一種復雜版面扭曲文檔圖像快速校正方法
2016-07-19 02:07:22曾凡鋒段漾波
計算機應用與軟件 2016年6期
曾凡鋒 段漾波
(北方工業大學計算機學院 北京 100144)
?
一種復雜版面扭曲文檔圖像快速校正方法
曾凡鋒段漾波
(北方工業大學計算機學院北京 100144)
摘要在對復雜版面扭曲文檔圖像進行OCR識別時,識別率較低。針對這類文檔圖像提出一種基于形態學文本行定位的扭曲校正方法。首先根據形態學特征在復雜版面中定位文本行,區分處理文字區域和非文字區域,利用文本行信息提取文本線;再以文本線為基準利用窗口掃描法進行文字行校正,最終重構圖像。實驗結果表明,該方法校正效果明顯,對于復雜版面的扭曲文檔圖像有較好的校正效果,校正后識別率大幅度提高。
關鍵詞復雜版面扭曲文檔形態學組件窗口掃描校正
0引言
在圖像的采集過程中,由于受到紙質文檔自身幾何形狀和拍攝角度的影響,采集到的圖像可能發生扭曲,而文檔圖像的扭曲將嚴重影響到OCR識別的效果。當文檔圖像是圖文混排等復雜版面的情況時,將進一步影響到OCR識別。這就需要對復雜版面文檔圖像進行有效的校正。近年來,國內外對扭曲圖像校正技術的研究在日趨增加,但目前大部分的研究主要針對于純文本的圖像,對圖文混排類的復雜版面文檔圖像的扭曲校正研究較少。對純文本扭曲圖像的校正方法主要分為基于3D模型的校正技術和基于2D的圖像處理技術,其中基于2D的校正技術有很好的實用性和易推廣性。基于2D的校正技術主要包括:1) 基于連通域的處理[1-3],這種方法有很好的校正效果,然而由于處理精度較高,對復雜版面敏感度較高,校正效率有待進一步提高。2) 基于文本線的處理[4,5],這類方法要很高的校正效率,但由于是從整體文本行入手,因此校正精度有細節上的損失,且對復雜版面的文檔圖像同樣不適用。3) 基于模型的校正方法,該方法可以對含有表格等非文字的文檔圖像進行檢測校正,但其校正粒度較為粗糙,效果欠佳。
通過以上分析總結,各種校正方法各有特點,但應用到復雜版面文檔圖像時都不易獲得理想的校正效果,其原因在于復雜版面中的非文字元素影響了各種校正方法中的處理步驟。因此如何在復雜版面上進行有效的校正成為關鍵所在。本文針對復雜版面的扭曲文檔圖像提出一種基于組件分析的文本線校正方法,實現了對圖像中的文字區域和非文字區域的有效區分,進而精準定位扭曲文本行,最后基于窗口掃描的方法以文本線為基準校正圖像。該方法解決了對復雜版面扭曲圖像的有效校正,并兼顧效率與校正精度。
1復雜版面扭曲文檔圖像特征及校正分析
在獲取圖像的過程中,相機位置及書籍的擺放,都可能使獲得的圖像發生扭曲,如圖1所示。

圖1 復雜版面扭曲文檔示意圖
在純文本文檔圖像扭曲的情況下,識別率將會大大降低;而在復雜版面的扭曲的情況下,識別率將進一步降低,甚至無法識別。在這種情況下,文字和非文字混合排入圖像中,對扭曲圖像的處理難度將進一步增加。文獻[6]在提出一種基于連通域的提取文檔圖像中的復選框組件的方法,但無法對文檔圖像中的圖像元素進行處理。在對文本行進行扭曲校正之前,必須排除非文字區域的影響。為了提高識別精度,最終也需要剔除非文字區域,保留純文本。這是本文所選用的處理思想。
2基于組件分析的扭曲校正算法
對于復雜版面扭曲文檔圖像,扭曲校正的重點是文本行的定位。本文就此提出一種基于形態學組件分析的校正方法。算法實現均采用C++編程語言。解決方案流程如圖2所示。
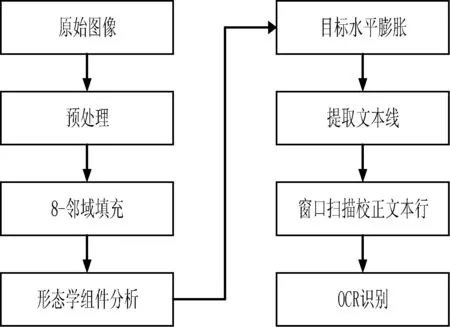
