基于Oracle組件的數據采集與全文檢索系統設計與優化
2016-05-14 00:24:05袁琴琴李志勛呂林濤
現代電子技術 2016年8期
袁琴琴 李志勛 呂林濤
摘 要: 從應用系統數據采集與全文檢索的需求出發,結合權限控制,提出基于Oracle Transparent Gateway,Oracle Text的數據采集與全文檢索的設計和實現方案。基于此方案,著重進行系統框架設計、采集存儲及數據庫設計,實現創建索引及檢索流程,最后給出系統性能優化方法,并對檢索速度和查準率進行測試分析。目前系統已上線運行,取得高效簡捷、運行穩定的使用效果。
關鍵詞: 數據采集; Oracle Transparent Gateway; 全文檢索; Oracle Text; 性能優化
中圖分類號: TN911?34; TP392 文獻標識碼: A 文章編號: 1004?373X(2016)08?0037?04
Design and optimization of data acquisition and full?text retrieval system
based on Oracle component
YUAN Qinqin1, LI Zhixun2, L? Lintao1
(1. Department of Electronic and Information Engineering, Xijing University, Xian 710123, China;
2. Xian Aerospace Propulsion Test Technique Institute, Xian 710100, China )
Abstract: Proceeding from the requirements of data acquisition and full?text retrieval for the application system, and in combination with the access control, the design and implementation scheme of data acquisition and full?text retrieval based on Oracle Transparent Gateway and Oracle Text is proposed. Based on this scheme, the system structure design, collection storage and database design are conducted emphatically. The index creation and search procedure were realized. At the end of this paper, the optimization method of system performance is given, and the retrieval speed and precision ratio of the system are analyzed. Now the system has been run on line, and achieved the using effect with high efficiency and stable running.
Keywords: data acquisition; Oracle Transparent Gateway; full?text retrieval; Oracle Text; performance optimization
0 引 言
隨著信息化建設的不斷推進以及信息技術的快速發展,為適應多元化業務發展需要,多個業務系統隨之建設,產生了大量的以不同方式存儲、依賴于不同數據庫管理系統的數據。例如業務數據分別存儲在SQL Server,Oracle數據庫中[1],在這些異構數據庫[2]平臺上運行著業務相關的多種應用系統。如何在不影響現有系統運行的前提下,最大限度地利用信息資源,避免重復開發,必須解決異構數據庫的統一操作問題。如何快速有效地采集異構數據庫中的信息,建立綜合信息資源庫,實現數據共享,是本文需要解決的問題之一。另外,面對綜合信息資源庫中的大量數據,怎樣在業務應用中實現快速、有效、全面的檢索效果,提高數據的利用性,也是本文需要解決的另一問題。
本文圍繞基于J2EE技術架構的多個業務應用系統開展研究,其信息來源十分廣泛,包括現有的業務管理系統、文件系統、文檔資料等。而各個系統的數據存儲方式、存儲結構、數據庫類型均不相同,如何在異構的存儲環境下實現穩定可靠的數據共享和數據采集是本文設計的要點之一。同時,業務數據涵蓋日常應用中的所有資料、文檔等信息,信息類型復雜多樣,包括結構化信息、非結構化信息、文件(DOC,PDF,txt,Excel,HTML)等多種格式。系統數據量隨著日積月累會越來越大,要在這樣大量復雜的數據中實現對多種類型信息的高效準確檢索也是本文設計的另一要點。
