用戶定制主題聚焦爬蟲的設(shè)計(jì)與實(shí)現(xiàn)
2015-12-20 06:59:12閔鈺麟黃永峰
計(jì)算機(jī)工程與設(shè)計(jì) 2015年1期
閔鈺麟,黃永峰
(1.清華大學(xué) 電子工程系 信息認(rèn)知與智能系統(tǒng)研究所,北京100084;2.清華大學(xué) 信息科學(xué)與技術(shù)國(guó)家實(shí)驗(yàn)室,北京100084)
0 引 言
互聯(lián)網(wǎng)時(shí)代用戶的個(gè)性化需求越來(lái)越高,在實(shí)際應(yīng)用場(chǎng)景下,不同用戶的需求通常存在差異,他們希望在其特定領(lǐng)域及方向上進(jìn)行 “定制化”的主題爬行。傳統(tǒng)的聚焦爬蟲在開(kāi)始工作之前需要對(duì)指定主題進(jìn)行建模和訓(xùn)練,在缺乏相應(yīng)主題訓(xùn)練集的情況下無(wú)法完成任務(wù),不能滿足用戶 “個(gè)性化”需求。本文設(shè)計(jì)并實(shí)現(xiàn)的定制主題聚焦爬蟲不依賴于主題訓(xùn)練集,僅在用戶提供少量未知主題的種子url(同一主題)的情況下完成主題爬行,得到針對(duì)該主題較高的收獲率 (havest rate)。
1 相關(guān)工作分析
聚焦爬蟲通過(guò)對(duì)url的優(yōu)先級(jí)進(jìn)行計(jì)算和排序,優(yōu)先訪問(wèn)較高概率指向相同主題網(wǎng)頁(yè)的url,從而得到較高的收獲率[1]。目前改進(jìn)聚焦爬蟲的思路主要有4 種:第1 種是基于網(wǎng)頁(yè)鏈接分析的方法,在論文[2]中,Hati定義了鏈接距離的計(jì)算方法并使用其對(duì)鏈接排序,Taylan在其論文中提出了基于樸素貝葉斯分類器的鏈接評(píng)分方法[3]。第2種思路是基于網(wǎng)頁(yè)文本分析的方法,主要思路是計(jì)算網(wǎng)頁(yè)文本或錨文本與主題的相關(guān)度,并使用相關(guān)度作為url排序的基準(zhǔn),例如G.Almpanidis提出了基于內(nèi)容和鏈接分析的方法[4],Hong Wei Hao的 研 究[5]表 明,在 主 題 相 似 度 計(jì) 算中使用潛在語(yǔ)義索引 (latent semantic indexing)比TFIDF有更好的表現(xiàn)。第3 種為基于本體領(lǐng)域的方法,Yang提出了支持本體的網(wǎng)站模型[6]并將其用于聚焦爬蟲,Punam利用特定領(lǐng)域的本體概念語(yǔ)義擴(kuò)大搜索話題,模仿人類的認(rèn)知搜索模式從SBS (social bookmarking site)找到潛在相關(guān)的網(wǎng)絡(luò)資源[7]。