基于條件隨機場的人物信息抽取
2016-03-25 17:40:43鄭軼?k
計算技術與自動化 2015年4期
鄭軼?k


摘要:近年來,信息抽取成為自然語言處理的一個熱點,同時也是難點。針對不同的問題,大家提出了不同的方法,而大多數的方法是基于啟發式規則或者抽象成分類問題,本文將從人物百科中抽取人物信息看成是一個序列標注的問題,利用條件隨機場對生語料進行序列標注。此外,文中詳細介紹數據分析的方法以及特征選取方法,所提出的方法直接從生語料中抽取,節省了大部分方法的數據預處理部分,同時避開了大部分方法使用的句法分析的特征,有效地提高了信息抽取的效率。在文章的最后做了兩組對比實驗,實驗結果表明,本方法能夠非常準確地從HTML生語料中抽取出人物信息。
關鍵詞:CRFs;人物;人物信息;信息抽取
中圖分類號:TP391.1文獻標識碼:A
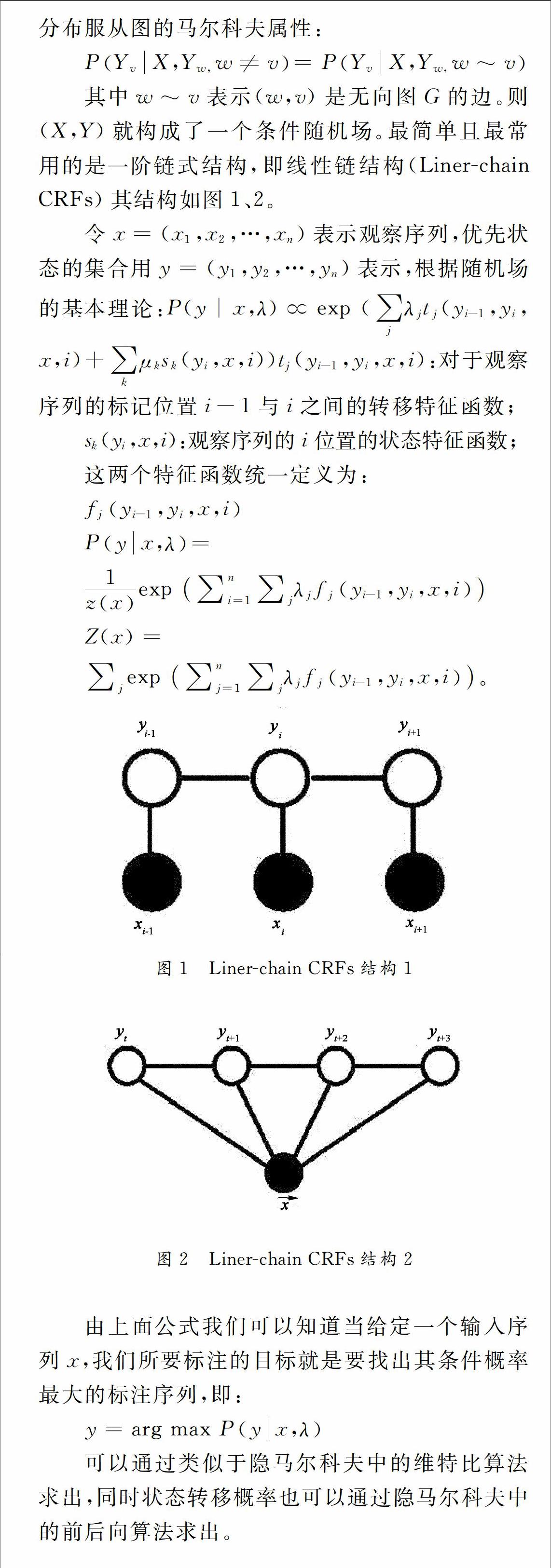
1引言
隨著互聯網的不斷發展,每天網絡中產生的信息越來越多,各種信息也呈爆炸式增長。而如何有效的從網絡中抽取出我們感興趣的信息,則顯得非常重要了。
傳統的信息抽取方法一般來說分為兩類:基于無監督的啟發式規則進行抽取,和基于機器學習方法進行有監督的信息抽取。其過程一般是定義一個清晰的信息抽取需求,然后分析所要處理語料的數據格式,再選擇合適的方法進行信息抽取。
為了從大規模的信息中抽取出所需要的信息,以及促進信息抽取的發展,美國華盛頓大學圖靈中心(University of Washington Turing Center)提出開放信息抽取(Open Information Extraction),這一理念也被稱為“新型抽取范式”的一種知識抽取方法[1]。
信息抽取系統的發展主要經歷了幾個階段,每一個階段都有其典型的系統,例如TEXTRUNNER系統[2]、REVERB系統[3]、R2A2系統[5]等。其中TEXTRUNNER系統是最早的開放信息抽取系統,主要通過自監督的學習器、信息抽取器和基于重復信息的評價器三個部分來進行信息抽取,其相比之前出現的KNOWITALL系統,錯誤率降低了30%[4]。但是EXTRUNNER有其自身的問題,首先是其抽取出的信息有些是無意義的,第二由于其light verb construction的現象導致丟失了關鍵信息。在此基礎上出現了REVERB系統,它的主要原理是以動詞作為句子的核心抽取標記,增加語法限制和詞匯限制,通過一定量的訓練語料發現信息抽取模式并進行泛化[5],其抽取效果較好,但是明顯的缺點是重動詞輕其他詞性,如以名詞作為中心詞的關系就抽取不出,而名詞作為中心詞在語言現象中出現的情況也屬常見,同時其論元的確定有寫也是錯誤的。這兩類信息抽取方法都是依據簡單的啟發式規則或簡單論元進行,不能適合大部分的復雜的語言語境,而后面出現的R2A2增加了論元識別器,即ARGLEARNER,目的是識別每一個Arg1和Arg2的左右邊界,原理是采用REPTree和條件隨機場以及正則表達式等技術進行語法監測,其準確率和召回率較前面的系統都有顯著的提升。
信息抽取的很重要的過程是分析數據文本,對指定信息進行定義,并發現其特征。本文借鑒了前面采用的信息抽取技術,并針對本文應用的百科數據進行分析,重點在于信息定義以及分析數據中信息特征,進行信息識別及抽取的過程,提出了基于條件隨機場的信息抽取方法。
3基于條件隨機場的人物信息抽取
