專利中基于語義角色的術(shù)語相似度計算方法
2016-05-03 13:12:05姜利雪蔡東風(fēng)
中文信息學(xué)報 2016年4期
姜利雪,季 鐸,蔡東風(fēng)
(沈陽航空航天大學(xué) 知識工程研究中心,遼寧 沈陽 110136)
專利中基于語義角色的術(shù)語相似度計算方法
姜利雪,季 鐸,蔡東風(fēng)
(沈陽航空航天大學(xué) 知識工程研究中心,遼寧 沈陽 110136)
術(shù)語是由一個到多個單詞按照某種語義角色組合而成的,傳統(tǒng)的基于統(tǒng)計的相似度計算方法,將術(shù)語看作一個基本單元來進行計算,忽略了術(shù)語內(nèi)部的語義角色,且對于上下文信息不豐富的術(shù)語,無法利用統(tǒng)計的方法取得理想的效果;基于語義資源的相似度計算方法,所涵蓋的詞語有限,因此不包含在語義資源中的術(shù)語便無法計算相似度。針對這些問題,該文針對專利提出了基于語義角色的術(shù)語相似度計算方法,該方法彌補了傳統(tǒng)方法的不足。該文對術(shù)語內(nèi)部的單詞進行語義角色標(biāo)注,通過共享最近鄰方法計算單詞的相似度,然后根據(jù)不同的語義角色,利用單詞相似度來計算術(shù)語相似度。實驗表明,該方法與傳統(tǒng)方法相比,取得了較好的效果。
術(shù)語;內(nèi)部語義角色;共享最近鄰;術(shù)語相似度;專利文本
1 引言
隨著科學(xué)技術(shù)的不斷發(fā)展,各種專利不斷涌現(xiàn),術(shù)語作為科技發(fā)明成果的載體也隨之增多。如何能夠在海量的術(shù)語中,正確的計算術(shù)語之間的相似度,準(zhǔn)確的找到相似的術(shù)語,這在術(shù)語的理解,同義詞擴展查詢,術(shù)語翻譯等領(lǐng)域起著重要作用。從語言學(xué)的觀點看術(shù)語,單詞是術(shù)語的構(gòu)成材料,術(shù)語則是由這些構(gòu)成材料形成的產(chǎn)品,因此可以說,一切術(shù)語都是由單詞構(gòu)成[1]。那么,術(shù)語的相似度可由單詞的相似度得到。單詞相似度的計算方法有兩種: 基于統(tǒng)計的詞語相似度計算方法和基于語義資源的詞語相似度計算方法。
基于統(tǒng)計的詞語相似度計算方法,一般是利用詞語的上下文環(huán)境作為詞語的特征來計算相似度。基于統(tǒng)計的詞語相似度計算方法歷史悠久,早在1993年Dagan I[2]就提出在大規(guī)模語料庫中,使用詞的上下文特征可以較好的計算詞語之間的相似度。后人的很多研究都是針對這種相似度計算方法進行研究和改進,2003年E Terra[3]對不同長度的上下文進行了實驗,實驗表明,上下文的尺寸對相似度結(jié)果具有很大的影響,上下文窗口越長相似度計算的準(zhǔn)確率越低。2009年于水等[4]引入模糊數(shù)學(xué)中隸屬函數(shù)的概念計算詞語上下文信息的模糊重要度,提出了一種基于語境的詞語相似度計算方法。
基于統(tǒng)計的相似度計算方法,是一種無監(jiān)督的機器學(xué)習(xí)方法,完全根據(jù)所選擇的語料進行相似度計算,計算結(jié)果具有客觀性,且無需大量人力編寫規(guī)則等,其通用性強。但是,該方法卻受限于所使用的語料庫,這樣難以避免由于數(shù)據(jù)稀疏問題所導(dǎo)致的詞語相似度計算不準(zhǔn)確的問題[4],而且該方法所使用的語料大都是通用領(lǐng)域的文本,所使用的單詞專業(yè)性不強,所以在大規(guī)模語料中,其上下文可以很好的表達單詞,相似度計算結(jié)果也較為理想。但是對于專利文本,其用詞較為單一,而且對于新產(chǎn)生的術(shù)語,其上下文信息不豐富,所以利用基于統(tǒng)計的方法來計算術(shù)語相似度,并不能得到很好的效果。