第4 種方法基于用戶日志,Sotiris Batsakis利用隱馬爾科夫模型 (HMM)學(xué)習(xí)用戶瀏覽行為并預(yù)測(cè)不同網(wǎng)頁(yè)聚類之間的聯(lián)系[8],Yajun Du提出了基于用戶日志的形式概念分析 (CFA)方法并將其用于網(wǎng)頁(yè)語(yǔ)義排名[9]。這些方法從不同角度出發(fā)提高聚焦爬蟲的效率,但是他們一個(gè)共同的局限性就是需要事先構(gòu)造主題訓(xùn)練集。
以基于網(wǎng)頁(yè)內(nèi)容的方法為例。基于網(wǎng)頁(yè)內(nèi)容的方法通常使用best-first策略對(duì)url進(jìn)行排序。best-first策略的基本思想是如果一個(gè)頁(yè)面和主題的相關(guān)度越高,則處于該頁(yè)面上的鏈接指向的網(wǎng)頁(yè)也屬于該主題的概率就越大。bestfirst策略實(shí)現(xiàn)方法如下:
(1)構(gòu)建具有一定規(guī)模的訓(xùn)練集,該訓(xùn)練集由網(wǎng)頁(yè)文本構(gòu)成,至少應(yīng)該有兩類,一類是與主題相關(guān)的網(wǎng)頁(yè)文本,另一類是與主題不相關(guān)的網(wǎng)頁(yè)文本。該訓(xùn)練集用于提取文本特征和主題建模。
(2)使用信息增益、χ2分布等方法提取該主題的特征,并統(tǒng)計(jì)特征詞的IDF權(quán)重,特征詞的IDF權(quán)重可以由總文件數(shù)目除以包含該詞語(yǔ)之文件的數(shù)目,再將得到的商取對(duì)數(shù)得到
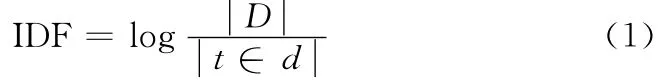
(3)利用VSM (vector space modle)模型將訓(xùn)練集中的主題映射到特征空間上,得到文本向量vt,其中n為文本特征維數(shù),xt,i(i=1,2,...,n)為TF·IDF特征權(quán)重
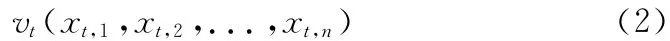
(4)對(duì)于一個(gè)新爬取的網(wǎng)頁(yè),同樣使用VSM 模型將解析出的網(wǎng)頁(yè)文本映射為向量vw
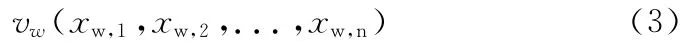
(5)使用余弦相似度評(píng)價(jià)網(wǎng)頁(yè)文本與主題的相關(guān)度
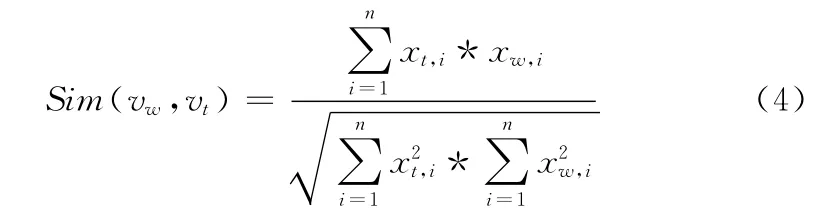
(6)將該頁(yè)面上的url加入隊(duì)列,并按照url所在頁(yè)面與主題的相關(guān)度Sim(vw,vt)進(jìn)行排序,這樣聚焦爬蟲每次從隊(duì)列中取出的url均為與主題最相關(guān)的頁(yè)面中的url。
