大數據融合、分析與價值
2016-05-14 02:53:14
信息通信技術 2016年6期
電子科技大學計算機科學與工程學院 成都 611731
引言
“數據”這一抽象的概念在我們日常生活過程中發揮著至關重要的作用,從城市交通控制系統到空間站運行,從國家政策頒發到企業戰略制定,數據無時無刻不存在于人們的日常生活過程中,并且隨著科學技術的發展而不斷推層出新。隨著最近幾十年來的數據爆炸式增長,以數據為依托的新興產業,如云計算、物聯網、社交網絡等新技術和服務日益影響著人們的日常生活,大數據時代正在悄然降臨。在全球七大重點領域內(包括教育、交通、消費、電力、能源、大健康以及金融),大數據的應用潛力高達上千億美元,相互之間以數據產品為中心的縱向結構和以大數據相關技術為核心的橫向結構不斷交錯形成新的價值鏈[1]。在這樣的背景之下,我國關于國民經濟和社會發展的第十三個五年計劃綱要更指出,需要實施國家級大數據戰略,推進數據資源的開放共享。在此期間,大數據領域必將迎來建設和投資高峰。
將數據作為一種戰略資源,實現數據成為經濟活動的主要承載者,需要著眼于大數據的生命周期和價值鏈條,而這其中主要涉及數據生成、獲取、存儲和分析四個階段。落實到具體的技術上,主要包括:1)通過大數據融合來解決數據本身的問題(包括數據量、數據類型和數據沖突等);2)通過軟件和硬件實現不同粒度的計算需求(包括存儲和計算硬件的發展和數據分析處理模型、架構的設計等);3)從精度的角度更好地發現數據背后的價值(包括人機交互、機器智能等技術的發展)[2]。目前,大數據研究的三個重要方面主要包括基于Web的互聯網應用、社會計算以及基于行業應用的商務智能和海量數據管理服務。因此,本文立足于從軟件的角度出發,通過對大數據融合、大數據分析、大數據處理平臺框架的闡述來介紹相關技術在當前背景之下的應用,并結合兩例大數據應用的具體實例,即某市醫保基金使用效率和少數民族語言翻譯與處理,從實踐價值的角度來闡述大數據應用的前景。
1 大數據融合
作為大數據的重要組成部分,數據融合最早產生于上世紀70年代,相關應用研究從最初的軍事領域逐步拓展到涵蓋資源管理、城市規劃、氣象預報等多個方面。根據定義,數據融合的過程需要實現對多個數據源信息的自動識別、連接、相關性分析和估計[3]。隨著大數據時代的到來,數據類型和維度都得到了極大豐富,挖掘并有效利用隱藏在海量數據下的信息成了企業發展和科技進步的必然趨勢,同時,這樣的需求也為大數據背景下進行數據融合帶來了諸多挑戰。
在大數據背景之下,數據的量(Volume)、多樣性(Variety)、高速變化(Velocity)的特點使得傳統數據融合工具越來越難以滿足應用的需要。目前,空間數據占了大數據比例的80%[4],在融合這一類數據的過程中,針對這些數據中的海量、多維度、多源頭、異構、冗余性、動態性和稀疏性的特點,需要結合云計算、機器學習和人工智能等領域的方法,實現“數據——信息——知識——智慧”的轉變。其次,數據標準和傳輸模式的差異造就了“僵尸數據”和“信息孤島”[5],因而需要針對多源、異類和異構的特點,對數據進行統一編目,其中主要包括數據接口定義、元數據格式以及數據編碼等內容。再次,大數據融合需要聯系割裂的多源異構數據,平衡數據規模和數據價值的矛盾,并解決跨媒體和跨語言的關聯、實體與關系的動態演化等問題,其相關的研究內容需要考慮如何加速融合效率、識別共同實體和連接關聯體,并針對沖突數據進行真偽鑒別、溯源和跟蹤[6]。此外,由于大數據異構和缺乏對數據的統一管理,在融合的過程中,有必要建立信息標準體系以及信息訪問機制,重點解決數據共享請求與分析、數據并發與同步、互斥訪問控制等問題[5]。
