
網絡搜索指數與汽車銷量關系研究
2016-05-14 20:24:35李憶文瑞楊立成
現代情報 2016年8期
李憶 文瑞 楊立成
〔摘要〕網絡搜索數據是消費者在信息搜集和購買決策過程中真實足跡的反映,對了解消費者購買需求具有重要價值。本文運用與現有研究不同的關鍵詞獲取方法,以我國汽車市場為背景,研究網絡搜索數據與銷量之間的關系。首先,確定網絡搜索數據的關鍵詞,主要運用了文本挖掘技術,具體而言:①對抓取的汽車論壇文本進行Jieba分詞;②利用Word2vec模型把分詞結果轉化為向量空間模型形式;③結合TF-IDF算法和余弦相似度算法確定關鍵詞。然后,基于108個月的長面板數據,建立網絡搜索與汽車銷量的固定效應模型。最后,采取滾動窗口的方式預測最近12個月的汽車銷量。實證結果顯示:網絡搜索與汽車銷量之間存在長期均衡關系,回歸模型可以解釋76%的方差;網絡搜索數據有助于預測我國汽車銷量。
〔關鍵詞〕網絡搜索數據;消費者;購買需求;汽車銷量;文本挖掘;關鍵詞獲取;長面板數據;預測
DOI:10.3969/j.issn.1008-0821.2016.08.026
〔中圖分類號〕F27213〔文獻標識碼〕A〔文章編號〕1008-0821(2016)08-0131-06
〔Abstract〕The online searching data reflects the real traces that consumers leave behind while gathering some information or making purchase decisions.The online searching data benefits us to know the information of what is the consumers need.In our paper,the selection of keywords differents from the existing researches,on the background of Chinas automobile market,the paper researched the relationship between online searching data and Chinese automobile sales.Firstly,identified the key words of online searching mainly according the text mining technology,to be specific:①Using Jieba segmenting the automobile BBS text captured to words;②Converting segmentary words to the Vector space model by Word2vec model;③Combining TF-IDF algorithm and cosine similarity algorithm to determinate the key words.Then,based on the 108 months long panel data,the paper established a fixed effect model between the online searching data and the automobile sales.Finally,the paper forecasted the automobile sales in nearly 12 months.The empirical result showed that:there