通過(guò)分析可以發(fā)現(xiàn),基于網(wǎng)頁(yè)內(nèi)容的聚焦爬蟲需要提供該主題的訓(xùn)練集才能完成對(duì)特征提取以及主題向量的計(jì)算。實(shí)際上,幾乎所有的聚焦爬蟲均需要事先構(gòu)建一個(gè)針對(duì)該主題的訓(xùn)練集,而對(duì)于個(gè)性化的用戶需求來(lái)說(shuō),主要面對(duì)的問(wèn)題是用戶的需求千變?nèi)f化,爬蟲可能會(huì)因?yàn)槿狈τ脩粜枨笾黝}的訓(xùn)練集而無(wú)法完成任務(wù)。
針對(duì)以上問(wèn)題,本文提出基于聚類算法的自適應(yīng)主題模型,用于指導(dǎo)聚焦爬蟲在只有少量未知主題的url的情況下完成主題爬行。
2 自適應(yīng)主題模型
2.1 主題建模
為了使模型能夠準(zhǔn)確地描述主題,本文引入文本聚類算法k-means的思想。k-means算法的目的是將一個(gè)文本庫(kù)中的文本分為k類。對(duì)于一個(gè)含有n (n>k)個(gè)文本的它首先 隨 機(jī) 選 定k 個(gè) 文 本 作 為 初 始 類 的 中 心Mi=1,..,k(xMi,1,xMi,2,...,xMi,m),其中m 為文本特征維數(shù);對(duì)于剩下的每個(gè)文 本vt(xt,1,xt,2,...,xt,m),計(jì)算它到每個(gè)類中心的歐氏距離
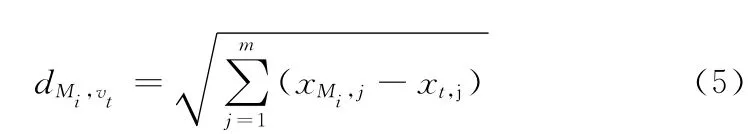
并把這個(gè)文本加入距離最近的類Mi,然后使用式 (6)更新該類的中心位置,為該類文本數(shù)目
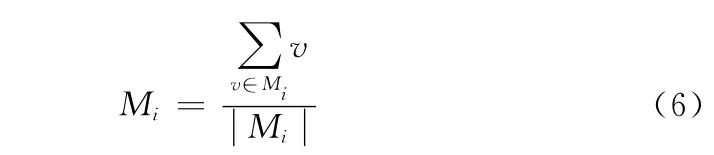
算法不斷重復(fù)這一過(guò)程,直到滿足某一收斂條件。
基于這一思想,對(duì)于用戶給定的n個(gè)url,因?yàn)閷儆谕恢黝},我們可以認(rèn)為這些url指向的網(wǎng)頁(yè)已經(jīng)聚為一類Mu,那么我 們 可 以 使 用 這n個(gè) 網(wǎng) 頁(yè) 文 本vui(i=1,..,n)(xui,1,xui,2,...,xui,m)的中心位置來(lái)代表用戶定制主題的向量

2.2 模型修正
在上一小節(jié)中我們基于聚類的主題模型得到了表征用戶定制主題的向量,但是該模型存在著初始向量過(guò)少的問(wèn)題。這些向量如果在特征空間上分布不均勻,那么它們的中心位置就不能很好地代表該主題。
為了能夠簡(jiǎn)單直觀地說(shuō)明這個(gè)問(wèn)題,我們以三維的特征空間為例。
如圖1所示,假設(shè)該主題的所有文本映射到特征空間后聚類形狀為球形,那么這個(gè)球的中心,即圖中 “O”所示位置,就可以代表這個(gè)主題 (類)的中心。

圖1 初始向量在特征空間上不均勻分布
