
Hadoop技術在移動支付行業的應用
2016-03-10 03:48:14梁明煌吳航
中國新通信 2016年1期
梁明煌 吳航

【摘要】 科學技術及互聯網的發展,推動著大數據時代的來臨。文章介紹了中國移動集團公司在移動互聯網支付系統建設中成功運用Hadoop技術的典型案例。案例采用了Hadoop云計算技術,實現了分布式數據和計算框架,對海量數據進行分布式并發計算,提升了系統并行處理能力,減少了處理等待時間,滿足了移動支付多樣化及第三方支付平臺接入的需要,系統健壯性也得到了極大的提高。
【關鍵詞】 中國移動 Hadoop HDFS MapReduce 移動支付 調度引擎 任務引擎Application of Hadoop technology in mobile payment industry
Liang Minghuang Wu Hang
[Abstract] With the development of science and technology and the Internet, the advent of the era of big data. This article introduces the typical cases of the successful application of Hadoop technology in the construction of the payment system of China Mobile group. In this case the Hadoop cloud computing technology, realize the distributed data and computing framework, distributed & concurrent computing on massive data. Through the mechanism of Hadoop, we are able to enhance the ability of parallel processing, to meet the demand of mobile payment, to diversify the payment platform access need, system robustness has also been greatly improved.
[Key words] China Mobile Hadoop HDFS MapReduce Mobile payment Scheduling engine Task engine
引言
科學技術及互聯網的發展,推動著大數據時代的來臨。“互聯網+”的創新模式使得傳統行業與互聯網融合發展,形成了更廣泛的以互聯網為基礎設施和實現工具的新經濟發展模式,也使得大數據的處理越來越引人注目。
Hadoop技術,在大數據分析以及非結構化數據蔓延的背景下,一出現就受到眾多大公司的青睞。迄今為止,Hadoop在互聯網領域已經得到了廣泛運用,例如,Yahoo 使用4 000個節點的Hadoop集群來支持廣告系統和Web 搜索的研究;Facebook 使用1 000 個節點的集群運行Hadoop,存儲日志數據,支持其上的數據分析和機器學習;百度用Hadoop處理每周200TB 的數據,從而進行搜索日志分析和網頁數據挖掘工作,等等。
本文介紹的是中國移動某子公司在移動互聯網支付系統建設中(簡稱移動支付系統),成功運用Hadoop技術的典型案例。
一、Hadoop是什么
Hadoop是一個由Apache基金會所支持的用Java實現的開源分布式數據和計算框架,在由大量計算機組成的集群中實現了對海量數據進行分布式計算。允許用戶在不了解底層細節的情況下,使用分布式程序。充分利用集群的威力進行高速運算和存儲。
Hadoop框架的核心,是HDFS和MapReduce。HDFS為海量數據提供存儲,MapReduce為海量數據提供計算。
1.1 HDFS簡介
整個Hadoop的體系結構主要是通過HDFS來實現對分布式存儲支持,。
HDFS采用主從(Master/Slave)結構模型,由一個NameNode和若干DataNode組成的。存儲在 HDFS 中的文件被分成塊,然后將這些塊分散到多個DataNode中。NameNode負責管理文件系統命名空間和客戶端對文件的訪問操作。DataNode管理存儲的數據。
1.2 MapReduce簡介
