基于復雜網絡理論的漢語復句關系詞搭配網的統計特征研究
2016-05-03 13:00:43劉延申
中文信息學報 2016年4期
胡 泉,謝 芳,李 源,劉延申
(1.華中師范大學 物理學院,湖北 武漢 430079;2.湖北工業大學 計算機學院,湖北 武漢 430068;3.華中師范大學 計算機學院,湖北 武漢 430079)
基于復雜網絡理論的漢語復句關系詞搭配網的統計特征研究
胡 泉1,謝 芳2,李 源3,劉延申1
(1.華中師范大學 物理學院,湖北 武漢 430079;2.湖北工業大學 計算機學院,湖北 武漢 430068;3.華中師范大學 計算機學院,湖北 武漢 430079)
漢語復句關系詞是漢語復句在語表形式上的標記,是復句中標識關系的重要構件,在現代漢語復句研究領域起著關鍵作用。漢語復句關系詞的搭配是指在漢語語篇中兩個或兩個以上的復句關系詞形成的句法共現形式,它不僅影響著分句的語義,而且影響著復句層次關系的劃分。該文利用復雜網絡的理論,基于已獲取的470個復句關系詞構建了一個“現代漢語復句關系詞搭配網絡”。通過對該網絡中的平均路徑長度、聚集系數和度分布等特征的統計,用來發現漢語復句關系詞之間的搭配能力和搭配強度,這些結果能夠幫助復句層次關系和復句邏輯語義的自動識別。
漢語復句關系詞搭配;復雜網絡;平均路徑長度;聚集系數;度分布
1 前言
復雜網絡是從全局的視角來研究復雜系統的新方法,無論網絡的結構多么復雜,規模有多大,它都是采用節點和邊兩大基本要素來研究復雜的網絡系統[1]。
20世紀末,美國康奈爾(Cornell)大學的博士生D J Watts及其導師S H Strogatz于1998年6月在《Nature》上發表了題為Collectivedynarnicsof‘small-world’networks的文章[2]。該文章揭示了小世界特征,并進一步建立了一個小世界網絡模型。美國圣母(Notre Dame)大學物理系的A L Barabasi教授及其博士生R Albert于1999年10月在《Science》雜志上發表了一篇題為Emergenceofscalinginrandomnetworks的論文,進一步揭示復雜網絡的無標度特性,并建立相應的無標度網絡模型[3]。這兩篇文章的發表,使得復雜網絡開始成為數學、物理、生物,以及管理和工程技術人員等各個學科領域的學者們共同研究的新內容、新方法,其研究方法還被稱為“網絡思維”[4-5]。“網絡思維”所關注的不是任何物理事物的本身,而是研究事物之間的聯系,或者說是事物內部及其與外界的各種關系[1,4]。
復雜網絡的研究具有極強的交叉學科特征,目前,復雜網絡已經在各個層面、各個領域都得到了廣泛的應用[1,5-6]。在復雜網絡的研究中,語言網絡作為一個新的研究方向,已經悄然興起[7-9]。早先研究語言網絡的是Cancho和Sole于2001年采用復雜網絡的方法構建了一個英文詞共現的語言網絡[10]。2004年韋洛霞和李勇等構建了一個漢字網絡,研究了該網絡的三度分隔與小世界效應問題[11];2005年又構建了一個漢語詞組網絡,研究了它的組織結構與無標度特性[12];2007年劉知遠和孫茂松采用復雜網絡的方法構建了一個漢語詞同現網絡,研究了該網絡的小世界效應和無標度特性[13];2008年又構建了一個漢語依存句法網絡,研究了它的復雜網絡性質[14]。從此許多語言學家和計算機工作者共同研究了一系列語言網絡,這些研究表明: 人類語言也是人類復雜系統中的一種復雜網絡,盡管各種不同語言網絡的構造原理和構造方法不同,但各種語言網絡都具有類似的統計特性[9-21]。
