廣告點擊率預估技術綜述
2015-10-31 08:55:08陳巧紅余仕敏賈宇波
浙江理工大學學報(自然科學版) 2015年11期
陳巧紅,余仕敏,賈宇波
(浙江理工大學信息學院,杭州310018)
廣告點擊率預估技術綜述
陳巧紅,余仕敏,賈宇波
(浙江理工大學信息學院,杭州310018)
廣告點擊率的預估是計算廣告學領域的重要研究內容,準確的廣告點擊率預估可以提高真實的廣告點擊率,增加收益。邏輯回歸模型、支持向量機模型、貝葉斯模型、神經網絡模型等模型適用于歷史廣告點擊數據豐富的情況,適用無歷史廣告點擊數據和廣告點擊數據稀疏的模型包括層次聚類模型、相似項預估模型、因子分解機等模型,而時間空間模型、層次模型則適用上述所有廣告點擊數據的情況。根據不同的廣告數據特征,采用不同的模型,可以獲得很好的預估效果。
廣告點擊率;預估模型;神經網絡;因子分解機
0 引 言
廣告點擊率(click-through rate,CTR)是指在廣告顯示中廣告被用戶點擊的概率,廣告點擊率的預估就是根據廣告數據和用戶數據來預估廣告點擊率。現在很多搜索公司例如百度聯盟和Google AdSense都是采用點擊付費(cost per click,CPC)[1],點擊付費是現在主流的付費方式,這類付費機制最適合交易型廣告,此類廣告的收益就是點擊次數和每次點擊的付費金額的乘積。研究顯示,用戶點擊廣告的概率性與廣告的投放位置有很大的相關性[2],要獲得最大的收益就是要把點擊率大的廣告投放在靠前的位置。根據精確的CTR預測來確定投放的順序,在線地在返回頁面中投放廣告[3]。
為了預測廣告的點擊率,要充分考慮影響廣告點擊率的因素,例如廣告自身的影響和廣告瀏覽者的影響相關性,上下文內容的相關性等因素,從而進一步提高廣告的點擊率,使點擊次數和每次點擊的付費金額的乘積變大,以此擴大搜索引擎的收益。
1 在線廣告點擊率預估流程
圖1所示廣告點擊率預估流程,數據包括廣告日志數據以及用戶數據,根據不同模型的要求提取相應的特征數據,這些特征數據通過歸一化或是規范化后,輸入到點擊率預估模型訓練,通過預估出的點擊率再進行排序,確定廣告的投放位置,提高真實的點擊率,從而擴大收益。

圖1 點擊率預估系統流程
廣告點擊率預估模型就是利用機器學習算法模型以及概率統計模型去預估廣告的點擊率,如圖2所示。其中基于歷史廣告數據豐富的預估模型,本文分別介紹邏輯回歸模型[4]、貝葉斯模型[5-8]、基于決策樹模型[9-10]、遞歸神經網絡模型[11]、支持向量機模型[12-13]、混合模型[14]和COEC模型[15]。基于稀疏廣告數據和新廣告數據的預估模型,本文介紹基于層次的預估模型[16-18]、相似項點擊率預估模型[19]、基于先驗概率的實時點擊預估模型[20]、時間空間模型[21]]和因子分解機模型[22]。
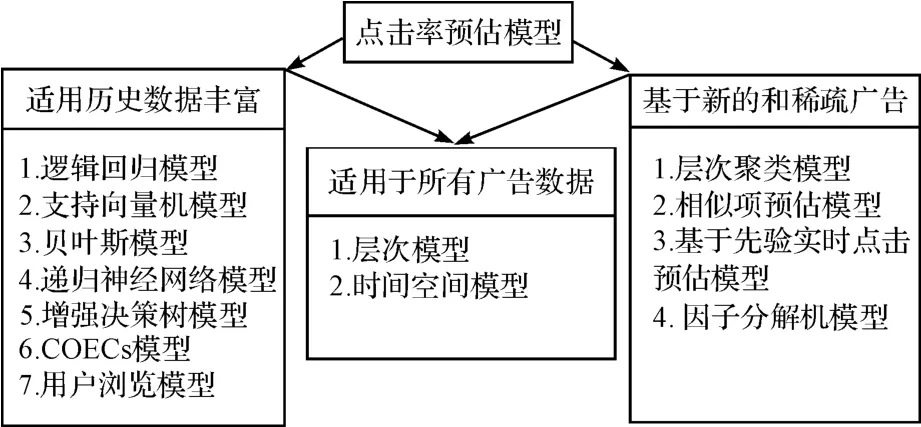
圖2 廣告點擊率的預估模型
圖3所示的是廣告點擊率預估常用的評估方法,常用的有KL距離(KL-Divergence)[20]和ROC曲線下面積(area under curve,AUC)方法[21]。

圖3 廣告點擊率模型的評估方法
2 廣告點擊率預測的模型
2.1基于歷史數據豐富的預估模型
在廣告本身的歷史數據點擊數據豐富的情況下,預測該類型的廣告要充分利用廣告的歷史點擊數據,基于邏輯回歸的預估模型、基于貝葉斯網絡的預估模型、基于支持向量機的預估模型、基于神經網絡的預估模型和基于決策樹的預估模型等模型在歷史數據豐富的情況下可以得到很好的訓練,最終獲得很好的預估效果。
2.1.1基于邏輯回歸預估模型
Richardson等[4]采用邏輯回歸模型(logistic regression model)去預估廣告點擊率,目前很多公司的廣告點擊率預估都是基于邏輯回歸的預估模型。該模型的特點就是簡單且非常適合解決概率預估問題,其核心計算公式為:

