基于移動Agent的分布式Web搜索模型的設計與實現(xiàn)
2016-05-09 07:07:28李明唐軼
計算機應用與軟件 2016年4期
李 明 唐 軼
基于移動Agent的分布式Web搜索模型的設計與實現(xiàn)
李 明1唐 軼2
1(國家電網(wǎng)開封供電公司 河南 開封 475004)
2(中國建設銀行武漢數(shù)據(jù)中心 湖北 武漢 430022)
傳統(tǒng)基于C/S模式的Web 搜索方法對網(wǎng)絡帶寬和網(wǎng)絡通暢性的要求都比較高,因此在當今互聯(lián)網(wǎng)的海量數(shù)據(jù)中的檢索效率比較低。在分析移動Agent技術特點的基礎上,提出一種基于移動Agent的分布式Web搜索模型。該模型根據(jù)中文信息搜索的特殊性,將移動Agent技術與分類算法相結合,在搜索過程中引入了用戶輸入信息的預處理過程來進行信息分類,然后根據(jù)分類結果形成基于用戶興趣度的移動Agent搜索路徑選擇策略以及并發(fā)方法,由此來提高Web搜索的效率。詳細介紹框架的組成和所采用的關鍵技術,并通過一個移動Agent的開發(fā)平臺——Aglet平臺對模型進行實現(xiàn)和實驗。實驗結果表明,采用該模型進行Web檢索,比傳統(tǒng)的C/S檢索方式減少50%以上的搜索時間,而在各資源服務器存儲的文件資源類別和資源數(shù)量差異較大情況下的搜索效率比非并發(fā)的其他移動Agent搜索模型搜索時間要減少70%以上。
移動Agent 分類算法 路由策略 并行方法
0 引 言
隨著互聯(lián)網(wǎng)信息資源爆炸式地增長,網(wǎng)絡信息搜索面臨著龐大的信息量和有限帶寬之間、單一搜索請求和大量相關站點之間、用戶個性化需求和搜索方式單一之間的種種矛盾[1]。而傳統(tǒng)的、基于C/S模式的搜索引擎通過在客戶和服務器之間建立一條邏輯信道來實現(xiàn)對需要檢索的遠程資源的本地文件索引,因此對網(wǎng)絡帶寬和網(wǎng)絡通暢性的要求都很高,且降低了檢索效率。而基于BDI(Belief、Desire、Intention)[2]理論模型的,集軟件、通訊、分布式技術于一體的移動Agent技術[3,4]可以有效運用網(wǎng)絡帶寬來進行高效的分布式計算。它將代碼遷移到資源所在地進行遠程檢索,只返回檢索結果,因此能很好地解決傳統(tǒng)搜索方式的不足。
1 移動Agent技術簡介
移動Agent是一個具有一定智能性的代替人或其他程序執(zhí)行某種任務的程序。它能自主地從一臺主機遷移到另一臺主機,當任務完成后,自動返回結果和消息。它主要分為2個部分:移動Agent和移動Agent環(huán)境[5]。當移動Agent遷移到資源所在地主機后,會在本地調(diào)用主機資源,進行相應的訪問和運算。由于移動Agent自身的特性,其在分布式信息檢索的優(yōu)勢主要體現(xiàn)在如下幾個方面[6,7]:
(1) 降低網(wǎng)絡負載 傳統(tǒng)的分布式信息搜索需要建立邏輯信道,以保持網(wǎng)絡通信正常,長時間的網(wǎng)絡連接必導致網(wǎng)絡阻塞。而移動Agent攜帶代碼遷移到資源所在地,避免了大量數(shù)據(jù)資源的傳輸,同時不需要網(wǎng)絡長時間保持連接狀態(tài),從而大幅度降低了網(wǎng)絡負載。
(2) 平臺無關 移動Agent的運行只依賴于是否有移動Agent環(huán)境,與網(wǎng)絡平臺無關。
