分步增值評(píng)分——提高主觀題評(píng)分質(zhì)量的有效方法
2015-12-27 06:25:26劉斯佳張建新
心理學(xué)探新 2015年3期
劉斯佳,張建新
(1.中國科學(xué)院心理研究所,北京100101;2.中國科學(xué)院大學(xué),北京100049)
1 問題的提出
1.1 主觀題評(píng)分中存在的問題
主觀題包括簡答題、論述題、應(yīng)用題、作文題等。相對(duì)客觀題,主觀題能更為真實(shí)地反映考生的能力,因此被廣泛運(yùn)用于人員選拔考試和語言類考試中,對(duì)人員的錄用和篩選具有重要的現(xiàn)實(shí)意義。然而,主觀題評(píng)分的客觀性和有效性卻不容樂觀(關(guān)丹丹,2008)。前期研究發(fā)現(xiàn)甚至某國家級(jí)考試論述題依然存在評(píng)分員寬嚴(yán)程度異常的現(xiàn)象(李中權(quán),孫曉敏,張厚粲,張立松,2008)。作文題作為一種復(fù)雜主觀題型,其誤差控制問題相較其他類型的主觀題型更為棘手,也更早受到研究者關(guān)注(劉遠(yuǎn)我,張厚粲,1998)。有研究發(fā)現(xiàn),評(píng)分員對(duì)作文評(píng)分寬嚴(yán)程度同樣存在著顯著差異(劉紅云,陳閱,駱方,王云峰,2010)。
主觀題評(píng)分的信度受到許多因素影響,包括題目難度、評(píng)分程序復(fù)雜程度、評(píng)分者間差異等等。有作者指出評(píng)分者誤差復(fù)雜性最高(王博,卞冉,車宏生,王蓉,2012)。評(píng)分者因?yàn)椴荒芎芎玫卣莆赵u(píng)分標(biāo)準(zhǔn),造成他們?cè)谠u(píng)分過程中認(rèn)知負(fù)荷過大,對(duì)不同等級(jí)評(píng)分標(biāo)準(zhǔn)認(rèn)識(shí)模糊,從而擴(kuò)大了評(píng)分誤差;另一方面,為了減少認(rèn)知負(fù)荷,評(píng)分者可能形成保守的打分策略,使考生評(píng)分結(jié)果難以進(jìn)行區(qū)分(Gilfert &Harada,1992)。王博等(2012)對(duì)某大型人事考試評(píng)分分析中,首次描述了保守現(xiàn)象的“習(xí)得”過程。可以預(yù)見的是,作文的評(píng)分過程可能存在更為嚴(yán)重的失真現(xiàn)象。因此,在有效評(píng)價(jià)主觀評(píng)分誤差的基礎(chǔ)上,有必要通過優(yōu)化評(píng)分流程來降低作文評(píng)分的誤差程度。
1.2 分步增值評(píng)分模式
在此背景下,國外研究者提出了分步增值評(píng)分模式(rating augmentation)以進(jìn)行有效的流程控制(Johnson,Penny,& Gorden,2000)。王博等(2012)在國內(nèi)首先對(duì)這種評(píng)分模式進(jìn)行了介紹。分步增值評(píng)分模式首先在較為寬泛的檔位上(bench mark)對(duì)試卷進(jìn)行打分,比如1 至4 檔;然后評(píng)分者通過附加分?jǐn)?shù)對(duì)試卷傾向性(lean)進(jìn)行評(píng)估,以“+”“-”進(jìn)行表示;最后分?jǐn)?shù)通過統(tǒng)一算法轉(zhuǎn)化為數(shù)值,形成考生的原始成績。這種方式可以幫助評(píng)分者確保評(píng)分成績的一致性和區(qū)分性。分步增值評(píng)分模式近期在國外的作文評(píng)分和言語類考試評(píng)分中得到了較為廣泛的應(yīng)用(如Penny & Johnson,2011;Morgan,Zhu,Johnson,& Hodge,2014)。然而對(duì)中文數(shù)據(jù)庫搜索之后,尚未發(fā)現(xiàn)分步增值評(píng)分模式的實(shí)證研究。
