基于n元詞組表示的去噪 方法及其在跨語言映射中的應(yīng)用
2016-05-03 02:46:06于墨趙鐵軍
智能計算機與應(yīng)用 2016年2期
于墨 趙鐵軍

摘 要:具有結(jié)構(gòu)化輸出的學(xué)習(xí)任務(wù)(結(jié)構(gòu)化學(xué)習(xí))在自然語言處理領(lǐng)域廣泛存在。近年來研究人員們從理論上證明了數(shù)據(jù)標(biāo)記的噪聲對于結(jié)構(gòu)化學(xué)習(xí)的巨大影響,因此為適應(yīng)結(jié)構(gòu)化學(xué)習(xí)任務(wù)的去噪算法提出了需求。受到近年來表示學(xué)習(xí)發(fā)展的啟發(fā),本文提出將自然語言的子結(jié)構(gòu)低維表示引入結(jié)構(gòu)化學(xué)習(xí)任務(wù)的樣本去噪算法中。這一新的去噪算法通過n元詞組的表示為序列標(biāo)注問題中每個節(jié)點尋找近鄰,并根據(jù)節(jié)點標(biāo)記與其近鄰標(biāo)記的一致性實現(xiàn)去噪。本文在命名實體識別和詞性標(biāo)注任務(wù)的跨語言映射上對上述去噪方法進行了驗證,證明了這一方法的有效性。
關(guān)鍵詞:表示學(xué)習(xí);半監(jiān)督學(xué)習(xí);去噪算法;自然語言處理;跨語言映射
中圖分類號:TP181 文獻標(biāo)識號:A 文章編號:2095-2163(2015)06-
Noise Removing based on N-gram Representations and its Applications to Cross-Lingual Projection
YU Mo, ZHAO Tiejun
(School of Computer Science and Technology, Harbin Institute of Technology, Harbin 150001, China)
Abstract: Problems with structured predictions (structured learning) widely exist in natural language processing. Recent research found that compared to classification problems, structured learning problems were affected more seriously by label noises, suggesting the importance of noise removing algorithms for these problems. Inspired by the development of representation learning methods, the paper proposes a noise-removing algorithm for structured learning based on low-dimensional representations of sub-structures. The algorithm finds