基于LZ編碼預測算法的數據挖掘應用研究
2016-05-14 00:20:54劉詩淼王博
現代電子技術 2016年5期
關鍵詞:數據挖掘
劉詩淼 王博

摘 要: 隨著移動通信系統的快速發展,用戶數量和業務種類的持續增長給系統設計帶來了新的挑戰。針對這種情況,研究了數據挖掘在用戶路徑預測技術上的應用,選擇LZ編碼預測方案用于數字集群系統的用戶路徑預測,并對方案進行了模擬仿真,同時分析了數字集群通信系統設備條件、應用場景和用戶移動模型的特點,證明了其在用戶路徑預測應用上的優勢。針對數字集群通信系統的特點,提出一種基于路徑預測技術的動態信道預留算法,以滿足系統QoS要求。并對提出的方案進行了Matlab仿真研究,與其他方案進行了性能比較,驗證了其在業務狀態變化下可以通過實時調整系統參數,從而降低系統切換呼叫阻塞率和提高信道利用率。
關鍵詞: 數字集群; 數據挖掘; 路徑預測; LZ編碼
中圖分類號: TN919.6?34 文獻標識碼: A 文章編號: 1004?373X(2016)05?0019?05
0 引 言
隨著移動通信系統的快速發展,用戶數量和業務種類的持續增長給系統設計帶來了新的挑戰。越區切換技術作為蜂窩小區移動通信系統的核心技術,其資源分配算法將直接決定系統的通話質量和業務承載能力。數字集群通信系統是一種專用移動通信系統,其應用場景、用戶組成都與公用移動通信系統有著顯著的不同,針對其特點設計合理的切換算法是技術發展的必然。
數據挖掘技術是近十年隨著大型數據庫技術發展、互聯網數據爆炸而產生的新的數據處理與知識發現技術,它將傳統的數據處理方法與應對大規模數據的復雜算法相結合,能夠從海量數據中發現新的數據模式。用戶移動路徑預測技術是數據挖掘在移動通信網絡優化領域的典型應用,通過對網絡運行產生的用戶數據進行挖掘,幫助系統提高運行效率和服務質量,對改善數字集群通信系統的性能具有重要意義[1]。
1 LZ編碼預測方案
1.1 方案設計
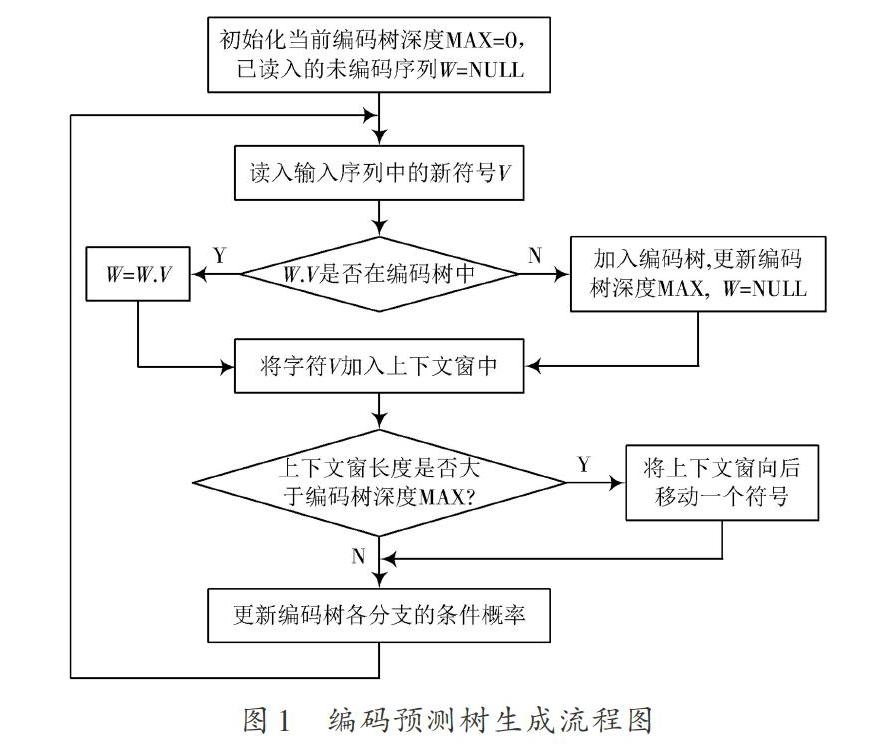
LZ78算法是較為原始的LeZi系列算法Active,編碼樹生成開始時,輸入數據就是已經處理完成的用戶移動序列,每個用戶都需要單獨生成一次預測樹并存儲起來,如圖1所示。
通過Active LZ算法預測流程圖,可以觀察到:與單階數馬爾科夫模型和序列模式挖掘方法相比,在預測過程中,可將用戶當前的移動序列與編碼預測樹中節點按條件概率最大的原則進行匹配得到預測結果,且無論預測結果是否正確,都可以實時調整編碼樹,在使用過程中提高預測精度,如圖2所示。
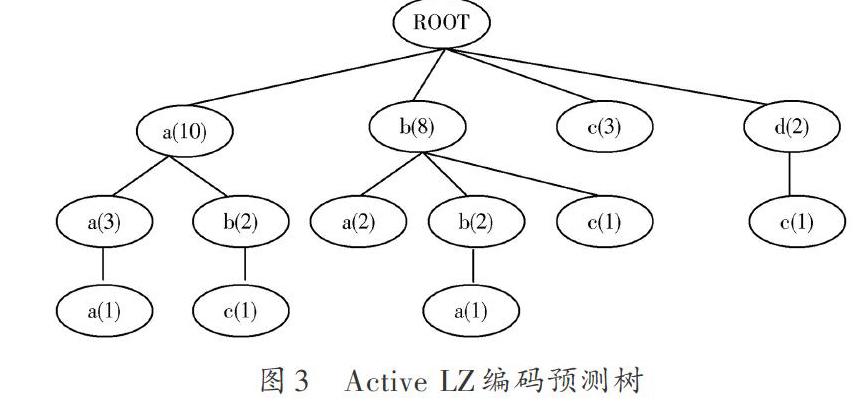
