
基于FPGA的串行結(jié)構(gòu)遞歸神經(jīng)網(wǎng)絡(luò)LS-SVM實現(xiàn)
2015-11-07 08:52:32宋魯
中國科技信息 2015年24期
宋 魯
基于FPGA的串行結(jié)構(gòu)遞歸神經(jīng)網(wǎng)絡(luò)LS-SVM實現(xiàn)
宋 魯
使用FPGA實現(xiàn)遞歸神經(jīng)網(wǎng)絡(luò)的LS-SVM串行計算結(jié)構(gòu),能有效降低并行計算結(jié)構(gòu)對嵌入式系統(tǒng)硬件資源的消耗。該結(jié)構(gòu)具有串行計算、并行傳輸?shù)奶攸c。采用verilog HDL來實現(xiàn)該結(jié)構(gòu),可以在編譯階段設(shè)置處理數(shù)據(jù)的字長,具有較強(qiáng)的靈活性。利用Altera Cyclone III系列FPGA完成LS-SVM訓(xùn)練的仿真實驗。結(jié)果表明,該硬件實現(xiàn)方法很好地完成LS-SVM的分類訓(xùn)練,與現(xiàn)有的LS-SVM matlab軟件包相比,達(dá)到相似分類準(zhǔn)確率的情況下,具有更快的訓(xùn)練速度。
支持向量機(jī)(SVM)作為機(jī)器學(xué)習(xí)的一個研究熱點,被廣泛應(yīng)用到工程領(lǐng)域中。目前,SVM的研究較多局限于軟件實現(xiàn)。然而,這種方法在執(zhí)行過程中需要巨大的硬件資源 。因此,研究SVM硬件實現(xiàn)架構(gòu)是必要的。這種專用電路結(jié)構(gòu)可以提高硬件資源的利用效率,從而降低芯片的面積、功耗、成本,提高速度和可靠性。
最早適用于VLSI實現(xiàn)的SVM學(xué)習(xí)電路采用Chua遞歸網(wǎng)絡(luò)來解決受約束的二次規(guī)劃問題,但其要達(dá)到精確解,懲罰因子會接近無窮大,硬件不易實現(xiàn)。隨后出現(xiàn)了一些處理SVM學(xué)習(xí)過程的雙層或單層結(jié)構(gòu)的神經(jīng)網(wǎng)絡(luò)。不足之處在于,當(dāng)不存在界內(nèi)支持向量,即當(dāng)所有支持向量機(jī)都為界上支持向量時,無法得到偏移量。
在雙層網(wǎng)絡(luò)的基礎(chǔ)上,文獻(xiàn)提出較為簡單的單層遞歸神經(jīng)網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)來實現(xiàn)SVM學(xué)習(xí),并在理論上證明了其收斂性和分類性能,與雙層網(wǎng)絡(luò)相比,其硬件實現(xiàn)更加簡單。然而,當(dāng)訓(xùn)練數(shù)據(jù)集較大時,并行系統(tǒng)將耗費過多的硬件資源,并行計算結(jié)構(gòu)將不能滿足嵌入式系統(tǒng)的要求。鑒于此,本文提出一種串行計算結(jié)構(gòu),使用FPGA實現(xiàn)基于遞歸神經(jīng)網(wǎng)絡(luò)的LS-SVM。該結(jié)構(gòu)具有串行計算、并行傳輸?shù)奶攸c,計算核心單元采用復(fù)用的方式,硬件資源得到較大程度的縮減。
基于遞歸神經(jīng)網(wǎng)絡(luò)的LS-SVM
最小二乘支持向量機(jī)(LS-SVM)
LS-SVM分類器由Suykens等提出,它通過線性系統(tǒng)來求解二次規(guī)劃問題。LS-SVM在原空間中求解如下優(yōu)化問題:

式中:e 為誤差;常數(shù)γ>0,用來控制對超出誤差樣本懲罰的程度。問題(1)相應(yīng)的拉格朗日函數(shù)為

式中,αi為拉格朗日乘子。根據(jù)最優(yōu)性條件,對式(2)求偏導(dǎo)并令其為0,得

消除變量ω和e,可得到如下矩陣方程來代替二次規(guī)劃問題:

