基于地域特征和異構社交關系的事件推薦算法研究
2016-05-04 02:54:31紀現才曹亞男
中文信息學報 2016年5期
喬 治,周 川,紀現才,曹亞男,郭 莉
(1. 中國科學院 計算技術研究所 北京100190; 2. 中國科學院大學 北京100049; 3. 中國科學院 信息工程研究所 北京100093)
基于地域特征和異構社交關系的事件推薦算法研究
喬 治1,2,周 川2,3,紀現才3,曹亞男3,郭 莉3
(1. 中國科學院 計算技術研究所 北京100190; 2. 中國科學院大學 北京100049; 3. 中國科學院 信息工程研究所 北京100093)
近幾年,在基于事件的社交網絡(EBSNs)服務中,為便于增強用戶體驗,事件推薦任務一直被廣泛研究。本文基于對EBSN中用戶行為數據的詳細分析,提出了一種新型的融合多種數據特征的潛在因子模型。該模型綜合考慮EBSN中兩種新型的數據特征: 異構的社交關系特征(線上社交關系+線下社交關系)和用戶參與行為的地域性特征。基于真實的Meetup數據集,實驗結果表明我們的算法在解決事件推薦問題時比傳統的算法有更好的性能。
事件推薦;基于事件的社交網絡;用戶行為傾向;協從過濾;地域特征;異構社交關系
1 引言
近年來,基于事件的社交網絡(EBSN)快速發展,積累了大量的用戶群體并深受廣大用戶的喜歡。這種新型社交網絡服務的主要應用包括國內的豆瓣同城以及美國的Meetup等網站。這種服務主要給用戶提供一種組織、參與、評論和分享線下事件(如酒會、沙龍、演唱會等)的平臺。面向該應用場景的事件推薦任務,獲得國內外研究者的廣泛研究和探索。事件推薦任務旨在為用戶推薦最相關、最感興趣以及用戶最有可能參與的事件。從網絡服務的宏觀角度看,該任務無論對于線下事件的組織者還是事件的參與者都提供便利。對于事件的組織者,線下活動可以被自動地推送給合適的用戶群從而吸引更多感興趣的用戶參與;對于事件的參與者,推薦任務可以過濾不相關事件,使得用戶可以從海量的信息中快速發現自己可能喜歡的事件。
區別于已有的推薦問題[1-4],在EBSN中的事件推薦任務面臨以下數據特征所帶來的挑戰。
? 地域特征。根據數據分析,我們發現用戶在選擇參與線下事件時,存在區域傾向性。即用戶除了對事件內容有個體性興趣傾向外,用戶對于事件舉辦地點的喜好也會影響用戶對于某一事件的參與行為。
? 異構社交關系特征。在基于事件的社交網絡中存在兩種社交關系。一種是線上社交關系,即傳統社交網絡應用中關聯用戶的社交關系。用戶通過EBSN中的線上社交網絡可以互相溝通、分享感興趣的事件以及體驗。第二種社交關系是線下社交關系。在數據挖掘頂級會議KDD-12[5]上,IBM研究院的研究人員在分析基于事件的社交網絡數據時提出并定義了這種新型的社交關系。這種關系的紐帶是線下事件。當用戶參與了同一線下事件時,他們勢必會有面對面的交流與互動,這種線下的關聯是對虛擬社交關聯的補充,被定義為線下社交關系。在EBSN中,同時存在著兩種異構的社交關聯。