基于語義資源的相似度計算方法,主要依靠語義資源庫,由于考慮到了詞語的語義信息,相似度計算更具準(zhǔn)確性。現(xiàn)在比較常用的語義資源有WordNet、維基百科、《同義詞詞林》和《知網(wǎng)》等,現(xiàn)在許多語義相似度計算方法都是基于這些語義資源所實現(xiàn)的。1999年,王斌[5]根據(jù)《同義詞詞林-擴展版》將所有的詞組織在一棵或幾棵樹狀的層次結(jié)構(gòu)中這一特點,利用兩個節(jié)點之間的路徑長度作為兩個概念的語義距離的一種度量。2002年劉群[6]首次利用《知網(wǎng)》來進行語義相似度計算,他提出了把兩個詞語之間的相似度問題歸結(jié)到兩個概念之間的相似度問題,概念相似度計算歸結(jié)到義原的相似度計算。2008年,丁林林[7]通過引入義原在義原樹中的層次信息和知網(wǎng)中的語義框架等信息對概念間的相似度、相關(guān)度計算方法進行了改進。2010年田久樂[8]根據(jù)《同義詞詞林-擴展版》的編碼及結(jié)構(gòu)特點,提出了一種基于同義詞詞林的詞語相似度計算方法。2013年P(guān)ilehvar[9]把WordNet表示成是一個有向圖,利用RankPage算法在“WordNet”中進行隨機行走,生成語義簽名的方法,以此來計算兩個單詞之間的相似度。
基于語義資源的相似度計算方法,簡單有效,也比較直觀,易于理解,但是該方法得到的結(jié)果受人的主觀意識影響較大,不能反映客觀事實[6],而且這些語義資源庫多數(shù)是由人為編寫,所涵蓋的詞語具有一定的局限性,因此不包含在語義資源中的詞語,便無法計算相似度。相比于普通的詞語,術(shù)語具有專業(yè)性,許多術(shù)語并沒有涵蓋在語義資源中,因此,基于語義資源的相似度計算方法也并不能很好的計算術(shù)語的相似度。
考慮到上述問題,針對專利文本,本文提出了一種基于內(nèi)部語義角色的術(shù)語相似度計算方法,在對術(shù)語進行分詞之后,對每條術(shù)語內(nèi)部的單詞進行語義角色標(biāo)注,然后通過共享最近鄰的方法計算各個單詞之間的相似度,最后兩個術(shù)語的相似度即為每類語義角色內(nèi)的單詞的相似度的加權(quán)求和。實驗表明,利用本文所提出的方法來計算術(shù)語相似度,相比于傳統(tǒng)的基于統(tǒng)計的和基于語義資源方法,效果有明顯的提高。
本文所做的工作有: ①提出了一種基于共享最近鄰的單詞相似度計算方法,用來彌補基于統(tǒng)計的單詞相似度計算方法由于數(shù)據(jù)稀疏所導(dǎo)致的相似度計算不準(zhǔn)確的問題;②根據(jù)前人對術(shù)語的研究和詞組型術(shù)語的特點,總結(jié)了12種語義角色,對詞組型術(shù)語內(nèi)部進行語義角色標(biāo)注;③提出了基于內(nèi)部語義角色的術(shù)語相似度計算方法,即對詞組型術(shù)語內(nèi)部單詞進行語義角色標(biāo)注,根據(jù)語義角色,利用單詞的相似度來計算術(shù)語的相似度。
2 研究背景
2.1 術(shù)語
術(shù)語是科技文獻中用來表達專業(yè)詞語的一種詞匯,集中承載著特定領(lǐng)域的核心知識,對于科技信息的傳播與交流有著重要的作用。本文對66 905篇已經(jīng)經(jīng)過分詞的漢語專利文本進行統(tǒng)計,每篇專利文本的摘要和權(quán)利要求部分的平均長度為812個單詞,平均包含59個術(shù)語。在所統(tǒng)計的術(shù)語中,各個長度的術(shù)語所占的比例如表1所示。

表1 各長度術(shù)語所占的比例