式(1)中的i是廣告的第個特征的數值,是廣告的第i個特征的學習權值。
該文使用L-BFGS(limited-memory broydenfletcher-goldfarb-shanno)方法(該方法是擬牛頓方法的一個優化算法)來訓練邏輯回歸模型,損失函數使用零均值和標準差的正態分布的交叉熵函數,每一個廣告特征都歸一化為期望值為0、單元標準差的數,該歸一化也應用于之后的訓練和測試廣告特征數據集。模型效果評估采用的是KL距離,文中的KL距離是模型預測的CTR和真實的CTR的距離。KL距離簡化了log似然模型,忽略測試數集的熵。作者還增加一個均方差(mean squared error,MSE)作為一個評估指標。由于邏輯回歸模型采用最大似然估計,需要大量數據以保證性能,所以不適合對稀疏廣告數據的預估。
2.1.2基于支持向量機算法的預估模型
Joachims[5]提出了從web搜索引擎日志中挖掘點擊數據,利用支持向量機實現對廣告點擊率的預估。支持向量機(support vector machine,SVM)利用核函數將一個向量映射到比其自身更高維的空間,在高維空間建立一個最大間隔的超平面。在分隔超平面兩邊各有一個與之平行的超平面,最大化平行超平面之間的間隔,平行超平面距離越大,分類效果越好。基于核函數,支持向量機可以處理多維非線性數據。該文利用點擊數據通過支持向量機來預估點擊率,從而提高搜索引擎的檢索能力,在沒有明確的反饋信息和沒有人工參數優化的情況下,該模型可以自動適應一些特殊的參數選擇。
2.1.3基于貝葉斯網絡的預估模型
Chapelle等[6]提出動態貝葉斯網絡模型,作者介紹了滿意度的概念,利用這個概念去分別模擬登陸頁面的相關性和搜索結果頁面可感知的相關性。動態貝葉斯網絡模型是用來模擬用戶瀏覽行為,并且認為只有用戶看到鏈接并且認為該鏈接與用戶所要獲得的信息有關的情況下才去點擊這個鏈接,用戶基于文檔觀察相關性決定是否要點擊和通過結果做出一個線性橫向選擇。如果用戶不滿意點擊的鏈接他們會選擇點擊下一個鏈接(基于真實的相關性)。
Guo等[7]提出基于貝葉斯結構的點擊鏈模型(click chain model in web search),類似鏈表結構,所以該模型具有很好的擴展性。將文檔內容的相關性和用戶點擊下一個鏈接的概率作為相關性后驗參數來建立模型的。
Graepel等[8]提出在線貝葉斯概率回歸模型(online bayesian probability regression),該模型基于特定廣告特征,所以很難準確做到個性化推薦。
Dupret等[9]提出了一種用戶瀏覽模型的點擊率估算方法,利用點擊日志預測文檔的點擊率,假設每次用戶點擊行為都是互相獨立,將日志內容的相關性和位置距離作為參數,利用EM(expectation maximization)算法迭代計算出所有參數的最大似然估計,再利用交叉檢驗的方法進行性能評估。
基于貝葉斯網絡的模型,當數據發生變化時模型必須重新訓練,耗時過長,且對新廣告數據無法預估。2.1.4 基于神經網絡的預估模型
Zhang等[10]提出了利用遞歸神經網絡(recurrent neural networks,RNN)來預測搜索廣告的點擊率問題。遞歸神經網絡是在多層神經網絡的中間層建立一種組合的遞歸網絡,用于取代一般的多層網絡,并依次對被控對象的動態特性進行直接的學習,通過調整其中有關參數,以獲得所需的最優控制輸入,過去的一些工作只是將單獨的廣告曝光作為輸入去預測點擊概率,并沒有考慮到不同廣告曝光的依賴性,而且過去在時間序列的分析常常也只是關注于構建數據序列趨勢或是周期性模式。近些年來的一些研究利用RNN來解決數據的時間依賴的問題。例如RNN語言模型[11]成功的利用大量語言庫中的大跨度連續的信息,獲得了比傳統神經網絡語言模型更好的效果。RNN由于它的特殊的遞歸神經網絡的結構使其有很大的能力去利用數據間連續的依賴關系。Michael Auli等認為每個用戶的廣告瀏覽歷史可以作為一個序列,從而產生了固有的內部依賴關系。神經網絡的輸入量必須是二元值,基于BPTT(back propagation through time)算法的RNN框架如圖4所示,實驗結果表明,比起神經網絡和邏輯回歸模型該模型的預測廣告點擊率更加準確。模型的評測標準采用的是AUC(area under roc curve)和RIG(relative information gain)。