上述這些研究都是選取一種語言中的部分字和詞構造一個復雜網絡,帶有一定的驗證性,均未涉及到某種完整的詞庫或者句子。目前,中文信息處理正面臨著句處理和篇章處理的研究難題,在“句處理”方面,主要分為單句處理和復句的處理。現在研究漢語單句信息處理的成果較多,然而復句是連接單句與篇章的橋梁,是漢語語法的重要實體單位,它表達的語義信息豐富而復雜,因而在信息處理領域具有更加重要的研究價值[22]。
關系詞是復句、句群或語篇中用來連接句子表明邏輯關系的詞語,是句子間的邏輯語義關系的重要標志之一,在句法結構分析中具有形式上和語義上的雙重作用[22-23]。
從1957年英國語言學家Firth正式將搭配(collocation)作為語言學術語提出至今,經過近60年的研究積累和完善,搭配已發展為一個重要的語言學概念和研究領域[24]。
漢語復句關系詞的搭配是漢語語篇中兩個或兩個以上的復句關系詞形成的句法共現,它是復句中用來聯結分句、標明分句間語義關系并形成復句句式的標記成分,是分句間句法關聯和語義關系的形式標志。漢語復句關系詞的搭配不僅影響著分句的語義,而且影響著復句層次關系的劃分[25]。研究發現,漢語篇章中絕大多數關系詞都具有搭配特性(占86%以上),有些關系詞還只能以搭配的形式存在[26]。
漢語關系詞搭配的研究具有很高的應用價值: 關系詞搭配的研究在對外漢語教學、機器翻譯、信息檢索、詞義消岐和情感分析等各個方面的應用都具有非常重要的意義[25-27]。
本文基于復雜網絡的理論和研究方法對漢語復句關系詞的搭配關系進行研究,在 “漢語復句關系詞本體知識庫”的基礎上[28],抽取其中470個搭配關系詞構建了一個現代漢語“復句關系詞搭配網”,并對該網絡的平均路徑長度、聚集系數和度分布等三個基本統計特性進行分析研究。研究表明: 現代漢語復句關系詞搭配網絡不僅是一個典型的復雜網絡,而且這些統計特性反映了復句關系詞的搭配能力和搭配對象之間的強弱關系,它們是深入研究現代漢語復句關系詞、復句層次關系和復句邏輯語義的自動識別與處理的重要基礎[25-26]。
2 現代漢語復句關系詞搭配網絡
定義1 在漢語中,能構成句法搭配的關系詞稱為“搭配關系詞”(或稱“搭配關系標記”),如“不但…而且…”是一組搭配關系詞,“只有…才能…”和“除非…否則…”都是搭配關系詞;在關系詞之間的搭配行為稱作“關系詞搭配”(或稱“關系標記搭配”),研究“關系詞搭配”,即發掘關系詞搭配的機制與規律;設wi、wj∈W,W={wj|wj是復句關系詞,j∈N},若D={
定義2 搭配關系詞對
一個實際的網絡可以形式化抽象為一個由節點集V和邊集E組成的圖形,即G=(V,E),其中,V中的元素稱為節點(vertex),節點數為N=|V|;E中的元素稱為邊(edge),邊數為M=|E|;而且E中的每條邊都對應有V中的一對節點(x,y)。[1,29-30]
通過對文獻[28]所介紹的漢語“復句關系詞本體知識庫”中的470個搭配關系詞進行分析、研究,構造了圖1所示的現代漢語復句關系詞搭配網絡。

圖1 470個現代漢語復句關系詞搭配網絡的總體結構圖

圖2 圖1中關系詞節點“接著”的局部放大圖
