走向智能時代的語言信息化產業
2016-05-30 10:48:04郭玉箐徐俊王海峰
語言戰略研究 2016年6期
關鍵詞:搜索引擎
郭玉箐?徐俊?王海峰

提 要 語言文字是信息最主要的載體,語言文字的信息化是實現國家信息化戰略目標的基礎。在語言信息化產業中,搜索引擎和機器翻譯是最具代表性且已經實現大規模產業化的兩大領域。本文以這兩個領域為例,詳細解讀語言信息化技術和產業如何應對互聯網時代的新機遇和新挑戰,并展望語言信息化產業的智能化趨勢。
關鍵詞 搜索引擎;機器翻譯;深度神經網絡
Abstract In recent years there has been an enormous boom in Computational Intelligence in Information Systems. This paper attempts to provide rich information and professional observation about the recent progress made in adapting Chinese language processing and computing industry to the new challenges arisen from rapid advancement of the Internet as well as the worldwide proliferation of mobile devices and social media. In the process of language digitization, search engine and machine translation are the two major typical areas pertinent to large scale industrialization. Through tracing the developing trajectory of these two areas as exemplar cases, we attempt to demonstrate how language digitization as a technology and industry deals with a range of new challenges, including intelligent applications and big data, such as business intelligence, social analytics, data/text mining, machine learning, text summarization and information retrieval. In conclusion, we are optimistic for the future of the fields in achieving even better quality based on paradigm shift away from linguistic/rule-based methods towards empirical/data-driven methods which have been made possible by the availability of large amounts of training data and large computational resources.
Key words search engine; machine translation; deep neural network
互聯網技術和產業的飛速發展,不僅使信息量呈爆炸式增長,更帶來了豐富多變的語言現象,對語言信息化技術提出了新的需求和挑戰,驅動搜索引擎、機器翻譯等語言信息處理技術和產業的快速發展。近年來,隨著云計算、大數據處理、深度學習等技術的進步,更加智能化的互動型產品也由實驗室階段逐步走向市場化。本文以搜索引擎和機器翻譯為例,闡述互聯網時代背景下語言信息化面臨的問題、解決的技術手段和前進的方向。
