基于改進Bagging算法的高斯過程集成軟測量建模
2016-07-04 03:43:48孫茂偉楊慧中江南大學教育部輕工過程先進控制重點實驗室江蘇無錫214122
化工學報 2016年4期
關鍵詞:模型
孫茂偉,楊慧中(江南大學教育部輕工過程先進控制重點實驗室,江蘇 無錫 214122)
?
基于改進Bagging算法的高斯過程集成軟測量建模
孫茂偉,楊慧中
(江南大學教育部輕工過程先進控制重點實驗室,江蘇 無錫 214122)
摘要:為提高對工況復雜的工業過程進行軟測量建模的模型精度和泛化能力,提出了一種基于改進Bagging算法的高斯過程集成軟測量建模方法。該算法采用高斯過程回歸算法建立集成學習模型的基學習器,并在Bagging算法對訓練樣本重采樣生成基學習器訓練子集的基礎上,采用基于正則化互信息的特征排序指標進行基學習器的輸入特征抽取,實現有監督的特征擾動,從而改善學習器的差異度。待測樣本進行軟測量估計時,根據各高斯過程基學習器輸出的方差自適應地選擇基學習器進行集成輸出。采用工業雙酚A生產裝置反應器的現場數據建模仿真,結果表明該方法是有效的。
關鍵詞:算法;軟測量;模型;高斯過程;反應器
2015-07-30收到初稿,2016-01-10收到修改稿。
聯系人:楊慧中。第一作者:孫茂偉(1990—),男,碩士研究生。
Received date: 2015-07-30.
Foundation item: supported by the National Natural Science Foundation of China (61273070) and the Project Funded by the Priority Academic Program Development of Jiangsu Higher Education Institutions.
引 言
____軟測量技術[1-2]是對工業過程中難以直接測量的重要變量進行在線估計的常用方法,其中建模方法是軟測量技術的核心內容。隨著現代工業水平的發展和提高,過程對象越來越復雜,通常存在多工況、非線性等問題,因此在建立軟測量模型時,對模型描述過程特性的能力要求越來越高,通常可以采用集成學習多模型建模[3-4]或基于聚類的多模型建模[5-6]等方法提高模型的泛化性能和估計精度。
集成學習算法是機器學習領域的一個熱點,該算法通過將一系列有差異的基學習器進行組合,以提高單一學習器的泛化能力。各基學習器具有較高的精確度并且存在較大差異是集成學習算法有效集成的關鍵[7]。目前已有的集成學習算法很多,Bagging算法[8-9]是其中比較常用的一種算法,可提高學習算法的泛化能力,對于因訓練樣本集較小變化可能導致學習結果發生較大變化的學習算法具有比較明顯的改善效果。例如文獻[10]將Bagging算法與高斯過程算法相結合,提高了單一高斯過程軟測量模型的泛化性能。為提高集成學習模型中基學習器的差異度,文獻[11]在基學習器建模時增加了基學習器的輸入特征擾動,且有監督的輸入特征擾動能夠提高基學習器的模型精度,進而提高集成學習模型的估計精度。特征選擇能夠去除冗余特征,提取關鍵特征,有助于提高學習器的學習效果[12]。