一種基于關(guān)鍵幀的分布式視頻分析解耦機(jī)制
2015-10-20 09:13:12蔡曉東陳文竹
電視技術(shù) 2015年14期
蔡曉東,華 娜,吳 迪,陳文竹
(桂林電子科技大學(xué) 信息與通信工程學(xué)院,廣西 桂林 541004)
隨著視頻監(jiān)控網(wǎng)絡(luò)化的發(fā)展,視頻數(shù)據(jù)量急劇增長。然而這些視頻數(shù)據(jù)中,用戶真正需要的信息只是少部分,或者說真正需要監(jiān)視的只是發(fā)生概率很小的某些事件,因此通過海量數(shù)據(jù)獲取有價值的信息面臨巨大挑戰(zhàn)。為了處理海量的視頻數(shù)據(jù),不僅要優(yōu)化計算機(jī)視覺和機(jī)器學(xué)習(xí)的算法,而且需要強大的計算平臺。近年來云計算在國內(nèi)外進(jìn)行地如火如荼,一些開源的云平臺針對海量數(shù)據(jù)集的存儲和計算能力等問題提出了解決方案[1-2],最著名的是MapReduce計算模型,它可以自動并行處理海量數(shù)據(jù)。因此將云計算技術(shù)引入視頻處理領(lǐng)域,研究利用云計算處理視頻技術(shù)的相關(guān)問題,具有十分重要的研究意義。
在計算機(jī)視覺方面應(yīng)用MapReduce計算模型的研究越來越多。在文獻(xiàn)[3]中,使用MapReduce框架搜索相似的圖像并生成圖像標(biāo)簽;文獻(xiàn)[4]中,MapReduce框架被用來進(jìn)行多媒體數(shù)據(jù)挖掘,并展示了k-means聚類和背景減除的結(jié)果。通常MapReduce框架是對由文件系統(tǒng)自動分割的數(shù)據(jù)塊進(jìn)行并行處理,但文獻(xiàn)[5]中用第三方庫FFMPEG解碼視頻塊,文獻(xiàn)[6]中用MapReduce處理的數(shù)據(jù)都是預(yù)分塊后上傳到文件系統(tǒng)中的視頻塊,均不是直接對文件系統(tǒng)中大尺寸的視頻數(shù)據(jù)進(jìn)行處理。
云計算中采用字節(jié)流的形式傳輸數(shù)據(jù),而視頻數(shù)據(jù)是非結(jié)構(gòu)化的數(shù)據(jù),視頻的處理單位是視頻幀,視頻幀的大小并不固定,視頻幀之間也沒有明確的界限。因此,MapReduce框架可以直接對結(jié)構(gòu)化數(shù)據(jù)如文本、日志等進(jìn)行分塊并行處理,但不能直接對文件系統(tǒng)中大的視頻進(jìn)行處理,無法通過字節(jié)大小判別視頻幀,否則視頻塊會因為幀不完整、找不到關(guān)鍵幀、缺少頭文件等情況而導(dǎo)致解碼失敗。
本文提出一種基于關(guān)鍵幀的分布式視頻分析解耦機(jī)制,可直接對文件系統(tǒng)中大尺寸的視頻數(shù)據(jù)進(jìn)行并行化處理,避免視頻塊因找不到頭文件、找不到關(guān)鍵幀而出現(xiàn)解碼不成功的現(xiàn)象,提高了海量視頻處理效率。
1 相關(guān)工作
