基于MapReduce的DHP算法并行化研究
2016-07-19 02:07:19周?chē)?guó)軍吳慶軍
計(jì)算機(jī)應(yīng)用與軟件 2016年6期
周?chē)?guó)軍 吳慶軍
(玉林師范學(xué)院數(shù)學(xué)與信息科學(xué)學(xué)院 廣西 玉林 537000)
?
基于MapReduce的DHP算法并行化研究
周?chē)?guó)軍吳慶軍
(玉林師范學(xué)院數(shù)學(xué)與信息科學(xué)學(xué)院廣西 玉林 537000)
摘要針對(duì)DHP(direct hashing and pruning)算法對(duì)大數(shù)據(jù)挖掘關(guān)聯(lián)規(guī)則存在執(zhí)行時(shí)間過(guò)長(zhǎng)、效率不高的問(wèn)題,對(duì)DHP算法的并行化策略進(jìn)行了研究。根據(jù)云計(jì)算平臺(tái)Hadoop的MapReduce并行編程模型,設(shè)計(jì)了一種并行DHP算法,給出了算法的總體流程和Map函數(shù)、Reduce函數(shù)的算法描述。與DHP算法相比,并行算法利用了Hadoop集群強(qiáng)大的計(jì)算能力,提高了從大數(shù)據(jù)集中挖掘關(guān)聯(lián)規(guī)則的效率。通過(guò)實(shí)例分析了并行DHP算法的執(zhí)行過(guò)程,在多個(gè)數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn)。實(shí)驗(yàn)結(jié)果表明:并行DHP算法對(duì)大數(shù)據(jù)具有較好的加速比和可擴(kuò)展性。
關(guān)鍵詞MapReduce Hadoop DHP算法關(guān)聯(lián)規(guī)則
0引言
關(guān)聯(lián)規(guī)則挖掘是數(shù)據(jù)挖掘領(lǐng)域的一個(gè)重要研究方向,其目標(biāo)是從事務(wù)數(shù)據(jù)庫(kù)中發(fā)現(xiàn)項(xiàng)與項(xiàng)之間的相關(guān)聯(lián)系。如何高效地找出所有的頻繁項(xiàng)集是關(guān)聯(lián)規(guī)則挖掘算法要解決的主要問(wèn)題。DHP算法[1]在Apriori算法[2]的基礎(chǔ)上利用哈希技術(shù)修剪候選項(xiàng)集和事務(wù)數(shù)據(jù)庫(kù),提高了生成頻繁項(xiàng)集的效率,是公認(rèn)的非常有效的算法。由于DHP算法具有很好的性能,在文本數(shù)據(jù)挖掘[3]、Web遍歷路徑挖掘[4]等方面得到了廣泛應(yīng)用。已經(jīng)有較多的文獻(xiàn)對(duì)DHP算法的Hash函數(shù)選取、Hash表結(jié)構(gòu)優(yōu)化、冗余事務(wù)的修剪策略等進(jìn)行了研究和改進(jìn),這些改進(jìn)算法進(jìn)一步提高了發(fā)現(xiàn)頻繁項(xiàng)集的效率。但是,DHP算法是一種時(shí)間復(fù)雜度較高的算法,受單機(jī)存儲(chǔ)空間和計(jì)算能力的限制,DHP算法及其改進(jìn)的串行算法對(duì)大數(shù)據(jù)集挖掘關(guān)聯(lián)規(guī)則存在執(zhí)行時(shí)間太長(zhǎng)、效率較低的性能瓶頸問(wèn)題。
