增強個體代表性:基于日志數據的長期時間利用預測①
2016-04-09 02:03:36檀學文
中國農業大學學報(社會科學版) 2016年1期
檀學文
?
增強個體代表性:基于日志數據的長期時間利用預測①
檀學文
[摘要]針對時間利用日志數據存在的個體代表性不足以及統計意義上的“多零”問題,文章借鑒已有文獻的兩部分回歸方法,從日志數據預測長期時間利用數據。結果顯示,利用人口和社會經濟變量以及活動參與頻率變量對長期時間利用的預測結果具有較好的穩健性,分布更均勻,同時大幅度減少了“多零”問題,清除了時間利用實證分析的一大障礙。因此,未來的時間利用調查如果添加非經常性活動參加頻率的問題,將會有利于提高時間利用數據的利用程度和效果。
[關鍵詞]時間利用福祉; 社會指標; 預測
社會科學的研究對象是人,主要是由個體組成的群體或社會,其中個體包括居民以及企業、社會組織、政府等法人。一般來說,研究個體的目的主要還是為了研究群體,個體主要充當樣本或案例。統計學以抽樣方法獲取有限數量的個體作為樣本,以推斷其所代表的總體的情況。在意識形態領域和社會科學方法論領域均有集體主義和個體主義之爭,但是后者通常還是為群體性目標服務。但是,近年以來出現了直接以個體為對象和目標的研究方法。一個典型例子是在福祉研究領域,在OECD創建的網站上②www.oecdbetterlifeindex.org。,網民輸入自己的各項指標,便可計算出自己的福祉指數——“更好生活指數(BLI)”;澳大利亞居民在給出自己對7項主觀滿意度指標分值后,也可以得出自己的福祉指數(AUWBI)。
在樣本量足夠大且具有代表性的情況下,其統計特征能夠用于推斷總體特征。但是如果要評價樣本本身,那么就需要考慮指標的樣本個體代表性問題。在經濟社會研究領域,一個經常性的問題是所使用的指標能在多大程度上體現該指標所應體現的含義。用統計術語來說,就是如何增強概念的名義定義和操作定義的一致性[1]。例如,在AUWBI指數中,福祉的含義是近期的主觀福祉狀況,其具體的組成變量是7個關于近期生活各個方面的滿意度評估,這些變量的含義以及時限與近期主觀福祉的內涵都是一致的。然而BLI指數使用了多個維度的客觀指標,其指標代表性就值得討論。例如,就業或失業都是指最近兩周的情況,時間利用是指昨日的時間利用,這些指標口徑對于個體樣本的近期狀況來說具有很大的偶然性,代表性比較差。
增強指標的個體代表性,一方面是為了順應當前個性化的時代趨勢,另一方面也是為了改進定量分析效果。如果以一日時間利用數據或一日消費數據來代表個體的時間利用特征,容易出現大量特異值,如0或特別大的值,損害實證分析結果的解釋力。對于這種類型的指標,就存在增強個體代表性的必要性。增強指標個體代表性的方法通常可以分為三種:擴大數據記錄的時間區間、使用估計的而不是記錄的數據、使用替代性指標,三者各有優劣。就時間利用而言,日志記錄數據準確但是代價高,如果增加記錄天數則代價更高;估計數據的代表性增強,而且調查成本低,但是其準確性降低;替代性指標與原指標的一致性有時會存在問題。這就是社會科學調查研究中經常面臨的數據需求與獲取之間的權衡取舍問題。本文以時間利用數據為例,對此進行探索,希望為依靠調查或統計數據進行的微觀研究提供有益的數據改進思路。