neighbors of each node in a sequential labeling task based on its associated n-gram representation, and then performs noise removing on the label of a node according to its consistency with the labels of its neighbors. Therefore the paper proves the effectiveness of the proposed algorithm on the cross-lingual projection of named entity recognition and POS tagging tasks.
Keywords: Representation Learning; Semi-supervised Learning; Noise Removing; Natural Language Processing; Cross-lingual Projection
0引 言
很多自然語言處理(NLP)技術(shù)依賴于有監(jiān)督學(xué)習(xí)方法訓(xùn)練的模型,而有監(jiān)督學(xué)習(xí)方法的性能不僅依賴于標(biāo)記樣本的數(shù)量,也依賴于標(biāo)記樣本的質(zhì)量。當(dāng)標(biāo)記樣本中發(fā)生了錯誤,即標(biāo)記存在著噪聲時,學(xué)習(xí)得到的分類器的推廣能力會受到影響(相應(yīng)的理論分析被稱為噪聲可學(xué)習(xí)性理論,見文獻[1-2])。由于具有結(jié)構(gòu)化輸出的學(xué)習(xí)任務(wù)(結(jié)構(gòu)化學(xué)習(xí))在NLP領(lǐng)域的廣泛存在性和重要性,于墨等人[3]將上述噪聲可學(xué)習(xí)性理論推廣到結(jié)構(gòu)化學(xué)習(xí)問題中,證明了對同樣的噪聲率,學(xué)習(xí)的難度隨結(jié)構(gòu)的復(fù)雜性的增加而有所提升。這一理論分析結(jié)果說明了當(dāng)NLP的結(jié)構(gòu)化學(xué)習(xí)任務(wù)包含噪聲時,一個好的去噪算法對模型性能的改進完善極為重要。
綜合上述原因,本文以序列標(biāo)注任務(wù)為例,提出了一種針對自然語言結(jié)構(gòu)化學(xué)習(xí)問題的去噪方法。這一方法采用了基于最近鄰樣本的去噪策略,即假設(shè)相似的樣本應(yīng)該具有相似的標(biāo)記,從而當(dāng)一個樣本的標(biāo)記與其最相似的幾個樣本標(biāo)記存在沖突時,便認為這個樣本的標(biāo)記存在著噪聲,并可以根據(jù)其近鄰樣本的標(biāo)記(或這些樣本標(biāo)記的多數(shù)投票)去對錯誤樣本的標(biāo)記進行修正。上述去噪算法的核心在于樣本相似性的定義,在自然語言的序列標(biāo)注問題中,重點關(guān)注了序列中每個節(jié)點(即詞)的標(biāo)記信息,從而每個詞被看作是一個樣本。然而由于詞的歧義性和用法的多樣性,僅使用詞本身并不足以描述該詞在序列中起到的作用并得出詞的標(biāo)記信息。因此,在序列標(biāo)注問題中,研究人員往往同時使用一個詞本身及其上下文詞去描述該詞的作用。這一思想啟發(fā)本研究也可使用同樣的上下文信息去定義樣本的相似性。