云計(jì)算[5]是近年來(lái)興起的一種計(jì)算模式,優(yōu)勢(shì)是提供了海量的存儲(chǔ)空間和強(qiáng)大的計(jì)算能力,將云計(jì)算技術(shù)應(yīng)用于數(shù)據(jù)挖掘領(lǐng)域是一個(gè)新的發(fā)展趨勢(shì)[6]。Google公司提出的MapReduce[7]是一種簡(jiǎn)潔高效的并行編程模型,該模型屏蔽了底層實(shí)現(xiàn)細(xì)節(jié),降低了編程難度。MapReduce模型將復(fù)雜的處理任務(wù)抽象成Map函數(shù)和Reduce函數(shù),Map、Reduce函數(shù)在分布式集群的節(jié)點(diǎn)上并行執(zhí)行,從而達(dá)到了對(duì)大規(guī)模計(jì)算任務(wù)進(jìn)行高效處理的要求[8]。Apache軟件基金會(huì)開(kāi)發(fā)的Hadoop[9]是一個(gè)開(kāi)源的分布式計(jì)算平臺(tái),該平臺(tái)以高可靠性、高擴(kuò)展性等優(yōu)點(diǎn)得到了學(xué)術(shù)界的認(rèn)可和工業(yè)界的廣泛應(yīng)用。Hadoop實(shí)現(xiàn)了MapReduce模型,用戶(hù)可以在大量廉價(jià)設(shè)備組成的Hadoop集群上運(yùn)行MapReduce應(yīng)用程序。
本文根據(jù)Hadoop平臺(tái)的MapReduce模型,對(duì)DHP算法的并行化方法進(jìn)行了分析,設(shè)計(jì)了一種并行DHP算法。該算法利用Hadoop集群中各節(jié)點(diǎn)的計(jì)算能力,縮短了對(duì)大數(shù)據(jù)集挖掘關(guān)聯(lián)規(guī)則的時(shí)間,具有較好的加速比和可擴(kuò)展性。最后,通過(guò)實(shí)驗(yàn)驗(yàn)證了并行DHP算法的性能。
1Hadoop平臺(tái)的MapReduce模型
Hadoop的MapReduce框架處理大數(shù)據(jù)集的一般過(guò)程是:將大數(shù)據(jù)集分解成許多數(shù)據(jù)分片,JobTracker進(jìn)程將MapReduce任務(wù)分配給TaskTracker節(jié)點(diǎn),TaskTracker進(jìn)程讀取一個(gè)(或多個(gè))數(shù)據(jù)分片、并執(zhí)行MapReduce任務(wù)。
在Hadoop中,MapReduce應(yīng)用程序的基本結(jié)構(gòu)包括主函數(shù)、Map函數(shù)和Reduce函數(shù)。主函數(shù)對(duì)每個(gè)MapReduce作業(yè)所需的參數(shù)進(jìn)行配置,并在作業(yè)啟動(dòng)后對(duì)程序的執(zhí)行流程進(jìn)行控制。Map函數(shù)定義為一個(gè)類(lèi)(稱(chēng)為Mapper類(lèi)),在Mapper類(lèi)中可以定義setup、map和cleanup等方法。