由表1可以看出,術(shù)語長度多在1—5個單詞之間,長度為1的術(shù)語僅包含一個單詞為單詞型術(shù)語,長度大于2的為詞組型術(shù)語,詞組型術(shù)語占據(jù)了整個術(shù)語的80%。
2.2 術(shù)語語義角色體系
由2.1節(jié)可知,詞語型術(shù)語占據(jù)了整個術(shù)語系統(tǒng)的80%左右,所以若能對詞組型術(shù)語進行深入的研究,對我們了解術(shù)語有很大的幫助。詞組型術(shù)語由多個單詞構(gòu)成,各個單詞之間存在一定的語義角色,若對術(shù)語內(nèi)部進行語義角色標(biāo)注,對術(shù)語的分析有很好的幫助作用。
《知網(wǎng)》定義了16種義原關(guān)系和76種動態(tài)角色,清華大學(xué)從《知網(wǎng)》中定義的動態(tài)角色中歸納總結(jié)了59種義原關(guān)系并實現(xiàn)了一個語義分析系統(tǒng),并將該系統(tǒng)應(yīng)用到語音識別中,取得了很好的效果。陳小芳根據(jù)術(shù)語的特點定義了14種語義關(guān)系,并將其運用到機器翻譯中,同樣取得了很好的效果[10]。
本文在陳小芳等[10]研究的啟發(fā)下,將語義信息運用到術(shù)語相似度計算中。我們根據(jù)已有的研究和詞組型術(shù)語中單詞的組成特點,定義了12類語義角色,包括否定、外觀、類別、方式、技術(shù)、性能、作用、使用者、關(guān)系、受事、材料和中心詞。如表2所示。
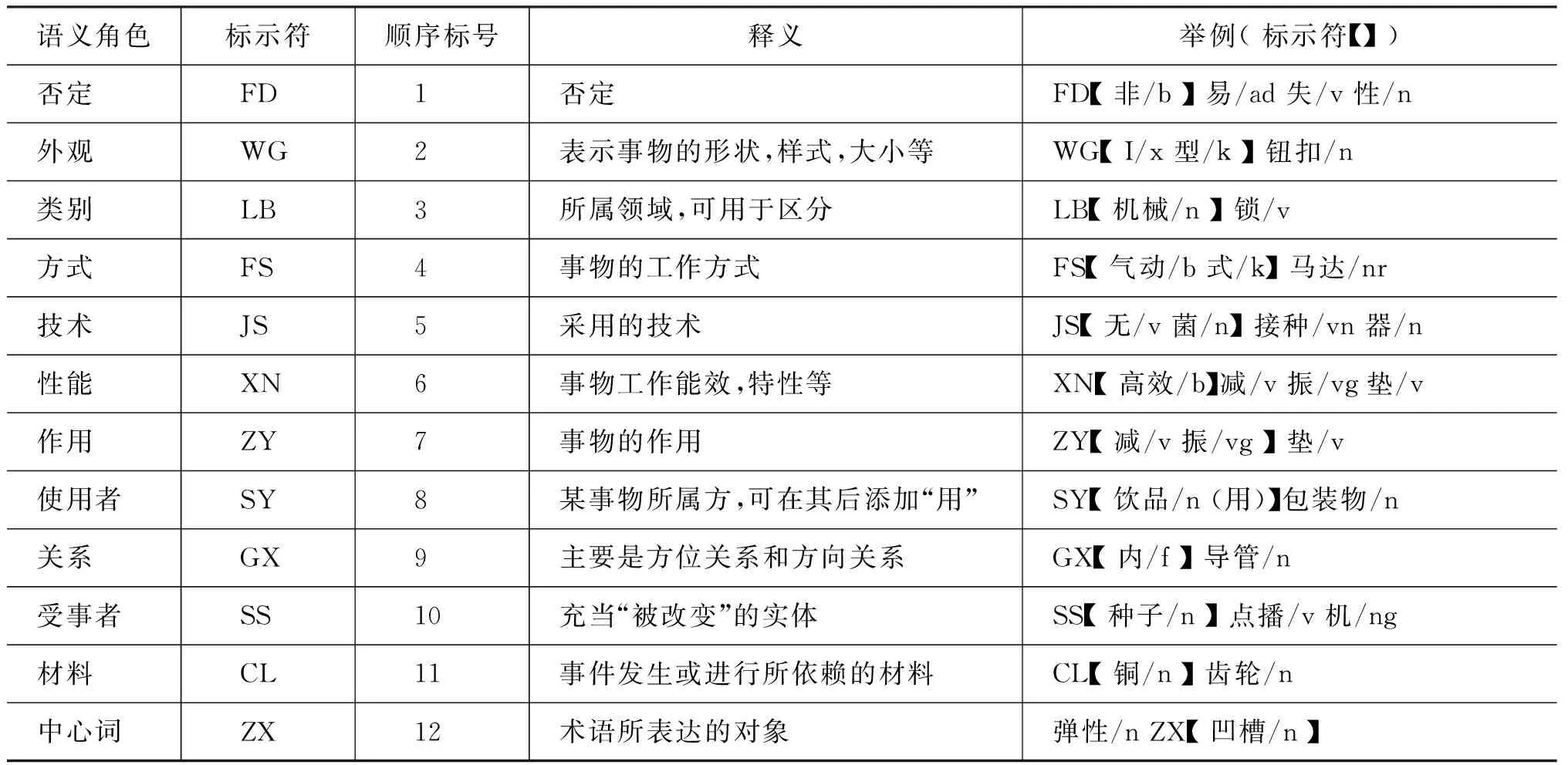
表2 語義角色類、釋義及舉例
本文對含有語義角色的18 744條詞組型術(shù)語進行統(tǒng)計,由于每條術(shù)語都包含中心詞,除中心詞以外的其余11類語義角色所占的比例如圖1所示。可以看出,“ZY”、“SY”、“SS”和“FS”這四類語義角色所占的比例較大,其余七類所占的比例很小。
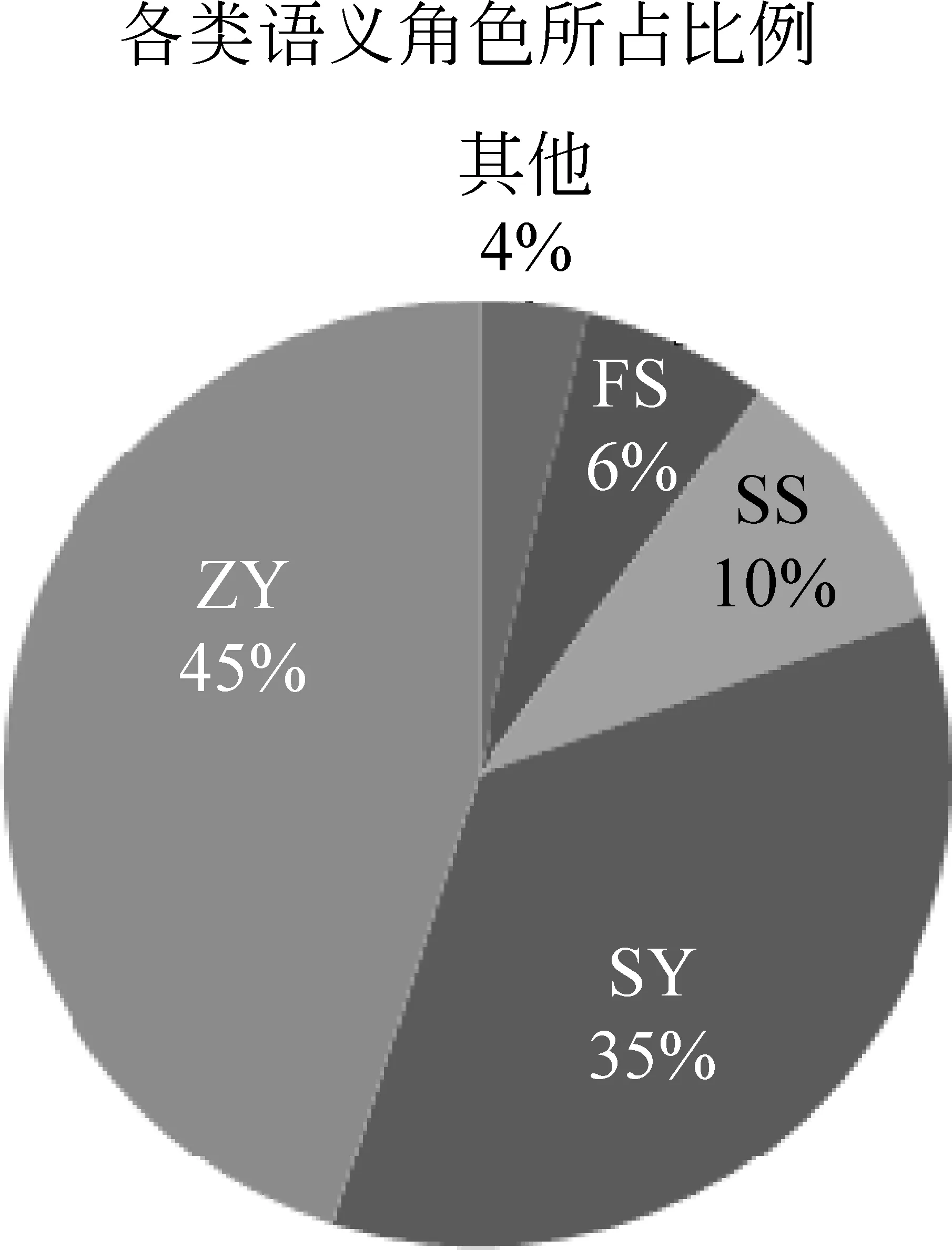
圖1 語義角色比例
本文利用CRF++對詞組型術(shù)語進行機器自動標(biāo)注語義角色,12類語義角色標(biāo)注的準(zhǔn)確率均在50%以上,其中,“FD”、“SY”、“SS”、“ZY”和“ZX”這五類語義角色的標(biāo)注準(zhǔn)確率在80%以上。同時,術(shù)語內(nèi)部的全部單詞都可以利用這12類語義角色進行分類標(biāo)注。
2.3 基于共享最近鄰的詞語相似度計算方法
基于統(tǒng)計的詞語相似度計算方法,最為常用的計算方法是向量空間模型(VSM: Vector Space Model),把單詞的特征處理為向量空間中的向量運算,以空間上的相似度表示詞語的語義相似度[10-11]。但是該方法要依賴于所使用的語料庫,這樣難以避免由于數(shù)據(jù)稀疏問題所導(dǎo)致的相似度計算不準(zhǔn)確的問題。
為了解決相似度計算不準(zhǔn)確問題,我們在VSM的基礎(chǔ)上提出了基于共享最近鄰的詞語相似度計算方法。共享最近鄰(SNN: Shared Nearest Neighbor)是Levent Ertoz[12-13]提出的一種聚類算法,它通過使用數(shù)據(jù)點間共享最近鄰的個數(shù)作為相似度來處理變密度簇的問題。
根據(jù)這種原理,我們提出了基于共享最近鄰的單詞相似度計算方法,即認為通過VSM方法計算得到的詞A的相似度結(jié)果為詞A的鄰居,通過計算詞A和詞B的鄰居的相似度,來對A和B的原始相似度進行懲罰,若兩者含有較多的共同的鄰居,則懲罰相對較小,反之,懲罰較大,然后選擇一定的閾值對相似度結(jié)果進行過濾,以此來提高相似度計算的準(zhǔn)確性。主要計算步驟如下。
