基于智能手機的維吾爾語語音控制系統的開發
2016-07-19 02:07:24米爾阿迪力江麥麥提吾守爾斯拉木努爾麥麥提尤魯瓦斯
計算機應用與軟件 2016年6期
米爾阿迪力江·麥麥提 吾守爾·斯拉木,2 努爾麥麥提·尤魯瓦斯,2
熱依曼·吐爾遜1,2 艾尼宛爾·托乎提21(新疆大學信息科學與工程學院 新疆 烏魯木齊 830046)2(新疆大學新疆多語種信息技術重點實驗室 新疆 烏魯木齊 830046)
?
基于智能手機的維吾爾語語音控制系統的開發
米爾阿迪力江·麥麥提1吾守爾·斯拉木1,2努爾麥麥提·尤魯瓦斯1,2
熱依曼·吐爾遜1,2艾尼宛爾·托乎提21(新疆大學信息科學與工程學院新疆 烏魯木齊 830046)2(新疆大學新疆多語種信息技術重點實驗室新疆 烏魯木齊 830046)
摘要以實現維吾爾語命令詞識別為目的,重點研究維吾爾語命令詞識別系統在Android平臺下的開發與實現過程,介紹系統開發難點、核心技術及系統典型的幾個功能。系統主要由Android開發包、Eclipse集成開發環境和API接口進行開發,并且通過自動選型規則來實現維漢英多種文字的正確顯示及處理等問題,針對廣大用戶的不同說話方式,重新構建維吾爾語語音語法文件,解決各地不同方言問題。在一般實驗室環境下做實驗得到了90.56%的正確識別率和85.00%的成功執行率等測試結果,表明維吾爾語非特定人命令詞識別研究中語法文件的結構及構建對系統有不同的影響。
關鍵詞Android平臺維吾爾語關鍵詞識別槽語法命令詞識別
0引言
近幾年在新疆使用智能手機的用戶越來越多,它將成為人們獲取信息的主要設備,因此基于手機的應用軟件愈來愈受到人們的關注和重視。目前Android技術是一個先進的、具有高人氣的技術,它還是一個開放性移動設備綜合平臺[1]。
我國是一個多民族的國家,新疆是個多民族地區之一[2],Android平臺的維吾爾語手機語音控制軟件一直以來都是少數民族市場上的空白。在國外,關鍵詞識別的研究初始于20世紀70年代,那時此研究序幕由Bridle[3]揭開的只稱“給定詞”識別,當時沒有使用語法或詞法信息,而是利用信號的LPC表示連續語音中的關鍵詞進行了檢測和定位。到80年代,Myers等人[4]利用基于DTW的局部最小算法來對關鍵詞識別和連接詞識別進行研究。