(3) 自主性 移動Agent可以根據(jù)實時網(wǎng)絡狀況和自身任務特點自主的選擇移動路線。使得移動Agent具有一定的智能性和應變能力。
(4) 并行性 用戶可以針對一個任務或多個任務同時創(chuàng)建多個移動Agent,使其并行工作,快速高效地完成用戶任務。
2 基于移動Agent的分布式搜索系統(tǒng)的系統(tǒng)架構
為了提高遠程資源的搜索效率,本文設計了一個基于特征信息和移動Agent的分布式搜索系統(tǒng)(IMADS)框架,該框架主要包含如下幾個部分:用戶本地Agent系統(tǒng)(ULAS)、遠程資源管理系統(tǒng)(RRMS)、Agent轉接系統(tǒng)(AD),如圖1所示。

圖1 基于移動Agent的分布式Web搜索系統(tǒng)架構
下面詳細介紹該框架的三個主要組成部分:
(1) 用戶本地Agent系統(tǒng) 由用戶輸入處理模塊、日志管理模塊、資源Agent、搜索Agent、管理Agent和路由表構成。其中:
a. 輸入處理模塊:其主要任務為在進行信息搜索前,對創(chuàng)建的Agent進行狀態(tài)、知識庫、約束條件等的初始化;對用戶的輸入信息進行分詞、去除停用詞等預處理;將代表用戶興趣目標的特征詞寫入知識庫;設置返回時間、站點停留時間、任務完成度、搜索范圍等。
b. 資源Agent:是一類移動Agent,當用戶提出查詢請求后,資源Agent查詢?nèi)罩局写鎯Φ目梢苿拥倪h程資源節(jié)點,然后根據(jù)具體信息生成路由表。返回給管理Agent,管理Agent設置搜索Agent遷移的路徑等。
c. 管理Agent:是用戶Agent的控制中心,它主要負責創(chuàng)建資源Agent,并派遣到遠程資源服務器上查詢可用的服務列表,并將目標URL地址、資源種類、數(shù)量等遠程資源信息反饋給用戶管理Agent;接收從用戶輸入接口輸入的查詢、約束條件、路由表等初始化信息,并打包成搜索Agent可攜帶的執(zhí)行格式;接收搜索Agent攜帶回來的數(shù)據(jù),并轉換成本地需要的數(shù)據(jù)格式在GUI上顯示。
d. 搜索Agent:是另一類移動Agent,它們攜帶用戶的查詢信息、遷移地址URL、路由表、遷移時間等在各資源所在地主機之間移動。搜索Agent遷移到遠程資源服務器,通過遠程資源服務器的管理Agent接口訪問遠程資源。結束搜索后,根據(jù)路由表信息決定下一步遷移目的地。搜索Agent在返回到用戶端或者遷移到下一個站點之前,先調(diào)用Ping命令判斷網(wǎng)絡的連通性。若連通則表示目的地的Agent環(huán)境已經(jīng)啟動,搜索Agent可直接遷移到對方主機。若不連通,則搜索Agent到AD中等候,AD將搜索Agent保存在硬盤上,并監(jiān)視目標主機,一旦連通,將激活搜索Agent讓其傳送到目標主機。
(2) 遠程資源管理系統(tǒng) 由注冊Agent和管理Agent等非移動的靜態(tài)Agent組成,負責給搜素Agent提供運行環(huán)境,每個資源所在地需要部署這樣的環(huán)境。當啟動該搜索Agent環(huán)境后,會向ULAS發(fā)送一個攜帶有該環(huán)境URL地址的注冊Agent,當管理Agent成功接收后,會將該URL地址保存起來,更新日志文件,以便于資源Agent進行實時訪問。它的另一個管理Agent為遷移到此環(huán)境的搜索Agent提供服務,保存歷史記錄以及向搜索Agent的下一個遷移目標發(fā)送Ping命令,測試其連通性。
