,提高了精確度[21]。
MS算法一階平滑估計噪聲譜的規(guī)則可用式(3)表示:

本算法無論是在語音存在段還是語音缺失段,噪聲功率譜估計均跟蹤平滑含噪語音譜的最小值,不采用閾值區(qū)分語音活動和語音端點(diǎn),可以結(jié)合任意需要噪聲譜估計的語音增強(qiáng)算法。
1.2.3 MCRA算法
MCRA算法使用一個平滑參數(shù)對功率譜的過去值取平均,其中平滑參數(shù)是通過子帶中語音存在的概率來調(diào)整的。首先對輸入的每一幀信號進(jìn)行頻域平滑:

其次,采用一階遞歸進(jìn)行時域平滑:

同時跟蹤含噪語音功率譜的局部最小值,估計語音存在概率,最后根據(jù)式(6)、(7)中規(guī)則更新噪聲譜:

(7)
1.2.4 IMCRA算法
該算法是對MCRA算法的改進(jìn),噪聲譜的更新規(guī)則不變。該算法包含兩次迭代:平滑和最小值跟蹤。第一次迭代是在每個頻域子帶內(nèi)進(jìn)行粗略的語音活動檢測,第二次迭代是對語音缺失段的功率譜進(jìn)行平滑,相對強(qiáng)語音信號部分并不進(jìn)行平滑,使得語音活躍段的最小值跟蹤具有魯棒性。
搜索窗長取120,子窗數(shù)為8,子窗長為15,其他有關(guān)參數(shù),默認(rèn)為文獻(xiàn)[15]給定的數(shù)據(jù)。
與MS算法不同的是,該算法考慮到連續(xù)窗口的相鄰頻域子帶之間語音存在的強(qiáng)相關(guān)性,分別在時域和頻域?qū)胝Z音功率譜進(jìn)行平滑處理。
1.2.5 連接語音時頻域(Conn_freq)算法
Conn_freq算法基于短時平滑功率譜和最小值跟蹤,定義了兩個語音存在檢測規(guī)則,表示為
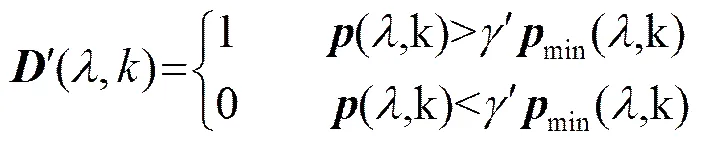
(9)
最終的語音存在檢測估計為

