基于領(lǐng)域本體學(xué)習(xí)資源庫(kù)自動(dòng)構(gòu)建模型研究
2015-11-02 02:34:05王銳何聚厚
電子設(shè)計(jì)工程 2015年24期
王銳,何聚厚
(1.陜西師范大學(xué)計(jì)算機(jī)科學(xué)學(xué)院,陜西西安710119;2.陜西師范大學(xué)現(xiàn)代教學(xué)技術(shù)教育部重點(diǎn)實(shí)驗(yàn)室,陜西西安710119)
基于領(lǐng)域本體學(xué)習(xí)資源庫(kù)自動(dòng)構(gòu)建模型研究
王銳1,何聚厚2
(1.陜西師范大學(xué)計(jì)算機(jī)科學(xué)學(xué)院,陜西西安710119;2.陜西師范大學(xué)現(xiàn)代教學(xué)技術(shù)教育部重點(diǎn)實(shí)驗(yàn)室,陜西西安710119)
領(lǐng)域?qū)W習(xí)資源構(gòu)建模型是實(shí)現(xiàn)個(gè)性化資源推薦、查詢檢索的關(guān)鍵因素,針對(duì)手動(dòng)構(gòu)建領(lǐng)域資源庫(kù)費(fèi)時(shí)費(fèi)力和領(lǐng)域資源之間缺乏語(yǔ)義聯(lián)系問(wèn)題,提出了一種基于領(lǐng)域本體和搜索算法的學(xué)習(xí)資源知識(shí)庫(kù)構(gòu)建模型,使用PageRank抓取算法對(duì)網(wǎng)頁(yè)資源進(jìn)行抓取,通過(guò)結(jié)合領(lǐng)域本體增強(qiáng)資源之間的語(yǔ)義聯(lián)系,從而完成特定領(lǐng)域資源知識(shí)庫(kù)的自動(dòng)構(gòu)建。實(shí)驗(yàn)表明該模型解決了手動(dòng)構(gòu)建領(lǐng)域資源庫(kù)費(fèi)時(shí)費(fèi)力和領(lǐng)域資源之間缺乏語(yǔ)義聯(lián)系的問(wèn)題。
知識(shí)庫(kù);領(lǐng)域本體;PageRank;語(yǔ)義
在21世紀(jì)的信息時(shí)代,互聯(lián)網(wǎng)為用戶提供了一個(gè)龐大的信息資源庫(kù),面對(duì)海量的信息,用戶很難高效的找出自己需求的資源。因此出現(xiàn)了大量的個(gè)性化推薦、查詢算法,為用戶減輕“負(fù)擔(dān)”,但由于網(wǎng)絡(luò)上的信息資源庫(kù)過(guò)于龐大,導(dǎo)致推薦資源達(dá)不到用戶的要求,因此特定領(lǐng)域資源庫(kù)的構(gòu)建十分重要,它是影響推薦、查詢算法準(zhǔn)確性的關(guān)鍵因素。
傳統(tǒng)的學(xué)習(xí)資源庫(kù)構(gòu)建主要是基于關(guān)鍵字手工或半自動(dòng)化的將資源的相關(guān)信息存儲(chǔ)于知識(shí)庫(kù)中,知識(shí)庫(kù)中的學(xué)習(xí)資源之間相互獨(dú)立沒(méi)有任何聯(lián)系,在進(jìn)行個(gè)性化資源推送、查詢時(shí)會(huì)忽略了語(yǔ)義問(wèn)題,即有可能忽略用戶的真正需求和查詢的真正意圖,這將會(huì)造成資源推薦、查詢的不準(zhǔn)確。同時(shí),考慮到學(xué)習(xí)資源信息的呈現(xiàn)方式,如:文字、圖形、音頻、視頻等對(duì)用戶的興趣度及學(xué)習(xí)效果的影響不同[1],本文提出了一種基于領(lǐng)域本體和搜索算法的學(xué)習(xí)資源知識(shí)庫(kù)自動(dòng)構(gòu)建模型,該模型改進(jìn)了經(jīng)典的PageRank算法,主要思想是PageRank算法在進(jìn)行網(wǎng)頁(yè)相似性分析時(shí),結(jié)合領(lǐng)域本體,同時(shí)對(duì)網(wǎng)頁(yè)中資源之間的語(yǔ)義相關(guān)性進(jìn)行分析抓取資源,最后根據(jù)信息的不同呈現(xiàn)方式對(duì)用戶興趣影響不同將信息資源存于不同的數(shù)據(jù)庫(kù)表中,完成特定領(lǐng)域資源知識(shí)庫(kù)的自動(dòng)構(gòu)建。
