基于訓(xùn)練樣本集擴展的隱式篇章關(guān)系分類
2016-05-04 02:43:07朱珊珊丁思遠嚴為絨姚建民朱巧明
中文信息學(xué)報 2016年5期
朱珊珊,洪 宇,丁思遠,嚴為絨,姚建民,朱巧明
(蘇州大學(xué) 江蘇省計算機信息處理技術(shù)重點實驗室,江蘇 蘇州 215006)
基于訓(xùn)練樣本集擴展的隱式篇章關(guān)系分類
朱珊珊,洪 宇,丁思遠,嚴為絨,姚建民,朱巧明
(蘇州大學(xué) 江蘇省計算機信息處理技術(shù)重點實驗室,江蘇 蘇州 215006)
隱式篇章關(guān)系分類主要任務(wù)是在顯式關(guān)聯(lián)線索缺失的情況下,自動檢測特定論元之間的語義關(guān)系類別。前人研究顯示,語言學(xué)特征能夠有效輔助隱式篇章關(guān)系的分類。目前,主流檢測方法由于缺少足夠的已標注隱式訓(xùn)練樣本,導(dǎo)致分類器無法準確學(xué)習(xí)各種分類特征,分類精確率僅約為40%。針對這一問題,該文提出一種基于訓(xùn)練樣本集擴展的隱式篇章關(guān)系分類方法。該方法首先借助論元向量,以原始訓(xùn)練樣本集為種子實例,從外部數(shù)據(jù)資源中挖掘與其在語義以及關(guān)系上一致的“平行訓(xùn)練樣本集”;然后將“平行訓(xùn)練樣本集”加入原始訓(xùn)練樣本集中,形成擴展的訓(xùn)練樣本集;最后基于擴展的訓(xùn)練樣本集,實現(xiàn)隱式篇章關(guān)系的分類。該文在賓州篇章樹庫(Penn Discourse Treebank, PDTB)上對擴展的訓(xùn)練樣本集進行評測,結(jié)果顯示,相較于原始訓(xùn)練樣本集,使用擴展的訓(xùn)練樣本集的實驗系統(tǒng)整體性能提升8.41%,在四種篇章關(guān)系類別上的平均性能提升5.42%。與現(xiàn)有主流分類方法性能對比,識別精確率提升6.36%。
隱式篇章關(guān)系;語義向量;訓(xùn)練樣本集擴展;篇章分析
1 引言
篇章關(guān)系研究任務(wù)旨在推理特定文本跨度范圍內(nèi)論元(即具有獨立語義的文字片段,包括子句、句子或文本塊等)之間的語義連接關(guān)系。賓州篇章樹庫(Penn Discourse Treebank, PDTB)[1-2]根據(jù)兩個論元(即“論元對”)之間是否存在連接詞,將篇章關(guān)系分成顯式篇章關(guān)系(Explicit Discourse Relation)和隱式篇章關(guān)系(Implicit Discourse Relation)。此外,PDTB又將具體的篇章關(guān)系類型分為三層,第一層包括四種主要篇章關(guān)系: Temporal(時序關(guān)系)、Expansion(擴展關(guān)系)、Comparison(對比關(guān)系)和Contingency(偶然關(guān)系);第二層和第三層分別針對上一層進行細分。例1給出兩種篇章關(guān)系實例,其中1(a)為顯式篇章關(guān)系實例,可直接通過連接詞“so”推理“論元對”的篇章關(guān)系類型為偶然關(guān)系;1(b)為隱式篇章關(guān)系實例,論元之間不存在連接詞,但結(jié)合上下文以及句子結(jié)構(gòu)等信息,可間接推理“論元對”的篇章關(guān)系類型為對比關(guān)系,因而可在“論元對”中插入連接詞“but”用來表示對比關(guān)系。
例1 (a) Arg1: I got up late.
<譯文: 我起床晚了>
Arg2: 【Explicit=So】I was late for work.
<譯文: 【所以】我上班遲到了>
篇章關(guān)系 =“Contingency(偶然關(guān)系)”
(b) Arg1: He loves cats.
<譯文: 他喜歡貓>
Arg2: 【Implicit=But】I hate cats.
<譯文: 【但是】我討厭貓>
篇章關(guān)系 = “Comparison(對比關(guān)系)”
目前,顯式篇章關(guān)系的研究已獲得較優(yōu)的分類性能。Pilter等[3]借助“顯式連接詞—篇章關(guān)系”之間的一一映射進行顯式篇章關(guān)系分類,最終分類性能為93.09%。相對地,隱式篇章關(guān)系分類精確率仍然較低。分析原因可知,隱式篇章關(guān)系樣本中,論元之間缺失連接詞, 無法直接判定篇章關(guān)系,需通過上下文、語義結(jié)構(gòu)以及句子特征等其他信息間接推理隱式關(guān)系。然而,上下文信息的不確定性、語義結(jié)構(gòu)的復(fù)雜性以及句子特征的歧義性,往往制約隱式篇章關(guān)系的有效判定。
傳統(tǒng)的隱式篇章關(guān)系檢測方法主要采用基于語言學(xué)特征的分類方法,通過自然語言處理技術(shù)抽取論元中的各種特征(例如,情感詞極性,動詞短語長度,單詞對,句法規(guī)則等)。然而,該方法分類性能仍然偏低,究其原因,發(fā)現(xiàn)存在如下兩個問題。
1) 人工標注的隱式訓(xùn)練樣本數(shù)量有限,訓(xùn)練語料中包含的特征信息不充分,難以有效學(xué)習(xí)各篇章關(guān)系的語言學(xué)特征;
2) 隱式訓(xùn)練樣本中各篇章關(guān)系類別分布不平衡,導(dǎo)致模型訓(xùn)練出現(xiàn)偏差,在少數(shù)類別上分類精度較低,影響了分類器的整體分類性能。
