流式大數據下隨機森林方法及應用
2015-10-22 09:41:41劉迎春陳梅玲
西北工業大學學報 2015年6期
關鍵詞:方法
劉迎春,陳梅玲
(北京航空航天大學經濟管理學院,北京 100191)
流式大數據下隨機森林方法及應用
劉迎春,陳梅玲
(北京航空航天大學經濟管理學院,北京 100191)
流式計算形態下的大數據分析一直是當前需要解決的問題,而且研究成果和實踐經驗較少。隨機森林方法是目前應用較多的分類算法,但在流式計算應用場景中,數據所呈現出來的實時性、易失性、無序性等特征會使得算法準確度逐漸降低。針對這個問題,分析了隨機森林的算法特點,提出了根據決策樹的準確度進行隨機森林剪枝的思路。同時為了適應數據的變化,結合準確度間隔的概念提出生成、驗證并補充新決策樹的方法,最終形成可以不斷隨數據更新的隨機森林,滿足流式大數據環境對算法的要求。使用實際數據對改進后方法的可行性進行了驗證,證明新方法在真實流式大數據場景中有著更高的分類準確度,最后分析討論了隨機森林方法如何進一步研究改進的主題。
決策樹;隨機森林方法;大數據;流式計算;社交網站;搜索引擎;分類器;剪枝;客戶評分;分布式系統
在各應用場景中,大數據計算模式[1-4]可分為批量計算、流式計算2種。批量計算,指先對數據收集存儲,再對已經存儲靜態數據集中計算,發現數據價值。流式計算,指無法確定數據到來順序和時間,也無法將歷史數據全部存儲,而是當數據流動進來后在內存直接實時計算數據,輸出有價值的信息。
大數據批量計算技術的研究相對更成熟[5-6],例如開源的Hadoop系統、Google的MapReduce模型等,得到廣泛應用的系統就都是基于批量計算技術的[7]。對于更看重輸出結果的準確性、全面性的場景,批量計算更有優勢。
對于實時性要求更高、數據流量不確定、對數據準確度要求稍低的場景來說,流式計算具有明顯優勢[8-9]。與大量的批量計算技術研究相比,關于流式計算的研究較少。早期的流式計算研究是以數據庫環境中的流式數據計算為主。
但隨著互聯網大數據需求的不斷增長,滿足實時性、突發性、無限性分析要求的流式計算系統開始出現,例如Yahoo在2010年推出的S4流式計算系統[10]、Twitter在2011年推出的Storm流式系統、Facebook的DFP系統[11]等。這些系統各有其缺點,如何構建高可靠、高吞吐、低延遲、持續運行的大數據流式計算系統,是當前急需解決的問題。
本文分析了流式計算場景的特點,討論了流式計算技術應該具有的主要技術特性,并基于Breiman等人在2001年提出的隨機森林方法(random forest),設計了在互聯網行業這一典型的大數據流式計算應用場景中的流式計算方法,并利用真實數據進行了測試,驗證了方法的實際可行性。
1 介 紹
1.1流式計算介紹
流式大數據計算主要有以下特征:
1)實時性。流式大數據不僅是實時產生的,也是要求實時給出反饋結果。系統要有快速響應能力,在短時間內體現出數據的價值,超過有效時間后數據的價值就會迅速降低。
2)突發性。數據的流入速率和順序并不確定,甚至會有較大的差異。這要求系統要有較高的吞吐量,能快速處理大數據流量。
3)易失性。由于數據量的巨大和其價值隨時間推移的降低,大部分數據并不會持久保存下來,而是在到達后就立刻被使用并丟棄。系統對這些數據有且僅有一次計算機會。