圖1中,以搭配關系詞為節點,以關系詞的搭配關系為連接邊。根據定義2,任何一對關系詞的搭配關系,都具有前呼標和后應標,所以它們是一種有向網絡,每條邊都是由前呼標指向后應標。例如,“不但”與“而且”是一對搭配關系詞,“不但”是前呼標,“而且”是后應標,于是網絡中的連線是由“不但”指向“而且”,即“不但”-→“而且”。圖1包含有470個漢語復句搭配關系詞的所有節點,以及這些節點之間所具有的3 958條邊,這些節點和邊所構建的網絡是一個非連通的復雜網絡。
由于許多關系詞既可以是前呼標,又可以是后應標,例如,關系詞“但是”,當其作為“前呼標”時,它可以與“反”、“反倒”、“反而”等12個“后應標”搭配;而當關系詞“但是”作為“后應標”時,它又可以和“倒”、“倒是”、“即便”等28個“前呼標”搭配,所以在圖1中,許多關系詞節點既有入度(箭頭指向該節點),又有出度(由它出發指向其他關系詞節點)。例如,圖2為圖1中關系詞節點“接著”的放大圖,由圖2可以看出,關系詞“接著”既有12個入度,又有28個出度。
通過對圖1的分析研究,不僅可以深入挖掘漢語復句關系詞的搭配能力和搭配強度,對于進一步研究復句層次結構的自動識別,以及復句邏輯語義的自動分析均具有重要的應用價值,而且對于復雜網絡的本體和應用研究也將產生促進作用。
3 現代漢語復句關系詞搭配網絡的平均路徑長度
定義3 平均路徑長度(averagepathlength): 復雜網絡中,兩個節點i和j之間的距離dij,定義為該兩個節點之間的最短路徑上的邊數;網絡中任意兩個節點之間的距離的最大值叫做網絡的直徑(diameter),記作D,即
(1)
實際上,D為網絡中任意兩個節點的最短路徑長度。網絡的平均路徑長度,定義為任意兩個節點之間的平均值,即
(2)
其中,n為整個網絡的節點數目[1,5]。

表1 圖1中部分節點的最短路徑長度

續表
通過對圖1進行統計分析,在現代漢語復句關系詞搭配網絡圖中,網絡的直徑D=10,表1給出了圖1中部分節點的最短路徑長度D。由表1可以看出,D為10的路徑有多條,例如,關系詞節點“但是”到“不然”、“從而”、“而不是”、“故”和“結果是”等關系詞節點的最短路徑長度均為10。
根據式(1)和式(2),由圖1可以計算出復句關系詞搭配網中的總路徑長度如式(3)所示。
(3)
由于圖1的節點數是n=470,所以由式(2)得到該網絡的平均路徑長度如式(4)所示。
(4)
現代漢語復句關系詞搭配網絡的路徑長度和平均路徑長度反映了兩個關系詞之間的距離。例如,從表1可以看出,關系詞“但是”與關系詞“便是”之間的距離是7,即“但是”→“卻”→“不料”→“倒”→“基本上”→“是”→“不是”→“便是”。然而關系詞“但是”與“不料”、“倒”、“基本上”、“是”、“不是”和“便是”等六個關系詞均不搭配,它們只是一種間接關系,即關系詞“但是”與關系詞“卻”搭配,關系詞“卻”與關系詞“不料”搭配,關系詞“不料”與關系詞“到”搭配,關系詞“到”與關系詞“基本上”搭配,關系詞“基本上”與關系詞“是”搭配,關系詞“是”與關系詞“不是”搭配,關系詞“不是”與關系詞“便是”搭配。如果關系詞“但是”與關系詞“便是”出現在同一個復句中時,它們可能會跨越多個復句的層次。
現代漢語復句中,兩個關系詞之間的距離體現了復句關系詞的離析度,文獻[25]和文獻[31]討論了離析度在復句關系和層次自動分析中的意義。所以,現代漢語復句關系詞搭配網絡中的路徑長度和平均路徑長度是進一步研究計算機自動識別復句層次關系的一種基本依據。
4 現代漢語復句關系詞搭配網絡的聚集系數
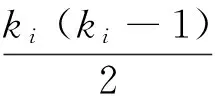