MapReduce框架由一個JobTracker(調度引擎)和多個TaskTracker(任務引擎)共同組成。JobTracker負責調度構成一個作業的所有任務,這些任務被分發到空閑的TaskTracker上執行。當一個作業被提交時,JobTracker接收作業內容和配置信息,然后生成Map和Reduce任務指派給空閑的TaskTracker執行,同時監視它們的執行情況,并重新分派失敗的任務。即如果TaskTracker出了故障,JobTracker會把任務轉交給另一個空閑的TaskTracker重新運行。
1.3 HDFS與MapReduce的結合
HDFS和MapReduce共同組成Hadoop分布式系統體系結構的核心。HDFS實現了分布式文件系統,MapReduce實現了分布式計算處理。HDFS在MapReduce任務處理過程中提供了存儲支持,MapReduce在HDFS的基礎上實現了任務的分發、、執行跟蹤等工作,二者相互作用,完成分布式集群的不同作業。
二、移動支付業務
移動支付也稱為手機支付,就是允許用戶使用其移動終端(通常是手機)對所消費的商品或服務進行賬務支付的一種服務方式。單位或個人通過移動設備、互聯網或者近距離傳感直接或間接向銀行金融機構發送支付指令產生貨幣支付與資金轉移行為,從而實現移動支付功能。移動支付將終端設備、互聯網、應用提供商以及金融機構相融合,為用戶提供貨幣支付、繳費等金融業務。
2.1 中國移動支付業務
本文介紹的移動支付系統是中國移動集團公司為了解決銀行繳費分省接入模式下網絡成本高、傭金成本高、運營成本高、用戶體驗不一致等問題,構建的集中運營、全網覆蓋的統一支付體系。
移動支付系統通過移動總部系統和銀行系統采用一點接入,完成總部(包括31個省公司)與全國性商業銀行開展移動總部對銀行總部的繳費服務合作,實現了客戶繳納手機話費和營銷活動費用的服務。后期,系統持續推進集中充值和支付能力建設,實現了分散向集中轉型、費率和能力雙統一。增加支持電子渠道繳費業務,支持電子充值營銷推廣。最大的亮點是對外提供了繳費能力平臺,實現了與天貓、移動商城的繳費合作,提供第三方支付能力的接入。系統建設示意圖如圖1所示。Hadoop技術,正是在此移動支付中實施應用的。
三、Hadoop技術在移動支付中的應用
移動支付系統提供了實時在線繳費和離線對賬結算兩部分。實時在線繳費負責完成實時繳費交易的處理,主要以HTTP即時請求的方式出現。離線對賬結算主要負責完成多方之間各類交易數據的每日對賬、定時結算、資金清分等,主要以文件批處理的形式出現。前文所提及的Hadoop應用主要體現在離線對賬結算功能中。
3.1 離線對賬結算架構方案
1)集群包括HDFS、MapReduce、YARN、Zookeeper和Hive。
2)集群通過JAVA接口訪問,包括對HDFS和Hive的基本操作。
3)各方對賬的底層就是文件的比對,兩方文件比對作為一個業務插件通過公共接口訪問操作集群。
4)對賬結算流程支持:
a.在HIVE中建立三張按省、日期進行分區的表,分別用于存放源比對數據、目標比對數據和雙方的差異數據
b.每次對賬開始先將源和目標的比對文件上傳到HDFS上
c.對賬業務插件將HDFS文件以Hive表的形式加載
d.通過程序調用執行比對的業務邏輯sql,將差異數據形成差異表
e.差異生成組件再讀差異表對應的HDFS文件;
f.將數據導出到現有的數據庫中以備后續的處理訪問。
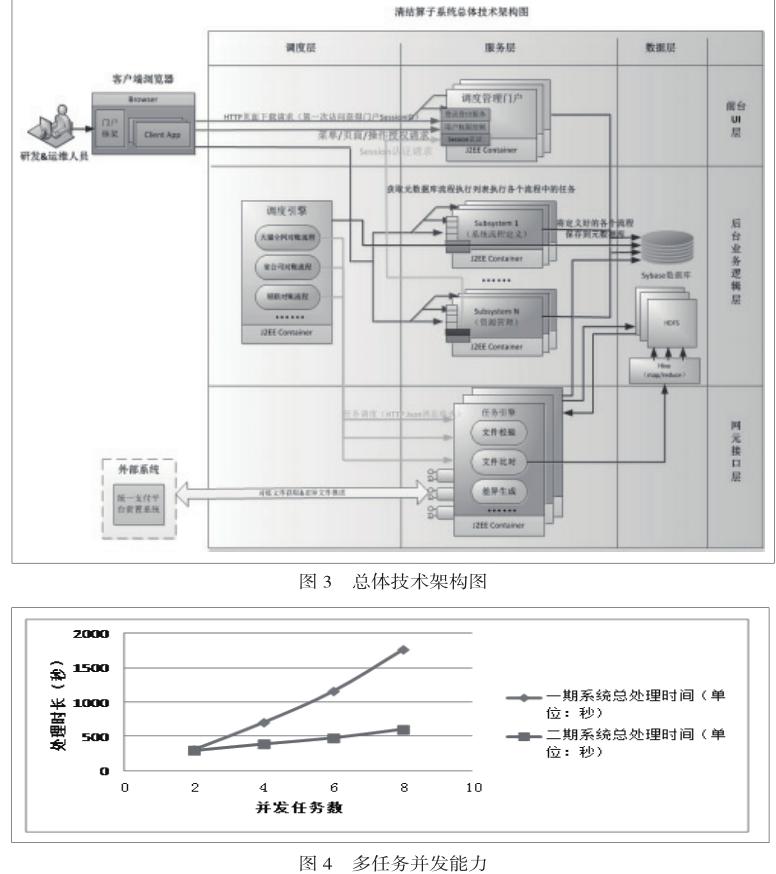
3.2 總體技術圖(圖3)
總體技術圖分為三部分:
1)調度管理子系統:自主研發的管理系統WEBX,提供任務流程的定義,實現調度管理系統功能。
2)調度引擎子系統:實現獲取調度管理定義的元數據,并行運行各個任務流程,根據每個任務流程中的任務節點信息,分發給任務引擎執行調度的分發工作。
3)任務引擎子系統:實現對各種原子任務形成組件形成統一管理,對外開放統一接口來獲取調度引擎信息,通過key-value方式動態調用實際任務組件,實現任務的執行。
從數據的流向看,劃分為調度層、服務層和數據層:
1)調度層:讀取元數據信息,啟動流程任務調度,分發給任務引擎處理。主要使用調度引擎實現各個流程的調度,核心的消息狀態觸發以及監聽機制采用YARN實現。
2)服務層:調度管理系統來搜集定義以及管理各個任務流程元數據信息,使用任務引擎提供實際任務的執行服務。主要采用任務引擎以及調度管理系統實現,對任務的各個組件采用原子化的方式管理,滿足原子任務拼裝定義成復雜流程。其核心組件主要有:業務到達、文件備份、文件校驗、文件入庫、文件比對、差異生成等組件。