EBSN數據的上述兩種特征給我們的問題分析和建模帶來了新的挑戰。為設計有效的推薦算法,我們需要聯合考慮上述兩種數據特征。在本文中,我們提出了一種新型的潛在因子模型(簡寫為HeSi),該模型綜合考慮了異構社交信息與區域傾向性,有效地解決了事件推薦問題。實驗表明,我們所設計的HeSi算法在解決事件推薦問題時比傳統的算法在精度上提高了近5%。
2 基于事件的社交網絡數據分析
在本文中,我們選擇Meetup數據集作為重點分析對象。Meetup網站是世界知名的EBSN應用,該數據集主要取自Meetup網站的用戶對線下活動的參與行為的數據。IBM研究人員在采集和清洗后開源了該數據集供研究者使用,并在KDD-12[5]中針對以Meetup網站為代表的一類EBSN應用做了詳細的數據分析工作。該論文的研究成果表明線下事件與參與者多在同一個地理區域。因此,我們從該數據集中選取五個有代表性的城市進行數據分析,(包括紐約、洛杉磯、休斯頓、芝加哥和舊金山)。首先,統計這些城市中的用戶和事件數量,如表1所示;然后,分析數據集的地域特性和異構社交關系特性。數據分析結果將在下文進行詳細介紹。

表1 數據集信息統計[6]
2.1 地域特性
在文獻[6]中,作者清洗并獲得了北美五座城市的事件數據(表1),并對基于事件的社交網絡數據的地域特征做了詳細的分析,圖1展示了休斯頓 數據的聚類結果。直觀上來看,每個類簇內的大多數事件呈中央集中型分布,同一顏色的點越密集表示該區域內發生的事件越多。采用均值法求出每個類簇的中心點坐標,發現中心點所在區域大多位于休斯頓當地的步行街、購物中心等繁華場所。因此,本文提出假設,社交事件一般發生在繁華區域并以這些區域為中心呈集中型分布。
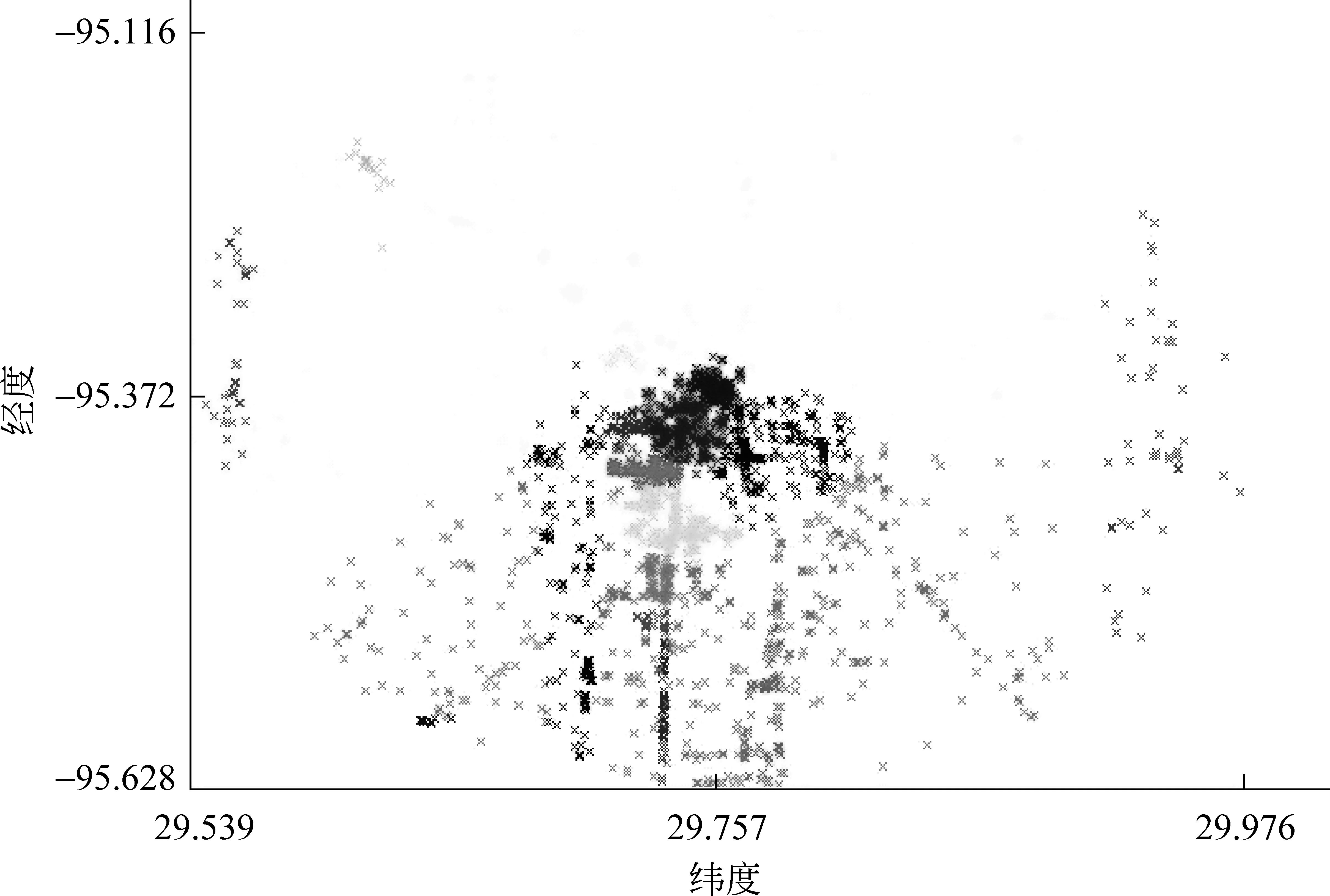
圖1 基于事件地理坐標的休斯頓數據的聚類分析注: 置類簇數目為20,將不同類簇的事件用不同顏色進行標記;每一個點表示在該城市內組織的一個事件,橫縱坐標分別表示緯度和經度,相同顏色的點表示從屬同一個聚類[6]
區域傾向性 線下事件區域呈集中性特點的基礎上,在文獻[6]中,作者又進一步分析數據發現了區域傾向性。假設將每一個類簇看作一個區域,那么每個城市均被劃分為20個區域,以用戶為關注點,我們分別統計每個城市中用戶參與事件的行為數據。分析結果表明: (1)超過80%以上的用戶僅訪問了不到六個區域,如圖2所示; (2)大多數用戶對每個訪問區域的平均訪問次數超過一次,如圖3所示。可見,用戶對不同區域事件的參與并不是隨機的,而是帶有明顯的個體傾向性,即較頻繁地訪問自己感興趣的區域。