(5)
顯然,Ci=[0,1],即0≤Ci≤1;當ki=1時,Ei=0,只有當ki>1時才有可能Ei>0。
設整個網絡的節點數為n,則整個網絡的聚集系數C即為所有節點的聚集系數Ci(其中i=1,2,3,…,n)的平均值[1,5]。即:
(6)
式(6)中0≤C≤1 。如果當且僅當網絡中所有的節點均為孤立節點時,則C=0,這時整個網絡中沒有任何連接邊;如果當且僅當整個網絡中任何兩個節點都直接相連,則C=1 ,這樣的網絡稱為“全局耦合網絡”[1,5]。
在現代漢語復句關系詞搭配網絡中,聚集系數可以用來度量一個關系詞節點與其相鄰的任意關系詞節點之間產生搭配關系的可能性和搭配強度。
由定義4和式(5)可知,圖1中的470個搭配關系詞構成了470個子網絡,圖3展示了圖1中搭配關系詞節點“但是”與其可能搭配的關系詞節點之間所構成的子網。從圖3可以看出,該子網中有k73=k“但是”=40個的節點數與節點“但是”相連,這40個節點之間存在的實際邊數是E73=E“但是”=74條。于是搭配關系詞“但是”節點的聚集系數如式(7)所示。


(7)

圖3 圖1中搭配關系詞節點“但是”與其可能搭配的40個關系詞節點之間所構成的子網圖
表2給出了圖1中部分子網的節點數ki、實際邊數Ei和相應的聚集系數Ci的值。
表2中,i為圖1中關系詞節點(子網)的編號,Ni為關系詞子網名,ki為相應子網的節點數,Ei為該子網中的實際邊數,Ci為該子網相應的聚集系數值。
根據式(6),在這n=470個節點的“現代漢語復句關系詞搭配網絡”中,整個網絡的聚集系數C就是所有關系詞節點i(i=1,…,470)的聚集系數Ci的平均值,即
(8)

表2 圖1中部分子網的節點數ki、實際邊數Ei和相應的聚集系數Ci的值

續表
在圖1所示的現代漢語復句關系詞搭配網絡中,其平均路徑長度為2.291 9,平均聚集系數為0.175 53,這些數據說明圖1的現代漢語復句關系詞搭配網絡具有典型的“小世界效應”[1]。它體現了漢語“復句關系詞本體知識庫”中的470個搭配關系詞之間的搭配關系都具有較好的搭配能力和大小不同的搭配強度。
5 現代漢語復句關系詞搭配網絡中的度分布
定義5 節點“平均度”: 在復雜網絡中,所有節點i的度ki的平均值就叫做該網絡的節點“平均度”,用
(9)
于是,復雜網絡中節點的度的分布情況就可以采用度分布函數P(K)來刻畫[1,5]。
定義6 度分布函數P(K): 設網絡中一個隨機選定的節點的邊的條數為N,該節點的度為k,于是度分布函數如式(10)所示。
(10)
式(10)中,K表示該節點的度的參數;P(k)的含義是: 網絡中任意一個隨機選定的節點i的度,恰好等于k的概率[1,5]。
在有向網絡中,一個節點的度可以劃分為“入度”(in-degree)和“出度”(out-degree)兩種。所謂節點的入度是指從其他節點指向該節點的邊的數目;所謂節點的出度是指該節點指向其他節點的邊的數目。
由圖1可以統計出470個關系詞節點的總入度值是1 979和總出度值是1 979,合計度數是3 958,這些度值就是網絡中的實際邊數。
根據式(9),圖1中470個關系詞節點i的平均度

(11)
在現代漢語復句關系詞搭配網絡中,平均度
復雜網絡中的度分布概率刻畫了該復雜網絡的“無尺度”現象,利用式(10)可以計算出“現代漢語復句關系詞搭配網絡”中470個節點的度分布概率,這些概率值進一步刻畫了圖1是一種典型的“無尺度語言網絡”。表3給出了圖1中部分復句關系詞節點的度分布數據及其度分布概率值,圖4給出了部分節點的概率分布情況。