本文針對篇章關(guān)系語料分布不平衡,及其引起的關(guān)系檢測模型訓(xùn)練存在偏見的問題,提出一種基于論元向量的隱式訓(xùn)練樣本集擴展方法。該方法首先將所有實例表示成固定長度且具有實值的向量,然后以PDTB標注的隱式篇章關(guān)系實例(即原始訓(xùn)練樣本集)為種子實例,從大規(guī)模同領(lǐng)域數(shù)據(jù)資源中挖掘與其內(nèi)容近似且關(guān)系相同的隱式“論元對”(簡稱為平行“論元對”),將平行“論元對”加入到原始訓(xùn)練樣本集中,獲得擴展的訓(xùn)練樣本集(即原始訓(xùn)練樣本集+所有平行“論元對”)。基于擴展的訓(xùn)練樣本集,本文在前人基于語言學(xué)特征的隱式篇章關(guān)系分類方法的基礎(chǔ)上,借助自然語言處理技術(shù),抽取所有實例的動詞、單詞對、產(chǎn)生式規(guī)則以及依存規(guī)則特征,使用LIBSVM分類器訓(xùn)練特征分類模型,最終在測試樣本上進行性能評測,實現(xiàn)隱式篇章關(guān)系的分類。
本文的組織結(jié)構(gòu)如下: 第二節(jié)概述相關(guān)工作;第三節(jié)介紹篇章檢測任務(wù)定義及數(shù)據(jù)分析;第四節(jié)介紹本文基于論元向量的隱式訓(xùn)練樣本集擴展方法;第五節(jié)介紹基于擴展的訓(xùn)練樣本集的隱式篇章關(guān)系分類方法;第六節(jié)給出實驗結(jié)果及相關(guān)分析;第七節(jié)總結(jié)全文。
2 相關(guān)工作
Pitler等[4]首次單獨針對PDTB中隱式篇章關(guān)系進行分類,采用全監(jiān)督的篇章關(guān)系分類方法訓(xùn)練分類器,使用情感詞極性、動詞短語長度、動詞類型、句子首尾單詞和上下文等特征進行關(guān)系分類,最終分類結(jié)果優(yōu)于隨機分類的性能。Lin等[5]繼承了Pitler等的方法體系,細化了上下文特征的采集技術(shù),使用了句法樹的結(jié)構(gòu)特征與依存特征;同時,結(jié)合Soricut等[6]提出的論元內(nèi)部結(jié)構(gòu)特征,在PDTB第二層隱式關(guān)系分類上獲得了40.20%的精確率。隨后,Wang等[7]基于卷積樹核函數(shù)提升了句法結(jié)構(gòu)特征的區(qū)分能力,但性能并沒有顯著的提升(精確率約40.00%),僅略優(yōu)于以淺層句法樹為特征的關(guān)系分類性能。Zhou等[8]使用三元文法模型搜索與隱式“論元對”一致的表達模式,在相鄰論元間插入合適的連接詞,借助顯式關(guān)系預(yù)測隱式關(guān)系,相比于Saito等,該方法不局限于語法的規(guī)范,滿足了詞特征相互組合的連貫性和靈活性,但是其性能僅在偶然和時序關(guān)系上有所提升,對擴展和比較關(guān)系的分類性能仍然偏低。Park等[9]提出特征集合優(yōu)化的方法,通過前向選擇算法使用情感詞極性、句子首尾單詞、產(chǎn)生式規(guī)則等特征進行特征融合,最終分類性能在四種篇章關(guān)系類別上獲得顯著提升。Lan等[10]提出多任務(wù)學(xué)習(xí)的隱式篇章關(guān)系分類方法,在交互結(jié)構(gòu)優(yōu)化(ASO)多任務(wù)學(xué)習(xí)框架下,抽取論元的動詞、極性等語言學(xué)特征,基于不同類型的訓(xùn)練樣本,訓(xùn)練主分類器及輔助分類器,最終推理性能達到42.30%。近期Li等[11]通過挖掘中英文之間的篇章結(jié)構(gòu)關(guān)系,借助已有的英文篇章關(guān)系語言學(xué)資源,有效地提升了中文隱式篇章關(guān)系的分類性能。
上述各隱式篇章關(guān)系分類系統(tǒng)均是通過挖掘有效的語言學(xué)特征,利用分類器進行隱式篇章關(guān)系分類,使用的語料均為PDTB隱式數(shù)據(jù)集。但并未有效提升隱式篇章關(guān)系的分類性能,整體分類性能仍維持在40%左右。究其原因,可發(fā)現(xiàn)上述研究均是以基于全監(jiān)督或者半監(jiān)督的方法學(xué)研究為基礎(chǔ),通過抽取各種有效的語言學(xué)特征,探索特征與具體類別之間的關(guān)系來提升分類性能,而忽略了對PDTB數(shù)據(jù)集的分析。由于PDTB數(shù)據(jù)集中各篇章關(guān)系分布不平衡(例如,Temporal關(guān)系實例僅占實例總數(shù)的5.36%),訓(xùn)練過程中,在少數(shù)類上缺少足夠的隱式訓(xùn)練樣本,分類器無法準確學(xué)習(xí)各種有效特征,導(dǎo)致分類模型出現(xiàn)偏差,影響最終的分類性能。此外,Wang等[12]進一步通過實驗證明,PDTB標注的隱式篇章關(guān)系實例中只有小部分“典型(typical)”的關(guān)系實例能夠有效地提升隱式篇章關(guān)系的分類性能,而其他實例對最終的分類性能影響較小甚至?xí)档头诸惼鞯姆诸愋阅堋T诖饲闆r下,能夠?qū)嶋H使用的隱式篇章關(guān)系實例則進一步減少。
針對數(shù)據(jù)不充分問題,早期的研究主要是使用顯式數(shù)據(jù)集資源,通過移除顯式“論元對”中的連接詞,構(gòu)造出大量的隱式“論元對”,對隱式訓(xùn)練樣本進行擴展。在此基礎(chǔ)上,基于構(gòu)造的隱式“論元對”樣本,通過分類器訓(xùn)練獲得隱式篇章關(guān)系分類模型(Marcu 等[13];Sporleder 等[14])。雖然通過此方法可以快速的獲得大量隱式訓(xùn)練樣本,然而直接移除“論元對”的連接詞,構(gòu)造出的隱式“論元對”會出現(xiàn)語義不連貫、表意不清的問題,最終實驗分類性能仍然較低。如何快速有效地對隱式訓(xùn)練樣本進行擴展,從而提升隱式篇章關(guān)系的分類性能仍是一個亟待解決的問題。對此,本文提出了一種基于論元向量的隱式訓(xùn)練樣本集擴展方法,輔助推理隱式篇章關(guān)系。