特征選擇的實現通常先要衡量特征之間的相關性,相關系數局限于對變量間線性關系的描述,而互信息能夠衡量兩個變量之間的線性或非線性相關關系。目前,基于互信息或正則化互信息的特征選擇方法很多,例如文獻[13]提出的mRMR方法以及文獻[14]提出的NMIFS方法,均已成功應用于分類問題中。因此本文通過基于正則化互信息的特征選擇從集成模型基學習器的原始輸入特征集中選擇輸入特征,從而實現有監督的基學習器輸入特征擾動,有效地提高集成學習模型的估計精度。
高斯過程回歸(Gaussian process regression,GPR)是一種具有嚴格統計學習理論基礎的機器學習方法,該方法與人工神經網絡(artificial neural networks,ANN)、支持向量機(support vector machine,SVM)相比,具有超參數自適應獲取、輸出具有概率意義等優點[15-16],已經在軟測量等許多領域廣泛應用。如文獻[17]采用一種基于高斯過程回歸和貝葉斯決策的組合建模方法對某雙酚A生產裝置建立了具有較高估計精度的軟測量模型。
為提高對復雜工業過程軟測量建模的模型精度和泛化能力,改善Bagging算法中基學習器的差異度,本文提出了一種改進Bagging算法的高斯過程集成軟測量建模方法。該算法將基于正則化互信息的特征選擇方法引入Bagging集成學習軟測量建模中,通過定義基于正則化互信息的特征排序指標從原始輸入特征集中有監督地抽取與模型輸出變量相關度大且冗余度小的特征作為基學習器的輸入特征,增加學習器間的差異度;將高斯過程回歸作為基學習器建模算法,并在集成輸出時利用高斯過程回歸基學習器的輸出方差自適應地選擇合適的基學習器集成輸出。采用來自工業雙酚A生產裝置現場的數據進行建模仿真。
1 高斯過程回歸
高斯過程回歸模型是一種非參數概率模型,能將待測樣本進行輸出估計并給出估計方差。高斯過程由均值函數和協方差函數唯一確定。
設訓練樣本集為D={(xi,yi)},i=1,2,…,n,xi∈Rm為m維輸入變量,y∈R為輸出變量。對于待測樣本xt,高斯過程回歸模型的預測分布是n個訓練樣本以及待測樣本xt所形成的n+1維的聯合高斯分布,其均值為

方差為
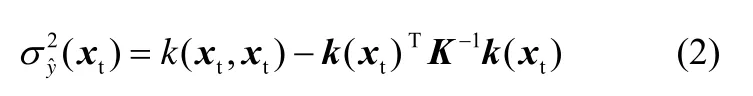
式中,k(xt)=[C(xt,x1),C(xt,x2),…,C(xt,xn)]T為待測樣本的輸入與訓練樣本輸入之間的協方差向量;矩陣K(n×n)為訓練樣本間的協方差矩陣,矩陣元素為兩個訓練樣本的輸入變量之間的協方差Ki,j=C(xi,xj),i,j=1,2,…,n; k(xt,xt)=C(xt,xt)為待測樣本輸入和其本身的協方差;y=[yt,y2,…,yn]T為訓練樣本的輸出向量。本文采用徑向基函數作為高斯過程的協方差函數
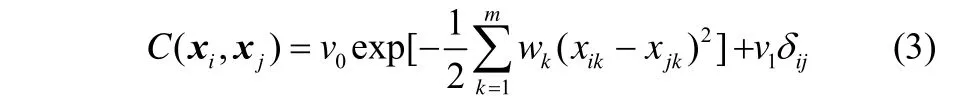
式中,v0為先驗知識的總體度量,v1為服從高斯分布的噪聲方差,dij為Kronecker算子。采用極大似然法優化協方差函數的參數q=(v0,w1,w2,…,wm,v1),從而獲得高斯過程模型的最優超參數。對于式(3)所示的協方差函數,訓練樣本的對數似然函數為
