一種結(jié)合詞向量和圖模型的特定領(lǐng)域?qū)嶓w消歧方法
2016-06-02 08:12:56汪沛線巖團郭劍毅文永華陳瑋王紅斌
智能系統(tǒng)學(xué)報 2016年3期
汪沛,線巖團,2,郭劍毅,2,文永華,2,陳瑋,2,王紅斌,2
(1.昆明理工大學(xué) 信息工程與自動化學(xué)院,云南 昆明 650500; 2.昆明理工大學(xué) 智能信息處理重點實驗室,云南 昆明 650500)
?
一種結(jié)合詞向量和圖模型的特定領(lǐng)域?qū)嶓w消歧方法
汪沛1,線巖團1,2,郭劍毅1,2,文永華1,2,陳瑋1,2,王紅斌1,2
(1.昆明理工大學(xué) 信息工程與自動化學(xué)院,云南 昆明 650500; 2.昆明理工大學(xué) 智能信息處理重點實驗室,云南 昆明 650500)
摘要:針對特定領(lǐng)域提出了一種結(jié)合詞向量和圖模型的方法來實現(xiàn)實體消歧。以旅游領(lǐng)域為例,首先選取維基百科離線數(shù)據(jù)庫中的旅游分類下的頁面內(nèi)容構(gòu)建領(lǐng)域知識庫,然后用知識庫中的文本和從各大旅游網(wǎng)站爬取到的旅游文本,通過詞向量計算工具Word2Vec構(gòu)建詞向量模型,結(jié)合人工標(biāo)注的實體關(guān)系圖譜,采用一種基于圖的隨機游走算法輔助計算相似度,使其能夠較準(zhǔn)確地計算旅游領(lǐng)域詞與詞之間的相似度。最后,提取待消歧實體的背景文本的若干關(guān)鍵詞和知識庫中候選實體文本的若干關(guān)鍵詞,利用訓(xùn)練好的詞向量模型結(jié)合圖模型分別進行交叉相似度計算,把相似度均值最高的候選實體作為最終的目標(biāo)實體。實驗結(jié)果表明,這種新的相似度計算方法能夠有效獲取實體指稱項與目標(biāo)實體之間的相似度,從而能夠較為準(zhǔn)確地實現(xiàn)特定領(lǐng)域的實體消歧。
關(guān)鍵詞:實體消歧;實體鏈接;Word2Vec;圖模型;隨機游走;維基百科 在提取模塊中,分別利用TextRank 算法提取出待消歧的實體指稱所在的背景文本的若干關(guān)鍵詞和候選實體對應(yīng)的知識庫描述文本的若干關(guān)鍵詞,這里提取的兩組關(guān)鍵詞用于后面的相似度計算。 提取模塊分為兩個步驟:候選實體獲取和關(guān)鍵詞提取。候選實體獲取實質(zhì)上就是羅列出所有可能是待消歧的實體指稱項的目標(biāo)實體,由于中文語義的多樣性,一個詞通常有多種表達方式,同樣一個實體也可能有多種形式,例如,在維基百科的重定向頁面中,“驢友”與“背包客”指的是同一個實體,“蟲草”與“冬蟲夏草”指的也是同一實體。針對這種情況,利用維基百科離線數(shù)據(jù)庫提供的3個SQL文件即可得到所有重定向的同義詞,并且能得到他們對應(yīng)的頁面信息和鏈接信息。 提取即在確定候選實體后,從待消歧實體所在文本中抽取n個關(guān)鍵詞,然后再從所有候選實體在知識庫中對應(yīng)的文本中分別抽取n個關(guān)鍵詞。這樣做是因為本文中相似度計算的前提是假設(shè)待消歧背景文本與知識庫中對應(yīng)文本的主題一致,在這個前提下,本文消歧任務(wù)實質(zhì)已經(jīng)轉(zhuǎn)變?yōu)橛嬎愦鐚嶓w指稱所在背景文本與知識庫中候選實體對應(yīng)文本之間的相似度。分別抽取兩個文本各n個關(guān)鍵詞,這里采用TextRank算法抽取權(quán)重最高的n個關(guān)鍵詞,具體計算方法參照本文1.2節(jié)。根據(jù)詞與詞之間在規(guī)定窗口大小內(nèi)相互進行“投票”計算出每個詞在文檔中的權(quán)重,在使用TextRank算法計算圖中點的權(quán)重時,需要給圖中的點指定任意的初值并遞歸計算直到某個詞語分?jǐn)?shù)收斂,收斂后每個點都獲得一個分?jǐn)?shù),代表該點在圖中的重要性,也就是該詞語在文檔中的重要性。表1為利用該算法確定的待消歧實體文本和對應(yīng)的3個候選實體文本中的關(guān)鍵詞,待消歧實體和候選實體1指的是香格里拉(景點名),候選實體2指的是香格里拉(酒店名),候選實體3指的是香格里拉(城市名)。
實體鏈接是知識庫構(gòu)建的關(guān)鍵技術(shù)之一,其目的是將文本中已經(jīng)獲取到的命名實體鏈接到已有的知識庫中,實體消岐是實體鏈接的關(guān)鍵任務(wù)。由于海量數(shù)據(jù)中存在的實體指稱通常可以對應(yīng)到多個命名實體概念,這無疑對實體消歧造成了很大的障礙。實體消歧的任務(wù)就是將這些存在歧義的實體指稱在眾多的候選實體中匹配出對應(yīng)的目標(biāo)實體。目前實體消歧任務(wù)分為兩種類型:實體聚類消歧和實體鏈接消歧[1],實體聚類消歧就是利用聚類算法來對實體進行消歧,而實體鏈接消歧則是借助外部知識庫,將待消歧命名實體指稱鏈接到外部知識庫中對應(yīng)實體來進行消歧。本文選擇用后者來實現(xiàn)特定領(lǐng)域的實體消歧。