本文提出了一種用于描述詞及其上下文的n元詞組的表示。這里“表示”指的是一種將n元詞組映射到某個低維向量空間的方法。在自然語言處理中,表示學(xué)習(xí)方法往往用于將某些語言成分或特征通過維度約減而映射到低維向量。比如詞聚類[4]和詞嵌入[5]分別通過將詞分配到一些離散聚類中,或者將詞表示為低維的連續(xù)向量,實現(xiàn)了對于詞匯信息的降維。這樣的低維表示常常被用作有監(jiān)督訓(xùn)練模型的輸入特征,從而避免模型具有過多參數(shù)而過擬合訓(xùn)練集樣本。而在本文中,具體是從另一個角度應(yīng)用上述低維表示,即通過這些表示為原本稀疏的n元詞組之間建立關(guān)系,并以此作為去噪算法的相似性度量。本文在NLP領(lǐng)域首次嘗試將表示學(xué)習(xí)的成果應(yīng)用于去噪算法,并在序列標(biāo)注問題的跨語言映射上取得了巨大的成功。同時據(jù)已有研究成果所知,本文也首次在NLP領(lǐng)域?qū)⑷ピ胨惴ㄒ虢Y(jié)構(gòu)化學(xué)習(xí)任務(wù)。
在本文的第一節(jié),我們將對基于n元詞組表示的去噪方法進行描述。本文的第二節(jié)將介紹實驗部分,即跨語言映射問題的實驗設(shè)置。第三節(jié)給出本文去噪算法的實驗結(jié)果。最后在第四節(jié)中,則是對本文工作進行總結(jié)并進一步討論未來的研究方向。
1基于n元詞組表示的去噪方法
1.1序列標(biāo)注問題
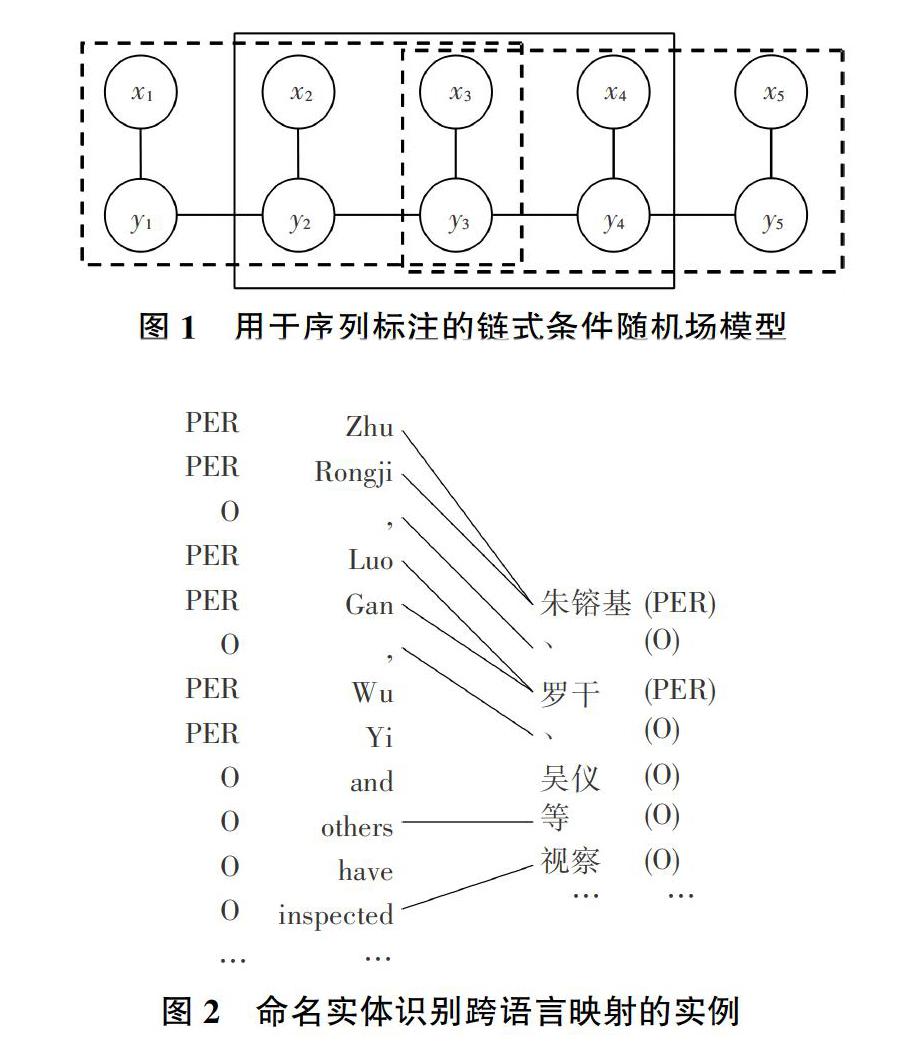
本文主要關(guān)注噪聲對序列標(biāo)注問題的影響。這里序列標(biāo)注問題可以被形式化定義為給定一個輸入序列X={xi},目標(biāo)為輸出標(biāo)記序列Y={yi}的技術(shù)實現(xiàn)過程描述。其中xi和yi形成了一一對應(yīng)。自然語言處理中的一個經(jīng)典序列標(biāo)注問題為詞性標(biāo)注研究,此時每個xi是句子中的一個單詞,而yi是這個單詞的詞性,如名詞、動詞等。圖1給出了使用條件隨機場(CRF)[6]對上述序列標(biāo)注問題建模的一個示意。該情形的任務(wù)目標(biāo)是為P(Y|X)建模。我們將該模型稱為1階模型,因為模型只考慮相鄰兩個標(biāo)記yi-1 yi的條件依賴。
1.2基于布朗聚類的n元詞組表示
本文所提出的n元詞組表示方法以詞表示作為基礎(chǔ),本節(jié)中使用詞表示的一種特例——布朗聚類完成這一任務(wù)。布朗聚類[4]是一種層次化的聚類算法,該算法的目標(biāo)是最大化基于詞聚類的二元詞組之間的互信息。布朗聚類在大量的自然語言處理任務(wù)中均已得到了成功的應(yīng)用,如命名實體識別[7],短語結(jié)構(gòu)文法分析[8],依存句法分析[9]以及語義依存分析[10]。
1.3基于n元詞組表示的去噪算法描述