is a Long-run equilibrium relationship between the online searching data and the automobile sales,and regression model can explain 76% of the variance.The holdout analysis suggested that online searching data can be of substantial use to forecast the Chinas automobile sales.
〔Key words〕online searching data;consumer;purchase decision;automobile sales;text mining;keywords obtaining;long panel data;forcast
搜索引擎已經成為消費者決策過程中信息搜索和評價過程的起點,根據在CNNIC調查社區進行的搜索營銷調查顯示,有77%的互聯網用戶在購買產品之前會上網搜索信息[1]。網民的搜索需求在一定程度上反映了他們的關注點和意圖,而網絡搜索數據正是對網民搜索需求的客觀記錄。網絡搜索數據的這一特性使其能夠映射用戶實際生活中的行為特點,并影響企業經營和政府管理方式,成為目前研究大數據的主要方向之一。
本文以我國汽車市場為背景,研究網絡搜索數據與汽車銷量之間的關系。之所以選擇汽車作為研究對象,是因為汽車產品屬性復雜并且要求較大資金投入,消費者在購買汽車時會對汽車產品各種屬性進行仔細考察和評估。不僅如此,汽車也是研究消費者外部搜索相關文獻中最為常用的產品對象之一[2]。
1研究意義與思路
11研究意義
網絡搜索數據的利用價值已經得到了學術界的廣泛關注。國外學者在房地產[3]、就業[4]、股票[5]、汽車和旅游[6]等眾多領域都驗證了谷歌搜索數據的作用。但是在中國,百度是應用最多的搜索引擎,因而用百度搜索指數研究中國的社會經濟行為更符合實際情況。任樂通過計算相關系數、確定領先階數并合成百度搜索指數,實證了北京市搜索數據與月旅游客流量之間的相關關系[7];袁慶玉等從網絡關鍵詞搜索數據與汽車銷量的角度建立了理論基礎框架,采用綜合賦權法對關鍵詞進行提取,預測了汽車銷量[8]。
但是對國內現有研究而言,利用網絡搜索數據預測用戶需求仍屬于一個新的研究領域,并沒有形成系統的研究體系,還存在以下不足:(1)對于關鍵詞的選取還存在爭議。多數研究是直接指定關鍵詞,或者是結合百度自動生成的關鍵詞來提取指數,并沒有考慮關鍵詞能否代表用戶實際的網絡搜索行為。(2)預測模型多采用時間序列的靜態回歸或者是對短面板數據的建模,不利于控制不同個體間的差異,也不利于準確地反映和刻畫在時間推移的過程中網絡搜索數據對銷售影響的動態變化。
為彌補現有研究存在的不足,本文在關鍵詞選擇和模型設定上都作出了改進,目的是驗證網絡搜索數據如何反映當前的汽車銷量并預測未來的銷量變化趨勢。本文的主要工作是:提出了一套結構化的流程來提取網絡搜索數據關鍵詞,并應用于我國汽車市場的研究。該流程為網絡搜索數據在其他領域的研究提供了參考。
12研究思路
本文的研究思路如下:①對汽車銷量預測和網絡搜索數據應用的相關研究進行梳理,總結出現有研究存在的不足;②以2007-2015年國內市場的汽車銷量為研究對象,基于文本挖掘技術,提出一套結構化的流程,獲得網絡搜索數據的關鍵詞,用于提取出百度搜索指數;③為避免百度搜索指數和汽車銷量之間存在偽回歸的可能性,對變量做了單位根檢驗和格蘭杰因果檢驗;④基于108個月的長面板數據,建立百度搜索指數與汽車銷量的固定效應模型,據此驗證網絡搜索數據如何反映當前的銷量;⑤采用滾動窗口的方式預測最近12個月的汽車銷量,來檢驗網絡搜索數據的預測效力。