噪聲功率譜估計為
(10)
該方法在連接時頻域的語音缺失段,將縮小的背景噪聲留在增強(qiáng)后的語音中,利用人的聽覺系統(tǒng)中的掩蔽機(jī)制,減少對語音段中噪聲的感知,消除語音缺失段的噪聲。
1.2.6 不同算法噪聲譜對比
圖1(a)和圖1(b)分別顯示了MS、MCRA、IMCRA、Hirsch四種算法在白噪聲背景下,在信噪比分別為-9 dB和5 dB情況下的噪聲譜估計,選取第20幀作為觀測。圖2顯示了Conn_freq算法在白噪聲背景下,在信噪比為-9 dB和5 dB情況下的噪聲譜估計。從圖2中可以看出,Conn_freq算法估計的噪聲譜更接近真實(shí)噪聲譜變化。為了更好地觀察對比這5種算法的真實(shí)噪聲譜和估計噪聲譜,我們將Conn_freq算法的噪聲譜估計圖單獨(dú)列出。
從圖1(a)中可以看出,在低信噪比-9 dB的情況下,MS算法的噪聲譜估計最低,Hirsch算法次之,IMCRA算法和MCRA算法的噪聲譜估計相似,只是在某些頻點(diǎn)處,IMCRA算法的噪聲譜估計要高于MCRA算法。MCRA算法和IMCRA算法的噪聲譜估計高于Hirsch算法,這是因?yàn)榍皟煞N算法在語音存在段不進(jìn)行噪聲譜更新,而是保持前一幀的噪聲譜不變,Hirsch算法仍然采用一階遞歸更新噪聲譜估計。從圖1(b)中可以看出,在信噪比為5 dB的情況下,MS算法的噪聲譜估計還是最低,Hirsch算法次之,MCRA算法的噪聲譜估計最高,而且超越了真實(shí)噪聲譜。從圖2中可以看出,Conn_freq算法在信噪比分別為-9 dB和5 dB時的噪聲譜估計變化接近真實(shí)噪聲譜,但是稍高于真實(shí)噪聲譜,并未超越含噪語音譜。
2 實(shí)驗(yàn)仿真
實(shí)驗(yàn)采用來自中文語言資源聯(lián)盟[22]語音數(shù)據(jù)庫的干凈語音共50句,是漢語連續(xù)音節(jié)構(gòu)成的語句,每個語句有6個左右音節(jié),其中男女語音各半。噪音數(shù)據(jù)采用Noisex92數(shù)據(jù)庫[23]的三類噪聲信號:White高斯白噪聲、F16飛機(jī)駕駛艙噪聲和Babble人群嘈雜噪聲等。干凈語音數(shù)據(jù)和噪聲數(shù)據(jù)均為16 kHz采樣率,混合產(chǎn)生信噪比在-9~3 dB范圍內(nèi)的帶噪語音。語音處理中,語音分幀幀長取320樣點(diǎn),幀間重疊50%,數(shù)據(jù)加窗采用漢明窗,F(xiàn)FT分析點(diǎn)數(shù)取640點(diǎn)。實(shí)驗(yàn)方法是將估計后的噪聲譜用于譜減法[24]對語音作增強(qiáng)處理,然后從不同的角度評價增強(qiáng)后語音的可懂度。