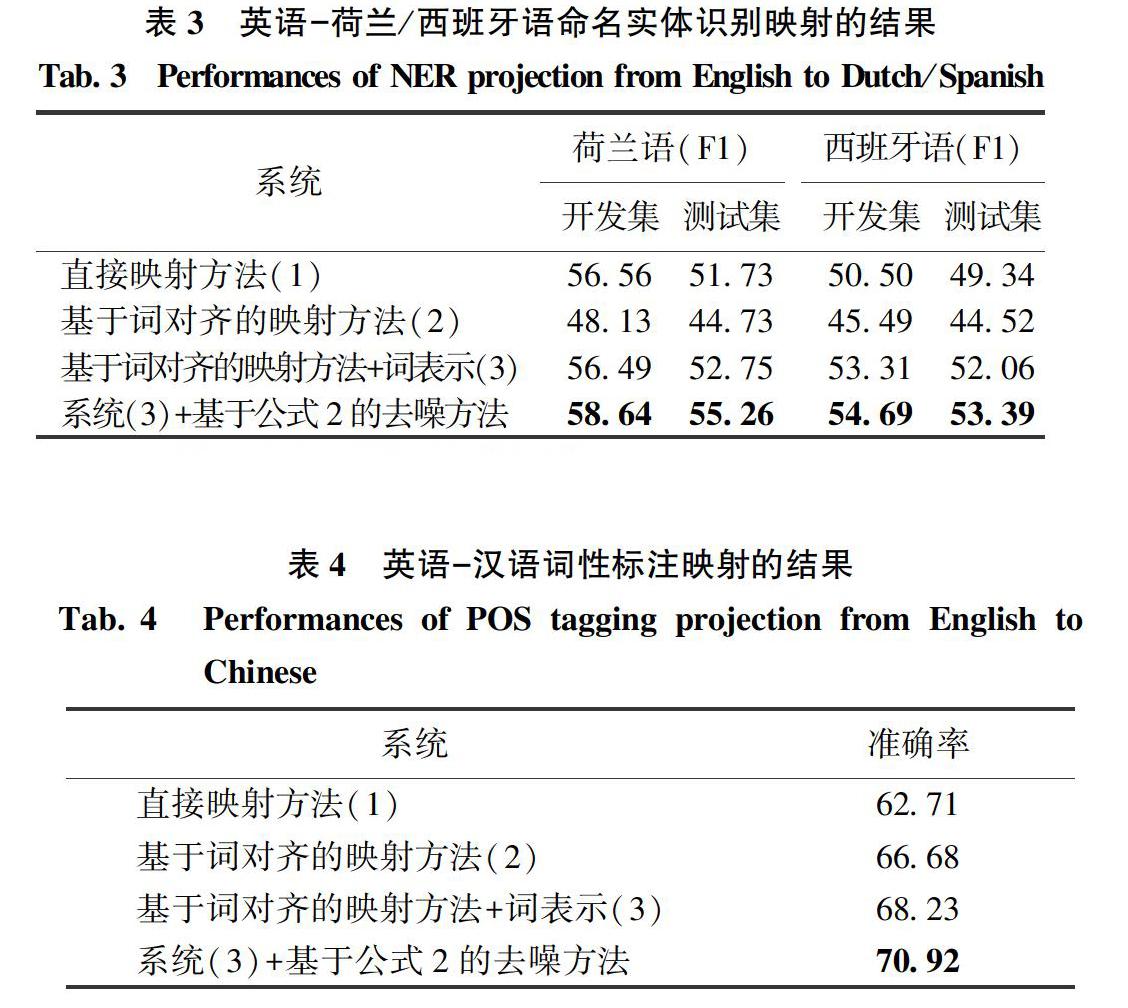
已有研究的理論分析[3]說明在結(jié)構(gòu)化學(xué)習(xí)問題中,類別噪聲對于分類器訓(xùn)練的影響會由于類別在結(jié)構(gòu)中的相互依賴而放大。而在很多自然語言處理任務(wù)中,標(biāo)注都會存在一定的噪聲。圖2給出了一個跨語言映射[11]的實例。這是一個命名實體識別任務(wù),即判斷句子中某個詞或詞組是否為人名、地名、機構(gòu)名等實體。在該例子中,源語言句子的標(biāo)注會根據(jù)詞對齊結(jié)果被映射到目標(biāo)語言端,從而在目標(biāo)語言端構(gòu)建了一個自動標(biāo)注數(shù)據(jù)樣例。這些自動標(biāo)注數(shù)據(jù)可以隨后應(yīng)用在目標(biāo)語言端來進行命名實體識別模型訓(xùn)練。同時,在這個例子中,目標(biāo)語言(漢語)端的“吳儀”一詞因為詞對齊的錯誤,沒有被標(biāo)記為命名實體,為此而成為了訓(xùn)練噪聲。由于詞對齊錯誤的大量存在,通過跨語言映射方法建立的目標(biāo)語言訓(xùn)練數(shù)據(jù)必將會存在大量的噪聲。
為了降低數(shù)據(jù)中的噪聲從而使得訓(xùn)練得到的模型更加精確,本節(jié)提出了一個基于表示學(xué)習(xí)的去噪方法。該方法的基本假設(shè)是相似的詞應(yīng)該具有相同的類別標(biāo)記,這就使得當(dāng)一個詞與其絕大部分近鄰標(biāo)記均為不同時,研究則認為該詞標(biāo)記錯誤,并將對應(yīng)標(biāo)記更改為其相近詞的標(biāo)記。
該方法的一個極端情況是對相同的詞賦予相同的類別。然而數(shù)據(jù)噪聲往往并非獨立同分布,而是具有某些偏置(bias)。比如圖2所示的噪聲來自于詞對齊算法的系統(tǒng)錯誤,導(dǎo)致在語料中,低頻詞“吳儀”的大部分出現(xiàn)都對應(yīng)著詞對齊錯誤。此時基于詞本身去噪并不能解決這一問題。而詞表示則可以給出具體解決辦法:對于上述例子,可以觀察到“吳儀”,“朱镕基”和“羅干”由于總是在相似的上下文中出現(xiàn),而被分配在同一聚類中。如果這個聚類中的詞大部分都是人名,研究則有理由相信“吳儀”一詞的類別應(yīng)被修改為“PER”。
另一方面,在序列標(biāo)注任務(wù)中,一個詞的類別標(biāo)記往往并不僅僅取決于詞自身,同時也取決于詞的上下文。因此,為了更精確地進行去噪操作,即可考慮以n元詞組取代詞作為一個樣本,從而相似的n元詞組的中心詞將會對應(yīng)著相同的類別標(biāo)記。在此設(shè)置下,最精確的去噪方式是使用n元詞組自身作為相似度度量,從而與上一段中的描述得到了類似推論:相同的n元詞組應(yīng)該具有相同的標(biāo)記。然而這一方法也同樣存在著問題:相比詞本身,n元詞組往往更加稀疏,因此從有限的數(shù)據(jù)樣本中可能難以獲得充分的統(tǒng)計信息去確定“一個n元詞組大部分情況下具有何種標(biāo)記”。而上一節(jié)中的n元詞組表示卻恰好能夠為這樣的稀疏數(shù)據(jù)進行平滑,從而使得去噪過程更加準(zhǔn)確。
2實驗設(shè)置
