一種基于項目屬性評分的協同過濾推薦算法*
2016-01-26 06:48:51龔安,高云,高洪福
計算機工程與科學 2015年12期
?
一種基于項目屬性評分的協同過濾推薦算法*
通信地址:266580 山東省青島市中國石油大學(華東)計算機與通信工程學院Address:School of Computer & Communication Engineering,China University of Petroleum,Qingdao 266580,Shandong,P.R.China
龔安,高云,高洪福
(中國石油大學(華東)計算機與通信工程學院,山東 青島 266580)
摘要:協同過濾是電子商務推薦系統中應用最成功的推薦技術之一,但面臨著嚴峻的用戶評分數據稀疏性和推薦精度低等問題。針對數據稀疏性高和單一評分導致的推薦精度低等問題,提出一種基于項目屬性評分的協同過濾推薦算法。首先通過均值法或縮放法構造用戶-項目屬性評分矩陣將單一評分轉化為多評分;其次基于每個屬性評分矩陣,計算用戶間的偏好相似度,得到目標用戶的偏好最近鄰居集;然后針對每個最近鄰居集,在用戶-項目評分矩陣上完成對目標用戶的初步評分預測;最后,將多個初步預測評分加權求和作為綜合評分,完成推薦。在Movie Lens擴展數據集上的實驗結果表明,該算法能有效提高推薦精度。
關鍵詞:屬性評分;均值法;縮放法;協同過濾;推薦
1引言
隨著Internet和電子商務的迅猛發展,“信息爆炸”和“信息過載”問題越來越嚴重,用戶很難從海量的信息中找到自己真正需要的信息。推薦系統可以在用戶目的不明確的情況下幫助用戶找到可能感興趣的信息并推薦給用戶。協同過濾是現行推薦系統中應用最廣泛最成功的技術之一,但其需要維護一個存儲用戶偏好的數據庫。因此,隨著系統中用戶和項目數量的不斷增加,協同過濾面臨嚴峻的用戶評分數據稀疏性、推薦實時性、可擴展性挑戰,推薦質量迅速下降。
對此,很多國內外學者提出了一些改進算法。Luo H等人[1]提出了局部用戶相似性和全局用戶相似性的概念及LU&GU架構,可發現高質量的鄰居用戶,提高推薦精度。黃創光等人[2]提出了一種不確定近鄰的協同過濾算法,通過不確定近鄰因子及調和參數計算基于用戶和項目的預測評分從而產生推薦。Lemire D教授[3]提出了Slope One算法,該算法具有易實現、查詢效率高等優點。Mi Z等人[4]將聚類和Slope One相結合應用在推薦算法中。Melville P等人[5]使用基于內容的方法填補用戶評分向量中的空值,緩解評分數據的稀疏性,從而提高協同過濾的推薦質量。楊興耀等人[6]通過協調優化的用戶評分相似性和基于項目屬性的用戶相似性改進相似性度量的精度。Huang M等人[7]結合屬性論提出了基于項目屬性的協同過濾推薦算法,緩解了數據稀疏問題,提高了推薦質量。上述研究雖然提高了推薦質量,但都沒有考慮用戶的屬性偏好。徐紅艷等人[8]提出了一種基于多屬性評分的協同過濾算法,該算法在一定程度上解決了數據稀疏問題,提高推薦準確度。范波等人[9]提出了一種基于用戶間多相似度的協同過濾推薦算法,即通過計算用戶間對不同項目類型多個獨立的評分相似度來分別描述用戶間對不同類型項目喜好的相似程度。上述研究均利用了項目的屬性信息,但文獻[8]中主要是針對多評分數據集的,對單一評分數據集并不適用;文獻[9]雖然計算了用戶之間的多個相似度,但其仍是利用用戶的直接評分,并未考慮用戶對項目某一屬性的偏好。