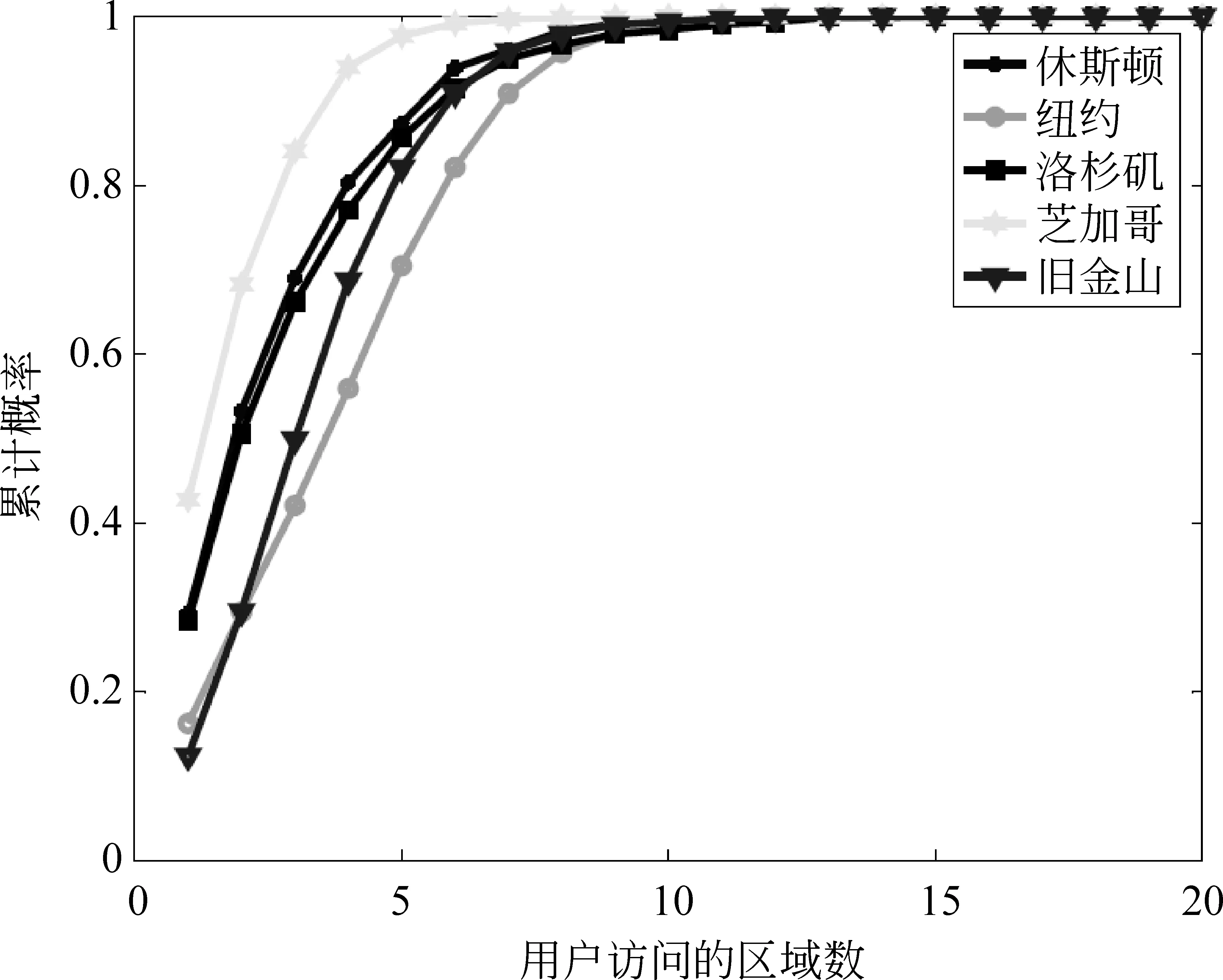
圖2 用戶訪問區域數的累計概率[6]
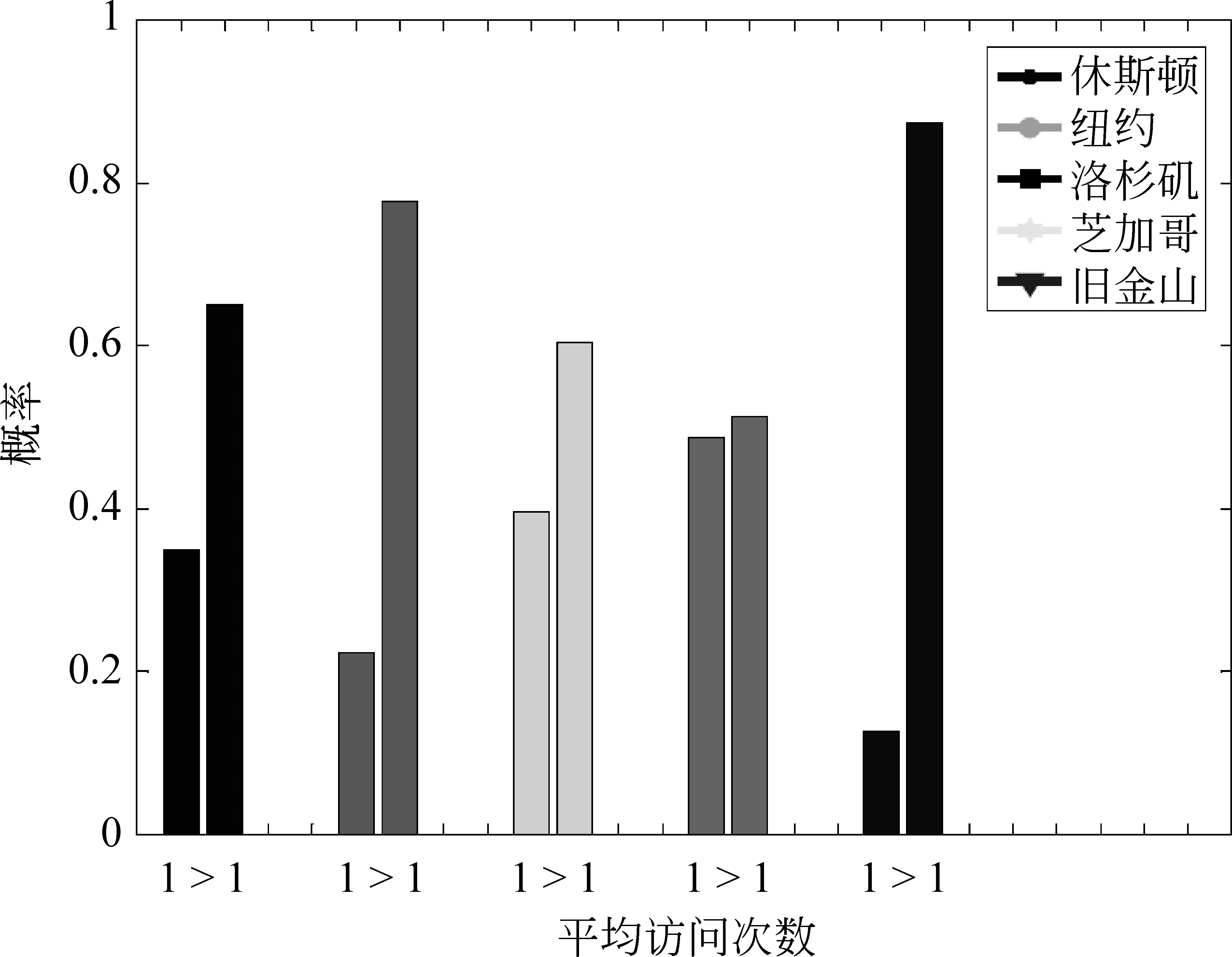
圖3 用戶平均訪問次數在1和>1兩種情況下的概率分布[6]
2.2 異構社交關系
針對本文的事件推薦任務,我們首先定義三種實體集合,包括用戶U、事件V和事件位置VL,以及兩種異構的社交網絡: 線上社交網絡Gon和線下社交網絡Goff。其中U={u1,u2,…,un}表示用戶集合,V={v1,v2,…,vm}表示事件集合,對于每一個事件vi都具有描述該事件的位置信息。線上社交網絡Gon描述所有用戶的線上社交關系,線下社交網絡Goff描述所有用戶的線下社交關系。
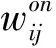
(1)
其中,G(ui)表示任意用戶ui參與的線上社交組的集合;|G(ui)∩G(uj)|表示用戶ui和uj參與的相同社交組的數量;分母|G(ui)∪G(uj)|表示用戶ui和uj各自參與的社交組的并集的基數。
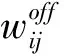
(2)
其中,E(ui)表示用戶ui參與的線下事件的集合;|E(ui)∩E(uj)|表示用戶ui和uj參與的相同線下事件的數量;分母|E(ui)∪E(uj)|表示用戶ui和uj各自參與的事件并集的基數。
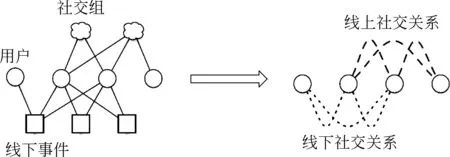
圖4 EBSN中的異構社交關系
2.3 問題定義
事件推薦任務旨在為用戶推薦其可能感興趣的事件。本文將推薦問題轉變為排序問題,即根據用戶對于各個事件的感興趣程度對事件排序,將排名靠前的事件推薦給用戶。因此,事件推薦的核心任務即如何估計用戶對事件的感興趣程度。我們定義評分r(ui,vj)度量用戶ui對事件vj的感興趣程度。基于本節數據分析結果,我們提出了一種基于矩陣因子分解技術的混合評分模型,將區域傾向性特征和異構社交關系特征引入興趣評估模型。矩陣因子分解模型是一種簡單、實用、高效的方法,可以靈活內嵌異構屬性,目前已被廣泛應用。我們希望通過引入兩種新的特征來提高事件推薦的性能。
3 相關工作
近年來,推薦問題已經受到了國內外研究者的廣泛關注。推薦算法可大致分為基于上下文的推薦和協從過濾兩大類。其中矩陣因子分解模型被廣泛地應用到推薦系統應用中并獲得了較好的性能。在矩陣因子分解模型中,通過計算模型預測值與實際值的差值來度量估計誤差,如下式所示。
(3)