(3) Agent轉接系統(tǒng) 主要功能是解決遷移失效問題。當一個搜索Agent遷移到某個用戶服務器上時,如果遇到服務器關閉或網(wǎng)絡阻塞等情況時,它將自動遷移到該服務器所在的Dock服務器上。當移動Agent到達Dock服務器后就不再運行,而在Dock服務器上的固定Agent控制下存儲到硬盤,固定Agent代替移動Agent監(jiān)視服務器狀態(tài)。當檢查到服務器恢復連接后,喚醒等待遷移到服務器上的搜索Agent,使得所有在Dock服務器上等待遷移到目標服務器的移動Agent能遷移過去。
3 系統(tǒng)實現(xiàn)的關鍵技術
3.1 基于樸素貝葉斯分類算法的用戶輸入預處理過程
用戶輸入處理模塊包括:用戶輸入預處理、關鍵詞語義擴展和關鍵詞分類三個部分。
(1) 用戶輸入預處理模塊
用戶輸入預處理模塊主要包含用戶輸入信息的分詞和去除停用詞。對于分詞,采用現(xiàn)有的分詞工具MManalyzie[6]。它基于字符串的最大長度匹配,分詞效果好,可靠性較高,速度也比較快。由于分詞后,會出現(xiàn)許多沒有實際意義的語氣助詞或沒有代表性的慣用詞語。為了提高運行效率,減少無謂的系統(tǒng)開銷,提高精確度,需要將分詞后的詞語與常用詞表進行比對,去除沒有特殊意義、分類效果不明顯的單詞,最后得到最能代表用戶搜索需求的若干關鍵詞。例如:今天進行的NBA比賽結果統(tǒng)計經(jīng)分詞、去除停用詞后就會變成“NBA/比賽/結果/統(tǒng)計”這樣的代表用戶真實搜索意圖的簡明、扼要的關鍵詞組。
(2) 關鍵詞語義擴展模塊
關鍵詞語義擴展的主要用途是為了更好地識別用戶的興趣度。通過對關鍵詞進行擴展,擴展出多個同義詞則可以使得后面關鍵詞分類的結果更準確。在這里調(diào)用較為廣泛使用的語義擴展系統(tǒng)WordNet[7]來獲取關鍵詞的同義詞。
(3) 關鍵詞分類模塊
在對關鍵詞分類上,首先需要大量的數(shù)據(jù)集作為訓練級,本文的訓練集由資源所在地的索引文檔提供。索引文檔是經(jīng)過預處理和TF-IDF[8]算法統(tǒng)計的所有待搜索文檔,按關鍵詞TF-IDF值從大到小排列構成,然后利用樸素貝葉斯算法對其進行分類。
TF-IDF是一種用于資訊檢索與資訊探勘的常用加權技術。其主要思想是:如果某個詞或短語在一篇文章中出現(xiàn)的頻率TF高,并且在其他文章中很少出現(xiàn),則認為此詞或者短語具有很好的類別區(qū)分能力,適合用來分類。
在形成了用戶輸入關鍵詞分類的訓練集后,就可以開始挖掘用戶的搜索興趣傾向了。本文采用簡單的樸素貝葉斯算法來實現(xiàn)對用戶關鍵字的分類。
樸素貝葉斯分類算法發(fā)源于古典數(shù)學理論,有著堅實的數(shù)學基礎以及穩(wěn)定的分類效率。同時,樸素貝葉斯分類算法模型所需的參數(shù)很少,對缺失數(shù)據(jù)不太敏感,算法也比較簡單,理論上與其他分類方法相比具有最小的誤差率。
樸素貝葉斯分類算法的思想基礎是:對于給出的待分類項,求解在此項出現(xiàn)的條件下各個類別出現(xiàn)的概率,哪個最大,就認為此待分類屬于哪個類別。用戶輸入處理模塊流程如圖2所示。

圖2 用戶處理模塊流程