實體消歧的本質(zhì)是計算實體指稱項和候選實體的相似度,選擇相似度最大的候選實體作為鏈接的目標(biāo)實體[2]。針對英文實體消岐,Bunescu和Pasca[3]提出了一種基于余弦相似度排序的方法來實現(xiàn)實體消歧。Bagga和Gideon[4-5]等將實體指稱項的上下文與候選實體的上下文分別表示成BOW(Bag of words)向量形式,利用向量空間模型實現(xiàn)了人名的消歧。韓先培等[6]提出一種基于圖的實體消歧方法,將指稱項與實體通過帶權(quán)的無向圖連接起來,從而將指稱項與實體、實體與實體間的語義關(guān)聯(lián)通過圖的形式表征出來。上述工作主要是對英文的實體消歧,相比較而言,針對中文的實體消歧工作遠遠落后于英文。在中文的實體消歧領(lǐng)域,王建勇等[7]利用一種基于圖的GHOST算法,結(jié)合AP聚類算法進行相似度計算,在人名消歧方面取得了較好的實驗結(jié)果。懷寶興等[8]提出了一種基于概率主題模型的命名實體鏈接方法,在通用領(lǐng)域,通過構(gòu)建歧義詞表,用LDA基于語義層面對文檔建模和實體消岐;寧博等[9]針對中文命名實體消歧問題提出了一種基于異構(gòu)知識庫的層次聚類方法,將維基百科和百度百科結(jié)合起來作為多源知識庫,并利用Hadoop平臺進行層次聚類,從而實現(xiàn)實體消歧。另外,朱敏等[10]提出了一種實體聚類消歧與百度百科詞頻的同類實體消歧相結(jié)合的消歧方法,通過構(gòu)建同義詞表、優(yōu)化知識庫、改進拼音距離編輯算法等方式實現(xiàn)對中文微博的實體消歧。
同樣在旅游領(lǐng)域也存在著大量的實體同名現(xiàn)象,在維基百科中“金花”一詞有11個同名實體,“香格里拉”一詞有12個同名實體,這無疑對消歧工作產(chǎn)生很大影響,例如,給定兩個句子:
1)2014年,香格里拉縣共接待國內(nèi)外游客1 080.22萬人次。
2)在結(jié)束了一天的旅程后我們選擇了在香格里拉酒店入住。
在上面的例子中,很明顯第一句中的“香格里拉”指的是某旅游勝地,第二句指的是某著名酒店品牌,但是如何讓計算機也能將實體指稱項準(zhǔn)確鏈接到知識庫中具有特定概念的實體仍然是自然語言處理領(lǐng)域研究的熱點和難點。
傳統(tǒng)的消歧模型難以有效利用能反映領(lǐng)域特有屬性的實體詞特征。因此,本文針對旅游領(lǐng)域?qū)嶓w間的關(guān)系較為復(fù)雜的特征,提出了一種結(jié)合詞向量和圖模型的消歧方法,通過提取實體指稱項背景文本的若干關(guān)鍵詞和候選實體文本的若干關(guān)鍵詞,利用訓(xùn)練好的模型對這些關(guān)鍵詞分別進行交叉相似度計算,把相似度均值最高的候選實體作為最終的目標(biāo)實體。
1相關(guān)理論
1.1詞向量
在自然語言處理中,要將自然語言理解的問題轉(zhuǎn)化為機器學(xué)習(xí)的問題,就需將自然語言的符號數(shù)學(xué)化,其中最直觀和常用的方法是 One-hot 表示法。這種方法將每個詞表示為一個很長的向量,其維數(shù)是詞匯表大小,其中絕大多數(shù)元素為 0,只有一個維度的值為 1,這個維度就代表當(dāng)前的詞。
在自然語言處理中,常將One-hot 表示采用稀疏的方式進行存儲,即為每個詞分配一個數(shù)字 ID。該方法因其簡單易用,廣泛應(yīng)用于各種自然語言處理任務(wù)中,如N-gram 模型中就采用這種詞向量表示法。 但這種表述方法也存在一定問題:其表示的任意兩個詞之間是孤立的,無法表示這兩個詞之間的依賴關(guān)系,從詞向量上看不出兩個詞是否相關(guān);采用稀疏表示法,在處理某些任務(wù),如構(gòu)建 N-gram 模型時,會引起維數(shù)災(zāi)難問題。
而在機器學(xué)習(xí)領(lǐng)域,一般采用分布式表示(distributed representation) 的方法表示詞向量,這種表示法最早由 Hinton[11]提出,通常稱為 Word Representation。這種方法將詞用一種低維實數(shù)向量表示,優(yōu)點在于相似的詞在距離上更接近,能體現(xiàn)出不同詞之間的相關(guān)性,從而反映詞之間的依賴關(guān)系。同時,較低的維度也使特征向量在應(yīng)用時有一個可接受的復(fù)雜度。 因此,新近提出的許多語言模型,如潛在語義分析(latent semantic analysis, LSA)模型、潛在狄利克雷分布 ( latent dirichlet allocation,LDA)模型以及目前流行的神經(jīng)網(wǎng)絡(luò)模型等,都采用這種方法表示詞向量[12-13]。
本文利用旅游領(lǐng)域的豐富語料對詞向量模型進行訓(xùn)練,從而將抽取的關(guān)鍵詞進行向量化表示,用這若干個關(guān)鍵詞向量來表征一篇文檔,通過計算關(guān)鍵詞向量間的余弦相似度得出它們之間的關(guān)聯(lián)程度,進而得出文檔之間的相似度。
1.2TextRank算法