本文的主要內容是做網頁信息的序列標注,所以這里本文采用CRF++開源工具包作為本文的分類器。CRF++工具包提供了兩類特征接口,一類是Unigram特征,一類是Bigram特征,其不同點在于生成特征時,包不包含前面一個輸出,顧名思義,Bigram是包含的,因此其能產生較多的特征,但同時效率也較低。
3.1數據分析
本文采用的數據語料是從網絡中爬取的歷史人物百科信息。該語料的特點是數據完全是原始的HTML數據,也正是因為如此,數據中包含了大量的HTML標簽和大量的對識別無意義的標識符。因此如何從生語料中分析出有價值信息就顯得格外重要。
經過仔細分析數據特點,我們發現對于人物百科HTML源碼,人物簡介部分,和人物介紹部分的HTML標簽并不固定,是會變化的。而且部分內容會以圖片連接的形式加入到HTML中,所以對于這些特殊情況,我們要對數據進行預處理。
3.2序列標注
從網頁源代碼中抽取人物信息的過程可以看成是序列標注的過程,即識別出HTML源中哪些部分是我們需要的語句塊,對于語句塊的序列標注具有多種表示方法,較常見的是IOB表示法和start/end表示法[7]。
IBO表示方法又可以分為IOB1,IOB2,IOE1和IOE2等四種。IOB1最早在[8]中提出,后來[9]在IOB1上進行改進,提出了其他幾種方法。但是其本質是相同的。表示如下:
B代表當前元素是一個組塊的開始。
I 代表當前元素是一個組塊的內部元素。
E代表當前元素是一個組塊的結束。
O代表當前元素不在任何一個組塊當中。
start/end是另外一種表示方法,最早由[10]中提出。其表達內容相比于IOB更加細致,共有I,O,E,B,S五種符號。其中BIEO表達的意思和上面一樣,而S代表當前元素獨立成一個組塊。
本文采用start/end表示方法,將我們所需要標注的訓練語料和測試語料都用BIEOS的方式標注。
3.3特征選擇
與以往進行序列標注的任務不同,我們的數據對象是HTML生文本,因此不需要進行Parser等工作,如此對于特征選取的效率會有一定的提高,但是同時也提高了分析數據特征的困難程度。對傳統的文本進行特征提取方式會提取句法結構、詞性等自然語言元素,對于本課題的任務,由于采用CRF++工具包作為分類器,本文采取以下特征模板:
Unigram:
1)div中每一個標簽中間的句的句原型。因為標簽中句原型是該部分的最直接、最明顯的信息特征,因此這是第一個最重要的特征。
2)中句原型所對應的HTML標簽,沒有則為NULL。即該句原型是被什么HTML標簽所包含,不同的HTML標簽表達的信息不同,因此HTML標簽可看作為該句的描述。
3)當前標簽前的class內容(-1,-2,-3,-4),沒有則為NULL。其中-1表示當前標簽的前一個class的內容,-2表示當前標簽的前兩個的class內容,以此類推,該項共表達了4個特征。class在HTML中表達固定部分的信息,其對應的是css樣式。如果前4個class都存在體現了標簽間互相包含的層次關系。
4)當前句的父class,沒有則為NULL。由于CRFs并不體現推理關系,也就是說各個特征之間在算法層面相互獨立,因此對于該特征與3中特征并不重復,該特征體現當前句是包含在哪個class中,對于當前句具有識別作用。
5)當前句后面的HTML標簽(+1,+2,+3,+4),沒有則為NULL。其中,+1表示當前句后第一個HTML標簽,+2表示當前句后第二個HTML標簽,以此類推,該項共表達了4個特征。由于部分HTML標簽有結束標記,部分HTML標簽沒有結束標記,因此用該特征來標記當前句的HTML信息。
6)當前句距離本
的距離歸一化值。用來標記當前詞的位置信息,位置對于序列標注具有重要的作用,而為了統一標準,這里對其進行歸一化處理。