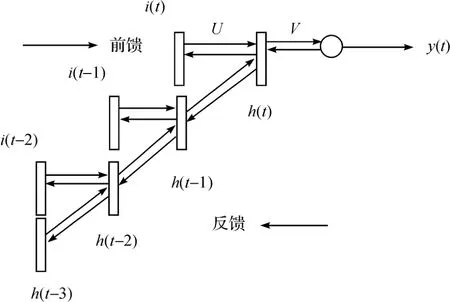
圖4 RNN結構框架
2.1.5基于決策樹的點擊率預估模型
Dave等[12]在文中從廣告數據中提取相似性特征,再利用梯度增強決策樹(gradient boosting decision tree,GBDT)作為一個回歸模型訓練相似特征來預估廣告點擊率。GBDT不像傳統的決策樹模型只有一棵決策樹,而是由多棵決策樹組成的。Boosting的基本思想是將一系列弱分類器組合起來,構成一個強分類器,也就是讓每棵樹不需要學太多的東西而是學一點點,再將每棵樹學到的知識累加起來組合成一個強大的模型。它的思想起源于Valiant提出的PAC(probably approximately correct)學習模型。
Rofimov等[13]提出了基于強分類決策樹(boosting tree)的一種機器學習的算法Matrix Net,它是梯度提升機器模型(gradient boosting machine,GBM)算法中采用隨機上升(stochastic boosting)的修改版算法。Matrix Net算法繼承了GBM的優點,而且在GBM中采用隨機上升可以進一步提高準確性和功能性。Matrix Net從GBM算法繼承以下3個主要的超參數,分別是上升步長M,正則化率v和最大樹高度H。作者采用均方誤差(MSE)作為效果評測標準。
增強分類決策樹的優點:a)防止過度擬合;b)高階交互處理;c)接近不連續函數;d)在大多數情況下不需要功能轉換。
2.1.6COEC預估模型
Zhang等[14]提出了COEC(clicks over expected clicks)模型,COEC定義為預先設置一個期望的點擊率值,再利用實際點擊率與之前設置的期望點擊率的比值作為目標函數,它具有排序標準化的好處。
2.1.7混合模型
Wang等[15]提出了將4種模型(在線貝葉斯概率回歸(online bayesian probit regression)、支持向量機(support vector machine)和因子模型(latent factor model)和基于最大似然估計的模型(maximum likelihood estimation)組合起來使用的一種混合模型,該模型可以更好地模擬用戶點擊行為,進而預估廣告的點擊率。首先使用基于一種綜合特征的方法去抽取和產生描述特征數,然后使用上述的描述特征數,將四種模型應用于訓練數集中,使用基于MLE的一些模型方法去模擬經常在訓練集中出現的實例,是為了充分利用訓練數集,最后提出了一種基于排序的集成學習方法,該方法可以規范化4種模型方法的結果并產生最后的結果。圖5就是作者所使用的多種模型結構圖。特別需要指出的是針對多種模型使用了兩組特征數,一組是原始特征數(包括離散特征和連續特征),一組是合成特征數(將任意兩組原始離線特征數結合起來作為一個合成特征數)。最后的評估標準采用的是ROC曲線下面積。

圖5 多模型結構
2.2基于稀疏數據廣告和新廣告數據的預估模型
具有豐富歷史點擊數據的廣告畢竟是少數,大多數的點擊數和曝光數都是很稀疏的,特別是新投放到平臺的廣告更是沒有歷史點擊數據的參考,所有需要在線地評估。2.1節所介紹的預估模型對歷史數據豐富的情況下,能獲得很好的預估效果,但是對上述問題不奏效,針對上述問題,下面介紹了基于層次的預估模型、基于相似項的預估模型、基于時間空間的預估模型和基于先驗概率的實時點擊的預估模型來解決廣告數據稀疏和新廣告的預估問題。