如果用戶給定鏈接對(duì)應(yīng)的網(wǎng)頁(yè)文本映射到特征空間后為圖中 “+”所示位置,則使用式 (7)計(jì)算后得到的主題中心位于圖中的 “Δ”所在的位置。可以很明顯地看到,通過(guò)計(jì)算得到的用戶定制主題中心和實(shí)際的主題中心存在偏差。
為了解決這個(gè)問(wèn)題,需要在爬行過(guò)程中尋找屬于高相關(guān)度的網(wǎng)頁(yè)來(lái)不斷修正用戶定制主題中心。基本思路是每下載一個(gè)網(wǎng)頁(yè),提取網(wǎng)頁(yè)文本內(nèi)容后映射為向量vw,使用式 (4)計(jì) 算 該 向 量 與vui(i=1,..,n)的 余 弦 相 似 度Sim(vw,vui),vui(i=1,..,n)為 初始鏈 接 對(duì) 應(yīng) 的 網(wǎng) 頁(yè) 文 本 向 量。在VSM模型中,兩個(gè)向量的余弦相似度越接近于1,那么這兩個(gè)向量所對(duì)應(yīng)的話題就越相似。當(dāng)Sim(vw,vui)大于某閾值時(shí),我們可以認(rèn)為該網(wǎng)頁(yè)和用戶提供的某個(gè)網(wǎng)頁(yè)屬于同一話題,即這個(gè)網(wǎng)頁(yè)屬于該主題,那么我們就能使用向量vw來(lái)更新用戶定制主題中心。
用Mp(xp,1,xp,1,...,xp,m)表 示 更 新 前 的 主 題 中 心Mn(xn,1,xn,1,...,xn,m),表 示 更 新 后 的 主 題 中 心,vw(xw,1,xw,2,...,xw,m)表示用來(lái)更新主題中心的向量,那么更新公式可表達(dá)為
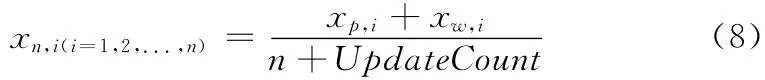
式中:n——用戶給出的鏈接個(gè)數(shù),UpdateCount——已更新次數(shù)。
使用該方法更新用戶定制主題中心可以在一定程度上解決主題中心偏移的問(wèn)題。
2.3 特征提取
在建模過(guò)程中需要解決的一個(gè)實(shí)際問(wèn)題是特征的提取與特征權(quán)重的計(jì)算。
問(wèn)題分析:初始信息只有用戶給定的一組鏈接,無(wú)法使用傳統(tǒng)的方法完成特征提取和IDF特征權(quán)重統(tǒng)計(jì)。
解決辦法:利用初始頁(yè)面的詞頻 (TF)作為特征的選取標(biāo)準(zhǔn),特征權(quán)重也使用TF代替TF·IDF。
特征詞一般選擇最能夠代表該主題的一類詞,詞頻高低在一定程度上也能體現(xiàn)一個(gè)詞在主題中的重要程度,單純使用詞頻作為特征選擇標(biāo)準(zhǔn)和特征權(quán)重會(huì)使一些常用但是沒(méi)有具體意義的詞 (又叫做停止詞),例如“的” “了” “和”等詞具有較高的權(quán)重。所以統(tǒng)計(jì)完詞頻之后需要先進(jìn)行停止詞的過(guò)濾再執(zhí)行特征降維。去除掉停止詞后可以大幅提高TF 作為特征權(quán)重的計(jì)算精度。