Bigram:
1)class內容-4/ class內容-3/ class內容-2/ class內容-1。也即Unigram中的特征3中的4個特征的組合特征,組合特征會產生更豐富的信息,有利于序列標注的準確性。
2)HTML標簽+1/ HTML標簽+2/ HTML標簽+3/ HTML標簽+4。也即Unigram特征5中4個特征的組合特征。
4實驗結果
根據上述標注方法,本文標注了3組不同數量的測試集,8組不同數量的訓練集。
從表中我們可以看出,人物描述部分TITLE和CONTENT是一一對應的。測試結果1:
第一,測試不同標注數量的訓練集對測試的影響。首先選定測試集為TEST1,當訓練集為TRAIN1TRAIN8時整體準確率、召回率和F值的變化如下:
1)隨著標注數量的增多,從標注1200組數據到標注2000組數據的過程中,整體的準確率上升幅度非常大,說明標注的數量對于整體的準確率影響很大。
2)SUMMARY部分的準確率一直處于100%狀態,說明選取特征與實際HTML中的情況相對吻合,但由于召回率起始并不高,說明標注語料覆蓋的程度較小。
3)TITLE和CONTENT部分的F值一直處于100%狀態。這一現象說明用于CRFs訓練的特征與實際HTML中的TITLE、CONTENT部分的分布情況十分吻合,同時根據我們所選取的特征說明HTML源中該部分的HTML標記相對規則。
測試結果2:
第二,測試使用標注數量最大的訓練集對相對大規模的網頁文本進行抽取,統計其準確度情況。
從表中我們可以看出:
1)隨著測試集的增多,使用同一訓練集的召回率在不斷下降,說明所標注的訓練集的內容并沒有覆蓋所有的實際情況。
2)盡管測試集數量從2000上升到10000SUMMARY、TITLE和CONTENT部分的準確率始終保持在98%左右, 說明我們所選取的特征確實反映了實際HTML中的情況。
從上面的兩組結果我們可以看到,本文所提出的基于條件隨機場的人物信息抽取,對于百科文本具有十分良好的效果,其準確率和召回率能夠滿足實際應用的需要,信息抽取出的結果有利于下一步科研的進行。后續工作我們還會繼續添加訓練語料,以盡可能完整地覆蓋實際百科HTML中的實際情況。
5結論與展望
本文中,根據特定的任務分析出數據的特點,有效地利用了人物百科HTML源中各個標簽所起的作用,分析出能夠合理表示我們所需信息的特征及其組合。
以往的信息抽取或者利用啟發式規則進行抽取,或者將其抽象成分類問題進行抽取,本文將信息抽取看成是一個序列標注問題進行序列標注,而不是抽取。在特征選擇的部分,拋開以往方法所用到的句法分析等耗時的步驟,直接從生語料中選取特征,一方面節省了大量的時間,另一方面減少了對生語料的處理步驟,從整體上講,大幅度的提高了信息抽取的效率。此外本文所提出的方法并不僅限于人物百科的抽取,同樣的方法可以應用到其他對于HTML源的信息抽取任務,提供了一種新穎的信息抽取思路。
信息抽取是當前自然語言處理的熱點也是難點,如何從每天產生的海量數據中抽取出我們所需要的、感興趣的信息,對于節省人力物力非常有意義,當前的信息抽取一般采用基于啟發式規則和機器學習相結合的方法來進行。但是大多是針對特定任務而提出的方法,并不具有通用性,因此如何提出一個普適的信息抽取方法將成為信息抽取發展的一個方向,這將為自然語言處理的發展,做出巨大的貢獻。
參考文獻
[1]張智雄,吳振新,劉建華,等. 當前知識抽取的主要技術方法解析[J]. 現代圖書情報技術,2008,08:2-11.