其中第一項為最小二乘的誤差評估函數,r(ui,vj)是模型預測值,Rij是實際評分值,Iij是指示變量,用來描述用戶ui是否參與了對事件vj的評分;為防止過擬合,我們引入了兩項正則化項‖Ui‖2和‖Vj‖2,它們分別是變量Ui和Vj的二范式。
目前,隨著各種新型網絡應用的出現和發展,為了應對新型網絡特征帶來的挑戰,推薦算法得到了進一步的增強和改進[6-12]。這些研究工作將多種新特征引入到推薦算法中從而提高推薦精度,包括社交關聯、地理信息等。
引入社交關聯的推薦算法主要包括基于社交關系的協從過濾和通過社交正則對評分行為做糾正的方法[13-16]。Fengkun Liu等[14]將社交關系應用于用戶間相似度的計算,提出了一種新型的協從過濾算法。該算法與傳統的基于行為相似度的協從過濾算法相比可以獲得精度的提升;然而當評分數據較稀疏時,算法性能并沒有明顯的優勢。Irwin King等[15]將用戶看作節點,將社交關系看作節點間的關聯提出了一種基于連續條件隨機場的社交推薦框架,以高昂的時間開銷換取了較高的精度。Hao Ma等[16]提出了一種社交正則的協從推薦方法,巧妙地將社交關系引入矩陣因子分解模型從而有效提高了算法精度。因此,在本文中,我們也采用社交正則的方法,將異構社交關系引入誤差函數,對模型參數作糾正。
考慮地理信息的推薦算法主要包括基于距離的協從推薦和面向位置信息的用戶行為傾向建模[17-23]。移動互聯網的興起使人們意識到位置信息對于用戶行為估計的影響,因此協從地理位置信息的推薦算法研究得到了廣泛的關注。其中,大多數研究工作僅依據位置信息進行推薦,例如S Chaudhuri等[24]采用KNN方法為用戶推薦最近的其他用戶信息。然而,在事件推薦問題中,推薦的核心在于事件位置信息只是輔助問題研究的特征之一。另外,有一類研究工作探索位置信息對于推薦性能的影響,例如N Bruno等[25]提出了Top-K的改進算法為用戶推薦距離較近的商品;Peng Zhang等[27]使用用戶的地理位置信息對用戶分組,探索不同用戶組對于商品類別的傾向性,提出了新型的評分算法。然而基于位置的用戶分組并不適用于基于事件的社交網絡中的事件推薦任務,相比之下基于位置的事件分組所呈現的用戶行為具有更明顯的區域傾向的特征。
我們基于事件推薦問題特有的數據特點,嘗試聯合建模地域特性和社交關系兩種特征提高推薦算法的性能。
4 聯合建模地域特性和社交關系的事件推薦框架
4.1 混合評分
為了便于聯合建模用戶個體興趣與區域傾向,我們使用文獻[6]中的混合評分模型,它由個體興趣評分和區域傾向評分兩部分加權生成。
(4)
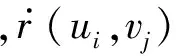