其中,

設(shè)上述方程的解為α=[α1,...,αN],則LS-SVM分類器的決策函數(shù)為:
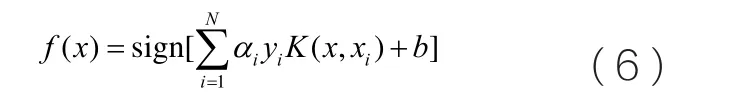
LS-SVM神經(jīng)網(wǎng)絡(luò)
在文獻(xiàn)中,作者利用部分對偶原理,將SVM的二次規(guī)劃問題轉(zhuǎn)化為遞歸神經(jīng)網(wǎng)絡(luò)的動態(tài)方程求解問題。
對式(4)展開,可得

其中:qij=yiyjkij,kij(=k, xi) xj為核函數(shù)。若核函數(shù)滿足Mercer條件,且對稱陣QC=[qij]為半正定,則該問題只有一個全局最優(yōu)解。
神經(jīng)網(wǎng)絡(luò)模型由下面的動態(tài)方程描述:
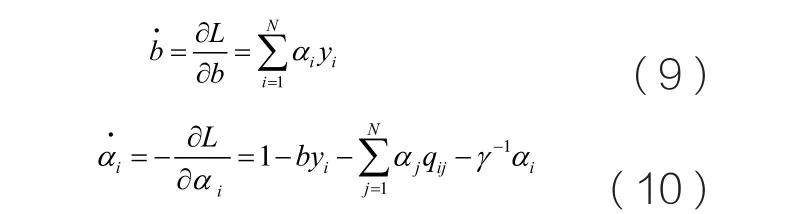
可以看出,該動態(tài)系統(tǒng)在平衡點處,即滿足最優(yōu)化條件(7)、(8)時,所提出的神經(jīng)網(wǎng)絡(luò)在平衡點處滿足KKT條件。這樣,當(dāng)所提出的動態(tài)網(wǎng)絡(luò)收斂到平衡點時,就可求解LS-SVM問題。式(9)、(10)兩邊同時積分可得:
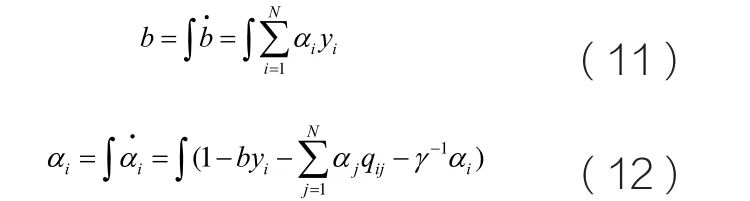
式(11)、(12)可以用圖1所示的遞歸神經(jīng)網(wǎng)絡(luò)來實現(xiàn)。
圖1所示的神經(jīng)網(wǎng)絡(luò)是由(N+1)個神經(jīng)元組成的遞歸網(wǎng)絡(luò);∑為累加器,傳輸函數(shù)f為一個積分環(huán)節(jié)。輸入向量通過如下權(quán)矩陣W進(jìn)入網(wǎng)絡(luò):
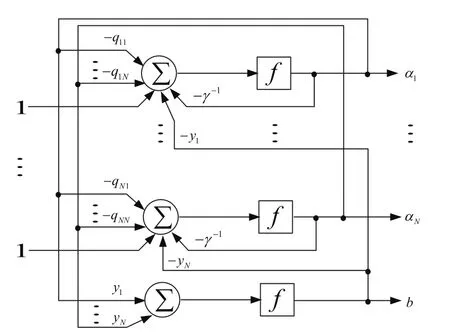
圖1 實現(xiàn)LS-SVM的神經(jīng)網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)圖
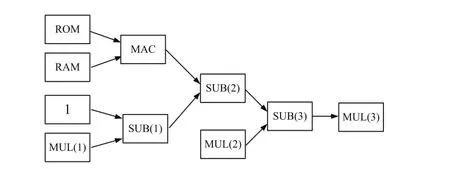
圖2 神經(jīng)元的verilog HDL運算流程框圖