本文意圖利用時間利用日志調查數據,估計具有更好樣本代表性的長期時間利用數據,對其統計學特征進行檢驗,從而對時間利用數據的獲取和應用提出相應的對策建議。正文包括四個部分。第一部分是關于長期時間利用預測的理論,包括作為參考的長期食品消費預測模型以及建立在這一模型基礎上的長期時間利用預測模型。第二部分利用中國農民抽樣調查數據,從日志時間利用預測長期時間利用。第三部分利用統計學原理,評價估計長期時間利用數據的統計學特征,評估其樣本代表性。最后一部分對本文使用的研究方法和結果進行評價,對其可能的應用價值進行了說明。
一、長期時間利用預測理論與方法
(一)居民福祉與時間利用
從傳統經濟研究和福利經濟學角度,經濟增長被視為福利改進的主要甚至唯一標志。福祉研究超越傳統福利經濟學的上述強假設,提出多維度、多指標表征福祉的必要性和可行性。除了用消費指標代替收入指標外,還有健康、社會聯系、時間利用、主觀福祉等多個領域的指標[2]。已有的多維福祉框架中,無論是社會層面還是個人層面的,大部分都包含時間利用或個人活動維度。時間利用通常情況下都是以時間在不同活動間的分配和使用狀況來表征居民在這項重要資源的利用方面的福祉狀況[3]。根據對福祉的不同定義,時間利用與福祉的關系大體上有三條指標選擇和研究路徑,即擴展的經濟福祉、實時性主觀福祉和多維客觀福祉[4](見表1)。其中,后二者屬于個人福祉范疇,可以分別稱為主觀時間和客觀時間[5]。本文遵循多維客觀福祉理論,將時間利用視為多維福祉的一個客觀維度,與教育、經濟等其他維度并列。如表1所示,即使在多維福祉框架下,時間利用指標也有主觀指標和客觀指標之分。其中,主觀指標主要是對時間利用狀況的主觀評價,而客觀指標主要是對實際時間利用的記錄或回憶/估計。
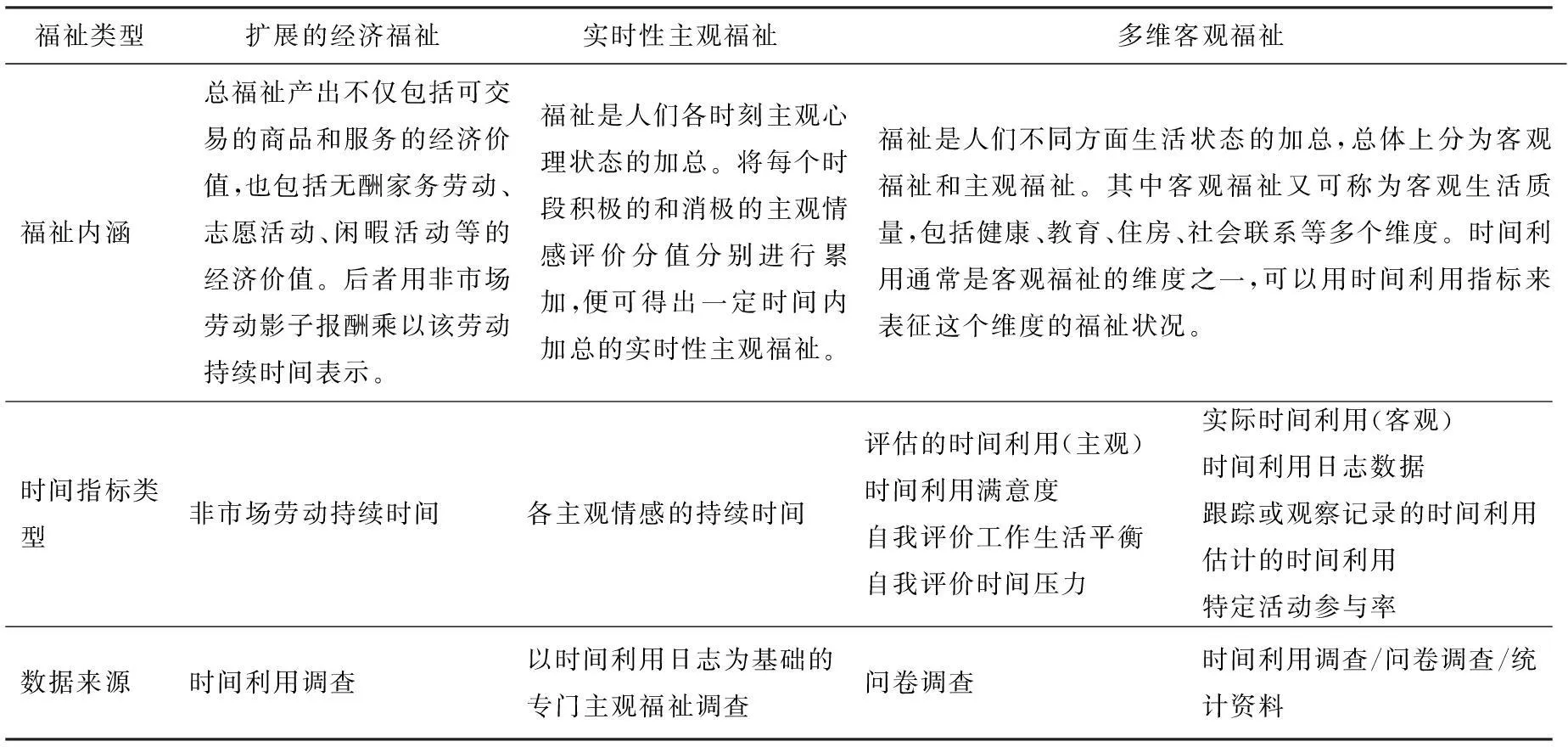
表1 對應于不同福祉內涵的時間利用指標及其數據來源
資料來源:根據文獻[3] [6] [7]整理。
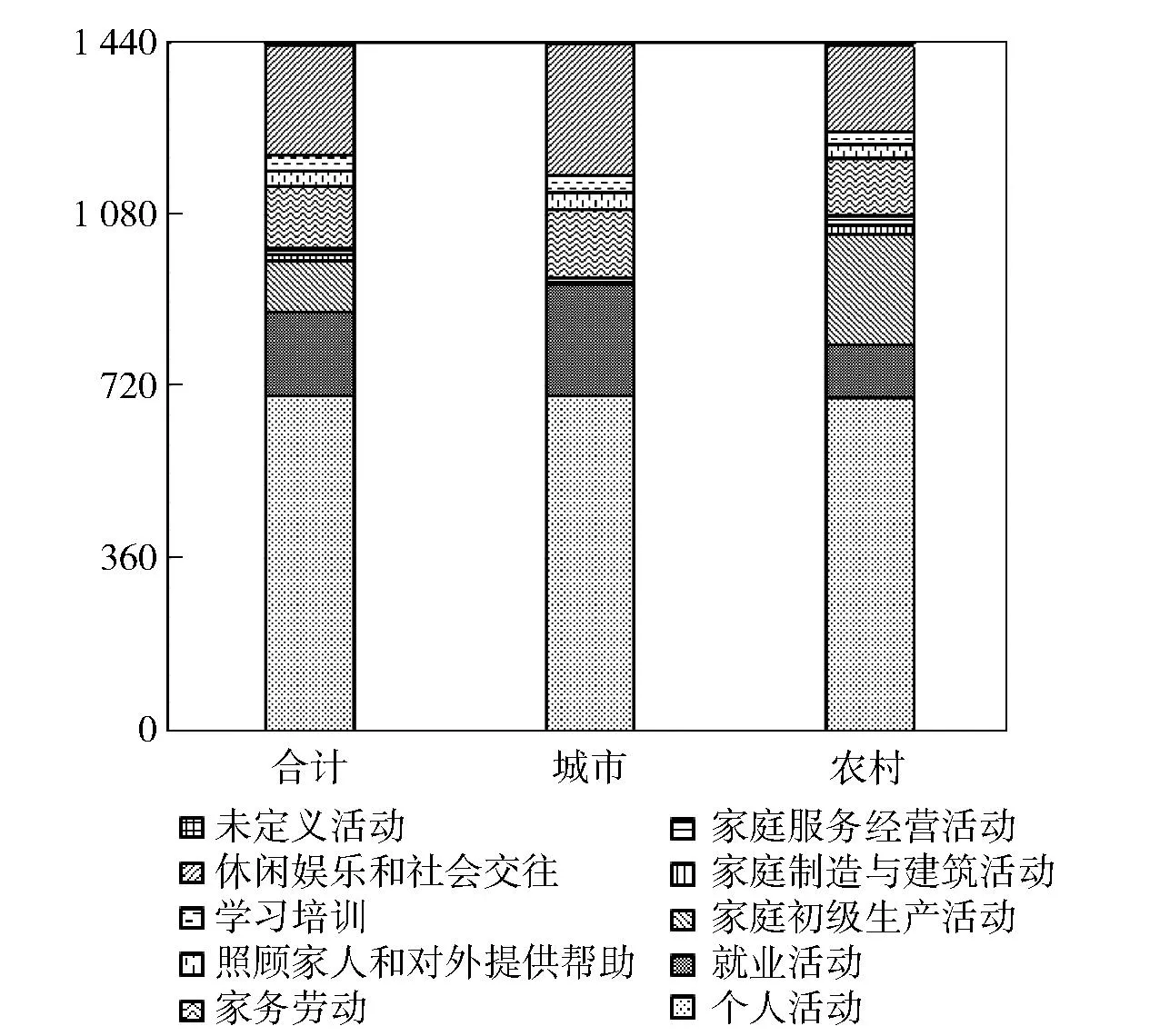
圖1 2008年按大類劃分的城鄉居民時間利用狀況 注:數據來源于《2008年時間利用調查資料匯編》,中國統計出版社,2009年。
本文的分析對象是作為客觀指標的時間利用日志數據。時間利用日志調查記錄受訪人的基本信息以及在調查前一天24小時內的所有活動情況。調查表通常以10分鐘為單位,將24小時劃分為144個連續的時間單元。受訪人按順序依次填寫每項活動的具體內容、持續時間、同時發生的其他活動、活動的地點以及與什么人在一起等。有時候,時間利用日志調查也通過問卷調查的方式進行,由調查員詢問受訪人并填寫問卷。時間利用日志調查僅調查受訪日前一天發生的活動,而且按時間順序排列,所以是最為準確的時間利用數據。時間利用日志調查表在填寫、回收后,經過對具體活動內容對照時間利用同類活動分類代碼表進行編碼、歸類,便可獲得受訪者的一日時間利用數據。例如,2008年,國家統計局在10個省、市開展了第一次居民時間利用調查,共獲得3.7萬個居民樣本[8]。這次調查的城鄉居民大類平均活動時間如圖1所示。從中可見,城鄉居民時間利用有明顯差別,主要體現在農民有酬勞動時間比市民長很多,而閑暇時間則短很多。
(二)從日志數據預測長期數據的方法
1.通常食品消費數量預測
