利潤約束的關聯規則挖掘算法
2015-11-19 09:17:10朱龍
華僑大學學報(自然科學版) 2015年5期
朱龍
(四川信息職業技術學院 信息工程系,四川 廣元628040)
購物籃分析是大數據在零售業的一個嶄新應用方向,就是商家希望通過分析每個購物籃子中都裝了什么商品,進而通過這些信息來研究顧客們的購買喜好,找出其中暗含的規則,其最終目標就是讓超市和生產企業通過大數據挖掘,建立自己產品的競爭優勢.購物籃分析中常用的是Apriori算法,它成功彌補了零售業數據分析不足、有價知識提取匱乏的問題,在商家積累的海量數據中,例如零售業數據,其中的知識若經Apriori算法有效分析提煉,可以充分提升商家銷售業績.本文對于Apriori算法原有的支持度和置信度的運算進行了相關調整,設計了新的基于利潤加權約束的加權支持度和加權置信度求取方法,并以此為基礎對Apriori算法進行改進.
1 Apriori算法
Apriori作為一種有特色的傳統算法,根據循序漸進的方式,利用數據庫找尋各項之間的聯系,并組成關聯規則.它的核心是挖掘穎繁項集,輸入minsupport,指導頻率的閾值,如minsupport=5%表示用戶(超市商家)是對數據庫中事務數據概率大于5%的子集感興趣.
Apriori算法輸入最小支持度minsupport后,利用數據庫提取出所有產品交易信息,并獲得Candidate 1-itemset.隨后就可以找到Large 1-itemset,此時將各個Large 1-itemset連接形成Candidate 2-itemset.當候選2項集中的某一項的支持度≥minsupport,則這個候選項就劃入到高頻項集.
以此類推,已建立的2項集為基礎,再找出所有的高頻2項集.然后,進一步利用提取出的高頻2項集,三三組合,生成候選3項集.重復高頻2項集的搜索方法,與minsupport作比較,提取大于minsupport的3項集構成高頻3項集.以此類推,直到達到用戶的目標為止.
2 利潤的約束關聯規則數據挖掘
Apriori算法是一種比較有效的關聯規則數據挖掘方法,但它以數據庫中所有項在挖掘時都是等價的為前提,即權值都為1、所有項的重要程度都一樣.但在現實世界中,數據庫中的每一項都是一種商品,它們的重要形式不同的.最直接的就是不同的商品帶給超市的利潤是不同的.若Apriori算法直接進行數據挖掘,則價值高的大件商品會因為出現頻率小(購買數量少)被算法認為不重要而丟掉,對關聯規則的數據挖掘結果造成不利影響.
2.1 利潤加權閾值的設計
利潤是超市經營決策者所關心的最重要的問題.利潤=商品銷售數量×商品利潤率,記為P,利潤P越大,越受到超市的重視.因為超市中商品銷售利潤率大多數情況下是比較固定的,不會隨著客戶購買商品的多少而變化,所以一種商品的銷售數量也可通過利潤P的值反映出來.
令項目權重集為

式中:W為商品的權重,由一段時間內的商品利潤計算得到.商品利潤建立的權重,如表1所示.

表1 權重對照表Tab.1 Weight comparison table
2.2 歸一化處理項目權重集
對于MINWAL(O)算法可能存在加權支持度大于1的情況,對權重集合W={W1,W2,…,Wj,…,Wm}實施歸一化處理.

原來的權重集W可以用歸一化權重集代替.為了表示方便,歸一化的項目權重集依舊用W表示,即
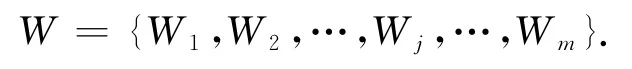
式中:W1+W2+…+Wj+…+Wm=1.
2.3 布爾向量的獲取
重新統一統計超市信息庫的原始交易記錄,交易記錄如表2所示.在購物籃分析的傳統方法中,僅是根據購買與否進行“1”和“0”狀態的歸一化處理.即對于在超市記錄的某種商品銷售數據中,若客戶購買,記為“1”;若無購買,則記為“0”.原始記錄依照此方法獲得的布爾向量,如表3所示.

表2 超市商品的交易記錄Tab.2 Trading recordings of supermarket goods

表3 傳統的布爾向量Tab.3 Traditional boolean vector
上述處理過程的缺點是沒有考慮每件商品的購買數量,認為大批量銷售和單件銷售的影響是一樣的,將銷售100件和1件等同處理.依照這種方式獲得的布爾類型數據,準確度值得商榷,獲得的知識有可能存在大量失真.首先,將某樣產品每一次的交易量除以在銷售中最多賣出的數量,如表2中商品1,4次交易中最大的銷售數量是93件,則商品1的各條記錄中在銷售數量的字段都除以數值93,可得到新的4次交易數值為0.88,0,0.16,1.00.按照此方式,對表1中的權重數據利用式(1)實施處理,數據統計后的結果,如表4所示.表4中:最后一行數據是新得出的.
當某項目(某種商品)歸一化后,若其數值大于或等于該商品的利潤加權閾值,布爾值轉換表中的對應位置結果記為“1”,以次標識用戶對該商品感興趣,以此作為后續挖掘關聯規則數據的屬性;若數值小于利潤加權閾值時,布爾值轉換結果記為“0”,作為后續挖掘關聯規則數據的屬性.根據這種規則,以商品1為例,它的權重W1等于0.4.因此,表4中商品1的交易號1的第1行記錄是0.881 7(>0.400 0),布爾變量取值為1;而交易號2,3記錄的值分別為0和0.161 3,它們都小于0.400 0,對應的布爾變量都取值為0;交易號4的記錄大于權重,以此布爾變量取值為1.依此類推,對表4中的數據實施布爾向量化,可以得到通過利潤加權閾值處理后的布爾記錄表,如表5所示.相比較于表3,可見表5的記錄更加簡化.

