大數據在電力行業的應用與挑戰
2016-06-02 08:07:48孟祥君張偉昌王宗光國網山東電力公司山東濟南250000
中國科技縱橫 2016年1期
孟祥君 張偉昌 王宗光(國網山東電力公司,山東濟南 250000)
?
大數據在電力行業的應用與挑戰
孟祥君 張偉昌 王宗光
(國網山東電力公司,山東濟南 250000)
【摘 要】大數據(big data),是指數據規模特別巨大,以至于無法通過傳統的軟件工具和處理方式有效地對數據進行采集、存儲、分析、整合、控制,達到數據的深度價值挖掘和輔助決策的信息資料。大數據具有4V特點:Volume(數據量大)、Velocity(實時性強)、Variety(數據種類多樣)、value(價值大)。
【關鍵詞】大數據 電力大數據 Hadoop 數據挖掘 分布式機器學習
【Abstract】Big data, refers to a huge amount of data, that it is unable to be collected, stored, analyzed, integrated and controlled by the conventional software tools and effective processing ways, in order to achieve the deep value mining and scientific decision-making.Big data has 4V features: Volume(massive data), Velocity(high real-time), Variety( various data types), Value(high value).
【Key words】big data; big data in electric power industry; Hadoop; data mining; distributed machine learning
1 引言
2014年7月28日 國務院印發《關于加快發展生產性服務業促進產業結構調整升級的指導意見》,更加明確了大數據技術在產業結構升級中的核心基礎性地位。
能源產業的全面、協調和可持續發展,是我國經濟實現平穩快速增長和轉型升級的重要基礎性保證。電力作為最主要的二次能源,其高效利用和優化配置,實現節能減排和服務轉型升級,對于順應低碳發展趨勢、構筑綠色能源產業體系、減少資源浪費、促進產業結構升級、創建可持續性發展的節約型社會具有重大意義。
2 什么是電力大數據
近年來,隨著全球能源問題日益嚴峻,世界各國都開展了智能電網的研究工作。智能電網的最終目標是建設成為覆蓋電力系統整個生產過程,包括發電、輸電、變電、配電、用電及調度等多個環節的全景實時系統。而支撐智能電網安全、自愈、綠色、堅強及可靠運行的基礎是電網全景實時數據采集、傳輸和存儲,以及累積的海量多源數據快速分析。因而隨著智能電網建設的不斷深入和推進,電網運行和設備檢/監測產生的數據量呈指數級增長,逐漸構成了當今信息學界所關注的大數據,這需要相應的存儲和快速處理技術作為支撐。