圖4 圖1中部分節點的度的概率分布圖
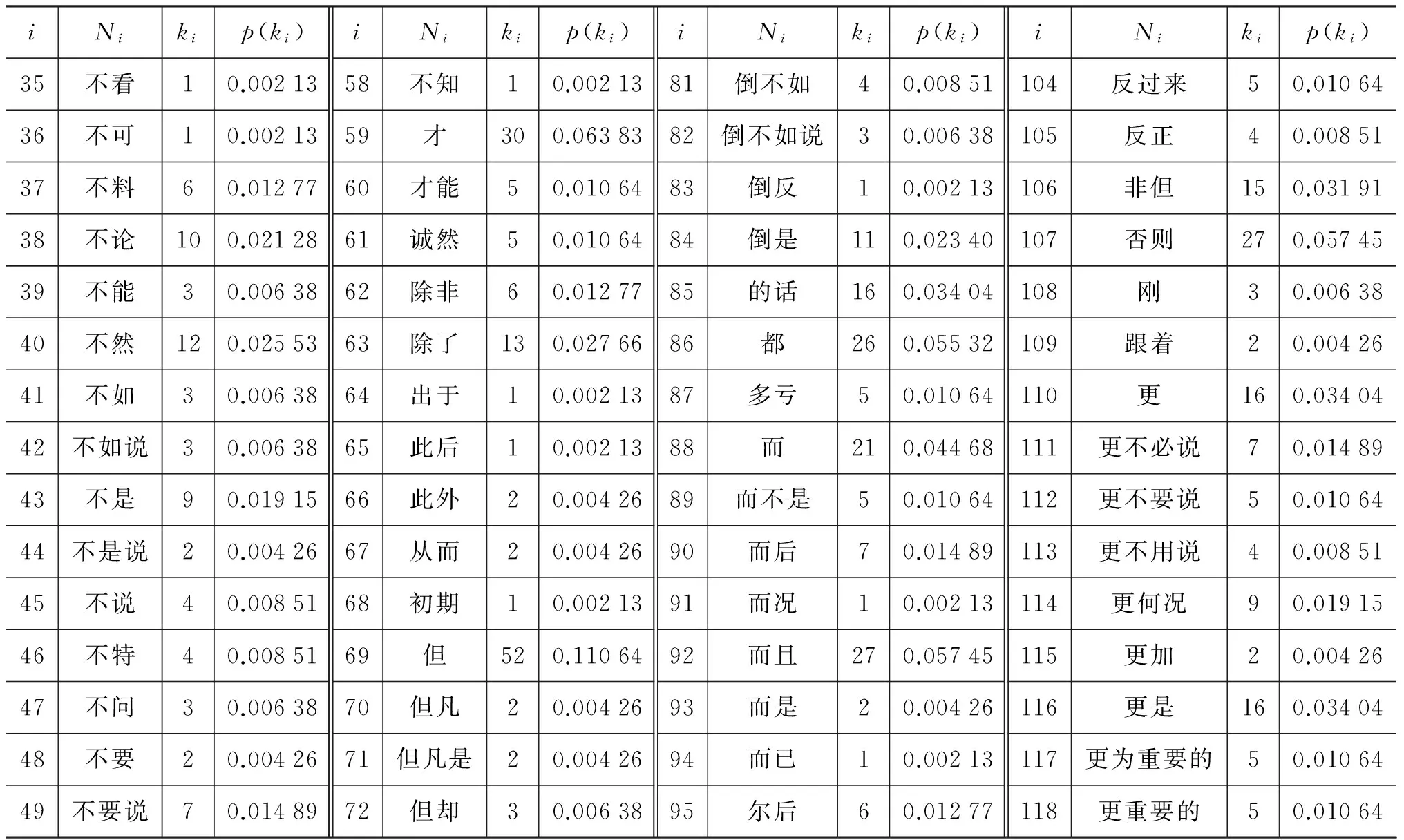
iNikip(ki)iNikip(ki)iNikip(ki)iNikip(ki)35不看10.0021358不知10.0021381倒不如40.00851104反過來50.0106436不可10.0021359才300.0638382倒不如說30.00638105反正40.0085137不料60.0127760才能50.0106483倒反10.00213106非但150.0319138不論100.0212861誠然50.0106484倒是110.02340107否則270.0574539不能30.0063862除非60.0127785的話160.03404108剛30.0063840不然120.0255363除了130.0276686都260.05532109跟著20.0042641不如30.0063864出于10.0021387多虧50.01064110更160.0340442不如說30.0063865此后10.0021388而210.04468111更不必說70.0148943不是90.0191566此外20.0042689而不是50.01064112更不要說50.0106444不是說20.0042667從而20.0042690而后70.01489113更不用說40.0085145不說40.0085168初期10.0021391而況10.00213114更何況90.0191546不特40.0085169但520.1106492而且270.05745115更加20.0042647不問30.0063870但凡20.0042693而是20.00426116更是160.0340448不要20.0042671但凡是20.0042694而已10.00213117更為重要的50.0106449不要說70.0148972但卻30.0063895爾后60.01277118更重要的50.01064
表3中,i為圖1中關系詞節點的編號,Ni為該節點名,ki為該節點的度,p(ki)為該關系詞節點的度分布概率值。
6 結束語
本文基于復雜網絡的理論與研究方法對漢語復句關系詞本體知識庫中470個搭配關系詞進行分析
研究,構建了一個現代漢語復句關系詞搭配網絡,得到470個節點間的最短路徑長度、網絡的聚集系數和度分布等三大基本統計值,這些統計值是復句關系詞搭配能力和搭配對象之間的關系,以及它們的搭配強度的反映。通過對現代漢語復句關系詞搭配網絡的三大統計特征的分析研究,可進一步探討復句的層次關系和復句邏輯語義關聯的特點與規律,是進一步研究復句層次關系和復句邏輯語義自動識別、自動處理的重要基礎與理論依據。
現代漢語復句關系詞搭配網絡是基于漢語“復句關系詞本體知識庫”而構建的,它具有典型的動態性,所以從分類模型角度分析,它屬于動態網絡;而從搭配角度分析,它是共現網絡;從搭配關系詞本體角度分析,它是典型的語義網絡;從搭配關系詞的前呼和后應關系角度分析,它是一種依存關系網絡[7]。