從隨機性短期數據估計長期數據的方法較早地以及較多地用于營養和健康領域的食物消費。居民食物消費數據具有與時間利用日志數據類似的形式,即受訪者對某日24小時內所有消費的食物的記錄或根據記憶的估計數據。類似于時間利用,一日的食物消費行為具有偶發性,實際食物消費數量對于通常食品消費數量而言存在典型的測量誤差,包括個人誤差和人際誤差,一般通過回歸校正法予以調整[9]。根據消費頻率,食品可以區分為日常性消費食品和偶發性消費食品。一項研究對這兩類消費數據的誤差修正方法進行了區分[10]。對于日常性消費食品,在傳統的混合模型基礎上,通過使用Box-Cox變換,將實際消費數據的偏態分布轉換為接近于正態分布,可以估計出實際消費數據的個人誤差和人際誤差。對于偶然性消費,論文采用了兩部分測量誤差模型:第一個方程用于估計消費某類食品的發生概率;第二個方程用于估計某類食品在發生消費的情況下所存在的兩類誤差,與對日常性消費食品所使用的模型相同。該模型具體表達如下:
(1)
(2)
其中,公式(1)為logistic回歸,估計第i種食品消費在第j日的發生概率pi,X1i為有關的解釋變量,μ1i為人際誤差;公式(2)為OLS回歸,估計第i種食品消費在第j日實際發生的情況下,其預測的消費數量,X2i為有關的解釋變量,隨機誤差μ2i和εij分別表示人際誤差和個人誤差。
從而,第i種食品的通常消費數量,也就是長期估計值,等于其發生概率以及在發生情況下的預測值的乘積,即:
Ti≡E(Tij|i) =piAi
(3)
該模型為混合效應模型,每個方程都包含固定效應和隨機效應。兩個方程存在聯系,不僅兩者的人際誤差μ1i和μ2i是相關的,而且它們的解釋變量中至少有部分變量是共同的。
在進行經驗估計時,解釋變量的選擇除了人口特征變量外,還包括了食品消費頻率(FFQ)變量作為補充變量。利用美國健康與營養調查數據(NHANES),該論文證明,通過將食品消費數據和食品消費頻率數據結合起來,即將FFQi添加為解釋變量Xi的一部分,能夠提高通常食品消費預測以及飲食—健康關系估計的精確性。
2.長期時間利用預測
食品消費數據和時間利用數據雖然都是記錄24小時內發生的事件,而且也都包含日常性事件和偶發性事件,但是它們實際上存在著很大差別:時間利用數據的單位是時間,如小時和分鐘,受總量約束,即一天的所有活動時間加總后必然等于1 440分鐘;食品消費數據的單位是數量,如克或公斤,加總后無總量約束。由于總量約束,一天內不同活動的時間存在替代關系,一類活動時間的增加必將導致其他某類活動時間的減少;而食品消費則不存在這種嚴格的替代關系,不同類型的食品消費是相互獨立的。
基于每日時間總量約束以及用一系列閑暇活動的參與頻率代表個人行為“習慣”的社會學理論[11],Gershuny提出了一種基于上述兩部分模型但是相對簡化的估計方案[12],可以表達如下:
(4)
(5)
(6)
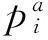
∑LTTi=1 440
(7)
公式(4)~(6)的函數形式分別與公式(1)~(3)相同。兩個模型的差別在于:
① 食品消費模型使用面板數據,從而可以同時估計個人隨機誤差和人際誤差;時間利用數據利用截面數據,只能估計人際誤差。
② 食品消費模型中,添加的FFQi變量是單一變量,只在估計第i類食品消費時使用該類食品的FFQ;時間利用模型中,添加的習慣變量是組合變量,即一組各類閑暇活動的參與頻率,對所有類型活動的估計是一樣的。
