大數據時代與大學圖書館服務
2016-06-29 03:14:56王銀艷
中國現代教育裝備 2016年11期
唐 玲 王銀艷
荊楚理工學院圖書館 湖北荊門 448000
?
大數據時代與大學圖書館服務
唐 玲 王銀艷
荊楚理工學院圖書館 湖北荊門 448000
摘 要:通過對大數據的概念和特點的分析,概括了大數據形成的三個階段,說明了大學圖書館應積極應對大數據時代的到來,從而更好地利用大數據為大學圖書館服務。
關鍵詞:大數據;數據庫;大學圖書館服務
隨著互聯網、物聯網的不斷發展,各種智能設備,移動終端如個人電腦、ultramobile與手機終端的廣泛應用,地球上每時每刻都在自動產生數以億萬計的數據,這些數據超越了時空的限制,以結構化、半結構化、異構化的形式存在這些海量的數據通過數據的集成、存取、分析,能為社會生活的方方面面提供有價值的情報,據此做出正確的判斷和決策,其準確度達93%,正因為這樣,許多發達國家如美國、英國紛紛斥巨資對大數據進行研究,美國率先將大數據上升到國家戰略高度,2012年3月29日奧巴馬政府在白宮網站發布了《大數據研究和發展倡議》,旨在提升利用大量復雜數據集合獲取知識和洞見的能力,并為此投入兩億美元以上的資金[1]。未來大數據將像黃金和石油一樣,成為人類發展的一種新資源被人們所重視,誰擁有了大數據,誰就占領了信息服務的制高點,大數據時代必將成為繼信息技術革命之后第三次技術革命的浪潮,而每一次技術革命都給圖書館的發展帶來深刻的變化。
1 大數據的概念、形成及應用
大數據單從字面上分析它是大規模的數據集,但它又不僅僅是一個簡單的數量概念[2]。維克多·邁爾·舍恩伯格在《大數據時代》一書中明確指出:大數據時代最大的轉變就是放棄對因果關系的渴求,而取而代之關注相關關系。也就是只需知道“是什么”,而不需要知道“為什么”,它顛覆了人類以前的慣性思維。大數據的特點表現在四個方面:即4V說:Volume(規模性),Variety(多樣性)和Velocity(高速性)以及Value(價值性)。大數據的核心就是它的預測性。
1.1 從傳統數據庫到大數據
傳統的數據庫是先有模式,然后才有數據,而且數據的形式是一種結構性的,其特征是由元數據和對象數據構成,用SQL語言進行查詢,有固定的結構和格式,便于整理,技術運用已經非常成熟。通過二維表結構來邏輯表達數據,多產生于服務器或者個人電腦,設備相對固定,比如圖書館的數字資源,超星數字圖書館,維普數據庫等。而大數據是很多難以確定的、數量繁多,復雜的數據,是以移動終端如手機、平板電腦,GPS等設備為代表的結構性、半結構性、異構性的數據,是在數據出現之后,再去找尋解決問題的模式,同時這種模式又是在不斷演進地動態之中。數據庫里的數據通常以MB為基本單位,而大數據則常常以GB,甚至是TB,PB(1 GB=1 024 MB,1 PB=1 000 TB)為基本單位,其數據規模遠遠大于傳統數據庫,就好像一個池塘與大海的關系。在處理對象上,傳統數據庫是以數據為對象,而大數據是將數據作為一種資源來輔助解決諸多領域的問題,也就是人們常說的數據思維。數據不再是處理對象,而是將數據作為一種資源來協同解決諸多領域的問題,通過收集、整理和分析數據足跡,以便對社會各行各業的活動和決策進行解釋、監控、預測和規劃[3]。單個的數據可能發現不了事物的真實狀況,但很多個數據集串聯起來就能夠發現問題,從而解決問題,比如證監會利用大數據發現股市老鼠倉的事件,比如企業利用大數據分析實現對采購和合理庫存量的管理,了解客戶的需求、掌握市場動向,避免因為盲目進貨而導致的庫存帶來的損失。氣象部門通過多年的氣象資料和當時當地大氣物理狀況指導農業生產和人們的出行。國家安全部門通過人們一些行為來分析判斷危害公共安全的隱患等等。