對(duì)于每個(gè)Map任務(wù),setup方法只在任務(wù)開(kāi)始之前調(diào)用一次,cleanup方法只在任務(wù)結(jié)束之前調(diào)用一次。相應(yīng)地,Reduce函數(shù)定義為一個(gè)稱(chēng)為Reducer的類(lèi),在Reducer類(lèi)中可以定義setup、reduce和cleanup等方法,對(duì)于每個(gè)Reduce任務(wù),setup和cleanup方法只調(diào)用一次。map、reduce方法的一般形式[10]表示如下:
map:(K1,V1) →list(K2,V2)
reduce:(K2,list(V2)) →list(K3,V3)
其中,(K1,V1)是數(shù)據(jù)分片的一條記錄經(jīng)過(guò)MapReduce框架解析后的鍵/值對(duì)表示形式,list(K2,V2)、list(K3,V3)分別是map和reduce方法輸出的鍵/值對(duì)列表。
2DHP算法的并行化策略
文獻(xiàn)[1]給出了DHP算法的詳細(xì)描述,DHP算法的三個(gè)部分都能采用MapReduce模型將其并行化,說(shuō)明如下:
第一部分對(duì)候選1-項(xiàng)集的支持度計(jì)數(shù)、哈希表的桶計(jì)數(shù)進(jìn)行并行化。與詞頻統(tǒng)計(jì)方法相似,Map函數(shù)對(duì)數(shù)據(jù)分片的每個(gè)事務(wù)t分解出所有項(xiàng)ij,計(jì)算出所有2-項(xiàng)子集x的哈希桶地址addr=h2[x],輸出
第二部分對(duì)事務(wù)數(shù)據(jù)庫(kù)Dk的修剪、候選k-項(xiàng)集的支持度計(jì)數(shù)和哈希表的桶計(jì)數(shù)進(jìn)行并行化。該部分是一個(gè)迭代計(jì)算頻繁k項(xiàng)集Lk的過(guò)程,每次迭代過(guò)程由一個(gè)MapReduce任務(wù)完成,需要解決3個(gè)主要問(wèn)題。①控制迭代次數(shù)。簡(jiǎn)單的方法是在主函數(shù)中由循環(huán)條件 (|{x|Hk[x]≥s}|≥LARGE) 控制MapReduce任務(wù)迭代的次數(shù)。②Map函數(shù)如何讀取所有頻繁(k-1)-項(xiàng)集Lk-1和哈希表Hk以生成所有候選k-項(xiàng)集Ck。在主函數(shù)中將Lk-1和Hk設(shè)置為分布式緩存文件,由Hadoop的MapReduce框架將Lk-1和Hk分發(fā)到執(zhí)行Map任務(wù)的TaskTracker節(jié)點(diǎn)就解決了這個(gè)問(wèn)題。③如何輸出修剪后的事務(wù)數(shù)據(jù)庫(kù)Dk+1。簡(jiǎn)單的方法是在Hadoop的文件系統(tǒng)HDFS中創(chuàng)建一個(gè)目錄,Map函數(shù)將修剪后的數(shù)據(jù)分片以文件形式寫(xiě)入到HDFS中。該方法的優(yōu)點(diǎn)是:第k+1次迭代只需在主函數(shù)中設(shè)置MapReduce任務(wù)的輸入路徑為Dk+1的目錄,Map函數(shù)便可讀取Dk+1的數(shù)據(jù)分片。