同一文檔中的大多數(shù)詞語都是為表達同一主題服務(wù)的,它們之間具有一定的語義關(guān)系。和詞語W有語義關(guān)系的詞語越多,詞語W越可能是表達文檔主題的重要詞語,同時和詞語W有語義關(guān)系的詞語的重要性也會影響詞語W的重要性。根據(jù)這兩個特性,本節(jié)引入基于圖的排序算法用于抽取多文檔關(guān)鍵詞。基于圖的排序算法是決定圖中點重要性的一種方法,它根據(jù)全局信息(圖的結(jié)構(gòu))而不是局部信息來對節(jié)點排序。其基本理論是“投票”,當(dāng)圖中一個點A和另一個點B之間有連線時,那么點A就給點B投票,點B獲得的投票越多,點B就越重要;更進一步,投票點A的重要性決定了其投票的重要性,因此,點B的分?jǐn)?shù)由其獲得的投票和給B投票的點的分?jǐn)?shù)共同決定。
Mihalcea[14]將在自然語言處理領(lǐng)域中應(yīng)用的基于圖的排序算法稱為TextRank,一般TextRank模型可以表示為一個加權(quán)的有向圖。TextRank的思想來源于Google的PageRank算法,通過把文本分割成若干組成單元并建立圖模型,利用投票機制對文本中的重要成分進行排序,僅利用單篇文檔本身的信息即可實現(xiàn)關(guān)鍵詞抽取。本文采用該算法將文檔表示為無向圖G(V,E),由點集合V和邊集合E組成,E是V×V的子集,圖中兩點i,j之間邊的權(quán)重為Wj。對于一個給定的點Vi,In(Vi)為指向該點的點集合,Out(Vi)為點Vi指向的點集合,點Vi的分?jǐn)?shù)定義為式(2):
(2)
式中:d為阻尼因數(shù),取值范圍為0~1,代表從圖中某一特定點指向其他任意點的概率。通過這種算法我們可以獲得每個詞語在文檔中的分?jǐn)?shù),從而可以根據(jù)分?jǐn)?shù)大小來進行關(guān)鍵詞的排序。
本文利用該算法抽取文檔中的關(guān)鍵詞,分別用抽取的關(guān)鍵詞來表征待消歧實體指稱項所在文本和目標(biāo)實體所在文本。
1.3隨機游走算法
隨機游走模型是在1905年Karl Pearson[15]首次提出的一種數(shù)學(xué)統(tǒng)計模型,它是一連串的軌跡組成的,其中每一次都是隨機的。它能用來表示不規(guī)則的變動形式,如同一個人酒后亂步,所形成的隨機過程記錄[16]。它的基本思想是,從一個或一系列頂點開始遍歷一張圖,在任意一個頂點,遍歷者將以概率1-α游走到這個頂點的鄰居頂點,以概率α隨機跳躍到圖中的任何一個頂點,稱α跳轉(zhuǎn)發(fā)生概率,每次游走后得出一個概率分布,該概率分布刻畫了圖中每一個頂點被訪問到的概率,用這個概率分布作為下一次游走的輸入并反復(fù)迭代這一過程,當(dāng)滿足一定前提條件時,這個概率分布會趨于收斂,收斂后,即可以得到一個穩(wěn)定的概率分布。近年來,隨機游走算法逐漸開始吸引機器學(xué)習(xí)研究者的目光,并開始被應(yīng)用于半監(jiān)督學(xué)習(xí)[17-18]、聚類分析[19-21]、圖像分割[22]和圖的匹配[23]等問題上。與隨機游走相關(guān)的擴散核也被應(yīng)用于[24-28]基于核的學(xué)習(xí)等方面。
由于實體間的關(guān)系錯綜復(fù)雜,可以將這種關(guān)系抽象為一種圖模型,本文在這種圖模型上運用隨機游走算法可以將實體間的關(guān)聯(lián)程度準(zhǔn)確地表征出來。
2領(lǐng)域?qū)嶓w消歧
2.1系統(tǒng)流程
本文提出的方法由4個模塊構(gòu)成分別為關(guān)鍵詞提取模塊、詞向量模塊、圖模型模塊和空實體判斷模塊。
在詞向量模塊中,抽取維基百科離線數(shù)據(jù)中旅游分類下的頁面信息構(gòu)建領(lǐng)域知識庫,由于維基百科中包含大量的結(jié)構(gòu)化信息,取該知識庫的摘要信息作為語料對詞向量模型進行訓(xùn)練,這時,領(lǐng)域?qū)嶓w都能通過該模型表征為一個向量,從而實現(xiàn)關(guān)鍵詞之間的相似度計算。
在圖模型模塊中,人工構(gòu)建一個領(lǐng)域?qū)嶓w關(guān)系圖譜,通過在該圖譜上的隨機游走算法實現(xiàn)關(guān)鍵詞之間相似度的計算。
在空實體判斷模塊中,從待消歧實體指稱所在的文本中抽取若干關(guān)鍵詞和從候選實體所在文本中抽取的關(guān)鍵詞分別用本文提出的圖模型與詞向量方法相結(jié)合進行交叉相似度計算取平均值,選擇其中最大的相似度平均值,因為計算結(jié)果所對應(yīng)的目標(biāo)實體未必在我們的知識庫中存在,這時通過比對該平均值與通過大量實驗確定的空實體閾值λ的大小,如果大于該閾值λ,則該實體為目標(biāo)實體,如果小于λ,則認(rèn)為該實體指稱在知識庫中沒有與之對應(yīng)的目標(biāo)實體,即空實體。
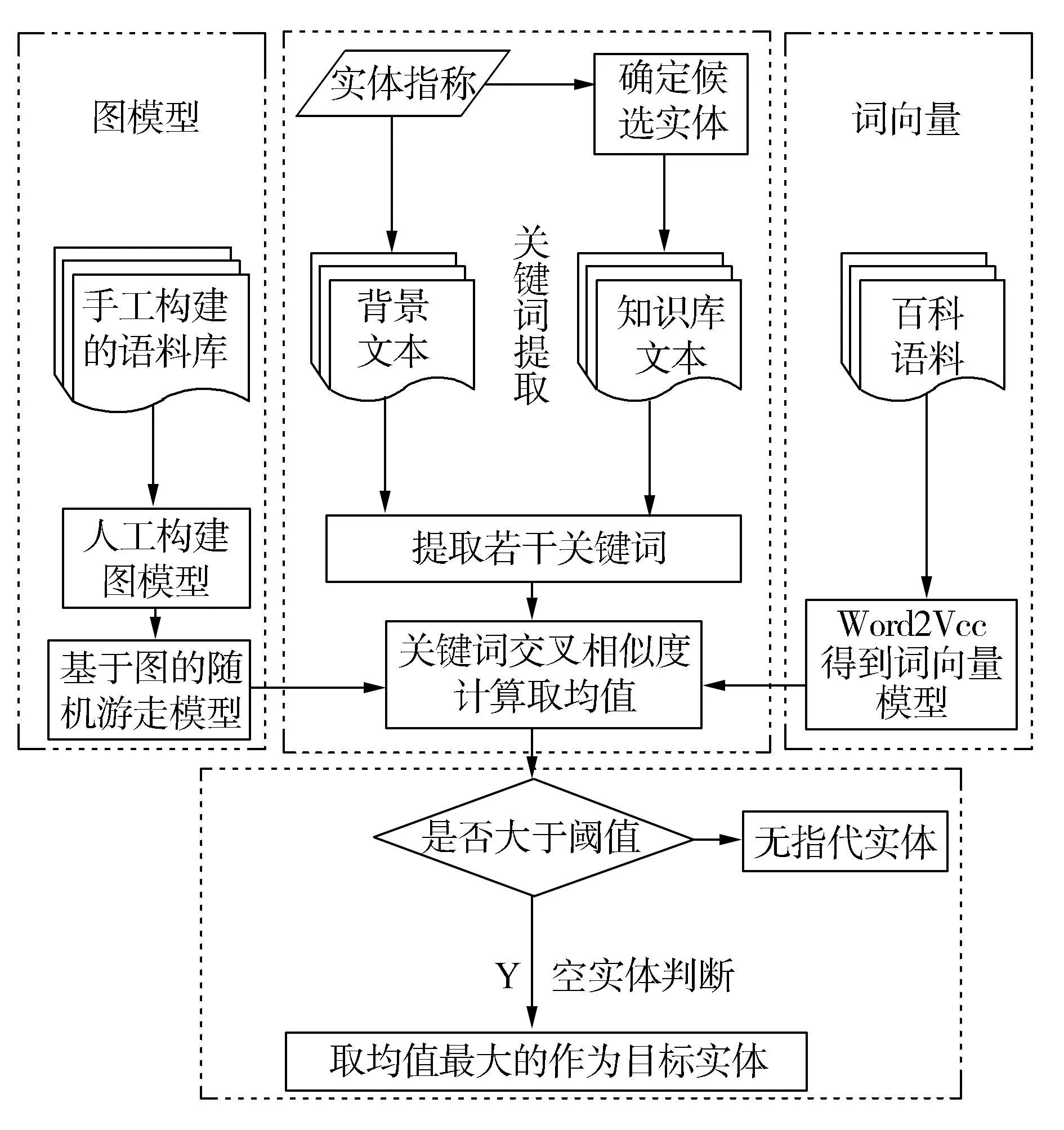
圖1 系統(tǒng)總體框架Fig.1 Overall framework of system
2.2關(guān)鍵詞提取
2.3詞向量的訓(xùn)練和應(yīng)用