該網(wǎng)絡(luò)結(jié)構(gòu)很容易采用硬件電路實現(xiàn)。為在FPGA實現(xiàn)該結(jié)構(gòu),先將式(9)、(10)進(jìn)行離散化處理,得
式中,?T 為采樣時間間隔,本研究取?T=2-10s。式(14)、(15)可用邏輯門電路實現(xiàn)。
LS-SVM神經(jīng)網(wǎng)絡(luò)神經(jīng)元FPGA實現(xiàn)
根據(jù)圖1和式(14)、(15)可知,用FPGA實現(xiàn)LS-SVM分類功能的神經(jīng)網(wǎng)絡(luò)架構(gòu)需要乘法累加器(MAC)、乘法器(MUL)、加法器(ADD)、減法器(SUB)和累加單元(AC)等運算單元。系統(tǒng)分別使用ROM單元和RAM單元,用于存儲神經(jīng)網(wǎng)絡(luò)權(quán)值系數(shù)qij和每個神經(jīng)元運算得到的αi值。神經(jīng)元硬件實現(xiàn)以圖1中第i個神經(jīng)元為例,神經(jīng)元的verilog HDL運算流程框圖如圖2所示。
在實現(xiàn)LS-SVM分類功能的神經(jīng)網(wǎng)絡(luò)時,神經(jīng)網(wǎng)絡(luò)權(quán)值系數(shù)qij在運算過程中保持不變,僅與訓(xùn)練數(shù)據(jù)集有關(guān)。在進(jìn)行神經(jīng)網(wǎng)絡(luò)訓(xùn)練前,首先將權(quán)值系數(shù)qij計算好并存放在FPGA的ROM單元中。為了縮短開發(fā)時間,MAC、MUL、ADD和SUB等計算單元均采用開發(fā)軟件QUARTUS II中的IP核實現(xiàn)。圖2可以看出,每個神經(jīng)元中ROM的讀取、RAM的讀取以及MUL(1)、MUL(2)的運算可以并行進(jìn)行,從而可以節(jié)約每個神經(jīng)元的運算時間。將網(wǎng)絡(luò)訓(xùn)練的初始αi值存儲在RAM中,當(dāng)運算需要αi時,可直接從RAM中讀取;下一個周期運算獲得新的αi值存儲在RAM中。RAM中的αi隨系統(tǒng)運行一直處于更新狀態(tài),這就對系統(tǒng)中時序的控制提出了較為嚴(yán)格的要求。在進(jìn)行神經(jīng)網(wǎng)絡(luò)訓(xùn)練時,只有在所有αi計算完成并存儲在RAM中,下一個周期的訓(xùn)練才能進(jìn)行,因為下一個周期的運算依賴于上一個周期的αi。以一個周期為例,說明LS-SVM神經(jīng)網(wǎng)絡(luò)神經(jīng)元FPGA的實現(xiàn),其流程圖如圖3所示。