2.1實驗數(shù)據(jù)
本文以跨語言映射問題為例,對本文提出的去噪方法進行測試。實驗中以英語作為資源豐富型語言,用漢語、荷蘭語和西班牙語模擬資源缺乏型語言。上述數(shù)據(jù)選擇即為研究提供了兩種不同的應(yīng)用環(huán)境:對于英語到漢語的映射任務(wù),源語言和目標(biāo)語言屬于兩個不同語系,從而具有較大差異;而歐洲語言對則相較而言會更為接近。本文隨即在英-漢語言對上進行了命名實體識別(NER)和詞性標(biāo)注(POS)的跨語言映射。為了評價英語到漢語的NER的任務(wù)準(zhǔn)確率,選擇使用了人民日報語料四月份部分(1998年)作為測試集(55 177個句子)。,并且將該數(shù)據(jù)的分詞標(biāo)準(zhǔn)轉(zhuǎn)化成賓州中文樹庫[12]的風(fēng)格。對于英語到荷蘭語/西班牙語的任務(wù),則使用了CoNLL 2002[13]任務(wù)所提供的標(biāo)準(zhǔn)數(shù)據(jù)劃分。為了評價POS任務(wù)的準(zhǔn)確率,主要使用了CTB的標(biāo)準(zhǔn)測試集,并將英漢詞性標(biāo)注類別都轉(zhuǎn)換為通用詞性集合[14]。
在本實驗中,使用了布朗聚類作為詞表示。具體就是通過使用[15]一文中提出的工具,在中文維基百科語料上訓(xùn)練得到1 000類的布朗聚類。在此基礎(chǔ)上,則使用斯坦福分詞器[16]對中文維基語料進行分詞。對于荷蘭語和西班牙語的布朗聚類,特別優(yōu)化使用了OpenNLP工具獲得這些語言維基百科語料的標(biāo)記化文本,再使用與漢語相同的方法訓(xùn)練1 000類的布朗聚類。
實驗中,使用了LDC2003E14語料作為英-漢雙語對齊語料。該語料包含了大約200,000個對齊句對。需要說明的是目前存在著豐富的大規(guī)模中英對齊語料,本文選擇該數(shù)據(jù)的原因是其規(guī)模適中,因此在其他語言對上也很容易收集到相似規(guī)模的對齊語料。這使得本文得出的結(jié)論在現(xiàn)實應(yīng)用中更具有一般性。對于英語到荷蘭語和西班牙語的映射任務(wù),有針對性地使用了Europarl語料[17]。同樣地,只為研究選取了這兩個對齊語料的前200 000個對齊句對。Europara語料提供了英語到西班牙語的詞對齊。對于其他語言對,則將使用GIZA++[18]產(chǎn)生詞對齊。
2.2基線系統(tǒng)
實驗中比較了三種基線系統(tǒng),第一個系統(tǒng)來自于文獻[19],在該方法中,源語言端訓(xùn)練出的布朗聚類根據(jù)詞對齊被映射到目標(biāo)語言端,從而為目標(biāo)語言的每個詞分配詞聚類。在此基礎(chǔ)上,還可以在同一個特征空間內(nèi)表示源語言和目標(biāo)語言樣本,因此用源語言語料在該特征空間上訓(xùn)練得到的模型可以直接應(yīng)用于目標(biāo)語言。本文將這種方法稱為直接映射方法。實驗的第二個系統(tǒng)來自于對[11]一文的直接應(yīng)用,在該方法中,利用源語言端的一個高質(zhì)量的模型[20]來標(biāo)記對齊語料中的源語言句子,并根據(jù)詞對齊將標(biāo)記結(jié)果傳播到目標(biāo)語言句子上,然后在目標(biāo)語言端重新訓(xùn)練模型。