首先對專利語料進行分詞、去除停用詞等預(yù)處理操作之后,利用VSM模型計算單詞相似度。
然后利用基于共享最近鄰進行相似度計算。通過計算兩個詞語A和B的鄰居之間的相似度,對A與B的原始相似度sim′(A,B)進行懲罰,計算如式(1)所示。其中,sim(A,B)為進行懲罰之后的相似度,sim(NA,NB)為A和B鄰居之間的相似度,計算如式(2)所示。在sim(NAi,NBj)中,NAi為A的第i個鄰居,NBi為B的第j個鄰居。
(1)
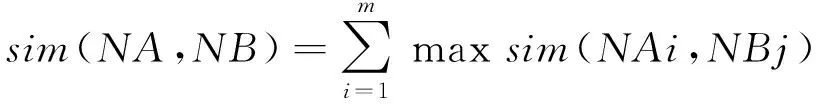
(2)
(j=0,1,…,n)
在對相似度進行懲罰之后,選擇閾值β對詞的鄰居進行過濾,對相似度大于β的鄰居予以保留,相似度小于β的鄰居進行丟棄,以此更新鄰居,在本文中β取值0.09,計算如式(3)所示。
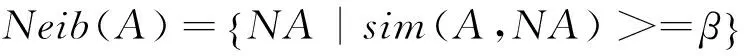
(3)
3 基于內(nèi)部語義角色的術(shù)語相似度計算方法
本文根據(jù)術(shù)語的特點提出了一種基于內(nèi)部語義角色的術(shù)語相似度計算方法,該計算方法主要分為以下幾步: (1)語義角色標(biāo)注;(2)術(shù)語相似度計算。術(shù)語的相似度由組成術(shù)語的單詞的相似度計算得到,實例如圖2所示。
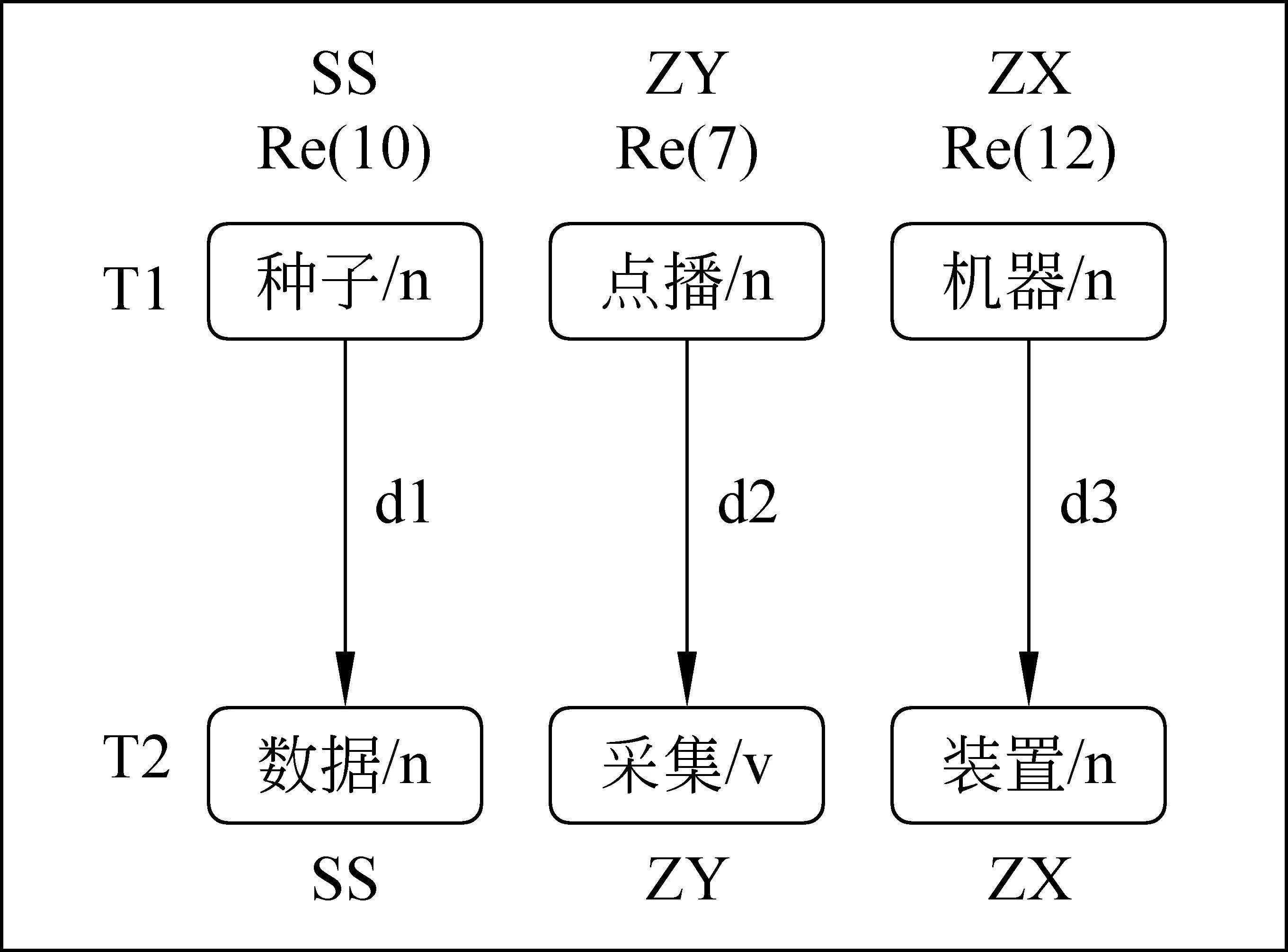
圖2 術(shù)語相似度計算舉例
其中,“SS”、“ZY”和“ZX”分別表示“受事”、“作用”和“中心詞”語義角色, Re (10)表示“受事”類語義角色的權(quán)重,以此類推,d1代表單詞“種子”和“數(shù)據(jù)”的相似度,以此類推。則術(shù)語“種子點播機器”與“數(shù)據(jù)采集裝置”的相似度即為 Re (10)/τ×d1+Re(7)/τ×d2+Re (12)/τ×d3,其中τ=Re (10)+Re (7)+Re (12)為歸一化因子。
3.1 術(shù)語語義角色標(biāo)注

圖3 術(shù)語語義標(biāo)注示例
3.2 術(shù)語相似度計算方法
術(shù)語是由多個單詞組成,要計算術(shù)語之間的相似度,首先需要知道各個單詞之間的相似度。由于語義資源庫涵蓋詞語有限,且專利中的單詞多具有專業(yè)性,所以基于語義資源的相似度計算方法并不能得到很好的效果,因此我們利用2.3節(jié)中提出的基于共享最近鄰的方法來計算單詞相似度。
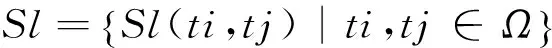
接下來,我們需要對兩個含有語義角色標(biāo)注的術(shù)語T1和T2進行相似度計算,本節(jié)中的單詞相似度均從集合Sl中獲得。
首先計算兩個術(shù)語中具有相同語義角色的單詞的相似度,得到的相似度要根據(jù)不同的語義角色乘以歸一化后的角色權(quán)重。
最后兩個術(shù)語的相似度即為每類相似度的求和。在計算時,若T1中的當(dāng)前詞W在Ω中不存在,或者是在Ω中,W與T2中的詞不具有相似度,那么詞W與T2中的詞的相似度賦值為0.10。示例如圖4所示。
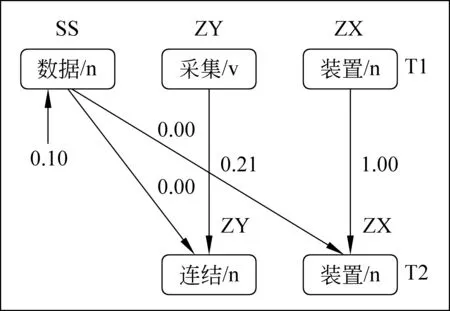
圖4 術(shù)語內(nèi)部相似度計算實例
圖4中,首先分別計算具有相同語義角色“ZX”和“ZY”的單詞的相似度,即“裝置”和“裝置”的相似度,乘以“ZX”語義類的歸一化權(quán)重;“采集”和“連結(jié)”的相似度,乘以“ZY”語義類的歸一化權(quán)重。然后,由于“SS”類語義角色,在T2中不存在,則分別計算“數(shù)據(jù)”與“連結(jié)”、“裝置”的相似度,但是由于在單詞相似度集合Sl中,“數(shù)據(jù)”與“連結(jié)”和“裝置”不具有相似度,則他們的相似度為0,那就把“數(shù)據(jù)”的相似度默認賦值為0.10,在乘以“SS”語義類的歸一化權(quán)重,還要乘以一懲罰因子δ。則T1與T2的相似度為 Re (10)/τ×0.10×δ+Re (7)/τ×0.21+Re (12)/τ×1.0其中,τ=Re (10)+Re (7)+Re(12)。