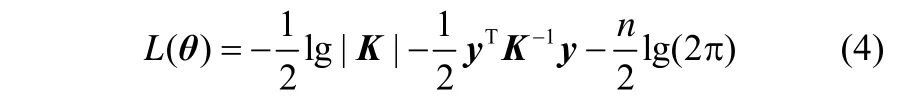
在優化過程中,通過求取式(4)的極大似然來調整超參數q。設q為在合理范圍內的隨機數,然后通過共軛梯度迭代方法搜索獲得超參數的最優值。得到最優超參數后,則可根據式(1)、式(2)估計待測樣本輸出的均值與方差。
2 Bagging集成學習算法
Bagging集成學習算法包括基學習器建模和基學習器的組合輸出兩個部分。
設訓練樣本集為D={(xi,yi)},i=1,2,…,n,xi∈Rm為m維輸入變量,y∈R為輸出變量。Bagging集成學習算法通過放回隨機抽樣技術(Bootstrapping取樣)生成集成模型中的基學習器。Bootstrapping取樣的基本思想是通過從原始訓練樣本集D中有放回地隨機抽取樣本從而構成與原始訓練樣本集樣本數相同的訓練子集。原始樣本集的部分樣本可能多次出現在訓練子集中,同時也有部分樣本可能不出現。通過多輪Bootstrapping重取樣,可以獲得具有一定差異的訓練子集{D1,D2,…,DN},利用這些存在差異的訓練子集,采用某種學習算法訓練獲得基學習器{f1,f2,…,fN}。因此Bagging算法中各個基學習器之間的差異性是由訓練樣本集重采樣的隨機性和獨立性產生的。
基學習器的組合方式多種多樣,Bagging集成軟測量模型常用的組合輸出方法包括取各基學習器輸出均值或加權輸出等方法。Bagging集成學習算法結構如圖1所示。
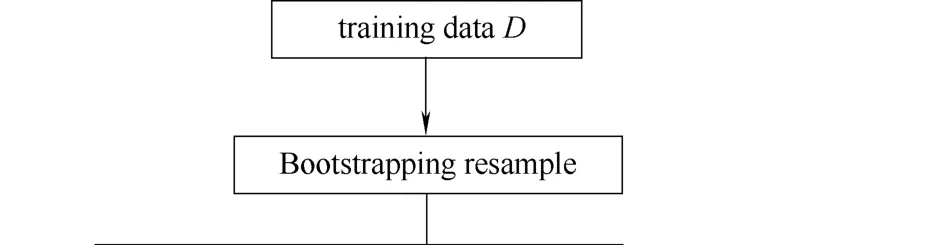
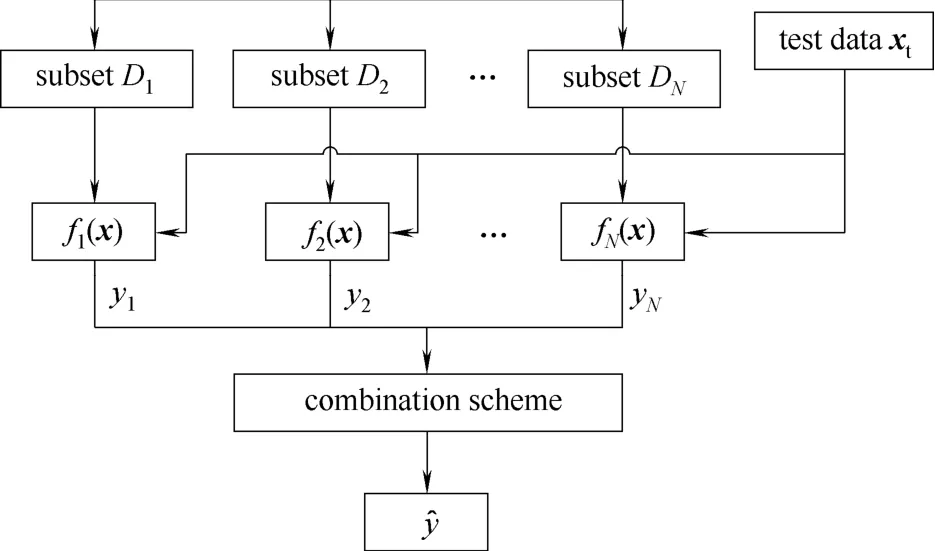
圖1 Bagging算法結構Fig.1 Structure of Bagging algorithm
3 改進Bagging算法的高斯過程集成軟測量建模方法
3.1基于正則化互信息的特征排序指標
互信息是信息論中的重要概念,目前已經廣泛應用于變量的相關性評價和變量的選擇等問題上[18-19]。對于變量x和y,其互信息定義為

式中,p(x)和p(y)分別是變量x和y的邊緣概率密度函數,p(x,y)為兩變量的聯合概率密度函數。I(x;y) ≥0并且其值越大,兩變量的相關性越大,當I(x;y)=0時,表明兩變量不相關。
正則化互信息[20]是對互信息的歸一化處理,即正則化互信息的值在[0,1]之間。定義正則化互信息為
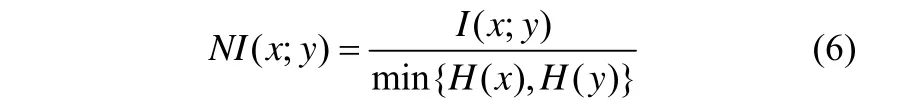
式中,H(x)和H(y)為變量的信息熵,其定義為
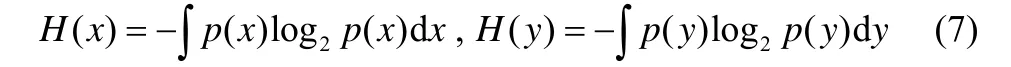
本文將基于正則化互信息的特征選擇方法引入集成學習軟測量建模中,用于實現基學習器的有監督特征擾動。設軟測量模型原始輸入特征集為S,S中已排序的特征構成集合S′。定義基于正則化互信息的特征排序指標為
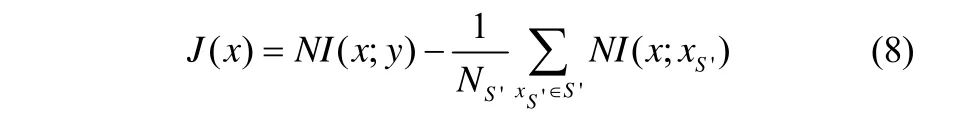
式中,x為原始輸入特征集S中待排序的特征,xS′為S′中的已排序特征,NS′為已排序特征的個數;y為模型輸出變量。