1.3 評(píng)分模式的量化考察
在另一個(gè)方面,如何選擇方法更好地量化主觀題的評(píng)分評(píng)價(jià)也是需要考慮的一個(gè)問題。關(guān)丹丹(2008)認(rèn)為項(xiàng)目反應(yīng)理論對(duì)于主觀題的評(píng)分評(píng)價(jià)具有較明顯的優(yōu)勢,并且特別對(duì)多面Rasch 模型(MFRM)進(jìn)行了介紹。MFRM 是項(xiàng)目反應(yīng)理論的衍生模型,可以很好地量化主觀題的區(qū)分度以及評(píng)分者評(píng)分時(shí)的寬嚴(yán)程度和偏差程度,MFRM 模型在往期研究中較為常見(李中權(quán)等,2008;劉紅云等,2010)。本文主要旨在通過MFRM 模型,分別考察傳統(tǒng)綜合評(píng)分模式和分步增值評(píng)分模式對(duì)于評(píng)分結(jié)果的區(qū)分度以及評(píng)分者的評(píng)分寬嚴(yán)程度和偏差程度;另外,通過引入專家評(píng)分,并假定其為評(píng)分的真分?jǐn)?shù)后,進(jìn)而考察綜合評(píng)分模式和分步增值評(píng)分模式的誤差程度;最后,通過評(píng)分用時(shí)來描述兩種評(píng)分模式的評(píng)分效率。研究假設(shè)相對(duì)于綜合評(píng)分模式,分步增值評(píng)分模式對(duì)評(píng)分結(jié)果的區(qū)分度更好、評(píng)分者在評(píng)分偏差程度指標(biāo)上的表現(xiàn)更加理想,并且可以提高評(píng)分效率。
2 研究設(shè)計(jì)
研究抽取某國家級(jí)大型考試的實(shí)測作文題答卷500 份作為樣本。挑選20 名評(píng)分經(jīng)驗(yàn)在三年以上的評(píng)分者參與評(píng)分。評(píng)分種類包括了傳統(tǒng)評(píng)分使用的綜合評(píng)分模式,以及上述介紹的分步增值評(píng)分模式。其中,綜合評(píng)分模式由6 名評(píng)分者參與評(píng)分,而分步增值評(píng)分模式由其余14 名評(píng)分者參與評(píng)分。在評(píng)分之前,首先對(duì)評(píng)分者進(jìn)行集中培訓(xùn),讓所有評(píng)分者了解作文題評(píng)分的要求和標(biāo)準(zhǔn)(見表1)。而參與分步增值評(píng)分模式的評(píng)分者則附加培訓(xùn)了分步評(píng)分過程中的等級(jí)、檔位和傾向(即“+”、“-”)標(biāo)準(zhǔn)(見表2)。評(píng)分者分為綜合評(píng)分組和分步評(píng)分組,他們的評(píng)分過程在下文中詳細(xì)介紹。

表1 綜合評(píng)分法的評(píng)分標(biāo)準(zhǔn)
綜合評(píng)分組:隨機(jī)選擇6 名評(píng)分者采用雙評(píng)方式獨(dú)立對(duì)500 份試卷進(jìn)行評(píng)價(jià),要求評(píng)分者按照表1 中的分制直接給考生打分。如果兩名評(píng)分者的評(píng)分結(jié)果超出誤差允許范圍,則要求第三名評(píng)分者進(jìn)行評(píng)分。考生的最終成績?nèi)∽詢擅u(píng)分者評(píng)定成績的平均值,或者第三名評(píng)分者和與其評(píng)分最接近的評(píng)分成績的平均值。