下面將給出一個基于Active LZ編碼預測方法進行路徑預測的示例:假設服務區域只有四個服務小區,編號分別為abcd,一個移動用戶移動路徑則可以被編碼為abcd組成的符號序列。為了顯示與LZ78編碼預測方法的區別,假設用戶路徑仍為“aaababbbbbaabccddcbaaaa”,通過Active LZ算法的編碼預測樹,可以觀察到某些路徑模式分支的統計頻次比LZ78算法增加了,這是因為LZ78中某些存在于讀入序列后綴中的序列模式沒有被統計,而在Active LZ中都被統計了[2]。將預測樹用于路徑預測時,假設用戶當前的路徑為ba,觀察到預測樹中ba沒有子節點,則只能按當前路徑為a來預測,觀察到a下方節點中a的子節點統計頻次最大,路徑預測結果即為a,如圖3所示[3]。
1.2 仿 真
仿真過程使用Matlab軟件進行,用戶移動模型采用隨機移動模型。考慮到不同的用戶會有不同長度的移動模式,數據集將用一個混合多階馬爾科夫模型生成。根據移動模型中目標的移動隨機程度,數據集將被分為強移動性數據集和弱移動性數據集。強移動性數據集中用戶的全部移動序列都由模型產生,弱移動性數據集則有部分用戶移動序列是等概率隨機產生的,以模擬某些移動用戶的無規律性。訓練集和測試集由同一個混合多階馬爾科夫模型生成,分別從中隨機截取而成,模型參考數[4]見表1。
表1 模型參數表
[參數\&取值 /%\&長度為2的移動模式比例\&60\&長度為3的移動模式比例\&20\&長度為4的移動模式比例\&15\&長度為5的移動模式比例\&5\&強移動數據集中由模型產生的移動序列比例\&100\&弱移動數據集中由模型產生的移動序列比例\&80\&]
1.2.1 預測精度
圖4比較了LZ編碼方案,基于Apriori序列模式挖掘方案和二階馬爾科夫預測方案對同一生成數據集的預測結果,顯示出Active LZ編碼方案在預測精度上性能稍好于其他兩個方案,驗證了在實際數據集中,用戶移動模式長短不一時,LZ編碼方案對移動模式長度的自適應特性,從而在預測精度上好于單階數馬爾科夫模型和Apriori算法。
同時可以觀察到:大多數情形下,LZ編碼和二階馬爾科夫方案預測用戶到達某一小區的數量都會大于實際到達的數量,這是因為二者實質上是概率模型,預測中總會選擇條件概率最大的分支作為預測結果,但是實際并不會總是到達該小區,因此在統計數量較小時,會出現這種預測結果大于實際結果的現象。
從LZ編碼和Apriori預測方案在兩種不同移動性的數據集中的性能可以看出兩種方案的預測正確率都有所下降,但LZ編碼預測算法性能下降的稍小一些,即使在低移動性數據集中表現也好于Apriori算法[5],如圖5所示。
1.2.2 算法對訓練集數量的依賴
二階馬爾科夫模型和Apriori預測算法在訓練集較小時就可以提供較高的預測精度,而LZ編碼預測算法對訓練集數量較為敏感,少量訓練集下預測精度低,但達到一定閾值之后,預測精度穩定后,性能優于其他兩種預測算法,三種預測方案預測精度和訓練集數量的關系如圖6所示。
2 路徑預測技術的動態信道預留方案
動態信道預留方案針對不同的場景調整信道預留策略,在保證切換呼叫阻塞率指標的同時,盡可能地提高信道利用率,改善新呼叫阻塞率。
2.1 方案介紹