3 任務(wù)定義及數(shù)據(jù)分析
3.1 任務(wù)定義
本文的主要研究任務(wù)是對隱式訓(xùn)練樣本集進行擴展,推理論元之間的隱式篇章關(guān)系,即在沒有顯式連接詞作為直接線索的情況下,對第一層的四種篇章關(guān)系予以判定。圖1為隱式篇章關(guān)系分類任務(wù)框架圖,輸入為隱式“論元對”,輸出則為具體的篇章關(guān)系類別。
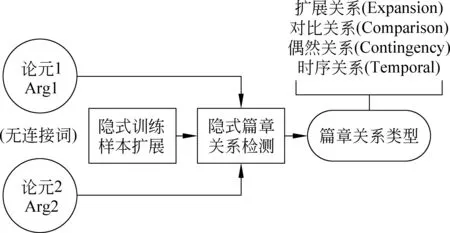
圖1 隱式篇章關(guān)系分類任務(wù)框架圖
3.2 訓(xùn)練樣本集數(shù)據(jù)分析
PDTB語料庫是2008年發(fā)布并標注具體篇章關(guān)系的語言學(xué)資源,共標注29 655個篇章關(guān)系實例,主要分為兩大類: 顯式篇章關(guān)系實例和隱式篇章關(guān)系實例。PDTB語料采用人工標注的方法,標注的“論元對”符合自然語言規(guī)律,語義信息較為明確,歧義性較小。近期的隱式篇章分類研究主要是基于該語料進行展開。然而其標注的隱式篇章關(guān)系實例數(shù)量有限(隱式篇章關(guān)系實例為13 815個),且人工標注耗時耗力,仍不足以解決隱式訓(xùn)練樣本不充分的問題。針對該問題,本文提出一種基于論元向量的方法實現(xiàn)對隱式訓(xùn)練樣本集的擴展。具體實現(xiàn)細節(jié)將在第四節(jié)進行描述。
本文選用PDTB 隱式數(shù)據(jù)集Section 00-20作為原始訓(xùn)練樣本集。表1為該訓(xùn)練樣本集中四種篇章關(guān)系類別的分布情況,從表1的統(tǒng)計結(jié)果發(fā)現(xiàn): 四種篇章關(guān)系類別分布嚴重不平衡,相較于Expansion類別,Comparison、Contingency、Temporal 三種類別的實例數(shù)量較少,實例總數(shù)僅占樣本的45.47%。在分類過程中,這種不平衡現(xiàn)象,容易導(dǎo)致分類器出現(xiàn)偏差,影響分類性能。基于此,本文對實例數(shù)量較少的三種類別: Comparison、Contingency以及Temporal進行樣本擴展,使得擴展后的訓(xùn)練樣本集的四種篇章關(guān)系比例達到平衡。
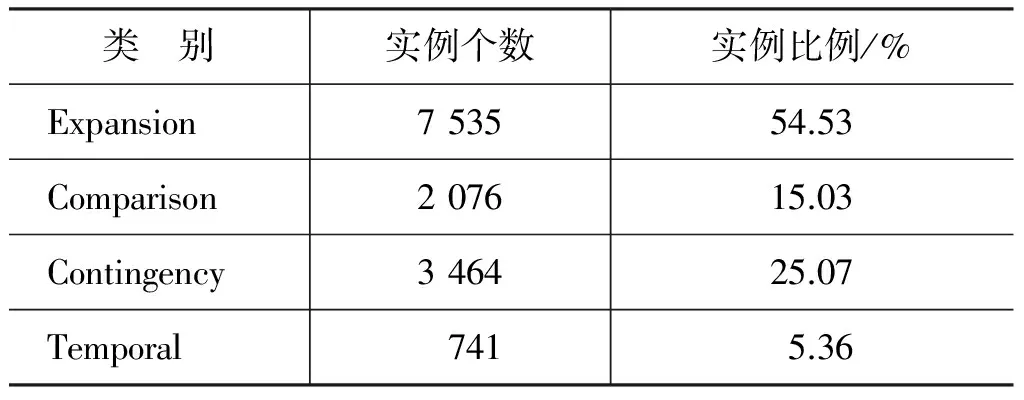
表1 PDTB 隱式數(shù)據(jù)集00-20章節(jié)四種篇章關(guān)系分布
此外,分析PDTB 隱式數(shù)據(jù)集發(fā)現(xiàn),有部分實例標注了兩種篇章關(guān)系類別,本文將這些實例定義為歧義“論元對”。雖然歧義“論元對”在數(shù)據(jù)集中所占比例較小,但如果對這些歧義“論元對”進行實例擴展,則會進一步增加不確定樣本在整個訓(xùn)練樣本集中的比重,勢必會影響分類性能,所以應(yīng)將歧義“論元對”從訓(xùn)練樣本集中刪除,并對歧義“論元對”也不進行實例擴展。本文接下來介紹的訓(xùn)練樣本集擴展方法,均默認已從原始訓(xùn)練樣本集中刪除歧義“論元對”。
4 基于論元向量的隱式訓(xùn)練樣本集擴展方法
針對隱式篇章關(guān)系分類任務(wù),本文提出一種基于論元向量的隱式訓(xùn)練樣本集擴展方法。本節(jié)首先概述論元向量的生成方法,然后給出具體的隱式訓(xùn)練樣本集擴展方法。
4.1 基于詞向量的論元向量生成方法
詞向量(Distributed representation,通常被稱為“Word Representation”或“Word Embedding”)是目前深度學(xué)習(xí)領(lǐng)域最熱門的研究任務(wù)之一,最早由Hinton[15]提出。詞向量模型旨在將單詞轉(zhuǎn)化成具有實值的語義向量,通過語義向量獲取文本的句法結(jié)構(gòu)、上下文信息等,目前已在多個領(lǐng)域廣泛應(yīng)用,例如,文本分類、問答系統(tǒng)、信息檢索、命名題識別以及句法分析等。Bengio等[16]基于詞向量,利用神經(jīng)網(wǎng)絡(luò)來構(gòu)建語言模型,相較于傳統(tǒng)的N-gram算法,模型性能提升10%~20%,奠定了詞向量研究的基礎(chǔ)。在此基礎(chǔ)上,Richard Socher等[17]提出基于半監(jiān)督遞歸自動譯碼器(Recursive auto-encoder,RAE)的語義向量生成方法,該方法基于神經(jīng)網(wǎng)絡(luò)語言模型訓(xùn)練獲得每個單詞的詞向量,通過句法樹將任意長度的文本片段轉(zhuǎn)化成固定維度的語義向量,并將該語義向量表示應(yīng)用于情感分類上,實驗結(jié)果顯示,相較于傳統(tǒng)基于規(guī)則的方法以及基于詞包模型(bag-of-words)的方法,情感分類性能獲得顯著提升。本文借助該語義向量生成方法實現(xiàn)論元的向量表示。
圖2為遞歸自動譯碼器的句子語義向量生成示意圖。其輸入為長度為4的句子
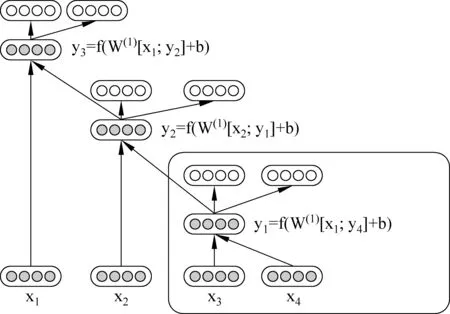
圖2 遞歸自動譯碼器標注示例
在單詞表示成詞向量的基礎(chǔ)上,遞歸自動譯碼器首先對輸入的句子進行句法分析,將每個句子表示成句法樹的形式,然后自右向左遍歷句法樹中的每個葉子節(jié)點,每兩個葉子節(jié)點
p=f(W(1)[c1;c2]+b(1))
(1)
按照上述計算方法,遍歷整個句法樹直到根節(jié)點,即獲得整個句子的語義向量。例2給出兩個實例的語義向量標注結(jié)果,因篇幅有限,只列出部分標注結(jié)果。
例2 Arg1 Mr. Tom avoided jail.