分步評(píng)分組:評(píng)分過程共分兩個(gè)階段。第一階段隨機(jī)選擇4 名評(píng)分者對(duì)500 份試卷參照表1 中的等級(jí)標(biāo)準(zhǔn)進(jìn)行定級(jí)工作;第二階段,對(duì)已經(jīng)定好等級(jí)的試卷,在每個(gè)等級(jí)內(nèi)再分為三檔,評(píng)分者對(duì)照各等級(jí)內(nèi)挑選的檔位標(biāo)桿卷進(jìn)行歸檔,歸檔原則是判斷當(dāng)前試卷水平與哪份檔位標(biāo)桿卷水平更為接近;評(píng)分者從整數(shù)水平對(duì)文章進(jìn)行歸檔后,還須進(jìn)一步指出文章是否有必要通過“+”和“-”進(jìn)行額外評(píng)分。如果標(biāo)記“+”,則代表比標(biāo)桿卷的能力水平要高;反之則要低(見表2)。評(píng)分者按照等級(jí)評(píng)分結(jié)果分成了四種類型,其中1 類卷(8.3%)每組由2 人評(píng)分,2 類卷(58. 2%)每組由3 人評(píng)分,3 類卷(30.5%)每組由3 人評(píng)分,4 類卷(3.0%)每組由2人評(píng)分。上述兩階段均采用評(píng)分者獨(dú)立評(píng)分的雙評(píng)方式。
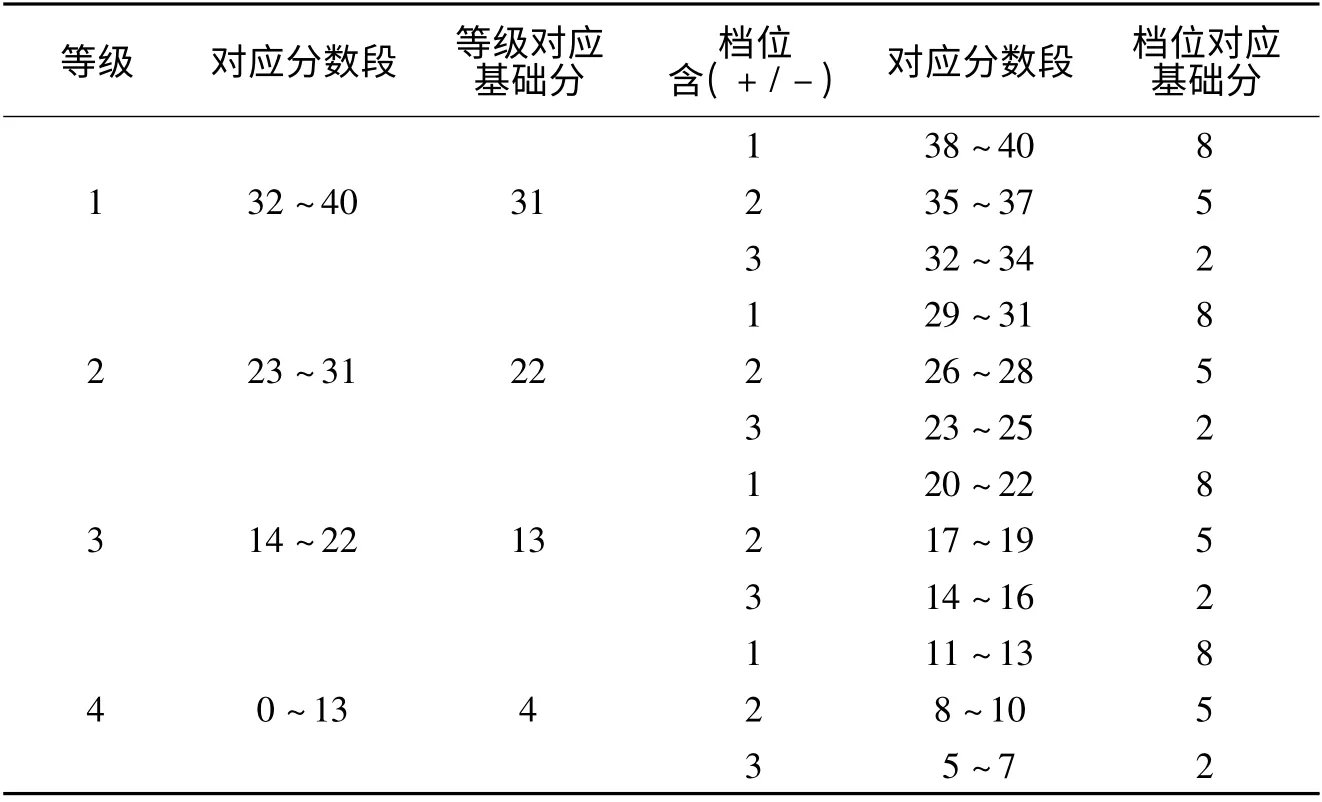
表2 分步評(píng)分分?jǐn)?shù)轉(zhuǎn)換對(duì)應(yīng)表
需要說明的是,在分步評(píng)分中,對(duì)于第一階段評(píng)分者12 評(píng)給出等級(jí)不一致的情況,先保留各自評(píng)判等級(jí)到第二階段,在第二階段分別在不一致的等級(jí)上再進(jìn)行雙評(píng),即在定檔階段會(huì)出現(xiàn)12 評(píng)和1234評(píng)兩種情況。這么處理是因?yàn)椋瑢?duì)于大多數(shù)判等不一致卷而言,由于有可能試卷本身就處于等級(jí)臨界水平上下,如果第二階段定檔時(shí)各評(píng)分者分歧不大,且所給出的檔位也在這個(gè)臨界點(diǎn)附近,第一階段定級(jí)的不一致就是可以接受的。另外,在第二階段如果認(rèn)為待評(píng)卷定級(jí)不夠準(zhǔn)確,可以做出“裁定”操作,不再進(jìn)行歸檔,重新回到第一階段進(jìn)行定級(jí)工作。
3 研究結(jié)果
3.1 評(píng)分等級(jí)不一致性
對(duì)兩種評(píng)分模式下的評(píng)分結(jié)果進(jìn)行等級(jí)不一致分析。其中綜合評(píng)分組不一致評(píng)分卷數(shù)為177 份(占35.40%),分步評(píng)分組不一致評(píng)分卷數(shù)為185 份(占37.00%)。兩種評(píng)分模式下評(píng)分不一致情況沒有顯著差異(χ2=0.22,p=0.64,odds ratio=1.03)。
3.2 評(píng)分成績水平分布

圖1 綜合評(píng)分組及分步評(píng)分組評(píng)分成績的直方圖和密度線