作為一種跨學科多方向的交叉領域,大數據融合囊括了許多傳統科學(如數學、計算機、通信等)和新興技術領域(如人工智能、機器學習、模式識別等)[7]。根據大數據融合的基本步驟,可以將其大致分為預處理和數據融合兩部分。
數據預處理需要達到的目的是從原始數據中選取合適的屬性作為后期融合的屬性,這一過程需要盡可能賦予屬性名和屬性值明確的意義,統一多數據源的屬性值編碼,去除唯一屬性、重復字段和可忽略字段。這一過程中,為了降低原始數據中的噪聲(無用字段、冗余字段等),常用方法包括分箱、聚類、回歸分析。分箱方法是一種簡單常見的預處理方法,核心思想是按照屬性值劃分子區間,通過考察同一個子區間內相鄰數據來確定最終的值。常見的分箱方法包括等深分箱法、等寬分箱法、最小熵法和用戶自定義區間法。聚類是依據對象特征屬性的距離來將一組對象按照距離指標劃分為特征相似的不同類別,并將孤立于所有類別的數據作為離群點(或噪聲)清除。其中常用的距離包括歐式距離、馬氏距離和其他根據特定場景定義的距離指標。常用聚類方法包括Kmeans[8]、分層聚類、兩步聚類和基于密度的聚類[9]等。回歸分析是指通過構建相應的數學模型,從而用一個組函數關系來描述特征變量和目標變量之間的關聯關系,通常被用來做預測分析。常見的回歸分析方法按照回歸類型的不同可分為線性回歸和非線性回歸,涉及機器學習、統計學習和人工智能等多個領域,常見的方法包括SVM、人工神經網絡、決策樹等。
通常進行融合之前的數據包含許多冗余信息,而在實際使用的過程只需要其中有用的部分,因此需要通過數據規約技術,在不破壞數據完整性的同時,通過使用比原始數據規模更小的子集進行融合。目前常用的數據歸約方法包括數據立方體聚集、維度歸約、數據壓縮、數值壓縮、離散化和概念分層等。
目前,大數據融合依賴的技術包括假設檢驗、聚類分析、濾波跟蹤、機器學習等。其中,根據對數據處理方式的不同,又可以進一步分為像素級、特征級和決策級融合。隨著傳感器網絡和物聯網在大數據時代的發展,大數據融合還涉及同類及異類數據的融合。在這之中,常用的理論方法包括貝葉斯推理法、神經網絡、Dempster-Shafer推理法、表決法等[10]。
2 大數據分析
2.1 大數據分析的幾個步驟
大數據分析是從浩瀚、廣泛的數據中發現潛在的價值與規律。大數據分析技術,不單是一個工業界的熱點,更是學術界的一個熱點研究方向,需要從理論與應用技術兩個層面進行研究。在學術研究領域,大數據分析是數據挖掘、機器學習、統計理論、復雜理論等多個學科知識相互交叉的前沿領域。在針對一個具體問題開展研究時,通常將問題分解為以下幾個步驟開展。
1)需求與問題的定義。在大數據時代中,對問題和需求的清楚定義顯得比任何時候都重要。針對具體的問題與需求,分析業務需求,清楚定義要解決的問題,才能從海量數據中提取出需要分析處理的數據,從而建立基于清楚問題的有效的數據分析模型進行研究、分析數據中的隱藏價值。
2)數據的預處理。大數據分析技術關鍵的一步是數據的預處理、感知、融合、數據表示等[11]。預處理任務通常為描述數據、數據清理、數據集成和變換以及數據離散化和概念分層等[12]。隨著互聯網2.0時代的到來,數據的類型和種類也越來越豐富,數據融合就愈發顯得重要了。數據融合技術已經成為當前學術界和工業界關注的一個熱點。
3)數據的深度理解。傳統的基于靜態、淺層特征對數據建模的方法,已經無法適應大數據時代中數據挖掘分析任務對數據的需求。對數據內容進行深層建模和語義理解,成為大數據分析技術中的難題。Web2.0時代大數據的種種特性又對數據的內容建模和語義理解的深度、關聯性與準確性提出了更高的要求。因此,通過理論方法與關鍵技術層面結合大數據的特征,針對數據挖掘與分析的特征模型、內容建模和語義理解三個方面展開研究,實現對數據的內容理解及演變規律的把握[13]。