動態信道預留的關鍵在于合理地針對未來業務狀態調節信道資源預留數量。為了解決這個問題,在信道預留系統之外設置一個路徑預測系統,用于預測下一時段用戶是否會到達基站覆蓋范圍,統計所有用戶路徑的預測結果,結合用戶呼叫業務狀態,就可以得到下一時段切換呼叫的到達數量[6]。
基于路徑預測的動態信道預留系統分為三個部分:信道預留系統、路徑預測系統和業務狀態模型。路徑預測系統用于對交換中心下的所有注冊用戶進行路徑預測,通過統計路徑預測的結果得出各個基站下一時段的到達用戶數量和離開用戶數量。預測結果將提供給業務狀態模型,借助到達和離開用戶數量預測結果計算每個基站下一時段切換呼叫到達率和總呼叫到達率,最后根據這些業務狀態參數調整信道預留系統的信道資源預留數量。信道預留系統是由若干個資源預留數量不同的固定信道預留系統組成,業務狀態參數和信道資源預留數量的關系將由切換呼叫阻塞率指標和信道利用率指標確定[7],如圖7所示。
2.2 仿 真
2.2.1 仿真條件
組呼是專用移動通信網絡特有的呼叫業務形式,呼叫過程中所有組內用戶共享下行信道資源,實際應用中組呼占呼叫業務比例高達80%。除去單呼和組呼,小區內還處在移動臺呼叫調度臺,調度臺呼叫移動臺等多種業務形式,為了簡化模型,將移動臺與調度臺之間的呼叫作為特殊形式的組呼,且在所有呼叫中移動臺都是發起方。此時無論對于單呼、組呼,移動臺發起呼叫都需要分配上行信道,對于基站信道資源分配來說要求是相同的。根據選取的場景,列出仿真過程中業務模型參數如表2所示。
為一個組呼組內的成員分配相同的移動模型,且組呼成員的移動模型的規律性將高于個呼用戶移動模型的規律性。仿真過程中,整個移動區域如圖8所示,共有13個服務小區,用字母A~M標記,用戶隨機從邊界進入移動區域,按混合多階馬爾科夫模型移動,仿真所預測的服務小區位于區域正中心。
在下列假設下考察基于路徑預測的動態信道預留策略的性能:服務小區內用戶的到達和離開數量基本平衡,仿真過程中固定用戶數量不變,根據用戶移動模型仿真結果調整切換呼叫比例,從而模擬服務小區內用戶移動導致切換呼叫數量變化引起切換呼叫比例變化,獲得基于路徑預測的動態信道預留策略性能曲線。
仿真過程中將以切換阻塞率小于0.03為判斷切換算法是否合格的指標。圖9中給出了仿真業務參數下切換率和切換呼叫阻塞率的對應關系,觀察可以發現,信道預留1條只能滿足切換率小于0.14時的要求,信道預留2條只能滿足切換率小于0.35時的要求,信道預留3條只能滿足切換率小于0.46時的要求。于是為了滿足切換阻塞率小于0.03,可以得到動態信道預留調節的參數如表3所示,動態信道預留算法的理論性能如圖10所示。
2.2.2 仿真結果分析
從靜態信道預留方案和基于路徑預測的動態信道預留方案瞬時切換呼叫阻塞率和信道利用率的曲線圖中可以看出,隨著切換呼叫比例的變化,動態預留方案的切換呼叫阻塞率始終保持在0.03以下,而兩種固定預留方案的切換呼叫阻塞率均有超出0.03的時刻,其中固定預留2條信道的方案幾乎完全無法滿足切換呼叫阻塞率低于0.03的要求,如圖11所示。