式(8)中,NI(x;y)為待排序特征x與輸出變量y的正則化互信息,反映了x與輸出變量y之間的相關程度,該項值越大則相關度越大;項為待排序特征x與所有已排序特征的正則化互信息的平均值,表示x與已排序特征的信息冗余程度,其值越小則冗余度越小。因此,基于正則化互信息的特征排序指標是表征輸入特征x與輸出變量y相關程度以及x與已排序特征冗余程度的綜合度量。進行基學習器的輸入特征抽取時,根據學習器原始輸入特征集中各特征對應的排序指標值,可對輸入特征進行優先度排序,即指標值J越大的特征越應當被優先抽取。
3.2高斯過程集成軟測量建模
為提高Bagging算法中基學習器的差異度,本文采用基于正則化互信息的特征排序指標對原始輸入特征集中的輸入特征進行特征抽取優先度排序,實現基學習器的有監督輸入特征擾動,使改進Bagging算法在提高基學習器間差異度的同時能夠提高基學習器的模型精度。設訓練樣本集為D={(xi,yi)},i=1,2,…,n,xi∈Rm為第i個訓練樣本的m維輸入向量,yi∈R為第i個訓練樣本的輸出值。原始輸入特征集為S,包含m個輸入特征。基于改進Bagging算法的高斯過程集成軟測量建模過程如下。
(1)設置基學習器的個數為N。
(2)進行輸入特征抽取優先度排序。計算原始輸入特征集S中每個輸入特征與輸出變量的正則化互信息并將正則化互信息值最大的輸入特征作為基學習器輸入特征抽取優先度最高的特征,將其加入已排序輸入特征集S′(初始為空集)中,然后按照式(8)計算S中每個未排序輸入特征的特征排序指標值,將指標值最大的輸入特征作為第二優先抽取的輸入特征并將其加入特征集S′。重復采用上述方法將原始特征集S中的m個輸入特征的抽取優先度進行排序。
(3)采用Bootstrapping取樣方法從訓練數據集D中進行重采樣得到基學習器訓練子集D′,同時按照步驟(2)的特征抽取優先度排序從原始輸入特征集中抽取優先度最高的m′個輸入特征作為基學習器的輸入,其中m′在[2,m]之間隨機產生,然后采用高斯過程回歸算法建立基學習器。
(4)重復步驟(3)得到N個高斯過程基學習器{GP1,GP2,…,GPN}。
由于高斯過程回歸模型的輸出具有概率意義,不僅能夠給出待測樣本的輸出估計值,并且給出了估計的方差,輸出方差越小,表明估計值的可信度越高,因此在模型集成輸出時,本文采用了輸出方差最小的N′個基學習器進行集成輸出,從而提高集成軟測量模型的最終估計精度,即對待測樣本xt進行輸出估計時,集成模型輸出為

式中,GP′1~GP′N′為N個基學習器中輸出結果方差最小的N′個基學習器。算法結構如圖2所示。
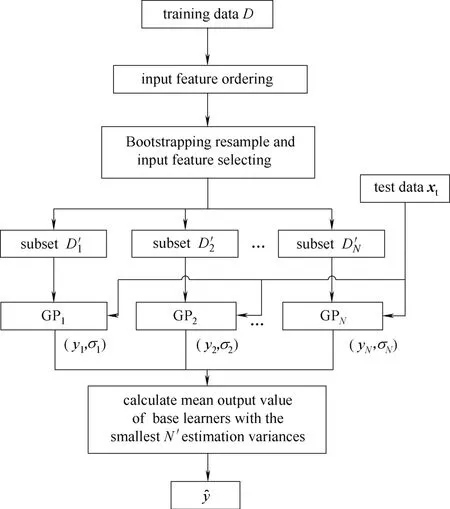
圖2 算法結構Fig.2 Structure of algorithm
4 仿真實例