<譯文: 湯姆先生免受牢獄之災(zāi)>
Arg2 【Implicit = Instead】He was sentenced to 500 hours of community service.
<譯文: 【相反】他被判處執(zhí)行500小時的社區(qū)服務(wù)工作>
篇章關(guān)系 =“Expansion(擴展關(guān)系)”
通過遞歸自動譯碼器,可將輸入的句子轉(zhuǎn)換成語義向量,該語義向量涵蓋句子的句法結(jié)構(gòu)以及上下文信息等,可直接利用該語義向量進行文本分析,從而降低對句子進行直接分析的復(fù)雜度。本文利用語義向量這一優(yōu)勢,將遞歸自動譯碼器生成的語義向量應(yīng)用于隱式樣本集擴展任務(wù)中,通過探索論元的語義向量(簡稱為論元向量)之間的關(guān)系,對隱式訓(xùn)練樣本集進行擴展,輔助推理論元之間的隱式篇章關(guān)系。
4.2 隱式訓(xùn)練樣本集擴展方法
本節(jié)將詳細介紹基于語義向量進行隱式訓(xùn)練樣本集的擴展方法。本文使用的外部語言學(xué)資源為GIGAWORD(LDC2003T05),其中包含了4 111 240篇新聞文本,來自四個不同的國際英語新聞專線,分別為: 法國新聞社、美國聯(lián)社、紐約時報以及新華通訊社。為了保證在外部數(shù)據(jù)資源中擴展的隱式實例與原始訓(xùn)練樣本集的格式一致(在原始訓(xùn)練樣本集中,每個訓(xùn)練實例由“論元對”及其對應(yīng)的篇章關(guān)系類別組成),在進行訓(xùn)練樣本集擴展之前,對GIGAWORD語料中的每篇文本進行切分,切分后的文本須符合以下規(guī)則:
1) 以“論元對”為單元,且每個論元符合自然語言規(guī)律(通過句法分析判定);
2) 兩個論元之間不包含連接詞*PDTB語料中定義的134個連接詞,即它們之間為隱式關(guān)系。
圖3為基于論元向量的訓(xùn)練樣本集擴展方法流程圖。本文從GIGAWORD語料中抽取出所有符合上述兩項要求的 “論元對”,將這些“論元對”加入到外部數(shù)據(jù)資源列表中。由于切分后獲取的“論元對”實例數(shù)量龐大,本文最終從該列表中隨機抽取一百萬個“論元對”實例,作為外部隱式“論元對”樣本集。基于此樣本集,利用4.1節(jié)介紹的遞歸自動譯碼器標注程序進行論元向量標注,并通過連接兩個論元向量,獲得“論元對”整體的向量表示。圖3中X和Y分別表示獲得的外部隱式“論元對”樣本集以及原始訓(xùn)練樣本集的語義向量標注集合。
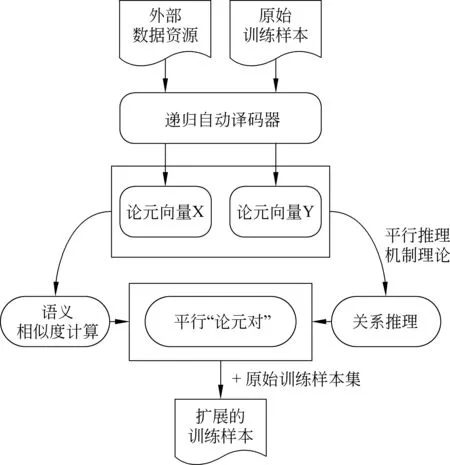
圖3 基于論元向量的訓(xùn)練樣本集擴充方法流程圖
以原始訓(xùn)練樣本集的每個“論元對”為種子實例,依據(jù)“平行推理機制”理論(Hong等[19])*平行推理機制: 如果兩個“論元對”在語義上以及結(jié)構(gòu)上具有一致性,則它們的關(guān)系也平行,即它們具有相同的篇章關(guān)系。,計算論元向量之間的語義相似度。依據(jù)計算結(jié)果,從外部隱式“論元對”樣本集中抽取與種子實例在語義上和關(guān)系上相似的隱式“論元對”(簡稱為平行“論元對”)。實驗過程中,針對每個種子實例,本文選擇語義最相似的TopN個隱式“論元對”作為平行“論元對”,其中,語義相似度度量采用歐式距離;N的取值與具體的關(guān)系類別有關(guān),如式(2)所示。
(2)