Word2Vec是Google 在2013年推出并開源的一款將詞表征為實數(shù)值向量的高效工具,其利用深度學(xué)習(xí)的思想,可以通過訓(xùn)練,把對文本內(nèi)容的處理簡化為K維向量空間中的向量運算,而向量空間上的相似度可以用來表示文本語義上的相似度。Word2Vec輸出的詞向量可以被用來做很多NLP相關(guān)的工作,比如聚類、找同義詞、詞性分析等。如果換個思路,把詞當(dāng)做特征,那么Word2Vec就可以把特征映射到K維向量空間,可以為文本數(shù)據(jù)尋求更加深層次的特征表示,本文將K值選定為200維。
本文主要利用該工具來實現(xiàn)指稱項與目標(biāo)實體間的相似度計算,為了提高實驗在旅游領(lǐng)域的準(zhǔn)確率,在選取訓(xùn)練語料時有針對性地選取旅游領(lǐng)域文本,這樣就最大程度避免其他領(lǐng)域文本對詞向量模型的精準(zhǔn)度產(chǎn)生影響,本文一方面采用維基百科的旅游分類下的文本來作為訓(xùn)練詞向量模型的語料,同時還加入了在各大旅游網(wǎng)站爬取的新聞?wù)Z料。訓(xùn)練完成后的模型能夠比較準(zhǔn)確地計算兩個旅游領(lǐng)域詞匯的相似度,效果比較理想。如表2所示為利用該工具計算出的背景文本中關(guān)鍵詞“香格里拉”與知識庫中目標(biāo)實體文本的7個關(guān)鍵詞之間的相似度,從圖中可以發(fā)現(xiàn)其與“景點”、“旅游”等詞語的相似度要明顯高于“民族”、“比重”,這與現(xiàn)實世界中它們之間的語義關(guān)聯(lián)程度相一致。通過詞向量計算處理,進一步加強了實體詞的領(lǐng)域相關(guān)性,有助于后續(xù)環(huán)節(jié)的相似度計算。
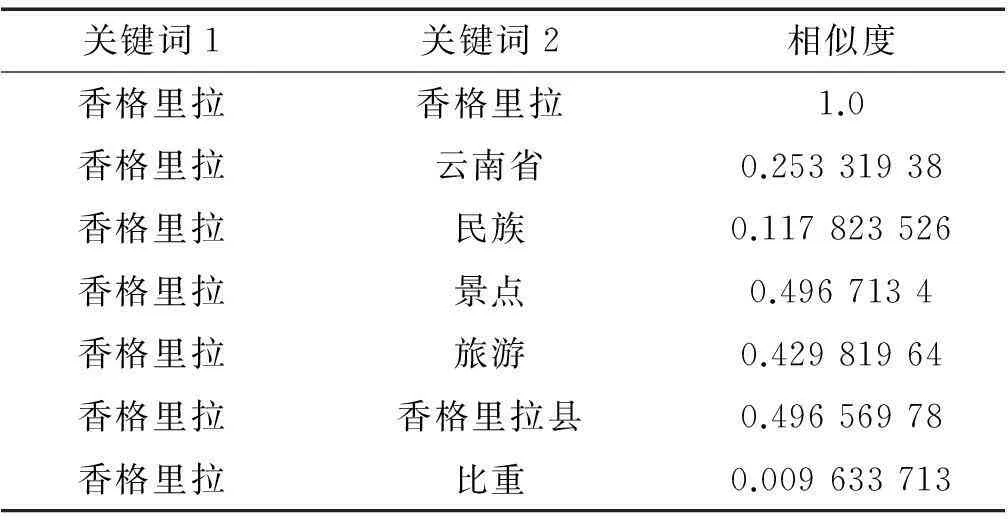
表2 用詞向量計算出的關(guān)鍵詞之間相似度
2.4圖模型的構(gòu)建和應(yīng)用
維基百科是目前世界上最大的在線百科全書,其內(nèi)容每天都會由世界各地的志愿者進行編輯和更新,有著很好的時效性,另外,維基百科的頁面包含有類別信息、重定向信息、外部鏈接信息等,這些信息無形中為實體之間建立了語義上的關(guān)聯(lián),所以本文選擇維基百科作為實體消歧的知識庫。由于本文是針對特定領(lǐng)域,本文抽取“旅游”分類信息下的所有頁面作為最終的知識庫來源,這樣我們在很大程度上實現(xiàn)了消歧,例如,“香格里拉(科幻小說)”和“香格里拉(電視劇)”就自然不在知識庫中,也就在一定程度上縮小了候選實體的范圍。在此基礎(chǔ)上,我們搭建了一個領(lǐng)域?qū)嶓w關(guān)系標(biāo)注平臺,利用圖數(shù)據(jù)庫Neo4j存儲數(shù)據(jù),這種圖數(shù)據(jù)庫與傳統(tǒng)的關(guān)系型數(shù)據(jù)庫相比能夠更準(zhǔn)確有效地表示各個數(shù)據(jù)項之間的復(fù)雜關(guān)系,將從維基百科中抽取到的領(lǐng)域?qū)嶓w導(dǎo)入該平臺的圖數(shù)據(jù)庫,通過人工標(biāo)注的方式構(gòu)建了一個實體與實體之間的關(guān)系圖譜,目的是通過利用在該圖譜上的隨機游走算法輔助計算關(guān)鍵詞之間的相似度,目前該平臺已經(jīng)擁有13 956個實體,8 127對關(guān)系。圖2是部分實體及其之間的關(guān)系。
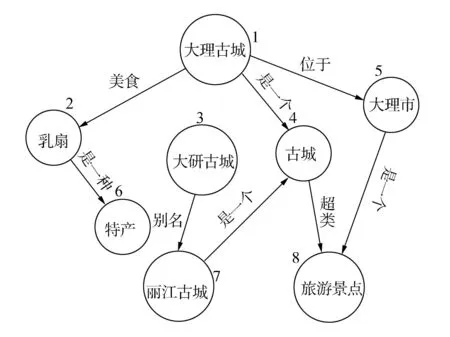
圖2 部分實體關(guān)系圖譜Fig.2 Part of the entity relationship mapping
為了提高關(guān)鍵詞之間相似度計算的準(zhǔn)確率,我們在詞向量的基礎(chǔ)上加入了利用圖模型計算的相似度來綜合衡量關(guān)鍵詞之間的相似度,下面將重點介紹一種用來計算相似度的基于圖的隨機游走算法。
由于目前我們已經(jīng)人工手動搭建了一個領(lǐng)域?qū)嶓w關(guān)系庫,圖2所示的就是一個典型的云南旅游領(lǐng)域相關(guān)實體的部分關(guān)系圖譜,從圖中我們認(rèn)為“大理古城”與“大理市”之間的相似度要高于“乳扇”與“大理市”之間的相似度,因為前兩者之間是“位于”的關(guān)系直接相連,而后兩者之間是通過“大理古城”這個中間實體相聯(lián)系起來的,所以相比較而言,“乳扇”與“大理市”之間的聯(lián)系就要弱得多,同樣,“特產(chǎn)”與“大理古城”之間的相似度要比“旅游景點”與“大理古城”之間的相似度要弱得多,因為后者之間的路徑更多,這些都與現(xiàn)實中實體之間的聯(lián)系密切程度相一致,而基于圖的隨機游走算法能將這種實體之間的聯(lián)系定量地表示出來。
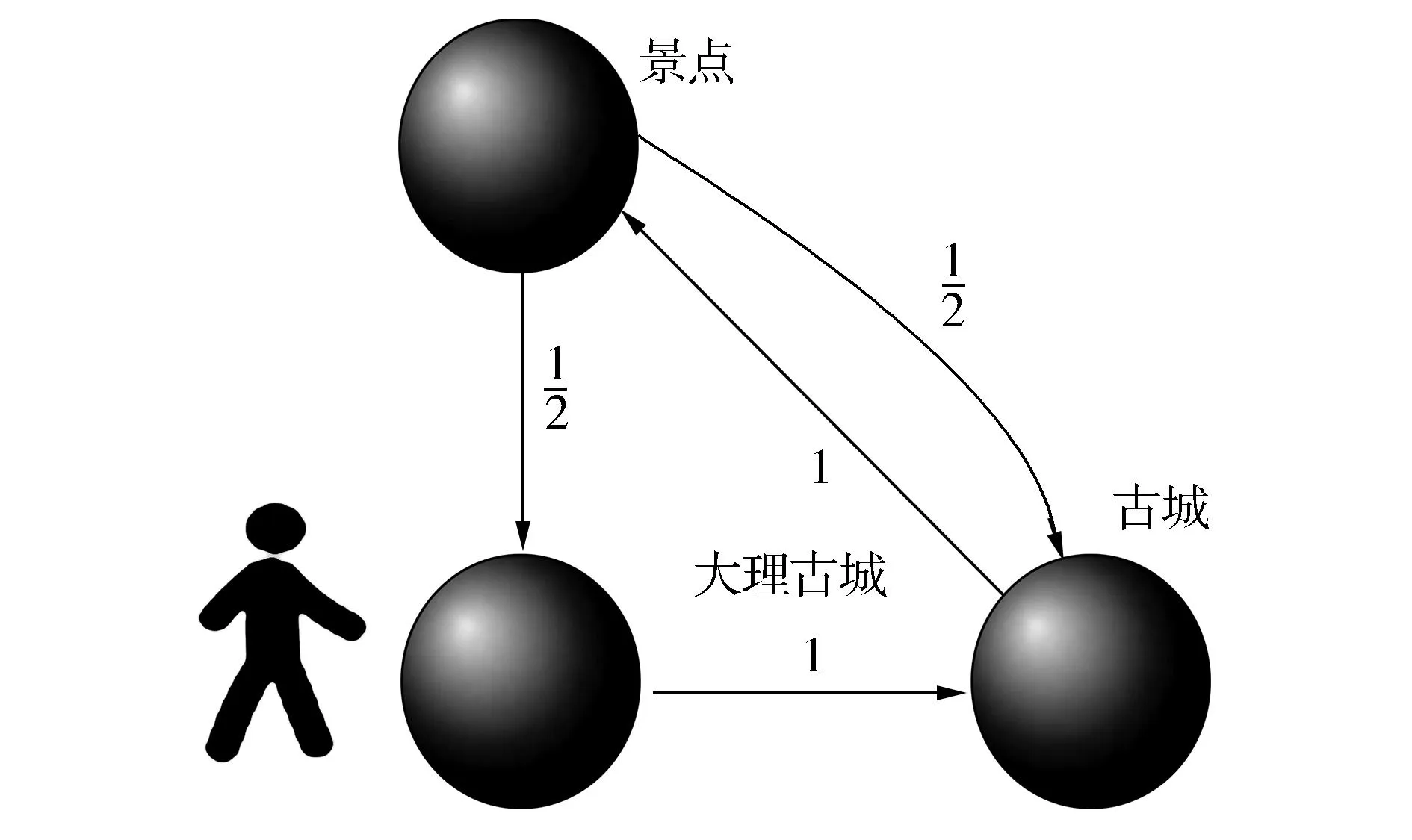
(a)從起始點出發(fā)
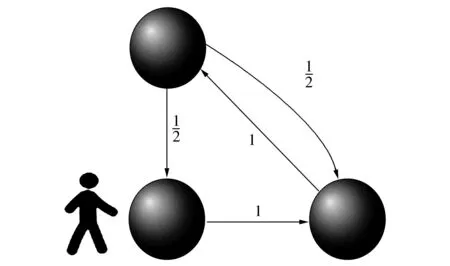
(b)到達第2個頂點后選擇下一個目標(biāo)