本仿真的數據來自某雙酚A(BPA)生產裝置中裂解重整回收單元的反應器R802以及R802的前級反應器R801。采用本文提出的基于改進Bagging算法的高斯過程集成軟測量建模方法對反應器R802出口組分中的BPA含量進行軟測量建模。根據生產工藝及流程分析,選擇R801頂部苯酚流量、頂部溫度、底部溫度、出口BPA含量以及R802頂部溫度、R802底部溫度6個變量作為軟測量模型的輸入輔助變量,以反應器R802出口組分中的BPA含量作為模型輸出主導變量。從現場取回180組R802出口組分BPA含量的人工分析值和與之對應的輔助變量現場數據作為樣本數據集,其中120組用于模型訓練,剩余60組用于模型效果測試。考慮到各變量由于量綱和單位不同會對建模精度產生影響,首先對樣本數據進行標準化處理然后再采用本文提出軟測量建模方法建立反應器R802出口組分BPA含量的軟測量估計模型,考慮訓練樣本集規模并根據多次實驗設置模型參數為:基學習器個數N=20,基學習器輸入特征個數m′∈{2,3,…,6},N′=5。

表1 模型仿真結果Table 1 Simulation result of models
為驗證本文方法的有效性,將本文方法模型的仿真結果與SVM單模型(表1中的方法1)、GP單模型(表1中的方法2)和增加無監督特征擾動的基于Bagging算法的GP集成軟測量模型(表1中的方法3)進行比較,其中集成學習模型的仿真結果為50次仿真的平均值,結果如表1所示,本文方法和單模型方法的估計結果如圖3所示。
表1中均方根誤差(RMSE)、最大絕對誤差(MAXE)、平均絕對誤差(ME)的計算方法如下

通過表1和圖3的仿真結果可知,本文提出的基于改進Bagging算法的高斯過程集成軟測量建模方法的模型精度和泛化能力明顯優于單一支持向量機模型和高斯過程模型;表1中方法3與本文算法的區別在于方法3中基學習器的輸入特征擾動是通過無監督隨機抽取方式產生的,而本文算法通過基于正則化互信息的特征排序指標實現有監督輸入特征擾動,從而進一步提高了集成模型的模型精度。
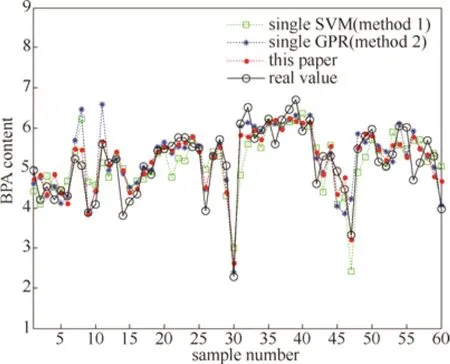
圖3 測試集估計結果Fig.3 Estimation results of test data set
5 結 論
本文提出了一種基于改進Bagging算法的高斯過程集成軟測量建模方法。該方法以高斯過程回歸算法作為基學習器的學習算法,采用Bagging算法建立高斯過程集成軟測量模型。在Bagging算法重采樣產生訓練子集的同時,通過基于正則化互信息的特征排序指標實現有監督的特征擾動,從而在增加基學習器之間的差異度的同時提高基學習器的估計精度;在集成輸出時,根據高斯過程基學習器輸出的方差信息選擇精確度高的基學習器進行組合輸出,從而提高集成學習模型的泛化能力和估計精度。采用來自工業雙酚A生產裝置的現場數據進行軟測量建模,仿真結果表明了算法的有效性。
References
[1] 曹鵬飛,羅雄麟. 化工過程軟測量建模方法研究進展 [J]. 化工學報,2013,64(3): 788-800. DOI: 10.3969/j.issn.0438-1157. 2013. 03.003. CAO P F,LUO X L. Modeling of soft sensor for chemical process [J]. CIESC Journal,2013,64(3): 788-800. DOI: 10.3969/j.issn.0438-1157. 2013.03.003.