圖2 本文解決方案流程圖
2.1圖像預處理
圖像預處理包括兩個步驟:灰度化和二值化。灰度化是將具有R,G,B分量的真彩色圖像轉換為灰度圖像。具體轉換規則采用以下公式:
I=0.11R+0.59G+0.3B
(1)
灰度化處理后需要將圖像轉為二值圖像,即只包括背景色和前景色的圖像。傳統的二值化方法較多,如雙峰法、大津法(OTSU)、Niblack法等。由于在光照均勻的情況下大津法可以很好地處理本文的研究圖像,得到效果較好的二值圖像,因此本文在研究中選用大津法進行處理。預處理后的圖像如圖3所示。

圖3 二值化
2.28-鄰域填充目標像素
對目標像素進行8-鄰域填充是為了更好地進行形態學組件分析[7]。由于文字筆畫有的地方較細,有可能出現斷筆等情況,在進行形態學分析時可能導致精確度不高。而8-鄰域填充可以使文字變得更飽滿,充實筆畫,提高形態學組件分析的精確度。
目標像素的8-鄰域示意如圖4所示。
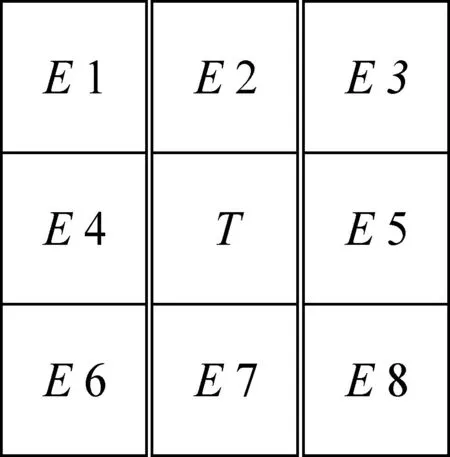
圖4 8-鄰域像素圖
具體填充規則如下:
(1) 對任意一個目標像素點T,掃描其8-鄰域的像素值,分別記為E1,E2,E3,E4,E5,E6,E7,E8。
(2) 由式(2)判斷其鄰域內是否有空白列或行。
α=(E1&&E2&&E3)‖(E3&&E5&&E8)‖(E6&&E7&&E8)
(2)
若α為1,則目標像素為外部點,不予處理;若α為0,則為內部點,對其8-鄰域像素進行置黑操作。
(3) 判斷若無置黑操作則退出,否則重復(1)、(2)。
8-鄰域填充的局部效果如圖5所示。

圖5 8-鄰域填充效果
2.3形態學組件分析
對于圖像的版面分析,文獻[8]提出了一種基于K-means的聚類分析算法,通過對圖像像素進行聚類分析將圖像內容分類。但是,這種方法的效率有限,在處理文字圖像時體現不出其優越性,因此本文在版面分析算法上主要參考基于形態學組件的分析方法。
形態學組件分析的目的在于區分出圖像中的文字行區域和非文字區域。采用以下步驟進行組件分析:
(1) 掃描圖像,統計圖像中的基本元素。
(2) 根據各元素的形態學特征區分為不同的組件。
(3) 提取文本行組件,并對其進行去噪修正。
由于在復雜版面的文檔圖像的識別中,關鍵在于定位文本區域信息。區分文字區域和非文字區域只要考慮各個組件的形態學特征即可[9,10]。因此,在掃描完圖像得到圖像各個組件后,分別計算其形態學特征,本文主要采用計算各組件的形態學高度和寬度來區分區域。計算規則如下:
用C表示組件元素集合:
C={c1,c2,c3,…,cn}
在編程實現中,首先定義結構體Component,用來保存各個組件的信息。結構體中包含組件的寬度、高度以及編號信息。統計每個組件的形態學寬度和高度,分別用集合H和W表示:
H={h1,h2,h3,…,hn}
W={w1,w2,w3,…,wn}
并由式(3)、式(4)計算組件的平均高度和平均寬度:
(3)
(4)
由經驗值可知計算出來的平均高度可以視為文檔圖像中文本行組件的近似平均高度。所以,在所有組件元素中,其形態學特征明顯不同于平均特征的組件被視為非文字行組件。對這些組件進行標注。對于文本行組件則進行編號記錄,并存儲這些文本行組件的坐標信息。本文采用一種基于組件邊界屬性的合并方法[9]。具體步驟如下:
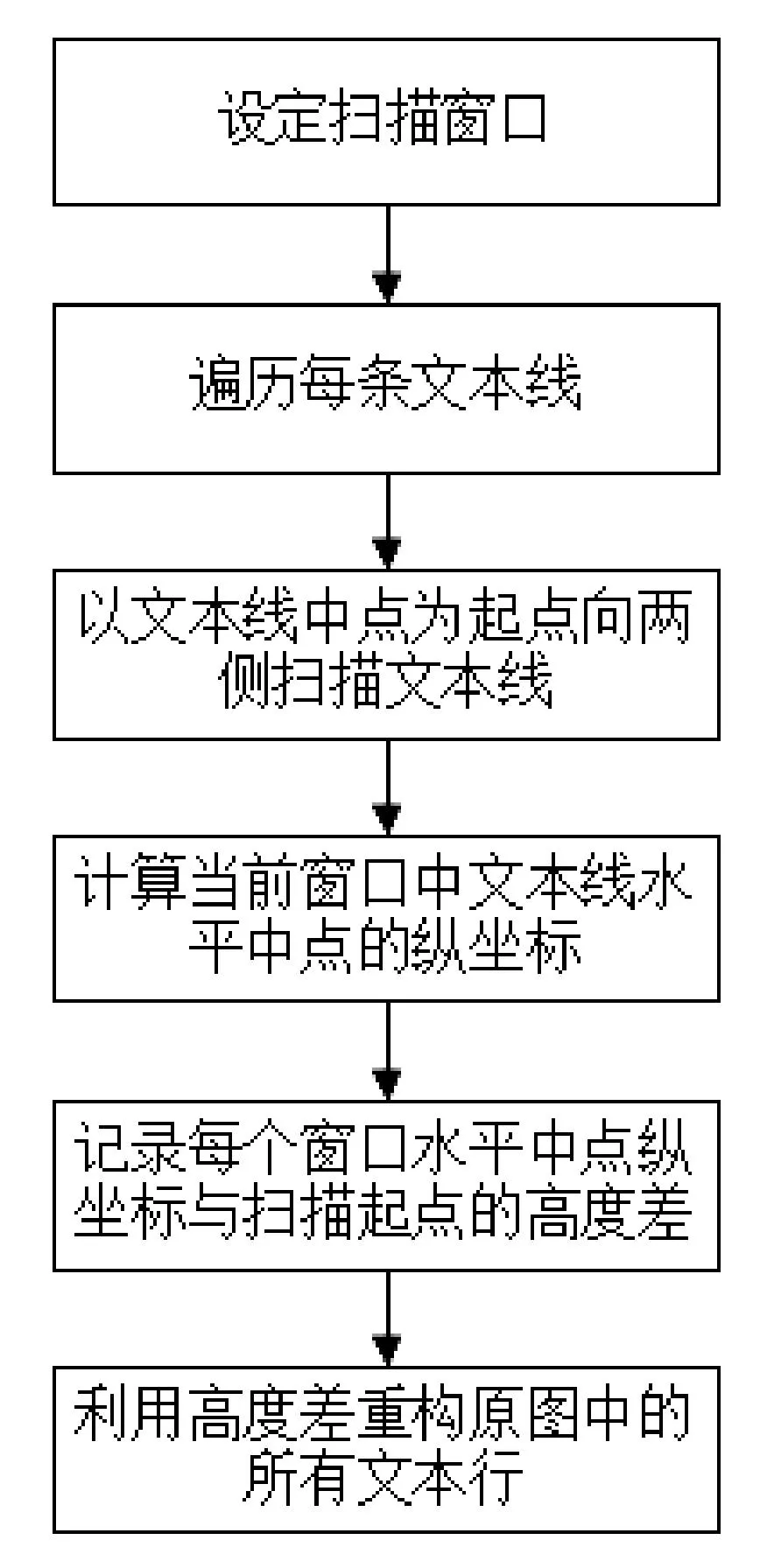
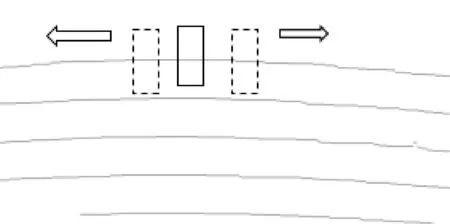