2文獻綜述
21有關汽車銷量預測的相關研究
關于國內汽車銷量的預測,從以往的相關研究來看,學者從定性和定量兩個方面進行了相關研究。在定性方面,如:門峰等針對我國汽車產業的發展方向進行研究,認為我國汽車產業已經成為國民經濟的重要支柱產業,并預測未來5~10年是我國由汽車工業大國向汽車工業強國轉變的重要時期[9];王莉分析了國際金融危機給中國汽車行業帶來的總體影響[10]。定量方面的研究則可以分為兩個層面:一是單方法預測法(包括多元回歸分析法、時間序列預測法、神經網絡分析法),如:陳歡通過定性灰色預測模型的方法對汽車銷量進行了預測[11],該方法能夠反映復雜數據的非線性和汽車銷量數據自身的規律性,但對歷史數據過于依賴,歷史數據越多,預測結果越可靠;郭順生等基于時間序列ARMA模型對中國汽車的月銷量數據進行預測[12];汪玉秀等綜合汽車顏色、排量及版本類型3個因素,建立了馬爾科夫過程的4S店汽車銷量預測模型(預測絕對誤差均小于5%)[13]。二是組合預測方法,如:李響等基于ARMA模型與RBF神經網絡相結合的混合模型預測了天津市日汽車銷量,認為組合模型相對于單一的預測模型有較高的預測精度[14];蔡賓等采用改進差分進化算法和灰色模型對幾個主要汽車品牌的銷量進行了預測,并對汽車銷量的發展趨勢作出了判斷[15];李莉通過建立灰色模型和馬爾科夫模型相結合的組合預測模型預測了我國小排量汽車的銷量,該模型整合了GM(1,1)模型處理光滑序列的有效性和灰色馬爾科夫鏈處理隨機序列的有效性,反映出了數據序列的發展趨勢[16]。
無論是傳統的定性預測方法,還是定量預測都只能依賴于歷史數據,但歷史數據具有很強的延遲性,而且其預測的粒度較大,一般為汽車銷量的年度數據。另外,與傳統的預測方法相比,人工智能建模方法雖然預測精度較高,但也存在算法復雜性高,應用廣泛性和對原始數據的變化趨勢依賴性較強等缺陷和不足。
22基于網絡搜索數據的經濟類、社會類行為相關性研究目前基于網絡搜索數據的經濟社會類行為預測已成為各領域學者們研究的一個新的熱點,并在國內外都取得了一定的研究成果。在宏觀經濟領域,Vosen等利用網絡搜索趨勢也對家庭支出做出了預測[17];Choi等研究如何利用網絡搜索數據預測短期經濟價值,文中的例子包括房地產、失業索賠、旅游目的地規劃和消費者信心[18]。在社會領域,Ripberger等使用網絡Query搜索數據對公眾的注意力進行衡量,取得了良好效果[19]。國內學者張崇等揭示了網絡搜索數據與居民消費價格指數(CPI)之間存在一定的相關關系和先行滯后關系,并取得了良好的預測效果[20]。董倩等發現網絡搜索數據不但能夠較好地預測房價指數,而且能夠分析經濟主體行為的趨勢與規律,有一定的時效性[21]。孫毅等對相關研究進行了綜述,提出基于網絡搜索數據的相關性研究是典型的交叉研究,而對于網絡搜索數據與經濟行為之間的相關性的機理分析、關鍵詞的選擇和數據處理模型選擇是需要解決的關鍵問題[22]。
網絡搜索數據也開始用來預測汽車銷量。Du等發現從谷歌搜索數據中對38個主要汽車品牌提取出來的7大趨勢可以從品牌層面解釋美國市場74%的汽車銷量[23]。國內學者王煉等以百度搜索指數為數據基礎,探討網絡搜索在我國汽車市場的預測作用,結果顯示網絡搜索數據對汽車銷量具有顯著的正向影響,研究還發現,在其他傳統指標的數據無法獲得時,網絡搜索數據依然能夠發揮重要預測作用[24]。但王煉等是對短面板數據進行建模回歸,數據量較少,不利于刻畫百度搜索指數與社會經濟活動的動態變化,也不能確定變量之間是否存在著長期的均衡關系。