1 學(xué)習(xí)資源庫(kù)構(gòu)建模型
目前學(xué)習(xí)資源庫(kù)構(gòu)建模型主要有以下兩種方式:
1)手動(dòng)構(gòu)建模型,主要思想是,首先相關(guān)領(lǐng)域?qū)<覍⒈绢I(lǐng)域相關(guān)知識(shí)資源的關(guān)鍵字羅列出來(lái),然后,手動(dòng)將關(guān)鍵字及其對(duì)應(yīng)的資源加入學(xué)習(xí)資源庫(kù)中,重復(fù)此過(guò)程,直到關(guān)鍵字已全部加入學(xué)習(xí)資源庫(kù)。
手動(dòng)模型,雖然能將所需的關(guān)鍵字及其資源存入資源庫(kù)中,但隨著領(lǐng)域規(guī)模的擴(kuò)大,羅列的關(guān)鍵字會(huì)越來(lái)越多,相對(duì)應(yīng)的資源也更加豐富,此時(shí)手動(dòng)構(gòu)建模型費(fèi)時(shí)費(fèi)力,已不能滿足要求。為解決手動(dòng)費(fèi)時(shí)費(fèi)力的問(wèn)題,提出了半自動(dòng)構(gòu)建模型。
2)半自動(dòng)構(gòu)建模型,主要思想是,利用網(wǎng)頁(yè)抓取算法在網(wǎng)絡(luò)上根據(jù)關(guān)鍵字抓取資源存入資源庫(kù)中。關(guān)于網(wǎng)頁(yè)抓取策略的研究,國(guó)外開(kāi)始于20世紀(jì)90年代末,Cho等人第一次引入了網(wǎng)頁(yè)抓取策略的概念。之后,網(wǎng)頁(yè)抓取的方法不斷涌現(xiàn)。主要有寬度優(yōu)先網(wǎng)頁(yè)抓取策略、基于反向鏈接數(shù)的網(wǎng)頁(yè)抓取策略、PageRank、Shark-Search、Best-FirstSearch等算法。自動(dòng)構(gòu)建模型利用抓取算法根據(jù)關(guān)鍵詞來(lái)抓取資源,雖然解決了費(fèi)時(shí)費(fèi)力的問(wèn)題,但是領(lǐng)域資源庫(kù)中的資源之間相互獨(dú)立、沒(méi)有語(yǔ)義聯(lián)系。
2 領(lǐng)域本體及其構(gòu)建
本體[2]這個(gè)概念最早是在哲學(xué)中使用的,表達(dá)“存在論”,對(duì)世界上客觀存在的事物進(jìn)行系統(tǒng)的描述,對(duì)其本質(zhì)進(jìn)行抽象。隨著信息技術(shù)的飛速發(fā)展,本體被引入到計(jì)算機(jī)領(lǐng)域并得到廣泛的應(yīng)用。但是,到目前為止,本體一詞還沒(méi)有一個(gè)準(zhǔn)確的含義。自1993年Gruber提出“本體是概念的模型明確的規(guī)范說(shuō)明”以后,它主要通過(guò)概念、概念之間的關(guān)系、屬性、實(shí)例四個(gè)方面來(lái)描述概念之間的語(yǔ)義。領(lǐng)域本體是對(duì)特定領(lǐng)域概念、屬性及關(guān)系進(jìn)行描述,對(duì)該領(lǐng)域內(nèi)的知識(shí)進(jìn)行抽象、描述、表達(dá)語(yǔ)義,從而達(dá)到信息整合與共享。本文以〈〈數(shù)據(jù)結(jié)構(gòu)〉〉課程為例,參考“七步法”[3]構(gòu)建數(shù)據(jù)結(jié)構(gòu)本體。構(gòu)建過(guò)程如下:
1)數(shù)據(jù)結(jié)構(gòu)課程中概念的抽取。主要有:數(shù)據(jù)結(jié)構(gòu),線性結(jié)構(gòu),樹(shù)形結(jié)構(gòu),圖形結(jié)構(gòu),排序,線性表,棧,隊(duì)列,串,數(shù)組,廣義表,樹(shù),二叉樹(shù),森林,哈夫曼樹(shù),鏈表,順序表,有向圖,完全圖,查找等概念。
2)概念屬性的確定。在本體描述語(yǔ)言O(shè)WL中Property包含3種。
一種是對(duì)象屬性(Object Properties),它表達(dá)實(shí)例和實(shí)例、類(lèi)和類(lèi)之間的關(guān)。如,在數(shù)據(jù)結(jié)構(gòu)本體中包含8種主要的對(duì)象屬性,分別是,isSame、isSubclass、isPartOf、isSibling、isUpper、isLower、isRelation、isExercise。具體含義如下面表1所示。
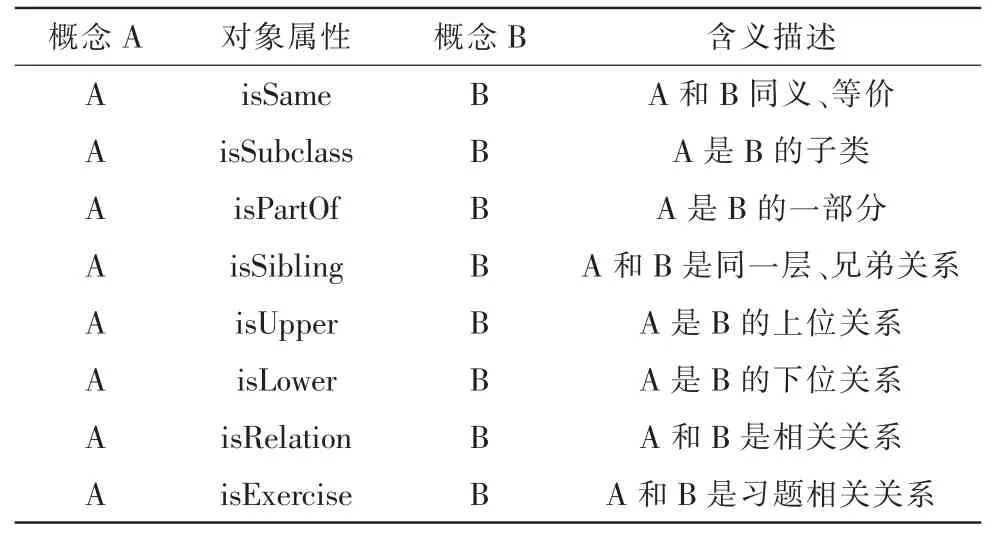
表1 概念間的對(duì)象屬性Tab.1The object properties between concepts
一種是數(shù)據(jù)屬性(Data Properties),它是實(shí)例的基本屬性,表達(dá)實(shí)例和基本數(shù)據(jù)類(lèi)型之間的關(guān)系。如,在此本體中包含的主要數(shù)據(jù)屬性有定義、存儲(chǔ)結(jié)構(gòu)、邏輯結(jié)構(gòu)、遍歷、分類(lèi)、應(yīng)用、最短路徑、算法、代碼、轉(zhuǎn)換。
最后一種是解釋屬性(Annotation properties),它可以用來(lái)解釋類(lèi)、對(duì)象屬性、數(shù)據(jù)屬性、實(shí)例,屬于元數(shù)據(jù),不常用。
3)向資源庫(kù)中添加實(shí)例。本文通過(guò)抓取算法結(jié)合數(shù)據(jù)結(jié)構(gòu)本體進(jìn)行自動(dòng)構(gòu)建,具體操作見(jiàn)下文。
圖1所示為用Protégé4.3構(gòu)建的〈〈數(shù)據(jù)結(jié)構(gòu)〉〉課本中線性表的類(lèi)關(guān)系圖。
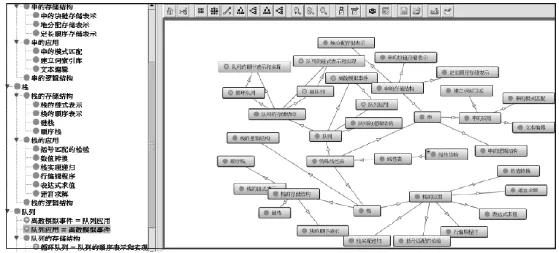
圖1 系統(tǒng)軟件設(shè)計(jì)結(jié)構(gòu)圖Fig.1Schematic diagram of the software test system
3 PageRank算法的基本原理
PageRank算法[4]是1998年Larry Page和Sergey Brin提出的。此算法認(rèn)為,一個(gè)頁(yè)面被多次引用,則這個(gè)頁(yè)面很可能是重要的,一個(gè)頁(yè)面盡管沒(méi)有被多次引用,但被一個(gè)重要頁(yè)面引用,則這個(gè)頁(yè)面的重要性被均勻地傳遞到它所引用的頁(yè)。PageRank評(píng)價(jià)標(biāo)準(zhǔn)認(rèn)為每個(gè)超鏈接的重要性與包含這個(gè)超鏈接的原web網(wǎng)頁(yè)的重要性是成比例的,而不是每個(gè)鏈接的重要性都相同。一個(gè)網(wǎng)頁(yè)的PR值的計(jì)算公式為:
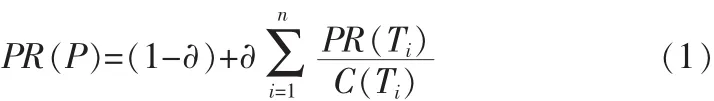