2.2.1基于層次結構的模型
Regelson等[16]提出了一種層次聚類(hierarchical clustering)方法,在歷史數據不足缺少或者沒有歷史數據情況下,用廣告的文檔相似度來預估點擊率,這種使用歷史數據分層聚合的方法可以獲得更準確的估計。
Agarwal等[17]提出使用稀疏數據預先存在的層次結構,解決稀疏事件及其稀疏數據的出現率估算問題,主要解決針對web網頁、廣告的點擊率的預估,這些網頁和廣告都可以在不同粒度中獲取廣泛的上下文信息來按層次分類。典型的情況是點擊率非常低的和層次覆蓋面比較稀疏的問題,為了解決這些問題,該文作者采用的抽樣方法是分析那些從訓練集中選取的特別樣本。該模型的預估點擊率模型可以分為兩個階段,第一個階段就是調整樣本偏差,第二個階段就是采用樹形結構的馬爾可夫模型(tree-structured markov model),通過同一級節點的相關性來達到對該層次點擊率的預估。
Agarwal等[18]提出了一種針對稀疏事件廣告數據具有高維多元可分層特征的預估方法模型,該模型叫做多層次Log線性模型(log-linear model for multiple hierarchies),這種模型可以處理在Map-Reduce框架的大規模數據(十億級別的訓練集合,數百萬潛在的預測因子)。考慮到準確性和擴展性,采用了一個基于尖峰和平板回歸(spike and slab prior)的內置篩選過程,刪除那些影響預測準確性的因子,保證準確性。
2.2.2基于相似項的預估模型
Richardson等[19]提出了一種方法利用新廣告和已知點擊率廣告的相同或者相似項(Term)去預測新廣告的點擊率。根據新廣告與舊廣告的相似項在線地根據新廣告數據評估新廣告的點擊率,采用聚類的方法,通過廣告內容的相似度來預估點擊率。
2.2.3基于時間空間的預估模型
Agrawal等[20]在2009年提出了時空模型(spatio-temporal predicting models)預估點擊率,通過動態伽馬泊松模型(dynamic gamma-poisson model)計算一段時間內固定位置的文檔點擊率;通過動態線性回歸模型(dynamic linear regressions)結合相關位置的文檔信息,有效地提高每一位置的點擊數,文中的各個模型通過基于特殊用戶和重復曝光性特征的首次點擊概率(probability of click on first article exposure)的指數級數來調整用戶的疲勞度,并且該模型支持個性化的推薦。
2.2.4基于先驗的實時點擊預估模型
Fang等[21]提出了一種針對具有極其稀疏和瞬時性特征的廣告數據實時點擊的預估模型。鑒于好的ID特征數據具有極其稀疏和瞬時性特征,這使傳統的機器學習處理起來很困難。提出了基于先驗的實時點擊預估模型(prior-based real-time estimator model,PRE),該模型可以直接使用上述的特征數據,首先從之前學習的先驗模型計算不同維的經驗點擊率數據,然后構造最小方差無偏估計量(minimum variance unbiased estimator)來作為點擊率數據的加權和,最后使用權值參數的另一個數集來放寬獨立性假設這個條件,獨立性假設這個條件影響每一維的數據。PRE模型最大的好處就是它自身具有實時性,只需要一些參數進行離線學習,PRE模型經過一段時間訓練就可以得出相對穩定的結果,并且簡單。與此同時,所有的在線計算都在封閉中進行的,而且證明很有效果。為了進一步提高估計效果,還使用了若干模型的融合技術去更好的結合LR模型和PRE模型。最后通過實驗得出,PRE模型可以提高點擊率預估模型的準確性和排名能力,特別是結合最新的數據,該模型的時效性超過一般的機器學習模型。