Hadoop[5]是一個分布式系統(tǒng)基礎(chǔ)架構(gòu),能夠?qū)A繑?shù)據(jù)以一種可靠、高效、可伸縮的方式進(jìn)行分布式處理,Hadoop框架中最核心的設(shè)計就是HDFS和MapReduce,HDFS為分布式計算存儲提供了底層支持,MapReduce提供了對數(shù)據(jù)的并行計算模式。
1.1 視頻數(shù)據(jù)在HDFS中的存儲
HDFS是根據(jù)Google的GFS設(shè)計而來的,HDFS可以容納超大型的文件,它將海量數(shù)據(jù)分布式存儲在集群的多個節(jié)點上,因此不受文件大小規(guī)定的限制,HDFS對客戶端寫入的大數(shù)據(jù)按照一定字節(jié)自動物理分割成數(shù)據(jù)塊,然后把每一個數(shù)據(jù)塊存儲在集群中的某個節(jié)點上,塊的大小默認(rèn)為64 Mbyte,塊是存儲的最小單位。
HDFS對存儲的數(shù)據(jù)按照字節(jié)大小進(jìn)行分塊,不考慮數(shù)據(jù)的存儲格式,當(dāng)存入視頻數(shù)據(jù)時,視頻數(shù)據(jù)分塊效果如圖1所示。圖1中第1、6、11、16幀是視頻的關(guān)鍵幀,而第2、8、14幀會被分割到兩個不同的塊中,是不完整的視頻幀,且在一個視頻塊中會有部分幀找不到關(guān)鍵幀。

圖1 HDFS中視頻數(shù)據(jù)分塊存儲效果
1.2 視頻數(shù)據(jù)在M apReduce中的并行處理機(jī)制
用MapReduce[7-9]處理一系列視頻數(shù)據(jù)塊如圖2所示。MapReduce是一個數(shù)據(jù)并行處理模型,先讀入HDFS中物理分割得到的數(shù)據(jù)塊Block,然后對數(shù)據(jù)塊進(jìn)行邏輯分片,通常默認(rèn)一個數(shù)據(jù)塊就是一個數(shù)據(jù)分片Split,一個數(shù)據(jù)分片Split對應(yīng)一個Map任務(wù),即Split為Map提供計算數(shù)據(jù)源。

圖2 MapReduce數(shù)據(jù)處理過程
2 分布式視頻分析解耦機(jī)制的實現(xiàn)
對二進(jìn)制輸入數(shù)據(jù)進(jìn)行并行處理,即需要將數(shù)據(jù)分成多個塊同時進(jìn)行處理。分塊的目的是使視頻數(shù)據(jù)的計算任務(wù)隨著數(shù)據(jù)分塊而分為幾個小的計算任務(wù)同時進(jìn)行。采用Hadoop默認(rèn)的方式無法保證各數(shù)據(jù)塊之間計算負(fù)載的均衡化,會出現(xiàn)Map任務(wù)失衡,整體效率下降。
本文提出的分布式視頻解耦和機(jī)制可以用MapReduce框架對HDFS中存儲的大視頻數(shù)據(jù)直接進(jìn)行并行處理,HDFS將存儲的視頻自動切割成視頻塊,用MapReduce對視頻塊進(jìn)行處理時,對視頻塊進(jìn)行邊界檢測,因為關(guān)鍵幀是獨立的編碼幀,解碼時不依賴于其他視頻數(shù)據(jù),因此在視頻塊的首尾邊界位置進(jìn)行關(guān)鍵幀檢測,若邊界位置是關(guān)鍵幀,則將該視頻塊作為一個視頻分片,否則繼續(xù)讀取下一個視頻塊的幀,直到遇到關(guān)鍵幀,并作為一個視頻分片,用MapReduce對數(shù)據(jù)分片進(jìn)行并行的解碼、計算機(jī)視覺處理等,實現(xiàn)了對大尺寸視頻數(shù)據(jù)自動分片,并直接從存儲位置中讀取視頻分片進(jìn)行并行處理。分布式視頻分析解耦策略設(shè)計如圖3所示。