譜減法是在頻域?qū)г胝Z音的功率譜減去噪聲的功率譜,從而得到純凈語音功率譜估計,開方后就得到語音幅度譜估計,用帶噪語音的相位來近似純凈語音的相位,再采用逆傅里葉變換恢復(fù)時域信號[25]。譜減法的原理圖如圖3所示。
算法性能評價采用可懂度衡量指標(biāo)STOI (Short-Time Objective Intelligibility, STOI)[26],將其用于衡量語音增強(qiáng)算法的可懂度性能,在STOI算法中,同時輸入干凈的語音()和經(jīng)過增強(qiáng)算法重建的干凈語音估計(),STOI算法會給出一個(0, 1)范圍內(nèi)的值,STOI值越大,表示處理后的語音的可懂度越高。圖4顯示了信噪比分別為-9、-6、-3、0、3 dB時,在White、F16和Babble三種噪聲背景下,語音增強(qiáng)前后的STOI值。
圖4顯示了不同噪聲、不同信噪比環(huán)境下不同算法的STOI值對比,從圖4(a)可以看出,在White噪聲背景下,MS算法處理后的語音可懂度最高,但是在信噪比為-9、-6 dB時仍然低于增強(qiáng)前的語音可懂度,也就是說,經(jīng)去噪處理后,含噪語音的可懂度并未得到提高。從圖4(b)中可以看出,在F16噪聲背景下,Conn_freq算法處理后的語音可懂度最低,在信噪比為-3、0、3 dB時,其他四種算法處理后的語音可懂度均得到了提高,在信噪比為-9、-6 dB時,MS算法處理后的語音可懂度最高,但是-9 dB時小于增強(qiáng)前的語音可懂度。從圖4(c)中可以看出,在Babble噪聲背景下,經(jīng)Conn_freq算法處理后的語音可懂度仍是最低,MS算法處理后的語音可懂度最高,Hirsch算法次之,然后依次是IMCRA算法、MCRA算法。
在主觀聽辨實(shí)驗(yàn)中,挑選三名聽力正常測試者對增強(qiáng)前后的語音分別進(jìn)行詞語聽辨測試。分別在-5、0和5 dB信噪比的高斯白噪聲、F16飛機(jī)噪聲和Babble噪聲背景下進(jìn)行聽辨實(shí)驗(yàn)。表1列出了不同算法增強(qiáng)后語音聽辨實(shí)驗(yàn)中的平均詞語識別率。從表1中可以看出,在white-5 dB噪聲背景下,Hirsch算法的詞語識別率高于其他算法,其他情況下,采用MS算法增強(qiáng)后的語音在聽辨實(shí)驗(yàn)中詞語的平均識別率均較其他四種算法要高。
由以上分析可以得出,在white噪聲背景下,在信噪比分別為-3、0、3 dB時,MS算法處理后的語音可懂度高于其他四種噪聲譜估計算法和含噪語音的可懂度,而由圖1的噪聲譜估計曲線可以看出,MS算法的噪聲譜估計偏低于其他四種噪聲譜估計算法。為了進(jìn)一步分析五種噪聲估計算法對語音可懂度的影響,下面采用語音信號增強(qiáng)前后的信噪比進(jìn)行實(shí)驗(yàn)。
定義語音信號增強(qiáng)前的信噪比pre和增強(qiáng)后的信噪比post,見下式:

(12)
文獻(xiàn)[6]提出,當(dāng)掩蔽信號過高于目標(biāo)信號時,會降低目標(biāo)信號的可懂度。Wang Deliang提出的IBM(Ideal Binary Mask)[27]實(shí)驗(yàn)表明,在英語含噪語音中,語音能量為主的時頻塊對語音可懂度的感知起關(guān)鍵作用,文獻(xiàn)[28]在漢語中進(jìn)行了IBM實(shí)驗(yàn),結(jié)果表明在中文含噪語音中,語音能量為主的時頻塊對語音可懂度感知也起重要作用。時頻塊是一幀信號FFT后某個頻率點(diǎn)幅度譜。

表1 不同算法增強(qiáng)后的語音的詞語識別率

表2 SNRpre≥0 dB的時頻塊經(jīng)不同算法增強(qiáng)后的其信噪比仍然大于等于0的比例

表3 SNRpre<0 dB的時頻塊經(jīng)不同算法增強(qiáng)后的其信噪比大于等于0的比例
3 結(jié) 論
本文分析了Hirsch、MS、MCRA、IMCRA和Conn_freq等五種噪聲譜估計算法對增強(qiáng)后語音可懂度的影響。詳細(xì)分析了在白噪聲背景下,五種算法在信噪比為-9 dB和5 dB條件下的噪聲譜估計,分析發(fā)現(xiàn)MS算法估計的噪聲譜相比其他算法偏低。為評價算法對語音可懂度的影響,選用譜減法對含噪語音作增強(qiáng)處理,并對不同噪聲、不同信噪比下語音增強(qiáng)前后的STOI值進(jìn)行了對比,發(fā)現(xiàn)經(jīng)MS算法處理后的語音可懂度高于其他算法。然后分析了增強(qiáng)前語音能量為主的時頻塊經(jīng)不同算法增強(qiáng)后的其信噪比仍然大于等于0的比例和增強(qiáng)前噪聲能量為主的時頻塊經(jīng)不同算法增強(qiáng)后的其信噪比大于等于0的比例,通過對比發(fā)現(xiàn),經(jīng)MS算法處理后的語音中,語音的能量大于噪聲的能量的時頻塊最多,這可能是MS算法相比其他噪聲譜估計方法具有更高語音可懂度的原因。
[1] Yuan W, Lin J, An W, et al. Noise estimation based on time-frequency correlation for speech enhancement[J]. Applied Acoustics, 2013, 74(5): 770-781.
[2] Lu Ching-Ta. Noise reduction using three-step gain factor and iterative-directional-median filter[J]. Applied Acoustics, 2014, 76(1): 249-261.
[3] Ming Ji. Crookes, Danny. An iterative longest matching segment approach to speech enhancement with additive noise and channel distortion[J]. Computer Speech and Language, 2014, 28(6): 1269-1286.
[4] Lim J. Evaluation of a correlation subtraction method for enhancing speech degraded by additive noise[J]. IEEE Transactions on Acoustics, Speech and Sinal Processing, 1978, 37(6): 471-472.
[5] Hu Y, Loizou P. A comparative intelligibility study of single-microphone noise reduction algorithms[J]. J. Acoust. Soc. Am., 2007, 122(3): 1777-1786.
[6] Loizou P, Kim G. Reasons why current speech-enhancement algorithms do not improve speech intelligibility and suggested solutions[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(1): 47-56.
[7] McAulay R, Malpass M. Speech enhancement using a soft-decision noise suppression filter[J]. IEEE Transactions on Acoustics, Speech and Signal Processing, 1980, 28(2): 137-145.
[8] McKinley B, Whipple G. Model based speech pause detection[C]// Acoustics, Speech, and Signal Processing, 1997. ICASSP-97., 1997 IEEE International Conference on. 1997, 2: 1179-1182.
[9] Meyer J, Simmer K, Kammeyer K. Comparison of one and two-channel noise-estimation techniques[C]// Proc. 5th International Workshop on Acoustics Echo and Noise Control, IEAENC-97. 1997, 137-145.
[10] Sohn J, Kim N, Sung W. A statistical model-based voice activity detection[J]. Signal Processing Letters, IEEE, 1999, 6(1): 1-3.
[11] Ris C, Dupont S. Assessing local noise level estimation methods: Application to noise robust ASR[J]. Speech Communication, 2001, 34(1): 141-158.
[12] Hirsch H, Ehrlicher C. Noise estimation techniques for robust speech recognition[C]// Acoustics, Speech, and Signa Processing, 1995. ICASSP-95., 1995 International Conference on. 1995, 1: 153-156.
[13] Martin R. Spectral subtraction based on minimum statistics[C]// European Signal Processing Conference. 1994, 1: 1182-1185.
[14] Cohen I, Berdugo B. Noise estimation by minima controlled recursive averaging for robust speech enhancement[J]. Signal Processing Letters, IEEE, 2002, 9(1): 12-5.
[15] Cohen I. Noise spectrum estimation in adverse environments: Improved minima controlled recursive averaging[J]. IEEE Transactions on Speech and Audio Processing, 2003, 11(5): 466-475.
[16] Sorensen K, Andersen S. Speech enhancement with natural sounding residual noise based on connected time-frequency speech presence regions[J]. EURASIP J, Applied Signal Process, 2005, 2005(18): 2954-2964.
[17] Li N, Bao C, Xia B, et al. Speech Intelligibility Improvement Using the Constraints on Speech Distortion and Noise Over-estimation[C]// Intelligent Information Hiding and Multimedia Signal Processing, Ninth International Conference on. IEEE, 2013: 602-606.