4)無限性。數據會持續不斷產生并流入系統。在實際的應用場景中,暫停服務來更新大數據分析系統是不可行的,系統要能夠持久、穩定地運行下去,并隨時進行自我更新,以便適應分析需求。
1.2應用場景介紹
互聯網領域就是很好的流式大數據應用場景。該領域在日常運營中會產生大量數據,包括系統自動生成的用戶、行為、日志等信息,也包括用戶所實時分享的各類數據。互聯網行業的數據量不僅巨大,其中半結構化和非結構化所呈現的數據也更多。由于互聯網行業對系統響應時間的高要求,這些數據往往需要實時的分析和計算,以便及時為用戶提供更理想的服務。
流式計算在互聯網大數據中的典型應用場景如下:
1)社交網站。在社交網站中,要對用戶信息進行實時分析,一方面將用戶所發布的信息推送出去,另一方面也要為用戶及時發現和推薦其感興趣的內容,及時發現和防止欺詐行為,增進用戶使用體驗。
2)搜索引擎。搜素引擎除了向用戶反饋搜索結果以外,還要考慮和計算用戶的搜索歷史,發掘用戶感興趣的內容和偏好,為用戶推送推廣信息。
3)電子商務。電子商務側重于大數據技術中的用戶偏好分析和關聯分析,以便有針對性地向用戶推薦商品。同時,隨著大量電子商務開始內嵌互聯網消費金融服務,對用戶的風險分析和預警也是非常重要的。
可以預見,隨著技術的不斷發展、互聯網與物聯網等領域的不斷深入連接,未來要分析的數據量必然還會爆炸性增長。傳統的批量計算方式并不適合這類對響應時間要求很高的場景,能持續運行、快速響應的流式計算方法,才能解決這一方面的需求。
1.3隨機森林方法介紹
隨機森林是目前海量數據處理中應用最廣的分類器之一,在響應速度、數據處理能力上都有出色表現[10,13]。隨機森林是決策樹{h(x,θk),k=1,…}的集合H,其中h(x,θk)是元分類器,是用CART算法生成的1棵沒有剪枝的回歸分類樹;x為輸入向量,{θk}是獨立而且同分布隨機向量,決定每一棵決策樹的生長過程。
每個元分類器h∈H,都等價于從輸入空間X到輸出類集Y的映射函數。對輸入空間X中的每一條輸入xi,h都可以得到h(xi)=yi,yi為分類器h給出的決策結果。
定義決策函數D,則分類器集合H對輸入xi所得到的最終結果y就可以定義如下:

在隨機森林中,單棵樹的生長過程如下:
1)針對原始訓練集,使用Bagging方法在原始樣本集S中進行有放回的隨機數據選取,形成有區別的訓練集Tset。
2)采用抽樣的方式選取特征。假設數據集一共有N個特征,選擇其中M個特征,M≤N。每個抽取出來的訓練集,使用隨機選取的M個特征來進行節點分裂。
3)所有生成的決策樹自由生長,不進行剪枝。每一棵決策樹的輸出結果之間可采用簡單的多數投票法(針對分類問題)或者結果平均法(針對回歸問題)組合成最終的輸出結果。
隨機森林方法是組合分類器算法的一種,是決策樹的組合。它擁有Bagging和隨機特征選擇這2種方法的優點。在大數據環境下,隨機森林方法還有以下優點:
①隨機森林方法可以處理大數據量,能夠應對突發性數據;
②隨機森林方法生成較為簡單的決策樹,易于解讀;
③隨機森林方法適用于分布式和并行環境,擴展性好,適用于對分布式架構有很高要求的流式大數據處理環境;
4)決策樹分類器非常簡單,能以極高效率對新數據進行處理,適用于流式大數據環境下對響應速度要求高的特點;
在流式大數據環境下,隨機森林方法也存在一些問題,其中最核心的問題,就是流式大數據環境中數據具有實時性和易失性的特點,經典隨機森林方法難以適應。以訓練集數據為基礎所生成的決策樹會過期,對新數據進行分類的準確度下降。