在實現(xiàn)過程中,采用[21]一文提出的方法,只使用一對一詞對齊進行映射,這一處理也使得映射后得到的數(shù)據(jù)質(zhì)量更高(見文獻[21]中的分析)。本文將上述方法稱為基于詞對齊的映射方法。實驗的第三個系統(tǒng)基于第二種方法,同時使用了文獻[22]提出的詞表示復(fù)合特征,該方法被記為基于詞對齊的映射方法+詞表示。
在上述模型訓(xùn)練過程中,研究使用了表1中的特征模板(來自文獻[22])。表中,w0代表當(dāng)前詞,p0代表當(dāng)前詞的詞性,c0代表當(dāng)前詞的詞聚類(其中使用上一節(jié)中的布朗聚類),y0為當(dāng)前詞的標(biāo)記,wi代表相對當(dāng)前詞位置為i的詞,w[1:i]代表詞w的長度為i的前綴,w[-i:-1]代表詞w的長度為i的后綴。Hyp和Cap是指示函數(shù),分別表示當(dāng)前詞是否包含連字符,以及當(dāng)前詞第一個字母是否大寫。對于漢語的實驗,這里忽略了表中的形態(tài)學(xué)特征。
為了證明本文所提出的方法對于多種不同的NLP任務(wù)都能起到作用,又設(shè)計給出了英語到漢語的詞性標(biāo)注映射結(jié)果。在這一任務(wù)中,明確使用了與NER任務(wù)相同的特征模板。表4給出了該任務(wù)上的結(jié)果。通過本文提出的基于n元詞組去噪方法的幫助,相比最好的基線系統(tǒng),最終得到了大約2.7個百分點的提升。而且,在這一任務(wù)上,基于n元詞組表示的去噪方法相比在NER任務(wù)上起到了更加重要的作用:加入詞表示特征(3)相比系統(tǒng)(2)帶來了1.5個百分點的提升,而本文的去噪方法在此基礎(chǔ)上又取得了2.7個百分點的提升(相較之下前面的任務(wù)中詞表示特征提升幅度更大)。一個可能的原因是本文的去噪方法在實際上就假設(shè)了每個樣本標(biāo)記均為詞級別的。現(xiàn)實中,這一假設(shè)對于詞性標(biāo)注是合理的,然而對于NER任務(wù)卻并不完全適用。
4結(jié)束語
本文提出了基于n元詞組表示的訓(xùn)練數(shù)據(jù)去噪方法。其中的n元詞組表示可以有效地描述詞的上下文信息,從而更好地幫助獲取每個訓(xùn)練樣本在標(biāo)記數(shù)據(jù)中的近鄰,并考察訓(xùn)練樣本標(biāo)記的一致性。在多個跨語言映射任務(wù)上的實驗結(jié)果證明這一去噪方法可以大幅地提升訓(xùn)練結(jié)果的準(zhǔn)確率。在未來,則將考慮使用如詞嵌入等連續(xù)表示,同時結(jié)合流形學(xué)習(xí)的方法進行更加精確的去噪。同時我們將研究其它子結(jié)構(gòu)的表示方法(如遞歸神經(jīng)網(wǎng)絡(luò)[23]),并將其應(yīng)用于更復(fù)雜結(jié)構(gòu)學(xué)習(xí)問題的去噪算法中。
參考文獻:
[1] ANGLUIN D, LAIRD P. Learning from noisy examples[J]. Machine Learning, 1988, 2(4): 343–370.