2.2.5因子分解機模型
Rendle等[22]提出因子分解機模型(factorization machine models),過去因子分解模型雖然是預測效果很好的模型,但是只針對特定的數據集,并且需要用不同的方法去處理不同的數據集,例如有平行因子分析法(parallel factor analysis)、因子分解個性化馬爾可夫鏈(factorizing personalized markov chains)等因子分解的方法。因子分解機模型是結合支持向量機和因子分解模型的優點,支持向量機無法對稀疏數據進行預估,因子分解機不斷的事實化參數對參數變量進行建模,所以因子分解機仍然適用于稀疏數據的預估,這也是與支持向量機相比最大的優點。
2.3各種模型的對比和總結
前面介紹了各種廣告點擊率預估模型,針對不同廣告數據來源采用不同的預估模型,不同的預估模型有它的優缺點,適用的場合也不盡相同,各模型具體的比較如表1所示。

表1 廣告點擊率預估模型的優點和缺點
由于每個模型都有優缺點,為了克服一些缺點,新的算法不斷地被提出,例如平衡采樣邏輯回歸算法[23]采用平衡采樣,由于刪除了大量的負樣本集,能縮短了訓練時間,能在不犧牲點擊率預估效果提升系統的性能,解決了訓練時間的問題;基于聯合概率矩陣分解的上下文廣告推薦算法[24],該算法適用于廣告數據稀疏和大規模數據的情況,解決了過去了一些模型無法預估稀疏廣告數據和大規模廣告數據的缺點。
3 廣告點擊率模型的評估方法
3.1KL距離
KL距離[25](KL-divergence)又叫相對熵,它是兩個概率分布的距離,這里的距離不是真實的距離,相對熵衡量的是相同事件空間里的兩個概率分布的差異情況,其意義就是概率分布P(x)事件空間,如果使用Q(x)概率(也可以叫做真實的概率情況)去編碼,其基本事件的平均編碼長度增加了多少比特。其計算公式如下:

式(2)中D(P||Q)就是KL距離。P(x)信息熵的含義是平均每個基本事件至少需要多少比特編碼。根據信息熵的知識可知,不存在其他比按照自身概率分布更好的編碼方式。所以相對熵是大于等于0的。預估的點擊率概率分布是Q(x),真實的點擊率概率分布是P(x),由此可以得出KL距離越小,越接近真實的概率分布,所以模型預估的點擊率越準確,效果越好。
3.2ROC曲線下面積法[26]
ROC(receiver operating characteristic)曲線分析,它是醫療分析領域的一種新的分類模型性能的評估方法,其中ROC的混淆矩陣主要用于比較分類結果和實例的真實信息,矩陣的每一行代表實例的預測類型,每一列代表實例的真實類別,在ROC坐標中,橫坐標表示假正率,縱坐標表示真正率,真正率表示正例分到正的概率,假正率表示負例錯誤的分到正的概率。

圖6 ROC曲線
圖6所示,曲線下面積AUC就是處于ROC曲線下方的那部分面積的大小。AUC的值在[0.5,1]區間內,值較大表示性能較優。首先根據模型預測的每個廣告的點擊率的不同,按高低依次確定投放廣告的位置,預測值大的放在前面,然后根據真實的點擊所反饋的信息,假正率等于1減去真正率,預設一個閾值,根據閾值將實例分成正類和負類,根據分類結果來繪制ROC曲線,其中Y軸方向代表被點擊率,X軸代表未被點擊率,由此可以得知ROC曲線下面積就越大,AUC就越大,預估的廣告點擊率就越準確。
4 結 語
廣告點擊率是計算廣告的重要內容,也是提高廣告收益的主要手段之一,本文首先介紹了一些相關知識,然后重點介紹了多種廣告點擊率的預估模型,基于歷史廣告數據的預估模型,例如邏輯回歸模型、貝葉斯模型、決策樹模型等,還有針對歷史廣告數據不足的預估模型,例如分層聚類模型,對未投放的新廣告的預估模型,例如Term CTR模型,還有適用于所有廣告數據的模型,例如時間空間模型和層次模型,最后介紹了點擊率預估模型的常用的評估方法。