一、互聯網時代的新機遇與新挑戰
語言文字的數字化徹底改變了人們使用語言文字的方式,從學術論文、會議紀要、工作匯報到生活日記,幾乎所有書寫的場合均可以使用計算機來完成。數字化極大地便利了語言信息的編輯處理,也為語言信息的高效傳遞奠定了必要的基礎。數字化的語言信息幾乎沒有重量、沒有體積,互聯網的興起使得語言信息的傳遞沒有了距離,從而極大地降低了語言信息傳遞的成本,空前地提升了語言信息傳遞的效率。互聯網的迅猛發展,深刻地改變了語言信息獲取和傳播的方式,帶來了海量規模的數據和多元化的信息資源,產生了大量新的語言現象和問題,這為語言信息化產業發展帶來了新的機遇,同時也向語言信息處理技術提出了新的挑戰。
(一)新模式
互聯網時代不僅催生了新型的信息承載形式——網站,也帶來了信息獲取和傳播方式的革命性變化。
在早期的門戶網站時代,網站在信息傳播中居主導地位,網站是信息匯總和發布的平臺,語言信息從網站單向傳播給用戶。在中國,新浪、網易、搜狐等一批門戶網站的首頁曾是用戶獲取信息的大門。
此后,用戶在信息傳播中由單純的閱讀者越來越多地參與到信息的建設中,普通用戶既是網站信息的閱讀者又是網站信息的貢獻者,語言信息開始在網站和用戶之間雙向傳播,即進入了交互網站時代。wiki、百科、知道、博客等新型網站開始大量涌現。交互式網站允許用戶以多種形式參與網站內容的編輯。博客網站一般允許用戶在網站留言評論,網站所有者(博主)可以回復評論。以百度知道為代表的問答類網站提供了一個網友之間相互答疑解惑的平臺,有相同或相似疑惑的用戶可以通過其他用戶的回答獲得信息。交互網站逐步發展,衍生出社交網站。網站的角色徹底淡化,成為一個信息多向交互的通路,社交網站改變了之前以信息為中心的傳遞模式,隨著以微信為代表的微型通信服務平臺的出現,用戶和用戶之間可以直接交流觀點,可以分享朋友圈的信息,徹底實現了以用戶為中心的信息傳遞模式,語言信息傳播的途徑被完全打通。
(二)新資源
隨著信息傳播方式的演進,互聯網上語言信息資源的特點也呈現出變化:從規模大到來源多、變化快。
短短數年之間,互聯網就積累了海量網頁,這些是語言信息處理重要的語料來源。互聯網的規模有多大?恐怕很難有人能給出一個精確的數字。但可以肯定的是,互聯網上所蘊含的信息已經遠大于世界上所有圖書館所擁有的信息的總和。百度作為世界上最大的中文搜索引擎,抓取到的網頁數量已達到千億量級。這些海量規模的網頁,本身即是信息獲取的來源,同時也真實地體現了各種語言現象,基于這些超大規模的語料庫,可以進行統計分析,并從中抽取語言特征和規律。
交互式網站帶來的是用戶生成內容,這是互聯網時代的新生語言信息和資源。UGC數據可細分為三類,即知識分享數據、博客和微博數據以及社區/論壇數據。知識分享型資源,如wikipedia、百度百科等在線百科類資源,由人工編輯,相對內容準確、噪聲較少,對于實體識別、信息抽取和自動文摘等語言信息化技術具有重要價值。博客/微博近年來越來越成為普通網民展示和表達自我的方式。根據2015年新浪第三季度財報,截至2015年9月30日,新浪微博月活躍用戶數已經達到2.12億人。博客/微博數據的最大特點在于其內容的個性化、主觀性以及時效性。這些特點使其在語言信息處理的很多方向上可以被加以研究和應用,例如用戶個性化興趣模型的構建、博客和微博內容的個性化推薦、主觀性內容的情感傾向性分析、熱點事件及輿情的檢測與跟蹤等。社區/論壇數據內容豐富,從社區和論壇的發帖、回帖數據中可以抽取問答知識,提供問答資源的檢索與推薦,或是對問答資源的數據質量進行自動評估。
(三)新問題
互聯網在提供給我們豐富多樣的資源和數據的同時,也提出了諸多的問題和挑戰,具體體現在以下兩個方面:
其一,應對快速涌現的新的語言現象,包括:新詞(如“給力”“雷人”),新概念(如“80后”“啃老族”),新專名(如“筷子兄弟”“旭日陽剛”),新用法(如“粉絲”“圍脖”),以及大量的網絡語言甚至“火星文”等。UGC數據的膨脹催化了新的語言現象的出現,同時也給自然語言處理技術帶來了很多新課題。只有準確地對新詞進行切分,對新概念/新專名進行挖掘,對新用法進行統計,對網絡語言進行改寫和規范化,才能夠滿足信息抽取、機器翻譯、自動問答等應用需求。
其二,數據噪聲的過濾與糾錯。互聯網數據的一大特點是信息的質量良莠不齊,具體體現在網頁數據中含有為數不少的不實新聞、虛假廣告、“軟文”等內容;在UGC數據中更是含有非常多的主觀性內容。因此在利用互聯網數據的時候應首先考慮數據內容的真實性、可信度、主觀性等方面,否則便容易受到錯誤或不實信息的誤導。此外,互聯網信息中還含有很多失范現象,主要體現為錯用別字、同音近音替代、表達隨意、句法不規則等。這些失范現象給語言信息處理的一系列底層技術,包括分詞、詞性標注、句法分析等提出了難題。因此一方面需要考慮如何對不實信息進行甄別,另一方面也要考慮如何對噪聲數據進行糾錯和過濾。(Sun et al. 2010)
互聯網時代,語言信息以驚人的速度增加,千禧年左右廣為引述的一句話很好地闡釋了這個時代的特征:“近30年來,人類生產的信息已超過過去5000年信息生產的總和。”而事實上,這個速度仍在加快,最新的數據顯示,人類近四五年產生的信息已經超過過去5000年信息生產的總和。在浩如煙海的信息之中,如何將人們同所需要的信息連接起來就成為互聯網時代語言信息化的核心目標。
二、搜索引擎
語言信息爆炸增長給用戶便捷獲取信息帶來了嚴峻挑戰,如何高效搜索到所需信息成為語言信息化的焦點,直接帶動了搜索引擎行業的蓬勃發展。
(一)傳統搜索模式
搜索引擎是指按照一定的策略從互聯網上收集信息,在對信息進行組織和處理后,為用戶提供檢索服務,并將相關信息展示給用戶的系統。互聯網發展早期,以雅虎為代表的網站分類目錄查詢非常流行,網站分類目錄由人工整理維護,精選互聯網上的優秀網站,并簡要描述,分類放置到不同目錄下。用戶查詢時,通過一層層的點擊來查找自己想找的網站。目錄查詢方式的效率顯然遠高于盲目的“地毯式搜索”,但是人工維護這樣一個目錄勢必難以適應互聯網語言信息數據的爆炸式增長。
此后,以谷歌搜索、百度搜索為代表的新一代搜索引擎推出了基于關鍵詞的全文檢索模式,搜索引擎對從互聯網上收集到的網頁數據進行信息提取并組織建立索引庫,然后依據查詢的關鍵詞在索引庫中檢索出相關網頁,并對網頁和查詢詞的相關度進行評價后返回結果。大致包括以下三個步驟:
1.搜集信息:搜索引擎利用稱為“網絡蜘蛛”的自動搜索機器人爬取每個網頁的超鏈接。機器人程序順著的超鏈接,從一個網站爬到另一個網站,就像日常生活中所說的“一傳十,十傳百……”,從少數幾個網頁開始,沿著網頁上的超鏈接,機器人便可以遍歷互聯網上的絕大部分開放網頁。
2. 整理信息:搜索引擎不僅要保存搜集起來的信息,還要將它們按照一定的規則進行編排。這個過程稱為“創建索引”,具體包括去除重復網頁、分詞、提取關鍵詞,并使用一種名為“倒排索引”的技術建立索引庫。如果信息是不按任何規則隨意堆放在搜索引擎的數據庫中,那么每次查找信息都得把整個數據庫完全翻查一遍,這樣即使是再快的計算機系統也沒有用。有了索引,搜索引擎就不用重新翻查所有保存的信息而迅速定位到所要的資料。
3.接受查詢:用戶輸入關鍵詞進行查詢,搜索引擎接受查詢并向用戶返回資料。搜索引擎每時每刻都要接到來自大量用戶發出的查詢,并根據這些查詢檢索索引數據庫,快速找到與用戶需求匹配的網頁,在對網頁進行相關性排序后返回給用戶。目前,搜索引擎返回結果主要是以網頁鏈接的形式提供的,通過這些鏈接,用戶便能到達含有自己所需資料的網頁。通常搜索引擎會在這些鏈接下提供一小段來自這些網頁的摘要信息,以幫助用戶判斷此網頁是否含有自己需要的內容。
(二)現代搜索引擎