其中,Nr表示篇章關(guān)系類別為r的種子實例關(guān)于TopN的參數(shù)N,CExpansion表示訓(xùn)練樣本中關(guān)系類別為Expansion的實例總數(shù),Cr表示訓(xùn)練樣本中關(guān)系類類別為r的實例總數(shù),r∈{Comparison, Contingency, Temporal}。
通過以上方法,本文計算獲得所有種子實例的平行“論元對”,形成“平行訓(xùn)練樣本集”,并將原始訓(xùn)練樣本集與平行訓(xùn)練樣本集組合,實現(xiàn)隱式訓(xùn)練樣本集的擴展。表2為隱式訓(xùn)練樣本集擴展的算法偽代碼。
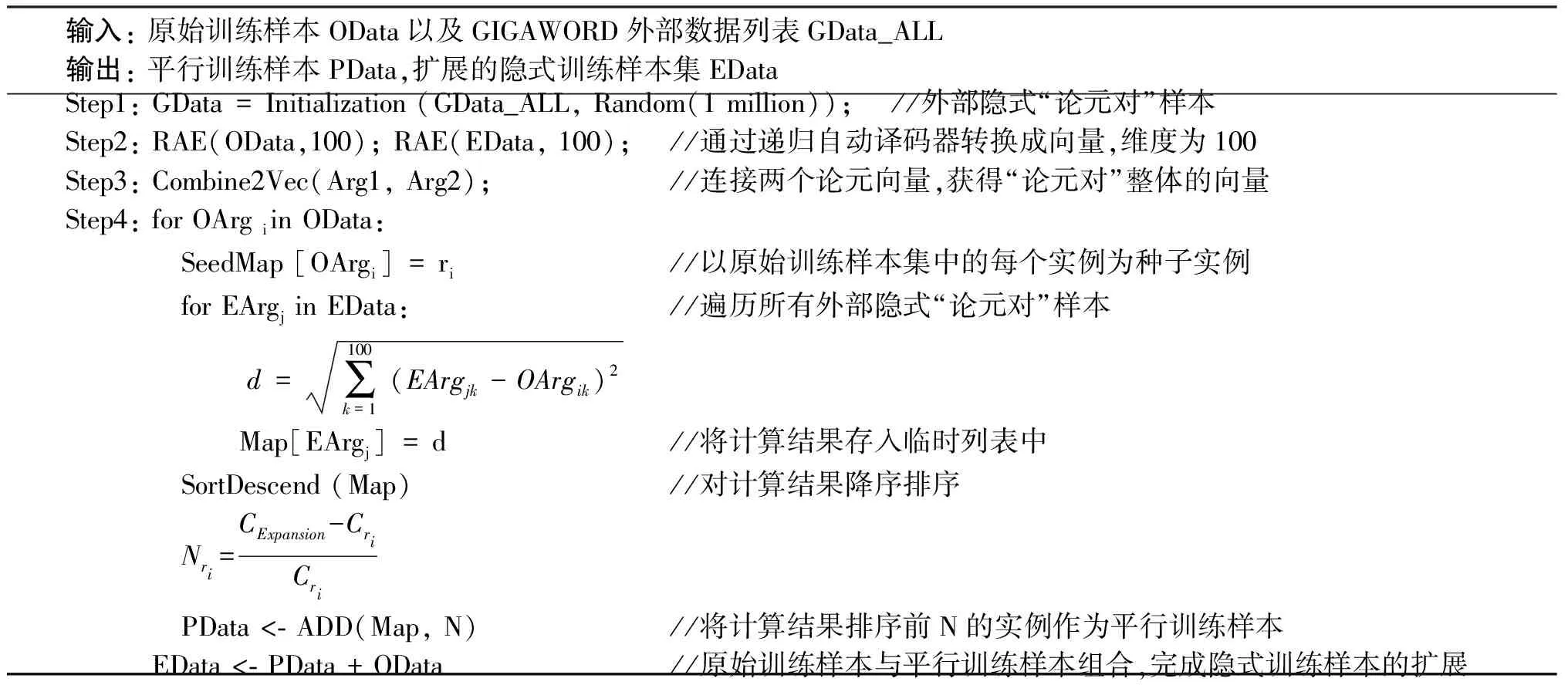
表2 隱式訓(xùn)練樣本集擴展算法偽代碼
5 基于擴展的訓(xùn)練樣本集的隱式篇章關(guān)系分類
在擴展的訓(xùn)練樣本集上,本文采用傳統(tǒng)的基于語言學(xué)特征的隱式篇章關(guān)系分類方法進行實驗。本節(jié)首先概述實驗分類特征,然后介紹實驗分類器。
5.1 分類特征
前人研究表明[4-5,9-10],動詞、單詞對、產(chǎn)生式規(guī)則以及依存規(guī)則等四種語言學(xué)特征在隱式篇章關(guān)系的分類問題中具有明顯的優(yōu)勢。因此,本文采用這四種分類特征進行實驗。下面對這四種分類特征進行描述。
動詞(Verbs) 論元Arg1和論元Arg2中的所有動詞。每個動詞表示成三個二元特征,分別表示該特征是否出現(xiàn)在Arg1、Arg2以及整個“論元對”中。
單詞對(WordPairs) 論元Arg1和論元Arg2的向量積——即兩個論元中的所有單詞(非停用詞)的交叉組合,對于任意一個特征(Wi,Wj),單詞Wi來自于Arg1中,單詞Wj則來自于Arg2中。
產(chǎn)生式規(guī)則(Production Rules) 論元Arg1、論元Arg2以及整個“論元對”的句法規(guī)則特征。基于斯坦福句法標注工具(version 3.5.0)*http://nlp.stanford.edu/software/lex-parser.shtml(下載地址),對所有實例進行句法規(guī)則標注,按照“parent-children”的格式抽取出句法樹中所有符合要求的產(chǎn)生式規(guī)則。每個產(chǎn)生式規(guī)則表示成三個二元特征,分別代表該特征是否出現(xiàn)在Arg1、Arg2以及整個“論元對”中。
依存規(guī)則(Dependency Rules) 論元Arg1、論元Arg2以及整個“論元對”的依存規(guī)則特征。同樣基于斯坦福句法標注工具,獲得所有實例的依存分析樹,對每個依存樹,抽取每個單詞及其相關(guān)的依存類型。每個依存特征表示成三個二元特征,分別代表該特征是否出現(xiàn)在Arg1、Arg2以及整個“論元對”中。
對于動詞、單詞對、產(chǎn)生式規(guī)則以及依存規(guī)則特征,本文在實驗中設(shè)定的頻率閾值為5,即如果某一特征在語料中出現(xiàn)的總頻數(shù)小于5,則舍棄該特征。
5.2 分類器
針對所有訓(xùn)練樣本,本文抽取上述四種分類特征,并將每個訓(xùn)練實例表示成特征向量,采用Chang 等[20]開發(fā)設(shè)計的LIBSVM作為分類器,核函數(shù)使用線性核。針對每種篇章關(guān)系,分別構(gòu)建一個二元分類器;同時,針對四種篇章關(guān)系類別,構(gòu)建一個多類分類器(分類類別為四種)。
6 實驗設(shè)計與結(jié)果分析
6.1 實驗設(shè)計