如圖1 所示,綜合評(píng)分組的評(píng)分成績(M =27.91,SD =3.92)相比分步評(píng)分組的評(píng)分成績(M=24. 14,SD = 6. 18)偏高,t(998)= 11. 51,p <0.001。并且綜合評(píng)分的峰度(Kurtosis=5.31,SE=0.22)相對(duì)分步評(píng)分的峰度(Kurtosis = -0.12,SE =0.22)更高,因此成績相對(duì)更為集中。另外,綜合評(píng)分的偏度(Skewness = -1.47,SE =0.11)相比分步評(píng)分(Skewness= -0.28,SE =0.11)顯示出更高的負(fù)偏態(tài)趨勢。另外,相比綜合評(píng)分組12 評(píng)的相關(guān)性(r=0.67,p <0.001),分步評(píng)分組12 評(píng)的相關(guān)性更高(r=0.76,p <0.001)。并且,以1 評(píng)作為因變量,一般線性模型發(fā)現(xiàn)2 評(píng)成績 × 組別(綜合、分步組)的交互作用顯著,F(xiàn) =33. 26,p <0. 001,η2=0.59,說明兩組相關(guān)系數(shù)大小存在顯著差異。
3.3 評(píng)分成績的多面Rasch 模型分析
使用Facets 3.71.4 學(xué)生版對(duì)兩種評(píng)分模式下的平均評(píng)分結(jié)果進(jìn)行多面Rasch 模型分析。首先將兩種評(píng)分模式成績劃分為12 個(gè)檔位,通過概率曲線進(jìn)行描述。理想情況下,概率曲線的峰值在每個(gè)檔位的分布比較均勻,如果概率分布過高或過低則表明檔位較難以區(qū)分。從圖2A 的檔位概率曲線可見綜合評(píng)分成績?cè)诘蜋n位較難區(qū)分,然而分步評(píng)分成績的概率曲線相比較綜合評(píng)分卻較為均勻。將12個(gè)檔位歸并成6 個(gè)分?jǐn)?shù)段之后,結(jié)果顯示分步評(píng)分成績的概率曲線依然較為理想(見圖2B)。
繼而對(duì)評(píng)分者的寬嚴(yán)程度、偏差程度以及區(qū)分度進(jìn)行分析(Linacre,2014)。分析選取綜合評(píng)分1評(píng)成績和分步評(píng)分第二步1 評(píng)成績作為因變量,考察各自1 評(píng)評(píng)分者的寬嚴(yán)程度、偏差程度和分?jǐn)?shù)的區(qū)分度。由于在分步增值評(píng)分模式中,每個(gè)評(píng)分者分別對(duì)某一等級(jí)的答卷進(jìn)行評(píng)分,故被給予高分答卷的評(píng)分者在寬嚴(yán)程度的結(jié)果上自然會(huì)“更高”或“更低”,因此并不能有效評(píng)定評(píng)分者的寬嚴(yán)程度,因此本研究只對(duì)綜合評(píng)分組評(píng)分者的寬嚴(yán)程度進(jìn)行分析。結(jié)果如表3 所示。

表3 評(píng)分者的寬嚴(yán)程度、偏差程度以及區(qū)分度

續(xù)表3

圖2 不同評(píng)分成績層次的概率曲線
寬嚴(yán)程度指標(biāo)(severity estimate)是對(duì)某個(gè)評(píng)分者總體對(duì)評(píng)分是否呈現(xiàn)偏低或偏高的趨勢(大于0為評(píng)分寬松,反之亦然),而寬嚴(yán)程度所對(duì)應(yīng)的標(biāo)準(zhǔn)誤可以判斷評(píng)分的穩(wěn)定程度。從表3 中的寬嚴(yán)程度指標(biāo)來看,所有綜合評(píng)分組評(píng)分者在這個(gè)指標(biāo)的分值都為正,因此說明評(píng)分存在過于寬松的現(xiàn)象。