第三部分對(duì)事務(wù)數(shù)據(jù)庫(kù)Dk的修剪和候選k-項(xiàng)集的支持度計(jì)數(shù)進(jìn)行并行化。在該部分中,主函數(shù)除了控制程序流程之外,還需要完成以下計(jì)算:在第一個(gè)MapReduce任務(wù)執(zhí)行前生成所有候選k-項(xiàng)集Ck,即執(zhí)行g(shù)en_candidate(Lk-1,Hk,Ck),并將Ck分發(fā)給執(zhí)行Map任務(wù)的節(jié)點(diǎn)。在每個(gè)MapReduce任務(wù)結(jié)束后執(zhí)行Ck+1=apriori_gen(Lk),并在下一次迭代前分發(fā)Ck+1。
3并行DHP算法設(shè)計(jì)與描述
3.1算法的總體流程及描述
并行DHP算法的總體流程如圖1所示,其中s是最小支持度閾值,LARGE是預(yù)定義的閾值。
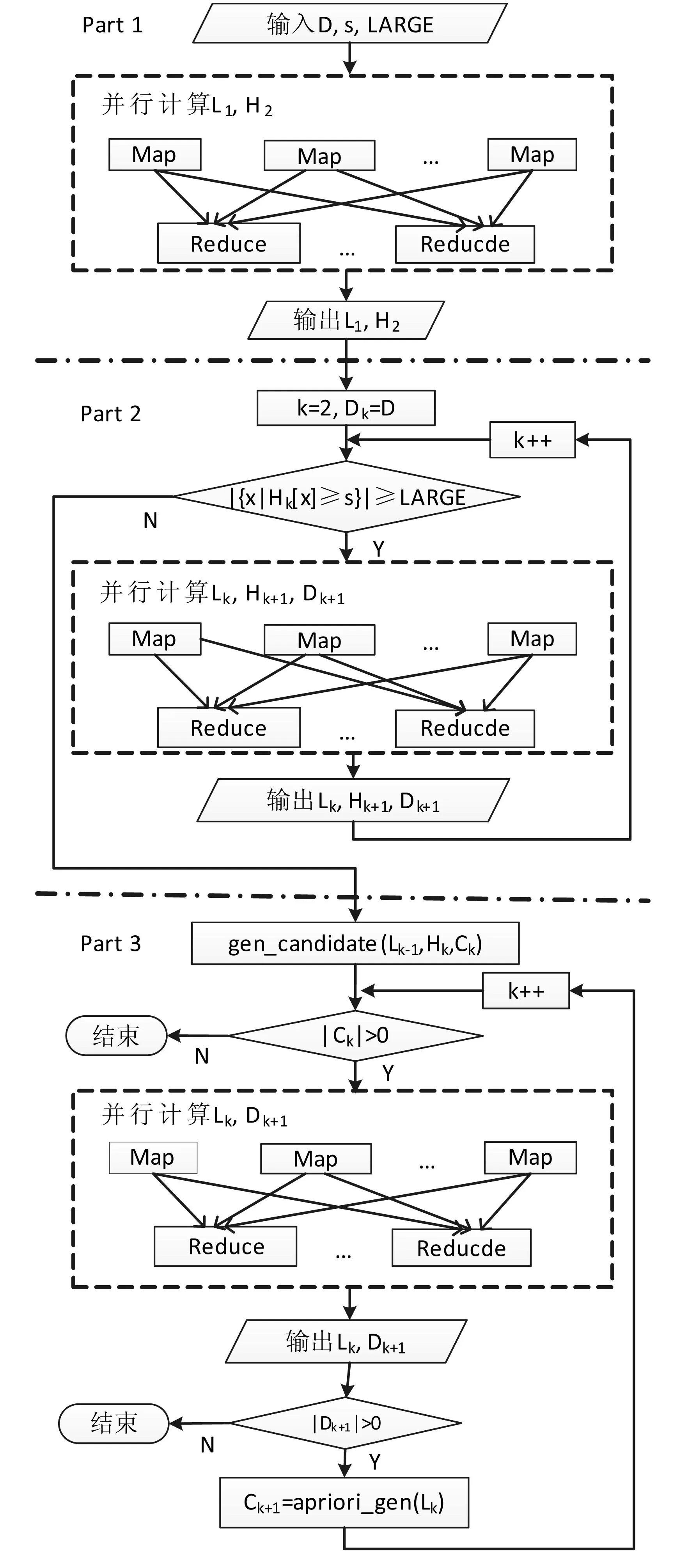
圖1 并行DHP算法流程圖
與DHP算法相對(duì)應(yīng),并行DHP算法也分為三部分。算法的流程控制由主函數(shù)實(shí)現(xiàn),各部分的并行計(jì)算由Map和Reduce函數(shù)實(shí)現(xiàn)。Map函數(shù)和Reduce函數(shù)描述如下:
Part1的Map函數(shù):
//TID是事務(wù)編號(hào),t是事務(wù)的項(xiàng)列表
map(key=TID,value=t){
foreach項(xiàng)ij∈t
output(
foreach2-項(xiàng)子集x∈t{
addr=h2(x);
//“*”是哈希地址addr的前綴字符
output(<*addr,1>);
}
}
Part1的Reduce函數(shù):
reduce(key=ij或key=*addr,values=list(1)){
count=0;
foreach1invalues
count++;
/* 輸出滿(mǎn)足條件的頻繁1-項(xiàng)集及支持度、
輸出哈希表的桶地址及計(jì)數(shù)值 */
if(count≥s)output(
}
Part2的Map函數(shù):
setup(){
//生成候選k-項(xiàng)集
gen_candidate(Lk-1,Hk,Ck);
Dk+1= ?;
}
map(key=TID,value=t){
foreacht的k-項(xiàng)子集c(=ti1...tik)
if(c∈Ck) {
output(
for(j=1;j≤k;j++)a[ij]++;
}
//刪除t中不必要的項(xiàng)
for(i=0,j=0;i<|t|;i++)


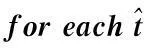
if(x的所有k-項(xiàng)子集y都滿(mǎn)足Hk[hk(y)]≥s){
addr=hk+1(x);
output(<*addr,1>);
for(j=1;j≤k+1;j++)a[ij]++;
}
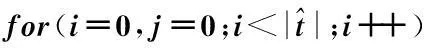

}
//刪除數(shù)據(jù)分片中不必要的事務(wù)
}
}
cleanup(){
在HDFS中創(chuàng)建一個(gè)目錄inputk+1;
將Dk+1分片保存在inputk+1目錄的一個(gè)文件中;
}
Part2的Reduce函數(shù):
reduce(key=c或key=*addr,values=list(1)){