基于上述分析,本文采用了Oracle數據庫的Oracle Transparent Gateway[3?4],Oracle Text[5?6]等技術。在設計采集檢索功能時,不僅要滿足異構數據庫環境下數據的實時采集和共享,還要支持權限控制[7?8]下對多種類型、多種格式文件內容的高效檢索。
1 數據采集與全文檢索方案設計與實現
1.1 系統框架設計
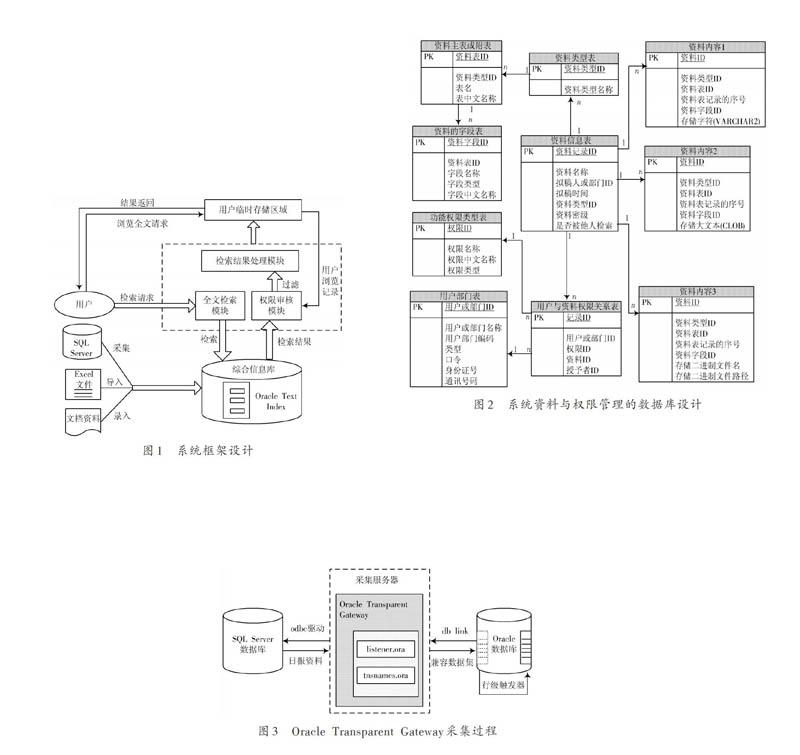
在Oracle Transparent Gateway,Oracle Text組件的基礎上,結合權限控制,本系統實現了高效簡潔的數據采集與全文檢索功能,系統框架設計如圖1所示。
系統數據來源于異構SQL Server數據庫、Excel文件和本系統的文檔資料。針對不同數據源,SQL Server數據庫采用“采集—處理—導入”的數據層集成方式,實現了異構數據向本系統數據庫的遷移,Excel文件和本系統的文檔資料通過導入、手工錄入方式將資料信息裝載入庫,自動建立全文信息索引, 為實現全文檢索奠定基礎。全文檢索建立于權限控制體制之上,首先由用戶提出檢索請求,待全文檢索模塊處理后進入綜合信息庫進行關鍵詞檢索,之后將檢索匹配的結果傳遞給權限審核模塊,然后在檢索記錄中過濾出可供用戶查閱的信息, 并將過濾后的信息經檢索結果處理模塊處理后存儲于用戶臨時存儲區供用戶瀏覽查詢。用戶瀏覽資料詳情時, 必須同時具備對資料所屬目錄的查看權限和對資料的查看權限才能查看資料。
1.2 系統實現
(1) 數據庫設計
綜合考慮系統采集檢索需求,需要采集的數據類型包含數字、字符、日期、文本等,需要檢索的資料信息分為三類:字符類型(varchar2)、大文本類型(clob)、非結構化blob類型數據(DOC,PDF,txt,Excel,HTML)。數據庫設計采用了反規范化設計方式,需要檢索的資料信息按其數據類型分別存儲在三張表:資料內容1、資料內容2、資料內容3中,每張表中均用記錄ID、資料類型ID、資料表ID、資料表記錄的ID、資料表記錄的字段ID進行關聯。系統資料與權限管理的數據庫設計見圖2。
(2) 數據采集與存儲
系統的數據來源主要有三部分:采集日報資料、導入重點資料和現行文檔資料。日報資料來源于基于SQL Server平臺的管理系統,系統采用Oracle Transparent Gateway實現與SQL Server的無縫連接,采取“采集—處理—導入”的數據層集成方式,實現了異構數據向本系統數據庫的遷移;重點資料為系統用戶批量導入的Excel信息;現行文檔為DOC,PDF,txt,Excel,HTML等格式的文檔資料。重點資料的批量導入和文檔資料的手工錄入在應用層實現。日報資料的采集是在數據層采用Oracle Transparent Gateway連接SQL Server,由PL/SQL編程實現。Oracle Transparent Gateway的采集過程見圖3。
在采集服務器上安裝Oracle Transparent Gateway for SQL Server,完成配置透明網關相關參數、listener.ora、tnsnames.ora。在Oracle端創建鏈接SQL Server數據庫的database link,發出查詢需求,SQL Server通過Transparent Gateway識別出Oracle端發出的查詢需求,獲取查詢結果記錄集,記錄類型主要包括數字、字符、日期、文本等,Transparent Gateway將記錄集數據轉換為與Oracle兼容的數據,并返回給Oracle服務器,存儲在臨時表中。通過臨時表上的行級觸發器將不同字段類型的數據導入到對應的信息資料表中。
(3) 創建索引和索引同步
系統采用CONTEXT類型索引,它支持并行檢索方式,在創建本地CONTEXT索引時,需要設置并行度和系統資源屬性。在執行檢索任務時,并行協調器依據創建索引時設置的并行度和系統資源屬性調用多個從屬進程對全文索引進行并行檢索。每個從屬進程對應于全文檢索的一個或多個分區,當檢索任務完成后,協調器負責將各個檢索結果進行匯總并傳遞給用戶。本系統分別對資料內容1、資料內容2、資料內容3的“存儲字符”、“存儲大文本”、“存儲二進制文件路徑”創建并行分區全文索引。
本系統在創建全文索引的同時采用了索引同步機制,原因是當資料內容1、資料內容2、資料內容3表中發生DML操作后,基表上對應的全文索引不會自動更新,需要手動對其更新,在此之前是不能檢索到基表中的新內容,因此需要調用CTX_DDL.SYNC_INDEX存儲過程手動同步索引。
(4) 檢索存儲過程
為實現文檔信息的全文檢索和權限過濾,本文的檢索存儲過程采用了如下核心SQL語句:
select /*+FIRST_ROWS*/ e.* from (
select b.*, rownum as rt from