其中,Ti(i:1,2,…,n)是指向網(wǎng)頁(yè)P(yáng)的其他網(wǎng)頁(yè),C(Ti)是網(wǎng)頁(yè)T向外指出的鏈接數(shù)目,?是(0,1)區(qū)間上的規(guī)范化因子,一般取值為0.85,經(jīng)過(guò)簡(jiǎn)單的迭代就可以計(jì)算出PR(P)的值。由公式(1)可以看到,基本的PageRank算法中網(wǎng)頁(yè)P(yáng)的PR值僅與其鏈入的超鏈接的個(gè)數(shù)以及鏈入的超鏈的PR值有關(guān),因此存在偏重舊網(wǎng)頁(yè)、主題漂移等問(wèn)題[5]。針對(duì)這些問(wèn)題,李瑞提出了PageRank算法權(quán)威值均分的改進(jìn)[6],楊博等人提出基于超鏈接多樣性分析的新型網(wǎng)頁(yè)排名算法[7],潘偉豐等人通過(guò)加權(quán)模型分析PR所識(shí)別關(guān)鍵包的傳播影響來(lái)確定PR值[8]。但這些方法都是在互聯(lián)網(wǎng)提供的龐大資源庫(kù)中進(jìn)行,對(duì)沒(méi)有考慮特定領(lǐng)域中的內(nèi)容主題相關(guān)因素的影響。因此,本文結(jié)合領(lǐng)域本,對(duì)基本PageRank算法進(jìn)行改進(jìn),在抓取數(shù)據(jù)時(shí)一方面考慮網(wǎng)頁(yè)鏈接的相關(guān)性,另一方面考慮內(nèi)容與領(lǐng)域本體的相關(guān)性。
4 基于本體的學(xué)習(xí)資源庫(kù)構(gòu)建模型
為了構(gòu)建特定領(lǐng)域的學(xué)習(xí)資源庫(kù),本文結(jié)合領(lǐng)域本體,從領(lǐng)域本體概念和網(wǎng)頁(yè)主題的語(yǔ)義相似度和網(wǎng)頁(yè)鏈接相似度兩個(gè)因素入手,改進(jìn)基本PageRank算法,從而自動(dòng)構(gòu)建領(lǐng)域資源庫(kù)。
基于本體的學(xué)習(xí)資源庫(kù)構(gòu)建模型算法如下:
1)首先在t_concept表中查找第一個(gè)本體概念,接著利用PageRank算法抓取第一個(gè)網(wǎng)頁(yè),同時(shí)計(jì)算此網(wǎng)頁(yè)中的主題概念與當(dāng)前的本體概念的語(yǔ)義相似度,借鑒已有的語(yǔ)義相似度計(jì)算方法,具體如下:
①考慮語(yǔ)義距離、層次因素對(duì)概念間的語(yǔ)義相似度的影響
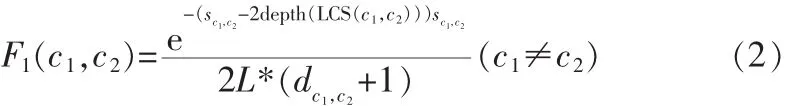
其中sc1,c2=Level(c1)+Level(c2)是概念c1和c2的層次和,dc1,c2=|Level(c1)-Level(c2)|,是概念c1和c2的層次差,L是本體的總層數(shù)。
Level(c1)表示概念c1所在的層次,depth(LCS(c1,c2))概念c1和c2共同的最小分類(lèi)LCS所在的層次。
②考慮上下位概念重合度對(duì)語(yǔ)義相似度的影響的度量算法如下:
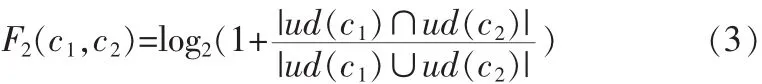
其中,ud(c1)表示c1的上下位概念集合,ud(c2)表示c2的上下位概念集合。
ud(c1)∩ud(c2)表示概念c1和c2相同的上下位概念集合,ud(c1)∪ud(c2)表示概念c1和c2所有的上下位概念集合。綜合考慮①、②因素,添加?,β進(jìn)行調(diào)節(jié),公式如下:
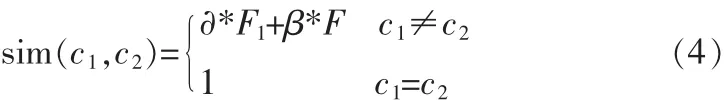
由式(4)就可以計(jì)算出此網(wǎng)頁(yè)中的主題概念與當(dāng)前的本體概念的語(yǔ)義相似度