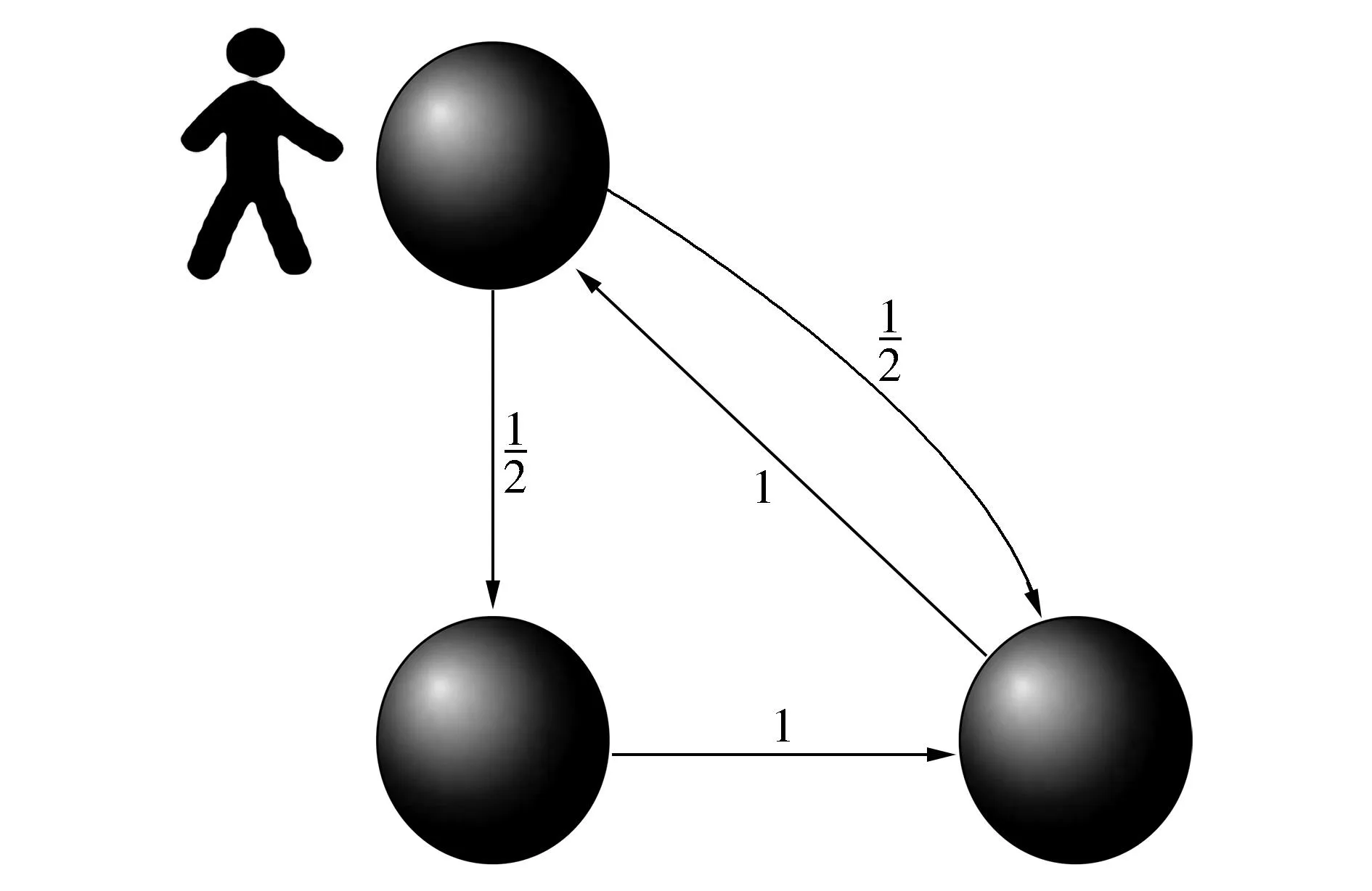
(c)到達第3個頂點后有兩個選擇
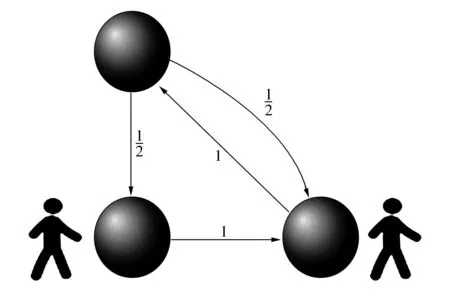
(d)依概率到達下一個目標(biāo)圖3 隨機游走原理圖Fig.3 Schematic diagram of random walk
如圖3所示我們從節(jié)點“大理古城”出發(fā),在3個結(jié)點組成的圖上隨機游走,邊上數(shù)字是轉(zhuǎn)移概率,圖3(a)~(d)分別顯示4種時刻的狀態(tài)。圖3(a)中“大理古城”和“古城”之間只有一個單向的關(guān)系,箭頭的方向表示關(guān)系的方向,所以“大理古城”到“古城”之間的關(guān)系在矩陣中表示為1,圖3(c)中“景點”和其他兩個實體間均有一個單向的關(guān)系,所以“景點”和另外兩個實體之間的關(guān)系在矩陣中都表示為1/2。由于實體間的關(guān)系錯綜復(fù)雜,可以將這種關(guān)系抽象為一種圖模型,本文在這種圖模型上運用隨機游走算法可以將實體間的關(guān)聯(lián)程度準(zhǔn)確地表征出來。
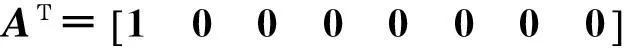
具體算法流程如下:
1)給定初始化矩陣A,并令B=A;
2)根據(jù)圖中實體間的轉(zhuǎn)移概率,生成矩陣M;
3)計算C=α·M·B+(1-α)A;
4)令B=C;
5)重復(fù)步驟3)、4),直到C達到穩(wěn)定狀態(tài)或者迭代次數(shù)超過某個閾值。

12次迭代后矩陣C達到穩(wěn)定狀態(tài),概率分布為
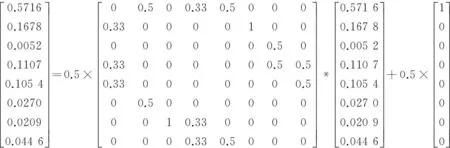
所以在經(jīng)過多次迭代運算后,這種基于圖的概率分布會趨向于一個穩(wěn)定值,從C矩陣我們可以看出結(jié)點1與結(jié)點2、結(jié)點4、結(jié)點5的相似度較大,分別為0.167 8、0.110 7、0.105 4,對應(yīng)著圖2中“大理古城”與“乳扇”、“古城”、“大理市”的相似度,而結(jié)點1與結(jié)點3的相似度最小,只有0.005 2,這與圖2中展示的實際情況也比較相符,如此一來,我們就將這種圖上的結(jié)點間的相似度實現(xiàn)了量化,并且實際效果與現(xiàn)實情況較為一致,可見該算法在輔助計算相似度時的實用價值。
2.5相似度計算
2.2節(jié)中已經(jīng)確定出權(quán)重最高的n個關(guān)鍵詞,在此基礎(chǔ)上分別用這n個關(guān)鍵詞來作為文本的特征模型:
式中:vq為帶消歧實體指稱所在背景文本的特征模型,ve為知識庫中候選實體對應(yīng)文本的特征模型,w為利用TextRank算法得出的文本關(guān)鍵詞,詞與詞之間的相似度用向量間的余弦值表示,具體計算如式(3)所示:
(3)
式中加號的前半部分是利用詞向量求關(guān)鍵詞之間的相似度,后半部分是利用基于圖的隨機游走算法計算的關(guān)鍵詞之間的相似度,其中wq為背景文本中關(guān)鍵詞的詞向量,we為候選實體對應(yīng)文本關(guān)鍵詞的詞向量,通過參數(shù)α來決定這兩種相似度計算方法的權(quán)重,這樣我們就能得到背景文本與候選實體文本關(guān)鍵詞兩兩進行計算后的相似度,一共能得到n2個Sim(q,e),然后対它們求均值,用這個均值來表示兩篇文檔的相似度,具體公式如式(4)所示:
(4)
最后利用上面計算的背景文本與候選實體文本的相似度,來對候選實體進行消歧,相似度最大的即為目標(biāo)實體。
2.6空實體判斷
由于知識庫不可能做到非常全面,實際消歧過程中往往會出現(xiàn)空鏈接的現(xiàn)象,即待消歧的實體指稱項在知識庫中并沒有與之對應(yīng)的目標(biāo)實體。這種情況有兩種可能:1)在獲取候選實體階段通過直接匹配和同義詞匹配兩種方式都沒有匹配到與之對應(yīng)的候選實體;2)在獲取候選實體階段匹配到至少一個候選實體,但是實際上這個候選實體并不是語義相關(guān)的。
第1種下情況將其直接返回NIL。第2種情況下通過設(shè)定一個閾值λ,如果最終的相似度小于λ,則認(rèn)為實體指稱項與候選實體語義上不相關(guān),同樣返回NIL。
3實驗驗證與結(jié)果分析
本文利用維基百科的離線數(shù)據(jù)庫實現(xiàn)對詞向量模型的訓(xùn)練,并在一個小型測試集上進行測試。本文通過兩個實驗對所提出的方法進行了驗證,實驗一通過對關(guān)鍵詞在不同個數(shù)下的對比試驗,確定出消歧準(zhǔn)確率在關(guān)鍵詞個數(shù)為多少時達到最高;在實驗二中加入了對空實體的判斷,通過對空實體閾值λ的不斷調(diào)優(yōu)得出在不同關(guān)鍵詞個數(shù)下準(zhǔn)確率是否有所提升,提升的程度如何以及最終的消歧準(zhǔn)確率對比。
實驗步驟如下:
1)利用旅游領(lǐng)域的百科語料對詞向量空間模型進行訓(xùn)練;