表4 歸一化后的商品交易記錄Tab.4 Commodity trading records after normalization

表5 利潤加權處理后的布爾向量Tab.5 Weight processing of Boolean vector
2.4 加權支持度和加權置信度
由于每個領域工程都已經有權重數據,Apriori算法中的運算需要進行改進,通過重新定義來滿足需要.以利潤加權關聯規則數據挖掘中的加權支持度和加權置信度為基礎.令數據庫中項目集X的交易記錄中的數量集合為S(X),交易總數取值為n.
對于項目集X{x1,…,xp},其加權支持度定義為

將最小加權支持度(Wminsupport)設定成用戶設定的原始最小加權支持度,假設計算出的加權支持度Wsup(X)≥Wminsupport,則算法稱X是“加權大項集”.
3 算法設計
對于Apriori算法,若求取高頻項集時,它的全部子集都屬于高頻項集;但是若項目添加了權重信息,上述的性質不再有效,大項集的某些子集可能并不屬于大項集.
3.1 算法描述
算法的輸入:數據庫D,每個商品項目的權重Wm,用戶設定的Wminsupport,用戶設定的最小加權置信度(Wminconf).
步驟1將各項目權重排除在外,基于布爾型關聯規則挖掘技術確定高頻項集,當項集的支持度大于或等于Wminsupport時,提取出該項集.如果一種商品十分受歡迎,數據挖掘過程中,加權的作用是突出更加它的受歡迎程度,即加權高頻項集是包含在這些未加權處理的項集的子集中,該項集就是加權高頻項集的超集.
步驟2對超集中包含的所有項集實施挖掘,求出每個超集中每個項集的加權支持度,把大于或等于(Wminconf)的項集取出作為加權大項集;對去除項集后的超集繼續掃描,直至找出超集中的所有的加權大項集.在第二步數據挖掘中,因為加權高頻項集包含在這些未加權項集的子集中,因此,無需再次掃描超市的商品交易數據庫,只需超集乘上每項所對應的項集權重即可.
步驟3基于加權大項集改良形成加權關聯規則.最大的改良之處在于經過加權處理后提取出的加權大項集形式未發生改變,因此,可以使用布爾型關聯規則產生加權大項集的關聯規則.
輸出:超市商品的加權關聯規則.
3.2 算法的數據挖掘流程
B為數據庫,Lk是高頻k的項集,Ck是候選k項集,T臨時項集,項目的權值屬性定義為W={W1,W2,…,Wj,…,Wm}.算法的運行過程為