2 流式大數據環境下的算法改進
2.1方法改進思路
以往對隨機森林方法的改進主要集中在幾個方面:
將隨機森林與Hadoop、MapReduce等計算框架結合,實現分布式隨機森林方法,提高算法的處理效率。
對數據進行預處理,降低數據集的不平衡性,以此提升算法在非平衡性數據集上的準確度和分類性能。
針對標準隨機森林方法采用C4.5作為節點分裂算法的情況,用效率更高的節點分裂算法如CHI2來替換C4.5,可以提高算法處理大數據集的能力。
基于分類器相似性度量和分類間隔概念,對冗余的分類器進行修剪,以取得更好的分類效果與更小的森林規模。
這幾種改進方法可以有效地在特定環境下提高隨機森林算法的表現,但都不能完全滿足流式大數據環境對算法的要求。鑒于流式大數據算法需求所表現出來的鮮明特征,從流式大數據的特征出發,對經典的隨機森林方法進行改造,思路如下:
1)使用隨機森林方法實時處理數據,由于隨機森林是一種比較簡單的分類器,對數據的響應時間可以得到保障,能夠滿足實時性要求。
2)僅對一段時間內的數據進行存儲,在內存可用的條件下處理少量數據,這樣就可以解決流式大數據的易失性和無限性特點。
3)由于數據的無序性,經典隨機森林所產生的分類器無法滿足所有的輸入數據,必須令分類器能夠隨著新數據的輸入不斷更新,保持對數據的敏感性和準確度。因為數據的易失性,所以分類器的更新就必須基于算法所臨時保存的有限訓練數據進行。
4)分類器更新方法必須是可伸縮的、高效的,不能影響到分類器對數據的正常處理。
2.2改進后的隨機森林方法
首先定義隨機森林中決策樹h的準確度(accurate)Ah:
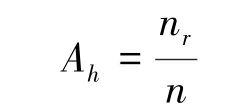
式中,nr是決策樹h給出正確結果的次數,n是決策樹h所處理過的所有數據數量。準確度給出了在一定時間內某棵樹給出正確結果的比例。
在回歸問題中,決策樹h給出的分類結果如與最終結果一致,則認為該決策樹得出了正確結果。計算決策樹h給出結果xi與最終結果之間的差值,并取其標準差作為h的準確度:
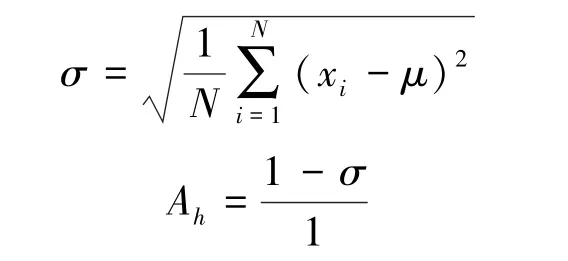
準確度衡量一棵樹在一段時間內判定結果的準確程度。算法在執行過程中跟蹤每棵樹的準確度,并定期對隨機森林進行更新,淘汰其中準確度最低的樹:
1)按照標準的隨機森林方法構造決策樹群H。
2)為每一棵決策樹h,h∈H建立1張記錄表Th,記錄隨機森林在處理數據過程中生成的結果。
3)一段時間后,對所有決策樹的結果記錄表進行掃描,刪除其中準確度最低的樹。
通過準確度進行篩選后,森林中樹的數量會越來越少,實現決策樹集的剪枝。但數量的過分減少,也會造成整個決策樹集在準確度上的降低[11]。
為了保持一定數量的決策樹,在剪枝的同時,也要對數據集進行跟蹤,生成新的決策樹來保持整個森林的質量。為了從數據集中篩選出對生成新的決策樹更有用的樣本,引入間隔(margin)定義如下:間隔指隨機森林在1條給定樣本數據(x,y)上的整體決策正確度,定義為:
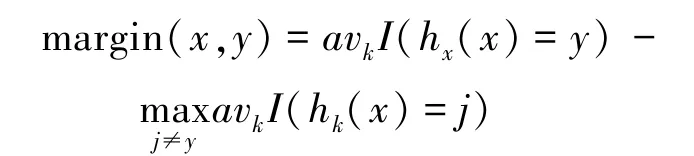