2.4 url排序策略
在得到用戶定制主題的模型之后,我們可以在基于best-first的策略上進(jìn)行改進(jìn)。我們使用url所在頁(yè)面對(duì)應(yīng)的文本向 量vw(xw,1,xw,2,...,xw,m)與 用 戶 定 制 主 題 中 心 點(diǎn)Mu(xu,1,xu,1,...,xu,m)的余弦相似度Sim(vw,Mu)來(lái)作為url優(yōu)先級(jí)的衡量標(biāo)準(zhǔn)
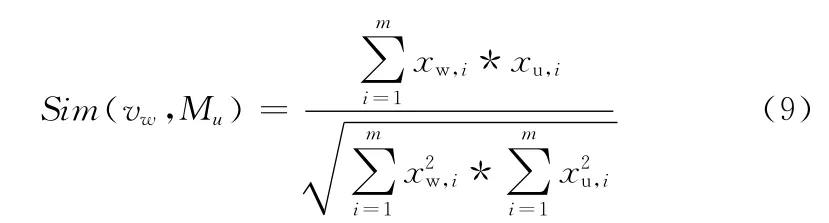
Sim(vw,Mu)越接近1,則頁(yè)面vw與主題就越接近,該頁(yè)面上的url在隊(duì)列中排序越靠前。
3 用戶定制主題爬蟲實(shí)現(xiàn)
基于自適應(yīng)主題模型,我們實(shí)現(xiàn)了用戶定制主題聚焦爬蟲。
系統(tǒng)框架如圖2所示,使用java語(yǔ)言實(shí)現(xiàn)。
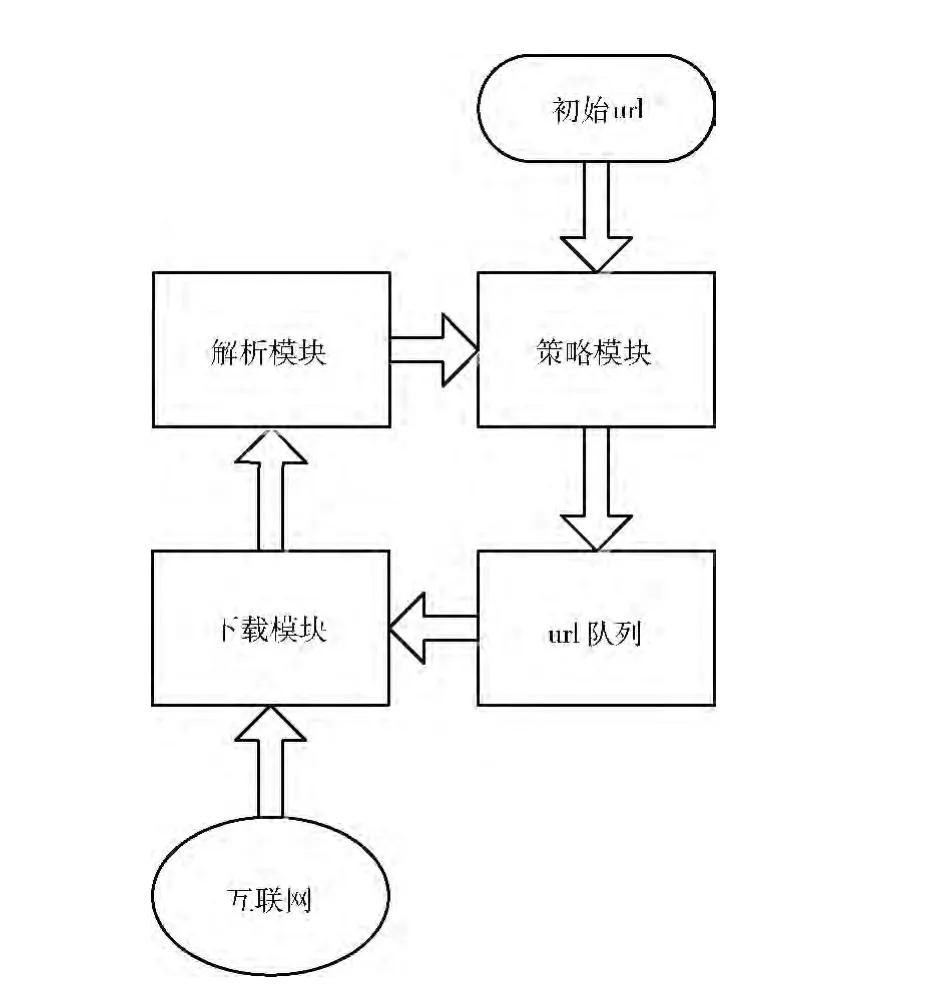
圖2 用戶定制主題爬蟲結(jié)構(gòu)
系統(tǒng)輸入為同一主題的初始url,由用戶自行指定。
系統(tǒng)框架中,下載模塊基于httpclient實(shí)現(xiàn)download函數(shù),可以根據(jù)url下載網(wǎng)頁(yè)。
解析模塊負(fù)責(zé)將該網(wǎng)頁(yè)中的文本和鏈接解析出來(lái)交給策略模塊處理。主要實(shí)現(xiàn)了兩個(gè)函數(shù)extract_urls和extract_content。這兩個(gè)函數(shù)均使用了第三方j(luò)ava包jsoup。jsoup可以通過(guò)css選擇器的語(yǔ)法來(lái)取得html文檔樹中的特定節(jié)點(diǎn)。extract_urls函數(shù)選擇所有含有href屬性的<a>節(jié)點(diǎn),并過(guò)濾掉其中href屬性值結(jié)尾為exe、jpg等非html頁(yè)面,最后返回這些鏈接和對(duì)應(yīng)的錨文本。extract_content函數(shù)選擇首先判斷網(wǎng)頁(yè)類型是topic型還是hub型,判斷依據(jù)是所有錨文本的長(zhǎng)度占整個(gè)頁(yè)面文本長(zhǎng)度的比例,如果該比值大于0.6,則認(rèn)為該頁(yè)面是hub型網(wǎng)頁(yè),否則認(rèn)為該頁(yè)面是topic類型;整個(gè)頁(yè)面文本的提取過(guò)程為選擇html文檔樹中所有節(jié)點(diǎn),去掉其中<script>、<iframe>等特殊的節(jié)點(diǎn),最后替換掉剩下節(jié)點(diǎn)的文本中換行符、空白符等無(wú)意義的符號(hào),即得到了整個(gè)頁(yè)面的文本;對(duì)于hub型網(wǎng)頁(yè),extract_content返回頁(yè)面中的所有錨文本,對(duì)于topic型網(wǎng)頁(yè),extract_content返回頁(yè)面文本去掉錨文本以后剩下的文本。