1.2 大數據的形成及應用
人類歷史上沒有哪個時期像現在這樣如此迅速地產生海量的數據。移動互聯網的加速發展,使得地球上每時每刻產生數以億萬計的數據,有資料顯示,1998年全球網民月平均使用流量是1 MB,2000年是10 MB,2003年是100 MB,2008年是1 GB,2014年是10 GB,全網流量累計達到1 EB(1 EB=10億GB)在2001年是一年,2004年是一個月,2007年是一周,2013年僅需一天。我國是世界上網民最多的國家,信息量呈爆炸式的增長,正在超出人們的想象爆發,如何快速高效利用大數據為人類的各行各業服務,就必須了解大數據形成的原因及背景,尋求解決大數據利用的模式和技術難題。大數據的產生及形成經歷了三個階段:第一階段是以數據庫的管理形式的運營式系統階段,它將數據的管理變得簡單易行,數據的產生方式是被動的,比如醫院每個病人的病歷記載數據,每個商店每條銷售記錄,每所學校每個學生的學業檔案等,都是通過人們記載而產生的數據。第二階段是互聯網的誕生,特別是Web2.0時代為標志的主動創作型系統階段,人們通過微博、博客記錄著自己的隨想、隨行在互聯網上傳播,這種原創的、主動型的數據在網上源源不斷地產生,在移動網絡、智能手機等新型設備的出現之后,使得人們可以隨時隨地發表自己的意見。第三個階段是感知式的系統階段,這個階段是以智能傳感器、物聯網為代表的自動數據產生階段。遍布城市各個角落的攝像設備,對整個社會的運轉進行監控,這些設備產生的數據是自動的,人們在網絡瀏覽的足跡等,也是產生大數據的根本原因。也就是說大數據的產生經歷了被動、主動和自動三個階段,這些被動、主動和自動的數據共同構成了大數據的數據來源,其中自動式的數據才是大數據產生的根本原因。這種規模性和多樣性的數據又給技術的管理和應用帶來挑戰和機遇。
2 大數據時代特點
在大數據時代,數據生成、存儲、分析、檢索、分享、消費共同構成了大數據的生態系統[4]。任何公司和個人都不可能解決大數據運用的全部問題,因此數據的采集、分析、存儲、利用必然出現分工和協作。
2.1 大數據時代的分工協作
數據形成的每個過程都有不同的部門和機構來完成。數據的采集是由無數的個人、傳感器和攝像頭主動或被動形成,這些數據又通過云計算平臺進行存儲計算。數據中心通過PaaS(平臺即服務)模式為數據服務商提供數據接口,而數據服務商組織專業的技術人員開發各種軟件,提供解決數據分析的服務模式,并通過云計算SaaS(軟件即服務)模式為用戶提供服務,企業和個人可以根據自己的需要定制各種服務,獲得自己所需要的答案,而不必去問詢產生這種服務的各個過程。整個大數據的處理流程可以定義為在合適工具的輔導下,對廣泛異構的數據源進行抽取和集成,結果按照一定的標準統一存儲。利用合適的數據分析技術對存儲的數據進行分析,從中提取有益的知識并利用恰當的方式如可視化技術將結果展現給終端用戶。
2.2 數據交換和共享成為主流
數據的價值在于利用,而這種利用又不是孤立的,而是相互聯系形成一個龐大的網絡系統。孤立的數據價值必然是1+1<2,而聯通的數據價值一定是1+1>2[5],數據的交換和共享成為必然趨勢,任何個人和組織都不能將數據據為己有,而開放的數據意味著個人隱私的暴露,但這種損失顯然小于開放帶來的價值,因此許多國家紛紛制定了數據開放服務的規則和規定。美國規定政府必須向民眾開放數據,并通過Data.gov網站向民眾提供數據服務,英國除了規定向民眾開放數據外,還鼓勵“私人數據商業化”,將數據像商品和資源一樣出售。
2.3 專業化的數據服務公司不斷涌現