③ 食品消費模型獨立地估計各類食品的消費數量;但是時間利用模型同時估計各類活動的長期時間,結果受一日時間加總約束。
根據此項研究,上述長期時間利用估計方法至少可以解決日志數據存在的兩個主要問題:一是閑暇活動等不經常發生的活動時間的“多零”問題*“多零”是指在居民時間利用調查數據中,當活動分類足夠細化時,很多類型的活動時間都會顯示為0,但這并不代表受訪者的這些活動時間真的為0。如果以它們作為自變量進行回歸,也會對回歸結果造成干擾。;二是數據正向偏斜和右尾極端值問題,由此增強數據的個體代表性。
二、中國農民長期時間利用預測
(一)數據
長期數據預測的基本思路是,短期行為是長期行為的一部分,從短期行為數據一方面可以估計其長期發生的概率,另一方面估計該行為在發生情況下的數值,該估計值與估計概率的乘積即為長期估計值。利用這種方法,可以用時間利用日志數據估計長期的時間利用規律,即通常情況下個人的24小時都用于哪些活動。這種方法的前提是需要更多的變量支持,對于常規的時間利用日志數據或飲食日志數據是不適用的。上述Gershuny使用的“Time Diary Study 2000/01”數據中除了日志數據,還有一系列活動參與頻率變量,后者是估計所需的重要解釋變量,代表著人們的行為“習慣”。借鑒上述方法,我們在調查問卷中設計了類似的活動參與頻率的問題,為預測長期時間利用提供了條件。
本文使用中國社會科學院創新工程項目“中國農民福祉研究”2013年農村居民抽樣調查數據。調查內容包含家庭成員、主觀福祉、勞動與就業等12個方面。其中,時間利用部分包括昨日時間利用日志、閑暇時間滿意度以及閑暇活動參與頻率三類問題。該調查在位于遼寧、江蘇、湖北、寧夏和貴州5個省的10個縣、市進行,在每個縣、市各抽取5個行政村,每個村預定抽樣規模為20人。樣本省分別位于東部、中部和西部,具有一定的地域代表性。省內的樣本縣、市按照經濟發展水平抽取,基本處于中等水平。縣、市內的樣本村通過隨機抽樣或者按照經濟發展水平高低進行抽取。在樣本村內,居民樣本分布于不同的村民組和不同的收入和生活水平,具有一定的村莊代表性。調查問卷均由調查員提問和填寫。本次調查一共回收1 000份有效問卷,其中860份問卷擁有完整時間利用數據,是本文預測長期時間利用的數據基礎*通常情況下,考慮到一日時間利用數據代表性問題,時間利用調查需要考慮具體的時間選擇問題,有些國家(如韓國)的時間利用調查甚至在一年內針對同一樣本進行2次到4次調查,力圖以此來增強其代表性。對于中國農民來說,應當考慮地域差異以及季節差異(農忙、農閑),而工作日和周末的差異是次要的。2008年中國居民時間利用調查時間為5月份,各地總體上都是農忙季節,具有較好的代表性。本研究使用的時間利用調查是與農戶問卷調查結合進行的,調查時間受總體調查安排的約束。不過,2013年農村居民抽樣調查是在7月至9月期間進行,總體上也都是農忙季節,但是并非最忙碌或農閑的時候,所以也具有一定的代表性。。
(二)預測步驟與結果
借鑒Gershuny建立的方法,本文以時間利用日志數據為基礎,預測個人的長期時間利用分布。主要預測步驟如下:
1.原始數據處理