雖然基于關鍵詞的全文搜索引擎較之早期的目錄索引無論在網頁數據搜集還是在用戶檢索效率上都有了質的飛躍,但是隨著互聯網海量信息的快速增長,由原來的以單一的文本信息為主發展成為文本、語音、圖像等多模態的信息處理。同時,用戶的需求也從關鍵詞搜索為主的信息獲取向著基于語義理解的自動問答、輔助決策等智能交互的方向發展。這對現代搜索引擎提出了更高的要求,首先由于信息量急劇膨脹,要求返回排序結果更為準確;隨著搜索廣度和深度的提高,要求對返回結果有匯總和聚合的能力,或者對于用戶問題能夠直接給出答案,實現“即搜即得”;更進一步,現代搜索引擎要能真正理解用戶需求,基于用戶行為實現個性化推薦和引導,即“不搜即得”。它有如下兩大特點:
1. 更準確的結果排序
優質的搜索引擎返回的結果應該和用戶查詢具有緊密的基礎相關性,此外還要考慮結果的權威性、時效性、多樣性等,反映用戶的個性化需求并過濾作弊結果。準確的結果排序依賴于分詞、詞性標注、命名實體識別、詞匯重要度、詞匯相關度計算等自然語言處理、機器學習和大數據挖掘技術。
由于網絡語言具有碎片化及口語化的特點,要求現代搜索引擎具有更強的語義表達能力,包括拼寫糾錯、詞干提取、繁簡轉換、數字格式統一、同義詞發現、近義表達歸一化等。例如“明天傷害的天氣”,對于這個查詢,糾錯技術需要自動甄別出其中可能存在的輸入錯誤:“傷害”應為“上海”。針對口語化結構靈活的用語,需要復述和改寫技術,一種方法是借鑒機器翻譯的思路,將查詢改寫看作是同一種語言間的翻譯問題,將用戶的冷門查詢“翻譯”成同義熱門查詢;或者通過從互聯網資源中抽取復述短語(Bhagat & Ravichandran 2008),對相似意圖的語句進行聚類和歸一。如“請問明天上海的天氣怎么樣啊”是很口語化的查詢,在語義上等同于“明天上海天氣”這個更常規化的句子。進一步,還可以基于當前日期對“明天”進行解釋,以便于精確查詢。
近年來深度神經網絡(DNN)技術再次獲得人們的廣泛關注,在自然語言處理中,主要使用DNN技術學習詞匯的語義表達,即在大量語料統計的基礎上,將詞匯映射為一個低維連續向量,稱之為詞嵌入(Bengio et al. 2003)。基于詞嵌入的表示方式,不僅一定程度上可以使意義相似的詞具有相似的向量,還可以容易地表征詞匯之間的類比關系,如果以W(“**”)表示“**”這個詞的向量,則有W(“女人”)-W(“男人”)≈W(“王后”)-W(“國王”),利用詞嵌入的這種屬性,可以更好地對詞匯之間的“相關/互斥”關系建模。同時,DNN技術可以充分利用幾十億用戶的點擊行為數據進行模型訓練,通過自動學習獲取用戶查詢與網頁相似性特征,從而有效地提升返回結果排序的準確性。
準確的返回結果不僅指與查詢語句的相似度,也包括對用戶個人信息的匹配度。例如,同是“蘋果”這條查詢,不同用戶的需求可能不同,包括水果、蘋果公司、蘋果筆記本電腦、蘋果手機或者名為《蘋果》的電影等不同的可能。每一個用戶的職業、年齡、興趣愛好等個人特征很大程度上決定了該用戶預期看到什么樣的搜索結果。即使是同一個用戶搜索“蘋果”,他想得到的搜索結果也可能不盡相同,因為用戶在搜索時所處地點和狀態也是影響其搜索需求的重要因素。為了使返回結果契合用戶查詢,需要用戶建模技術,包括個性化和場景化建模。所謂個性化建模,是指針對每個人的屬性(如性別、年齡等)、狀態(如上學、求職等)、興趣(如喜歡科幻電影、搖滾音樂等)、消費習慣(如經常購買電子產品等)等方面建立模型。例如,“中學生”在搜索引擎的查詢中常會出現“試卷”“成績”“考試”等關注點,“大學生”的查詢里面常會出現“考研”“四級”“簡歷”等關注點,“上班族”的查詢里面常會出現“搜房”“稅率”“人事”等關注點。場景化建模則是指針對時間、地點、上下文語境甚至輸入終端等條件建立模型。只有準確全面地了解用戶信息,才能正確理解用戶的意圖、預測用戶的行為,從而提供準確匹配用戶需求的搜索結果。
2. 更直觀的答案展示
對于現代化搜索引擎的另一個要求是,不應當只是給出搜索結果列表,讓用戶自己從中查找想要的信息,而是要做到真正理解用戶問題,直接給出答案,找到服務。在這個需求驅動下,一種稱之為知識圖譜的關系網絡應運而生。知識圖譜旨在描述真實世界中存在的各種實體或概念。其中,每個實體或概念用一個全局唯一確定的標識符來標志,用屬性—值對來刻畫實體的內在特性,用關系來連接兩個實體并刻畫它們之間的聯系。知識圖譜的構建通常從包括百科類數據在內的多種數據源分別獲取候選實體及其屬性信息,從網頁和文本中抽取兩個實體間的關系(Banko et al. 2007)。知識圖譜的構建依賴于實體識別、實體對齊、屬性歸一化等自然語言處理技術及遠距離監督學習等機器學習技術。