偏差程度,或偏差診斷指標(biāo)(misfit diagnosis)由OUTFIT 和INFIT 卡方指標(biāo)來進(jìn)行評(píng)價(jià)。其中,OUTFIT 對(duì)位于兩端的成績比較敏感,而INFIT 則對(duì)所有成績等級(jí)中存在的偏差現(xiàn)象比較敏感,可以診斷成績中不可預(yù)期的復(fù)雜特性。如果OUTFIT 和INFIT 分?jǐn)?shù)在0.5 和1.5 之間,則說明成績比較合理;如果分?jǐn)?shù)高于1.5,則說明在某個(gè)成績段上存在評(píng)分偏差,而如果分?jǐn)?shù)低于0.5,則可能說明評(píng)分者沒有用所有的分?jǐn)?shù)段進(jìn)行評(píng)分。結(jié)果顯示,綜合評(píng)分組評(píng)分者ID 01 和ID 06 的偏差程度超出了可接受的范圍,說明評(píng)分偏差過高;而評(píng)分者ID 02 的偏差沒有達(dá)到可接受的范圍,說明可能沒有使用所有的評(píng)分段來進(jìn)行評(píng)分。相比之下,分步評(píng)分組評(píng)分者的評(píng)分結(jié)果卻沒有出現(xiàn)評(píng)分偏差過大或過小的現(xiàn)象。
區(qū)分度(item discrimination)考察的是考生的評(píng)分成績相對(duì)于理想的區(qū)分度之間的偏差程度。區(qū)分度越接近1 越好,表明成績的區(qū)分與檔位相符合,大于1 則說明在某些成績上的區(qū)分度比預(yù)期更高,相比合理區(qū)分度打分更為細(xì)致;而小于1 則說明在某些成績上的區(qū)分度比預(yù)期更低,相比合理區(qū)分度打分較為粗疏。結(jié)果顯示,綜合評(píng)分組評(píng)分者的評(píng)分成績的區(qū)分度較1 的偏差(M =0.29,SD =0.17),相比分步評(píng)分組偏差更大(M =0.15,SD =0.10),Cohen’s d=1.15,達(dá)到高差異水平。
3.4 評(píng)分成績的誤差分析
為了進(jìn)一步探究兩種評(píng)分方法在評(píng)分效果上的差異,研究選取了不同評(píng)分方法下最終成績爭議較大的試卷進(jìn)行評(píng)分準(zhǔn)確性分析。在挑選爭議卷時(shí),選取兩種評(píng)分方法最終得分差值在8 分以上的試卷共94 份,由專家先進(jìn)行評(píng)定。一般認(rèn)為,主觀閱卷雙評(píng)的評(píng)分差值閾限在滿分的20%以內(nèi)是可接受的。專家閱卷時(shí),并沒有限定具體的評(píng)分方式,而是讓專家根據(jù)自己的評(píng)分習(xí)慣進(jìn)行評(píng)分。假定專家評(píng)分結(jié)果為真分?jǐn)?shù),分別計(jì)算綜合評(píng)分組和分步評(píng)分組成績和專家評(píng)分的差異,并且再由分步評(píng)分組挑出1 評(píng)成績作為比較,其差值視為評(píng)分誤差。
結(jié)果發(fā)現(xiàn),綜合評(píng)分組的誤差值最高(M=7.11,SD=2.53),分步評(píng)分組(M=3.22,SD=2.34)和分步評(píng)分組1 評(píng)誤差值較小(M=3.51,SD=2.95)。三組間的差異顯著(F=64.12,p <0.001,η2=0.32),而事后檢驗(yàn)發(fā)現(xiàn)綜合評(píng)分組和分步評(píng)分組(MD =3.88,p<0.001,Cohen’s d =0.20)以及分步評(píng)分1 評(píng)成績(MD=3.59,p <0.001)的差異均顯著,然而分步評(píng)分組和分步評(píng)分1 評(píng)成績之間的差異卻不顯著(MD =0.29,p=0.73,Cohen’s d=1.71)。