4)數據的深度解析、挖掘及復雜數據的計算模型。數據規模的爆發式增長、數據類型多樣、結構復雜、數據維度高等特點導致傳統全量數據計算模式不再適用,數據計算基本模式面臨巨大挑戰[13]。如何應對大數據帶來的挑戰,對數據進行深度解析、挖掘,并在此基礎上構建有效的多類型復雜數據計算模型,成為大數據分析技術的核心問題。
5)驗證模型。傳統建立的分析模型都是針對小規模的數據集。針對海量數據的挑戰,應建立適應大數據分析模型,并在小部分數據進行驗證與分析,檢驗模型是否能夠很好地解決問題,滿足需要也是驗證模型有效的一個方法。模型的驗證對模型的及時修改有著重要意義。
6)部署和更新模型。通過小規模數據對數據分析模型的驗證后,將模型部署更新在實際的大數據應用分析平臺上進行運營。當面對實際浩瀚的數據時,數據分析模型的有效性、實時性得到很好的驗證,處理的實效性、實時性等標準都是檢驗模型的重要指標。對模型的更新也是數據分析模型的一個重要任務。
2.2 數據處理模型與數據分析技術
數據的處理模型和分析技術是整個大數據分析技術的靈魂,下面簡要介紹目前常見、常用的幾種數據處理模型和數據分析技術。
常見數據處理模型:MapReduce是Google提出的一種分布式海量數據處理模型;Dryad是由微軟提出的一種集群環境下海量數據處理模型,Dryad是一個通用的粗顆粒度的分布式計算和資源調度引擎;Storm是一套分布式、高可靠性、高可容錯的流式數據處理系統。
批數據處理技術:批量數據具有3個特征,數據體量巨大、精度較高、價值密度高[14]。針對批量數據特點,批處理技術適用于對實時性要求較低,數據需求量較大的數據分析任務,是實行先存儲后分析的一種數據處理技術。
流處理技術:是針對流數據的一種分布式、高可用、低延遲,具有自身容錯性的實時計算技術。針對流數據進行聚類,異常檢測,概念漂移的相關復雜的數據進行分析挖掘[15]。
近實時處理技術:大數據分析技術另外一個重點是近實時性[16],數據的價值往往在較短的時間內,所以大數據分析技術對實時性的要求很高。目前常用的方式是通過在線學習,增量式學習等機器學習方法實現對實時數據的處理。這樣的好處是能夠對模型進行快速良好的更新與修正。
3 大數據挖掘分析核心平臺
3.1 現有的主流平臺
隨著大數據時代的到來,硬件、技術和數據的不斷進化,數據分析和處理的需求也從傳統的數據分析處理擴展到從海量的數據中快速獲取有價值的信息,并以此提供低延遲、高性能、高擴展的服務。目前行業內主流的大數據平臺主要包括Cloudera、MapR、Hotonworks和Storm等。
Cloudera是基于Hadoop開源平臺開發的,定位于企業級數據分析處理的一款開源分布式平臺,其針對大數據中數據量龐大,分析過程漫長的問題,旨在加速數據分析過程[17]。Cloudera的核心部分由五個子系統構成:Cloudera Manager(主要提供系統的管理、監控、診斷和集成)、Cloudera CDH(Cloudera CDH作為分析處理的核心部分,是在Hadoop基礎上發展而來)、Cloudera Flume(Flume是一個高可靠、高可用、分布式的海量日志采集系統)、Cloudera Impala(Impala為存儲在DFS、HBase的數據提供直接查詢互動的SQL)和Cloudera hue(Hue是cdh專門的一套Web管理器,它包括3個部分hue ui,hue server,hue db)[18]。目前,包括Csico、SanDisk、SAMSUNG等公司都已成為Cloudera的受益者,而包括Microsoft Azure、EMC、TCS等公司也開放自己的產品用于支持Cloudera[19]。