式中,avk()是一個求均值函數,I()是一個度量函數。如果在隨機森林中大部分決策樹對樣本(x,y)得到正確結果,則margin(x,y)大于零。如果margin(x,y)小于零或某一閾值,則說明該樣本被大部分決策樹識別失誤,算法對該樣本得出了錯誤結論。
margin(x,y)大于零的樣本,說明決策樹集可以得到正確結果。與已有的決策樹相似度高的樹并不會提高整個森林的準確度,此類樣本不需要再次處理。為了讓新生成的決策樹能夠提高整個森林的準確度,記錄margin(x,y)小于等于零的樣本,形成新的訓練數據集S′。數據集S′的特點,是只占當前數據集S中的一小部分,但其數據特征與其他數據不同。
在數據集S′上使用隨機森林方法,獲得一個新的決策樹集合{h′(x,θk),k=1,…}。數據集S′只代表了全部數據集中的一部分數據,在S′中篩選一定比例的決策樹,加入原來的決策樹集合中。
根據S′與S之間的比例確定要篩選出的決策樹數量:
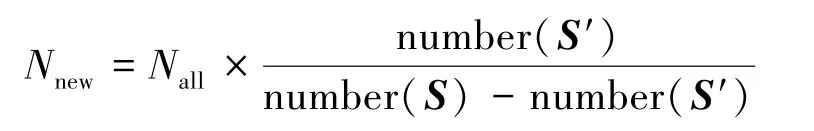
篩選方法可以有以下幾種:
S′篩選法:利用S′進行檢驗,并按照準確度對所有決策樹排序,選擇其中準確度最高的Nnew棵決策樹。
S篩選法:利用全部數據集S進行檢驗,并按準確度對所有決策樹排序,選擇準確度最高的Nnew棵樹。
Margin篩選法:計算每棵樹在數據集S′上的margin均值與margin方差之比[18],作為每一棵決策樹的重要性衡量指標,選擇最重要的Nnew棵樹。
改進后的隨機森林方法流程如圖1所示。
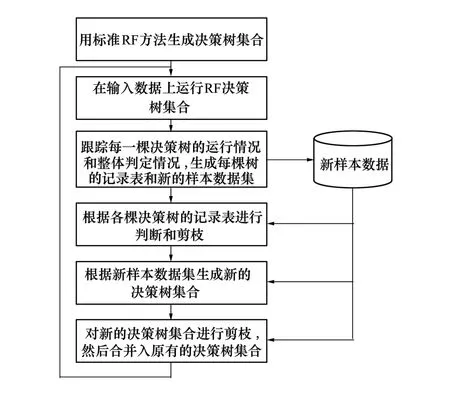
圖1 改進后隨機森林方法流程圖
①使用初始訓練數據集S生成最初的隨機森林H;
②使用隨機森林H對當前待處理的數據集Si進行分類:
a)用隨機森林中的每一棵樹hj對Si中的每一條數據xj進行分類;
b)記錄每一棵樹和每一條數據的分類結果,同時計算該條數據分類結果的間隔值margin(xj,y);
c)如果margin(xj,y)小于給定閾值,則將xj加入新訓練數據集S′。
③Si分類完畢后,計算每棵樹的準確度,并進行剪枝;
④在新訓練數據集S′上執行隨機森林方法,生成新的隨機森林H′;
⑤對新的隨機森林進行剪枝,將剪枝后的H′與H合并,形成新的隨機森林H;
⑥清空訓練數據集S′,開始處理下一批數據。
2.3新隨機森林方法的優點
新的隨機森林方法有著以下優點:
1)新方法每次所處理的數據集是有限的,在實際應用中,可以根據內存大小設計每次處理的數據集大小,保證數據的實時計算和計算效率;
2)新方法中,需要存儲的只有結果記錄表和新訓練數據集,相比原始數據流小了很多,滿足流式大數據的易失性特點,在大數據量下的伸縮性更好;
3)對新數據的處理只需要使用隨機森林進行驗證和投票,執行效率高,能夠實時反饋數據的處理結果;
4)該系統可以持續地更新運行下去,并能夠不斷使用數據的新特性來更新自身,滿足流式大數據環境的無序性和無限性特點。
3 數據驗證
3.1測試數據集
測試數據集為來自互聯網行業的客戶信息數據。數據量為20萬條,5年時間跨度,每個季度的數據量為1萬條。數據包括1個目的類別(客戶值:高/低)和如表1所示的16個特征屬性。
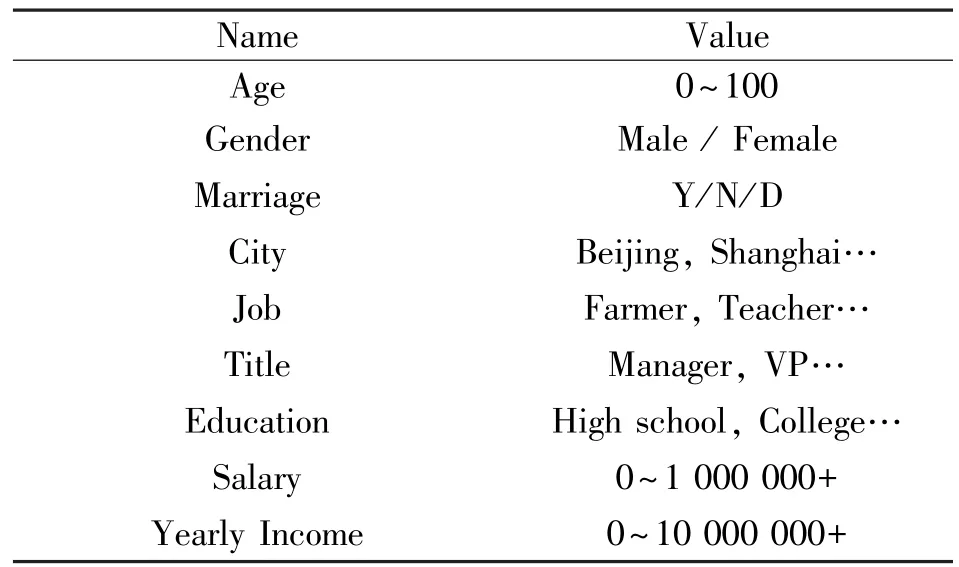
表1 測試數據集
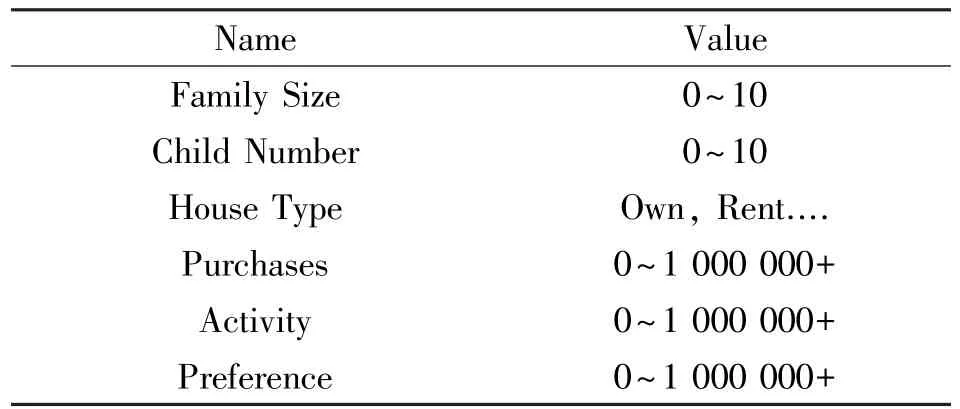
續表1