90年代MIT、CMU和Dragon、Toshiba和IBM等公司就對KWS的研究得到了進一步發展,國外已經進入了高潮,但是國內研究歷史并不久。國內利用基于音節的一種漢語無限制語音流的關鍵詞識別系統,采用了獨特的統計拒識方法[5]。科大訊飛作為國內和國際語音技術產業的領導者,國內語音技術及中文關鍵詞識別、命令詞識別技術進入了更高的一層。國內外連續語音識別及關鍵詞識別技術取得了一定的成就,市場上也出現了一些應用產品,可是我國少數民族對關鍵詞識別技術的研究與開發正處在初期階段。
本文利用維吾爾語朗讀式的語料訓練而得到的聲學模型作為本文命令詞識別系統的聲學模型,然后基于規則的方式,建立了槽語法文件。此文件由15個槽(slot) 和三個語法規則(
1軟件總體架構及設計
1.1系統層次結構
本系統的設計首先通過對用戶的需求進行一系列的調查與分析,最終明確了該系統的使用對象及其功能。即本軟件的主要任務是在方便、有效的原則上為廣大維吾爾族群眾用戶提供一個維吾爾語語音控制平臺,本系統的總功能劃分如圖1所示。

圖1 系統總功能結構圖
從圖1所示可知,此軟件主要是由如下11個主模塊組成:打電話、發短信、打開應用、網絡導航、播放音樂、活動提醒、獲取考試信息、獲取新聞、天氣查詢、地圖查詢模塊及軟件附加模塊等。
1.2系統設計
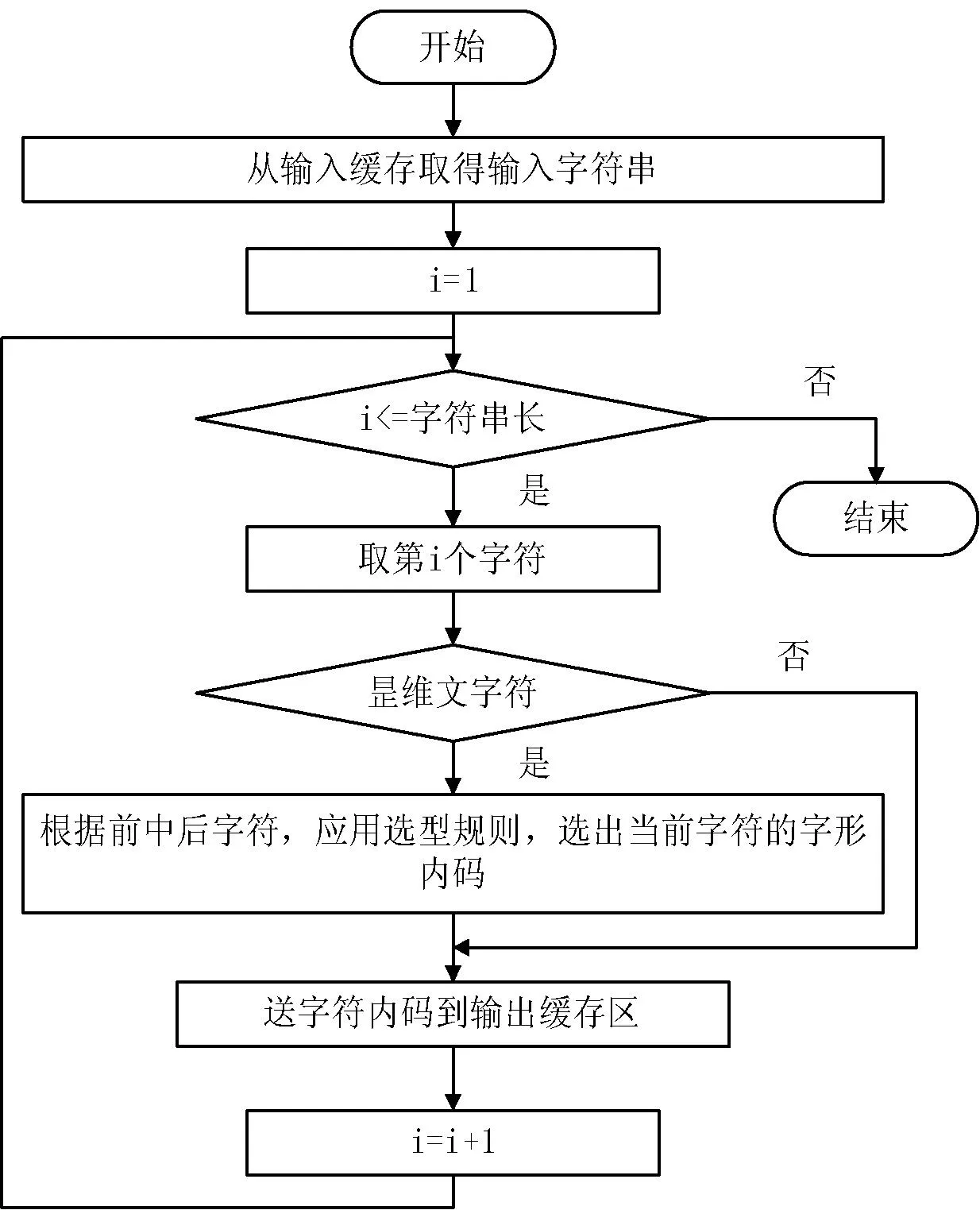
圖2 輸入處理模塊流程圖
系統開發中利用Android的API函數接口,同時引用科大訊飛公司研究院所提供的安卓底層語音處理API接口和它所包含的AitalkRecognizer類的類方法getInstance( )和調用創建語音識別引擎的createAitalkEngine( )方法等核心方法。軟件啟動之前通過sdCard.getAbsolutePath( )必須獲取用戶SD卡的絕對路徑,然后在用戶的SD卡上通過File( )類在此絕對路徑上創建一個"MyFiles"文件夾,再將我們預先準備的語法文件(grammar.bnf)放入到絕對路徑上。對此語法文件進行動態修改,并將最初需要對用戶說的維吾爾文通過UygToLat()方法來轉換為拉丁文,并以拉丁文來進行后續操作,運行流程如圖2所示。
2難點及核心技術
2.1維吾爾文處理