MapR是MapR Technologies Inc.旗下的一款產品,作為Hadoop的一個特殊版本,MapR極大地擴大了Hadoop的使用范圍和方式,解決了Hadoop面臨的種種問題。其設計思想可以概括為以下四點:首先,在元數據服務器的架構上采用分布式取代集中式的方式,以期獲得良好的擴展性;其次,增加每個數據節點塊的數量以降低塊報告的大小;再次,進一步減小了查詢服務的內存開銷;最后,服務能夠更加快速的重啟,從而實現服務的高可用性[20]。通過上面的思路,MapR的擴展性提高了4倍以上,系統文件的容量擴大了近100倍,而文件數量則提高了1 000倍左右。此外,MapR還支持諸如隨機讀寫、快照、鏡像等應用特性。
Hortonworks是由Yahoo和Benchmark Capital聯合創立的公司基于Apache Hadoop推出的數據分析平臺,提供大數據云存儲,大數據處理和分析等服務。該平臺專門用于應對多來源和多格式的數據,并使其處理起來能變成簡單、更有成本效益,主要包括HortonworksDataFlow(收集、組織、整理和傳送來自于互聯網的實時數據)和Hortonworks Data Platform(用于創建安全的企業數據池,提供實現快速實時的商業應用的分析信息)[21]。目前包括Microsoft、SAP、EMC等公司在內都是Hortonworks的忠實客戶,其中Webtrends通過嘗試使用Hortonworks替換原有的存儲系統,并通過使用Kafka信息隊列和處理腳本,能夠在20~40毫秒之間完成數據分析,而相應的硬件成本則降低了25%~50%[22]。
Storm最早起源于Nathan Marz及其小組BackType,作為一種流式數據處理框架,其支持mirco batch和streaming processing兩種方式來處理信息[23]。從處理邏輯上來看,Storm主要包含Spout(用于把流入平臺的數據封裝成平臺內處理的stream)和bolts(對stream進行業務處理邏輯)兩部分內容,任何作業都被抽象為一個或多個spout和多層bolt來完成。從體系結構來看,Storm服從主從式的結構,其中Nimbus節點作為主節點負責作業的分配和調度,Supervisor作為從節點負責具體業務的執行,而由Zookeeper集群負責兩者之間的協調。相較于同樣是主從結構的Spark,Storm在數據的處理粒度上更小,并且因為數據傳輸方式的不同,能夠保證所有數據都被執行,并且更加適合于實時的處理需求[24]。此外,Storm在支持增量計算的高速事件處理系統中表現尤為出色,可以在等待結果的同時進一步進行分布式計算。目前,國外包括Twitter、Yahoo、Spotify等公司都在其應用中使用了Storm,而國內諸如百度、愛奇藝、淘寶網等耳熟能詳的企業也把Storm納入其產品體系內[25]。
3.2 大數據挖掘分析核心平臺
由電科軟信—電子科大聯合實驗室研發的大數據挖掘分析核心平臺,其核心功能是對結構化、半結構化、非結構化數據進行預處理和挖掘分析。提供了完備的數據預處理、分類、聚類、識別、預測、評估驗證等功能模塊。基于該核心平臺,可快速完成面向特定領域、特定業務的產品定制設計與開發。該平臺包含如下子系統(如圖1)。
1)數據存儲中心:分布式文件系統HDFS和HBase。
2)ETL中心:面向數據源完成數據抽取、清洗和轉換及落地存儲處理,主要由Sqoop、Flume、Kettle組成。
3)數據分析處理系統:提供批量處理和流式處理兩類計算模式,批量計算MapReduce為主,流式計算以Storm和Spark 為計算框架。