(select n.資料ID,n.擬稿時間, n. 資料名稱,
u.用戶或部門名稱,t.資料類型名稱
from
(select v.資料ID from 資料內容1 v
where v.資料類型ID in (||′類型ID串′||) and
contains(v.內容, ||′關鍵詞′||,1) > 0 //全文檢索
union
select b.資料ID from 資料內容3 b
where b.資料類型ID in (||′類型ID串′||) and
contains(b.內容, ||′關鍵詞′||,1) > 0 //全文檢索
union
select c.資料ID from資料內容2 c
where c.資料類型ID in (||′類型ID串′||) and
contains(c.內容, ||′關鍵詞′||,1) > 0 //全文檢索
) y,資料信息表 n,資料類型表 t,用戶部門表 u
where n.資料ID = y.資料ID and
n.資料類型ID = t.資料類型ID
) b,
(select uip.資料ID
from (select u.用戶或部門ID from用戶部門表) u
where u.用戶或部門ID = ||′傳入部門ID′||) c,
用戶與資料權限關系表 uip,
功能權限類型表 ip
where uip.用戶或部門ID = c.用戶或部門ID and
uip.權限ID = ip.權限ID and //權限過濾
ip.權限類型= ′傳入的權限參數′) d
where d.資料ID = b. 資料ID and
b.rt >=||′翻頁記錄起始條數′||
)e where e.rownum<=||′翻頁記錄終止條數′|| )
2 系統優化
為了提高數據庫性能,加快應用系統的檢索速度,系統采用了以下方法進行優化。
2.1 采用分區表技術
系統在設計資料內容1、資料內容2、資料內容3時采用了按范圍分區的分區表技術[9?11],可以將大表分成多個存儲單元,避免了系統資料信息表作為一個大的、單獨的對象進行管理,提高了大量數據的伸縮性。
通過采用分區表技術,實現了對資料信息表的多分區管理,每個分區對應一個小的存儲單元,每個存儲單元可以單獨操作管理。檢索時采用多分區并行處理技術,減少時間開支,提高執行效率,還可通過采用屏蔽故障分區技術,確保數據檢索的可靠性。
2.2 優化檢索響應時間
在大規模數據檢索過程中,用戶期望在最短時間內看到檢索結果,可采用快速返回前幾條檢索結果的方式顯示給用戶。在編寫查詢語句時加入FIRST_ROWS提示,可以使查詢優化器以較快的查詢速度將前幾條檢索結果傳遞給用戶,避免了在整個查詢任務結束后方能瀏覽檢索結果的局限性,滿足了用戶快速檢索的需求。
另外本系統在創建CONTEXT索引時采用了索引分區技術,為分區表創建相應的分區索引。這樣在檢索過程中,只需要檢索相關的分區,特別是對于分區鍵列上的范圍搜索和排序,可避免全表掃描過程,能夠顯著縮短檢索響應時間。
2.3 定時優化全文索引
全文檢索對象所在的基表經DML操作后,其相應的全文索引不會自動更新,有必要采用全文索引同步機制。同時頻繁的索引同步操作會導致索引的碎片,過多的碎片會降低檢索的效率,因此,需要對全文索引進行優化。
例如資料信息中包含關鍵詞“優化”的文檔有doc2,doc6,doc7,當含有關鍵詞“優化”的doc8被存儲之后,倒排索引會單獨為doc8文檔創建一條索引條目,從而產生了碎片。系統采用CTX_DDL.OPTIMIZE_INDEX存儲過程對索引進行優化,可以避免碎片的產生,由于系統創建CONTEXT索引采用了分區索引技術,因此需要對每個分區進行索引優化。Oracle Text僅提供了一種手動索引優化方式,本系統采用dbms_scheduler調度的create_job創建作業,可定時自動優化全文索引。
2.4 定期維護統計信息
在Oracle較新版本中查詢優化器采用了改進的CBO(基于成本的優化器)[12],根據收集的系統統計信息和對象統計信息對查詢計劃成本進行計算,最終實施選用最低成本的查詢計劃。這就需要對系統統計信息和對象統計信息進行實時更新,以確保CBO有良好執行計劃。為獲取最新系統統計信息和對象統計信息,系統將收集表統計信息過程DBMS_STATS.GATHER_TABLE_STATS和收集索引統計信息過程DBMS_STATS.GATHER_INDEX_STATS寫入Oracle的自動維護作業中,定期自動執行,確保統計信息的實時更新。
2.5 存儲優化
若將blob格式的數據存儲在數據庫中,隨著數據量的增大,將導致全文索引的膨脹率隨之增大,不僅占用較大的存儲空間,增加管理維護難度,而且還會影響I/O效率。為此,系統采用了將blob格式(DOC,PDF,txt,Excel,HTML)數據存儲在外部專用存儲設備上的存儲方式,使Oracle Text以 FILE_DATASTORE方式進行數據訪問。另外采用了Oracle的ASM(自動存儲管理機制)以優化I/O資源實現負載均衡。通過創建ASM實例,系統可以自動將數據均勻地存儲在不同通道的不同磁盤上,實現I/O請求的均勻化,并將對文件的操作改為對磁盤組的操作,可顯著提高I/O性能。