圖2中訓練集的獲取需要由搜索Agent定時遍歷遠程資源服務器的資源信息,以保證訓練集的全面性。這個過程優(yōu)先級不高、花費時間較長且對樸素貝葉斯算法的準確度影響不大。日常的用戶輸入處理可直接調(diào)用本地的訓練集數(shù)據(jù),該模塊是一個獨立的數(shù)據(jù)挖掘子程序,在用戶點擊搜索按鈕后觸發(fā),為創(chuàng)建用戶個性化搜索路由表提供條件。
3.2 移動Agent的路由策略
在搜索Agent遷移過程中,為了實現(xiàn)更優(yōu)的搜索效果,本文為移動類型的資源Agent和搜索Agent設計了不同的路由策略,其中資源Agent的遷移采用最小生成樹的路由策略,而搜索Agent則采用基于用戶興趣度的個性化搜索路由策略。
(1) 最小生成樹資源路由策略
按如下步驟定義最小生成樹路由算法:
a. 設集合S={未訪問過的遠程資源服務器},N={已經(jīng)訪問過的遠程資源服務器}。初始值S={S1,S2,…,Sn},N={S0}。
b. 對任意的Si∈N,計算它到服務器Sj∈S,發(fā)送Ping命令的時間Tij,選取minTij。
c. 修改路由表,讓i服務器上的移動Agent遷移到j服務器上。若i服務器沒有駐留的資源Agent則由管理Agent新產(chǎn)生一個資源Agent訪問j服務器。
d. 將Sj加入到N。
e. 重復步驟b ,直到所有的遠程資源服務器都被訪問,資源Agent傳遞資源信息給管理Agent后,銷毀。
(2) 個性化搜索路由策略
基于用戶興趣度的個性化搜索路由策略描述如下:
a. 管理Agent根據(jù)用戶輸入處理模塊的用戶興趣度挖掘結果,從日志文件中將包含用戶最感興趣類別的遠程資源服務器信息提取出來。
b. 管理Agent按遠程資源服務器中關鍵類別資源數(shù)量多少,按照由多到少的次序?qū)Y源服務器進行排序。
c. 管理Agent對每一條資源服務器信息添加一個讀寫狀態(tài)系數(shù),初始化參數(shù)為0,形成初始化搜索Agent路由信息表。
d. 當管理Agent派遣一個搜索子Agent進行搜索時,管理Agent將路由表中與該搜索Agent遷移目的地相同的路由信息讀寫狀態(tài)參數(shù)修改為1,表示正有搜索Agent對該遠程資源服務器進行搜索任務。
e. 當一個搜索Agent完成了它所在的遠程資源服務器位置的搜索任務后,通過消息機制,管理Agent捕獲到搜索子Agent的狀態(tài)。再一次互斥讀寫搜索路由表,將當前搜索Agent停留的遠程資源服務器的狀態(tài)參數(shù)改為2,表示該遠程資源服務器已經(jīng)被成功訪問。
f. 管理Agent訪問搜索Agent路由表的下一條路由。并與之前的資源路由表比對,判斷現(xiàn)有的搜索Agent到達下一條路由的路線是否與資源Agent相同。若相同,則在搜索Agent完成搜索任務后,搜索Agent會攜帶管理Agent賦予的新的路由信息,繼續(xù)遷移到下一個遠程資源站點;若不相同,則管理Agent會創(chuàng)建一個新的搜索子Agent,遷移到下一條路由的路線。
g. 搜索Agent在完成搜索任務后,若管理Agent未賦予其新的遷移地址,搜索Agent自動返回管理Agent。
h. 當搜索Agent路由表中所有的路由讀寫狀態(tài)參數(shù)均為2時,完成搜索。
搜索路由表的格式如表1所示。
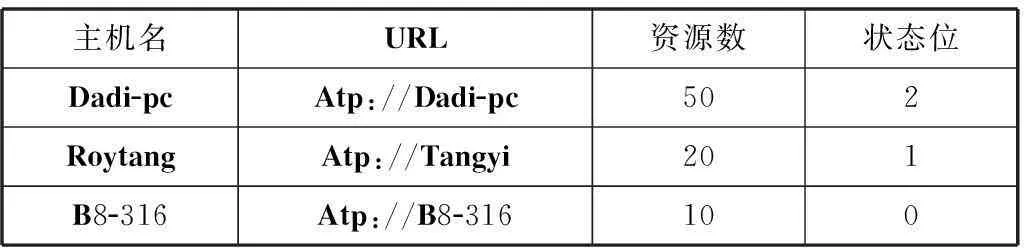
表1 搜索路由表
3.3 搜索的并行化