3.5 評(píng)分效率分析
實(shí)驗(yàn)中,對(duì)評(píng)分者的評(píng)分時(shí)間進(jìn)行了測量。由于評(píng)分時(shí)間記錄了裝訂了10 至20 份試卷的試卷本為單位,通過求平均計(jì)算了在某個(gè)試卷本中試卷評(píng)分的平均時(shí)間;另外,分步評(píng)分組試卷在第二階段進(jìn)行了不同等級(jí)的匯總,因此可以相應(yīng)地計(jì)算出每個(gè)等級(jí)卷本的評(píng)分時(shí)間,并與第一階段相應(yīng)的試卷評(píng)分時(shí)間進(jìn)行求和;最后求得500 份試卷在綜合評(píng)分組12 評(píng)、分步評(píng)分組12 評(píng)和分步評(píng)分1 評(píng)中所用的總評(píng)分時(shí)間進(jìn)行比較。
結(jié)果發(fā)現(xiàn),綜合評(píng)分組的平均用時(shí)(秒)較短(M=112.20,SD=23.31),分步評(píng)分組的平均用時(shí)較長(M=169.49,SD =26.89),而分步評(píng)分1 評(píng)的總評(píng)分時(shí)間卻比綜合評(píng)分12 評(píng)所用的總時(shí)間更短(M=91.68,SD=19.59)。三組間的差異顯著(F =1478.82,p <0.001,η2=0.66),而事后檢驗(yàn)發(fā)現(xiàn)綜合評(píng)分組評(píng)分效率比分步評(píng)分組更高(MD=57.29,p <0.001,Cohen’s d =0.60),但卻不如分步評(píng)分1評(píng)(MD= -20.52,p <0.001,Cohen’s d=0.17)。
4 討論
4.1 主觀題的評(píng)分誤差問題
實(shí)證結(jié)果顯示,作文題成績的確存在大量評(píng)分等級(jí)不一致情況。這樣的結(jié)果和往期作文題或其他主觀題成績研究結(jié)果是相互吻合的(關(guān)丹丹,2008;劉遠(yuǎn)我,張厚粲,1998;劉紅云,陳閱,駱方,王云峰,2010)。這說明雖然主觀題能更好地反映考生能力,然而對(duì)主觀題評(píng)分進(jìn)行控制存在問題。劉紅云等(2010)通過多面Rasch 模型對(duì)作文綜合評(píng)分模式下評(píng)分者的寬嚴(yán)程度和區(qū)分度進(jìn)行了量化分析,然而現(xiàn)在尚沒有探討作文評(píng)分模式的其他實(shí)證研究文獻(xiàn)。
4.2 分步增值評(píng)分模式的優(yōu)越性
通過引入分步增值評(píng)分模式進(jìn)行流程控制(王博等,2012),我們發(fā)現(xiàn)分步評(píng)分組相對(duì)于傳統(tǒng)綜合評(píng)分組的評(píng)分分布情況確實(shí)存在一些優(yōu)越性,并且12 評(píng)的一致性程度也更高。概率曲線結(jié)果進(jìn)一步表明,分步評(píng)分相較于綜合評(píng)分的平均值在不同難度上區(qū)分程度更好。這樣的結(jié)果說明,分步增值評(píng)分模式是一種有價(jià)值的嘗試,或許可以有效解決主觀題(特別是作文題)中的評(píng)分質(zhì)量問題。