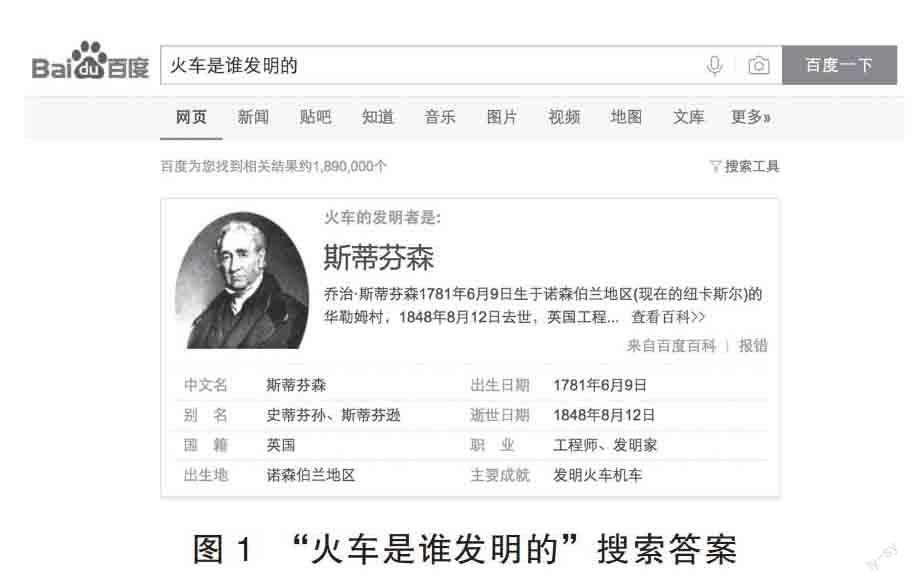
當用戶查詢與一個命名實體相關的問題時,基于構建好的知識圖譜,可以通過卡片等特殊形式展現問題中涉及的實體及其各種屬性。例如,用戶詢問“火車是誰發明的”,搜索引擎直接返回答案“斯蒂芬森”及其別名、國籍、出生地、出生日期等相關信息,給用戶以更加直觀的滿足。
圖1 “火車是誰發明的”搜索答案
此外,知識圖譜還可以賦予搜索引擎簡單的推理計算能力。比如,查詢“180以上的男明星”,可以推測出這里的“180”是指人的身高,并據此搜索圖譜中所有身高在180cm以上的男明星,給出符合問題的答案集合。
是非型問題,如“寶寶能吃海參嗎”“羽絨服能不能水洗”,以及觀點類問題,如“寶寶打嗝兒怎么辦”“紅燒肉怎么做”等,是知識圖譜不擅長的,此時需要深度問答技術。深度問答技術在自動分析問句需求和類型的基礎上,利用搜索技術從網頁中自動挖掘到一批候選答案,之后過濾、計算每個答案的相關性分數和可信度,最后排序輸出可信度高的答案。其中不僅需要搜索結果聚合技術,還涉及自動文摘技術。例如,詢問“wifi密碼怎么改”,搜索引擎可以查找到“百度知道”中含有的相關答案,并對答案進行整理和摘要,基于匯總的結果生成步驟式的可讀性強的答案。
3. 更高效的用戶引導
現代搜索引擎,除了根據關鍵詞相關性排序返回結果列表,還應具有查詢引導機制,即根據用戶信息和搜索歷史,推薦相關高質量的查詢給用戶,引導用戶瀏覽相關內容,讓用戶更快地得到所求。
高效的推薦引導,往往充分利用大數據挖掘技術,根據用戶過往的搜索會話和點擊日志等預測用戶的關注點,準確擴展出與用戶輸入搜索意圖相似或相關的高質量查詢,引導用戶進行新的搜索。例如,搜索“青藏高原”后,百度搜索識別出這是一首李娜的歌曲,猜測用戶對李娜的歌曲感興趣,則在主頁面的右側醒目地推薦“李娜的熱門歌曲”,引導用戶繼續點擊。而當用戶搜索“小威”的時候,右側也會推薦“李娜”,但這次推薦的不是歌唱家李娜,而是網球明星李娜,這是依靠大數據實現的實體消歧技術。此外,每個推薦實體的下面都會有一行灰色的小字,稱為“推薦理由”,目的是給用戶呈現更豐富的信息,同時也可以增加吸引力,讓用戶對推薦的內容更感興趣。
推薦引導不僅可以在搜索完成后,還可以貫穿在用戶查詢操作的過程中,即用戶已經開始在搜索框中輸入關鍵詞但輸入還未完成的階段。此時最常采用的方式是使用suggestion(簡寫為sug)的方式,結合用戶當前輸入,向用戶推薦完整的高質量查詢。優質的sug,需結合用戶輸入的上下文動態變化,例如用戶在前一個查詢中輸出了“百度股價”,之后再輸入“谷歌”時,根據上下文預測用戶查詢的是“谷歌股價”,并將其列在sug的首位;而如果用戶前一個查詢是“百度翻譯”,則再次輸入“谷歌”時,sug的首位則變為“谷歌翻譯”。此外,還有“點擊后推薦”,即當用戶點擊后回到搜索結果頁時,在用戶點擊過的結果下為用戶推薦相關查詢。“上翻推薦”,當用戶上翻搜索結果頁時,隨著用戶上翻網頁的同時,向用戶推薦相關查詢。還有更為醒目的通欄“瀏覽式引導”等。這些都為提升用戶體驗、激發用戶需求、加速信息傳遞和獲取的效率提供了很好的手段。
回顧互聯網的發展歷程,搜索引擎不愧為其中發展最為迅速的領域之一,如今,提供多語言搜索服務的谷歌公司的市值已突破5000億美元,僅次于蘋果公司位列全球企業第二。在中文搜索市場上,百度則一直獨占鰲頭,每天響應著來自世界上100多個國家和地區的幾十億次搜索請求。毫不夸張地說,沒有搜索引擎,也就沒有互聯網的今天。
三、機器翻譯
機器翻譯綜合多種語言的詞法、句法、語義分析和生成等技術,一直被公認為自然語言處理研究最難的課題之一,也是人工智能領域的終極目標之一。同時,機器翻譯又有著廣闊的應用場景,可以帶來豐厚的經濟效益和社會效益。