大數據的產生和發展是建立在互聯網和物聯網快速發展基礎上的,大數據催生出大量的創新產業,相關機構不斷涌現。以提供軟硬件服務的系統開發商,如英特爾、IBM公司,以硬件+數據+軟件提供整體服務供應商,如IBM、微軟、惠普等大企業,還有的數據服務企業以直接和間接的數據提供給企業或個人來獲取一定的商業價值,如國外的Facebook,Twitter等,目前,大數據的搜索服務、數據庫、服務器、數據存儲、數據挖掘等核心技術都被國外的IT巨頭所壟斷,我國的大數據布局遠遠落后于國外的大公司,目前主要以互聯網應用服務為主,如阿里云、騰訊、百度等云計算平臺。
3 大數據時代大學圖書館的功能與作用
在如火如荼的大數據時代,人們總是想用最經濟的方式獲取及時有價值的信息。具體來說,就是人們想在任何時候、任何地方都可以得到全面的、互動的、個性化的,有助于決策的信息服務。圖書館作為保存人類文化知識的地方,一直承擔著傳遞信息和知識的作用。在人類從IT到DT的時代,迅速調整自己的位置,順應時代的發展,努力從人才培養、信息檢索、知識信息的搜集整理方面做好準備,圖書館和圖書館管理人員理應成為大數據時代人們獲取有用信息的重要場所和運用大數據的重要幫手,只有這樣才能讓圖書館立于不敗之地。下圖是武漢大學陳傳夫教授在2012年東莞圖書館年會上展示了大數據時代數字圖書館體系結構圖,介紹了大數據對數字圖書館結構的改變。
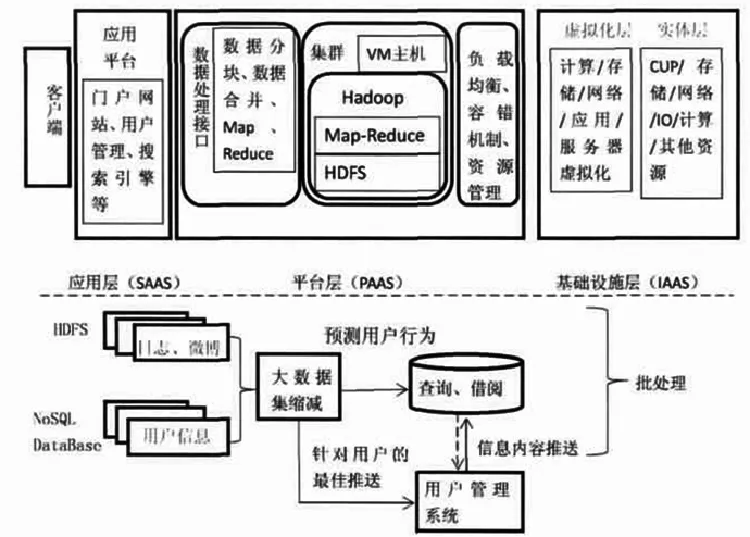
大數據時代數字圖書館體系結構圖
3.1 大學圖書館建成全院信息資料庫
大數據時代分工協作的特點顯示,任何一個公司不可能完成所有數據存儲、分類、檢索、清洗、應用技術等各項工作,因此高校圖書館要成為一所院校的信息集散地。高校圖書館一直都是為高校的教學和科研服務,隨著互聯網的廣泛應用,特別是移動互聯網和智能手機的出現,人們對圖書館紙質圖書的依賴性越來越小,從全國各高校圖書借閱率下降情況可以看出,隨著公共數據的開放程度越來越大,人們隨時隨地的可以從互聯網上下載閱讀,能夠不受時間地點的限制,就能夠方便地獲取知識。但這并不能說圖書館就此消亡,圖書館也有自己的專業優勢,可以在情報信息收集、整理、檢索上下功夫,成為數據專家的得力助手,建立本地化數據,這是別的單位和個人無法取代的,一方面廣泛采集本學院在科研實驗中的各種數據加以保存,這是科學研究的最寶貴的第一手資料。另一方面收集全院所有學生的個人信息,包括專業設置、學業狀況、就業意向,作為人才儲備庫加以保存,為社會對人才的需求提供可靠的數據,將學校與社會對接,通過數據的相互交換達到人才培養的優化組合,這也是大數據的專業分工所賦予的責任和義務。
3.2 培訓數據整理和保管人員,成為咨詢能手
一直以來,圖書館的服務都是以提供一種結構化的數據為主,比如圖書館書目數據的查詢、參考咨詢服務、圖書文獻的深加工以及各種科研課題的定題服務等,但在大數據時代,數據的產生是一個動態的過程,這就為圖書館的服務提供了挑戰和機遇,人們處于源源不斷的數據流之中,如何幫助人們獲取準確的信息,即“是什么”,而不是“為什么”,就是目前國外提出的數據策管課題之一,即數據的保存和監管,是一項有策劃和策略的管理,是對系統數字進行選擇、保存、維護和歸檔等一系列管理活動[6]。早在2008年Uribe和Macdonald就提出數據監管將得益于圖書館員傳統的索引、編目和其他信息組織技術。而Lyon在2007年所提出的大學圖書館員或學科館員是承擔數據監護任務的理想人選的觀點也得到了業內廣泛的認同,而現有大多數圖書館管理人員顯然不具備這方面的能力,需要大力培訓這方面的管理和運用人才,圖書館人就必須在大數據時代早做準備,在國外,許多大學開設了相應的管理與培訓課程。在國內有條件的大學也在從事這方面的教學和培訓工作,只有這樣我們才能在大數據時代變革中不至于驚慌失措,無所適從。