從各個(gè)評(píng)分者評(píng)分寬嚴(yán)程度、偏差程度和區(qū)分度的角度而言,分步評(píng)分組相較于綜合評(píng)分組同樣更加優(yōu)越,而綜合評(píng)分組某些評(píng)分者的偏差程度指標(biāo)則出現(xiàn)過高或過低的異常現(xiàn)象,說明存在評(píng)分不穩(wěn)定或者某些分?jǐn)?shù)段數(shù)值太少的不利現(xiàn)象。因此,分步增值評(píng)分模式不僅對(duì)于總體評(píng)分成績有積極影響,對(duì)評(píng)分者導(dǎo)致評(píng)分成績差異的現(xiàn)象或許也可以起到良好的控制作用。然而,為何分步評(píng)分組相比綜合評(píng)分組在評(píng)分者的偏差程度和區(qū)分度層面有更好的控制作用呢?這樣的差異或許來自于主觀題考試對(duì)評(píng)分尺度的選擇層面。
值得注意的是,我國國家級(jí)作文題一般采用15分以上的大量尺評(píng)分量表。而陳睿(2011)、關(guān)丹丹等人(2011)的實(shí)證研究認(rèn)為大尺度評(píng)分量表下評(píng)分者間的一致性有待提高。在保持大尺度評(píng)分的前提下,分步增值評(píng)分模式將難以區(qū)分的評(píng)分標(biāo)準(zhǔn)細(xì)化成可控制的等級(jí)和檔位尺度,將大尺度評(píng)分化簡為不同階段的小尺度評(píng)分。如同王博等(2012)文中的介紹,我們的研究結(jié)果證實(shí)分步評(píng)分優(yōu)化了評(píng)分流程且提高了作文評(píng)分的質(zhì)量;而評(píng)分成績分布的合理性以及對(duì)評(píng)分者差異性的降低,或許來自對(duì)大尺度評(píng)分認(rèn)知負(fù)荷和保守打分策略的有效控制(Gilfert & Harada,1992)。
4.3 分步增值評(píng)分模式的實(shí)用性
在評(píng)分的實(shí)用性方面,研究抽取了分步評(píng)分1評(píng)和綜合評(píng)分12 評(píng)的情況進(jìn)行比較。結(jié)果發(fā)現(xiàn)分步評(píng)分1 評(píng)比綜合評(píng)分12 評(píng)的誤差程度還要低,而分步評(píng)分1 評(píng)和分步評(píng)分12 評(píng)的誤差程度卻不存在顯著差異。然而分步評(píng)分單評(píng)所用的時(shí)間卻要比綜合雙評(píng)所用的時(shí)間更短。因此,分步增值評(píng)分模式不僅是一種更為準(zhǔn)確的評(píng)分方式,還是一種更為經(jīng)濟(jì)有效的評(píng)分策略。
5 研究結(jié)論
雖然主觀題(特別是作文題)總是存在著評(píng)分不一致的問題,然而分步增值評(píng)分模式能夠有效的控制評(píng)分的質(zhì)量問題。這種新的評(píng)分模式相對(duì)于傳統(tǒng)綜合評(píng)分模式的優(yōu)越性表現(xiàn)在評(píng)分成績分布的合理性以及對(duì)評(píng)分者差異有效控制這兩個(gè)層面。其次,分步增值評(píng)分模式不僅能降低評(píng)分成績的誤差,還能有效提高評(píng)分程序的效率,或許可以視為一種更為實(shí)用的評(píng)分模式。
6 不足及建議