綜上所述,雖然網絡搜索數據可以作為傳統數據的良好補充來實現對市場需求的預測,但仍有以下方面可以改進:(1)該領域的很多研究都是以谷歌趨勢為數據源。雖然谷歌是全球最大的搜索引擎,但依然存在很多像中國這樣的國家偏向于使用本地的搜索引擎,因而應用百度搜索指數研究我國市場需求更符合實際情況。(2)在確定獲取百度搜索指數的關鍵詞上,并沒有一個系統化、統一的的方法。之前的研究普遍都是手動指定關鍵詞,或者是利用百度自動生成的詞。在本文中,我們基于文本挖掘技術,提出了一個結構化的流程來確定檢索關鍵詞,可以真實地反映出用戶網絡搜索的習慣。(3)以往的研究大都采用時間序列數據,或是短面板數據,不利于檢驗更復雜的行為模型。本文收集了國內市場最近9年的汽車月度銷量數據,采用長面板數據建模,可以準確地反映和刻畫在時間長期推移的過程中網絡搜索數據對銷售影響的動態變化。
3實證分析
31數據來源
311汽車銷量
本文的汽車銷量數據來源于搜狐網站汽車頻道(http∥db.auto.sohu.com/cxdata/),該數據為月度更新數據。為了研究網絡搜索數據與汽車銷量之間的長期相關關系,我們選取的時間段為2007年1月至2015年12月,共108個月。考慮到車型數據在此期間的持續可獲得性,我們將連續12個月無銷量的車型排除。最終,我們收集了55款車型在此期間的國內市場月度銷量數據。
312網絡搜索
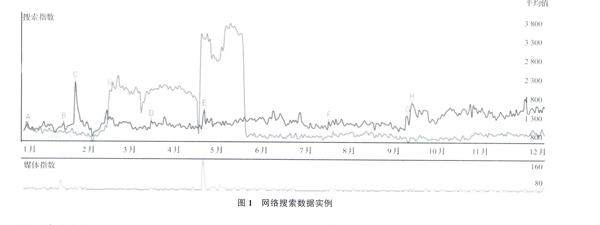
本文使用的網絡搜索數據源于百度搜索指數。百度(baidu.com)是全球最大的中文搜索引擎,截至2015年第三季度,百度在國內的市場份額達到823%,遠超過其后的“谷歌中國”(79%)、搜狗(48%)、360搜索(38%)[25]。百度搜索指數是以百度網頁搜索為基礎的免費海量數據分析服務,可以反映不同關鍵詞在過去一段時間里的“用戶關注度”。用戶關注度以數千萬網民在百度的搜索量為數據基礎,以關鍵詞為統計對象,代表了各個關鍵詞在百度網頁搜索中的搜索頻次,每天更新1次。圖1是網絡搜索數據的1個示例。顯示的是兩款車型“普力馬”和“福美來”在2015年用戶關注度的變化趨勢。可以看到,在2015年的大部分時間里,“福美來”受關注程度要高于“普力馬”,在2月初,“普力馬”的用戶關注度大幅上升而超過“福美來”,而在6月份以后,“普力馬”的受關注程度又始終低于“福美來”。
32遴選關鍵詞
在研究汽車銷量與百度搜索指數之間關系的過程中,選取恰當的網絡搜索關鍵詞是非常重要的,直接影響研究結果的可靠性。一方面,由于汽車是屬性復雜并且要求較大資金投入的產品,消費者在購買汽車時會對汽車的各種屬性進行仔細考察和評估。另一方面,根據CNNIC調查社區開展的搜索營銷調查結果,有77%的互聯網用戶在購買產品前會上網搜索信息[1]。考慮到這一點,我們選取了用戶活躍度最高的汽車論壇——汽車之家論壇來提取關鍵詞。為了準確地反映消費者考慮購買汽車并上網搜索信息時所采用的搜索詞,我們采取以下詳細步驟來確定搜索關鍵詞。
321確定基本詞條
我們根據搜狐網站汽車頻道(http:∥db.auto.sohu.com/cxdata/)所提供的車型名以及“品牌名+車型名”的組合(如:A4L以及奧迪A4L)來作為最初的基本詞條。
322獲取基本詞條的近義詞
在汽車之家論壇(http:∥club.autohome.com.cn/)該車型的論壇主題下,通過自主開發的軟件程序,采用抓取網頁的方式收集了論壇帖子的內容。為了更準確地確定關鍵詞,我們用文本挖掘技術找出基本詞條的同義詞。具體過程為:先對抓取后的文本語料進行Jieba分詞;利用深度學習的Word2vec模型對分好詞的語料做訓練,把詞轉化為向量空間模型的形式;然后結合TF-IDF算法和余弦相似度算法找出與基本詞條相似的詞條(對于延伸詞條我們不予考慮,如A4L油耗),即近義詞。對找出來的近義詞繼續做訓練,重復多次,總共得到了452個詞條。經過結構化查詢語言(SQL)去重后得到了318個詞條。