3)數據層:主要由Sybase以及HDFS組成,負責業務數據和文件的存儲
在功能層次上,劃分為前臺UI層、后臺邏輯層和網元接口層:
1)前臺UI層:前臺UI層負責向用戶展示UI界面,所有的用戶請求都通過apache前置機分發給后臺邏輯層。
2)后臺邏輯層:后臺邏輯層物理上由N個子系統組成, apache前置機負責將用戶的功能請求分發到不同的子系統上。
3)網元接口層:網元接口層負責獲取以及推送對外網元的相關接口數據。
四、性能表現
使用了Hadoop技術以后,相對于未使用hadoop的一期系統,性能有了多方面不同程度的提升。為了方便比對,我們在兩個系統上各自運行測試任務,將兩個100萬記錄的文件進行逐行比對,并分別生成相同數據記錄與有差異的數據記錄。以下是一系列性能測試的結果,我們將其總結為圖表。
4.1 任務并發性能顯著增強
通過測試,我們發現由于一期系統采用數據庫進行任務處理,其處理效率取決于oracle數據庫的處理性能。因此,當數據庫滿負荷的情況下,其任務處理時間基本近似于任務的串行處理時間。且數據庫是一個不易于擴展的節點資源,因此暫時認為其不適合處理并發多任務。
而二期系統由于采用多節點的Hadoop組織方式,因此任務分被分配到各個空閑節點上執行,同時,在Hadoop組織方式下,處理節點是一個易于擴展的資源,因此,二期系統的并發處理能力要強 于一期系統。
4.2 具備線性擴展能力
從上表中可以看出,兩個系統相比,在少量任務的處理能力上,并沒有明顯的差距。但使用了Hadoop平臺的統一支付二期系統在多任務并發的場景下,其任務處理時間是一條增長更為平緩的曲線。因此,可以認為使用了Hadoop平臺,也充分繼承了其線性擴展能力的特點。
4.3 具備大文件處理 能力
這也是使用Hadoop平臺帶來的一個優勢。
在一期系統中,正常情況下系統無法處理超大文件,需要 對文件進行分片,即分割為100MB大小的多個記錄文件。當內容記錄較多時,會產生一大堆從001到999編號的文件,記錄 出錯概率大,運維管理難度高。Hadoop平臺天生對大文件有良好的支持,最新版本的Hadoop平臺在存儲時自動將大文件以128M大小的分片進行存放。因此,從應用視角,只需要操作一個文件,不必擔心其大小超過限制。這也為開發、測試、運維工作帶來了諸多多便利。
五、結束語
經過不斷調優和持續改進,歷時一年的不懈努力,二期系統終于在去年年底順利上線并投入運營。在該系統中,項目團隊首次采用了Hadoop云計算技術,提升了系統并行處理能力,不僅滿足了移動支付多樣化及第三方支付平臺接入的需要,系統吞吐量及健壯性也得到了極大的提高,滿足了互聯網時代大數據處理需求。
參 考 文 獻
[1]中國移動通信集團公司. 中國移動統一支付系統二期工程需求. 2014-03
[2]中國移動通信集團公司. 中國移動統一支付系統技術方案. 2014-04
[3]中國移動通信集團公司. 中國移動統一支付系統二期架構設計. 2014-06
[4]告訴你Hadoop是什么 .中國大數據. 2014-06.http://www.thebigdata.cn/Hadoop/10722.html
[5]詳解Hadoop核心架構 .中國大數據. 2014-07.http://www.thebigdata.cn/Hadoop/10973.html
[6]為什么hadoop對你大數據處理的意義重大.中國大數據. 2014-03.http://www.thebigdata.cn/Hadoop/9064.html
[7]移動支付的五種技術.價值中國. 2013-04. http://www.chinavalue.net/BookInfo/Comment.aspx?CommentID=48215
[8]陸嘉恒. Hadoop在百度中的應用. 腳本百事通. http://www.csdn123.com/html/itweb/20130916/120496_120504_120501.htm
猜你喜歡
江蘇安全生產(2023年10期)2023-11-14 12:12:58
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
知識經濟·中國直銷(2018年3期)2018-04-12 06:43:21
商周刊(2017年22期)2017-11-09 05:08:31
家庭影院技術(2017年9期)2017-09-26 03:41:45
河南電力(2015年5期)2015-06-08 06:01:46