電力行業的大數據在電力的生產和使用過程中,伴隨著發電、輸電、變電、配電、用電以及調度等環節產生。
3 電力大數據的關鍵技術
3.1 數據挖掘
電力大數據的分析和挖掘主要面向結構化和非結構化數據,能夠針對復雜數據結構、多類型的海量數據做有效的處理。
但目前電力行業的數據挖掘計算大多都是基于小數據集進行計算的,這是因為目前在大數據行業內主流的大數據計算框架還沒有在電力大數據領域內得以普遍應用,使用傳統方式做海量數據的挖掘計算往往需要數天甚至幾個月的時間,這是人們在實際業務場景中無法接受的。而是用小數據集進行的數據挖掘操作,其真實性、可靠性都遠不及基于海量數據的挖掘結果。這也是我們目前正在持續進行的研發重點。
基于Hadopp HDFS、HBASE的快速訪問,基于Spark的分布式訪問和分布式計算,基于R和Spark mllib的統計、計算、分析,基于Mahout的機器學習,共同構建了基于大數據的高性能流計算的數據挖掘、統計、分析技術框架。
3.2 實時計算
電力行業的實時計算在其大數據應用領域內具有不可忽視的地位。電力行業的實時數據往往代表著設備運行參數、生產環境的各項指標、客戶的實時需求等等,這樣的數據,其價值只有在其剛剛產生的時候,才是最大的。而且,在數據剛剛產生的時候,就對其進行移動、計算和使用才是最有意義的,這也符合數據應用的一般規律。因此,電力大數據一定要重視實時計算場景的應用。
現階段,基于傳統數據量實現的實時計算框架已經比較能夠成熟的應用在電力行業。例如,在電廠中,以秒、分鐘為單位采集電廠電力設備的各項運行指標、參數,數據采集完成之后,將被發送實時計算框架。在框架中,所采集到的參數指標將應用于數據挖掘建立的數據模型及電力專家長年積累的業務規則,實現設備故障檢測、故障預警、設備狀態評估等功能。實時計算完成后,計算結果及原始數據將被保存至數據庫,供后續數據挖掘使用,而挖掘出的規則、知識、數據模型,也將重新應用實時計算的過程中,形成一套近似于自我完善的完整體系。但是,由于其單節點計算的瓶頸,沒有分布式計算的概念,導致其能夠同時支撐的實時計算模型有限,無法適應電力行業發展的需求。因此,電力行業的實時計算急需通過分布式內存計算的方式,解決數據量增大時計算性能受限的瓶頸。
充分利用Spark Streaming的分布式數據訪問能力,基于Spark分布式計算平臺和Spark分布式計算對R的整合,并結合Redis分布式內存數據庫,完全可以解決海量數據下的電力大數據實時訪問和實時計算分析。
4 主流的大數據技術
4.1 apache Hadoop
Hadoop是一個能夠對大量數據進行分布式處理的軟件框架。具有可靠性高、可擴展性高、訪問效率高、計算效率高、容錯性高、伸縮性強的特點,用戶可以基于hadoop平臺輕松架構和使用自己的分布式計算平臺,開發和運行處理海量數據的應用程序,是大數據行業內,最為主流的大數據平臺構建基礎(如圖1),其分布式存儲系統和作業調度系統已經成為其他大數據框架的構建基礎,居于主導地位。以Hadoop技術架構為核心的大數據技術架構生態系統構成目前最主流的大數據技術生態系統。大數據技術目前正處于快速發展時期,業界普遍預期,大數據相關技術架構,將在未來1-2年趨于成熟。