個體興趣評分 類似于基于矩陣分解的潛在因子模型,假設因子向量的維度為l,定義每一個用戶ui有一個潛在的維因子向量Ui∈Rl,每一個事件vj也有一個潛在的l維因子向量Vj∈Rl。我們將因子空間看作興趣空間,使用因子向量描述用戶或事件在因子空間的投影,那么用戶的個體特性決定了其在因子空間的興趣分布,線下事件在因子空間的投影反應了事件的興趣分布。因此,可以使用向量內積來計算用戶對于事件的個體興趣評分,如下所示:
(5)
區域傾向評分 由于用戶對事件所處地理位置的喜好也會影響用戶參與該事件的行為傾向,因此我們我們需要對用戶的區域傾向性進行評價。通過2.1節的數據分析,我們發現事件呈區域集中式分布,即是圖中同種顏色的類簇由中心向外的發散特點。分析類簇中心點所在的具體位置,發現類簇多集中在城市內的商業街或金融街一類繁華的地段。因此,可以將事件聚類結果看作對相應城市的區域劃分。我們可以使用聚類的方法獲得事件的近似區域。我們使用文獻[6]中區域傾向評分的建模方式去建模此處的區域傾向評分。與個體興趣評分類似,我們為每一個用戶ui定義區域相關的因子向量Πi,為每個區域定義區域相關的因子向量Mk。用向量Πi和Mk的內積表示用戶ui對第k個區域的傾向評分。由于事件類簇只是對實際區域的近似,因此我們引入從屬因子Cjk來表示第j個事件屬于第k個區域的概率。最終,用戶對區域的傾向性評分是通過對事件所處各個區域的評分加權求得的,賦予權值的依據是事件對區域的從屬概率。
(6)
為了求解Cjk,我們首先假設每一個區域內的事件呈高斯分布,定義參數(μ,∑)描述區域特征,其中μ表示均值向量,∑表示協方差矩陣。因此,可以通過式(7)對Cjk進行求解。
(7)
其中,N(Li|μk,Σk)表示用戶ui的位置Li出現在區域k的概率密度。
4.2HeSi模型
鑒于矩陣因子分解模型在精度和效率等方面的優越性,我們將上一節中的混合評分函數嵌入矩陣因子分解模型中,誤差評估函數中的模型預測值采用式(4),并為參數Π和M增加二范式正則項以便約束參數的取值范圍。從而獲得以下目標函數。
(8)

(9)
HeSi目標優化函數 將異構社交正則[見公式(8)]應用到基于混合評分的矩陣因子分解模型[見公式(9)]中, 獲得最終的目標優化函數,如式(10)所示。
(10)
4.3 參數學習
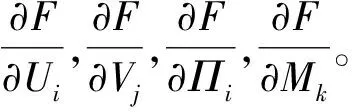
5 實驗結果及分析
本節主要通過使用真實網絡應用數據集來驗證事件推薦算法的性能。在本節中,首先介紹實驗數據集和評價指標,然后介紹對比方法,最后對實驗結果進行討論。
5.1 數據集
我們主要采用Meetup數據集作為我們的實驗數據集。如文章第三部分所示,我們首先抽取出美國五座代表型城市的相關數據構造五個實驗數據集合,每座城市的數據集合包括該城市內注冊的用戶、注冊的事件以及發生的參與行為。數據的詳細信息已在表1中詳細闡述。
5.2 評價指標
為了便于評價事件推薦算法的性能,我們采用三種標準的評價方法AUC、P@k以及MAP。