count=0;
foreach1invalues
count++;
/* 輸出滿(mǎn)足條件的頻繁k-項(xiàng)集及支持度、
輸出哈希表的桶地址及計(jì)數(shù)值 */
if(count≥s)output(
}
Part3的Map函數(shù):
setup(){
讀取Ck;
Dk+1= ?;
}
map(key=TID,value=t){
foreacht的k-項(xiàng)子集c(=ti1...tik)
if(c∈Ck) {
output(
for(j=1;j≤k;j++)a[ij]++;
}
//刪除t中不必要的項(xiàng)
for(i=0,j=0;i<|t|;i++)

//刪除數(shù)據(jù)分片中不必要的事務(wù)
}
cleanup(){
在HDFS中創(chuàng)建一個(gè)目錄inputk+1;
將Dk+1分片保存在inputk+1目錄的一個(gè)文件中;
}
Part3的Reduce函數(shù):
reduce(key=c,values=list(1)){
count=0;
foreach1invalues
count++;
//輸出滿(mǎn)足條件的頻繁k-項(xiàng)集及支持度
if(count≥s)output(
}
3.2算法的實(shí)例分析
下面通過(guò)一個(gè)實(shí)例來(lái)說(shuō)明并行DHP算法的執(zhí)行過(guò)程,如圖2所示。

圖2 并行DHP算法執(zhí)行過(guò)程示例
在該實(shí)例中,使用文獻(xiàn)[1]給出的示例數(shù)據(jù)庫(kù)。假定Map、Reduce任務(wù)數(shù)各為2,選取s=2、LARGE=3,選取的Hash函數(shù)定義如下:
hk({i1,i2,…,ik})=((order(i1)+order(i2)+…+order(ik-1))×10+order(ik))modp

對(duì)于該實(shí)例,算法的執(zhí)行過(guò)程需要3個(gè)MapReduce任務(wù)去完成。第1個(gè)MapReduce任務(wù)執(zhí)行Part1的過(guò)程,得到L1和H2。由于條件 |{x|H2[x]≥s}|≥LARGE成立,第2個(gè)MapReduce任務(wù)執(zhí)行Part2的過(guò)程,得到L2、H3和D3。由于條件 |{x|H3[x]≥s}|≥LARGE不成立,第3個(gè)MapReduce任務(wù)執(zhí)行Part3的過(guò)程,得到L3和D4。由于|D4|=0,算法結(jié)束。
算法的執(zhí)行結(jié)果與文獻(xiàn)[1]的結(jié)果相同,可見(jiàn),本文設(shè)計(jì)的并行DHP算法是正確的。
4實(shí)驗(yàn)結(jié)果及分析
4.1實(shí)驗(yàn)環(huán)境與實(shí)驗(yàn)數(shù)據(jù)
實(shí)驗(yàn)環(huán)境是7臺(tái)配置相同的計(jì)算機(jī)組成的Hadoop集群,其中1臺(tái)作為JobTracker節(jié)點(diǎn),6臺(tái)作為T(mén)askTracker節(jié)點(diǎn)。計(jì)算機(jī)的配置是:雙核2.93GHzCPU、2GB內(nèi)存和100M網(wǎng)卡。使用的軟件是:Ubuntu12.04LTS、Hadoop1.2.1、JDK1.7.0_51。