研究中抽取了500 份作文主觀題答卷,未來可以抽取樣本量更大的答卷來進(jìn)行分析,并且分別對(duì)不同類型主觀題評(píng)分成績的情況進(jìn)行分析。后期訪談中,筆者發(fā)現(xiàn)部分評(píng)分者對(duì)定級(jí)和定檔的標(biāo)準(zhǔn)有時(shí)把握不準(zhǔn),也就是在相鄰等級(jí)或相鄰檔位水平的試卷評(píng)定上有時(shí)把握不太穩(wěn)定。如何更好地規(guī)范評(píng)分者評(píng)分的準(zhǔn)確性也是未來流程設(shè)計(jì)需要改進(jìn)的方向。另外,研究中的評(píng)分時(shí)間以裝訂試卷本為單位,未來研究或許可以通過網(wǎng)絡(luò)評(píng)分手段,對(duì)每一份試卷的評(píng)分時(shí)間進(jìn)行單獨(dú)測量。最后,本次研究并沒有對(duì)評(píng)分過程中的認(rèn)知加工過程進(jìn)行深入分析。通過引入與認(rèn)知加工能力相關(guān)的行為測試,或許可以更好地考察認(rèn)知個(gè)體差異對(duì)試卷評(píng)分的影響情況。
陳睿.(2011).國內(nèi)外寫作評(píng)分量表的對(duì)比研究.考試研究,6,59 -67.
關(guān)丹丹,陳睿,張開,趙靜宇. (2011). 兩種評(píng)分量表的評(píng)分效應(yīng)比較研究.教育研究與實(shí)驗(yàn),4,92 -96.
關(guān)丹丹.(2008). 主觀題評(píng)分質(zhì)量的估計(jì)方法評(píng)述.中國考試,10,52 -55.
李中權(quán),孫曉敏,張厚粲,張立松.(2008).多面Rasch 模型在主觀題評(píng)分培訓(xùn)中的應(yīng)用.中國考試,1,26 -31.
劉紅云,陳閱,駱方,王云峰. (2010). 學(xué)業(yè)水平測試中作文評(píng)分誤差的多面Rasch 分析.心理科學(xué),33(4),925 -927.
劉遠(yuǎn)我,張厚粲. (1998). 概化理論在作文評(píng)分中的應(yīng)用研究.心理學(xué)報(bào),30,211 -218.
王博,卞冉,車宏生,王蓉. (2012). 主觀評(píng)分保守現(xiàn)象的形成機(jī)制與控制研究.心理學(xué)探新,32(5),429 -438.
Gilfert,S.,& Harada,K. (1992). Two composition swcoring methods:The analytic vs. holistic method. Bulletin of Faculty of Foreign Languages,1,17 -22.
Johnson,R. L.,Penny,J.,& Gordon,B. (2000). The relation between score resolution methods and interrater reliability:An empirical study of an analytic scoring rubric.Applied Measurement in Education,13,121 -138.
Morgan,G. B.,Zhu,M.,Johnson,R. L.,& Hodge,K. J.(2014). Interrater reliability estimators commonly used in scoring language assessments:A monte carlo investigation of estimator accuracy.Language Assessment Quarterly,11,304 -324.Penny,J. A.,& Johnson,R. L. (2011). The accuracy of performance task scores after resolution of rater disagreement:A Monte Carlo study.Assessing Writing,16,221 -236.