4 實驗
4.1 實驗準(zhǔn)備
本實驗選擇1.8G大小的中文專利語料,通過術(shù)語抽取系統(tǒng)抽取術(shù)語,并選擇出現(xiàn)頻數(shù)大于100的18 744條詞組型術(shù)語作為實驗對象,利用中國科學(xué)院分詞工具“NLPIR漢語分詞系統(tǒng)”進行分詞,然后進行語義角色標(biāo)注。
4.2 評測方法
由于現(xiàn)在沒有可利用的術(shù)語同義詞詞林,因此,我們組織14名具有自然語言處理知識的人員對187 440條詞組型術(shù)語進行分類,將具有同義性的術(shù)語組織到一類中,構(gòu)建適用于術(shù)語的同義詞詞林。評測方法為信息檢索領(lǐng)域常用的一種系統(tǒng)性能測試指標(biāo)F值。
我們規(guī)定,對于術(shù)語Tj,通過相似度計算方法得到的鄰居中的任一術(shù)語t,若在術(shù)語同義詞詞林中t與Tj屬于同一類,則認為術(shù)語t是Tj正確的鄰居,即為1,否則即為0。則術(shù)語Tj的準(zhǔn)確率P(Tj)為,Tj的鄰居NebTj中正確的鄰居的個數(shù)除以NebTj中鄰居的總數(shù)MTj,平均準(zhǔn)確率P為所有術(shù)語的準(zhǔn)確率總和的均值,見式(4);術(shù)語Tj的召回率R(Tj)為Tj的鄰居NebTj中正確的鄰居的個數(shù)除以術(shù)語同義詞詞林中與Tj所屬同一類的所有術(shù)語的總數(shù)M,平均召回率R即為所有術(shù)語的召回率總和的均值,見式(5),其中N為術(shù)語的總條數(shù);平均F值,見式(6)。
(4)
(5)
(6)
4.3 實驗介紹
(1) 術(shù)語語義角色標(biāo)注實驗
隨著煤礦井下綜采裝備的自動化水平提高,煤礦井下掘進效率低下導(dǎo)致的采掘失衡問題日益突出[1-2]。前期研究發(fā)現(xiàn)國內(nèi)外在掘進機的自動化和智能化控制方面取得了很大進展[3],但由于受煤礦井下環(huán)境限制,掘進機的精確定位仍未解決,限制著掘進機的智能化發(fā)展。目前國內(nèi)大多數(shù)煤礦依然需要人工操作,這就導(dǎo)致掘進效率低下。 由于掘進過程中粉塵濃度大、光線差等環(huán)境惡劣,導(dǎo)致司機視野受限不能準(zhǔn)確判斷截割頭在截割斷面的位置,從而容易導(dǎo)致超挖欠挖、不能保證巷道成形的質(zhì)量。
利用3.1節(jié)中人工3 000條術(shù)語作為實驗對象,將該語料平均分為十組,每組300條。利用十折交叉驗證,即輪流用九組作為訓(xùn)練語料,剩余一組作為測試語料,利用CRF++0.58對測試語料進行語義標(biāo)注。通過計算各個語義角色標(biāo)注的平均準(zhǔn)確率,以證明本文提出的語義角色體系的可用性。
(2) 通過不同的單詞相似度計算方法計算術(shù)語相似度實驗
分別利用基于《知網(wǎng)》[7],VSM和通過共享最近鄰方法計算單詞相似度,然后利用三種方法得到的單詞相似度來計算術(shù)語相似度。
(3) 術(shù)語相似度計算方法比較實驗
分別利用以下三種方法對18 744條詞組型術(shù)語進行相似度計算: ①“VSM”方法,即把術(shù)語作為一個基本單位,利用其在專利文本中的上下文作為特征來計算術(shù)語相似度;②共享最近鄰方法,即把術(shù)語作為一個基本單位,在通過“VSM”得到的結(jié)果基礎(chǔ)之上加入鄰居的信息來計算術(shù)語相似度;③基于內(nèi)部語義角色的術(shù)語相似度計算方法。對比三種方法得到術(shù)語相似度的效果。