[2]Michele Banko, Michael J Cafarella, Stephen Scoderl, Matt Broadhead, Oren Etzioni. Open Iniformation Extraction from the Web[C]. In Proceedings of Conference on Arti_cial Intelligence, 2007:2670-2676
[3]Anthony Fader, Stephen Soderland, Oren Etzioni. Identifying Relations for Open Information Extraction[C]. In Proceedings of the Conference of Empirical Methods in Natural Language Processing, 2011
[4]SCHMITZ M,BART R,SODERLAND S,et al.Open language learning for information extraction[C]//Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Association for Computational Linguistics, 2012: 523-534.
[5]ETZIONI O,FADER A, CHRISTENSEN J, et al. Open information extraction: The second generation[C]//Proceedings of the Twenty-Second international joint conference on Artificial IntelligenceVolume Volume One. AAAI Press, 2011: 3-10.
[6]孫靜, 李軍輝, 周國棟. 基于條件隨機場的無監督中文詞性標注[J]. 計算機應用與軟件, 2011, 28(4): 21-23.
[7]丁偉偉,常寶寶. 基于語義組塊分析的漢語語義角色標注[J]. 中文信息學報,2009,05:53-61+74.
[8]RAMSHAW L A,MARCUS M P.Text chunking using transformation based learning[C]//Proceedings of the 3rd Workshop on VeryLarge Corpora. 1995.
[9]SANG E F,KIM T J. Veenstra. Representing text chunks [C]//Proceedingsof the 38th Annual Meetingof the Association for Computational Linguistics, Hong Kong, China. 1999.
[10]UCHIMOTO K,MA Q,MURATA M,OZAKU H,ISAHARA H.Named Entity Extraction Based on A Maximum Entropy Model and Transformation Rules [C]// Proceedings of the 38thAnnual Meeting of the Association for Computational Linguistics, Hong Kong, China. 2000.