針對一個資源遍歷任務或文本搜索任務,往往需要多個Agent并行執(zhí)行,提高速度和效率。資源Agent的并行性主要通過最小生成樹的路由協(xié)議控制,搜索Agent的并行化則通過對搜索路由表參數(shù)的互斥讀寫并與資源Agent的比對來控制。
因此基于以上策略,用戶無需在搜索前人為規(guī)定需要幾個Agent并行執(zhí)行。而是將Agent的并發(fā)程度交給系統(tǒng)判斷,管理Agent根據(jù)路由表的訪問情況動態(tài)的添加、銷毀Agent。體現(xiàn)了移動Agent的并發(fā)智能性。
Agent的并發(fā)個數(shù)并不是越多越好。理論上同時并發(fā)的Agent數(shù)目不應該超過遠程資源服務器的數(shù)量。否則,頻繁的搜索Agent、資源Agent與管理Agent交互的輸入輸出,將影響Agent處理任務的速度。
4 系統(tǒng)實現(xiàn)與實驗
本文基于Aglet[9]平臺對以上框架進行了實現(xiàn)。Aglet是日本IBM公司基于Java技術研發(fā)成的Mobile Agent技術,通過Aglet Workbench供人們開發(fā)和實施Agent系統(tǒng)。它提供了一個簡單和全面的編程模型,可以實現(xiàn)在代理之間建立動態(tài)和有效的編程機制,同時具有易用的安全機制。Aglet同時傳送代碼及其狀態(tài),以線程的形式駐留在計算機上,可暫停正在執(zhí)行的工作,并允許將整個Aglet分派到一臺計算機上,再重新啟動執(zhí)行任務。
本系統(tǒng)主要通過建立3個Agent類來實現(xiàn),其中AgletFrame繼承Frame類,提供了用戶交互界面;SplitWord類提供了對文本分詞和去停用詞等預處理工作;SearchFile類是系統(tǒng)的關鍵,它是一個具有搜索功能的移動Agent,與AgletFrame交互,攜帶用戶的查詢關鍵字到文本所在地進行查詢。當查詢結束或者最大Agent生存時間到點后將結果返回用戶。
本系統(tǒng)采用IBM的Aglet-2.0.2版本,并安裝了jdk1.6。在局域網(wǎng)中選擇4臺電腦,其中一臺為客戶端的查詢主機安裝WindowXP操作系統(tǒng),另外3臺存有搜索資源的目標主機安裝Win7系統(tǒng),3臺目標主機中存放有利用爬蟲技術從網(wǎng)頁抓取下來的各類信息資源。以文本形式按新聞、體育、科技、財經(jīng)、娛樂5種類別進行分類存儲,信息資源在3臺目標主機上均勻分布。
在實驗之前,需要先裝好JDK并設置好環(huán)境變量,然后將Aglets-2.0.2.jar解壓到JDK路徑中并完成相關配置便可以啟動Aglets移動Agent平臺。當四臺主機都運行了移動Agent環(huán)境后,便完成了實驗環(huán)境的搭建。
4.1 與傳統(tǒng)分布式搜索對比
本文分別采用傳統(tǒng)的搜索方法和基于移動Agent的分布式搜索方法進行了某些主題的搜索,由于采用移動Agent的優(yōu)勢是并發(fā)性和個性化搜索,因此下面給出實驗的主要測試內(nèi)容與結果。
圖3顯示了本系統(tǒng)和傳統(tǒng)的分布式搜索模型的對比結果。

圖3 搜索耗費時間對比結果
通過圖3可以看出。隨著文本數(shù)目的增加,傳統(tǒng)分布式技術的效果越差,移動Agent技術支持的搜索越能體現(xiàn)出其優(yōu)越性。移動Agent攜帶搜索代碼遷移到資源所在地實行本地執(zhí)行,有效地降低了運行時間。這一點在文本資源很龐大的情況下尤為突出。
