基于評論關系圖的垃圾評論者檢測研究
2015-12-29 05:09:04林秀嬌魏晶晶廖祥文
福州大學學報(自然科學版) 2015年2期
關鍵詞:檢測
林秀嬌,魏晶晶,劉 月,廖祥文
(1.福州大學數學與計算機科學學院,福建福州 350116;2.福建省網絡計算與智能信息處理重點實驗室,福建福州 350116;3.福建江夏學院電子信息科學學院,福建福州 350116)
0 引言
隨著電子商務的高速發展,越來越多的用戶會在購買產品后發表自己對產品、商店服務等評論信息.這些信息對潛在用戶和商店是一個很重要的資源.但是有一些用戶為了提升或者詆毀某一產品或某一類產品的聲譽,發表不真實的、有欺騙性質的垃圾評論,這些評論可能會誤導潛在消費者;同時還可能干擾評論意見挖掘和情感分析系統的分析[1].因此,對產品垃圾評論的識別很有必要.
目前,國內外針對產品垃圾評論識別展開了很多的研究,并且取得了一定的成果.但是大部分工作集中在文本相似[1-3]、語言特征[4]、評論者行為[5-6]和評分模式[5-7]等方面,這些方法只能識別重復的垃圾評論或是寫重復評論的垃圾評論者,對于其他類型則無法檢測.為此,本研究提出構造評論者、評論和商店以及回復者的評論關系圖,利用四者的關系計算評論者可信度來檢測產品垃圾評論者.
1 相關工作
1.1 垃圾評論文本的檢測
2007年Jindal等[1-3]首次提出垃圾評論這個概念,把它分為三種類型:untruthful opinion,reviews on brands only,non-reviews,然后采用logistic回歸建立機器學習模型來識別三種類型的垃圾評論.Lai等[4]提出一種基于unigram模型的識別方法,利用句法分析和英文格式上的特征作為分類特征.Ott等[8]將垃圾評論的識別看成一個二元分類問題.除此之外,文獻[7,9-10]也利用垃圾評論文本內容檢測垃圾評論.
上述方法需要對文本內容有深度理解和觀點抽取.但垃圾評論者為能成功誤導消費者,會使自己的評論看起來與正常評論區別不大甚至沒有區別[11],因此利用評論文本來識別垃圾評論會比較困難.
1.2 垃圾評論者的檢測
這類檢測方法的基本思想是:垃圾評論者發表的評論多為垃圾評論.Lim等[5]和邱云飛等[6]利用用戶行為來檢測垃圾評論者.Liu等[12]通過研究“非期望規則”來識別垃圾評論者.但是這些方法只能檢測某種特定的垃圾評論者,如寫重復評論的產品垃圾評論者.Liu等[13-14]認為產品垃圾評論不只是個人的行為,而是一種團體活動,他們結合評論組特征與單個評論者特征建立三個交叉模型識別垃圾評論者.Xie等[15-16]利用時間序列檢測垃圾評論者.Li等[17]把垃圾評論者檢測和垃圾評論檢測兩者結合起來,但該方法仍然需要抽取評論文本內容.Wang等[18]利用評論者、評論和商店三者之間的關系檢測垃圾評論者,不僅避開了對文本內容深度理解和觀點的抽取,而且還能檢測出寫非重復垃圾評論的垃圾評論者.但是他們尚未加入回復者對評論的影響,對于有越多可信度高的回復者認為有用的評論,有理由相信該評論的真實度會更高.因此,本研究提出構造評論者、評論、商店以及回復者的評論關系圖,利用四者之間的關系計算評論者可信度檢測垃圾評論者.
2 基于回復者特征的垃圾評論者檢測模型
為了檢測垃圾評論者,用帶有箭頭的實線將評論者與其評論及所在商店相連.如果一條評論有其他評論者(回復者)對其回復,則用帶有箭頭的虛線將回復者與評論相連,形成評論關系圖,如圖1所示.

圖1 評論關系圖Fig.1 Review graph
2.1 問題定義
由圖1可以看出,評論者與其評論有關聯,因此判斷一個評論者是否為垃圾評論者,可以觀察該評論者的評論是否真實.假設一個評論者的可信度與其所有評論的真實度的總和Hr有關系.圖1中的評論者用R={r1,r2,…,rn}表示,T(r)={T(r1),T(r2),T(rn)}表示評論者r的可信度,K是評論者可信度的上界,nr是評論者r的評論總數量,αir是評論者r的第i個評論.則問題定義為:

為了方便計算,將T(r)的值歸一化到[-1,1],則評論者的可信度為:

其中:

明確評論者可信度T(r)的求解方法后,需要求得公式中的另一個參數H(v).
2.2 評論真實度度量
用戶在判斷一條評論是否真實可信,一般會從以下三個方面進行考慮:①了解商店是否可靠.對于可靠的商店,用戶會相信其評論是真實可信的,而對于聲譽差的商店,用戶一般會懷疑其評論的真實性.②觀察該評論的周圍評論,即同一家商店一定時間內Δt的其他評論.如果周圍評論都認為產品是好的,則用戶會相信該產品是好的;反之,用戶會懷疑該產品的質量.③觀察這條評論的回復者,如果越多可信度高的回復者認為評論有用,則認為評論的真實度越高.反之,用戶會覺得該評論不真實.基于以上三方面考慮,評論真實度模型有三個影響因素,即商店的可靠性、周圍評論的一致性分數以及回復者的回復分數.因此,將評論v的真實度定義為:
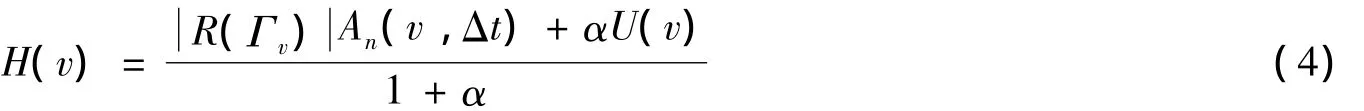
H(v)的值在[-1,1].其中:α是參數,取值為0.3、0.5、0.7、1.0、1.5、2.0;An(v,Δt)是周圍評論的一致性分數;R(Γv)是商店Γv的可靠性分數;Γv是評論v評論的商店id;U(v)是評論v的回復分數.
2.2.1 周圍評論的一致性分數估計
把評論v的所有周圍評論的集合記為Sv,即:

其中:tv是評論v的評論時間.對于Sv中任意兩條評論i、j,如果這兩條評論關于同一家商店的同一產品的觀點相似,則認為這兩條評論是一致的.由于觀點挖掘需要的代價大,假設兩條評論關于同一家商店有相似的評分,則認為這兩條評論對這家商店有相似的觀點.
因此,根據假設,如果

其中:ψv是評論v的評分;δ是一個給定的邊界(本文的評分有5個等級,δ取值為1),則表示一致評論.現把 Sv劃分為兩個集合,Sv,a和 Sv,d,定義如下:

同時,考慮評論者的可信度分數.評論者可信度越高,其評論越真實,即使它的周圍評論和它不一致,因為周圍評論可能都是不可信評論者寫的.類似地,一條評論和周圍的評論都一致也有可能是不真實的,因為周圍評論有可能都是垃圾評論者寫的.因此,定義評論v在一定時間內的周圍評論的一致性分數為:
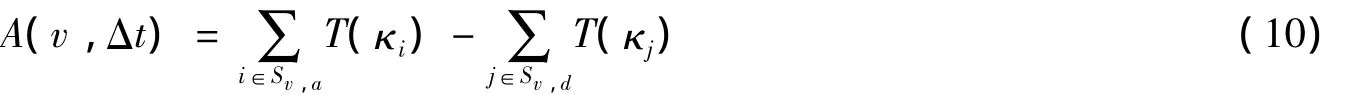
其中:κv是評論v的作者id,Δt取發表這條評論時間的前后3個月.對周圍的一致性分數歸一化到[-1,1]后得到:

2.2.2 商店的可靠性計算
如果一個商店有更多可信度高的評論者寫正面的評論,則認為這家商店更可靠.反之,則認為這家商店更不可靠.因此定義商店s的可靠性為:

其中:

R(s)的值在[-1,1];vs是商店s的評論集合;u是評分系統的中間值,故u取3.
2.2.3 回復分數估算
回復者對評論的回復可反應其他人對這條評論的認可程度,從而間接反應出評論的書寫者是否可信.如果一條評論有越多的可信度高的回復者對其回復,并且認為這條評論有用,則這條評論的真實度越高.反之,則認為這條評論不真實.
依據回復者的可信度將回復者分為可信回復者和不可信回復者.根據不可信評論者的大部分評論是不可信的,假設不可信回復者的回復是不可信的.在計算回復分數時只考慮可信回復者(回復者的可信度大于零)的回復對評論的影響.同時,在計算回復分數時不考慮評論者自己對自己評論的回復,因為這可能只是評論者對自己評論的補充.
因此,定義評論v的回復分數為:
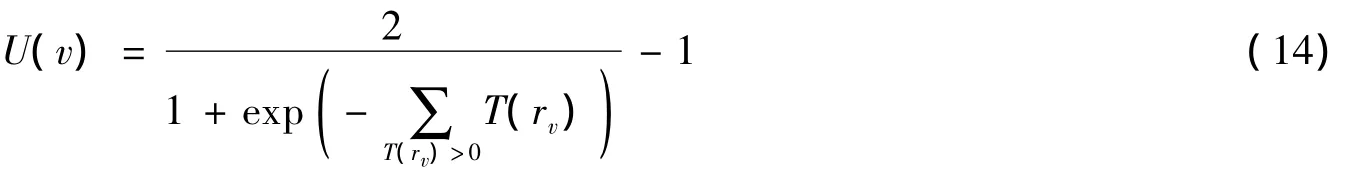
U(v)的值在[-1,1].其中,rv是評論者r認為評論v有用的回復者.
2.2.4 迭代算法
采用迭代算法求解評論者可信度分數,依據文獻[8],本文的迭代次數為5,具體算法步驟如下:
輸入:商店 s={s1,s2,…,st},評論v={v1,v2,…,vk},評論者r={r1,r2,…,rn},時間窗口Δt,評論相似閾值δ.
輸出:評論者可信度T(r),評論真實度H(v),商店可靠性R(s).
Step1:初始化商店可靠性R(s)=1,評論者可信度T(r)=1,評分中間值u=3;
Step2:根據初始值計算評論的周圍分數An(v,Δt)以及回復分數U(v);
Step8:重復迭代上述步驟,當第i次迭代和第i+1次迭代得到的評論者可信度的向量ξi和ξi+1滿足:1 -cos(ξi,ξi+1)< 5 ×10-4時,迭代結束.
3 實驗結果與分析
3.1 數據集構造
使用文獻[6]提供的亞馬遜網站的評論作為實驗數據集.根據得到的數據集,假設同一個品牌的商品為同一家商店出售.
數據集分為評論數據集和回復數據集.對數據集先進行預處理:①刪除在評論數據集中沒有評論的回復者.②刪除重復的回復評論.③刪除評論者對自己的回復.經過預處理后得到的數據集如表1所示.

表1 預處理后的數據集Tab.1 The dataset after preprocessing
3.2 實驗結果分析
為了檢驗模型的合理性和有效性,首先用本文算法識別出前100個高度可疑的垃圾評論者作為候選垃圾評論者,然后對這100個候選垃圾評論者進行人工(3個標記人)標注,識別過程中標記人是獨立的.根據大多數投票原則,一個評論者如果同時被2個或2個以上的標記人標記,則認為該評論者是垃圾評論者.根據最終人工標記的結果,采用準確率(precision)來評估方法的好壞.
式(4)中的α 取值為0.3、0.5、0.7、1.0、1.5、2.0.由于篇幅限制,這里只列出實驗效果最好的(α =0.5)人工標記結果,如表2所示.

表2 人工標記結果Tab.2 Human evaluation result (個)
表2顯示了人工標記的一致性.例如,由算法檢測的前100個可疑垃圾評論者中,標記人1認為其中48個可疑垃圾評論者為真實的垃圾評論者,標記人2與標記人1有36個可疑垃圾評論者一致認為是真實的垃圾評論者,而標記人3與標記人1有35個可疑垃圾評論者一致認為是真實的垃圾評論者.
為了驗證本文方法的合理性和有效性,設計了回復分數前后的對比實驗.實驗結果顯示,當回復分數中的 α 取值為0.3、0.5、0.7、1.0、1.5、2.0時,準確率分別為44%、45%、43%、44%、42%、41%,與基準的準確率41%相比都有提高或持平.可以看出,當α>1之后,準確率的提升空間逐漸減小,這說明回復分數對評論真實度有影響,但是其影響力度與商店的可靠性和周圍評論的一致性對評論真實度的影響力度相比較小,所需要的權值也應該更小.
通過實驗證明,回復分數對評論的真實度有影響,能夠提高垃圾評論者識別的準確率.例如,正常的評論者“kanghui35”在基準實驗下,他的可信度分數為-0.550 420,被認為是可疑的垃圾評論者.而加入回復數后“kanghui35”的可信度分數為0.145 761,可信度分數提高了,被正確識別.
雖然加入回復分數之后的準確率提高了,但是提高的幅度不大,即使在α=0.5實驗效果最好的情況下與基準的準確率相比只提高了4個百分點,總的準確率還有較大的提升空間.影響準確率的原因可能是:首先,由于回復的數據集較少,一些真實可靠的評論并未得到可信度高的回復者回復;其次,回復分數中參數α對實驗結果有一定的影響,需要繼續對α進行優化,降低其對結果產生的誤差,提高識別精度;另外,還可能是因為一些垃圾評論者的特征指標尚未被考慮,無法識別更多的垃圾評論者.以上三種可能有待于之后的進一步細致研究.
致謝:感謝邱云飛,王建坤等為本文提供的亞馬遜網站的評論數據集.
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