本文針對單一評分數據集上推薦精度低的問題,采用均值法和縮放法將單一評分轉換為多評分,計算用戶對項目的各個屬性的偏好評分得到多個用戶-項目屬性評分矩陣;然后,在各屬性矩陣上計算用戶相似度得到用戶的多個相似鄰居集;接下來,針對每組最近鄰,分別在用戶-項目評分矩陣進行評分預測;最后,將同一用戶對同一項目的多個預測評分加權求和后作為綜合評分,依據綜合評分的大小進行項目推薦。
2問題定義及基本方法
定義推薦系統中的數據源D={U,I,R};其中U={u1,u2,…,um}表示基本用戶,I={i1,i2,…,in}表示基本項目,R代表一個m×n階的矩陣,用戶u對項目j的評分,記作 Ru,j。由于系統中大部分用戶對大部分項目沒有評分,所以矩陣中存在大量的空值。
傳統的基于用戶的協同過濾推薦算法首先計算用戶之間的相似度。相似度計算方法主要有以下三種:
(1)余弦相似性:用戶被看作n維項目空間的向量。設向量u、v分別代表用戶u和用戶v的評分,則用戶u和用戶v之間的相似度sim(u,v)定義如下:
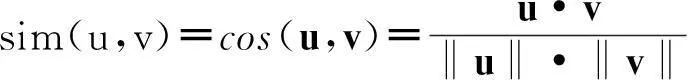
(1)
(2)修正的余弦相似性:余弦相似性未考慮不同用戶之間的評分尺度偏差的問題,修正的余弦相似性通過減去用戶的平均評分來改善這一缺陷,其定義如下:
sim(u,v)=

(2)

(3)相關相似性:選取用戶u和用戶v的共同打分的項目集,記作Iu,v,則sim(u,v)如下:
sim(u,v)=
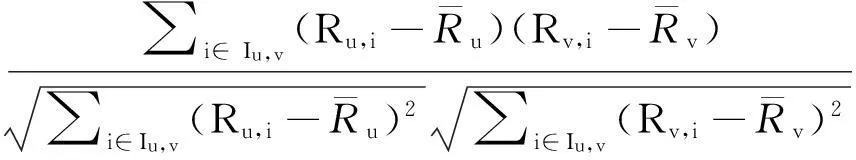
(3)
然后,推薦系統選取與目標用戶u相似度較高的用戶作為其最近鄰居集,記作N(u),并預測用戶u對其未評分項目i的評分Pu,i:

(4)
最后,推薦系統將預測評分最高的前K個項目推薦給用戶,完成推薦過程。
3基于項目屬性評分的協同過濾推薦算法
本文認為用戶使用(購買或者觀看)了項目,可能是因為對項目的某種屬性有所偏好,例如有些用戶喜歡喜劇片,有些用戶喜歡動作片,還有的用戶購買了大量的電子產品等,因此本文擬通過尋找在屬性上有類似偏好的用戶作為相似用戶,然后基于他們的歷史評分產生推薦。
3.1 算法思路
定義項目的屬性集為A={A1,A2,…,Ak,…,Al},Ak={a1,a2,…,as,…,at},其中,Ak為屬性,as為屬性的取值。需要注意的是,對于某一項目ij的屬性Ak,其可能有多個取值。例如,一部電影既是動作片又是科幻片,一件商品既是女裝又是戶外等。
圖1給出了算法的流程。首先,構建用戶-項目評分矩陣、用戶-項目屬性評分矩陣并選取屬性;然后,在每個屬性評分矩陣上計算用戶之間的相關相似性,并選取相似度最高的K個用戶作為相似鄰居;接著,根據K個鄰居的歷史評分預測目標用戶對目標項目的評分;當所有屬性評分矩陣的預測完成時,會得到目標用戶對于每個目標項目的一組預測評分,將這些評分加權求和作為綜合評分;最后,選取綜合評分最高的前T個項目推薦給用戶。