本文使用PDTB 2.0版本中Section 00-20作為原始訓(xùn)練樣本集,共包含13 502個實例(本文刪除具有兩種關(guān)系類型的歧義“論元對”,共313個);Section 21-22作為測試樣本集,包含1 046個實例;Section 23-24作為驗證集,包含1 192個實例。所有樣本使用第一層的四種篇章關(guān)系類型: 擴展關(guān)系(Expansion)、對比關(guān)系(Comparison)、偶然關(guān)系(Contingency)以及時序關(guān)系(Temporal),其中實體關(guān)系類型(EntRel)以及無關(guān)系類型(NoRel)均不包含在訓(xùn)練樣本集、驗證樣本集以及測試樣本集中。此外,本文對外部數(shù)據(jù)資源GIGAWORD語料中的所有文本進行切分,切分后的文本以“論元對”為單元且兩個論元之間的關(guān)系為隱式關(guān)系。通過生成隨機數(shù)的方式從該文本中抽取一百萬個“論元對”作為外部隱式“論元對”樣本。基于此樣本,進行后續(xù)平行隱式“論元對”的挖掘。
為了檢驗不同特征的分類性能,針對不同的分類特征,本文在四種篇章關(guān)系類別下分別訓(xùn)練一個二元分類器,以檢驗該特征在當前篇章關(guān)系類型上的單一分類性能,評價標準采用F值;同時本文也針對每個特征(動詞、單詞對、產(chǎn)生式規(guī)則以及依存規(guī)則特征)分別訓(xùn)練一個整體分類器,用來檢驗該特征在四種篇章關(guān)系類型上的整體分類性能,評價標準采用精確率(Accuracy),如式(3)所示。
(3)
其中TruePositive表示被正確分為正例的個數(shù);TrueNegative表示被正確分為 負 例 的 個 數(shù),N
為待測“論元對”總數(shù)。實際上在表示整體分類性能時,TrueNegative值為0,TruePositive為四種篇章關(guān)系類別中被正確分為正例的總數(shù)。
6.2 實驗結(jié)果與分析
圖4為使用四種不同分類特征的實驗結(jié)果,圖4(a)、4(b)、4(c)以及4(d)分別表示使用動詞特征、單詞對特征、產(chǎn)生式規(guī)則特征以及依存規(guī)則特征的實驗分類性能(度量標準為F值)。從實驗結(jié)果可以看出,使用擴展的訓(xùn)練樣本集進行模型訓(xùn)練,分類器在保證Expansion關(guān)系類別分類精度的同時,有效地提升了Comparison、Contingency以及Temporal 三個關(guān)系類別上的分類性能,在四種分類特征上性能分別提升11.21%、7.67%、4.46%和11.53%。由于本文只對Comparison、Contingency以及Temporal三種關(guān)系類別進行訓(xùn)練樣本擴展,從實驗結(jié)果還可以看出,實驗性能在這三種類別上提升較為明顯,而在Expansion類別上的性能基本保持不變,這說明本文基于論元向量獲取的“平行訓(xùn)練樣本集”具有一定的準確性,在Comparison、Contingency以及Temporal三種關(guān)系類別上加入更多的有效實例,有效地提升了分類器在這三種類別上的分類性能,而在Expansion關(guān)系類別上,由于沒有加入更多的訓(xùn)練實例,分類性能則基本保持不變。
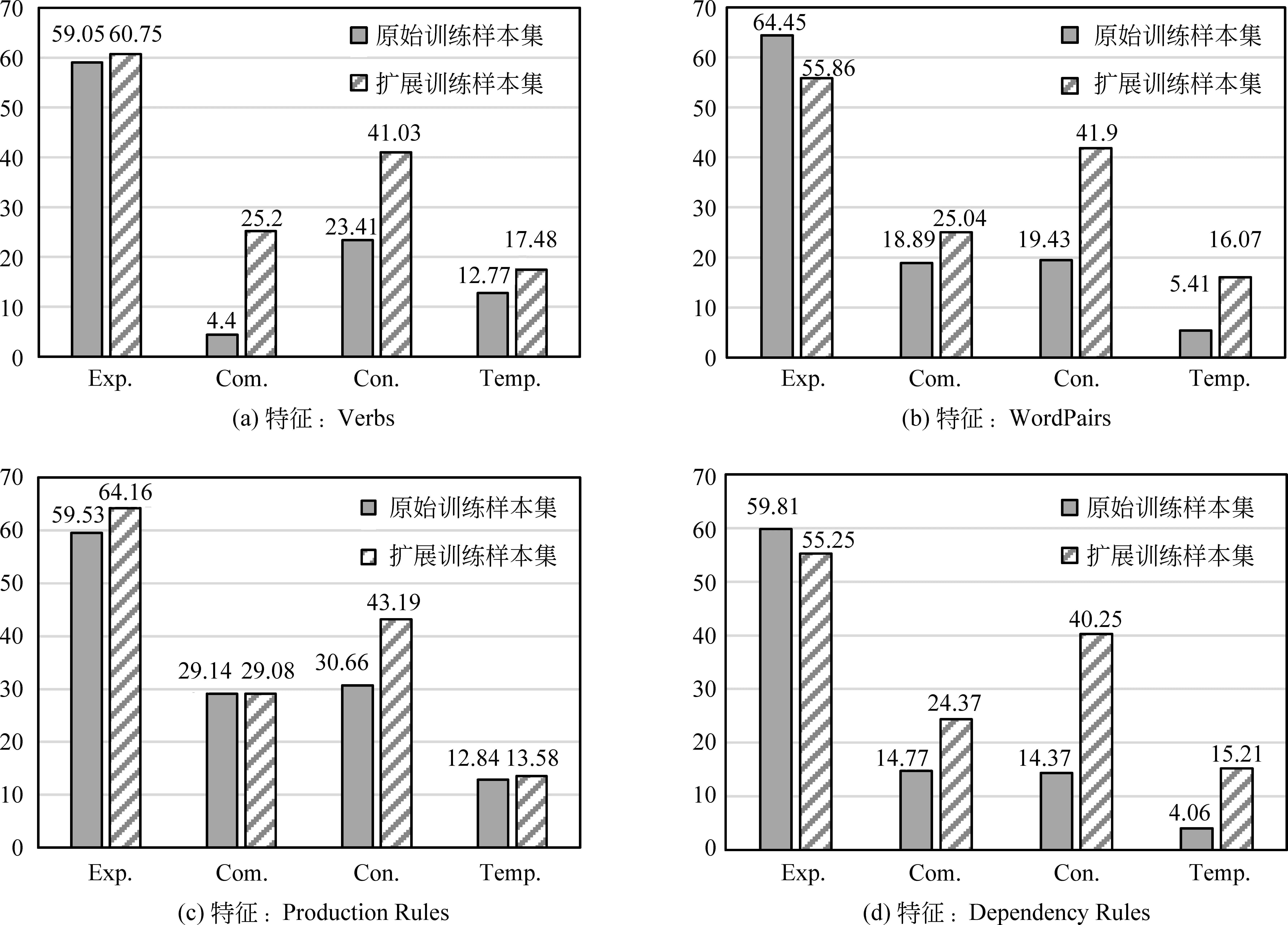
圖4 分類器在四種不同特征下的實驗性能對比注: Expansion, Comparison, Contingency, Temporal分別簡寫為Exp., Com., Con., Temp.