漢語復句是連接分句與篇章的橋梁,是漢語語法的重要實體單位,它表達的語義信息豐富而復雜,所以研究復句和復句關系詞的計算機自動識別與處理顯得更為重要、更加迫切,然而這又是非常艱難的研究任務。本文所研究的現代漢語復句關系詞搭配網絡的平均路徑長度、聚集系數、度分布等統計特征,體現了現代漢語復句關系詞之間的搭配能力和搭配強度,文獻[25]指到,搭配能力和搭配強度是進一步研究復句層次關系和復句邏輯語義自動識別的基礎。所以,在本文的研究基礎上,將進一步研究現代漢語復句關系詞搭配依存網絡,為深入研究現代漢語復句層次關系和復句邏輯語義的計算機自動識別與自動處理奠定基礎。
[1] 汪小帆,李翔,陳關榮編著.復雜網絡理論及其應用[M].北京: 清華大學出版社,2006: 9-29.
[2] D J Watts,S H Strogatz.Collective dynamics of‘small- world’networks[J]. Nature.1998,393(6684): 440-442 .
[3] A L Barabasi,R Albert.Emergence of scaling in random networks[J].Science.1999, 286(5439): 327-335.
[4] Barabási A L. Linked: The New Science of Networks. Massachusetts[M].Persus Publishing, 2002: 223-256.
[5] 周濤,柏文潔,汪秉宏等.復雜網絡研究概述[J].系統工程理論與實踐,2005,34(1): 31-36.
[6] 范超,王厚峰.社交網絡中的社團結構挖掘[J].中文信息學報,2014,28(1): 56-63.
[7] 韓普,王東波,路高飛,等.語言網絡研究進展[J].中文信息學報,2014,28(1): 9-18.
[8] Amancio D R,Antiqueira L Pardo T A S,etl.Complex networks analysis of manual and machine translations[J].International Journal of Modern Physics C.2008,19(4): 583-598.
[9] 劉海濤.漢語語義網絡的統計特征[J].科學通報,2009,54(14): 2060-2064.
[10] Cancho R F I,Sole R V.The Small World of Human Langquage[C]//Proceedings of the the Royal Society of London Series B-Biological Sciences,2001(1482): 2261-2265.
[11] 韋洛霞,李勇,李偉,等.漢字網絡的3度分隔與小世界效應[J].科學通報,2004,49(24):2615-2616.
[12] 韋洛霞,李勇,康世勇,等.漢語詞組網的組織結構與無標度特性[J].科學通報,2005,50(15): 1575-1579.
[13] 劉知遠,孫茂松.漢語詞同現網絡的小世界效應和無標度特性[J].中文信息學報,2007,21(6):52-58.
[14] 劉知遠,鄭亞斌,孫茂松.漢語依存句法網絡的復雜網絡性質[J].復雜系統與復雜性科學,2008,5(2): 37-45.
[15] 劉海濤.漢語句法網絡的復雜性研究[J].復雜系統與復雜性科學.2007,4(4): 38-44.
[16] 趙鵬,蔡慶生,王清毅,等.一種基于復雜網絡特征的中文文檔關鍵詞抽取算法[J].模式識別與人工智能,2007,20(6): 827-831.