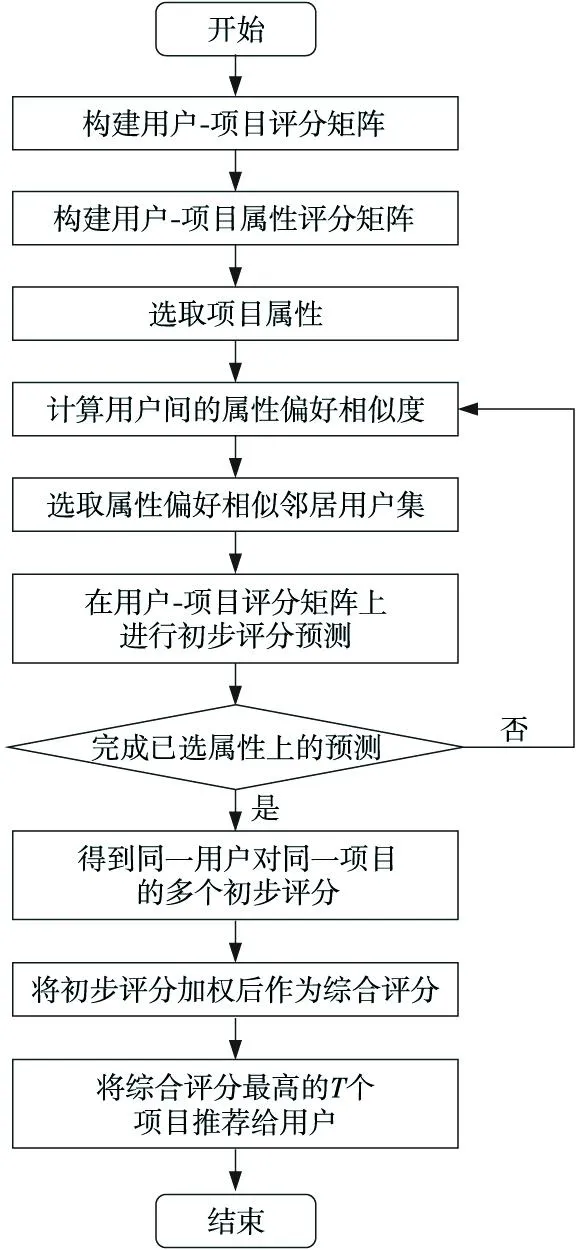
Figure 1 Algorithm flowchat圖1 算法流程
3.2 算法描述
本文分三方面探討基于項目屬性評分的協同過濾推薦算法,即用戶-項目屬性評分矩陣的構造、項目屬性的確定和推薦的生成。
3.2.1 用戶-項目屬性評分矩陣的構造
設用戶對項目的第k個屬性Ak的評分矩陣為G,表示如下:
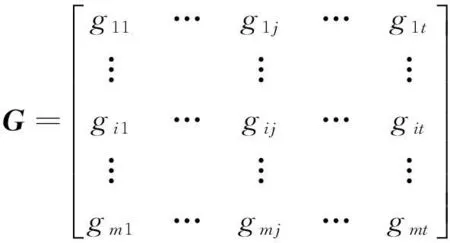
(5)
其中,m為用戶數量,t是屬性Ak值的數量。
要構造用戶-項目屬性評分矩陣,首先要確定用戶對各屬性值的評分,即gij,文獻[8]采用的是用戶對屬性的直接評分,但是日常生活中數據集大多都是單一評分的。因此,本文采用以下兩種方法來構造屬性評分:
(1)均值法:即以用戶對具有某一屬性值的項目的評分的均值作為其評分,定義如下:
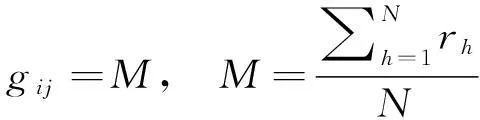
(6)
其中,N代表用戶i評價過的Ak=aj的項目的數量,rh代表用戶對Ak=aj的項目的評分。由定義可知,每個用戶對每個屬性值的評分至多只有一個,例如,用戶A對喜劇電影的評分為4;如果A沒有看過喜劇電影,則其沒有該項評分。
(2)縮放法:如果用戶對具有某一屬性值的項目的評分的差距都比較小但評分又不完全相同,則可認為用戶比較偏愛此類項目,需要對其評分進行放大,反之,其評分需進行適當的縮減;如果用戶對具有某一屬性值的項目只有一次評分,則可認為用戶不喜歡此類項目,令其評分為零;如果用戶對具有某一屬性值的項目的評分完全相同,則忽略其評分。本文采用方差對評分進行縮放,并將閾值定為1,即如果方差大于1,就將評分縮減,反之,將評分放大。因此,縮放法定義為用戶對具有某一屬性值的項目的評分的均值和方差的比值,公式如下:

(7)
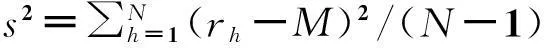
下面通過一個例子進行闡述,假設用戶A、B、C、D觀看過的喜劇電影為1、2、3、4,其歷史評分、均值評分和縮放評分如表1所示。可以發現,當用戶評分比較穩定時,例如用戶A的評分,其縮放評分被放大;而當評分波動比較大時,例如用戶B的評分,其評分被縮小。另外,注意到縮放法中的評分范圍不是從1到5,而是根據用戶的歷史評分動態調整。
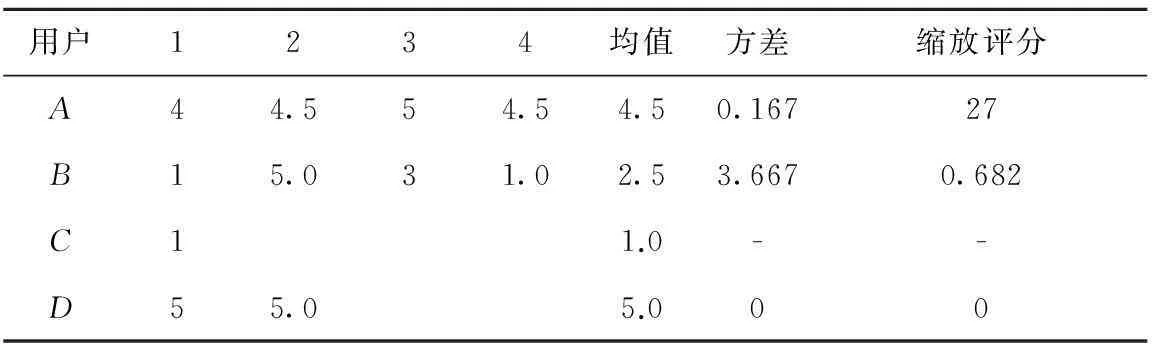
Table 1 Examples of user-rating
3.2.2 項目屬性的確定
推薦系統中,項目的屬性繁多,若在所有屬性上進行推薦,勢必增加系統負荷,降低系統效率。因此,本文選取部分屬性,選取依據為數據稀疏度和數據減少率:
(1)數據稀疏度:用戶評分數據矩陣中未評分條目所占的百分比,其公式如下:
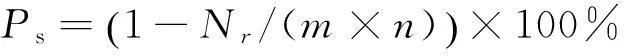
(8)
其中Nr為評分數量,m為矩陣行數(用戶的數量),n為矩陣列數(項目或者項目屬性值的數量)。