為進一步驗證基于論元向量擴展的“平行訓(xùn)練樣本集”的準確性。實驗過程中,對于Comparison、Contingency以及Temporal三種關(guān)系類別,本文從外部隱式“論元對”樣本中隨機選擇與“平行訓(xùn)練樣本集”相同數(shù)量的“論元對”,將該樣本集稱為“偽平行訓(xùn)練樣本集”。由于“偽平行訓(xùn)練樣本集”中可能含有較多噪音信息,通過該樣本集訓(xùn)練得出的分類器可靠性不強,可將其作為實驗的對比系統(tǒng),以檢驗“平行訓(xùn)練樣本集”的實驗性能。因此,本文設(shè)置了以下五個實驗系統(tǒng): 其中Baseline實驗系統(tǒng)使用原始訓(xùn)練樣本集;SYS1實驗系統(tǒng)使用“偽平行訓(xùn)練樣本集”;SYS2實驗系統(tǒng)使用“平行訓(xùn)練樣本集”;SYS3實驗系統(tǒng)使用加入“偽平行訓(xùn)練樣本集”的擴展訓(xùn)練樣本集;SYS4實驗系統(tǒng)使用加入“平行訓(xùn)練樣本集”的擴展訓(xùn)練樣本集。圖5為各實驗系統(tǒng)在四種分類特征上的實驗性能對比。
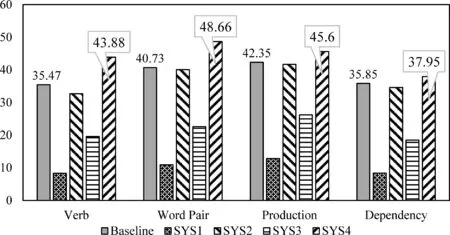
圖5 各實驗系統(tǒng)性能對比圖
從圖5分類性能對比圖可以看出,加入“平行訓(xùn)練樣本集”后,系統(tǒng)SYS4的分類性能明顯優(yōu)于基準系統(tǒng)(僅使用原始訓(xùn)練樣本),且在每種特征上分類性能分別提升為8.41%、7.93%、3.25%和2.10%,最優(yōu)分類性能達到48.66%(特征: 單詞對)。進一步觀察發(fā)現(xiàn),實驗系統(tǒng)SYS2僅使用擴展的“平行訓(xùn)練樣本集”進行實驗,獲得的實驗分類性能僅略低于基準系統(tǒng),而實驗系統(tǒng)SYS3使用“偽平行訓(xùn)練樣本集”獲得的實驗性能明顯偏低,從而證明本文基于論元向量擴展的“平行訓(xùn)練樣本集”與原始訓(xùn)練樣本具有較高的相似性,在一定程度上可輔助實現(xiàn)隱式篇章關(guān)系的分類。
此外,本文將實驗性能最優(yōu)的分類系統(tǒng)SYS4與基準系統(tǒng)以及各主流分類系統(tǒng)進行對比。本文選取的兩個對比系統(tǒng)為WANG_SYS和LAN_SYS。其中,WANG_SYS采用基于樹核函數(shù)的方法實現(xiàn)隱式篇章關(guān)系分類,使用的分類器及評價標準與本文一致,最終分類器的整體分類性能為40.00%;LAN_SYS采用基于多任務(wù)學(xué)習(xí)框架的方法實現(xiàn)隱式篇章關(guān)系分類,通過不同的訓(xùn)練樣本訓(xùn)練主分類器和輔助分類器,最終整體分類性能達到42.30%。表3列出各個系統(tǒng)的分類性能,從各實驗系統(tǒng)分類性能可以看出,本文加入“平行訓(xùn)練樣本”的實驗系統(tǒng)SYS4的分類性能相較于兩個對比系統(tǒng)WANG_SYS以及LAN_SYS均有顯著提升,分類精確率分別提高8.66%和6.36%,這也進一步驗證本文基于訓(xùn)練樣本集擴展的隱式篇章關(guān)系分類方法具有一定的有效性和可行性。
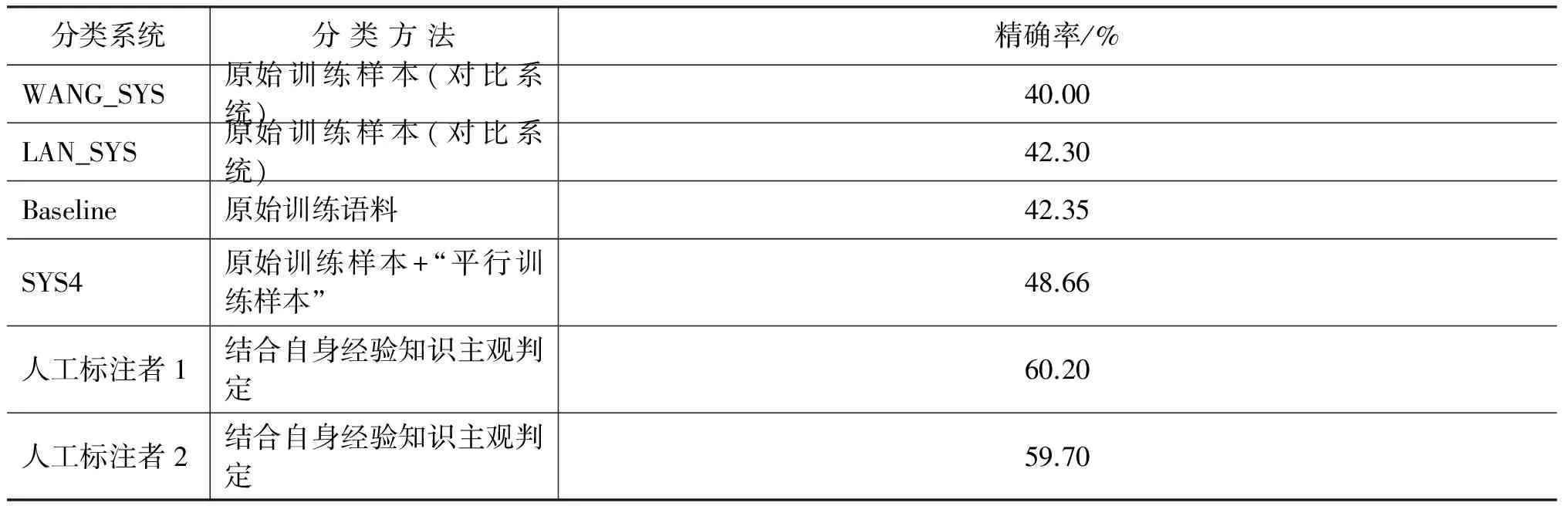
表3 各隱式篇章關(guān)系推理系統(tǒng)性能
表3中還給出兩位人工標注者的分類精確率(來自徐凡等[21]),針對同一測試集,兩者僅取得60%左右的精確率。雖然與人工標注者的實驗結(jié)果相比,本文的最優(yōu)性能仍然偏低,但現(xiàn)有系統(tǒng)和人工標注的性能均不高,這種現(xiàn)象從側(cè)面反映隱式篇章關(guān)系分類難度較大,在篇章分析領(lǐng)域仍是一個具有挑戰(zhàn)性的研究任務(wù)。
7 總結(jié)
針對隱式訓(xùn)練樣本不足以及篇章關(guān)系類別不平衡的問題,本文提出一種基于訓(xùn)練樣本擴展的隱式篇章關(guān)系分類方法。該方法借助論元向量,以原始訓(xùn)練樣本為集種子實例,從外部數(shù)據(jù)資源中挖掘所有種子實例的平行隱式“論元對”,并將所有平行隱式“論元對”加入到原始訓(xùn)練樣本集中,對訓(xùn)練樣本集進行擴展。基于擴展的訓(xùn)練樣本集,在PDTB數(shù)據(jù)集上進行性能測試。相較于直接使用原始訓(xùn)練樣本集的實驗系統(tǒng),分類性能提升最優(yōu)達到8.41%,相較于兩個主流對比實驗系統(tǒng),分類性能分別提升8.66%和6.36%。
然而,本文提出的基于訓(xùn)練樣本集擴展的隱式篇章關(guān)系分類方法性能仍偏低,原因在于,隱式“論元對”本身具有較強的主觀性和歧義性,從不同的角度考慮具有不同的語義關(guān)系。例如, “He worked all night yesterday”和“He slept all day today”兩論元之間既可表示偶然關(guān)系也可表示時序關(guān)系。針對這一問題,未來工作中,我們將對本文方法深入和細化: 在訓(xùn)練樣本集擴展方面,嘗試借助LDA模型以及篇章上下文信息選擇歧義性較小的實例作為種子實例;在論元向量計算方面,采用更多的相似度計算方法,例如,余弦相似度、Jaccard相似度等;在特征表示方面,嘗試采用特征選擇、特征融合等方法。此外,將現(xiàn)有的篇章關(guān)系分類方法擴展至第二層的篇章關(guān)系識別,實現(xiàn)更細粒度的篇章關(guān)系分類。
[1] R Prasad, N Dinesh, A Lee, et al. The Penn Discourse TreeBank 2.0[C]//Proceedings of the 6th International Conference on Language Resources and Evaluation (LREC), 2008: 2961-2968.