為了驗證改進后隨機森林算法的有效性,使用第1年第1季度的1萬條數據作為初始化訓練集,利用這些數據建立最初的隨機森林,樹的數量ntree=100。
3.2數據模式的變化對算法的影響
以第1年第1季度的1萬條數據作為初始化訓練集,建立隨機森林,并利用建好的隨機森林對后面的流式客戶數據進行處理,每個季度為1個周期。隨著時間的變化,原有隨機森林會逐漸變得不適應新的數據,客戶價值評級的準確度隨時間降低,從第1季度的93%下降到第5年的81%。
定義剪枝數量為50%,用改進后的隨機森林方法生成新的決策樹,加入到原有的隨機森林中。使用2.2節所描述的不同決策樹篩選方法,改進后的隨機森林方法表現如圖2所示。
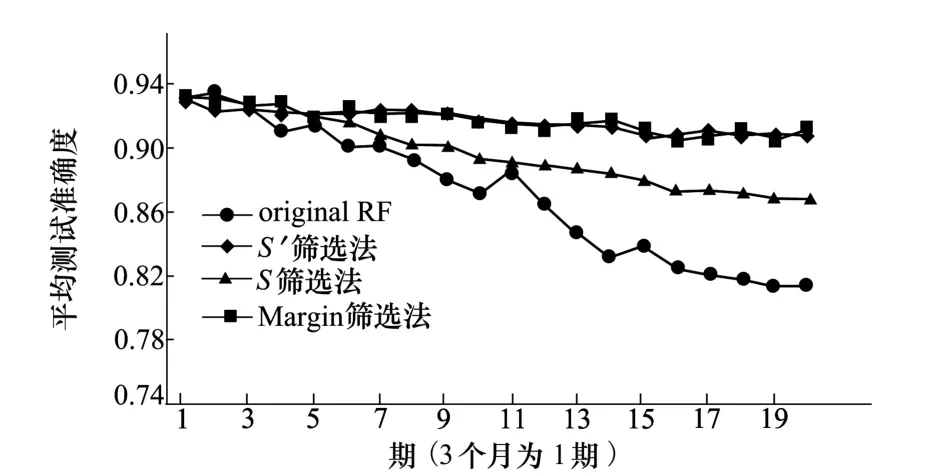
圖2 改進后隨機森林方法的準確度比較
可以看到,與原有的隨機森林方法相比,改進后的隨機森林方法對數據模式的變化有明顯更好的適應性,隨著時間的變化整個森林也在緩慢更新,改進后方法的準確度一直穩定保持在90%以上。
在篩選新決策樹的方法中,使用在新樣本數據集S′上的準確度進行篩選(S′篩選法)和使用每棵樹的margin均值與margin方差之比篩選(margin篩選法),都可以得到很好的效果,方法之間差別很小。使用數據集S進行篩選的方法(S篩選法)也可以提高準確度,但其準確度逐漸下降到87%,不如另外2種方法。
假設不考慮內存限制,在每一季度結束后使用另外2種模式來更新隨機森林:
模式1:每次都使用從最開始到當前的全部數據來重新訓練生成隨機森林;
模式2:每次都使用上一季度的全部數據來重新訓練生成隨機森林;
模式3:使用新的隨機森林方法來訓練生成隨機森林;
以上3種模式下的隨機森林方法表現如圖3所示。
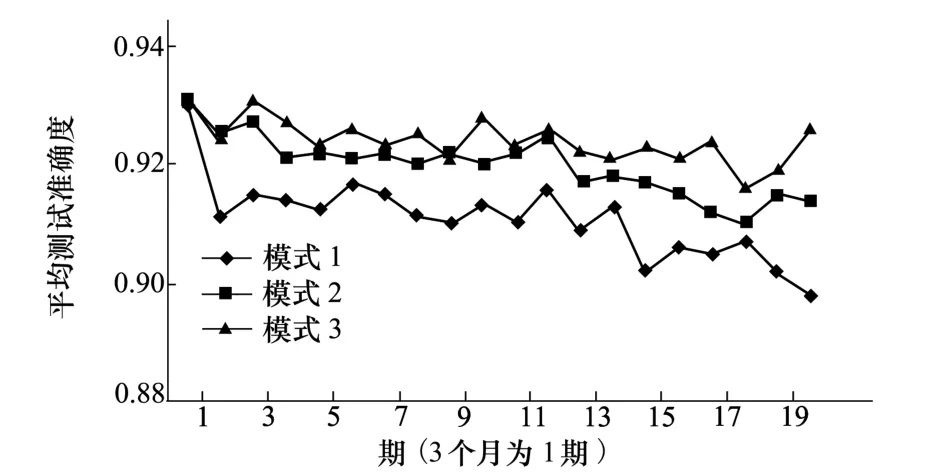
圖3 不同模式隨機森林方法的準確度比較
可以看到,模式3的準確度是最優的,模式2的準確度稍差,但是也較為平穩,模式1的準確度最差,隨數據量增大下降較快。
這3種模式分別所需要耗費的存儲空間如圖4所示。
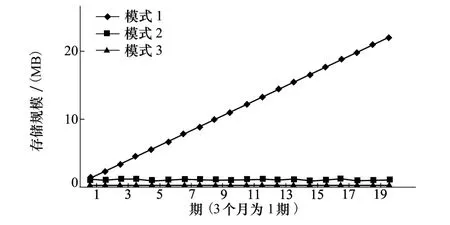
圖4 不同模式隨機森林方法所需存儲比較
可以看出,模式1所需要的存儲空間隨時間和數據量線性增長,所需要的空間最大。模式2所需要的存儲空間與每個周期的總數據量相關,比模式1要少很多,在流量變化不大時會保持平穩。模式3所需要的空間最少,遠小于模式2,而且其波動幅度僅與算法當前準確度有關,與總的數據流量關系不大。
4 結 論
本文在原有隨機森林方法的基礎上,提出了一種能夠適應流式大數據環境的新隨機森林方法。新的方法可以在流式大數據只經過分類器1次的情況下工作,不需要對海量的歷史數據進行存儲和掃描,對存儲空間的要求很低;還可以根據流式大數據的變化進行自我調整,適應新的數據,在保證數據吞吐量和處理效率的同時,保持對數據的處理準確度。
在使用真實互聯網行業流式大數據場景試驗表明,新的隨機森林方法可以解決互聯網行業流式大數據場景所遇到的實際問題,驗證了其有效性。
但該方法在其他類型的數據集上是否通用,剪枝的判定函數是否還可以有所提高,新決策樹所占的比例應該是多少合適以及如何將改進后的隨機森林算法與Storm、S4等分布式大數據處理架構結合,實現更好的系統容錯、資源調度、負載均衡性能等有待探討。