[2] 王海寧,夏陸岳,周猛飛,等. 過程工業軟測量中的多模型融合建模方法 [J]. 化工進展,2014,33(12): 3157-3163. DOI: 10.3969/j.issn.1000-6613.2014.12.005. WANG H N,XIA L Y,ZHOU M F,et al. Multi-model fusion modeling method for process industries soft sensor [J]. Chemical Industry and Engineering Progress,2014,33(12): 3157-3163. DOI: 10.3969/j.issn. 1000-6613.2014.12.005.
[3] 周鑫,譚帥,楊琦,等. 基于Bagging集成的球團礦燒結過程混合模型 [J]. 控制工程,2015,22(3): 516-520. DOI: 10.14107/ j.cnki.kzgc.140039. ZHOU X,TAN S,YANG Q,et al. Modeling for pellets induration process based on Bagging method [J]. Control Engineering of China,2015,22(3): 516-520. DOI: 10.14107/j.cnki.kzgc.140039.
[4] 李毓,徐成賢. 修剪Bagging集成的方法及其應用 [J]. 系統工程理論與實踐,2008,28(7): 105-110. DOI: 10.3321/j.issn: 1000-6788. 2008.07.014. LI Y,XU C X. A method for pruning Bagging ensembles and its applications [J]. Systems Engineering—Theory and Practice,2008,28(7): 105-110. DOI: 10.3321/j.issn:1000-6788.2008.07.014.
[5] 陳定三,楊慧中. 基于局部重構融合流形聚類的多模型軟測量建模 [J]. 化工學報,2011,62(8): 2281-2286. DOI: 10.3969/j.issn. 0438-1157.2011.08.034. CHEN D S,YANG H Z. Multiple model soft sensor based on local reconstruction and fusion manifold clustering [J]. CIESC Journal,2011,62(8): 2281-2286. DOI: 10.3969/j.issn.0438-1157.2011.08.034.
[6] 呂業,鄧玉俊,楊慧中. 基于類別特征提取的組合支持向量機模型 [J]. 化工學報,2011,62(8): 2164-2169. DOI: 10.3969/j.issn. 0438-1157.2011.08.013. Lü Y,DENG Y J,YANG H Z. Compositional support vector machine model based on feature extraction of categories [J]. CIESC Journal,2011,62(8): 2164-2169. DOI: 10.3969/j.issn.0438-1157.2011.08.013.
[7] 孫博,王建東,陳海燕,等. 集成學習中的多樣性度量 [J]. 控制與決策,2014,29(3): 385-395. DOI: 10.13195/j.kzyjc.2013.1334. SUN B,WANG J D,CHEN H Y,et al. Diversity measures in ensemble learning [J]. Control and Decision,2014,29(3): 385-395. DOI: 10.13195/j.kzyjc.2013.1334.
[8] 安睿. 基于Bagging的電力信息安全態勢分析系統的研究與實現[D]. 北京: 華北電力大學,2012. AN R. Research and implementation on Bagging of electrical information security situation analysis system[D]. Beijing: North China Electric Power University,2012.
[9] 劉余霞,呂虹,胡濤,等. 基于Bagging集成學習的字符識別方法[J]. 計算機工程與應用,2012,48(33): 194-196,211. DOI: 10.3778/j.issn.1002-8331.1207-0203. LIU Y X,Lü H,HU T,et al. Research on character recognition based on Bagging ensemble learning [J]. Computer Engineering andApplications,2012,48(33): 194-196,211. DOI: 10.3778/j.issn. 1002-8331.1207-0203.
[10] 李雅芹,楊慧中. 一種基于Bagging算法的高斯過程集成建模方法[J]. 東南大學學報(自然科學版),2011,41(S1): 93-96. DOI: 10.3969/j.issn.1001-0505.2011.S1.020. LI Y Q,YANG H Z. Ensemble modeling method based on Bagging algorithm and Gaussian process [J]. Journal of Southeast University (Natural Science Edition),2011,41(S1): 93-96. DOI: 10.3969/j.issn. 1001-0505. 2011.S1.020.
[11] 亓慧,王文劍,郭虎升. 一種基于特征選擇的SVM Bagging集成方法 [J]. 小型微型計算機系統,2014,35(11): 2533-2537. QI H,WANG W J,GUO H S. An SVM Bagging ensemble learning algorithm based on feature selection [J]. Journal of Chinese Computer Systems,2014,35(11): 2533-2537.
[12] 徐峻嶺,周毓明,陳林,等. 基于互信息的無監督特征選擇 [J].計算機研究與發展,2012,49(2): 372-382. XU J L,ZHOU Y M,CHEN L,et al. An unsupervised feature selection approach based on mutual information [J]. Journal of Computer Research and Development,2012,49(2): 372-382.