2)利用2.2中的方法在待消歧實體指稱所在的文本中抽取n個關(guān)鍵詞;
3)用同樣的方法在所有候選實體所在文本中分別抽取n個關(guān)鍵詞;
4)利用2.3和2.4中包含有豐富語義信息的模型將上面兩步中的n個關(guān)鍵詞分別進行交叉相似度計算,并且取平均值;
5)選取其中相似度平均值最大的作為最終目標(biāo)實體。
3.1語料的獲取和模型的訓(xùn)練
由于本文需要利用Word2Vec工具對詞向量空間模型進行訓(xùn)練,所以采用了維基百科2014年12月的中文離線數(shù)據(jù)庫,并提取其中的旅游分類下的頁面信息,共計71 208條。將這些語料經(jīng)過預(yù)處理,提取頁面中的摘要信息,形成一篇篇的文本。接著編制爬取程序從國內(nèi)幾個著名的旅游網(wǎng)站爬取了相關(guān)的文本,與維基文本結(jié)合,共計75 016篇。作為本次試驗的訓(xùn)練語料。經(jīng)過訓(xùn)練得到一個131M的實驗?zāi)P臀募ectors.bin。
利用基于圖的隨機游走算法計算相似度時,圖模型的構(gòu)建是至關(guān)重要的一個環(huán)節(jié),我們將上一個環(huán)節(jié)中得到的領(lǐng)域?qū)嶓w語料通過人工標(biāo)注的方式構(gòu)建了一個領(lǐng)域?qū)嶓w關(guān)系圖譜,通過在這張領(lǐng)域?qū)嶓w關(guān)系網(wǎng)絡(luò)上的隨機游走算法來輔助計算關(guān)鍵詞之間的相似度。
3.2測試集的選取
實驗所用來測試的是一個小規(guī)模的測試集,本文從某旅游網(wǎng)站上爬取了596篇旅游攻略作為測試文本,通過觀察發(fā)現(xiàn)并不是每一篇文本中都包含有存在歧義的實體指稱,所以通過人工選取符合消歧條件的文本共計135篇,從每一篇文本中人工標(biāo)記出存在歧義的旅游領(lǐng)域?qū)嶓w指稱,并將其指向的知識庫中對應(yīng)實體標(biāo)注出來用于對實驗結(jié)果進行驗證。
3.3實驗結(jié)果與分析
實驗1本文就兩種相似度計算方法的權(quán)重值α的確定采用了一種自動調(diào)優(yōu)的方法,我們的問題可以簡化為C=α·A+(1-α)·B,要使實驗效果相對較好就是要使關(guān)鍵詞之間的相似度值差異較大,即使C的方差達到最大值,這時問題又可以簡化為求使得C方差最大時α的值。先給定α一個初始值0.5 ,由于基于圖的方法在本文中只是起到輔助作用,所以將α每次增加0.05,記錄取每個不同α值的情況下C的方差值,實驗結(jié)果如圖4所示。
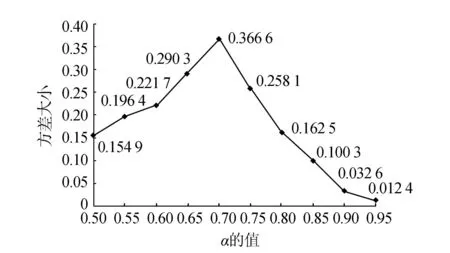
圖4 不同α值時對應(yīng)的樣本方差Fig.4 The sample variance of different α values
根據(jù)實驗結(jié)果可以得出,當(dāng)α的值取0.7時,相似度樣本的方差達到最大值0.366 6,說明此時關(guān)鍵詞之間的相似度分布最為稀疏,相似度值差異最大。
實驗2本文就關(guān)鍵詞個數(shù)n的確定做了6組實驗,分別測試n在取5、6、7、8、9、10時對消歧準(zhǔn)確率的影響,實驗結(jié)果如圖5所示。
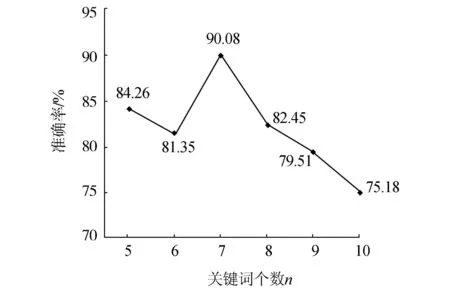
圖5 不同關(guān)鍵詞個數(shù)時系統(tǒng)準(zhǔn)確率Fig.5 Accuracy of different number of keywords
根據(jù)實驗結(jié)果發(fā)現(xiàn),針對本文的測試集和知識庫,將關(guān)鍵詞個數(shù)n定為7的時候準(zhǔn)確率達到最大值90.08%。但是考慮到該知識庫其實并不完備,并非所有的實體指稱項在知識庫中都有相應(yīng)的目標(biāo)實體與之對應(yīng),即所有的候選實體可能并不是目標(biāo)實體,而判斷空實體時只考慮了在知識庫中是否存在,不存在則返回NIL,如果存在,本文的方法是取相似度均值最大的候選實體,這就不可避免地增加了系統(tǒng)的誤差。
實驗3針對以上這種空實體,本文通過大量的實驗,針對不同的關(guān)鍵詞個數(shù)分別對其空實體閾值 λ 進行調(diào)優(yōu),最終結(jié)果如表3所示。
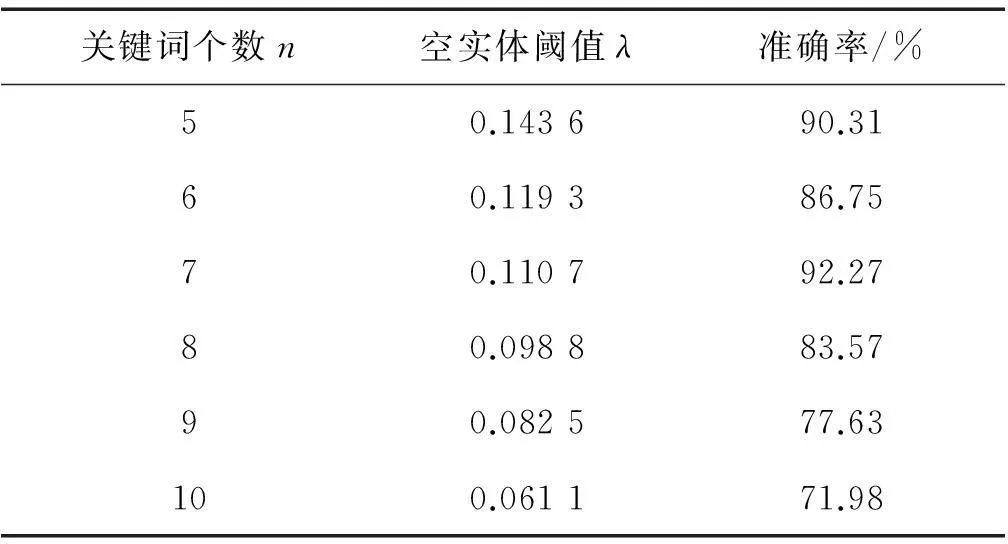
表3 調(diào)優(yōu)后的空實體閾值λ
在加入空實體閾值λ后,系統(tǒng)準(zhǔn)確率在關(guān)鍵詞個數(shù)為5、6、7、8時都有不同程度的提高,在9、10時反而出現(xiàn)下降的趨勢。經(jīng)過分析發(fā)現(xiàn),準(zhǔn)確率的提升程度隨著關(guān)鍵詞的增多而下降,這是因為關(guān)鍵詞的權(quán)重是逐漸遞減的,個數(shù)的增加會使相似度均值發(fā)生不同程度的下降,這會對空實體閾值λ的確定造成一定影響,在判斷空實體的時候容易將相似度均值較低的目標(biāo)實體判斷為空實體,這就反而降低了系統(tǒng)的準(zhǔn)確率。實驗結(jié)果如圖6所示。