(一)發展簡史
早在計算機誕生之時,美國洛克菲勒基金會副總裁W. Weaver就提出并和英國工程師A.D.Booth討論過利用計算機進行語言自動翻譯的想法。1954年1月7日,美國喬治敦大學和IBM公司在IBM701上進行了第一次機器翻譯試驗,真正標志著機器翻譯在人類歷史上的出現。在中國,1956年機器翻譯被列入中國科學工作發展規劃。1957年,中國科學院語言研究所與計算技術研究所正式合作開展俄漢機器翻譯試驗,這可以說是中文信息處理的第一項工程。此后,機器翻譯經歷了20世紀50年代到60年代前半期不斷上升的發展期,到1966年,美國科學院語言自動處理咨詢委員會(簡稱ALPAC委員會)公布了一個題為《語言與機器》的報告,該報告全面否定了機器翻譯的可行性,機器翻譯發展陷入了停滯期。直至70年代中期,各國科技情報交流日趨頻繁,計算機科學、語言學研究特別是計算機硬件性能大幅度提高,驅動機器翻譯研究逐漸走向復蘇。這一時期,機器翻譯技術以基于規則的方法為主,在“中間語言”模式的基礎上進行源語言分析和目標語言生成方法的探索(董振東 2000)。
進入90年代,商業和信息的全球化使得對翻譯的需求空前增加,機器翻譯進入快速發展的時期。在中國,隨著中軟公司率先推出“譯星”翻譯軟件,“雅信”“通譯”“華建”“東方快譯”等產品相繼上市,實現了機器翻譯的產品化和商業化。這時的機器翻譯研究被新興的基于語料庫的方法向前推進著,由IBM公司研究人員提出的統計翻譯模型替代基于規則的方法成為主流,此外,日本著名的機器翻譯專家長尾真提出的基于實例的機器翻譯方法也具有比較廣泛的影響。在翻譯形式上,除了自動翻譯,還出現了更貼近實用化的計算機輔助翻譯工具,比如Trados公司的Translator Workbench,國內交大銘泰公司的雅信CAT系統等。這些系統融合了文本處理和出版軟件、術語管理以及翻譯記憶庫等,可以輔助專業翻譯人員提高工作效率,對傳統語言翻譯產業產生了極大的沖擊和影響。
(二)互聯網機器翻譯
隨著互聯網的發展和經濟全球化時代的到來,克服語言障礙、實現跨語言自由溝通的需求日益凸顯。網絡時代對機器翻譯技術提出了新的挑戰:(1)互聯網數據規模和翻譯需求的激增,導致翻譯系統計算負荷加重;(2)互聯網數據復雜多樣,語言資源噪聲大,領域分布不均,大多數小語種語言數據稀缺,翻譯知識獲取困難;(3)語言歧義現象多,語義理解困難,難以構建高質量翻譯系統。
在這樣的背景下,2010年初,百度組建了機器翻譯團隊,研發基于互聯網大數據的機器翻譯系統。2011年6月30日,百度機器翻譯服務正式上線,經過幾年的不懈努力,不斷實現機器翻譯領域技術難題的突破:(1)構建了基于互聯網大數據的分布式機器翻譯模型,快速響應高負荷翻譯需求;(2)將百度最先進的搜索技術與翻譯技術相結合,基于網頁檢索、網站權威性計算、大數據挖掘、新詞偵測等技術,從海量的互聯網網頁中獲取高質量翻譯知識。同時提出了基于“樞軸語言(pivot
language)”的機器翻譯模型,攻克了機器翻譯中小語種覆蓋和語言快速遷移的難題;(3)2015年5月,百度上線了世界上第一個基于深度學習的大規模線上機器翻譯系統(He et al. 2016),并結合百度已有的多種主流翻譯模型,包括傳統的基于規則、基于實例、基于統計等翻譯策略,發揮多種方法的各自優勢,減少語言語義歧義,大幅提升了翻譯效果。目前百度翻譯可支持漢語、英語、西班牙語、日語、韓語、法語、俄語等27種語言,702個翻譯方向,每天響應近億次的翻譯請求,在全球擁有超過5億的用戶。百度翻譯語種目前已覆蓋全球超過88%的國家和地區,惠及47億世界人口。機器翻譯技術的突破為人們生活帶來各種便利,小到出國旅游、科技文獻翻譯,大到國際貿易、跨語言文化交流,用戶可以通過百度機器翻譯,解決衣食住行中遇到的各種語言難題。