互聯網的快速發展,廣告點擊率的預估模型也在不斷的改變,傳統上Google、百度等搜索公司是以邏輯回歸模型作為預估模型,百度意識到LR嚴重限制了模型學習與抽象特征的能力[27],百度嘗試將DNN(deep neural network)深度學習應用到搜索廣告,并于2013年服務于百度搜索廣告系統。但DNN在搜索廣告的應用遠遠不夠,結合海量的廣告點擊數據,如何充分發揮分布式分析計算的最大能力去實現廣告點擊率預估,如何提高廣告點擊率預估的準確性以及更好地實現個性化廣告精準推薦,是未來的發展方向。
[1]李 敏.計算廣告學將成為數字商業的奠基學科[J].程序員,2014(5):109-109.
[2]周傲英,周敏奇,宮學慶.計算廣告:以數據為核心的Web綜合利用[J].計算機學報,2011,34(10):1805-1891.
[3]紀文迪,王曉玲,周傲英.廣告點擊率估算技術綜述[J].華東師范大學學報:自然科學版,2013(3):2-14.
[4]Richardson M,Dominowska E,Ragno R.Predicting clicks:estimating the click-through rate for new ads[C]//Proceedings of the 16th International Conference on World Wide Web.ACM,2007:521-530.
[5]Joachims T.Optimizing search engines using clickthrough data[C]//Proceedings of the 8th ACM SIGKDD International Conference on KnowledgeDiscovery and Data Mining.ACM,2002:133-142.
[6]Chapelle O,Zhang Y.A dynamic bayesian network click model for web search ranking[C]//Proceedings of the 18th International Conference on World Wide Web. ACM,2009:1-10.
[7]Guo F,Liu C,Kannan A,et al.Click chain model in web search[C]//Proceedings of the 18th International Conference on World Wide Web.ACM,2009:11-20.
[8]Graepel T,Candela J Q,Borchert T,et al.Web-scale bayesian click-through rate prediction for sponsored search advertising in microsoft's bing search engine[C]// Proceedings of the 27th International Conference on Machine Learning(ICML-10).2010:13-20.
[9]Dupret G E,Piwowarski B.A user browsing model to predict search engine click data from past observations[C]//Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.ACM,2008:331-338.
[10]Zhang Y,Dai H,Xu C,et al.Sequential click prediction for sponsored search with recurrent neural networks[J].AAAI,2014:1369-1375.