根據(jù)各個語義角色所占的比例,我們可以知道,“ZY”、 “SY” “SS”、“FS”和“ZY”以上五類語義角色對相似度計算所起的作用較大,其余七類所起的作用較小,因此在選擇語義權(quán)重時,我們僅對以上五類語義角色的權(quán)重取平均,其余七類的權(quán)重保持初始值不變,初始權(quán)重為各個語義角色所占比例。
4.4 實驗結(jié)果
(1) 術(shù)語語義角色標(biāo)注實驗
各個語義角色的標(biāo)注準(zhǔn)確率如表3所示。
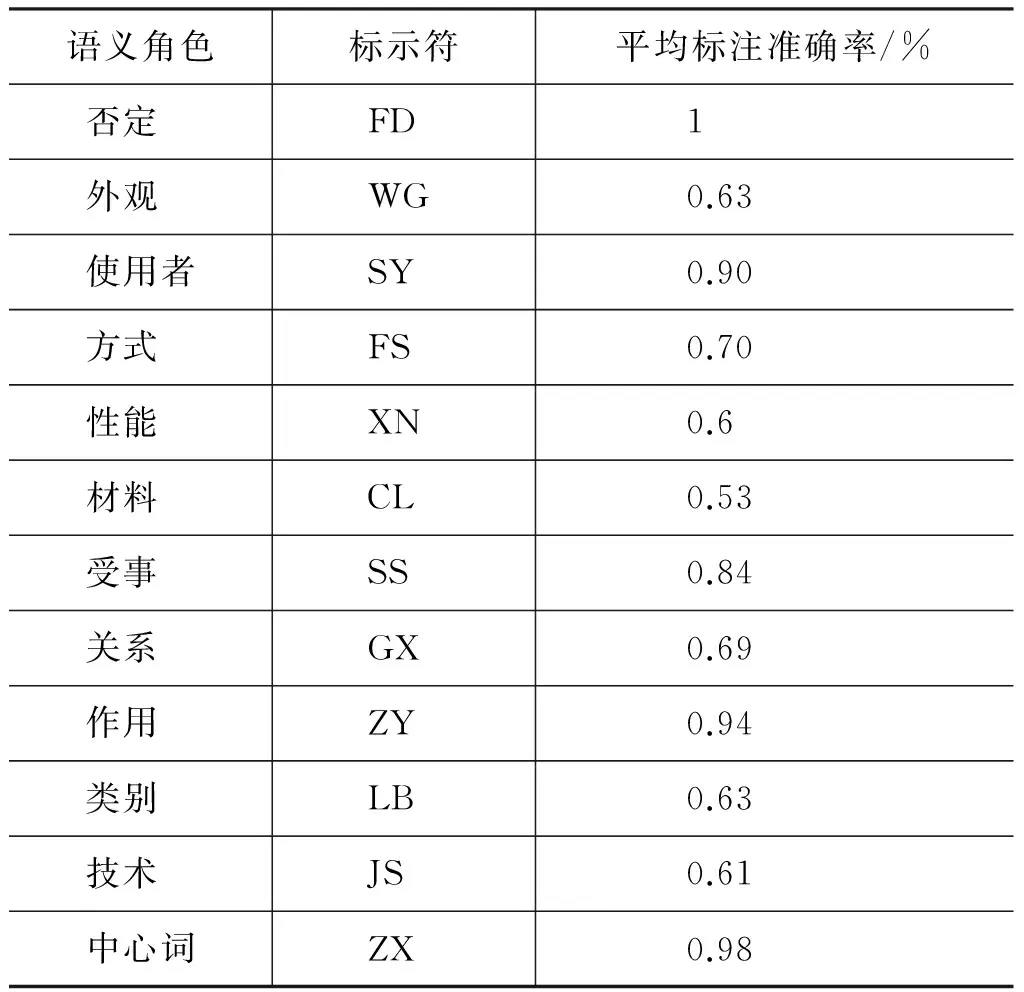
表3 語義角色機器標(biāo)注結(jié)果
由表3可以看出,在各類語義角色中,“FD”、“SY”、“SS”、“ZY”和“ZX”這五類語義角色的標(biāo)注準(zhǔn)確率在80%以上,其中 “CL”這類標(biāo)注準(zhǔn)確率在60%以下,通過觀察發(fā)現(xiàn)導(dǎo)致這類準(zhǔn)確率低的原因主要有以下兩點。
首先,“CL”與“SY”這兩類語義角色的結(jié)構(gòu)非常相似,“SY”語義類的組成結(jié)構(gòu)多為“名詞+名詞”,例如“催化劑/n 載體/n”,其中第一個名詞多為“SY”類,第二個名詞為“ZX”類。但是對于例如像“鋁/n 基線路板/n”這一類術(shù)語的組成結(jié)構(gòu)同樣為“名詞+名詞”,但是“鋁/n”卻不屬于“SS”類,這種結(jié)構(gòu)類似的術(shù)語會導(dǎo)致標(biāo)注錯誤。其次,由于訓(xùn)練語料不充足,會導(dǎo)致數(shù)據(jù)稀疏問題,這也會導(dǎo)致標(biāo)注錯誤。
(2) 通過不同的單詞相似度計算方法計算術(shù)語相似度實驗
實驗結(jié)果如圖5所示。
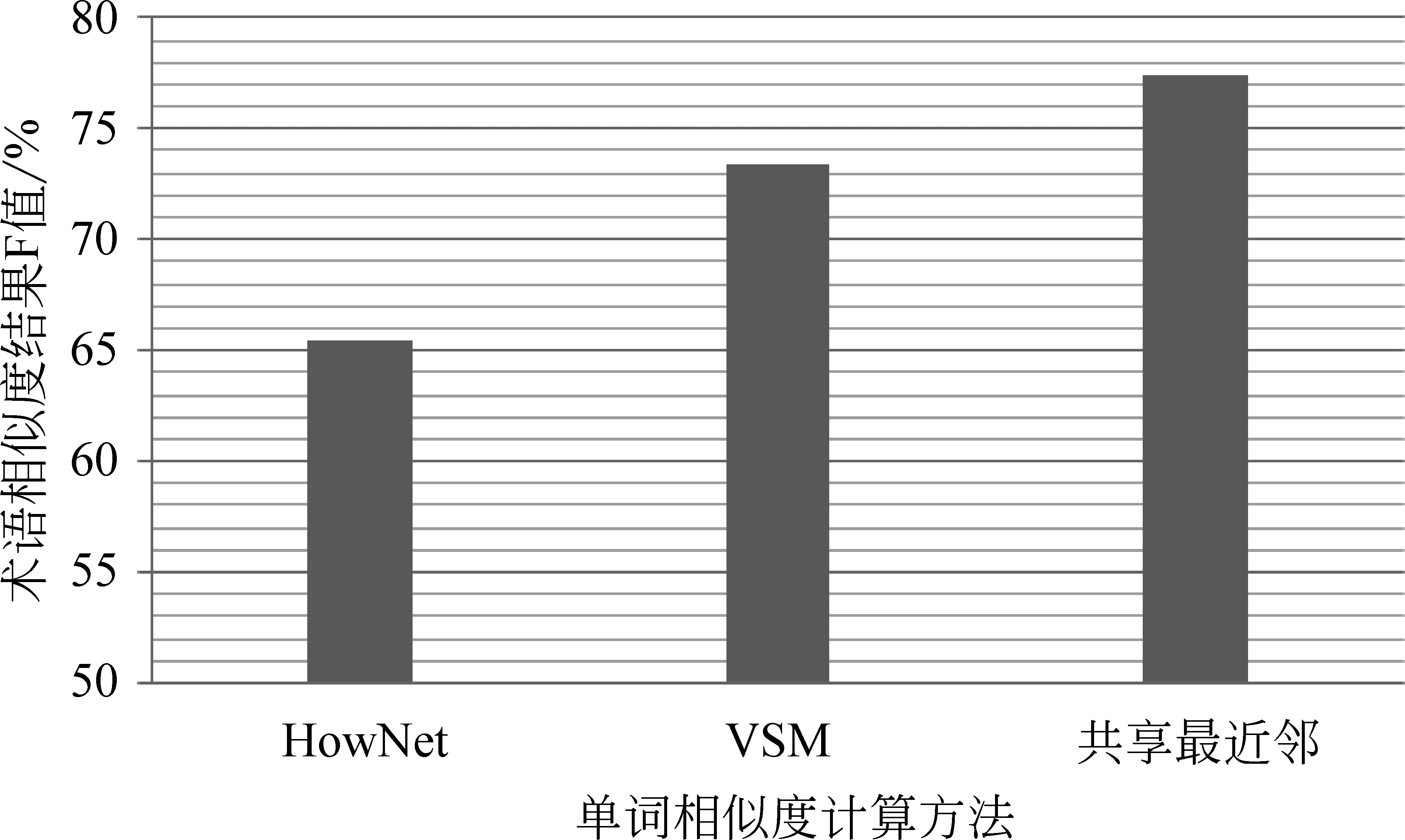
圖5 三種單詞相似度計算方法效果比較
由圖5可以看出,“VSM”方法得到的F值要比“HowNet”得到的F值高,主要原因是,“VSM”方法是利用單詞在大量專利文本中的上下文作為特征來計算相似度的,其所得到的結(jié)果更符合專利文本中的術(shù)語,而《知網(wǎng)》中的單詞是面向通用領(lǐng)域的,并不能很好的適用于專利文本。因為“共享最近鄰”方法是在“VSM”的基礎(chǔ)上加入了鄰居的信息來進行改進,所以得到的效果比單純使用“VSM”方法有所提高。
(3) 術(shù)語相似度計算方法比較實驗
我們利用三種方法計算術(shù)語相似度,然后比較結(jié)果。實驗結(jié)果如圖6所示。
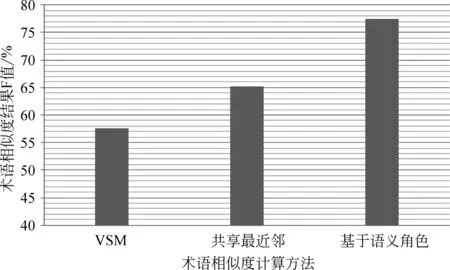
圖6 三種術(shù)語相似度計算方法效果比較
由圖6可以看出,通過“VSM”方法計算得到的F較低,主要原因是,專利文本格式較為統(tǒng)一,術(shù)語的上下文信息并不能完整的表達其含義,而且對于一些新產(chǎn)生的術(shù)語,其上下文信息并不豐富,所以利用“VSM”方法得到的效果并不理想。共享最近鄰方法是在“VSM”方法的基礎(chǔ)上進行改進的,能夠在一定程度上縮減由于數(shù)據(jù)稀疏等問題造成的相似性計算不準(zhǔn)確的問題。基于內(nèi)部語義角色的相似度計算方法,沒有利用術(shù)語不豐富的上下文,而是加入了語義角色的信息,根據(jù)語義角色,通過單詞的相似度來計算術(shù)語的相似度,效果與其它兩種方法相比有很大提升。
5 結(jié)論與展望