包括時間利用活動類型重新歸類、部分解釋變量重新編碼、缺失值處理等。各種時間利用統計活動分類都有大小不同的差別。中國國家統計局2008年時間利用調查將活動分為10個大類、66個中類和115個小類。本文根據分析需要以及中國農民很多閑暇活動參與率極低的現實,將一些大類合并,將閑暇活動分為4種類型,合計將活動類型分為11類。為滿足模型回歸需要,對部分變量進行重新編碼、缺失值處理。其中,對婚姻狀況、健康狀況、教育、社會身份等都進行了重新編碼。
2.活動的參與概率預測
以重新歸類的11類活動時間為基礎,將其轉換為以0或1表征的“是否參與”變量:若活動時間大于0,新變量編碼為1,表示當日參與了該活動;若活動時間為0,新變量編碼為0,表示當日未參與該活動。以該新變量為因變量,以特別選定的變量為自變量,用logit方程估計個人對各類活動的參與概率。自變量分為人口和社會經濟特征等控制變量以及活動參與頻率變量兩類,前者包括年齡、年齡平方、性別、婚姻狀況、健康狀況、需照料家庭成員情況、教育、工作類型、調查日類型(工作日或周末)、最近一周累計工作時間以及省份虛擬變量;后者包括14類非經常性閑暇活動參與頻率變量,代表個人活動習慣(表2)。
3.活動的參與者參與時間預測
以重新歸類的11類活動時間為因變量,以上述兩類變量為自變量,用最小二乘回歸方程估計個人對各項活動的參與者參與時間。此處使用的自變量與步驟2中的logit回歸相同。
4.活動的長期平均參與時間計算
將步驟2和3的結果相乘,得出個人各項活動的長期平均參與時間的預測值。
5.長期時間利用估計值調整
對步驟4的結果進行負值調整和總和調整。將小于0的估計值調整為0;并以加總值與1 440的比值為調整因子,對預測的長期平均參與時間進行調整,使得他它們的加總值仍然為1 440分鐘。
由此得出的估計的長期時間利用分布如表3所示。

表2 代表習慣的不經常性閑暇活動參與頻率變量
注:表中參與頻次指過去一年內的參與次數,最高為365;參與頻率分為5個等級:全年最多1次、每月不足1次、每周不足1次、每周1到4次、每周4次以上。
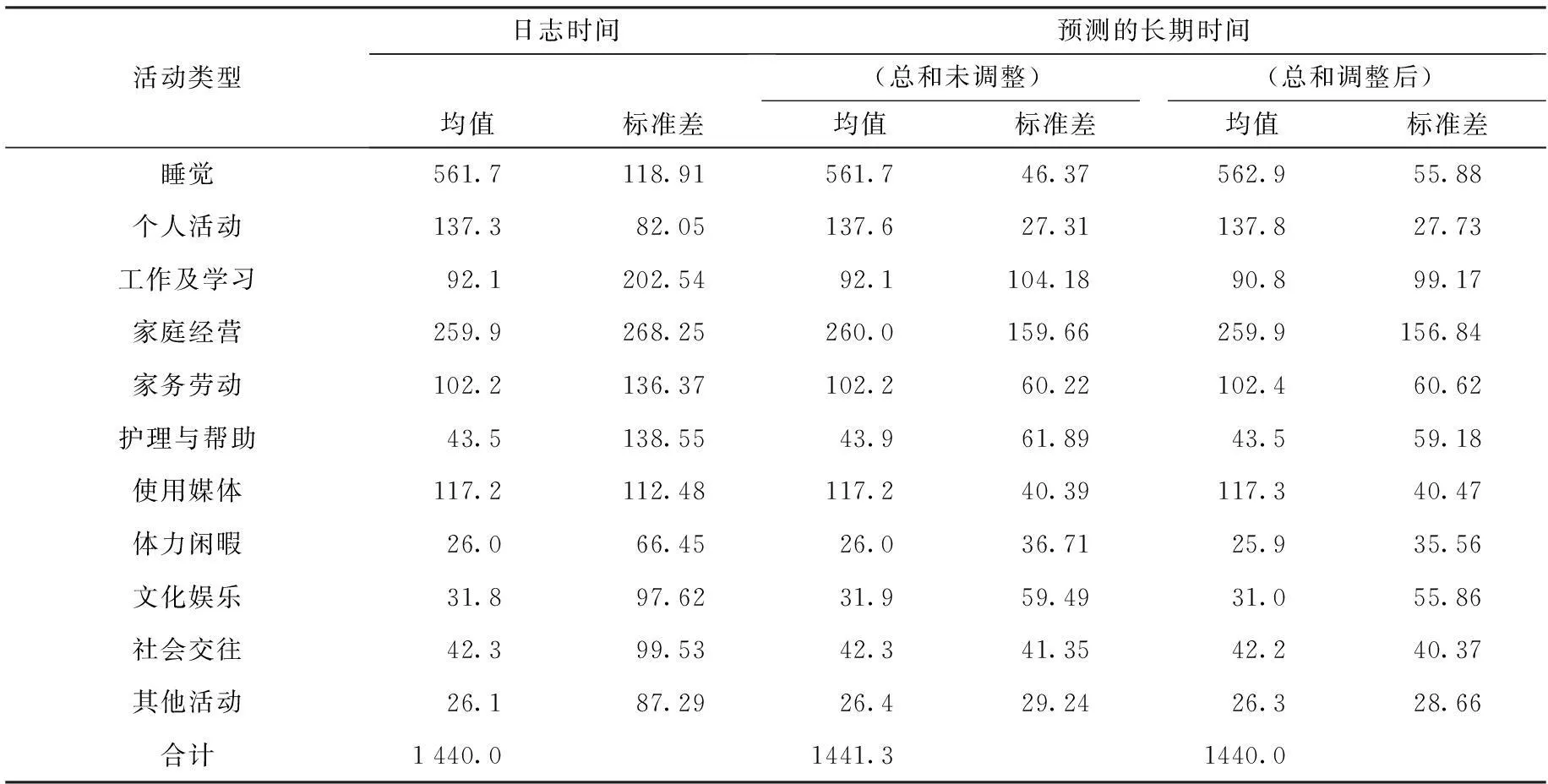
表3 長期時間利用預測結果 單位:分鐘
注:此表及以后各表采用下述方案Ⅲ的結果。
(三)預測結果可靠性與穩健性檢驗
與Gershuny的依據類似,從日志時間得到的樣本總體各項活動的平均時間和樣本長期時間配置的總體均值應該近似相等,本文的計算結果符合此條件。為了進一步檢驗預測結果的可靠性,我們分別對3套解釋變量方案進行估計:方案Ⅰ僅以上述控制變量對被解釋變量進行回歸;方案Ⅱ和Ⅲ同時以控制變量和不經常性活動參與頻率變量對被解釋變量進行回歸,其中后者在方案Ⅱ中采取參與頻次形式,在方案Ⅲ中采取頻率形式(見表2)。結果顯示,3套方案的預測結果都極為接近,分別是1 440.4分鐘、1 442.0分鐘和1 441.3分鐘,這表明模型設置具有較好的穩健性。方案Ⅱ和Ⅲ使用了不經常性活動參與頻率變量,各方程回歸結果顯示,它們的R2和PseudoR2值都明顯地大于方案Ⅰ,表明模型的解釋能力得到了較大的提升(見表4)。方案Ⅲ的R2和PseudoR2值總體上稍大于方案Ⅱ,但是差別非常小,表明不經常性閑暇活動頻率變量可以用分類形式代替原始頻率形式且不損失效率。
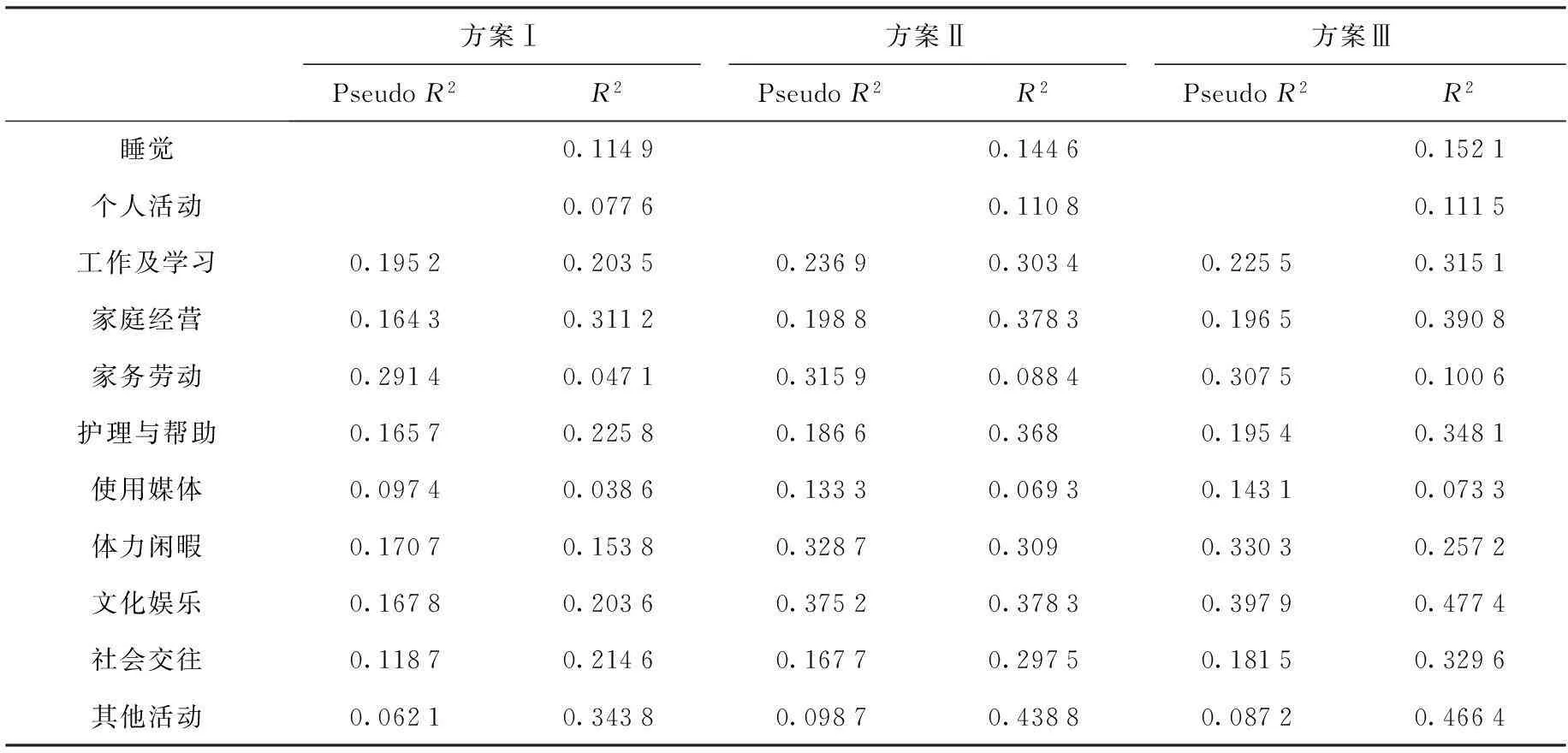
表4 長期時間利用預測的三套方案擬合效果比較