(2)數據減少率:用戶-項目屬性評分相比用戶-項目評分所減少的數據量的比率,定義如下:
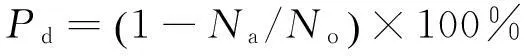
(9)
其中,Na為用戶-項目屬性評分的數據量,No為用戶-項目評分的數據量。
在屬性選取時,應選擇數據稀疏度低的屬性以保證相似度計算的準確性,提高推薦精度;選擇數據減少率高的屬性以降低系統數據量,提高系統效率。
3.2.3 推薦的生成
由于在多個屬性評分矩陣上進行了鄰居搜索并針對每個鄰居集分別進行了評分預測,因此得到了用戶對同一項目的多個預測評分(初步評分)。此時,系統不應將每個屬性的推薦直接推送給用戶,而應該根據用戶對不同屬性的偏好程度,對各屬性上的預測評分加權后再產生推薦。但是,在推薦系統中,每個用戶的偏好不同且不易度量,所以,本文對各屬性評分取相同權重求和后作為綜合評分,并將綜合評分由大到小排序后選取TopT項目推薦給用戶。
4實驗結果及分析
4.1 實驗數據集
本文采用MovieLens10M的擴展數據集,包括2 113個用戶對10 197部電影的855 598條評分。其評分數據從1到5,評分越高,表示用戶對電影越喜歡。為了分析稀疏度和系統規模對算法性能的影響,本文從數據集中隨機抽取三個訓練數據集(250位用戶對431部電影的10 000條評分,250位用戶對247部電影的10 000條評分及1 000位用戶對1 101部電影的50 000條評分),對應每個訓練集抽取部分數據作為測試集。訓練集的用戶-項目評分矩陣和采用均值法構造的用戶-項目屬性評分矩陣描述如表2所示。由于縮放法中對部分評分填充了空值,所以其構造的評分矩陣的數據稀疏度和數據減少率都在一定程度上有所提高。需要注意的是,對于一部電影,其導演、國家、時間只有一個,但是演員、類型、拍攝地、用戶所打標簽并不唯一。對于前者,將屬性的每個值都作為評分矩陣的一列;針對后者,本文分兩種情況進行處理:
(1)屬性有排序行為,則取前兩個值;
(2)屬性無排序行為,則考慮所有值。
本實驗數據集中,演員、標簽屬于(1),類型和拍攝地屬于(2)。
4.2 評價指標
本文采用平均絕對偏差MAE(Mean Absolute Error)來評價算法的推薦精度。MAE的計算公式如下所示:
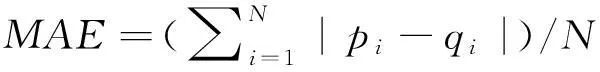
(10)
其中,pi為目標用戶對項目(或項目屬性值)的預測評分,qi目標用戶對項目(或項目屬性值)的實際評分,N為預測評分的數量。
4.3 實驗方案
首先進行屬性選取,本文選擇的屬性為:國家、類型、拍攝地1和時間;然后,將兩種構造方法在各屬性上產生的推薦分別和直接評分的預測結果進行比較;第三,將由兩種方法確定綜合評分與直接評分的預測結果進行比較;最后,對比本文方法與直接評分的效率。

Table 2 Descriptions of datasets
4.4 實驗結果及分析
4.4.1 不同構造方法與直接評分推薦精度的對比
圖2為均值法和縮放法在數據集1上產生的各屬性的推薦結果對比,其他數據集的結果與此相似。由圖2可見,均值法在單個屬性上的推薦精度基本都低于直接評分;縮放法的推薦精度在屬性國家、類型上有所改善但并不穩定。