1) AUC評價方法可以用來度量整體的分類結果。在本實驗數據集中未評分事件占較大比例,AUC評價方法恰適合于不平衡數據。具體計算過程如式(9)所示。
(19)

2) P@k指Top-k個估計值中正確估值的比例,多用于排序問題。在事件推薦任務,把評分較高的事件推薦給用戶,也可看作為排序問題。
3) MAP是P@k的均值,指算法在選擇不同Top-k時的精度的均值,可根據式(20)計算。
(20)
其中L(u)描述采用模型估計出的用戶u對各個事件評分的降序排列,Lk(u)描述這個排序中興趣度第k大的事件,函數I是指示函數。

算法1:HeSi模型學習輸入:評分數據R、線上社交關系Won、線下社交關系Woff、地理位置信息、參數Θ、區域數K輸出:用戶興趣因子U、事件興趣因子V、用戶區域傾向因子Π、區域因子M01 初始化模型參數U,V,Π,M02 使用K?Means算法聚類事件產生K個區域03 計算每個區域的特有參數(μ,∑i),i=1,…,K04 計算事件與區域的從屬概率Cij,參見公式(7)

05 定義并初始化變量P=006 計算當前參數下模型誤差值Q(使用公式(8)的第一部分)07 WhileQ-P>ε08 P=Q09 采用公式計算目標函數在當前參數值下的偏導數,參見公式(15)~(18)10 采用公式更新模型參數,參見公式(11)~(14)11 計算模型誤差值Q12 EndWhile13 返回當前的參數值計算模型誤差值Q14 EndWhile
5.3 對比方法
我們使用以下四種模型與Hesi模型進行對比,它們分別是: 1)矩陣因子分解(MF)[26]; 2)基于社交正則的矩陣因子分解(MFs); 3)基于異構社交正則的矩陣因子分解(MFh); 4)基于區域傾向的矩陣因子分解(gMF)。
5.4 實驗結果
參數α討論 在混合評分中,參數α聯合個體興趣評分和區域傾向評分,并決定兩種評分的比重,見等式(4)。因此,我們首先討論參數α的取值對于模型性能的影響。此處,使用AUC評價方法,在五個數據集上,分別測試模型在不同的α取值(0.91~0.99)下,模型精度的變化。實驗結果顯示圖5中。如圖所示,在五個數據集上,模型精度伴隨著α取值的變化而輕微變化,在0.95附近出現明顯的波動,并取得近似局部最優值。因此,在后邊的實驗中,我們定義α取值為0.95。
整體性能評價 為了便于驗證算法整體的分類性能,我們首先在五個實驗數據集上,使用AUC評價標準,對比HeSi算法與其他四種算法的性能優劣。實驗結果如表2所示。從實驗結果中,我們可以發現以下五個特征: 1)矩陣因子分解的算法可以獲得比基于用戶/對象相似度的協從過濾算法更高的精度; 2)使用社交正則后的矩陣因子分解算法的性能優于未使用社交正則的矩陣因子分解算法; 3)異構社交正則的方法除了增加了線上社交關系的約束也增加了線下社交關系的約束,比起單純使用線上社交關系有更好性能; 4)只使用基于區域傾向的矩陣因子分解算法在性能上比其他算法并沒有明顯優勢; 5)基于混合個體興趣與區域傾向性的矩陣因子分解方法在異構社交正則的約束下可以獲得更好的性能。