此外,百度還通過開放API(應用程序編寫接口),支持了華為、金山、OPPO、敦煌網等上萬家第三方翻譯應用,有力地提升了中國企業的開放創新能力,帶動了相關產業的繁榮與發展。2015年,百度與中科院自動化所、中科院計算所、浙江大學、哈爾濱工業大學和清華大學共同研發的“基于大數據的互聯網機器翻譯核心技術及產業化”項目,憑借最廣泛的全球使用人群及其實用價值,榮獲了國家科學技術進步二等獎。
機器翻譯研究已走過半個多世紀歷程,人類對機器翻譯的探索和渴求始終沒有停止過。兼通文理、統合技術與藝術的學科魅力吸引了無數的研究者獻身其中;促進跨語言交流的顯著作用和巨大的應用價值吸引了大量的機構投資其中。互聯網的普及和廣泛應用進一步推動了機器翻譯技術和產品的發展。現代機器翻譯技術和產品正在逐步改變人們的工作、生活以及國際交往,并服務“一帶一路”國家戰略,讓世界各地的人們自由交流,在全球范圍內獲取資訊和服務,創造顯著的經濟價值和社會效益。
四、理解語言,擁有智能
根據第36次《中國互聯網絡發展狀況統計報告》,截至2015年6月,中國互聯網普及率為48.8%,網民規模達6.68億,其中手機網民規模達5.94億。這標志著中國已經進入了移動互聯網的時代。由于移動設備屏幕更小,鍵盤輸入不夠便捷,對使用文字以外的符號,如語音、圖片等多模態的人機交互方式的需求越來越顯著,特別是使用語音交互的方式逐漸普及。得益于深度學習技術在語音識別及合成中取得的成功,以及互聯網所能提供的海量語音及文字數據,語音技術的效果得到了迅速提升,并已廣泛應用于各類互聯網產品中。根據《2015中國智能語音產業發展白皮書》,2015年全球智能語音產業規模達到61.2億美元,其中語音領域的傳統龍頭企業Nuance的市場份額在迅速下降,而谷歌、微軟、蘋果、百度、科大訊飛等公司的語音技術及產品則迅猛發展。借助語音交互技術的語音助手、智能車載、智能家具和可穿戴設備的應用將變得越來越普遍。
無論是搜索引擎還是機器翻譯,其使用場景和交互手段都朝著多模態、多維度的方向發展,用戶的需求則朝著基于內容的語義理解和基于用戶理解的智能交互和個性化服務的方向演變。例如,百度翻譯不僅集成了語音識別和合成,還集成了文字識別和圖像識別,這樣中國人在國外的餐館點餐時,就可以對外文菜單上的文字進行識別和翻譯,也可以對手機拍的照片中的食物進行識別和翻譯。隨著手機以及智能眼鏡、智能手表等可穿戴設備的普及,用戶可以隨時隨地用各種方式發起搜索請求。更加智能化擬人化的交互手段和服務方式,比如多輪對話和智能機器人,開始占據越來越多的比例。
繼谷歌在今年I/O大會上公布了智能即時通信應用Allo,全球幾大科技公司陸續推出了各自的虛擬助理,包括蘋果Siri、微軟小冰 & Cortana、百度度秘等。這些虛擬助手各有特色,Siri主打智能語音與硬件控制,可以看作 iPhone/iPad/Mac 的貼身小管家;Cortana 背靠微軟 Wndows 操作系統,扮演著辦公室助理的角色,而小冰更像一個呆萌的少女,擅長賣萌聊天;Allo 中內置的 Google Assistant可以看作Google Now的升級版,植根于谷歌強大的個人賬號體系,主打服務的強個性化;而度秘則根植于百度搜索及O2O戰略,致力于更好地連接人與信息、人與服務。
從搜索引擎到問答系統、再到虛擬助手,語言信息化技術和產品正朝著人性化和智能化的方向不斷演進,這得益于計算機和移動互聯設備的不斷革新,云計算、大數據處理能力的不斷增強,自然語言處理、語音圖像技術的不斷進步。近年來,深度學習技術在視覺、聽覺以及圍棋博弈等領域都展現出了無堅不摧的能力。在機器翻譯等自然語言處理任務中,雖然深度學習也比過往各種方法都行之有效,但對比在識別領域中取得的顯著成效不免相形見絀(Manning 2015)。這是因為文本理解與語音圖像的模式識別有著本質區別,語言作為知識的載體,承載了復雜的信息量,具有高度的抽象性,對語言的理解屬于認知的范疇,不能僅靠模式匹配的方式完成。另一方面,深度學習采用的層次結構從大規模數據中自發學習的黑盒模式是不可解釋的,即知道是什么,卻無法解釋為什么,然而以語言為媒介的人與人之間的溝通應是建立在相互理解的基礎上的。