圖中,神經(jīng)元按圖3箭頭所指的方向進(jìn)行運算,依次從基本元件庫中調(diào)用運算單元,從而完成式(14)中b 和式(15)中αi的計算。
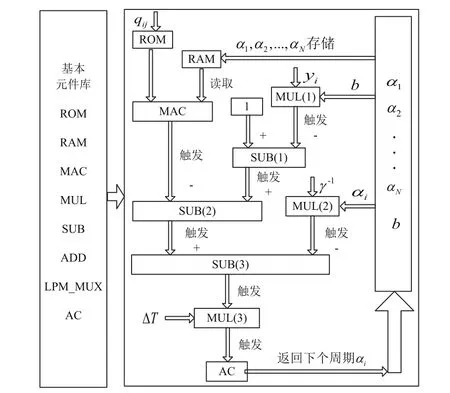
圖3 LS-SVM神經(jīng)網(wǎng)絡(luò)神經(jīng)元實現(xiàn)流程圖
LS-SVM神經(jīng)網(wǎng)絡(luò)串行計算的FPGA實現(xiàn)
LS-SVM串行計算的FPGA實現(xiàn)如圖4所示。系統(tǒng)主要由系統(tǒng)時序控制單元(TCU)、Lssvm_alpha單元、Lssvm_bias單元、RAM讀寫單元、Judge單元、Add及Lock單元組成。各單元的功能簡介如下。
(1)系統(tǒng)時序控制單元(TCU):負(fù)責(zé)整個系統(tǒng)的時序產(chǎn)生及控制,包括αi(i=1,…,N),b值運算時序的產(chǎn)生,RAM讀寫時序的產(chǎn)生,ROM讀取時序的產(chǎn)生以及系統(tǒng)中加法器、鎖存器等運算單元時序控制。
(2)Lssvm_alpha單元:在時序控制單元的控制下,串行逐個完成圖2所示的每個神經(jīng)元的計算。
(3)Lssvm_bias單元:當(dāng)前周期所有的αi(i=1,…,N)值計算完成后,將αi(i=1,…,N)值存儲在RAM中,通過時序控制模塊將αi(i=1,…,N)值從RAM中讀出,并與yi值進(jìn)行乘法累加運算,以獲得b。與此同時,該單元并行將運算獲得的b值送入Lssvm_alpha單元,進(jìn)行b值的更新,為下一個周期的運算做準(zhǔn)備,該單元的模塊結(jié)構(gòu)圖如圖5所示。
(4)RAM讀寫單元:負(fù)責(zé)αi(i=1, 2,…,N)存取,為Lssvm_alpha單元、Lssvm_bias單元以及加法器單元提供本周期的αi(i=1,…,N)值,同時從Lock鎖存器單元中獲得下一周期計算得到的αi(i=1,…,N)值,并按順序存儲。
(5)Judge單元用于判斷每個神經(jīng)元的輸出增量值是否小于設(shè)定閾值,若N個神經(jīng)元的輸出增量值均小于設(shè)定閾值,則判斷αi(i=1,…,N)訓(xùn)練完畢。
(6)Add單元將上一個周期的αi值與本周期神經(jīng)元輸出的增量值相加,通過Lock單元將獲得的αi逐個鎖存起來,并將所有計算完成的αi(i=1,…,N)統(tǒng)一傳給RAM單元存儲。
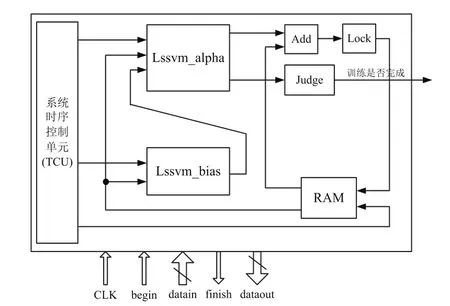
圖4 LS-SVM串行計算實現(xiàn)框圖