專利文本較普通文本而言,用詞較為單一,所使用的詞語多具有專業(yè)性,基于統(tǒng)計的和基于語義詞典的相似度計算方法不能很好的對術(shù)語進行相似度計算,考慮到這一問題,本文結(jié)合術(shù)語本身的語義結(jié)構(gòu)特征,提出了一種適合術(shù)語的相似度計算方法——基于內(nèi)部語義角色的術(shù)語相似度計算方法。我們所提出的方法能夠很好的解決傳統(tǒng)的基于統(tǒng)計的方法由于數(shù)據(jù)稀疏所導(dǎo)致的相似度計算不準(zhǔn)確和傳統(tǒng)的基于語義資源的由于語義資源覆蓋不全面而無法計算相似度的問題。
本文所提出的方法,并沒有考慮到術(shù)語的上下文,僅是利用其內(nèi)部語義角色來計算相似度,雖然對于術(shù)語,其上下文信息并不全面,但是若給予考慮,也可對相似度計算提供一定的價值,所以在將來的工作中,我們考慮可以將“VSM”相似度計算方法和基于內(nèi)部語義角色的相似度計算方法進行融合,既考慮上下文信息,又考慮術(shù)語內(nèi)部角色,力求能夠更好的計算詞組型術(shù)語的相似度。
[1] 馮志偉. 術(shù)語形成的經(jīng)濟律——FEL 公式[J]. 中國科技術(shù)語, 2010, 12(2): 9-15.
[2] Dagan I, Marcus S, Markovitch S. Contextual word similarity and estimation from sparse data[C]//Proceedings of the 31st annual meeting on Association for Computational Linguistics. Association for Computational Linguistics, 1993: 164-171.
[3] Terra E, Clarke C L A. Frequency estimates for statistical word similarity measures[C]//Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology-Volume 1. Association for Computational Linguistics, 2003: 165-172.
[4] 蔡東風(fēng), 白宇, 于水, 等. 一種基于語境的詞語相似度計算方法[J]. 中文信息學(xué)報, 2010, 24(3): 24-28.
[5] 王斌. 漢英雙語語料庫自動對齊研究[D]. 中國科學(xué)院博士學(xué)位論文, 1999.
[6] 劉群, 李素建. 基于《知網(wǎng)》的詞匯語義相似度計算[J]. 中文計算語言學(xué), 2002, 7(2): 59-76.
[7] 于林林. 基于知網(wǎng)的漢語詞義消歧方法的研究[D]. 沈陽航空工業(yè)學(xué)院碩士學(xué)位論文, 2008.
[8] 田久樂, 趙蔚. 基于同義詞詞林的詞語相似度計算方法[J]. 吉林大學(xué)學(xué)報: 信息科學(xué)版, 2010 (006): 602-608.
[9] Pilehvar M T, Jurgens D, Navigli R. Align, disambiguate and walk: A unified approach for measuring semantic similarity[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (ACL 2013). 2013.
[10] 陳小芳. 漢語術(shù)語語義分析技術(shù)研究及其應(yīng)用[D]. 沈陽航空航天大學(xué)碩士學(xué)位論文, 2011.