2.1 獲取視頻數(shù)據(jù)并建立視頻索引
為了在云平臺上處理視頻數(shù)據(jù),視頻解碼器必須能夠從HDFS中讀取視頻。有兩種方法可以將視頻數(shù)據(jù)讀入解碼器,一是由MapReduce框架讀取HDFS中的視頻后傳給解碼器,二是將指定的視頻數(shù)據(jù)直接讀入解碼器,為了提高處理速度,本文采用第二種方法,但是Xuggler只能讀取本地文件,因此擴(kuò)展了Xuggler與HDFS進(jìn)行通信的接口,通過擴(kuò)展的接口讀取數(shù)據(jù)更加穩(wěn)定、快速。
分布式視頻解耦合機(jī)制是按照關(guān)鍵幀的位置對視頻進(jìn)行分片,因此本文用Xuggler對HDFS中存儲的視頻數(shù)據(jù)建立基于關(guān)鍵幀的索引,索引格式為“FrameNum,F(xiàn)ramePosition”,F(xiàn)rameNum是當(dāng)前幀幀數(shù),F(xiàn)ramePosition是每幀在視頻中的字節(jié)位置。

圖3 視頻分布式解耦流程
2.2 FrameRecordReader解析
RecordReader是插入MapReduce作業(yè)的輸入文件格式中。它將輸入流中的數(shù)據(jù)解析成key-value對,并將key-value對傳入map和reduce任務(wù)中進(jìn)行處理。
FrameRecordReader要實現(xiàn)兩個函數(shù)分別是initialize()和nextKeyValue()。結(jié)構(gòu)如圖4所示。
在initialize()中,先讀取視頻塊,每個視頻塊大小為64 M,獲取視頻塊起始字節(jié)位置和終止字節(jié)位置,讀取已建立的視頻幀索引,根據(jù)索引判斷視頻塊的起始字節(jié)位置和終止字節(jié)位置處是否是關(guān)鍵幀,若不是,則自適應(yīng)調(diào)節(jié)視頻分塊起始字節(jié)位置和終止字節(jié)位置,并按照起始字節(jié)位置和終止字節(jié)位置直接從HDFS中讀取視頻數(shù)據(jù),并給每個流數(shù)據(jù)追加視頻頭信息,寫成Xuggler可以讀取的視頻流形式AVInputStream。
AVInputStream是完成視頻塊分片的數(shù)據(jù)流,需要將AVInputStream傳入nextKeyValue()中進(jìn)行鍵值對解析,因此AVInputStream也需要實現(xiàn)能與HDFS進(jìn)行通信的接口。
在nextKeyValue()中,讀取initialize()中按關(guān)鍵幀分片得到的視頻分片AVIputStream,并對AVInputStream進(jìn)行解碼,得到AVPacket,將AVPacket轉(zhuǎn)換得到的Buffered Image作為value,將當(dāng)前視頻幀對應(yīng)的幀數(shù)作為key。這樣就解析出了key-value對,并將key-value對傳入Map進(jìn)行處理。