[2] E Miltsakaki, L Robaldo, A Lee, et al. Sense Annotation in the Penn Discourse Treebank[C]//Proceedings of the Computational Linguistics and Intelligent Text Processing. Springer Berlin Heidelberg, 2008: 275-286.
[3] E Pitler, M Raghupathy, H Mehta, et al. Joshi. Easily Identifiable Discourse Relations[R]. Technical Reports (CIS), 2008: 87-90.
[4] E Pitler, A Louis, A Nenkova. AutomaticSense Prediction for Implicit Discourse Relations in Text[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP (ACL-AFNLP), 2009, 2: 683-691.
[5] Z H Lin, M Y Kan, H T Ng. Recognizing Implicit Discourse Relations in the Penn Discourse Treebank[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2009, 1: 343-351.
[6] R Soricut, D Marcu. Sentence Level Discourse Parsing Using Syntactic and Lexical Information[C]//Proceedings of the Human Language Technology and North American Association for Computational Linguistics Conference (HLT-NAACL), 2003: 149-156.
[7] W T Wang, J Su, C L Tan. KernelBased Discourse Relation Recognition with Temporal Ordering Information[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics (ACL), 2010: 710-719.
[8] Z M Zhou, Y Xu, Z Y Niu, et al. Predicting Discourse Connectives for Implicit Discourse Relation Recognition[C]//Proceedings of the 23rd International Conference on Computational Linguistics (CL): Posters, 2010: 1507-1514.
[9] J Park, C Cardie. Improving Implicit Discourse Relation Recognition Through Feature Set Optimization[C]//Proceedings of the 13th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL), 2012: 108-112.
[10] M Lan, Y Xu, Z Y Niu. Leveraging Synthetic Discourse Data via Multi-task Learning for Implicit Discourse Relation Recognition[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (ACL), 2013: 476-485.
[11] J J Li, M Carpuat, A Nenkova. Cross-lingual Discourse Relation Analysis: A corpus study and a semi-supervised classification system[C]//Proceedings of the 25th International Conference on Computational Linguistics (COLING), 2014: 577-587.
[12] X Wang, S J Li, J Li, et al. Implicit Discourse Relation Recognition by Selecting Typical Training Examples[C]//Proceedings of the 22nd International Conference on Computational Linguistics (COLING), 2012: 2757-2772.
[13] D Marcu, A Echihabi. AnUnsupervised Approach to Recognizing Discourse Relations[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics (ACL), 2002: 368-375.
[14] C Sporleder, A Lascarides. Using automatically labelled examples to classify rhetorical relations: An assessment[J].Natural Language Engineering, 2008, 14(03): 369-416.
[15] G E Hinton. Learning distributed representations of concepts[C]//Proceedings of the eighth annual conference of the cognitive science society (COGSCI).1986: 1-12.
[16] Y Bengio, R Ducharme, P Vincent, et al. A neural probabilistic language model[J]. The Journal of Machine Learning Research, 2003, 3: 1137-1155.
[17] R Socher, J Pennington, E H Huang, et al. Semi-supervised recursive autoencoders for predicting sentiment distributions[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2011: 151-161.
[18] J Turian, L Ratinov, Y Bengio. Word representations: a simple and general method for semi-supervised learning[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics (ACL), 2010: 384-394.
[19] Y Hong, X P Zhou, T T Che, et al. Cross-argument inference for implicit discourse relation recognition[C]//Proceedings of the 21st ACM International Conference on Information and Knowledge Management (CIKM), 2012: 295-304.
[20] C C Chang, C J Lin. LIBSVM: a library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2001, 2(3): 389-396.
[21] 徐凡, 朱巧明, 周國棟. 基于樹核的隱式篇章關(guān)系識別[J]. 軟件學(xué)報, 2013, 24(5): 1022-1035.
Implicit Discourse Relation Classification Method Based on the Training Data Expansion
ZHU Shanshan, HONG Yu, DING Siyuan, YAN Weirong,YAO Jianmin, ZHU Qiaoming
(Key Lab of Computer Information Processing Technology of Jiangsu Province, Soochow University, Suzhou, Jiangsu 215006, China)
The implicit discourse relation recognition is to automatically detect the relationships between two arguments without explicit connectives. Previous studies show that linguistic features are effective for implicit discourse relation recognition. However, the state-of-the-art accuracy is merely 40% for the lack of enough training data. For the problem, this paper presents a novel implicit discourse relation recognition method based on the training data expansion. Firstly, we take some origin training data as seed samples, and then use them to mine semantically and relationally parallel data from the external data resources by using “arguments vectors”. Secondly, we augment origin training data with the mined parallel training data. Finally, we experiment the implicit discourse relation classification using the expanded data. Experiment results on the Penn Discourse Treebank (PDTB) show that our method outperforms the baseline system with a gain of 8.41% on the whole, and 5.42% on average in classification accuracy respectively. Compared with the state-of-the-art system, we further acquire 6.36% improvements.
implicit discourse relation; semantic vector; training data expansion; discourse analysis

朱珊珊(1992—),碩士研究生,主要研究領(lǐng)域為篇章分析。E?mail:zhushanshan063@gmail.com洪宇(1978—),通信作者,副教授,主要研究領(lǐng)域為信息抽取,信息檢索,事件關(guān)系檢測等。E?mail:tianxianer@gmail.com丁思遠(1992—),碩士研究生,主要研究領(lǐng)域為事件關(guān)系檢測。E?mail:dsy.ever@gmail.com
1003-0077(2016)05-0111-10
2014-12-25 定稿日期: 2015-03-27
國家自然科學(xué)基金(61373097, 61272259, 61272260, 90920004);教育部博士學(xué)科點專項基金(2009321110006, 20103201110021);江蘇省自然科學(xué)基金(BK2011282);江蘇省高校自然科學(xué)基金(11KJA520003);蘇州市自然科學(xué)基金(SH201212)
TP
A
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