[13] PENG H C,LONG F H,DING C. Feature selection based on mutual information: criteria of Max-Dependency,Max-Relevance,and Min-Redundancy [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27(8): 1226-1238. DOI: 10.1109/TPAMI. 2005.159.
[14] ESTEVEZ P A,TESMER M,PEREZ C A,et al. Normalized mutual information feature selection [J]. IEEE Transactions on Neural Networks,2009,20(2): 189-201. DOI: 10.1109/TNN.2008.2005601.
[15] 何志昆,劉光斌,趙曦晶,等. 高斯過程回歸方法綜述 [J]. 控制與決策,2013,28(8): 1121-1129,1137. DOI: 10.13195/j.kzyjc. 2013.08.018. HE Z K,LIU G B,ZHAO X J,et al. Overview of Gaussian process regression [J]. Control and Decision,2013,28(8): 1121-1129,1137. DOI: 10.13195/j.kzyjc.2013.08.018.
[16] NI W D,TAN S K,NG W J,et al. Moving-window GPR for nonlinear dynamic system modeling with dual updating and dual preprocessing [J]. Industrial and Engineering Chemistry Research,2012,51(18): 6416-6428. DOI: 10.1021/ie201898a.
[17] 雷瑜,楊慧中. 基于高斯過程和貝葉斯決策的組合模型軟測量 [J].化工學報,2013,64(12): 4434-4438. DOI: 10.3969/j.issn.0438-1157. 2013.12.025. LEI Y,YANG H Z. Combination model soft sensor based on Gaussian process and Bayesian committee machine [J]. CIESC Journal,2013,64(12): 4434-4438. DOI: 10.3969/j.issn.0438-1157. 2013.12.025.
[18] 韓敏,劉曉欣. 基于Copula熵的互信息估計方法 [J]. 控制理論與應用,2013,30(7): 875-879. DOI: 10.7641/CTA.2013.21262. HAN M,LIU X X. Mutual information estimation based on Copula entropy [J]. Control Theory and Applications,2013,30(7): 875-879. DOI: 10.7641/CTA.2013.21262.
[19] 范雪莉,馮海泓,原猛. 基于互信息的主成分分析特征選擇算法[J]. 控制與決策,2013,28(6): 915-919. FAN X L,FENG H H,YUAN M. PCA based on mutual information for feature selection [J]. Control and Decision,2013,28(6): 915-919.
[20] 洪智勇,劉燦濤,鄧寶林. 基于二次Renyi熵的正則化互信息特征選擇方法 [J]. 計算機應用,2010,30(5): 1273-1276. HONG Z Y,LIU C T,DENG B L. Normalized mutual information feature selection method based on Renyi’s quadratic entropy [J]. Journal of Computer Applications,2010,30(5): 1273-1276.
Gaussian process ensemble soft-sensor modeling based on improved Bagging algorithm
SUN Maowei,YANG Huizhong
(Key Laboratory of Advanced Process Control for Light Industry of Ministry of Education,Jiangnan University,Wuxi 214122,Jiangsu,China)
Abstract:In order to improve the accuracy and generalization ability of soft-sensor for complex industrial process,a Gaussian process ensemble soft-sensor modeling algorithm based on the improved bagging algorithm is proposed. This algorithm uses Gaussian process regression algorithm to build base learners and the resample method of bagging algorithm to form training subsets of base learners. A criteria for feature ordering base on normalized mutual information is proposed with selecting input features of base learners,which can implement supervised feature perturbance in the ensemble modeling for the sake of improving the diversity between base learners. When estimating the output of the test sample according to the output variances given by Gaussian process base learners,several base learners are selected adaptively to calculate the output of ensemble model. A soft-sensor modeling simulation using the data from the reactors of industrial Bisphenol-A production units shows the effectiveness of the algorithm.
Key words:algorithm; soft-sensor; model; Gaussian process; reactors
DOI:10.11949/j.issn.0438-1157.20151223
中圖分類號:TP 274
文獻標志碼:A
文章編號:0438—1157(2016)04—1386—06
基金項目:國家自然科學基金項目(61273070);江蘇省高校優勢學科建設工程資助項目。
Corresponding author:Prof. YANG Huizhong,yhz_jn@163.com
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