圖5 Lssvm_bias單元的模塊結(jié)構(gòu)圖

圖6 實驗1的FPGA實現(xiàn)運行結(jié)果
實驗結(jié)果及分析
通過仿真實驗測試串行LS- SVM結(jié)構(gòu)的性能,并將其與LS-SVM Matlab軟件包運算值進(jìn)行比較。實驗所用的計算機(jī)配置為:Intel (R)Core(TM)2Duo CPU2.40GHz,1GB內(nèi)存;Matlab版本為R2009a。硬件平臺為Altera公司的Cyclone III系列FPGA,系統(tǒng)仿真頻率為100MHz。軟件平臺為Quartus II編譯環(huán)境及Verilog HDL硬件編程語言。其中,采用verilog HDL實現(xiàn)該串行計算結(jié)構(gòu)具有較強(qiáng)的靈活性,因為可以在編譯階段指定處理數(shù)據(jù)的字長。
(1)實驗1。選取植物數(shù)據(jù)集(Iris data)中Irissetosa與Iris-versicolor共10個樣本點作為訓(xùn)練數(shù)據(jù),2類中剩余的90個樣本作為測試數(shù)據(jù)。Iris-setosa與Iris-versicolor線性可分,4個屬性分別為sepal length、sepal width、petal length和petal width。核函數(shù)選擇高斯核函數(shù),sig2=2.25;γ-1=0.2。圖6為參數(shù)α的FPGA平臺實現(xiàn)結(jié)果,“result”中的10個數(shù)分別代表參數(shù)α0,α1,…,α9,Judge模塊輸出信號all_ok為“1”時,α訓(xùn)練完成。將FPGA訓(xùn)練的α0, α1,…,α9、b值代入LS-SVM Matlab軟件包對測試數(shù)據(jù)集進(jìn)行預(yù)測,結(jié)果如表1所示:其中,分類準(zhǔn)確率達(dá)到98.89%,與LS-SVM Matlab軟件包獲得的分類準(zhǔn)確率相同。從參數(shù)α的收斂時間來看,F(xiàn)PGA的計算速度明顯優(yōu)于LSSVM Matlab軟件包的運算速度。結(jié)果表明,串行結(jié)構(gòu)的LS-SVM FPGA實現(xiàn)架構(gòu)同樣可以很好地解決實驗1的分類問題。可見,本文方法對解決線性可分分類問題是可行的,且在縮短訓(xùn)練時間的同時不會降低預(yù)測準(zhǔn)確率。

表1 實驗1的軟硬件平臺速度比
(2)實驗2。選取植物數(shù)據(jù)集(Iris data)中Irisversicolor和Iris-verginica共20個樣本點作為訓(xùn)練數(shù)據(jù),2類中剩余的80個樣本作為測試數(shù)據(jù)。Iris-versicolor與Iris-verginica線性不可分,4個屬性分別為sepal length、sepal width、petal length和petal width。核函數(shù)選擇高斯核函數(shù),sig2=2.25;γ-1=0.2。按照試驗1的方法,將FPGA訓(xùn)練得出的α0, α1,…,α19、b值代入LS-SVM Matlab軟件包對測試數(shù)據(jù)集進(jìn)行預(yù)測,獲得的結(jié)果如表2所示。其中,分類準(zhǔn)確率達(dá)到96.25%,比LS-SVM Matlab軟件包獲得的分類準(zhǔn)確率略高一些。從參數(shù)α的收斂時間看,F(xiàn)PGA的訓(xùn)練速度是LS-SVM Matlab軟件包的運算速度的28.65倍。結(jié)果表明,串行結(jié)構(gòu)的LSSVM FPGA實現(xiàn)架構(gòu)同樣可以很好地解決實驗2的分類問題。可見,本文方法對解決線性不可分分類問題是可行的,且在縮短訓(xùn)練時間的同時還提高了預(yù)測準(zhǔn)確率。

表2 實驗2的軟硬件平臺速度比
結(jié)束語
本文研究了最小二乘支持向量機(jī)的FPGA硬件實現(xiàn),完成了基于遞歸神經(jīng)網(wǎng)絡(luò)的LS-SVM串行FPGA結(jié)構(gòu)設(shè)計。該結(jié)構(gòu)具有串行計算、并行傳輸?shù)奶攸c。采用verilog HDL來實現(xiàn)該結(jié)構(gòu),設(shè)計者可以在編譯階段設(shè)置處理數(shù)據(jù)的字長,具有較強(qiáng)的靈活性。實驗表明,與LS-SVM matlab軟件包實現(xiàn)相比,基于遞歸神經(jīng)網(wǎng)絡(luò)的LS-SVM串行FPGA結(jié)構(gòu),能夠準(zhǔn)確地進(jìn)行線性可分、線性不可分?jǐn)?shù)據(jù)分類,并在速度上有一定的優(yōu)勢,驗證了該硬件結(jié)構(gòu)是可行、有效的,從而為LS-SVM在硬件平臺上實現(xiàn)提供了一種思路。
10.3969/j.issn.1001-8972.2015.24.004
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
哲學(xué)評論(2021年2期)2021-08-22 01:53:34
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中華詩詞(2019年7期)2019-11-25 01:43:04
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