[1] 孟小峰,慈祥.大數據管理:概念、技術與挑戰[J].計算機研究與發展,2013,50(1):146-169
Meng X F,Ci X.Big Data Management:Concepts,Techniques and Challenges[J].Journal of Computer Research and Development,2013,50(1):146-169(in Chinese)
[2] Lim L,Misra A,Mo T L.基于節能智能手機的連續處理傳感器數據流自適應數據采集策略[J].分布式和并行數據庫,2013,31(2):321-351
Lim L,Misra A,Mo T L.Adaptive Data Acquisition Strategies for Energy-Efficient,Smartphone-Based,Continuous Processing of Sensor Streams[J].Distributed and Parallel Databases,2013,31(2):321-351(in Chinese)
[3] Li B D,Mazur E,Diao Y L.SCALLA:可伸縮的單通過分析用Map Reduce平臺[J].ACM數據庫系統通訊,2012,37 (4):1-43
Li B D,Mazur E,Diao Y L.SCALLA:A Platform for Scalable One-Pass Analytics Using Map Reduce[J].ACM Trans.on Database Systems,2012,37(4):1-43(in Chinese)
[4] Yang D,Rundensteiner E A,Ward M.數據流中的鄰近模式挖掘[J].信息系統,2013,38(3):331-350
Yang D,Rundensteiner E A,Ward M.Mining Neighbor-Based Patterns in Data Streams[J].Information Systems,2013,38 (3):331-350(in Chinese)
[5] 李國杰,程學旗.大數據的研究現狀與科學思考[J].中國科學院院刊,2012,27(6):647-657
Li G J,Cheng X Q.Research Status and Scientific Thinking of Big Data[J].Bulletin of Chinese Academy of Sciences,2012,27 (6):647-657(in Chinese)
[6] 王元卓,靳小龍,程學旗.網絡大數據:現狀與展望[J].計算機學報,2013,36(6):1125-1138
Wang Y Z,Jin X L,Cheng X Q.Network Big Data:Present and Future[J].Chinese Journal of Computers,2013,36(6):1125-1138(in Chinese)
[7] 覃雄派,王會舉,杜小勇,王珊.大數據分析——RDBMS與MapReduce的競爭與共生[J].軟件學報,2012,23(1):32-45