使用Java語(yǔ)言實(shí)現(xiàn)了文獻(xiàn)[1]提出的DHP算法和本文設(shè)計(jì)的并行DHP算法,并對(duì)數(shù)據(jù)集進(jìn)行了3組實(shí)驗(yàn),分別測(cè)試算法的運(yùn)行時(shí)間、加速比和可擴(kuò)展性。實(shí)驗(yàn)選取的數(shù)據(jù)集來(lái)自網(wǎng)站http://fimi.ua.ac.be/data/。為了便于測(cè)試算法的可擴(kuò)展性,從數(shù)據(jù)集webdocs中分別隨機(jī)抽取1×105、2×105、3×105、4×105、5×105、6×105條記錄作為6個(gè)實(shí)驗(yàn)數(shù)據(jù)集。
4.2算法的運(yùn)行時(shí)間測(cè)試
使用4個(gè)數(shù)據(jù)集測(cè)試算法的運(yùn)行時(shí)間,retail、kosarak是稀疏型數(shù)據(jù)集,設(shè)置了較小的支持度閾值,accidents、pumsb是稠密型數(shù)據(jù)集,設(shè)置了較大的支持度閾值。為了便于與DHP算法比較,分別使用1個(gè)和2個(gè)TaskTracker節(jié)點(diǎn)測(cè)試并行DHP算法的運(yùn)行時(shí)間。實(shí)驗(yàn)結(jié)果如表1所示。

表1 DHP算法與并行DHP算法的執(zhí)行時(shí)間
從表1可以看出,使用1個(gè)TaskTracker節(jié)點(diǎn),并行DHP算法在4個(gè)數(shù)據(jù)集上的運(yùn)行時(shí)間都大于DHP算法;使用2個(gè)節(jié)點(diǎn),除retail之外,并行DHP算法在其余3個(gè)數(shù)據(jù)集上的運(yùn)行時(shí)間均小于DHP算法。retail是一個(gè)較小(4.2MB)的稀疏型數(shù)據(jù)集,對(duì)該數(shù)據(jù)集挖掘頻繁項(xiàng)集的計(jì)算時(shí)間較小。但是,并行DHP算法需要5個(gè)MapReduce任務(wù)才能完成對(duì)retail的數(shù)據(jù)處理,每個(gè)任務(wù)的初始化和啟動(dòng)所用的時(shí)間相對(duì)于計(jì)算時(shí)間有較大的比重,所以總的運(yùn)行時(shí)間要大于DHP算法。
由此可見(jiàn),并行DHP算法不適合對(duì)計(jì)算量小的數(shù)據(jù)集挖掘頻繁項(xiàng)集;對(duì)于計(jì)算規(guī)模較大的數(shù)據(jù)集,并行DHP算法顯著減少了挖掘頻繁項(xiàng)集的時(shí)間,提高了算法的執(zhí)行效率。
4.3算法的加速比測(cè)試
加速比是評(píng)價(jià)并行算法性能的重要指標(biāo)之一,文獻(xiàn)[11]給出了加速比的計(jì)算公式,定義如下:
Sp=t1/tp
(1)
其中,t1、tp分別表示在1個(gè)節(jié)點(diǎn)和p個(gè)節(jié)點(diǎn)上的執(zhí)行時(shí)間。