4)知識庫管理:對算法、數據模型和業務模型等進行統一管理,并面向批量、流式計算提供服務。
5)控制臺:負責必要的業務(流程)處理和展現處理,并按人員的角色進行功能分配,是人機操作的總控制臺。
該平臺能夠提供靈活的、可配置的算法、模型和數據,以供不同行業的業務分析師針對差異化業務進行方案制定,快速形成具有個性化的行業產品。
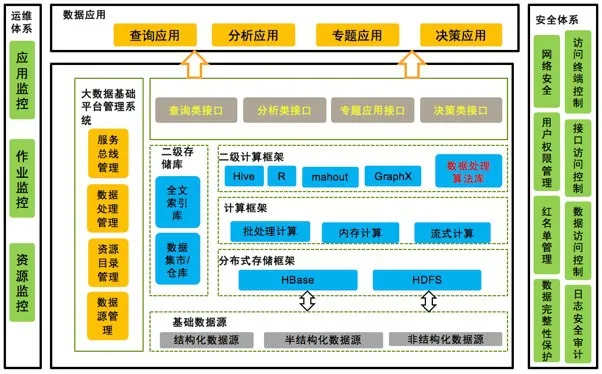
圖1 大數據處理平臺邏輯結構圖
4 大數據處理實踐與價值
4.1 某市醫保基金使用效率評價
借助于上述大數據挖掘分析核心平臺,針對某市2011~2015年的所有醫保數據(共計數百萬人,數十億條醫療報銷記錄,數據量達到TB級),我們進行了醫保基金使用效率分析與評價。
我們基于此醫保數據,結合數據挖掘思想與傳統的醫療分析方法,完成了以下業務目標,從而為政策的制定和醫療機構的質量評價提供科學的依據,
1)離群點分析:從報銷總費用和費用結構的角度實現離群點分析和醫療費用結構離群點分析。
2)醫保報銷費用決策:基于關聯規則算法和決策樹算法并結合現有報銷政策,建立醫保報銷費用決策模型,從而為醫保機構合理付費提供科學依據。
3)醫療質量評價:基于離群指標、病例優良率、轉診路徑,再次入院間隔等指標,建立醫療質量評價模型,得到各醫院的質量評價分數,完成對醫院進行醫療質量評價分級,從而達到規范醫療機構行為,促進醫療質量提升的目的。
4.2 基于大數據的智能機器翻譯平臺
為促進民族團結和文化交流,我們對互聯網上可獲取的大規模雙語語料進行遍歷搜索抓取,利用大數據分析挖掘核心平臺實現了將少數民族語言翻譯成為漢語。
翻譯引擎采用基于統計的機器翻譯框架,通過對大規模平行語料進行統計分析,構建統計翻譯模型;利用高效的搜索算法,根據待翻譯句子的上下文環境,找到最優翻譯。
少數民族語言翻譯平臺分為三層:訓練層、解碼服務層和WEB層,其中訓練層包含用于訓練翻譯系統所需的語料庫和相關工具,解碼服務層包含了解碼器、短語翻譯概率表和語言模型等,WEB層除了提供用戶界面之外,還提供翻譯API,并在其中設計了任務調度、預處理和后處理功能。
1)訓練層:主要負責翻譯模型的訓練。共分為三步:目標語言模型訓練、翻譯模型訓練,翻譯模型調優。執行這三步之前需要對已獲取的大規模語料進行快速分詞,由源語言分詞模塊和目標語言分詞模塊完成;對于雙語語料,還需要對齊,這由對齊模塊完成。對于雙語語料,需要從中按一定概率隨機抽取一部分語料用于翻譯模型調優。
2)解碼服務層:解碼器利用短語翻譯概率表、語言模型等來快速搜索最優的譯文,其中解碼器是核心部件。
3)WEB層:提供友好的用戶界面供用戶使用本系統。同時,為了處理大規模的并行翻譯請求,平臺還增加了任務調度模塊。
5 總結
本文主要從大數據分析的共性特點出發,對數據融合與大數據分析的方法、類型、軟件平臺、應用案例進行了詳細闡述。
針對不同的業務領域,數據融合與分析的方法是不盡相同的,但總的來說都會經歷相同的步驟。針對數據融合,不可避免的需要制定融合規則、數據預處理與數據整合。針對數據分析,需要經歷業務理解、數據理解、數據準備、數學建模、模型評價與優化部署六個階段。在不同的階段,必須借助或開發相應的軟件系統或算法模型完成自動化處理。
本文描述的技術路線,在實際的大數據分析應用中(某市醫保基金使用效率評價與基于大數據的少數民族語言翻譯)得到了充分應用,實踐證明,這樣的技術路線是可行、高效的。
參考文獻
[1] "十三五"數據中國建設[EB/OL].[2016-07-09].http://www.ocn.com.cn/us/shujuzhongguo.html.