圖6 加入空實體閾值后的結(jié)果比較Fig.6 Comparison with the result after adding an empty entity threshold
實驗結(jié)果表明,在關(guān)鍵詞個數(shù)取7,并且加入空實體閾值判斷后,系統(tǒng)達到了最大的準(zhǔn)確率92.27%,這說明本文提出的方法能夠在中文旅游領(lǐng)域?qū)崿F(xiàn)較為理想的消歧結(jié)果,在與現(xiàn)有的主流消歧方法的對比中,優(yōu)勢較為明顯。
表4與主流消歧方法的比較
Table 4Comparison with other mainstream method of disambiguation

方法名準(zhǔn)確率Wikify0.60Cucerzan0.71M&W0.83CSAW0.87本文方法0.92
4結(jié)束語
本文針對特定領(lǐng)域消歧的特點,提出了一種結(jié)合詞向量與圖模型計算的方法,實現(xiàn)了特定領(lǐng)域?qū)嶓w消歧。試驗結(jié)果表明,相比已有的消歧方法,本文提出的方法能在特定領(lǐng)域?qū)嶓w消歧上取得較為理想的結(jié)果。下一步的工作在關(guān)鍵詞個數(shù)的選擇方面將考慮根據(jù)詞的權(quán)重動態(tài)來選擇;另外對于空實體的判斷方法還有待改進。本文實驗結(jié)果也將應(yīng)用到其他特定領(lǐng)域?qū)嶒烌炞C。
參考文獻:
[1]趙軍. 命名實體識別、排歧和跨語言關(guān)聯(lián)[J]. 中文信息學(xué)報, 2009, 23(2): 3-17.
ZHAO Jun. A survey on named entity recognition, disambiguation and cross-lingual coreference resolution[J]. Journal of Chinese information processing, 2009, 23(2): 3-17.
[2]趙軍, 劉康, 周光有, 等. 開放式文本信息抽取[J]. 中文信息學(xué)報, 2011, 25(6): 98-110.
ZHAO Jun, LIU Kang, ZHOU Guangyou, et al. Open information extraction[J]. Journal of Chinese information processing, 2011, 25(6): 98-110.
[3]BUNESCU R C, PASCA M. Using encyclopedic knowledge for named entity disambiguation[C]//Proceedings of the 11st conference of the european chapter of the association for computational linguistics. Trento, Italy, 2006: 9-16.
[4]BAGGA A, BALDWIN B. Entity-based cross-document coreferencing using the vector space model[C]//Proceedings of the 17th international conference on computational linguistics-volume 1. association for computational linguistics. Montreal, Canada, 1998: 79-85.
[5]MANN G S, YAROWSKY D. Unsupervised personal name disambiguation[C]//Proceedings of the 7th conference on natural language learning at HLT-NAACL 2003-volume 4. Sapporo, Japan, 2003: 33-40.
[6]HAN Xianpei, SUN Le. A generative entity-mention model for linking entities with knowledge base[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1. Stroudsburg, PA, USA, 2011: 945-954.
[7]FAN Xiaoming, WANG Jianyong, PU Xu, et al. On graph-based name disambiguation[J]. Journal of data and information quality (JDIQ), 2011, 2(2): 10.
[8]懷寶興, 寶騰飛, 祝恒書, 等. 一種基于概率主題模型的命名實體鏈接方法[J]. 軟件學(xué)報, 2014, 25(9): 2076-2087.