使用表1列出的4個(gè)數(shù)據(jù)集和最小支持度測(cè)試并行DHP算法的加速比,實(shí)驗(yàn)結(jié)果如圖3所示。從圖3可以看出,對(duì)于計(jì)算規(guī)模較小的數(shù)據(jù)集retail和kosarak,算法表現(xiàn)出很低的加速比,這是因?yàn)殡S著計(jì)算節(jié)點(diǎn)數(shù)的增加,在節(jié)點(diǎn)之間的通信開(kāi)銷(xiāo)相對(duì)于計(jì)算時(shí)間的比重顯著增大,不能取得較好的加速比;對(duì)于計(jì)算規(guī)模較大的數(shù)據(jù)集accidents和pumsb,算法取得了較好的加速比。
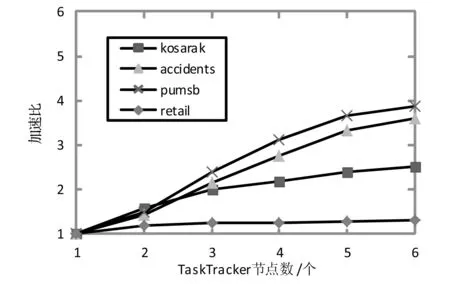
圖3 并行DHP算法的加速比
4.4算法的可擴(kuò)展性測(cè)試
可擴(kuò)展性是指算法能否隨節(jié)點(diǎn)數(shù)的增加而按比例提高。文獻(xiàn)[12]給出了等速度可擴(kuò)展性的計(jì)算公式,定義如下:
(2)
其中,w、p是問(wèn)題規(guī)模和處理機(jī)規(guī)模,w′、p′是擴(kuò)展后的問(wèn)題規(guī)模和處理機(jī)規(guī)模。
對(duì)從webdocs中隨機(jī)抽取的6個(gè)數(shù)據(jù)集(數(shù)據(jù)規(guī)模成倍增加)進(jìn)行可擴(kuò)展性測(cè)試,實(shí)驗(yàn)結(jié)果如圖4所示。實(shí)驗(yàn)結(jié)果表明,對(duì)于兩種不同的最小支持度,并行DHP算法都能取得較好的可擴(kuò)展性。

圖4 并行DHP算法的可擴(kuò)展性
5結(jié)語(yǔ)
DHP算法是一種經(jīng)典的關(guān)聯(lián)規(guī)則挖掘算法,受單機(jī)計(jì)算能力和內(nèi)存的限制,DHP算法對(duì)大數(shù)據(jù)挖掘頻繁項(xiàng)集存在執(zhí)行時(shí)間過(guò)長(zhǎng)、效率不高的問(wèn)題。針對(duì)該問(wèn)題,本文根據(jù)Hadoop平臺(tái)的MapReduce并行編程模型對(duì)DHP算法的并行化策略進(jìn)行了研究,設(shè)計(jì)了一種基于MapReduce模型的并行DHP算法,通過(guò)實(shí)例分析了算法的執(zhí)行過(guò)程和正確性。與DHP算法相比,本文設(shè)計(jì)的并行算法利用了Hadoop集群強(qiáng)大的計(jì)算能力,縮短了對(duì)大數(shù)據(jù)集挖掘頻繁項(xiàng)集的時(shí)間,具有較高的執(zhí)行效率。在多個(gè)數(shù)據(jù)集上對(duì)算法進(jìn)行了測(cè)試,實(shí)驗(yàn)結(jié)果表明:并行DHP算法對(duì)大數(shù)據(jù)集具有較好的加速比和可擴(kuò)展性。
參考文獻(xiàn)
[1]ParkJS,ChenMS,YuPS.Aneffectivehash-basedalgorithmforminingassociationrules[C]//Proceedingsofthe1995ACMSIGMODInternationalConferenceonManagementofData.NewYork:ACM,1995,24(2):175-186.