[18] Su Y, Tsao Y, Wu J, et al. Speech enhancement using generalized maximum a posteriori spectral amplitude estimator[C]// Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on. IEEE, 2013: 7467-7471.
[19] Djendi M, Scalart P. Reducing over- and under-estimation of the a priori SNR in speech enhancement techniques[J]. Digital Signal Processing, 2014, 32(2): 124-136.
[20] Chen Y, Wu J. Forward-backward minima controlled recursive averaging to speech enhancement[C]// Computational Intelligence for Multimedia, Signal and Vision Processing (CIMSIVP), 2013 IEEE Symposium on. IEEE, 2013: 49-52.
[21] Martin R. Noise power spectral density estimation based on optimal smoothing and minimal statistics[J]. IEEE Transactions on Speech and Audio Processing, 2001, 9(5): 504-512.
[22] 中文語言資源聯(lián)盟. http://www.chineseldc.org/
Chinese Linguistic Data Consortium. http://www.chineseldc.org/
[23] Varga A, Steeneken H. Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems[J]. Speech Communication, 1993, 12(3): 247-251.
[24] Berouti M, Schwartz R, Makhoul J. Enhancement of speech corrupted by acoustic noise[C]// Acoustics, Speech, and Signal Processing, IEEE International Conference on ICASSP’79. 1979, 4: 208-211.
[25] 張雪英. 數(shù)字語音處理及MATLAB仿真[M]. 北京: 電子工業(yè)出版社, 2010. 7.
ZHANG Xueying. Digital speech processing and MATLAB simulation[M]. Beijing: Publishing House of Electronics Industry, 2010, 7.
[26] Taal C, Hendriks R, Heusdens R, et al. An evaluation of objective quality measures for speech intelligibility prediction[C]// Proc. Interspeech. 2009. 2009: 1947-1950.
[27] Wang D, Kjem U, Pedersen M, et al. Speech intelligibility in background noise with ideal binary time-frequency masking[J]. J. Acoust. Soc. Am., 2009, 125(4): 2336-2347.
[28] Zhou J, Liang R, Zhao L, et al. Whisper Intelligibility Enhancement Using a Supervised Learning Approach[J]. Circuits, Systems, and Signal Processing, 2012, 31(6): 2061-2074.
Effects of noise spectrum estimation algorithms on speech intelligibility
ZHANG Jian-wei, TAO Liang, ZHOU Jian, WANG Hua-bin
(Key Laboratory of Intelligent Computing and Signal Processing of Ministry of Education, Anhui University, Hefei 230031, Anhui, China)
Noise spectrum estimation is a key step in single channel speech enhancement algorithms. Most of current speech enhancement algorithms are designed to improve speech quality, however, algorithms for increasing speech intelligibility are few. The traditional speech enhancement algorithms improve speech quality, while sacrificing speech intelligibility. In this paper, classical noise spectrum estimation algorithms are evaluated for their effects on speech intelligibility. Noise spectrum is estimated in different noise environments with SNRs between-9 dB and 3 dB. The spectral subtraction is thereafter used for speech denoising. The STOI(Short-Time Objective Intelligibility) value of the enhanced speech is computed. At last, according to the signal-to-noise ratio, the proportions of speech dominated time-frequency blocks under different noise environments are analyzed. Experimental results show that, compared with other noise estimation algorithms, the minimum statistics (MS) obtains high speech intelligibility because it retains more speech dominated time-frequency blocks after speech denoising.
noise spectrum estimation; spectrum subtraction; time-frequency blocks; MinimaStatistics(MS); Short-Time Objective Intelligibility(STOI); speech intelligibility
TP391
A
1000-3630(2015)-05-0424-07
10.16300/j.cnki.1000-3630.2015.05.009
2014-12-15;
2015-03-29
國家自然科學(xué)基金(61301219、61003131)、安徽省自然科學(xué)基金(1408085MF113)資助項(xiàng)目。
張建偉(1989-), 女, 山東莘縣人, 碩士研究生, 研究方向?yàn)檎Z音增強(qiáng)。
張建偉, E-mail: zhangjianwei.i.123@163.com
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
媽媽寶寶(2019年10期)2019-10-26 02:45:34
中國生殖健康(2019年3期)2019-02-01 06:12:26
鐵道通信信號(2018年11期)2019-01-19 01:15:08
電子制作(2018年11期)2018-08-04 03:25:42
鐵道通信信號(2018年2期)2018-04-18 12:18:10
鐵道通信信號(2016年11期)2016-06-01 12:11:32
鑿巖機(jī)械氣動工具(2016年3期)2016-03-01 04:00:25
中國病理生理雜志(2015年8期)2015-12-21 12:38:06