圖4 FrameRecordReader的結(jié)構(gòu)
3 實驗分析
3.1 實驗環(huán)境
硬件環(huán)境:華碩服務(wù)器,CPU為2個6核Intel(R)Xeon(R)CPU E5-2620處理器,內(nèi)存為64 Gbyte,通過KVM虛擬化技術(shù)搭建Hadoop集群,集群中設(shè)置1個主節(jié)點和3個子節(jié)點。
軟件環(huán)境:操作系統(tǒng)為64位的Centos6.6,在每個節(jié)點安裝JDK1.7.0,Hadoop2.2.0,F(xiàn)FMPEG,對FFMPEG封裝的Java開源庫Xuggler。
3.2 并行創(chuàng)建索引實驗結(jié)果分析
3.2.1 均衡性分析
該測試實現(xiàn)的功能是對HDFS中的視頻數(shù)據(jù)進(jìn)行解碼,測試視頻是AVI視頻,分辨率為1 920×1 080,測試使用的視頻具有不同的時長,分別是30 min、60 min、90 min和120 min,對視頻進(jìn)行并行處理時,使視頻分片含有不同數(shù)目的GOP,即視頻分片具有不同的長度,GOP是圖片組,表示兩個關(guān)鍵幀之間的圖片序列。
表1是在Hadoop默認(rèn)的分片方式下,不同長度的視頻解碼所需時間;表2是在按關(guān)鍵幀對視頻塊分片方式下,不同長度的視頻解碼所需時間。
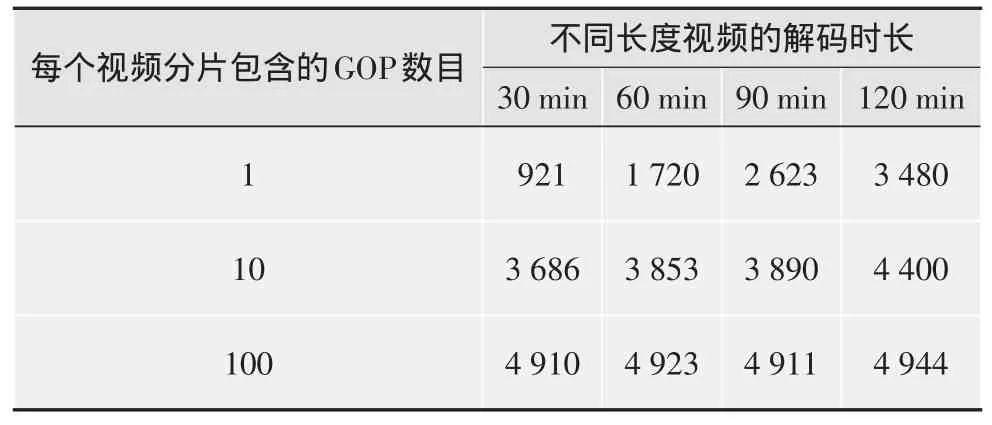
表1 不同長度的視頻在Hadoop默認(rèn)分片方式下解碼時長 s

表2 不同長度的視頻在按關(guān)鍵幀分片方式下解碼時長 s
比較表1、表2中的實驗數(shù)據(jù),當(dāng)視頻時長相同時,隨著GOP數(shù)目的增加,在本文提出的基于關(guān)鍵幀的分布式視頻解耦機(jī)制下對視頻分片后進(jìn)行解碼所需時間明顯減少,當(dāng)GOP數(shù)目相同時,隨著視頻時長的增長,用本文提出的方法對視頻進(jìn)行解碼所需時間更短,有效提高了視頻處理速度。同時按照關(guān)鍵幀對視頻塊進(jìn)行分片,視頻分片含有不同的GOP數(shù)目,有效提高了計算負(fù)載的均衡性。
3.2.2 性能分析
圖5示出了該分布式解耦合機(jī)制在不同節(jié)點數(shù)的集群上的性能。測試視頻是AVI視頻,分辨率為1 920×1 080,實驗表明,相同數(shù)據(jù)量的情況下,隨著集群節(jié)點個數(shù)的增加,處理視頻數(shù)據(jù)所需的時間近似線性減少,因此可以通過增加集群節(jié)點個數(shù)來有效減少響應(yīng)時間。
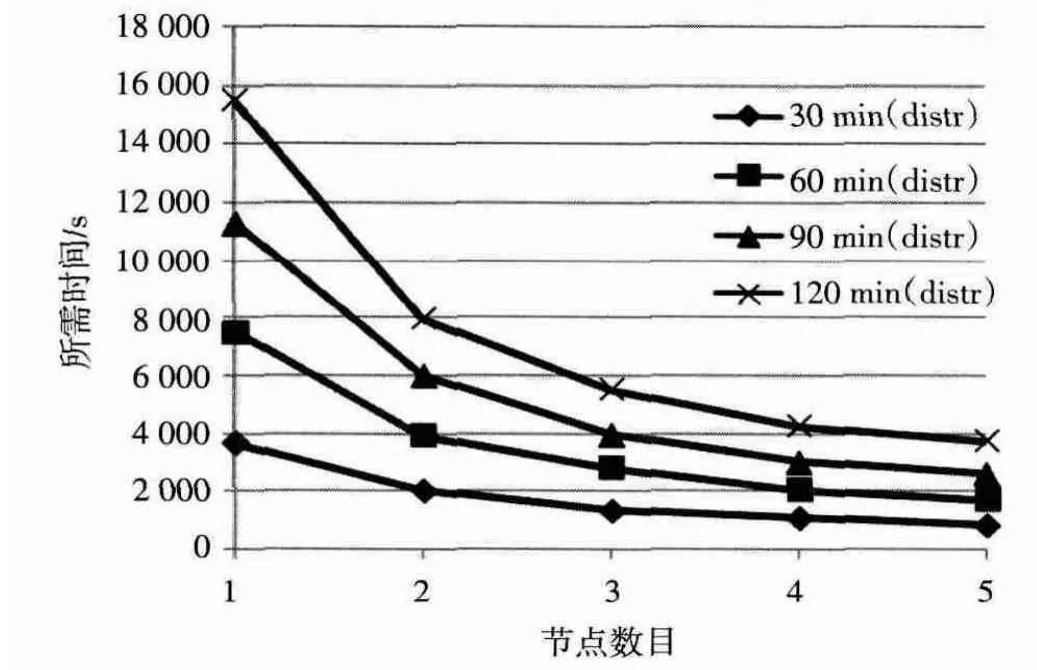
圖5 基于關(guān)鍵幀的分布式解耦機(jī)制在各集群上的性能
3.2.3 與FFMPEG解碼作比較
本實驗將本文所采用的分布式解耦機(jī)制與文獻(xiàn)[5]中所使用的分布式視頻解碼方式進(jìn)行比較,文獻(xiàn)[5]中是采用第三方庫FFMPEG對視頻分片進(jìn)行解碼,由于FFMPEG不能直接處理HDFS中的數(shù)據(jù),因此讀取數(shù)據(jù)占用了一定時間。實驗中測試視頻是H264格式的視頻,分辨率為640×360。如圖6所示,采用本文方法對同等大小的視頻進(jìn)行解碼,所需時間明顯少于文獻(xiàn)[5]中的視頻解碼方法,說明本文方法能夠有效地在Hadoop平臺上進(jìn)行視頻處理。