注:睡覺和個人活動的參與頻率被設定為1,故沒有為它們設立概率估計方程,從而也就不存在PseudoR2。
三、預測前后的時間利用分布比較
(一)總體時間利用比較
從近期研究成果看,在統計上,中國農民時間利用具有典型的發展中國家特征,即睡眠時間足夠;有酬勞動時間更長;休閑娛樂和社會交往時間更短,且以消極閑暇活動為主;無酬家務勞動時間也偏短;女性勞動時間長而閑暇時間短[4]。農民的時間利用分布在2008年與2012年以及2013年都比較接近,表明他們的時間利用規律是比較穩定的。對2013年農民時間利用日志數據和長期估計數據的統計特征進行比較顯示:在總體上,兩類數據的平均值極為接近,T檢驗顯示差異均不顯著。但是預測的長期時間利用比日志時間利用的統計分布更加均勻,即估計后的標準差、偏度、峰度都比估計前大幅度下降了(表5)。
此外,預測的長期時間利用數據大大減少了日志數據中存在的“多零”問題。盡管我們在計算中使用的簡化分類已經大大減少了活動類型的數量并降低了發生零的可能性,但是日志數據中仍然有大量的零存在。除睡眠和個人活動外,其他9種活動時間為0的情況平均達到65%之多。而在預測數據中,該比例下降到1.9%(表6)。
進一步地,我們可以形象地考察各類活動的時間分布特征。在圖2所列舉的三類活動中,睡眠時間的分布最為接近于正態分布,尤其是對于長期估計值而言;接下來是工作時間,其分布偏度較小,但是峰度明顯比睡眠時間小,即顯得更為平坦;閑暇時間分布的偏度比正態分布大,而且是向右偏,但是其峰度與睡眠時間接近。分活動的長期預測時間與日志時間相比最大特點就是其分布更加集中,不對稱程度也有所下降。
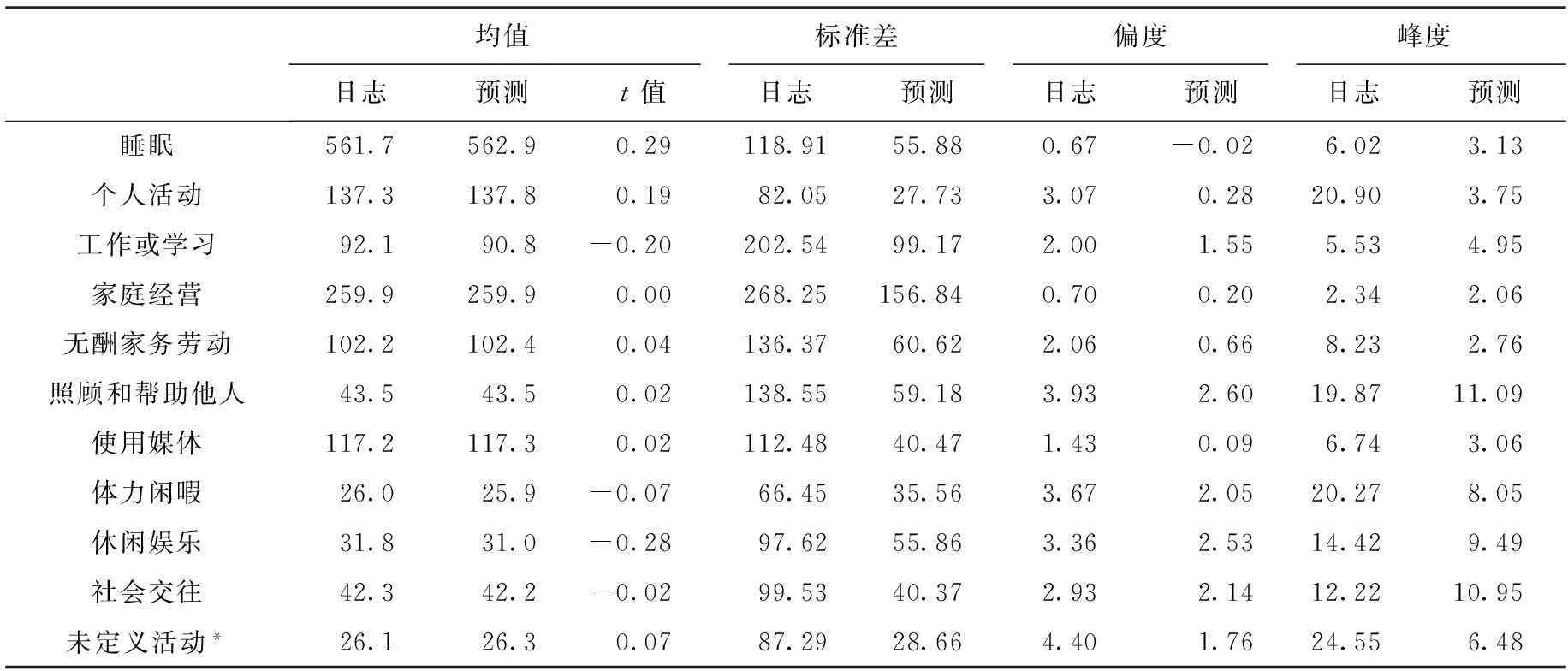
表5 日志時間與預測時間利用描述統計比較 單位:分鐘
注:社會和政治參與活動所發生的樣本極少,為方便分類,將其并入未定義活動內。
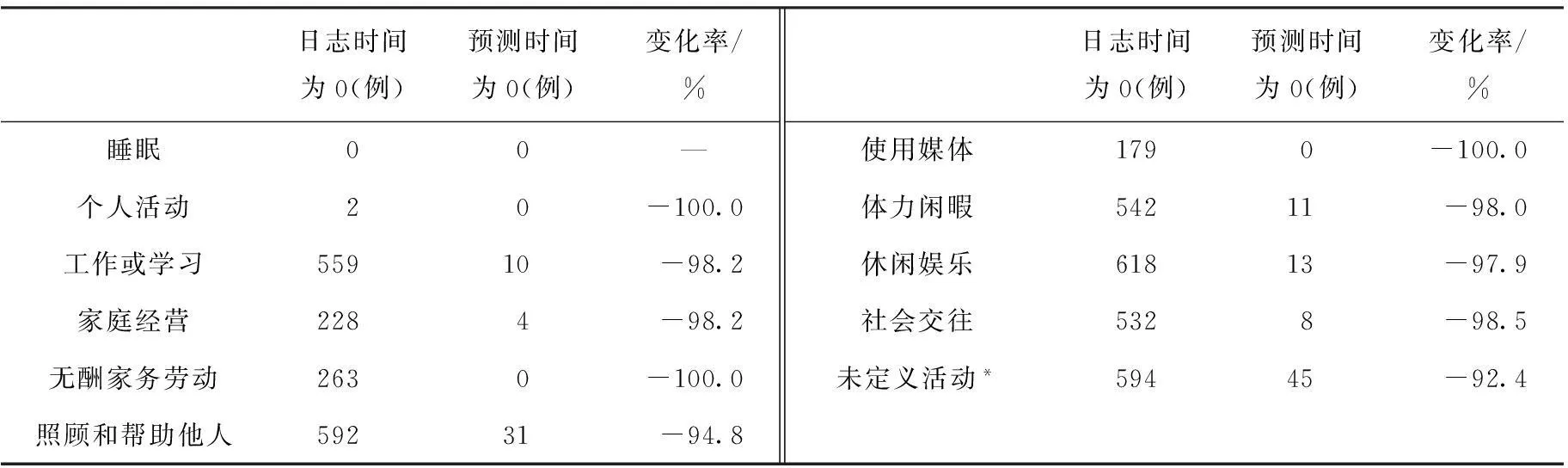
表6 預測時間與日志時間相比含零樣本數量及其變化
注:樣本量為702個。
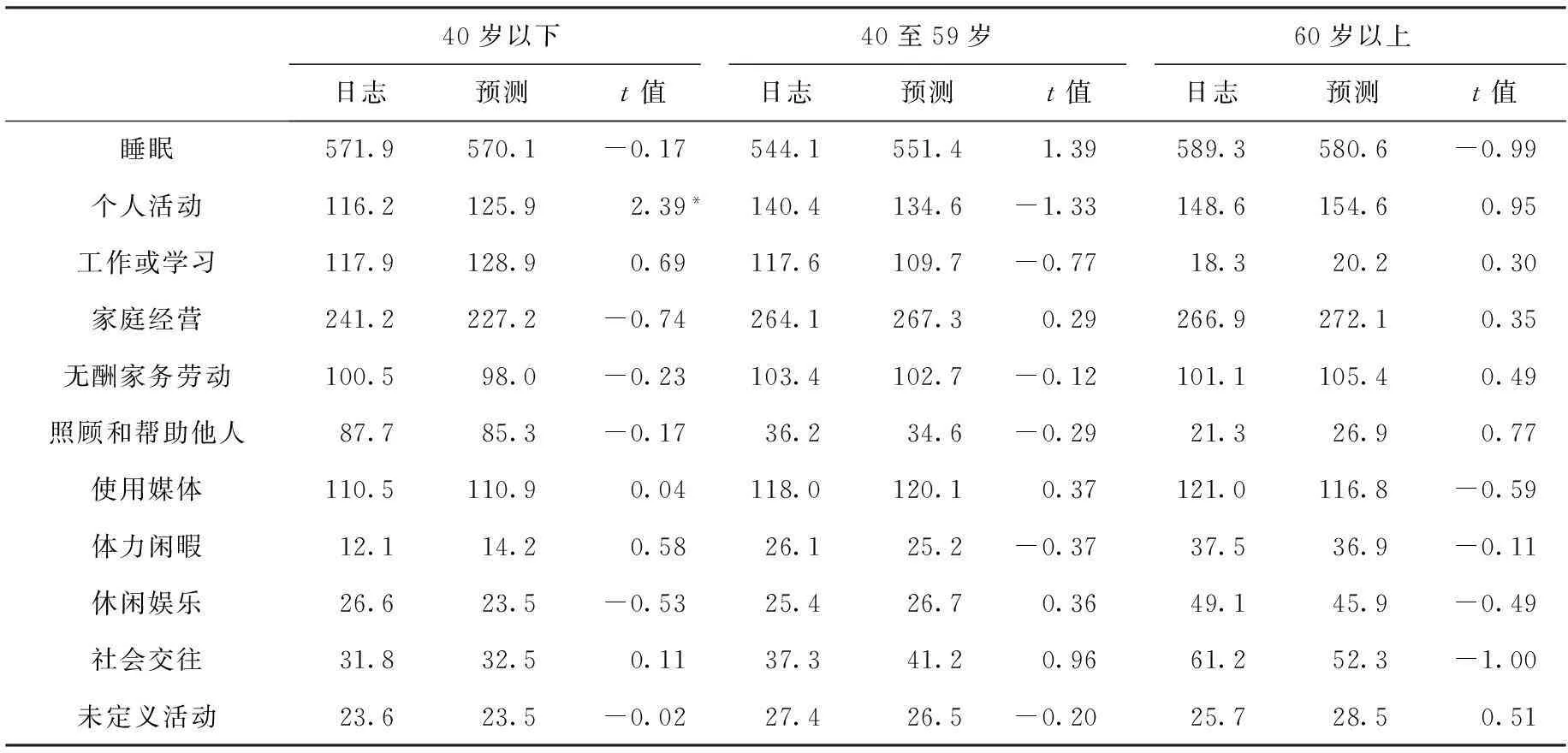
(二)分群體時間利用比較
我們對預測前后的時間利用進行了分群體比較,包括分性別和分年齡組比較,其中按年齡分為三組:40歲以下、40至59歲、60歲以上。對不同群體的日志時間和預測時間分別進行T檢驗,結果顯示,除了極個別情況之外(40歲以下組的個人活動時間的日志值和預測值差異顯著),包括性別分類和年齡分組,幾乎所有活動時間的日志值和預測值的差異都是不顯著的(表7)。為節約篇幅,分性別的結果比較省略。
四、總結與討論
作為一項衍生性或工具性任務,本文致力于從日志時間利用數據預測長期時間利用數據,其目的是提高時間利用數據的個體代表性。我們借鑒一項英國學者的研究成果,利用課題組的抽樣調查數據,估計了長期時間利用的預測數據。從預測數據的統計學特征看,預測數據具有較好的穩定性和比日志數據具有更好的個人代表性。對于日志數據存在的“多零”問題,預測結果對其有了很大的彌補。從而,預測的長期時間利用數據可以更好地用于時間利用指標構建以及福祉決定的實證研究。