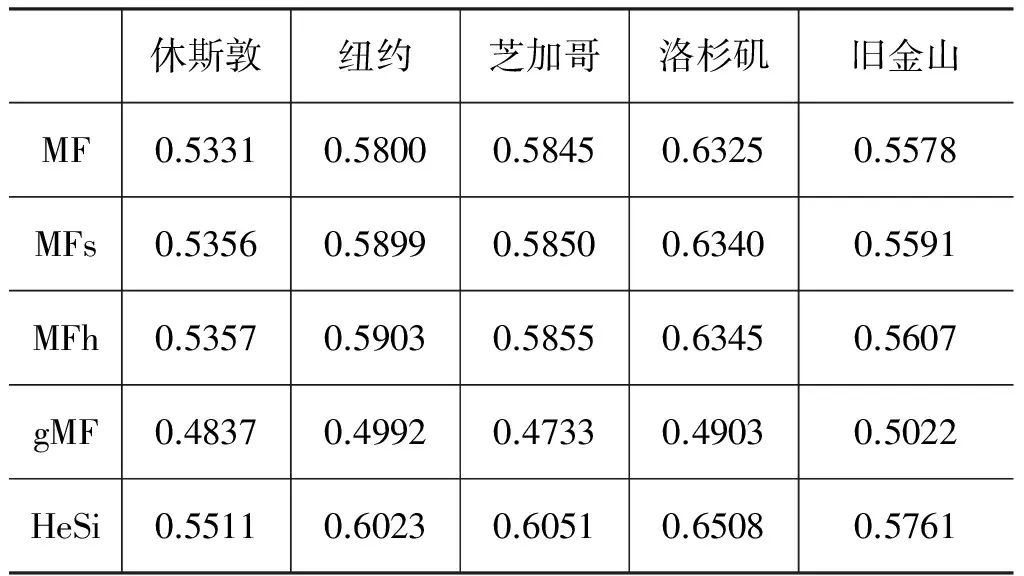
表2 AUC度量的算法準確度評價
推薦結果評價 在真實的應用場景中,用戶關注的是被展示的推薦結果,它的準確與否決定了用戶體驗的優劣。因此,我們采用P@k和MAP方法去評價幾個算法的推薦性能。鑒于頁面信息的豐富性和用戶瀏覽的隨機性,用戶通常僅對排名靠前的結果感興趣而忽略大量剩余的推薦結果,因此我們主要測試了P@1和P@3。此外,我們使用MAP評價算法整體的推薦結果。在之前的性能評價中,我們已經發現矩陣因子分解算法在性能上的優勢。因此,我們只是比較HeSi算法和MF、MFh兩種算法,實驗結果如圖6,7,8,9,10所示,采用P@1、P@3和MAP三種指標進行評價,HeSi算法比其他三種算法能得到更好的推薦性能。
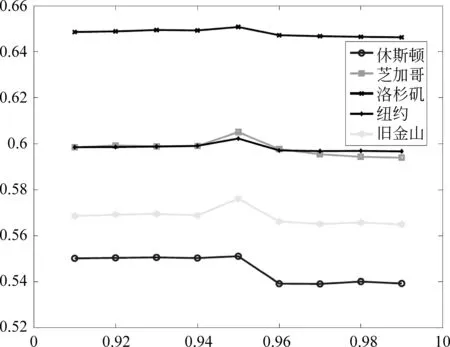
圖5 混合因子α在不同取值下對于模型AUC精度的影響
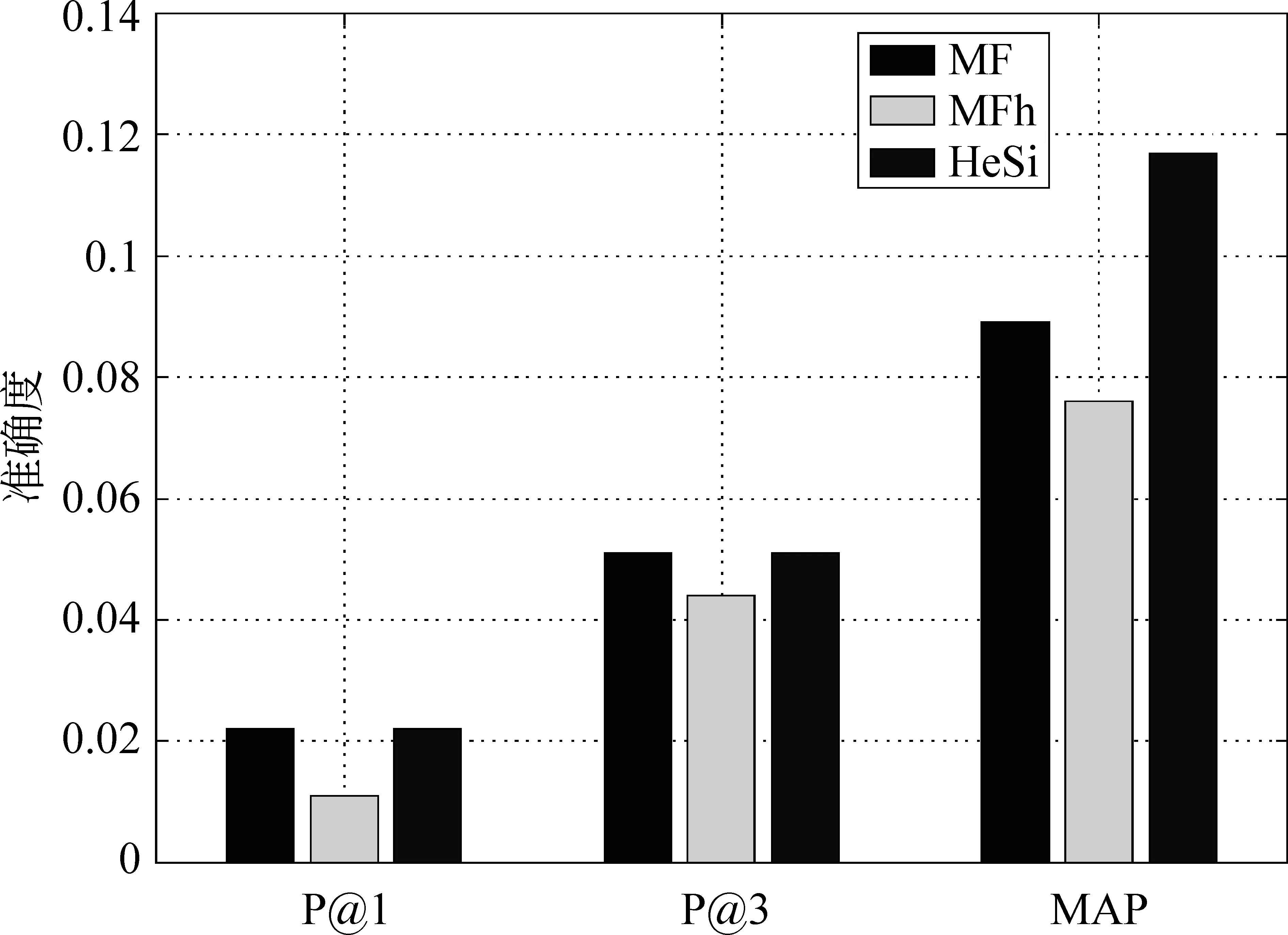
圖6 休斯敦數據集在三種不同評價下的算法精度度量
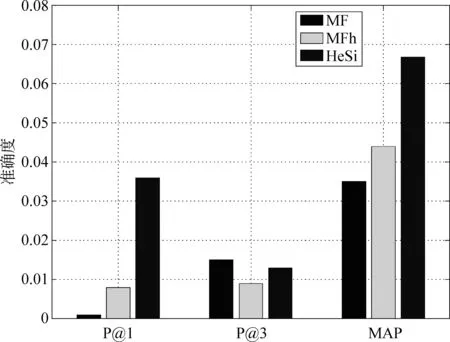
圖7 芝加哥數據集在三種不同評價下的算法精度度量
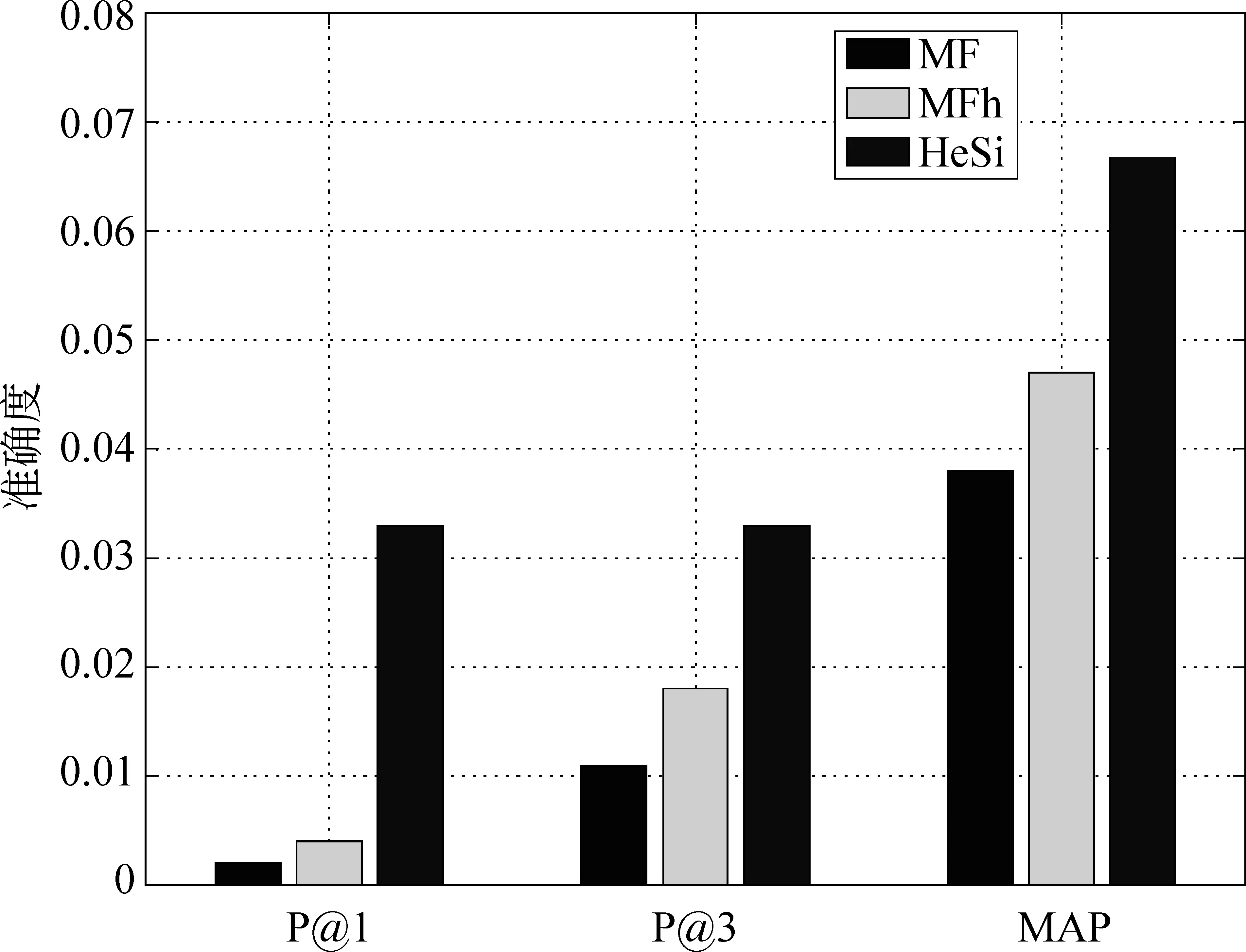
圖8 洛杉磯數據集在三種不同評價下的算法精度度量
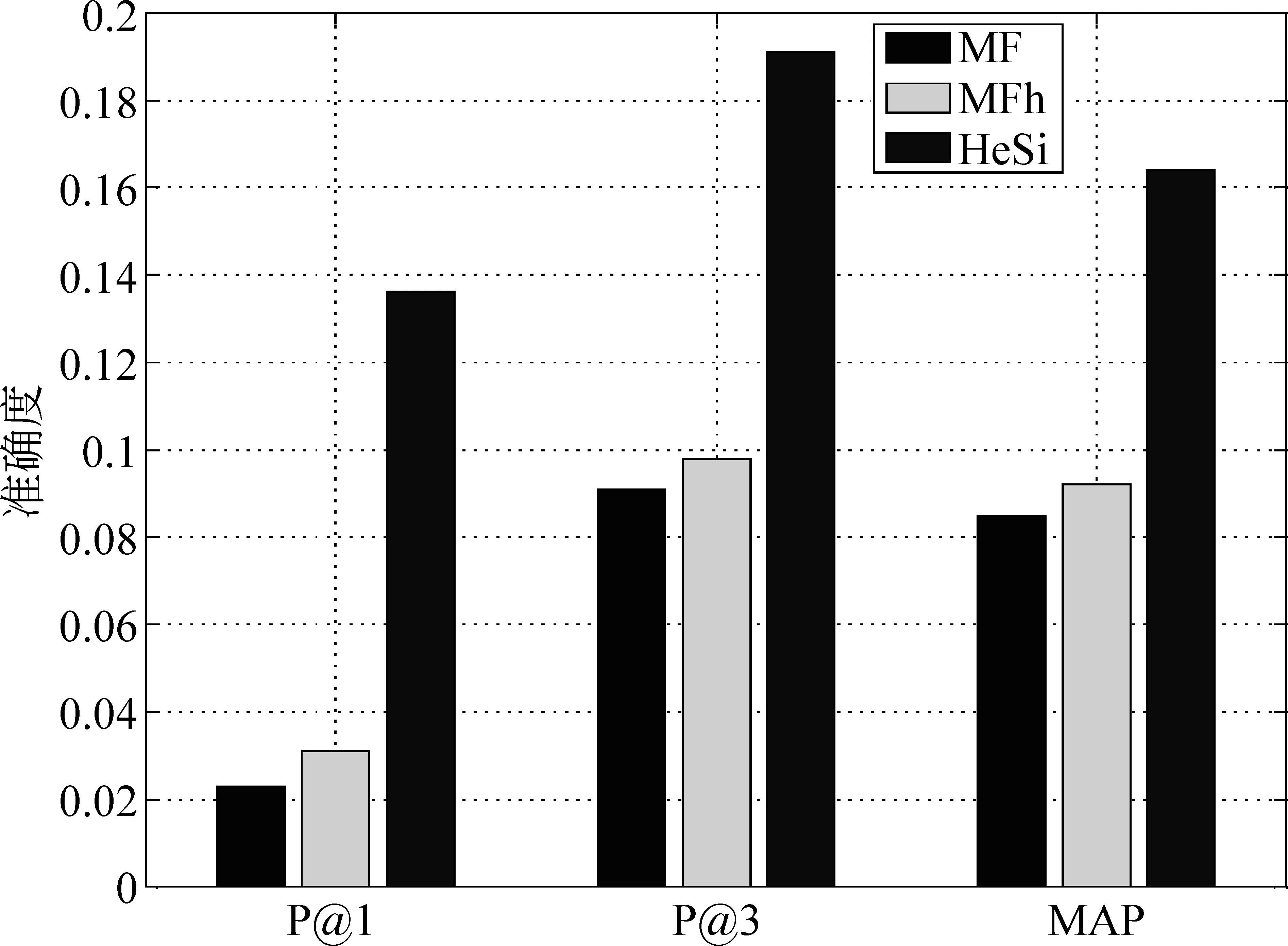
圖9 紐約數據集在三種不同評價下的算法精度度量
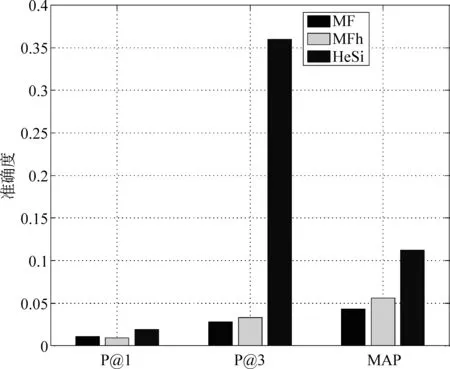
圖10 舊金山數據集在三種不同評價下的算法精度度量
6 結論及展望
本文主要探索了社交網絡應用中的事件推薦問題。首先,通過分析Meetup數據,發現了EBSN數據的社交關系異構性和區域傾向性。然后,針對這些屬性我們提出了融合地理特征和社交關系的HeSi模型,有效地提高了事件推薦的性能。
然而,在真實的應用場景中,新用戶行為數據以數據流的形式持續實時到達,數據規模逐步增大。批處理學習難以應對流式數據的挑戰。因此,在未來的研究工作中,我們主要關注事件推薦算法的在線學習策略。
[1] 彭澤環,孫樂,韓先培,石貝. 基于排序學習的微博用戶推薦[J].中文信息學報, 2013, 27(4):96-102.