HUAI Baoxing, BAO Tengfei, ZHU Hengshu, et al. Topic modeling approach to named entity linking[J]. Journal of software, 2014, 25(9): 2076-2087.
[9]寧博, 張菲菲. 基于異構(gòu)知識庫的命名實體消歧[J]. 西安郵電大學(xué)學(xué)報, 2014, 19(4): 70-76.
NING Bo, ZHANG Feifei. Named entity disambiguation based on heterogeneous knowledge base[J]. Journal of Xi’an university of posts and telecommunications, 2014, 19(4): 70-76.
[10]朱敏, 賈真, 左玲, 等. 中文微博實體鏈接研究[J]. 北京大學(xué)學(xué)報:自然科學(xué)版, 2014, 50(1): 73-78.
ZHU Min, JIA Zhen, ZUO Ling, et al. Research on entity linking of chinese micro blog[J]. Acta scientiarum naturalium universitatis pekinensis, 2014, 50(1): 73-78.
[11]HINTON G E. Learning distributed representations of concepts[C]//Proceedings of the 8th annual conference of the cognitive science society. Amherst, USA, 1986: 1-12.
[12]張劍, 屈丹, 李真. 基于詞向量特征的循環(huán)神經(jīng)網(wǎng)絡(luò)語言模型[J]. 模式識別與人工智能, 2015, 28(4): 299-305.
ZHANG Jian, QU Dan, LI Zhen. Recurrent neural network language model based on word vector features[J]. Pattern recognition and artificial intelligence, 2015, 28(4): 299-305.
[13]MIKOLOV T, CHEN Kai, CORRADO G, et al. Efficient estimation of word representations in vector space[C]//Proceedings of the International Conference on Learning Representations. Scottsdale, Arizona, 2013: 1388-1429.
[14]MIHALCEA R, TARAU P. TextRank: bringing order into texts[C]//Proceedings of EMNLP-04and the 2004 Conference on Empirical Methods in Natural Language Processing. Spain, 2004: 404-411.
[15]PEARSON K. The problem of the random walk[J]. Nature, 1905, 72(1865): 294.
[16]鄭偉, 王朝坤, 劉璋, 等. 一種基于隨機游走模型的多標(biāo)簽分類算法[J]. 計算機學(xué)報, 2010, 33(8): 1418-1426.
ZHENG Wei, WANG Chaokun, LIU Zhang, et al. A multi-label classification algorithm based on random walk model[J]. Chinese journal of computers, 2010, 33(8): 1418-1426.
[17]SZUMMER M, JAAKKOLA T. Partially labeled classification with Markov random walks[C]//Advances in neural information processing systems (NIPS). Cambridge, 2002, 14: 945-952.
[18]ZHOU Dengyong. Learning from labeled and unlabeled data on a directed graph[C]//Proceedings of the 22nd international conference on machine learning. New York, USA, 2005: 1036-1043.
[19]TISHBY N, SLONIM N. Data clustering by Markovian relaxation and the information bottleneck method[C]//Proceedings of Neural Information Processing Systems. Vancouver, Canadian, 2000: 640-646.
[20]HAREL D, KOREN Y. On clustering using random walks[M]//HARIHARAN R, VINAY V, MUKUND M. Foundations of software technology and theoretical computer science. Berlin Heidelberg: Springer, 2001: 18-41.
[21]LUXBURG U V. A tutorial on spectral clustering[J]. Statistics and computing, 2007, 17(4): 395-416.
[22]GRADY L. Random walks for image segmentation[J]. IEEE transactions on pattern analysis and machine intelligence, 2006, 28(11): 1768-1783.
[23]GORI M, MAGGINI M, SARTI L. Exact and approximate graph matching using random walks.[J]. IEEE transactions on Pattern analysis and machine intelligence, 2005, 27(7): 1100-1111.
[24]KONDOR R I, LAFFERTY J. Diffusion kernels on graphs and other discrete structures[C]//Proceedings of the 19th international conference on machine learning. Sydney, Australia, 2002: 315-322.
[25]BELKIN M, NIYOGI P. Laplacian eigenmaps for dimensionality reduction and data representation[R]. Chicago,
USA: University of Chicago, 2002.
[26]LAFFERTY J, LEBANON G. Information diffusion kernels[C]//Advances in neural information processing systems. Cambridge, 2002: 375-382.
[27]SMOLA A J, KONDOR R. Kernels and regularization on graphs[M]//Learning theory and kernel machines. Berlin Heidelberg: Springer, 2003: 144-158.
[28]HU Jian, WANG Gang, LOCHOVSKY F, et al. Understanding user's query intent with Wikipedia[C]//Proceedings of the 18th International Conference on World Wide Web. Beijing, China, 2009: 471-480.

汪沛,男,1990年生,碩士研究生,主要研究方向為自然語言處理、信息抽取。

線巖團,男,1981年生,博士研究生,主研方向為自然語言處理、信息抽取、機器翻譯、機器學(xué)習(xí)。

郭劍毅,女,1964年生,教授,主要研究領(lǐng)域為自然語言處理、信息抽取、機器學(xué)習(xí)。
中文引用格式:汪沛,線巖團,郭劍毅,等.一種結(jié)合詞向量和圖模型的特定領(lǐng)域?qū)嶓w消歧方法[J]. 智能系統(tǒng)學(xué)報, 2016, 11(3): 366-375.
英文引用格式:WANG Pei, XIAN Yantuan, GUO Jianyi, et al. A novel method using word vector and graphical models for entity disambiguation in specific topic domains[J]. CAAI transactions on intelligent systems, 2016, 11(3): 366-375.
A novel method using word vector and graphical models for entity disambiguation in specific topic domains
WANG Pei1, XIAN Yantuan1,2, GUO Jianyi1,2, WEN Yonghua1,2, CHEN Wei1,2, WANG Hongbin1,2
(1.School of Information Engineering and Automation, Kunming University of Science and Technology, Kunming 650500, China; 2. Key Laboratory of Intelligent Information Processing, Kunming University of Science and Technology, Kunming 650500, China)
Abstract:In this paper, a novel method based on word vector and graph models is proposed to deal with entity disambiguation in specific topic domains. Take the tourism topic domain as an example. The method firstly chooses the web-pages of the tourism category in a Wikipedia offline database to build a knowledge base; then, the tool Word2Vec is used to build a word vector model with the texts in the knowledge base and texts taken from several tourism websites. Combined with a manual annotation graph, a random walk algorithm based on the graph is used to compute similarity to accurately calculate the similarity between words within the tourism domain. Next, the method extracts several keywords from the background text of the entity to be disambiguated and compares them with the keyword text in the knowledge base that describes the candidate entities. Finally, the method uses the trained Word2Vec model and graphical model to calculate the similarity between the keywords of name mention and the keywords of candidate entities. The method then chooses the candidate entities which have the maximum average similarity to the target entity. Experimental results show that this new method can effectively capture the similarity between name mention and a target entity; thus, it can accurately achieve entity disambiguation of a topic-specific domain.
Keywords:entity disambiguation; entity linking; Word2Vec; Wikipedia; graphical model; random walking
作者簡介:
中圖分類號:TP393
文獻標(biāo)志碼:A
文章編號:1673-4785(2016)03-0366-09
通信作者:郭劍毅.E-mail:gjade86@hotmail.com.
基金項目:國家自然科學(xué)基金項目(61262041,61472168,61462054,61562052);云南省自然科學(xué)基金重點項目(2013FA030).
收稿日期:2016-03-19.網(wǎng)絡(luò)出版日期:2016-05-13.
DOI:10.11992/tis.201603048
網(wǎng)絡(luò)出版地址:http://www.cnki.net/kcms/detail/23.1538.TP.20160513.0958.036.html
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