如表1所示,時間利用指標有主觀指標和客觀指標之分,類型很多,通過比較判斷各類指標的優缺點以及選擇更好的指標是時間利用研究的一項有價值的任務。本文對長期時間利用的預測可以對這項工作有所貢獻,可以用預測的長期時間利用指標與其他類型指標進行比較。長期時間利用預測對數據要求比較高,除了日志數據還需要大量的個人特征變量以及閑暇活動頻率變量,對問卷長度和調查成本形成挑戰。但是無論如何,該投入對于增加時間利用數據的整體價值是有利的。中國到目前為止只開展了一次官方時間利用調查。我們預期未來中國必將進行更多的時間利用調查。因此我們建議在未來的調查中對全體樣本或者部分樣本收集更多的信息,例如預測長期時間利用所需的控制變量以及活動頻率變量,以便于更好地開展時間利用數據分析和研究。
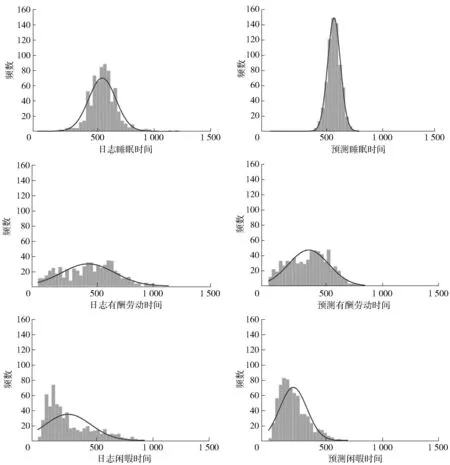
圖2 三類活動的日志時間與長期預測時間分布對比
單位:分鐘
注:*表示在5%水平上差異顯著,雙尾檢驗。
[參考文獻]
[1]巴比.社會研究方法(第10版).邱澤奇譯.北京:華夏出版社,2005
[2]Stiglitz J E,Sen A, Fitoussi J P.ReportbytheCommissionontheMeasurementofEconomicPerformanceandSocialProgress. http:∥www.stiglitz-sen-fitoussi.fr/,2009
[3]Gershuny J.Time-UseSurveysandtheMeasurementofNationalWell-Being. Swansea, UK: Office for National Statistics, 2011
[4]檀學文.時間利用對個人福祉的影響初探——基于中國農民福祉抽樣調查數據的經驗分析.中國農村經濟,2013(10):76-90
[5]Robinson J P. Using Time as Social Indicator.SocialIndicatorsNetworkNews(SINET), 2013(114-115):1-7
[6]Bloom N, KretschmerT, Van Reenen J. Work Life Balance, Management Practices and Productivity∥Freeman, Shaw (ed.).InternationalDifferencesintheBusinessPracticesandProductivityofFirms. The University of Chicago Press,2009
[7]檀學文,吳國寶.福祉框架下時間利用研究進展.經濟學動態,2014(7):151-158
[8] 新莉,殷國俊.2008年時間利用調查結果簡介.國家統計局網站(http:∥www.stats.gov.cn),2008-11-21
[9]Carroll R J, RuppertD, StefanskiL A, et al.MeasurementErrorinNonlinearModels:AModernPerspective, 2nd edition. Boca Raton, Florida: Chapman and Hall CRC Press, 2006