第一步由組件分析的結果將文字組件按照以下規則合并文本行組件;
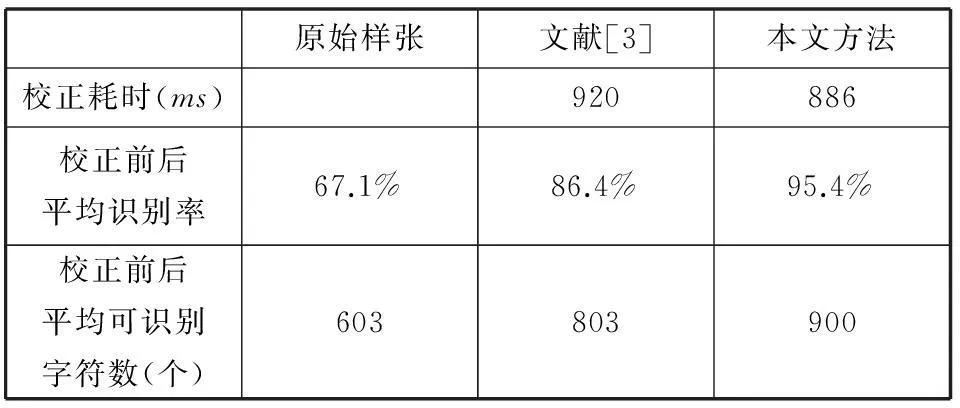
用left,right,top,bottom,width,height分別表示組件的左右上下邊界如果max(right1,right2)-min(left1,left2) left=min(left1 ,left2) right=max(right1 ,right2) top=min(top1 ,top2) bottom=max(bottom1 ,bottom2) 組件合并之后的初始狀態下, 各文字組件都處于屬性未定狀態。修正文本行組件的過程就是采用一種漸近的過程, 首先,根據組件的寬度和高度形態學特征,區分為文字和非文字;然后,把屬性已經統計為文字的各組件按照它們的間距從小到大的順序加以逐步合并。在這一合并過程中, 只有屬性未定組件將被處理。該過程最終將各個文字組件合并成為文本行。 第二步對文本行組件進行修正,對于不連續的文本行進行不同編號標記。 對上一步中合并出來的文本行進行水平膨脹,這樣處理的目的是為了快速統計各個文本行,并對各個文本行進行編號。 第三步記錄所有文本行位置信息。 利用上一步中水平膨脹后的文本行可以準確地標記各個文本行在圖像中的坐標位置。對所有文本行進行標記,以進行下一步處理。 2.4提取文本線 組件分析完成后,由于對非文本元素進行了標注,因此,可以對文本行組件進行文本線的提取。具體的提取方法為:提取每個文字行組件的中心點,將這些中心點組成文本線,保存這些文本線的坐標信息。 提取文本線的效果如圖6所示。 圖6 提取文本線 2.5窗口掃描校正 圖7 窗口掃描校正流程圖 已有的文獻的研究方法中,一種校正方法是先對文本線進行擬合,再進行幾何變換來重構文本行;另一種方法是先將文字切分,再通過移動單個文字到正確位置來重構文本行。本文提出一種兼顧兩種方法優點的重構文本行方法,即以適當大小的窗口為單位掃描文本線,對目標像素進行位置變換,來達到重構文本行。本方法相比于完全的文本線擬合重構方法提高了效率,相比于以文字為單位重構方法又可以更好地保留文本行細節。 利用已經獲得的文本行平均高度,以及文本線位置信息,以文本線為基準,以一定大小的窗口對文本行進行扭曲校正。窗口掃描的程序流程如圖7所示。 第一步設定掃描窗口大小,對于文檔圖像來說,其中的文本信息除去標題等少數特殊文本之外,其余文本的特征基本統一。所以,在設定掃描窗口大小時可以以文本行的平均高度為參照。本文選定的窗口大小遵照以下規則: 用window_H表示窗口高度,用window_W表示窗口寬度,其大小分別按式(5)、式(6): (5) (6) 第二步選取每條文本線的中點作為掃描起點,首先記錄掃描起點的高度坐標,分別向左向右移動窗口,每移動一次,記錄此次窗口內文本線中點的高度,并計算其與掃描起點的高度差,記此高度差為windowGap,然后對于每一條文本線設置一個保存高度差的數組Height_Gapn(n為文本線編號),將每個窗口相應的高度差windowGap記錄在這個數組中。掃描過程如圖8所示。 圖8 窗口掃描 第三步根據高度差數組中的數據文本行進行重構。在經過組件分析后的圖像中,文本行已經定位,因此在這一步中,對于每一條文本行,利用掃描文本線所得出的高度差結果,同樣從文本行的中點處開始向兩邊分別移動窗口,在窗口內的目標像素統一移動其相應的窗口高度差windowGap,直至掃描移動完成當前文本行。對每一條文本行執行上述過程,直至全部文本行完成。