Measuring Term Similarity Based on Internal Semantic Role in Patent Text
JIANG Lixue, JI Duo, CAI Dongfeng
(Knowledge Engineering Research Center, Shenyang Aerospace University, Shenyang, Liaoning 110136, China)
The Chinese term is composed of one or multiple words with certain semantic roles. The traditional similarity calculation methods based on statistics, which regard the term as a basic unit for similarity computation, ignore the semantic roles inside a term. This paper presented a method for computing similarity of Chinese terms based on the internal semantic roles, i.e. calculating term similarity according to the different semantic roles assigned to them automatically. Experiments show that the proposed similarity calculation method achieves better results than traditional methods.
term; internal semantic roles; shared nearest neighbor; term similarity; patent text

姜利雪(1988—),碩士,主要研究領(lǐng)域為自然語言處理。E-mail:jlxsnow@163.com季鐸(1981—),博士,副教授,主要研究領(lǐng)域為自然語言處理。E-mail:jiduo_1@163.com蔡東風(fēng)(1958—),博士,教授,主要研究領(lǐng)域為人工智能,自然語言處理。E-mail:caidf@vip.163.com
1003-0077(2016)04-0037-07
2014-08-20 定稿日期: 2015-05-08
國家“十二五”科技支撐計劃項目(2012BAH14F00)
TP391
A
猜你喜歡
中等數(shù)學(xué)(2022年2期)2022-06-05 07:10:50
小學(xué)生學(xué)習(xí)指導(dǎo)(低年級)(2020年6期)2020-07-25 02:31:36
開放教育研究(2020年2期)2020-03-31 01:54:14
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
小學(xué)生學(xué)習(xí)指導(dǎo)(低年級)(2018年9期)2018-09-26 05:59:44
瘋狂英語·新讀寫(2018年2期)2018-09-07 09:32:10
智慧少年·故事叮當(dāng)(2018年11期)2018-05-14 11:48:18
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學(xué)學(xué)報(2015年2期)2015-02-27 08:28:11
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