4.2 apache spark(分布式計算)
Apache spark是一款開源的數據分析集群計算框架,由于他基于內存的分布式計算設計,使得他的計算效率相比Hadoop自帶的Mapreduce計算框架要高20~100倍。由于這樣的性能優勢,spark已經成為大數據行業內最為主流的分布式計算框架。
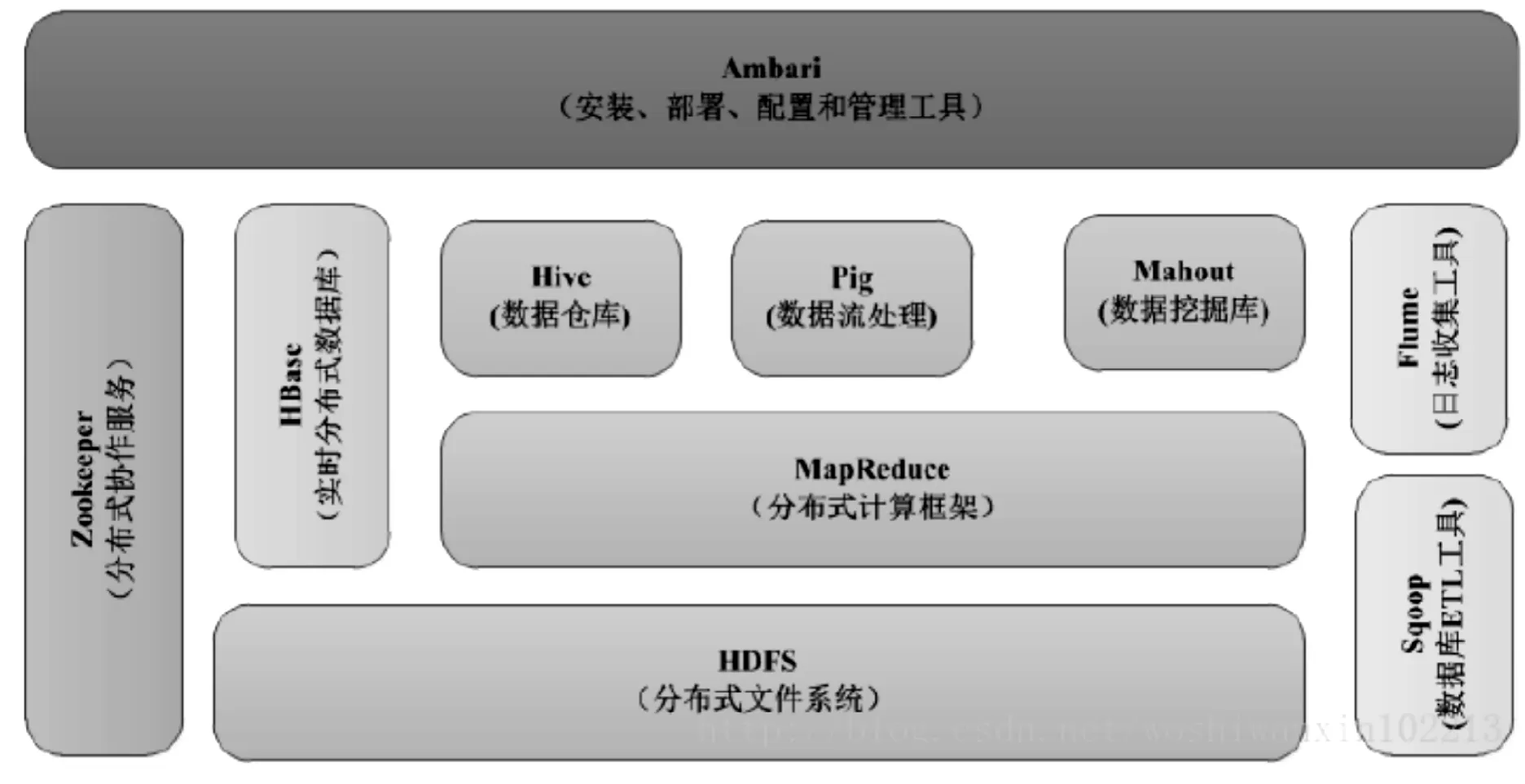
圖1
Spark開發團隊基于Spark計算框架,又相續研發出了分布式實時計算框架Spark Streaming和數據倉庫Hive in Spark,這兩款工具以其高計算性能、高容錯性、巨大的數據處理規模、低端的學習成本已經逐漸在其相關領域內占據了不可替代的位置。
4.3 apache kafka(分布式消息系統)
Kafka是一款開源的基于隊列實現的分布式消息訂閱發布系統,主要用于處理活躍的流式數據,比較常見的是日志處理系統,在電力行業內通常作為實時數據與實時計算框架之間的緩沖區存在。他具有速度快、可擴展性好、可靠性好的優點。
4.4 apache Mahout(機器學習)
Mahout起源于2008年,最初是Apache Lucent的子項目,它在極短的時間內取得了長足的發展,現在是Apache的頂級項目。
Mahout的主要目標是創建一些可擴展的機器學習領域經典算法的實現,旨在幫助開發人員更加方便快捷地創建智能應用程序。Mahout現在已經包含了聚類、分類、推薦引擎(協同過濾)和頻繁集挖掘等廣泛使用的數據挖掘方法。除了算法,Mahout還包含數據的輸入/輸出工具、與其他存儲系統(如數據庫、M o n g o D B或Cassandra)集成等數據挖掘支持架構。
5 電力大數據的應用
電力大數據的價值在于挖掘海量數據隱藏的物與物之間的關系和規律,為企業電力生產、經營管理和電力服務在質量、效益、效率方面提高提供有力的支撐,促進電力資源配置、服務的優化。
電力生產過程中各個環節數據的融合、發掘,能夠幫助發現電力生產的薄弱環節、尋找改進措施。電力生產大數據的挖掘和分析處理技術可以指導發電企業更好地進行設備運行狀態評估及故障診斷、發電生產決策與控制等。
5.1 安全評估及故障診斷
基于數據挖掘技術的設備運行狀態監視:基于DCS、PI等系統的實時數據和海量的歷史數據,結合其他第三方系統數據(例如天氣狀況、電網調度歷史數據等),建立機組安全運行狀態模型,數據挖掘技術可以自動發現某些不正常的數據分布,從而暴露設備運行中的異常變化,分析潛在的不安全因素,協助運行和檢修人員預測機組運行狀態,并迅速找出問題發生的范圍及時檢修和采取對策。
5.2 發電生產決策與控制