4.2 與普通Agent搜索系統(tǒng)對比
圖4顯示了測試3臺遠程資源站點的資源類別相同、各類別的資源的個數(shù)也基本一致情況下的普通移動Agent模型和本文提出的模型的搜索時間對比情況。3臺資源站點的資源各為1000個,共測試50次。普通Agent模型為3個搜索Agent遍歷所有遠程資源服務器;本文模型為具有智能并發(fā)性的個性化Agent模型。

圖4 遠程資源服務器含資源類別相同的搜索時間對比
圖5顯示了測試3臺資源站點的資源類別完全不同,且待搜索資源的個數(shù)差距較大情況下的普通移動Agent模型和本文提出的模型的搜索時間對比情況。其中3臺資源站點各有不同類別的資源1000個,共測試50次。

圖5 遠程資源服務器含資源類別不同的搜索時間對比
由上面的分析結果可以看出,本文提出的模型適用于資源分布差異化較大的一系列站點。若在資源分布相似度較高的環(huán)境下,由于涉及到用戶輸入的處理運算,搜索效果并不明顯。而將本文模型運用在差異化較大的遠程資源服務器時,根據(jù)前期的路由選擇可有效地避免對一些無效遠程資源服務器的訪問,大幅度提高搜索速度。
若擴展到多遠程資源服務器的網(wǎng)絡中,可以預見由于分類算法預測的不確定性必然會導致搜索結果精確度降低,故本框架不利于對資源相似度較高的多站點進行全面檢索。而對于規(guī)定有限搜索結果返回的資源類別差異性較大的環(huán)境中,則能最好的發(fā)揮效果。
4.3 Agent并行化對比
對資源Agent的并行化進行測試,表2分別為一個資源Agent訪問3個遠程資源服務器。規(guī)定3個資源Agent同時訪問3個資源服務器,本系統(tǒng)模型的管理Agent自主分配若干資源Agent。
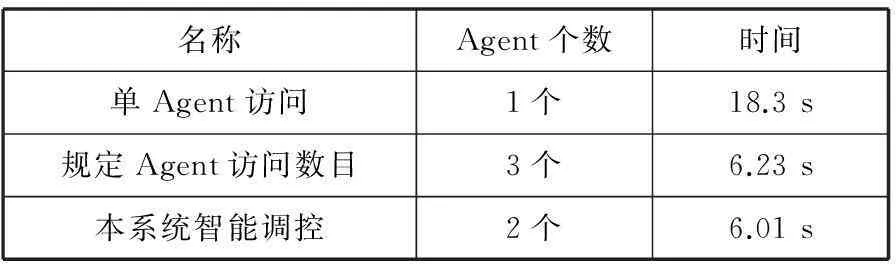
表2 Agent并行化結果
根據(jù)表2中的數(shù)據(jù)分析可以得出,多Agent并行訪問可顯著提高資源Agent的遍歷速度。與規(guī)定訪問數(shù)目的Agent進行遍歷相比,本系統(tǒng)對移動Agent智能調(diào)控,減少了一個資源Agent的創(chuàng)建,從而避免了資源不必要的浪費,減輕了系統(tǒng)壓力。同時,基于動態(tài)最小生成樹的路由策略,可以讓一部分資源Agent
完成任務后不必返回管理Agent,而是攜帶新的遷移地址,遷移到新的遠程資源服務器,提高了檢索效率。
通過以上實驗,將本文所提出的IMADS模型分別與傳統(tǒng)的分布式模型以及無并發(fā)的移動Agent模型進行比較,驗證了IMADS模型在差異化程度較大的遠程資源搜索上具有較大的優(yōu)勢。智能性的移動Agent并行化能在一定程度上提高搜索速度,減輕系統(tǒng)壓力。
5 結 語
通過以上分析可以得出,將移動Agent技術運用在分布式信息搜索上可以解決網(wǎng)絡信息服務在實際過程中的很多難點和資源限制問題,優(yōu)化了程序的執(zhí)行速度,降低了網(wǎng)絡資源的占用率。可以預見,移動Agent技術在分布式搜索上的應用將成為未來信息搜索技術的一個發(fā)展方向。隨著移動Agent技術的不斷發(fā)展和成熟,基于移動Agent的分布式搜索必將成為搜索領域的潮流。
[1] 張云勇.移動Agent技術[M].北京:清華大學出版社,2001.