[17] 劉海濤.語言復雜網絡的聚類研究[J].科學通報,2010,55(27-28): 2667-2674.
[18] 陳芯瑩,劉海濤.漢語句法網絡的中心節點研究[J].科學通報,2011,56(10): 726-731 .
[19] Yu S,Liu H,Xu C.Statistical properties of Chinese phonemic networks[J].Physics A.2011,390(7): 1370-1380.
[20] 趙輝,劉懷亮,范云杰.復雜網絡理論在中文文本特征選擇中的應用研究[J].現代圖書情報技術,2012,224(9): 23-28.
[21] 孫茂松,劉 挺,姬東鴻,等.語言計算的重要國際前沿[J].中文信息學報,2014,28(1):1-8.
[22] 邢福義.漢語復句研究[M].北京: 商務印書館,2001: 26-37.
[23] 魯松,白碩,李素建,等.漢語多重關系復句的關系層次分析[J].軟件學報,2001,12(7): 987-995.
[24] 孫茂松,王昌寧,方捷.漢語搭配定量分析初探[J].中國語文,1997,256(1): 29-38.
[25] 姚雙云.復句關系標記的搭配研究[M].武漢: 華中師范大學出版社.2008: 75-180.
[26] 姚雙云,胡金柱,等.關聯詞搭配的自動發現[J].計算機應用研究,2011,28(12): 4426-4428,4432.
[27] 魯松,宋柔.漢英機器翻譯中描述型復句的關系識別與處理[J].軟件學報,2001,12(1): 83-93.
[28] 胡金柱,吳鋒文等.漢語復句關系詞庫的建設及其利用[J].語言科學,2010,(2): 133- 142.
[29] Huanshen Jia,Haixing Zhao.Spanning Trees in a Class of Four Regular Small World Network Computer Science and Application[J].2014,4(4): 43-49.
[30] Ke Zhang,Haixing Zhao,Faxu Li,et al.A Kind of Deterministic Small-World Networks Model and Analysis of Their Characteristics[J].2014,4(4): 27-31.
[31] 劉云.漢語虛詞知識庫的建設[M].武漢: 華中師范大學出版社.2009: 204-302.
[32] Hu Quan,Liu yanshen,et al. Research on the Automatic Identification method of the Collocation of Relative Word in Chinese Complex Sentences[C]//Proceedings of the 2013 3rd International Conference on Advanced Materials and Information Technology Processing, Los Angeles, CA, USA.2013,10: 1-2.
Statistical Analysis of the Collocation Networks of Relative Words in Chinese Complex Sentences Based on Complex Network Theory
HU Quan1, XIE Fang2, LI Yuan3, LIU Yanshen1
(1. College of Physical Science and Technology,Central China Normal University, Wuhan, Hubei 430079, China;2. College of Computer, Hubei University of Technology, Wuhan, Hubei 430068, China;3. College of Computer, Central China Normal University, Wuhan, Hubei 430079, China)
The relative words are markers in Chinese Complex Sentences, indicating the relationships between the clauses. The collation relationship of relative words means the co-occurrence form of one or more relative words in one complex sentence. It can influence the semantic and gradation relationship of the clauses. This paper constructs a Collation Network of relative words of Chinese Complex Sentences with 470 relative words based on the complex networks. We study the characteristics of average length of path, clustering coefficient, and distribution of degree depending on the collation network. These results can be applied to analyze the collation strength of relative words, which might help identify the gradation relationship and logic semantics of complex sentence automatically.
the collocation of relative words of Chinese complex sentences;complex networks;average path length;clustering coefficient; distribution of degree

胡泉(1980—),博士,講師,主要研究領域為計算機軟件工程和中文信息處理。E-mail:123750955@qq.com謝芳(1981—),博士,講師,主要研究領域為業務流程建模、自然語言處理。E-mail:33460694@qq.com李源(1972—),博士,副教授,主要研究領域為計算機軟件工程和中文信息處理。E-mail:yuanli@mail.ccnu.edu.cn
1003-0077(2016)04-0056-09
2014-03-08 定稿日期: 2015-01-30
國家社科青年基金(13CYY037);教育部社科基金(14YJA740020);國家自然科學基金(61177063)
TP391
A
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
開放教育研究(2020年2期)2020-03-31 01:54:14
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