歸根到底,語言信息處理技術不應該只聚焦于數據模型的能力,更應該關注語言和認知本身的問題,例如:如何系統化地表示語言的習得和變化規律;是否存在適用于人類各語種的通用的抽象語義結構;能夠對個體類別進行抽象泛化的基本概念的范疇和力度是什么;適于進行推理計算的常識知識應如何進行表示等。尤其是句法分析標準、語義結構規范、知識表示方式,它們是計算機理解自然語言和實現智能化的基礎。這些問題一方面需要對大量真實語言現象進行統計和總結,一方面也需要傳統語言學工作者在理論上進行探索,予以引導。
面向智能化的語言信息處理技術的發展,勢必要借助于語言學、計算機科學、數學、腦科學和認知科學等多學科的共同促進,才可能實現計算機與人之間自然高效的交流。“理解語言,擁有智能,改變世界”,是語言信息化技術和產業發展的終極目標,即讓計算機理解人類的語言,打造真正擁有智能的產品,最終改變人們的生活,構建和諧美好的世界。
參考文獻
董振東 2000 《中國機器翻譯的世紀回顧》,《中國計算機世界》第1期。
Banko, Michele, Michael J. Cafarella, Stephen Soderland, Matt Broadhead, and Oren Etzioni. 2007. Open Information Extraction from the Web. Proceedings of IJCAI, 2670-2676.
Bengio, Yoshua, Réjean Ducharme, Pascal Vincent, and Christian Jauvin. 2003. A Neural Probabilistic Language Model. Journal of Machine Learning Research 3(6), 1137-1155.
Bhagat, Rahul and Deepak Ravichandran. 2008. Large Scale Acquisition of Paraphrases for Learning Surface Patterns. Proceedings of ACL, 674-682.
He, Wei, Zhongjun He, Hua Wu, and Haifeng Wang. 2016. Improved Neural Machine Translation with Smt Features. Proceedings of AAAI Conference on Artificial Intelligence.
Manning, Christopher D. 2015. Computational Linguistics and Deep Learning. Computational Linguistics 41(4), 699-705.
Sun, Xu, Jianfeng Gao, Daniel Micol, and Chris Quirk. 2010. Learning Phrase-Based Spelling Error Models from Clickthrough Data. Proceedings of ACL, 266-274.
責任編輯:劉玥妍
猜你喜歡
計算機與網絡(2022年2期)2022-03-17 22:48:16
中國衛生(2015年12期)2015-11-10 05:13:38
警察技術(2015年3期)2015-02-27 15:37:09
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
科學導報·學術論壇(2013年5期)2013-06-26 05:41:54
百科知識(2012年11期)2012-04-29 08:30:15
中原工學院學報(2011年4期)2011-12-27 09:19:14
微型計算機·Geek(2009年1期)2009-12-15 05:37:32
計算機應用文摘(2009年17期)2009-04-29 00:44:03