[2] 何炎祥,陳萃萌.Agent和多Agent系統(tǒng)的設計和應用[M].武漢:武漢大學出版社,2001.
[3] 黃佳進,邱洪君,鐘寧.基于移動Agent的非結構化P2P網(wǎng)絡搜索方法[J].北京大學學報,2012,38(1):96-100.
[4] 王素貞,杜治娟.基于移動Agent的移動云計算系統(tǒng)構建方法[J].計算機應用,2013,33(5):1276-1280.
[5] 宋寶貴.基于過程特性的網(wǎng)絡信息重復檢索策略研究[J].計算機應用與軟件,2013,30(5):223-225,232.
[6] 潘金貴.一個個性化的信息搜索集Agent的設計和實現(xiàn)[J].軟件學報,2001,12(7):33-38.
[7] 文軍.面向查詢意圖的搜索引擎設計和實現(xiàn)[J].計算機應用研究,2012,29(10):157-162.
[8] 羅偉.基于移動Agent的主題搜索引擎研究[D].武漢:中南民族大學,2005.
[9] 徐朝輝,秦杰,甄彤.基于Agent-Aglet的Web信息檢索方法[J].微電子學與計算機,2012,29(1):60-65.
DESIGN AND IMPLEMENTATION OF MOBILE AGENT-BASED DISTRIBUTED WEB SEARCH MODEL
Li Ming1Tang Yi2
1(StateGridKaifengElectricPowerCo.,Ltd.,Kaifeng475004,Henan,China)2(WuhanDataCenter,ChinaConstructionBank,Wuhan430022,Hubei,China)
Traditional Web search methods based on C/S mode have higher requirements in bandwidths and smoothness of network, therefore their retrieval efficiency of mass data in current Internet are rather low. On the basis of analysing the features of mobile Agent technology, we proposed a mobile Agent-based distributed Web search model. According to the particularity of Chinese information search, the model combines the mobile Agent technology with classification algorithms, and introduces the pre-processing process of user inputted information into search process to classify the information, then forms the users interest degree-based route selection strategy of mobile Agent and concurrent method according to classification results, and so as to improve the efficiency of Web search. In the paper we expound the constitution of the framework and the key technologies adopted, as well as the implementation and experiments of the model on Aglet platform, a development platform for mobile Agent. Experimental results indicated that, to carry out Web search using the model could reduce the search time by 50% or lesser than the traditional C/S retrieval mode, and under the condition that there are quite big difference in categories and amounts of documents resources stored in various resource servers, its search efficiency reduced by 70% or higher than the search time of other non-concurrent mobile Agent search model.
Mobile Agent Classification algorithm Route policy Parallel method
2014-08-15。廣東省省部產(chǎn)學研項目(2012B0911004 90)。李明,工程師,主研領域:Wed信息搜索,調(diào)度自動化。唐軼,工程師。
TP18
A
10.3969/j.issn.1000-386x.2016.04.005
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
小天使·一年級語數(shù)英綜合(2018年11期)2018-11-23 09:47:26
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
資源再生(2017年3期)2017-06-01 12:20:59
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