3 系統測試分析
系統開發完成后,重點對檢索速度和查準率進行了測試,測試過程如下:對于檢索速度的測試,采用Oracle Text對1 000個Word,PDF格式文檔循環插入生成的50萬條記錄進行了查詢時間測試;對于查準率的測試,分別用微軟和Adobe的搜索工具對1 000個Word和PDF文檔進行10組關鍵詞的檢索,兩者的檢索結果合并后作為基準,與Oracle Text全文檢索結果進行比較,以確定Oracle Text檢索功能的準確性。
系統測試環境中戴爾 R720服務器CPU為2×4核E5620 2.4 GHz,內存為12 GB,操作系統為redhat 5.5 Linux,Oracle數據庫版本為Oracle 11g R2 11.2.0.4。選取50萬條文檔資料作為測試對象,在1 000,10 000,100 000,200 000,500 000條數據規模下對Oracle Text檢索分別進行了20次測試,取其平均值作為測試結果,結果如表1所示。
表1 Oracle Text的檢索時間、查準率
測試結果表明:數據庫表中的記錄在50萬數據量級的測試條件下,Oracle Text的檢索響應時間小于1 s,平均查準率為88%,可以滿足用戶需求。
4 結 語
本文采用Oracle Transparent Gateway,Oracle Text等關鍵技術,結合權限控制,給出了應用系統數據采集與全文檢索的方案設計與優化。該方案具有運行效率高、簡單快捷等優點,可以有效地采集業務系統中的異構信息資源,提供對多種類型、多種文件格式內容的高效檢索。
從該方案應用前景來看,其異構數據庫采集功能較強,不僅支持SQL Server數據庫,還可擴展至Sybase,DB2等數據庫。
參考文獻
[1] 魏永豐,劉立月.異構數據庫系統中的Oracle與SQL Server 數據共享技術[J].華東交通大學學報,2005,22(1):92?94.
[2] 郭東恩,沈燕.Oracle透明網關技術實現異構數據庫互連[J].電腦開發與應用,2008,21(9):58?59.
[3] 藍永健.利用Oracle透明網關技術進行系統整合的研究[J].廣東第二師范學院學報,2008,28(5):92?96.
[4] Oracle Corporation. Oracle 11g database documentation: gateway for SQL server users guide, 11g release 2 [R]. California, USA: Oracle Corporation, 2009.
[5] Oracle Corporation. Oracle 11g database documentation: text application developers guide 11g Release 2 [R]. California, USA: Oracle Corporation, 2009.
[6] Oracle Corporation. Oracle 11g a documentation: text reference [R]. California, USA: Oracle Corporation, 2009.
[7] 熊志輝,王德鑫,王煒,等.基于Oracle的多權限多格式文檔組織與檢索系統[J].計算機應用,2008,28(9):2407?2409.
[8] 朱松巖,葉華平,李生林,等.基于多層授權體制的檔案全文檢索系統設計與實現[J].后勤工程學院學報,2005,21(1):57?60.
[9] 李瑞麗,錢皓,黃以凱.基于Oracle大數據的全文檢索技術研究與實現[J].微型電腦應用,2013,29(1):18?21.
[10] 李尚初.Oracle的全文檢索技術[J].哈爾濱師范大學自然科學學報,2009,25(4):92?95.
[11] Oracle Corporation. Oracle 11g database documentation: performance tuning guide [R]. California, USA: Oracle Corporation, 2009.
[12] 趙偉,張學,廉鑫.全文檢索應用開發中的性能優化方法[J].信息與電腦(理論版),2011(4):65?67.
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中華手工(2017年2期)2017-06-06 23:00:31
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中外會展(2014年4期)2014-11-27 07:46:46