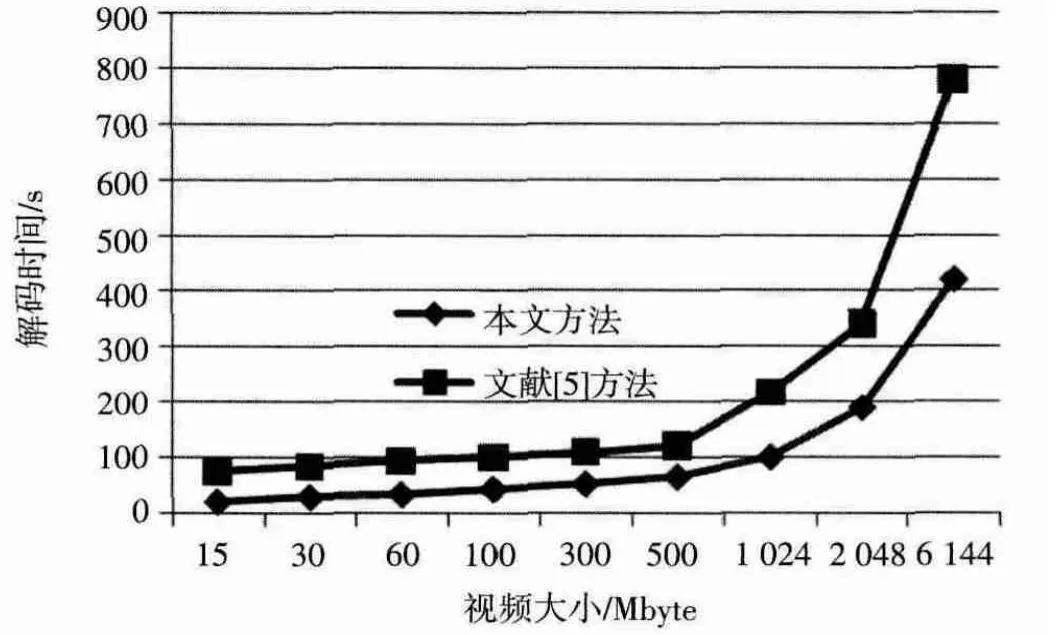
圖6 本文方法與文獻(xiàn)[5]方法對比
4 小結(jié)
經(jīng)過以上分析,基于關(guān)鍵幀的分布式視頻分析解耦機(jī)制通過對視頻塊按關(guān)鍵幀進(jìn)行分片后并行處理,解決了在云平臺上處理海量視頻數(shù)據(jù)出現(xiàn)的幀不完整、不能解碼的問題,提高了計算負(fù)載的均衡性,并在整體上提高了視頻處理效率。
[1] 方權(quán)亮,余諒.基于云計算的智能高清視頻監(jiān)控系統(tǒng)研究[J].微型機(jī)與應(yīng)用,2013,32(3):90-92.
[2] 孫偉.基于云計算的視頻監(jiān)控和資源整合優(yōu)化系統(tǒng)[J].電視技術(shù),2015,39(8):44-46.
[3] 劉炳均.基于超算平臺和Hadoop的并行轉(zhuǎn)碼方案設(shè)計[J].電視技術(shù),2014,38(7):123-126.
[4]WHITE B,YEH T,LIN J,et al.Web-scale computer vision using MapReduce for multimedia data mining[C]//Proc.the 10th International Workshop on Multimedia Data Mining.Washington DC:[s.n.],2010,7:1-10.
[5] 重慶大學(xué).一種基于Hadoop的視頻大數(shù)據(jù)分布式解碼方法:中國,201310203900.1[P].2013-09-04.
[6]KIM M,CUI Y,HAN S,et al.Towards efficient desion and imple-mentation of a hadoop-based distributed video transcoding system in cloud computing environment[J].International Journal of Multimedia and Ubiquitous Engineering,2013(2):213-224.
[7]DEAN J,GHEMAWAT S.MapReduce:simplified data processing on large clusters[C]//Proc.Symposium Conf.Opearting Systems Design & Implementation.[S.l.]:IEEE Press,2004:107-113.
[8] 李建江,崔健,王聃,等.MapReduce并行編程模型研究綜述[J].電子學(xué)報,2011,39(11):2635-2642.
[9] 李成華,張新訪,金海.MapReduce新型的分布式并行計算編程模型[J].計算機(jī)工程與科學(xué),2011,33(3):129-135.