定理1 設X為項集,C1和C2分別為單調性約束和非單調性約束.
1)如果C1(X)=不正確,那么?Y?X,C1(Y)∧C2(Y)=不正確,即X的任何子集都不同時滿足C1和C2;
2)如果C1(X)=正確,C2(X)=正確,則存在Y?X,使得C1(Y)∧C2(Y)=正確;
3)如果C1(X)=正確,C2(X)=不正確,則存在Y?X,使得C1(Y)∧C2(Y)=正確.
證明 如果C1(X)=不正確,很顯然有?Y?X.根據單調約束的性質,C1(Y)=不正確,于是不管C2(Y)的值如何,C1(Y)∧C2(Y)=不正確.
4 試驗結果分析
關聯規則挖掘的目標是挖掘出暗含在數據庫中的知識,為了測試基于利潤的約束的關聯規則挖掘算法的特性,選用了將其他算法與Apriori算法進行比較,如圖1所示.圖1中:縱坐標是數據挖掘獲取的高頻項集;橫坐標是不同的最小支持度的取值.對于各個不同的最下支持度,每個橫坐標點左邊柱體是Apriori算法數據挖掘所算出的最有意義的項目,右邊柱體是算法在該的最小支持度下挖掘出的有效項集數量.由圖1可知:其他算法(右邊柱體)和Apriori算法(左邊柱體)直接按對比明顯,提取出的有價值項集數目精簡明顯.
假設非單調性約束C1:max(S.cost)≤min(S.price);單調性約束C2:total(S.price)≥100;最小支持度為20%(表1).
1)求出數據庫頻繁1項集(按支持度由大到小排列):D,E,B,A,C.
2)C2(DEBAC)=不正確,得出N值至少大于等于2.
3)C1(D)=正確,C1(E)=正確,C1(B)=正確,C1(A)=正確,C1(C)=正確.
以A為例,D的支持度最大,沒有必要生成D的條件數據庫,因為它的支持度最大,已經沒有前綴項了.
4)求出A的條件數據庫,其投影事務在原數據庫中分別為(項按支持度由大到小排列):{DEB,DB,E,DE,DEB}.
5)求出頻繁1項集:D,E,B.由于DEBA為4項,大于N的值,因此,后面考慮繼續生成各項的條件數據庫.
6)C1(DEBA)=不正確;C1(DA)=正確;C1(EA)=正確;C1(BA)=不正確.
7)由于DEA的子集除了DEA是3項外,其余為≤2,經檢查,均不滿足C2,最后輸出滿足C1∧C2的A的條件數據庫中的頻繁項集為DEA.
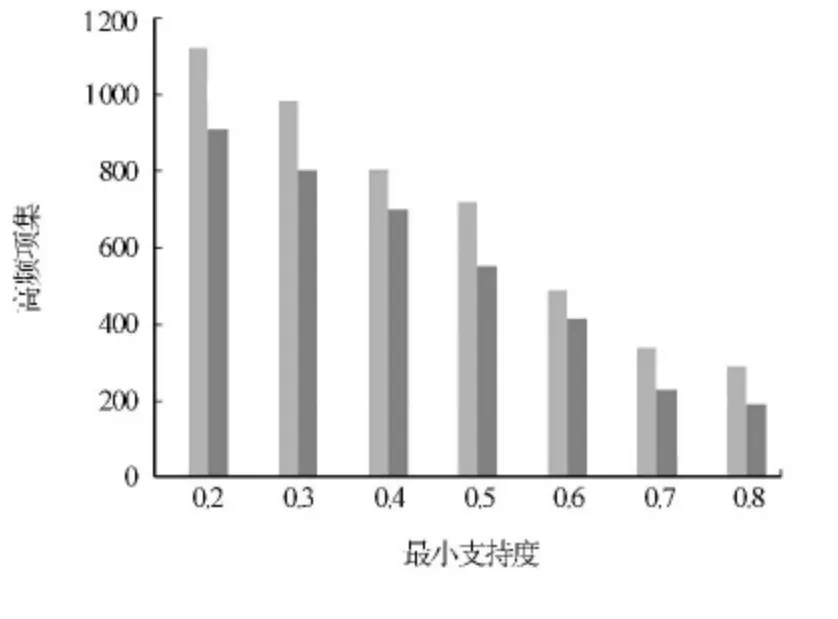
圖1 算法比較Fig.1 Algorithm comparison
5 結束語
針對Apriori算法在實際應用中的不足,設計了基于利潤的約束關聯規則挖掘算法,對數據庫的原始數據實施了利潤約束修正,增加了利潤加權閾值,有效提升數據挖掘算法的知識挖掘性能.到目前為止,大部分算法還只是一種挖掘,所以其算法還是不夠完善,而新算法不但能進行約束的挖掘,還能進行另一種算法,分別是單調性和非單調性.
[1]HAN Jia-wei,KAMBER M.數據挖掘概念與技術[M].北京:機械工業出版社,2001:132-156.
[2]陳奇,俞瑞釗.關聯規則采掘綜述[J].計算機應用研究,2000,17(1):1-5.
[3]李興良,陳湘濤.數據挖掘中關聯規則算法的研究[J].計算機工程與科學,2007(12):111-116.
[4]MICHAEL J A B,GORDON S L.數據挖掘:客戶關系管理科學與藝術[M].北京:中國財政經濟出版社,2004:10-52.
[5]黃健斌.基于關聯規則挖掘的入侵檢測技術研究[D].重慶:重慶大學,2007:13-19.
[6]王德興,胡剛,劉小平.基于概念和Apriori的關聯規則挖掘算法分析[J].合肥工業大學學報:自然科學版,2006,29(6):69-702.
[7]杜海濤,陳定方,張波.基于關聯規則的超市購物籃分析方[J].湖北工業大學學報,2008,23(4):15-18.
[8]薛紅,聶桂華.基于關聯規則分析的購物籃分析模型研究[J].北京工商大學學報:自然科學版,2008,23(4):15-18.
[9]黃嘉滿.面向零售業的關聯規則挖掘的研究與實現[D].上海:上海交通大學,2007:4-45.
[10]馮瑤.基于零售業的數據挖掘技術和關聯規則算法的改進研究[D].天津:河北工業大學,2006:31-43.
[11]謝小蘭.應用數據挖掘技術提高決策能力的研究[J].商情,2011(47):139-142.
[12]張文獻,陸建江.加權布爾關聯規則的研究[J].計算機工程,2003,29(9):55-57.
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
瘋狂英語·新讀寫(2020年3期)2020-06-06 09:06:16
當代水產(2019年7期)2019-09-03 01:02:08
學苑創造·A版(2018年11期)2018-02-01 06:29:20
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
湖南農業(2016年3期)2016-06-05 09:37:36
信息通信技術(2015年6期)2015-12-26 01:16:46
現代企業(2015年2期)2015-02-28 18:45:07