323選取論壇高頻詞條
對每一詞條我們都在論壇的文本中統計出詞頻,并選取詞頻較多的詞作為百度搜索指數中檢索的目標關鍵詞。對于仍有歧義的詞條,我們會加上品牌名來作為目標檢索關鍵詞,如“金剛”,目標詞則為“吉利金剛”。類似的例子還包括“雨燕”、“北斗星”、“高爾夫”等。
324確定最終搜索詞條
對目標詞在百度搜索指數中進行檢索,我們選取在百度指數中排名最高的詞作為關鍵詞。對于仍不能確定排名的詞,我們再選取其與銷量之間在不同滯后期0~6期皮爾遜相關系數最高的詞作為搜索關鍵詞。最終得到了55款車型可各自用于百度指數檢索的惟一關鍵詞。
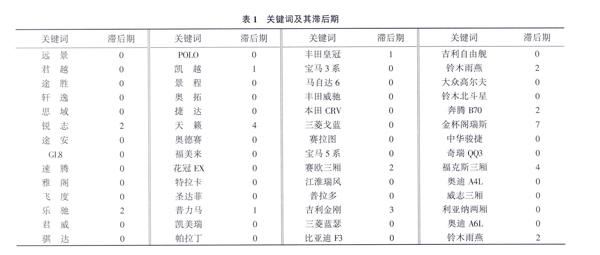
對每一個關鍵詞指數我們都計算了其與銷量在0~12滯后期的皮爾遜相關系數,表1是關鍵詞的百度搜索指數與銷量之間基于最大皮爾遜相關系數的滯后階數。可以看出滯后期普遍集中在0~2期,且其中大多數滯后期都為0期。對該現象可能的解釋是:盡管現實當中消費者在最終購買前可能會產生幾個月的信息搜索和評價過程,但是他們搜索的數量和強度都比較小,直到在購買的前1個月其搜索數量會達到1個臨界點。
4百度搜索指數與汽車銷量的關系
41單位根檢驗
本文選擇實際汽車銷量(S)為因變量,以百度搜索指數(B)為自變量。為了減少異方差對檢驗結果帶來的影響,本文數據全部對數處理(lnS,lnB),這樣處理也是考慮到了銷量和搜索指數的偏斜分布。進行對數處理還有一個好處是,在解釋估計結果時能夠以百分比變化而非絕對值的變化解釋搜索的預測作用。
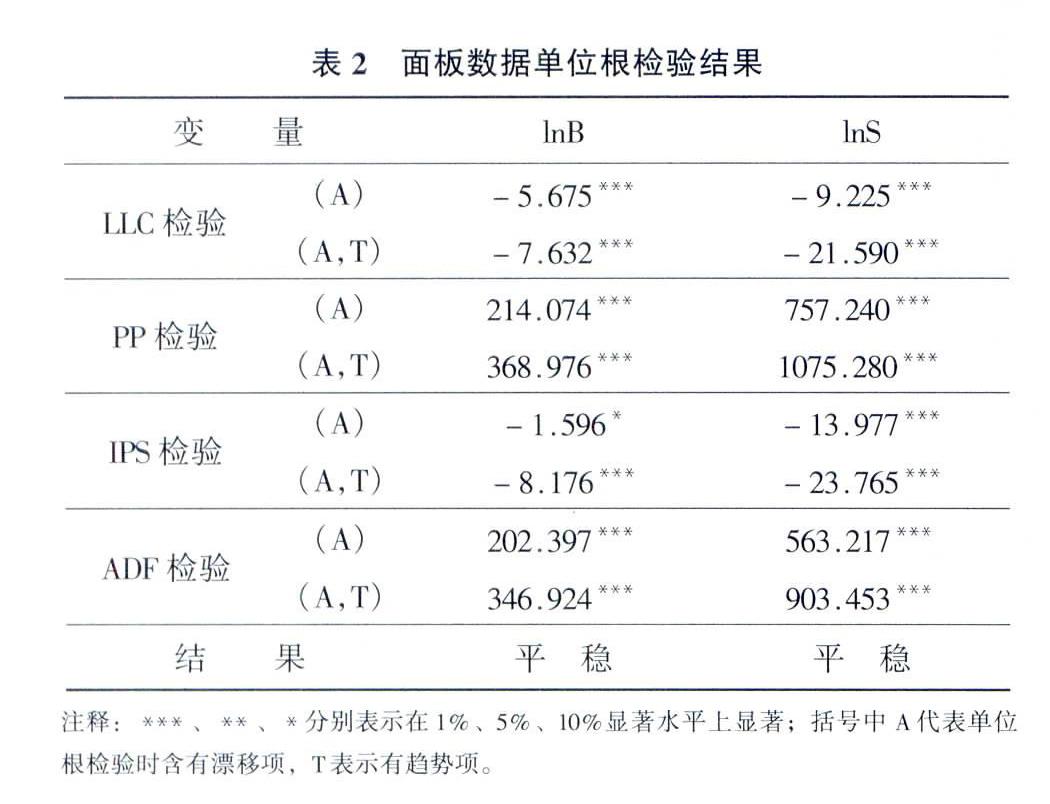
由于本文的樣本數據均為面板數據,和時間序列數據一樣,為了保證變量的平穩性和避免偽回歸現象,在建立計量經濟學模型之前要對變量進行單位根檢驗和協整檢驗。常用的面板數據單位根檢驗方法有LLC檢驗、PP檢驗、IPS檢驗和ADF檢驗等,本文采用這4種方法同時進行檢驗,檢驗結果如表2所示,由于檢驗原理不同,不同檢驗方法的結果不盡相同,本文以4種方法結果一致為準,得到汽車銷量和網絡搜索指數在所有情況下都為水平平穩。由于協整檢驗的目的是看一組非平穩序列的線性組合是否具有協整關系[26],所以本文不再對汽車銷量和網絡搜索數據做協整檢驗,而直接進入Granger因果檢驗。
42格蘭杰因果檢驗
從實際生活來看,消費者會在購買汽車前上網搜索信息,那么網絡搜索發生在購買汽車之前,也即百度搜索指數是汽車銷量的原因,為了驗證實際數據能否支撐該結論,必須進行格蘭杰因果檢驗,檢驗的前提條件是數據平穩。從網絡搜索到汽車購買,實際產出滯后期有0~2個月,但本研究以網絡搜索數據對汽車銷量的預測為目的,對同期影響不作考慮。因此本文在進行格蘭杰因果檢驗時將滯后期設定為1~2期,結果如表3所示。
從格蘭杰因果檢驗的結果看,在滯后1期和2期的情況下網絡搜索指數與汽車銷量存在著雙向互動的因果關系。但格蘭杰因果檢驗度量對汽車銷量進行預測時,網絡搜索數據的前期信息對均方誤差MSE減少的貢獻要大于另外一種情況。因此網絡搜索數據對汽車銷量具有預測作用。
51模型設定
采用面板數據分析網絡搜索與銷量關系時,首先需要用F檢驗來分析是采用混合回歸還是面板數據,結果發現本文應該采用面板數據。在研究它們的關系時很有可能會產生遺漏相關變量的問題。在回歸模型中,遺漏重要的相關變量是導致內生性的主要原因。因為一旦這個被遺漏的變量同時與因變量和目標自變量相關,那么目標自變量與隨機擾動項的無關性假定就不再成立,這時如果用最小二乘估計,目標自變量的估計就是有偏的。出于此考慮,本文首先采用固定效應模型對面板數據做估計,由此來控制由于遺漏變量而產生的內生性影響,用固定效應模型控制截面變異也是面板數據模型對于截面數據模型的一大優勢所在,而且Hausman檢驗的結果也拒絕了采用隨機效應模型來建模。考慮到銷量與網絡搜索之間存在滯后期,在該模型當中,使用前一期搜索指數和前兩期搜索指數作為自變量,以檢驗前1個月網絡搜索和前兩期搜索是否都能夠預測銷量。對車型i在時間t的銷量有如下模型:
圖2為福克斯三廂實際銷量數據和預測銷量數據的對比圖,其中lnS為實際銷量數據的對數值,lnF1、lnF2分別為提前1個月和2個月的預測。從對比圖可以看出,百度搜索指數與汽車銷量結合程度較好,模型預測效果很好。該結果再次體現了網絡搜索數據的預測效力。圖2福克斯三廂實際銷量數據與預測數據對比圖
按照Hyndman[28]提出的方法,本文選擇平均絕對誤差(MAE)作為評價預測效力的指標。平均絕對誤差的單位與因變量的單位一致,易于解釋。此外,本文還計算了預測值的均方根誤差(RMSE),因為這一指標比平均絕對誤差對異常值更加敏感,同時使用能夠更加全面地評價模型的預測效力。考慮到要反映誤差大小的相對值,本文又計算了不受量綱影響的平均相對誤差MPE。
預測結果顯示在表5當中,模型預測效果很好,加入百度搜索指數之后模型的擬合優度和預測精度都有了提高,這和格蘭杰因果檢驗百度搜索指數是汽車銷量的原因一致。對比網絡搜索提前1個月和提前2個月的預測誤差,可看出總體差別不大,提前1個月的百度搜索指數預測效果要略優于提前2個月的預測。表5各預測期樣本外預測誤差結果
誤差指標MAERMSE〖〗MPE提前1個月098315790342提前2個月0986158003426結語
本文用文本挖掘技術,對汽車之家論壇帖子提取關鍵詞,以關鍵詞的百度搜索指數為數據基礎,研究了網絡搜索數據與我國汽車銷量之間的關系,發現:①網絡搜索數據與汽車銷量之間存在著長期均衡關系,且網絡搜索數據可以解釋汽車銷量76%的方差;②可以用提前1個月或2個月的網絡搜索數據,對我國汽車銷量做預測。
本文的理論意義在于:①基于文本挖掘技術,提出了結構化的流程確定搜索數據關鍵詞,為網絡搜索數據在其他領域的研究提供了參考;②對近9年的長面板數據建立模型,檢驗了網絡搜索數據對汽車銷量的預測作用。本文的實踐意義在于:在不依賴歷史銷量數據的情況下,可以預測中國市場的汽車銷量變動情況,有利于汽車企業制定相關營銷策略和調整生產計劃,同時也為政府部門制定相關政策提供了參考。
本文的研究局限體現在:采用固定效應模型來探索網絡搜索數據對我國汽車銷量的影響,在預測效果上還可以使用其他模型來完善。另一方面,本文是基于汽車之家論壇來確定網絡檢索的關鍵詞,但在以后的研究上可以考慮綜合如微信、微博、博客等其他社交媒體來全方位捕捉消費者的在線行為足跡。
參考文獻
[1]中國互聯網絡信息中心.2012年中國網民消費行為調查報告[R].中國互聯網絡信息中心,2013.http:∥www.cnnic.cn/hlwfzyj/hlwxzbg/dzswbg/201301/t2013011638522.htm,4-4.
[2]Klein L R.Evaluating the Potential of Interactive Media through a New Lens:Search versus Experience Goods[J].Journal of Business Research,1998,41(3):195-203.
[3]Wu L,Brynjolfsson E.The Future of Prediction:How Google Searches Foreshadow Housing Prices and Sales[J].Social Science Electronic Publishing,2014.