這時,圖像的所有文本行已經完成校正。其校正效果如圖9所示。 圖9 文本行重構效果 3方法測試及實驗結果分析 3.1測試環境 本實驗在VS2005開發環境下采用C++語言實現。測試環境為:Inter(R)Core(TM) 2DuoCPUE7400 @2.80GHz;內存2GB;操作系統為Windows7。實驗樣張取自16開普通中文書本,共對100張樣張進行測試。拍攝攝像頭像素為500W像素。使用漢王OCR文字識別軟件進行文字識別。 圖像的獲取均在光照均勻的環境下進行,本文校正方法忽略噪聲的干擾。圖像數據為:24位真彩圖像,大小為1944×2592像素。本文算法主要是針對橫排的文檔圖像進行研究的,圖像的版面特征主要是文檔圖像中混入了圖像,簡單圖形(如線條)以及表格線等非文字元素,對這些文檔圖像均能進行有效的扭曲校正。對于任意復雜的版面,本文方法還不能有效處理,有待改進。 3.2校正效果對比 實驗結果如圖10所示, 圖10為文獻[3]方法校正結果,圖11為本文方法校正結果。可以看出,對于復雜版面的文檔圖像,文獻[3]的校正效果明顯較差,不但沒有排除非文字元素的干擾,而且有的文字行已經損失,識別率也會因此大大降低。而本文的算法進行校正的效果明顯,且已經剔除非文本元素的干擾,這樣可以較高地提升識別率。相比于文獻[11,12]中所提出的相應校正算法,較之本文提出的算法都有明顯不足。在所有進行測試的樣張中,只有3張的校正效果不是很理想,其余的樣張在校正后不論是可識別字符數還是識別率都有大幅度提升,其中識別率可達95%以上。對實驗結果進行統計分析,其結果如表1所示。 圖10 文獻[3]校正效果 圖11 本文校正效果 原始樣張文獻[3]本文方法校正耗時(ms)920886校正前后平均識別率67.1%86.4%95.4%校正前后平均可識別字符數(個)603803900 由于本文所提的方法首先需要對文檔的版面進行分析以確定文本行,所以相對于已有的基于文本線擬合的方法在時間效率上的提升并不是很明顯,但是在校正精確度和校正后識別率以及可識別字符數上都有明顯優勢。對于這種復雜版面的文檔圖像大多數已有的校正方法的校正效果很差,甚至無法校正。本文方法相比于基于連通域文字分割的校正方法就有著較為明顯的效率優勢。其中所測試的樣張中平均識別率可以達到95%以上,而可識別字符也比其他方法明顯多出。同時本文方法有較強的魯棒性,對于不同的復雜版面都能有較好的校正效果。 4結語 本文針對復雜版面扭曲文檔圖像進行研究,提出基于組件 的窗口掃描校正方法。首先通過形態學特征對文檔內容進行組件分析,確定文本行;然后提取文本線,最后以文本線為基準,以適當大小窗口掃描校正文本行。該方法能在900毫秒內校正1944×2592像素的圖像,而且校正效果良好,其校正后的OCR識別率可以達到95%以上。經過進一步測試,對于復雜版面的英文文檔圖像也可以準確進行校正。本文方法在本實驗室開發的智能閱讀機進行了應用,無需人工干涉的情況下已能實現復雜版面扭曲文檔圖像的快速校正,校正后的實時識別率能達到95%。因此,本文提出的方法可以推廣到實時文字圖像識別系統中進行應用。 