2)從時(shí)間效應(yīng)考慮,在基本PageRank算法基礎(chǔ)上為頁(yè)面增加一個(gè)時(shí)間因子,使新網(wǎng)頁(yè)排名靠前,時(shí)間因子公式如下:

其中,D是本網(wǎng)頁(yè)的時(shí)間因子,d為阻尼系數(shù),Td表示爬取到這張網(wǎng)頁(yè)的次數(shù),次數(shù)越多說(shuō)明時(shí)間越長(zhǎng),R是采集時(shí)間,λ為時(shí)間參數(shù)調(diào)節(jié)因子。綜合1)、2)兩個(gè)方面,改進(jìn)PageRank算法的PR值計(jì)算式為:
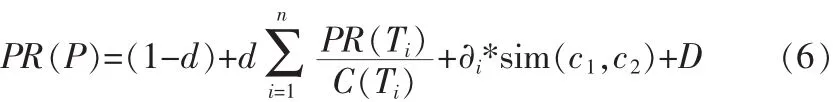
3)通過(guò)步驟2)計(jì)算出當(dāng)前網(wǎng)頁(yè)的PR值,當(dāng)PR值達(dá)到要求時(shí),將當(dāng)前網(wǎng)址存于數(shù)據(jù)庫(kù)對(duì)應(yīng)的數(shù)據(jù)表中。
4)重復(fù)1)~3)步驟,直到表t_concept中的所有概念查完。
通過(guò)基于本體的學(xué)習(xí)資源庫(kù)構(gòu)建模型就可以完成特定領(lǐng)域?qū)W習(xí)資源庫(kù)的自動(dòng)構(gòu)建。
5 實(shí)驗(yàn)
為了驗(yàn)證該模型的有效性,本文基于本體建模工具Protégé4.3構(gòu)建了〈〈數(shù)據(jù)結(jié)構(gòu)〉〉課程本體,基于Jean接口完成本體文件到關(guān)系數(shù)據(jù)庫(kù)MySQl的存儲(chǔ)。由于本體文件存儲(chǔ)形式存儲(chǔ)的數(shù)據(jù)量較小而且每次使用開(kāi)銷(xiāo)大,所以本文選擇用關(guān)系數(shù)據(jù)庫(kù)存儲(chǔ)數(shù)據(jù)。為了滿足特定領(lǐng)域的個(gè)性化推薦、查詢的方便,根據(jù)學(xué)習(xí)資源信息的呈現(xiàn)方式不同用戶的興趣度不同,主要分為視頻音頻、文字、圖像3種類(lèi)型,將數(shù)據(jù)以3種類(lèi)型存于3張不同的數(shù)據(jù)表中。數(shù)據(jù)庫(kù)中的7張表如圖2所示。

圖2 數(shù)據(jù)庫(kù)的7張表Fig.2Seven tables in database
抓取的學(xué)習(xí)資源存于數(shù)據(jù)表t_wordEntity,t_imageEntity,t_mediaEntity表中,如圖3所示。
6 結(jié)論
該模型對(duì)基本PageRank算法進(jìn)行改進(jìn),在其基礎(chǔ)上結(jié)合領(lǐng)域本體,使得在抓取學(xué)習(xí)資源的時(shí)候,參照本體之間的語(yǔ)義關(guān)系,與已有的構(gòu)建模型相比,解決了人工費(fèi)時(shí)費(fèi)力的問(wèn)題,同時(shí)又構(gòu)建了具有語(yǔ)義關(guān)系的學(xué)習(xí)資源庫(kù),為個(gè)性化資源推薦、查詢檢索的準(zhǔn)確性奠定基礎(chǔ)。
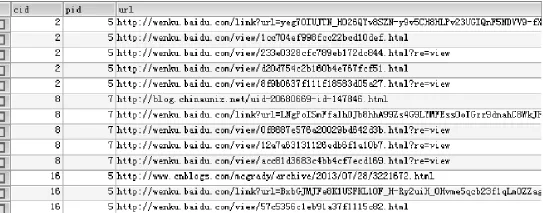
圖3 t_wordEntity表Fig.3Table t_wordEntity
[1]康誠(chéng),周愛(ài)保.信息呈現(xiàn)方式與學(xué)習(xí)者的個(gè)性特征對(duì)多媒體環(huán)境下學(xué)習(xí)效果的影響[J].心理發(fā)展與教育,2009(1):83-90.