基于數據挖掘技術的決策支持和控制:決策支持方面,發電企業門戶系統的主要功能是統計和展示,并沒有提供決策信息(例如某電廠的月度發電量指標、年度經營指標等如何制定);控制方面,當機組出現異常情況時.目前仍然是基于專家系統的控制方式,即依賴經驗豐富的專家(值長),此時呈現在專家面前的數據量從幾十條/min瞬時上升為幾十條/s,數據量的激增使得專家在應對異常狀況時也有較大壓力,因此這種控制方式也已無法適應生產要求。數據挖掘技術具有定性分析能力。從大量數據中去除冗余信息,可將每一種狀態的故障特征提取出來.成為判斷機組狀態、如何快速處理故障、準確決策的依據。
5.3 設備檢修策略改進
基于數據挖掘技術的電力設備狀態檢修:首先收集設備的基礎信息、歷史運行數據、設備缺陷信息等,通過對歷史運行數據和缺陷信息進行數據挖掘,得到設備缺陷狀態下特征值及關聯參數值,將挖掘得到的信息與設備當前運行監測值進行對比分析,即可以判斷設備當前運行狀態是否正常。例如,通過關聯規則分析,往往可以發現A設備振動報警后。B設備也會有較大概率出現振動報警,該關聯規則可以提供早期故障預測及原因分析。
在電力輸送領域內進行電力的實時線損計算,通過智能電表采集到的海量能源數據,實時計算分線、分壓、分區、分臺區等等各種范圍的線路損耗,從而為電網的調度、交易和檢修提供支撐,有利于實現更為經濟、可靠的電網運行方式,增強電力資源的配置能力。
除了電力領域之內在電力企業外部,電力大數據也為社會民生、經濟發展的動向提供了有力的客觀依據。目前,作為一種高時效性、高準確性的數據,電力數據已經被廣泛的應用于分析經濟發展水平、經濟走勢、產業分布情況,甚至政策實施效果等等科學問題。我們通過分析各種產業用電量之間的關系,深入研究產業結構與經濟體系的變化特點,能夠對未來幾年內的電力需求情況有大致的預測,為社會經濟發展提供了有力的支撐。
6 結語
電力大數據作為大數據領域內新興的技術和理念,已經展露出其數據中蘊含的巨大價值和能量,其數據無論是與自身關聯,還是與其他行業相關聯,都是一筆巨大的待人挖掘的財富。
眼下,以數據為中心的信息化理念異軍突起,正在逐步變革傳統的信息化工作思路,促進信息化與工業化深度融合,給電力行業帶來全新的工作方式和商業模式。在不遠的將來,電力大數據一定能夠變革傳統的電力生產、營銷模式,使電力產業以嶄新的姿態出現在國民經濟發展的大潮中!
作者簡介:孟祥君(1975—),男,山東濟寧人,本科,高級工程師,國網山東省電力公司,主要從事信息化管理工作;張偉昌(1971—),男,山東棗莊人,本科,高級工程師,國網山東省電力公司,主要從事信息化管理工作;王宗光(1971—),男,山東濟寧人,本科,高級工程師,山東魯能軟件技術有限公司,主要從事電力信息化系統開發與建設管理工作。
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
信息通信技術(2015年6期)2015-12-26 01:16:46
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