策略模塊模塊實(shí)現(xiàn)兩個(gè)功能,一是依據(jù)自適應(yīng)主題模型對(duì)初始url建模。過(guò)程為首先下載用戶給出的初始鏈接,調(diào)用extract_content函數(shù)提取文本內(nèi)容并完成特征提取,基于VSM 模型把網(wǎng)頁(yè)文本轉(zhuǎn)換為文本向量,然后計(jì)算這些文本向量的中心作為初始主題中心,并在后續(xù)的流程中更新主題中心。策略模塊另一個(gè)功能是分析網(wǎng)頁(yè)文本,對(duì)其中的未爬取url進(jìn)行優(yōu)先級(jí)評(píng)估,加入url隊(duì)列并排序。具體做法為提取下載網(wǎng)頁(yè)的文本和url,轉(zhuǎn)換網(wǎng)頁(yè)文本為文本向量,計(jì)算該向量和定制主題中心的距離,把該頁(yè)面上的url去重后加入隊(duì)列,并根據(jù)該距離對(duì)隊(duì)列中的url進(jìn)行排序。
系統(tǒng)工作流程如圖3所示。
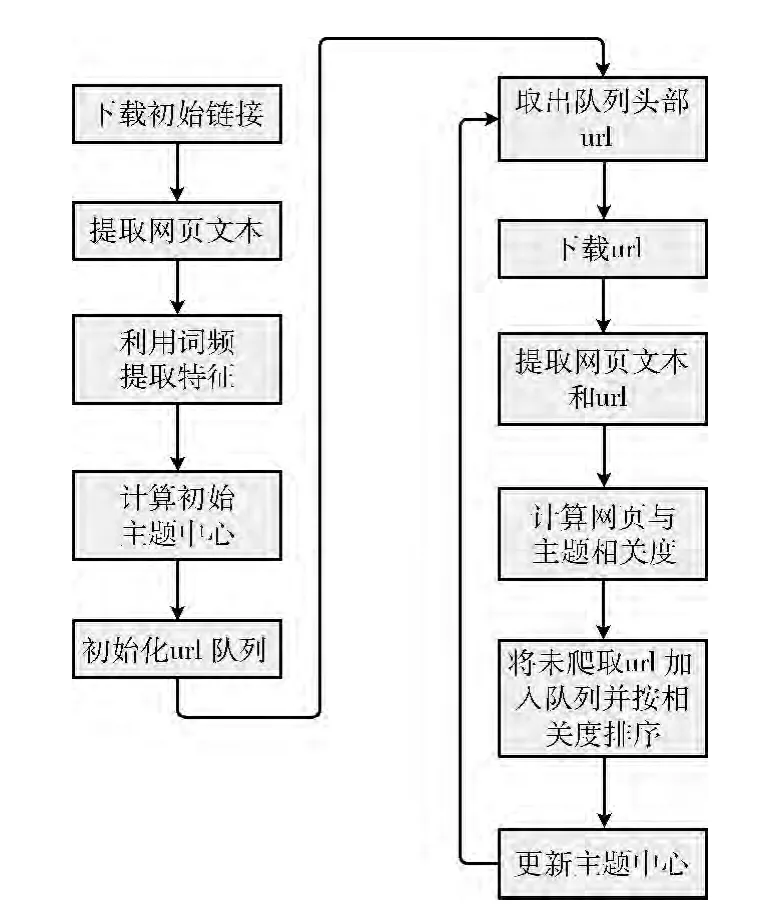
圖3 用戶定制主題爬蟲工作流程
4 實(shí) 驗(yàn)
4.1 評(píng)價(jià)體系
通常情況下使用收獲率 (HavestRate)來(lái)評(píng)價(jià)一個(gè)聚焦爬蟲的性能
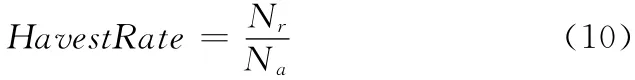
式中:Na——爬取網(wǎng)頁(yè)的總量,Nr——爬取網(wǎng)頁(yè)中和主題相關(guān)網(wǎng)頁(yè)的數(shù)量。HavestRate 越高,則爬取相同數(shù)量網(wǎng)頁(yè)的情況下,相關(guān)網(wǎng)頁(yè)的數(shù)量就越高。在帶寬一定的情況下,HavestRate 較高的聚焦爬蟲能夠在相同的時(shí)間內(nèi)獲取更多主題相關(guān)的網(wǎng)頁(yè),效率也就更高。
4.2 實(shí)驗(yàn)結(jié)果
為了客觀評(píng)價(jià)該聚焦爬蟲的性能,我們以使用bestfirst策略和width-first(寬度優(yōu)先)策略的爬蟲作為對(duì)比。
3個(gè)爬蟲都給定相同的10個(gè)體育新聞鏈接作為初始種子,基于best-first策略的爬蟲事先使用搜狗語(yǔ)料庫(kù)[10]進(jìn)行主題的訓(xùn)練。