3.3 為讀者進行準確的信息推送和提供個性化的服務
大數據應重點關注讀者個性化閱讀需求,為讀者提供具有較高精細度和精確度的個性化服務[7]。為讀者進行精準的信息推送和個性化的服務,就必須先了解讀者的閱讀行為,明確用戶的閱讀需求和閱讀習慣。圖書館可以通過大數據中讀者瀏覽足跡,例如瀏覽的網頁和查閱的資料等各類行為,可以細化到一篇文章、一個詞,將讀者的微行為匯集到數據庫,然后根據不同人群的興趣愛好分層次的準確推送,還可以根據大數據匯制讀者閱讀興趣愛好圖,預測讀者閱讀需求表,從而為信息資源建設提供準確而可靠的依據,最終達到真正意義上為讀者的需求服務,大大提高圖書館的社會效益。
隨著大數據信息時代的到來,圖書館也迎來了大服務時代的到來,圖書館人必須緊跟時代的步伐,全面掌握了解大數據基本技術和原理,努力提高自己的專業能力和水平,樹立以讀者個性化服務和用戶滿意度核心價值觀,真正意義上實現以人為本的圖書館服務理念。
參考文獻
[1]王忠.美國推動大數據技術發展的戰略價值及啟示[J].中國發展觀察,2012(6):44-45.
[2]李廣建,楊林.大數據視角下的情報研究與情報研究技術[J].圖書與情報,2012(6):1-8.
[3]孟小鋒,慈祥.大數據管理:概念、技術與挑戰[J].計算機研究與發展,2013,50(1):146-169.
[4]薛紅吉.發展大數據產業:我國能否搶占先機?[EB/OL].[2013-03-26].http://www.china-cloud.com/plus/view.php?aid=17842.
[5]鐘輝新.大數據時代信息服務的發展走向以及高校圖書館應對策略[EB/OL].http://www.cnki.net?1994-2014china Academic Journal Electronic Publishing House.All rights reserved.
[6]張曉林,張冬榮.機構知識庫內容保存與傳播的權利管理[J/ OL].中國圖書館學報,2013-04-26.
[7]馬曉亭.大數據時代圖書館數據可用性:價值、挑戰和保障[J].圖書館理論與實踐,2014(10):5-8.
The Big Data and University Library Services
Tang Ling, Wang Yinyan
Jingchu University of Technology, Jingmen, 448000, China
Abstract:This article generalizes the three periods of formation of big data through analysing comceptions and characteristic of it, which illustrates university libraries should reply the coming of big data actively to make better use of big data to serve university libraries.
Key words:big data; database; university library services
收稿日期:2015-12-24
作者簡介:唐玲,本科,館員。
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2010年20期)2010-10-19 01:48:32