從給出了三種方案下切換呼叫阻塞率和信道利用率的時間平均曲線圖中可以看出,動態預留方案的信道利用率介于兩者固定信道預留方案之間,達到了75%,高于固定信道預留3條的72%,在保證切換呼叫阻塞率指標的情況下,提高了信道利用率,如圖12所示。
從三種方案下新呼叫阻塞率的性能曲線圖中可以看出動態預留方案的平均新呼叫阻塞率介于兩者固定信道預留方案之間,達到0.38,低于固定預留3條的0.42,如圖13所示。
3 結 論
本文在數據挖掘理論的基礎上選擇了基于LZ編碼的預測算法對用戶路徑序列進行處理,生成編碼預測樹,能有效地應對不同長度的用戶移動模式挖掘需求,提高預測精度。經過Matlab的仿真,證明了LZ編碼預測方案在混合長度用戶模式數據集中能夠有效提高預測準確率,并且對訓練集數量要求較低;提出一種基于路徑預測技術的動態信道資源預留方案,有效地預測業務狀態變化,并合理調整信道資源預留,始終將切換呼叫阻塞率保持在要求指標之下,同時部分改善新呼叫阻塞率性能,提高了信道利用率。
本文雖然在路徑預測技術方面做了部分理論研究,并得出了一些結論,但在工作中仍有很多需要進一步深入的問題,包括:LZ編碼預測算法在實際數據集中的預測性能需要進一步驗證;研究過程中,難以獲得真實的用戶路徑數據集;在仿真過程中以混合多階馬爾科夫模型為用戶模型生成路徑數據集以供使用,但生成數據集和實際數據集仍有很大區別,其影響需進一步研究。
參考文獻
[1] LANGDON G G. A note on the Ziv?Lempel model for compres?sing individual sequences [J]. IEEE transactions on information theory, 1983, 29(2): 284?287.
[2] GOPALRATNAM K, COOK D J. Online sequential prediction via incremental parsing: the active Lezi algorithm [J]. IEEE intelligent systems, 2007, 22(1): 52?58.
[3] 王浩,武凌,司鳳山,等.基于移動代理的分布式入侵檢測系統研究[J].重慶科技學院學報(自然科學版),2013,78(6):143?145.
[4] 王晟,趙壁芳.基于模糊數據挖掘和遺傳算法的網絡入侵檢測技術[J].計算機測量與控制,2012,20(3):660?663.
[5] 趙艷君,魏明軍.改進數據挖掘算法在入侵檢測系統中的應用[J].計算機工程與應用,2013,49(18):69?72.
[6] 段惠超,王麗俠,潘旭,等.入侵檢測系統中的帶權模式匹配算法[J].計算機技術與發展,2014,24(2):160?163.
[7] 閆光燦.60 GHz網絡MAC層的干擾抑制和空間重用[D].北京:北京郵電大學,2012.
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