參考文獻 [1]LiuHong,YeLu.AmethodrestoreChinesewarpeddocumentimagesbasedonbindingcharactersandbuildingcurvedlines[C]//InternationalConferenceonSystems,ManandCybernetics:ICSMC2009:2009:989-993. [2]LiZhang,YipAndyM,BrownMichaelS,etal.Aunifiedframeworkfordocumentrestorationusinginpaintingandshape-from-shading[J].PatternRecognition,2009,42(11):2961-2978. [3] 宋麗麗,吳亞東,孫波.改進的文檔圖像扭曲校正方法[J].計算機工程,2011,37(1):204-206. [4] 張偉業,趙群飛.讀書機器人的版面分析及文字圖像預處理算法[J].微型電腦應用,2011,27(1):58-61. [5]LiuHong,DingRunwei.InternationalConferenceonSystemsManandCybernetics[C]//ICSMC2009:RestoringChinesewarpeddocumentimagesbasedontextboundarylines,2009. [6]ZhangShengnan,YuanShanlei,NiuLianqiang.AutomaticRecognitionMethodforCheckboxinDataFormImage[C]//SixthInternationalConferenceonMeasuringTechnologyandMechatronicsAutomation,2014:159-162. [7] 于明,郭僉,王棟壯.改進的基于連通域的版面分割方法[J].計算機工程與應用,2013,49(17):195-198. [8]HamedBehin,AfshinEbrahimi,SepidehEbrahimi.IncorporatedPreprocessingandPhysicalLayoutAnalysisofaBinaryDocumentImageUsingaTwoStageClassification[C]//InternationalConferenceonComputerandCommunicationEngineering:ICCCE2010:2010. [9] 付蘆靜,錢軍浩,鐘云飛.基于漢字聯通分量的印刷圖像版面分割方法[J/OL].計算機工程與應用,2013,49(3):4[2013-07-31].http://www.cnki.net/kems/detail/11.2127.TP.20130731.1817.001.html. [10] 石蒙蒙.基于結構化局部邊緣模式的文檔圖像分類[J].廈門大學學報,2013,52(3):349-355. [11]AmirRezaGhods,SaeedMozaffari,FarhadAhmadpanahi.DocumentImageDewarpingusingKinectDepthSensor[C]//21stIranianConference,ElectricalEngineering:ICEE2013:2014:1-6. [12]TongLijing,ZhangGuoliang,PengQuanyao,etal.Warpeddocumentimagemosaicingmethodbasedoninflectionpointdetectionandregistration,InternationalConferenceonMultimediaInformationNetworkingandSecurityMINES2012:November2-4,2012[C]//Nanjing,2012:306-310. A