[10]Kipnis V, Midthune D, Buckman D W. Modeling Data with Excess Zeros and Measurement Error: Application to Evaluating Relationships between Episodically Consumed Foods and Health Outcomes.Biometrics, 2009(65): 1003-1010
[11]Bourdieu P.Distinction. London: Routledge and Kegan Paul, 1984
[12]Gershuny J. Too many zeros: a method for estimating long-term time-use from short diaries.AnnalsofEconomicsandStatistics,2012(105/106): 247-271
Enhancing Individual Representativeness:Predicting Long-term Time Use Based on Diary Data
Tan Xuewen
AbstractAs for problems of weak sample representativeness and “too many zeros” in statistical sense, this paper uses two-part modeling methods of existing literature to predict long-term data from diary time use data. The results show that, the predicted outcomes of long-term time use are statistically robust and more evenly distributed. Moreover, the large-extent reduction of “too many zeros” problems can be realized at the same time, which helping clearing a major obstacle involving in the time use of empirical analysis. Hence, there is no doubt that adding questions like non-recurring event participation frequency in the future time use survey, would improve the efficiency of the utilization of the time use data.
Key wordsTime use; Well-being; Social indicators; Prediction
(責任編輯:陳世棟)
[作者簡介]本文是中國社會科學院創新工程項目“中國農民福祉研究”的部分成果。 檀學文,中國社會科學院農村發展研究所副研究員,郵編:100732。
[收稿日期]2015-06-14
①吳國寶研究員組織創新團隊成員對論文進行了討論,譚清香和楊穗專門提出了修改建議,特此表示感謝。