Figure 2 Recommendation comparison of each attribute on dataset 1圖2 數據集1上各屬性的推薦結果對比
4.4.2 組合評分與直接評分推薦精度的對比
在該部分,將兩種構造方法得到的初步預測評分進行組合,即加權求和后與直接評分進行對比,在數據集1、數據集2、數據集3上的實驗結果如圖3所示。將圖3和表2結合對比可見,當系統數據量相同、數據稀疏性比較低的時候,縮放法的推薦精度明顯高于均值法和直接評分;當數據稀疏性相似、系統數據量不同時,縮放法和均值法的推薦精度均高于直接評分,但前者略優于后者。綜上,本文認為,當數據稀疏度較高時,應采用縮放法以取得較高的推薦精度,反之,則可任選其一。

Figure 3 Precision comparison on each data set圖3 各數據集上的推薦精度對比
4.4.3 組合評分與直接評分效率的對比
該部分以均值法在數據集1上30個鄰居用戶的推薦為例,對比組合評分與直接評分的時間復雜性問題,各屬性上的推薦與直接評分所需時間如圖4所示。可以發現,單個屬性推薦所需時間均明顯低于直接評分,分析原因如下:在相似度計算階段,由于每個屬性矩陣的列的數目和數據量相對較少,所以每個屬性矩陣在該階段花費的時間比直接評分少;在計算預測評分階段,兩種方法均是基于原始用戶-項目評分矩陣的,所以當鄰居用戶數目相同時,本文方法與直接評分的方法在該階段花費時間相同。綜上,本文方法在單個屬性矩陣上的推薦所需時間少于直接評分。如前所述,本文需要計算多個評分的組合值,如果依次計算每個初步評分,本文算法的效率勢必低于直接評分。但實際上,各屬性上的推薦是相互獨立的,可以并行計算,這樣本文算法所需時間即為各個屬性推薦中所需的最長時間,在圖4中即為時間屬性推薦所需的時間(30 s)。當然,直接評分也可以并行推薦,此處不再比較。
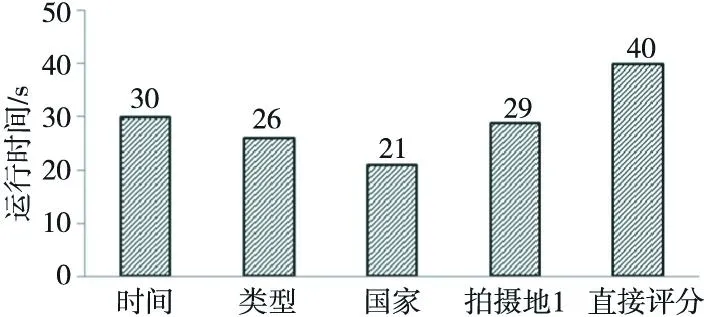
Figure 4 Efficiency comparison between the mean value method and the directed ratings圖4 均值法在各屬性上的推薦與直接評分效率的對比
5結束語
本文提出了一種基于項目屬性評分的協同過濾推薦算法,并詳細闡述了項目屬性的選取原則和用戶-項目屬性評分矩陣的兩種構造方法:均值法和縮放法。該算法首先計算用戶在不同屬性上的相關相似度,從而得到多個相似鄰居集;然后,針對各個鄰居集,在用戶-項目評分矩陣上產生目標用戶對同一項目的多個初步預測評分;最后將評分進行組合作為綜合評分,進而對目標用戶給出推薦結果。實驗結果表明該算法能有效提高推薦精度。
參考文獻:附中文
[1]Luo H,Niu C Y,Shen R M,et al.A collaborative filtering framework based on both local user similarity and global user similarity[J].Machine Learning,2008,72(3):231-245.