[2] Laird P D. Learning from good and bad data[M]. Berlin: Springer Science & Business Media, 2012.
[3] 于墨, 趙鐵軍, 胡鵬龍, et al. 結(jié)構(gòu)化學(xué)習(xí)的噪聲可學(xué)習(xí)性分析及其應(yīng)用[J]. 軟件學(xué)報, 2013, 24(10): 2340–2353.
[4] BROWN P F, DESOUZA P V, MERCER R L, et al. Class-based n-gram models of natural language[J]. Computational linguistics, 1992, 18(4): 467–479.
[5] Bengio Y, Schwenk H, Sene ?cal J S, et al. Neural probabilistic language models[M]. Berlin: Springer, 2006: 137–186.
[6] LAFFERTY J, MCCALLUM A, PEREIRA F C. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[C]// ICML 2001. San Francisco: IMLS, 2001: 282-289
[7] MILLER S, GUINNESS J, ZAMANIAN A. Name tagging with word clusters and discriminative training[C]// NAACL 2004. Boston, Massachusetts: ACL,2004: 337-342.
[8] CANDITO M, CRABBE B. Improving generative statistical parsing with semi-supervised word clustering[C]// IWPT. 2009, [S.l.] ACL,2009: 138-141.
[9] KOO T, CARRERAS X, COLLINS M. Simple Semi-supervised Dependency Parsing[C]// Proceedings of ACL-08: HLT. Columbus, Ohio: ACL, 2008: 595–603
[10] ZHAO H, CHEN W, KIT C, et al. Multilingual dependency learning: a huge feature engineering method to semantic dependency parsing[C]// CoNLL 2009, Boulder, Colorado: ACL,2009: 55-60.
[11] YAROWSKY D, NGAI G, WICENTOWSKI R. Inducing multilingual text analysis tools via robust projection across aligned corpora[C]// HLT 2001, [S.l.]: ACL,2001: 1–8.
[12] XUE N, XIA F, CHIOU F, et al. The eenn Chinese treebank: Phrase structure annotation of a large corpus[J]. Natural Language Engineering, 2005, 11(2): 207.
[13] TJONG K S E. Introduction to the CoNLL-2002 shared task: Language-independent named entity recognition[C]//CoNLL 2002, Taipei, Taiwan: ACL, 2002: 155–158.
[14] PETROV S, DAS D, MCDONALD R. A universal part-of-speech tagset[J]. arXiv preprint arXiv:1104.2086, 2011.
[15] Liang P. Semi-supervised learning for natural language[D]. Massachusetts Institute of Technology, 2005.
[16] TSENG H, CHANG P, ANDREW G, et al. A conditional random field word segmenter for sighan bakeoff 2005[C]//SIGHAN 2005, [S.l.]: ACL,2005: 171.
[17] KOEHN P. Europarl: A parallel corpus for statistical machine translation[C]//MT summit. 2005, Phuket, Thailand: Citeseer,2005: 79–86.
[18] OCH F J, NEY H. A systematic comparison of various statistical alignment models[J]. Computational linguistics, 2003, 29(1): 19–51.
[19] T?CKSTR?M O, MCDONALD R, USZKOREIT J. Cross-lingual word clusters for direct transfer of linguistic structure[C]// NAACL 2012. Montréal, Canada: ACL,2012: 477-487.
[20] MANNING C D, SURDEANU M, BAUER J, et al. The Stanford CoreNLP Natural Language Processing Toolkit[C]// ACL 2014 (System Demonstrations). Baltimore, Maryland: ACL,2014: 55-60.
[21] HU P, YU M, LI J, et al. Semi-supervised Learning Framework for Cross-Lingual Projection[C]// WI-IAT 2011, Lyon, France: IEEE: 2011(3): 213–216.
[22] YU M, ZHAO T, DONG D, et al. Compound Embedding Features for Semi-supervised Learning[C]// NAACL 2013. Atlanta, Georgia: ACL,2013: 563-568.
[23] SOCHER R, BAUER J, MANNING C D, et al. Parsing with compositional vector grammars[C]// ACL 2013. Sofia, Bulgaria: ACL,2013: 455-465.