在3個(gè)爬蟲各爬取了3000 個(gè)網(wǎng)頁(yè)后對(duì)爬行過(guò)程中HavestRate 的變化統(tǒng)計(jì)如圖4所示。從圖中可以看到使用width-first策略的爬蟲的效率最低,在爬行了3000個(gè)網(wǎng)頁(yè)之后HavestRate降到40%以下。使用best-first策略的爬蟲的效率最高,穩(wěn)定以后HavestRate 基本能保持在75%以上。基于自適應(yīng)主題模型的策略效率比best-first策略略低,在70%上下浮動(dòng),但也遠(yuǎn)遠(yuǎn)高于使用width-first策略的爬蟲。比best-first策略效率低的原因是基于best-first策略的爬蟲使用了語(yǔ)料庫(kù)進(jìn)行了訓(xùn)練,在特征提取和特征權(quán)重的計(jì)算上具有優(yōu)勢(shì),并且擁有更多的數(shù)據(jù)來(lái)確定主題向量。
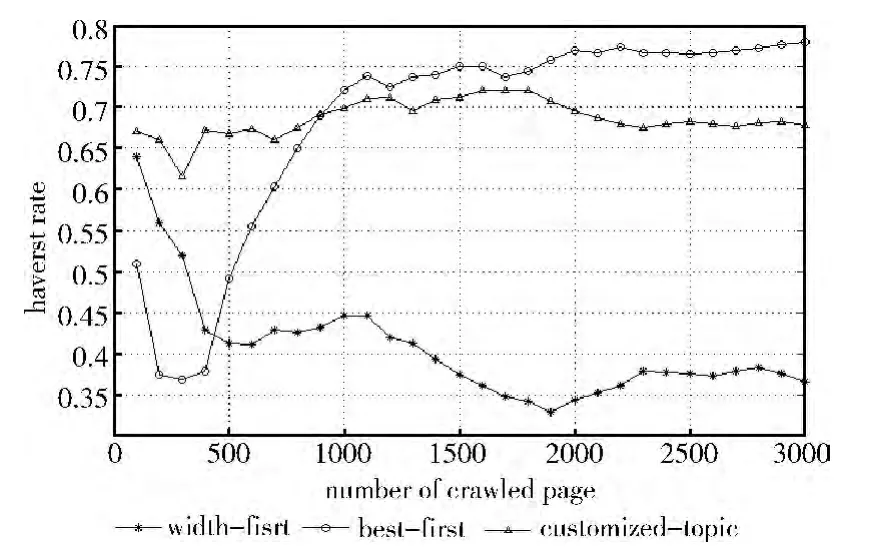
圖4 實(shí)驗(yàn)結(jié)果
5 結(jié)束語(yǔ)
為解決傳統(tǒng)聚焦爬蟲無(wú)法對(duì)未知主題爬行的問(wèn)題,本文提出了基于聚類算法的自適應(yīng)主題建模方法和修正方法,并基于該模型實(shí)現(xiàn)用戶定制主題聚焦爬蟲。通過(guò)對(duì)比實(shí)驗(yàn)驗(yàn)證,在沒(méi)有使用訓(xùn)練集的情況下,該爬蟲達(dá)到了和使用訓(xùn)練集主題爬蟲相當(dāng)?shù)男省T谟脩糁惶峁┥倭客恢黝}url的情況下,該爬蟲就可以完成未知主題的爬行,這點(diǎn)是傳統(tǒng)主題爬蟲無(wú)法比擬的優(yōu)勢(shì),具有實(shí)際的應(yīng)用價(jià)值。
[1]PENG Tao.Reseach on topical web crawling technique for topic-specific search engine [D].Changchun:Jilin University,2007 (in Chinese).[彭濤.面向?qū)I(yè)搜索引擎的主題爬行技術(shù)研究 [D].長(zhǎng)春:吉林大學(xué),2007.]
[2]Hati D,Kuma A.UDBFC:An effective focused crawling approach based on URL distance calculation [C]//Computer Science and Information Technology,2010.
[3]Taylan D,Dogus Univ,Poyraz M,et al.Intelligent focused crawler:Learning which links to crawl[C]//Innovations in Intelligent Systems and Applications,2011.