Qin X P,Wang H J,Du X Y,Wang S.Big Data Analysis:Competition and Symbiosis of RDBMS and Map Reduce[J].Ruan Jian Xue Bao/Journal of Software,2012,23(1):32-45(in Chinese)
[8] Kobielus A.大數據架構中流式計算技術的角色.2013.http://ibmdatamag.com/2013/01/the-role-of-stream-computing-inbig-data-architectures/
Kobielus A.The Role of Stream Computing in Big Data Architectures.2013.http://ibmdatamag.com/2013/01/the-role-ofstream-computing-in-big-data-architectures/(in Chinese)
[9] 孫大為,張廣艷,鄭緯民.大數據流式計算:關鍵技術及系統實例[J].軟件學報,2014(4):839-862
Sun D W,Zhang G Y,Zheng W M.Big Data Stream Computing:Technologies and Instances[J].Journal of Software,2014 (4):839-862(in Chinese)
[10]Neumeyer L,Robbins B,Nair A,Kesari A.S4:分布式流計算平臺.第十屆IEEE數據挖掘國際會議(ICDMW 2010).Sydney:IEEE Press,2010.2010.170-177
Neumeyer L,Robbins B,Nair A,Kesari A.S4:Distributed Stream Computing Platform.In:Proc.of the 10th IEEE Int'l Conf. on Data Mining Workshops(ICDMW 2010).Sydney:IEEE Press,2010:170-177(in Chinese)
[11]Borthakur D,Sarma JS,Gray J,Muthukkaruppan K,Spigeglberg N,Kuang HR,Ranganathan K,Molkov D,Mennon A,Rash S,Schmidt R,Aiyer A.臉書中Apachi Hadoop的實時應用.ACM數據管理國際會議(SIGMOD 2011 and PODS 2011). Athens:ACM Press,2011:1071-1080
Borthakur D,Sarma JS,Gray J,Muthukkaruppan K,Spigeglberg N,Kuang HR,Ranganathan K,Molkov D,Mennon A,Rash S,Schmidt R,Aiyer A.Apache hadoop goes realtime at Facebook.In:Proc.of the ACM SIGMOD Int'l Conf.on Management of Data(SIGMOD 2011 and PODS 2011).Athens:ACM Press,2011:1071-1080(in Chinese)
Random Forest Method and Application in Stream Big Data Systems
Liu Yingchun,Chen Meiling
(School of Economics and Management,Beihang University,Beijing 100191,China)
Stream computing is an important form of big data computing.Random forest method is one of the most widely applied classification algorithms at present.From the actual requirements,random forest method faces not only huge number of features but also constantly changing data pattern over time.The accuracy of a random forest algorithm without self renewal and adaptive algorithm will gradually reduce over time.Aiming at this problem,this paper analyzes the characteristics of random forest algorithm,gives a new pruning idea according to the accuracy of the decision trees.In order to adapt to the change of data,a new random method based on margin is presented.This new method can update itself constantly and can be applied in stream big data environments.Using the actual data,the new method is verified has higher accuracy in classification,and analysis and discussion of how to further research and improve the random forest method in big data environment.
decision tree,random forest,big data,stream computing,social network,searching engine,classifier,pruning,customer rating,distributed system
TP391
A
1000-2758(2015)06-1055-07
2015-04-24
劉迎春(1980—),女,北京航空航天大學博士研究生,主要從事大數據、分布式系統研究。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