[2] 大數據技術發展的十個前沿方向(上)[E B/O L].(2015-9-9)[2016-07-09].http://www.cbdio.com/BigData/2015-09/09/content_3783903.htm
[3] 李靜,賈利民.數據融合綜述[J].交通標準化,2007(9):192-195
[4] 郭立群,母東升,張海,等.面向大數據時代的數據融合系統之空間數據挖掘、分析和改進[J].測繪與空間地理信息,2013(9):15-19
[5] 康瑛石,鄭子軍.大數據整合機制與信息共享服務實現[J].電信科學,2014(12):97-102
[6] 孟小峰,杜治娟.大數據融合研究:問題與挑戰[J].計算機研究與發展, 2016, 53(2):231-246
[7] alazs J A, Velásquez J D. Opinion Mining and Information Fusion: A survey[J]. Information Fusion,2016, 27(C):95-110
[8] 高紅菊,劉艷哲,陳莎.基于改進K-means算法的WSN簇頭節點數據融合[J].農業機械學報,2015(S1):162-167
[9] 萬樹平.多傳感器數據的聚類融合方法[J].系統工程理論與實踐,2008,28(5):131-135
[10] 馬雙鴿,王小燕,方匡南.大數據的整合分析方法[J].統計研究,2015, 32(11):3-11
[11] 李志杰,李元香,王峰,等.面向大數據分析的在線學習算法綜述[J].計算機研究與發展2015,52(8):1707-1721
[12] Jianqing Fan, Fang Han, Han Liu. Challenges of Big Data analysis[J].National Science Review,2014(3):293–314
[13] 靳小龍,王元卓,程學旗.大數據的研究體系與現狀[J].信息通信技術,2013,7(6):35-43
[14] 程學旗,靳小龍,王元卓,等.大數據系統和分析技術綜述[J].軟件學報,2014,25(9):1889-1908
[15] 崔星燦,禹曉輝,劉洋,等.分布式流處理技術綜述[J].計算機研究與發展,2015(5):318-332
[16] 陳世敏.大數據分析與高速數據更新[J].計算機研究與發展,2015,52(2):333-342
[17] Cloudera[EB/OL].[2016-07-09].http://www.cloudera.com/
[18] 大數據架構師基礎:Hadoop家族,Cloudera系列產品介紹[EB/OL].[2016-07-09].http://www.36dsj.com/archives/17192
[19] Cloudera Wiki[EB/OL].[2016-07-09].https://en.wikipedia.org/wiki/Cloudera
[20] MapR公司與其產品MapR[EB/OL].(2013-1-3)[2016-07-09].http://www.caecp.cn/News/News-652.html
[21] Hortonworks[EB/OL].[2016-07-09].http://zh.hortonworks.com/products/.
[22] Hortonworks與其Hortonworks大數據平臺HDP[EB/OL].(2013-1-9)[2016-07-09].http://www.caecp.cn/News/News-650.html
[23] Storm (event processor).[EB/OL].[2016-07-09].https://en.wikipedia.org/wiki/Storm_(event_processor)
[24] Tony Sicilian. 流式大數據處理的三種框架:Storm,Spark和Samza[EB/OL].(2015-3-9)[2016-07-09].http://www.csdn.net/article/2015-03-09/2824135
[25] Storm[EB/OL].[2016-07-09].http://storm.apache.org
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
現代出版(2020年3期)2020-06-20 07:10:34
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