[2] 孫建凱,王帥強,馬軍. Weighted-Tau Rank:一種采用加權Kendall Tau的面向排序的協同過濾算法[J].中文信息學報, 2014, 28(1): 33-40.
[3] 羅成,劉奕群,張敏,馬少平,茹立云,張闊. 基于用戶意圖識別的查詢推薦研究[J].中文信息學報, 2014, 28(1): 64-72.
[4] 李銳,王斌.一種基于作者建模的微博檢索模型[J].中文信息學報, 2014, 28(2): 136-143.
[5] Liu X, Hey Q, Tiany Y, et al. Event-based social networks linking the online and offline social worlds[C]//Proceeding of the 18th ACM SIGKDD international conference on knowledge discovery and data mining, 2012: 1032-1040.
[6] Qiao Z, Zhang P, Cao Yanan,et al. Combining Heterogeneous Social and Geographical Information for Event Recommendation[C]//Proceeding of 28th AAAI Conference on Artificial Intelligence, 2014: 145-151.
[7] Salakhutdinov R, Mnih A. Probabilistic matrix factorization[C]//In Neural Information Processing Systems, 2008: 880-887.
[8] Somekh O, Aizenberg N, Koren Y. Build your own music recommender by modeling internet radio streams[C]//Proceedings of the 21st international conference on World Wide Web, 2012: 1-10.
[9] Wang C, Blei D M. Collaborative topic modeling for for recommending scientific articles[C]//Proceeding of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, 2011: 448-456.
[10] Zhang P, Zhou C, Wang P,et al. E-tree: An efficient indexing structure for ensemble models on data streams[J]. IEEE Transactions on Knowledge and Data Engineering, 2015, 27(2): 461-474.
[11] Rendle S, Freudenthaler C, Gantner Z,et al. Bpr: Bayesian personalized ranking from implicit feedback[C]//Proceeding of the 25 Conference on Uncertainty in Artificial Intelligence, 2009: 452-461.
[12] Pan W, Xiang E, Yang Q. Transfer learning in collaborative filtering with uncertain ratings[C]//Proceeding of Twenty-Sixth AAAI Conference on Artificial Intelligence, 2012: 662-668.
[13] Ma H, Yang H, Lyu M R,et al. SoRec: social recommendation using probabilistic matrix factorization[C]//Proceeding of the 17th ACM conference on information and knowledge management, 2008: 931-940.
[14] Liua F, and Lee H J. Use of social network information enhance collaborative filtering performance[J]. Expert Systems with Applications, 2010, 37(7): 4772-4778.
[15] Xin X, King I, Deng H,et al.A social recommendation framework based on multi-scale continuous conditional random fields[C]//Proceeding of the 18th ACM conference on information and knowledge management, 2009: 1247-1256.
[16] Ma H, Zhou D, Liu C, et al.Recommender systems with social regularization[C]//Proceeding of the 4 ACM international conference on Web search and data mining, 2011:287-296.
[17] Lu Y, Tsaparas P, Ntoulas A,et al. Exploiting social context for review quality prediction[C]//Proceeding of the 19th International Conference on World Wide Web, 2010: 691-700.
[18] Cheng C, Yang H, King I,et al. Fused matrix factorization with geographical and social influence in location-based social networks[C]//Proceeding of the 26 AAAI Conference on Artificial Intelligence, 2012: 542-548.
[19] Ye M, Yin P Y, Lee W-C L,et al. Exploiting geographical influence for collaborative point-of-interest recommendation[C]//Proceeding of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2011: 325-334.
[20] Zheng V W, Zheng Y, Xie X, et al. Collaborative location and activity recommendations with gps history data[C]//Proceeding of the 19th international conference on World Wide Web, 2010: 1029-1038.
[21] Qiao Z, Zhang P, He J,et al. Combining geographical information of users and content of items for accurate rating prediction[C]//Proceeding of 23rd International World Wide Web Conference, 2014: 361-362.
[22] Takeuchi Y, Sugimoto M. Cityvoyager: An outdoor recommendation system based on user location[J]. ubiPCMM, 2005, 4(3):625-636.
[23] Borzsonyil S, Kossmann D, Stocker K. The skyline operator[C]//Proceeding of 17th International Conference on Data Engineering, 2011:421-430.
[24] Chaudhuri S, Gravano L. Evaluating top-k selection queries[C]//Proceeding of the 25th International Conference on Very Large Data Bases, 1999: 397-410.
[25] Bruno N, Gravano L, Marian A. Evaluating top-k queries over web-accessible databases[J]. In ACM Transactions on Database Systems, 2004, 29(2): 369-369.
[26] Koren Y, Bell R, Volinsky C. Matrix factorization technology for recommendation system[J]. Journal of Computer, 2009, 42(8), 30-37.
Event Recommendation Based on Geographical Features and Heterogeneous Social Relationships
QIAO Zhi1,2, ZHOU Chuan2,3, JI Xiancai3, CAO Yanan3, GUO Li3
(1. Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190,China) (2. University of Chinese Academy of Sciences, Beijing 100049,China) (3. Institute of Information Engineering, Chinese Academy of Sciences, Beijing 100093,China)
In order to improve users’ experience in event-based social networks (EBSNs) services, the event recommendation task has been studied in the recent years. In this paper, the user motivation data of EBSN applications is analyzed, and a novel latent factor model unifying multiple data features is proposed. This method considers two new types of features, i.e., heterogeneous online& offline social relationships and regional preference of users, and applies them for event recommendation. Experimental results on real-world data sets showed our method had better performance than some traditional methods.
event recommendation; event-based social network; collaborative filtering; regional preference; heterogeneous social relationship

喬治(1986—),博士,主要研究領域為數據挖掘。E?mail:qxs1986@126.com周川(1984—),博士,副研究員,主要研究領域為社會計算。E?mail:zhouchuan@iie.ac.cn紀現才(1976—),博士研究生,主要研究領域為數據挖掘與機器學習。E?mail:jixiancai@iie.ac.cn,
1003-0077(2016)05-0047-10
2015-03-09 定稿日期: 2015-07-22
國家重點基礎研究發展計劃(973計劃)(2013CB329605);國家自然科學基金(61502479,61403369);中國科學院戰略先導科技專項(XDA06030200)
TP
A
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