[2]Huang Chuang-guang,Yin Jian,Wang Jing,et al.Uncertain neighbors’ collaborative filtering recommendation algorithm[J].Chinese Journal of Computers,2010,33(8):1369-1377.(in Chinese)
[3]Lemire D,Maclachlan A.Slope one predictors for online rating-based collaborative filtering[C]∥Proc of SDM,2005:1-5.
[4]Mi Z,Xu C.A recommendation algorithm combining clustering method and slope one scheme[C]∥Proc of ICIC’11,2011:160-167.
[5]Melville P,Mooney R J,Nagarajan R.Content-boosted collaborative filtering for improved recommendations[C]∥Proc of the 18th International Conference on Artificial Intelligence,2002:187-192.
[6]Yang Xing-yao,Yu Jiong,Ibrahim Turgun,et al.Collaborative filtering recommendation models considering item attributes[J].Journal of Computer Applications,2013,33(11):3062-3066.(in Chinese)
[7]Huang M,Sun L,Du W.Collaborative filtering recommendation algorithm based on item attributes[C]∥Proc of the 15th IEEE/ACIS International Conference on Software Engineering,Artificial Intelligence,Networking and Parallel/Distributed Computing(SNPD),2014:1-6.
[8]Xu Hong-yan,Du Wen-gang,Feng Yong,et al.A collaborative filtering algorithm based on multi-attribute rating[J].Journal of Liaoning University(Natural Sciences Edition),2015,42(2):136-142.(in Chinese)
[9]Fan B,Cheng J J.Collaborative filtering algorithm based on users’ multi-similarity[J].Computer Science,2012,39(1):23-26.(in Chinese)
[2]黃創光,印鑒,汪靜,等.不確定近鄰的協同過濾推薦算法[J].計算機學報,2010,33(8):1369-1377.
[6]楊興耀,于炯,吐爾根·依布拉音,等.考慮項目屬性的協同過濾推薦模型[J].計算機應用,2013,33(11):3062-3066.
[8]徐紅艷,杜文剛,馮勇,等.一種基于多屬性評分的協同過濾算法[J].遼寧大學學報(自然科學版),2015,42(2):136-142.
[9]范波,程久軍.用戶間多相似度協同過濾推薦算法[J].計算機科學,2012,39(1):23-26.

龔安(1971-),男,四川巴中人,博士生,副教授,研究方向為數據庫及信息系統。E-mail:gongan0328@sina.com
GONG An,born in 1971,PhD candidate,associate professor,his research interests include database, and information system.
A collaborative filtering recommendation algorithm based on ratings of item attributes
GONG An,GAO Yun,GAO Hong-fu
(School of Computer & Communication Engineering,China University of Petroleum,Qingdao 266580,China)
Abstract:Collaborative filtering is one of the most successful techniques in E-commerce recommender system. However, it faces severe problems of sparse user ratings and low recommendation accuracy. To solve the problems of lower recommendation quality caused by rating data sparseness and single rating, we propose a collaborative filtering recommendation algorithm based on ratings of item attributes. Firstly, we construct user-item attribute rating matrices using the mean value method or scaling method to transform single rating to multi-rating. Based on each rating matrix of attributes, we then calculate the similarity among users to obtain the preference set of the nearest-neighbors, and accomplish a primary prediction for each set of the nearest-neighbors based on user-item rating matrices. Finally, we calculate the weighted sum of multiple primary predictions as the final scores, and then complete the recommendation. The experimental results on the extended datasets of Movie Lens show that the proposed algorithm can get higher recommendation accuracy than traditional algorithms.
Key words:attribute rating;mean value method;scaling method;collaborative filtering;recommendation
作者簡介:
doi:10.3969/j.issn.1007-130X.2015.12.026
中圖分類號:TP311
文獻標志碼:A
基金項目:中央高校基本科研業務費專項資金資助(14CX06150A)
收稿日期:修回日期:2015-10-21
文章編號:1007-130X(2015)12-2366-06