[11]Auli M,Galley M,Quirk C,et al.Joint language and translation modeling with recurrent neural networks[C]//EMNLP.2013:1044-1054.
[12]Dave K,Varma V.Predicting the click-through rate for rare/new ads[R].Centre for Search and Information Extraction Lab International Institute of Information Technology Hyderabad-500 032,India,2010.
[13]Rofimov I,Kornetova A,Topinskiy V.Using boosted trees for click-through rate prediction for sponsored search[C]//Proceedings of the 6th International Workshop on Data Mining for Online Advertising and Internet Economy.ACM,2012:2.
[14]Zhang W V,Jones R.Comparing click logs and editorial labels for training query rewriting[C]//WWW 2007 Workshop on Query Log Analysis:Social and Technological Challenges.2007.
[15]Wang X,Lin S,Kong D,et al.Click-through prediction for sponsored search advertising with hybrid models[C]//KDD Workshop.2012.
[16]Regelson M,Fain D.Predicting click-through rate using keyword clusters[C]//Proceedings of the Second Workshop on Sponsored Search Auctions.2006,9623.
[17]Agarwal D,Broder A Z,Chakrabarti D,et al. Estimating rates of rare events at multiple resolutions[C]//Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM,2007:16-25.
[18]Agarwal D,Agrawal R,Khanna R,et al.Estimating rates of rare events with multiple hierarchies through scalable log-linear models[C]//Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM,2010:213-222.
[19]Richardson M,Dominowska E,Ragno R.Predicting clicks:estimating the click-through rate for new ads[C]//Proceedings of the 16th International Conference on World Wide Web.ACM,2007:521-530.
[20]Agarwal D,Chen B C,Elango P.Spatio-temporal models for estimating click-through rate[C]// Proceedings of the 18th International Conference on World Wide Web.ACM,2009:21-30.
[21]Fang Y,Liu J.A novel prior-based real-time click through rate prediction model[J].International Journal of Machine Learning and Cybernetics,2014,5(6):887-895.
[22]Rendle S.Factorization machines[C]//Data Mining(ICDM),2010 IEEE 10th International Conference on. IEEE,2010:995-1000.
[23]施夢圜,顧津吉.基于平衡采樣的輕量級廣告點擊率預估方法[J].計算機應用研究,2014,31(1):33-36.
[24]涂丹丹,舒承椿,余海燕.基于聯合概率矩陣分解的上下文廣告推薦算法[J].軟件學報,2013,24(3):454-464.
[25]Kullback S,Leibler R A.On information and sufficiency[J].The Annals of Mathematical Statistics,1951,22(1):79-86.
[26]劉 唐.基于多類別特征的在線廣告點擊率預測研究:以騰訊搜搜為例[D].北京:北京郵電大學,2012.
[27]余 凱,賈 磊,陳雨強.深度學習:推進人工智能的夢想[J].程序員,2013(6):22-27.Overview of Advertisement Click-through Rate Estimating Techniques
CHEN Qiao-hong,YU Shi-min,JIA Yu-bo
(School of Information Science and Technology,Zhejiang Sci-Tech University,Hangzhou 310018,China)
The prediction of advertisement click-through rate is an important research content in the field of computational advertising.Accurate prediction of advertisement click-through rate can improve real advertisement click-through rate and increase income.Logistic regression model,support vector machine(SVM)model,the Bayesian model and neural network model are applicable to enriching historical advertisement click-through data,the models without historical advertisement click-through data and sparse advertisement click-through data,similar term prediction model and factorization machine etc.Time-space model and hierarchical model apply to all the above situations.According to the characteristics of different advertising data,different models can get good prediction effect.
cadvertisement click-through rate;prediction model;neural network;factorization machine
TP181
A
1673-3851(2015)06-0851-07
(責任編輯:陳和榜)
2014-11-13
浙江省自然科學基金項目(LQ13F020015)
陳巧紅(1978-),女,浙江臨海人,副教授,主要從事計算機輔助設計及機器學習技術方面的研究。
余仕敏,E-mail:ywy2130635@163.com
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