[4]Almpanidis G,Kotropoulos C,Pitas I.Combining text and link analysis for focused crawling-an application for vertical search engines [J].Information Systems,2007,32 (6):886-908.
[5]Hong Weihao,Cui Xiamu,Xu Chengyin.An improved topic relevance algorithm for focused crawling [C]//Systems,Man,and Cybernetics,2011.
[6]Yang SY.A focused crawler with ontology-supported website models for information agents[C]//Expert Systems with Applications,2010.
[7]Punam Bedi,Anjali Thukral,Hema Banati.Focused crawling of tagged web resources using ontology [J].Computers and Electrical Engineering,2013,39 (2):613-628.
[8]Sotiris Batsakis,Euripides GM Petrakis,Evangelos Milios.Improving the performance of focused web crawlers[J].Data&Knowledge Engineering,2009,68 (10):1001-1013.
[9]Du Yajun,Hai Yufeng.Semantic ranking of web pages based on formal concept analysis [J].Journal of Systems and Software,2013,86 (1):187-197.
[10]Sogou corpus [EB/OL].http://www.sogou.com/labs/dl/c.html,2013 (in Chinese). [Sogou語(yǔ)料庫(kù) [EB/OL].http://www.sogou.com/labs/dl/c.html,2013.]
猜你喜歡
大灰狼畫報(bào)·益智版(2024年3期)2024-12-09 00:00:00
保健醫(yī)苑(2022年1期)2022-08-30 08:39:14
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
語(yǔ)文知識(shí)(2014年1期)2014-02-28 21:59:13
河南科技(2014年23期)2014-02-27 14:19:15