FAST CORRECTION METHOD FOR WARPED DOCUMENT IMAGESINCOMPLEXLAYOUT Zeng FanfengDuan Yangbo (College of Computer,North China University of Technology,Beijing 100144,China) AbstractThe recognition rate of OCR (optical character recognition) on warped document images in complex layout is relatively low. To solve this problem, we proposed a morphology-based warp correction method with rows of text positioning. First, according the morphological characteristics it locates the rows of text in complex layout to distinguish the text areas from other areas. After that it uses the rows of text information to extract the text lines, and then uses the text lines as the benchmark, employs the window scanning method to correct the rows of text, and finally reconstructs the image. Experimental results demonstrated that this method achieved manifest correction effect. For warped document images in complex layout it gained acceptable correction results, the recognition rate improved significantly after the correction. KeywordsComplex layoutWarped documentMorphologic componentWindows scanning correction 收稿日期:2015-01-08。國家自然科學基金項目(61371142);北京市自然科學基金項目(4132026)。曾凡鋒,副研究員,主研領域:圖像處理,智能識別,系統辨識。段漾波,碩士生。 中圖分類號TP391 文獻標識碼A DOI:10.3969/j.issn.1000-386x.2016.06.042


猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
兒童故事畫報(2019年5期)2019-05-26 14:26:14
電子制作(2018年18期)2018-11-14 01:48:06
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