[2]AgrawalR,SrikantR.Fastalgorithmsforminingassociationrules[C]//Proceedingsofthe20thInternationalConferenceonVeryLargeDataBases.Santiago,Chile,1994:487-499.
[3]HoltJD,ChungSM.Efficientminingofassociationrulesintextdatabases[C]//ProceedingsoftheEighthInternationalConferenceonInformationandKnowledgeManagement.NewYork:ACM,1999:234-242.
[4] 王濤偉,周必水.基于DHP的頻繁遍歷路徑挖掘算法[J].杭州電子科技大學(xué)學(xué)報(bào),2005,25(5):60-63.
[5]ArmbrustM,FoxA,GriffithR,etal.Abovetheclouds:aBerkeleyviewofcloudcomputing[R/OL].2009-02-10[2015-02-15].http://www.eecs.berkeley.edu/Pubs/TechRpts/2009/EECS-2009-28.html.
[6] 周麗娟,王翔.云環(huán)境下關(guān)聯(lián)規(guī)則算法的研究[J].計(jì)算機(jī)工程與設(shè)計(jì),2014,35(2):499-503.
[7]DeanJ,GhemawatS.MapReduce:simplifieddataprocessingonlargeclusters[J].CommunicationsoftheACM,2008,51(1):107-113.
[8] 李建江,崔健,王聃,等.MapReduce并行編程模型研究綜述[J].電子學(xué)報(bào),2011,39(11):2635-2642.
[9]TheApacheSoftwareFoundation.Hadoop[EB/OL].2014-12-12[2015-02-15].http://hadoop.apache.org/.
[10] 黃立勤,柳燕煌.基于MapReduce并行的Apriori算法改進(jìn)研究[J].福州大學(xué)學(xué)報(bào)(自然科學(xué)版),2011,39(5):680-685.
[11] 陳興蜀,張帥,童浩,等.基于布爾矩陣和MapReduce的FP-Growth算法[J].華南理工大學(xué)學(xué)報(bào)(自然科學(xué)版),2014,42(1):135-141.
[12] 陳軍,莫?jiǎng)t堯,李曉梅,等.大規(guī)模并行應(yīng)用程序的可擴(kuò)展性研究[J].計(jì)算機(jī)研究與發(fā)展,2000,37(11):1382-1388.
RESEARCH ON PARALLELISATION OF DHP ALGORITHM BASED ON MAPREDUCE
Zhou GuojunWu Qingjun
(School of Mathematics and Information Science,Yulin Normal University,Yulin 537000,Guangxi,China)
AbstractDHP algorithm is confronted with the problems in association rules mining for big data such as long execution time and low efficiency,etc.In order to solve the problems,we studied the parallelisation strategy of DHP algorithm.According to MapReduce parallel programming model of cloud computing platform Hadoop,we designed a parallel DHP algorithm,presented the overall flow of the algorithm and the algorithm descriptions of Map function and Reduce function.Compared with DHP algorithm,the parallel DHP algorithm makes use of the powerful computing capacity of Hadoop cluster,improves the efficiency of mining association rules from big data.We analysed the execution process of parallel DHP algorithm by example,and carried out experiments on a couple of datasets.Experimental results showed that the parallel DHP algorithm has good speedup and scalability on big data.
KeywordsMapReduceHadoopDHP algorithmAssociation rules
收稿日期:2015-03-03。廣西高校科學(xué)技術(shù)研究立項(xiàng)項(xiàng)目(LX20 14300)。周?chē)?guó)軍,講師,主研領(lǐng)域:數(shù)據(jù)挖掘,云計(jì)算。吳慶軍,副教授。
中圖分類(lèi)號(hào)TP311.1
文獻(xiàn)標(biāo)識(shí)碼A
DOI:10.3969/j.issn.1000-386x.2016.06.012