[2]吳建絨.論基于本體的領(lǐng)域知識(shí)庫(kù)構(gòu)建[J].科技創(chuàng)新導(dǎo)報(bào),2010(30):250-251.
[3]馬曉丹,鄧曉晴,彭文娟,等.基于領(lǐng)域本體的知識(shí)庫(kù)架構(gòu)和實(shí)現(xiàn)[J].河北聯(lián)合大學(xué)學(xué)報(bào):自然科學(xué)報(bào),2012,34(4):44-45.
[4]PAGE L,BRINS,MOTWANI R,et al.The PageRank Citation Ranking:Bring order to the Web[EB/OL].(1998-12-19)http://ilpubs.Stanford.edu:8090/422,1998.
[5]劉恩海,張梅芳,李天義.基于兩級(jí)修正的頁(yè)面排序改進(jìn)算法[J].計(jì)算機(jī)工程與設(shè)計(jì),2014,35(6):2024-2028.
[6]李瑞,郭小溪.PageRank算法權(quán)威值均分的改進(jìn)[J].大連交通大學(xué)學(xué)報(bào),2013,34(2):109-110.
[7]楊博,陳賀昌,朱冠宇,等.基于超鏈接多樣性分析的新型網(wǎng)頁(yè)排名算法[J].計(jì)算機(jī)學(xué)報(bào),2014,37(4):833-834.
[8]潘偉豐,李兵,馬于濤,等.基于加權(quán)PageRank算法的關(guān)鍵包識(shí)別方法[J].電子學(xué)報(bào),2014,37(4):833-834.
Research of learning resources building model based on domain ontology
WANG Rui1,HE Ju-hou2
(1.School of Computer Science,Shaanxi Normal University,Xi'an 710119,China;2.Key Laboratory of Modern Teaching Technology,Ministry of Education,Shaanxi Normal University,Xi'an 710119,China)
Learning resources building model based on domain ontology is a key factor to achieve a specific field of personalized resources recommended,query and retrieve.For repository time-consuming and laborious in manual build and lacking of semantic contact between resources,this paper propose learning resources building model based on domain ontology and search algorithm.Using PageRank algorithm to grab web resources,by combining domain ontology enhance the semantic relations between the resources,to complete automated building knowledge base resources in special fields.The experiment show that the model solves laborious problem of learning resources building manually and lacking of semantic relations between learning resources.
knowledge base;domain ontology;PageRank;semantic
TN91
A
1674-6236(2015)24-0032-04
2015-03-20稿件編號(hào):201503273
中央高校基本科研業(yè)務(wù)費(fèi)專(zhuān)項(xiàng)資金資助(GK201002028,GK201101001)
王銳(1988—),女,陜西西安人,碩士研究生。研究方向:資源信息推薦。
猜你喜歡
現(xiàn)代裝飾(2022年1期)2022-04-19 13:47:32
吉林廣播電視大學(xué)學(xué)報(bào)(2021年4期)2022-01-14 02:35:48
作文成功之路·小學(xué)版(2020年5期)2020-06-11 12:48:26
開(kāi)放教育研究(2020年2期)2020-03-31 01:54:14
現(xiàn)代裝飾(2020年2期)2020-03-03 13:37:44
小天使·一年級(jí)語(yǔ)數(shù)英綜合(2018年11期)2018-11-23 09:47:26
中學(xué)生數(shù)理化·高一版(2018年9期)2018-10-09 06:46:48
中學(xué)生數(shù)理化·高一版(2017年9期)2017-12-19 12:15:14
資源再生(2017年3期)2017-06-01 12:20:59
現(xiàn)代語(yǔ)文(2016年21期)2016-05-25 13:13:44