Android手機不支持從右向左的文字輸入方向和系統輸入法,為維吾爾文輸入及處理帶來一定的難度。維文字母與漢英文的不同,其特點主要表現在: 1) 書寫方向相反。漢字和西文是從左到右, 而維文是從右到左; 2) 維吾爾文字母根據在單詞中的位置不同會有四種變形; 3) 每個界面按鈕和文本標簽都是維吾爾文,命令都是普遍的維吾爾的標準詞匯。系統中主要是用自動選型處理和字母序列轉換函數來處理維吾爾文的正常顯示和處理方式(如圖3所示)。圖中i為當前需要選形的字母,i-1是當前字母前面的字符,i+1是當前字母后面的字符,設定i-1、i、i+1字符值為0(特殊字母或非維文字母)或1( 普通字母) ,當i-1、i、i+1字符值為不同的值時,i字符選形也不同。即使用戶手機沒裝維文字體和輸入法,該軟件也能有效解決處理。
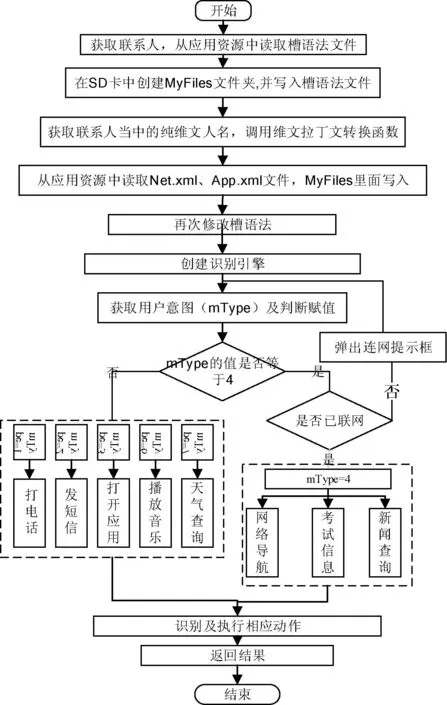
圖3 系統總流程圖
2.2語音關鍵詞識別技術
在維吾爾語關鍵詞識別系統中如何理解用戶的意圖是一個非常棘手的問題。本系統先利用已經準備好的語料庫進行前段處理、訓練,從而建立聲學模型;再規定語法文件,通過網絡化結構的轉換,得到語言模型;為了得到識別結果,依據已建好的聲學模型和語言模型,利用一定的搜索算法,對輸入的測試數據進行搜索匹配,再給出最終結果。關鍵詞識別系統主要有隱馬爾可夫模型(HMM),動態時間歸正技術(DTW)和人工神經元網絡(ANN)等模式匹配方法[8]。因此本實驗也利用了應用最廣泛、最成功的基于統計模型的HMM搜索匹配法[9]。
2.3槽語法
語法文件的創建在本系統開發過程中起著至關重要的核心作用。本文采用的是基于巴克斯范式BNF(Backus-NaurForm)的槽語法(SlotGrammar)[10]。將系統設定為只接受該語法約束下的信息查詢語句,卻略去無關信息,從而提高系統的性能和效率。一般槽語法中,槽的個數不能太多,因為當槽的個數太多,且也有嵌套層級的情況時,將會導致產生的語法網絡較復雜,直接影響語法靜態擴展無法實現。
創建語法文件后利用HTK的HParse[11,12]工具得到語言模型,因此該文件的構造是整個系統的最核心技術。本系統槽語法文件是按規定維吾爾文所對應的拉丁文(如表1所示)書寫的。槽語法由!slot、!grammar以及< >,[ ],||組成。除此之外,還有
表1國際標準維文拉丁文對照表
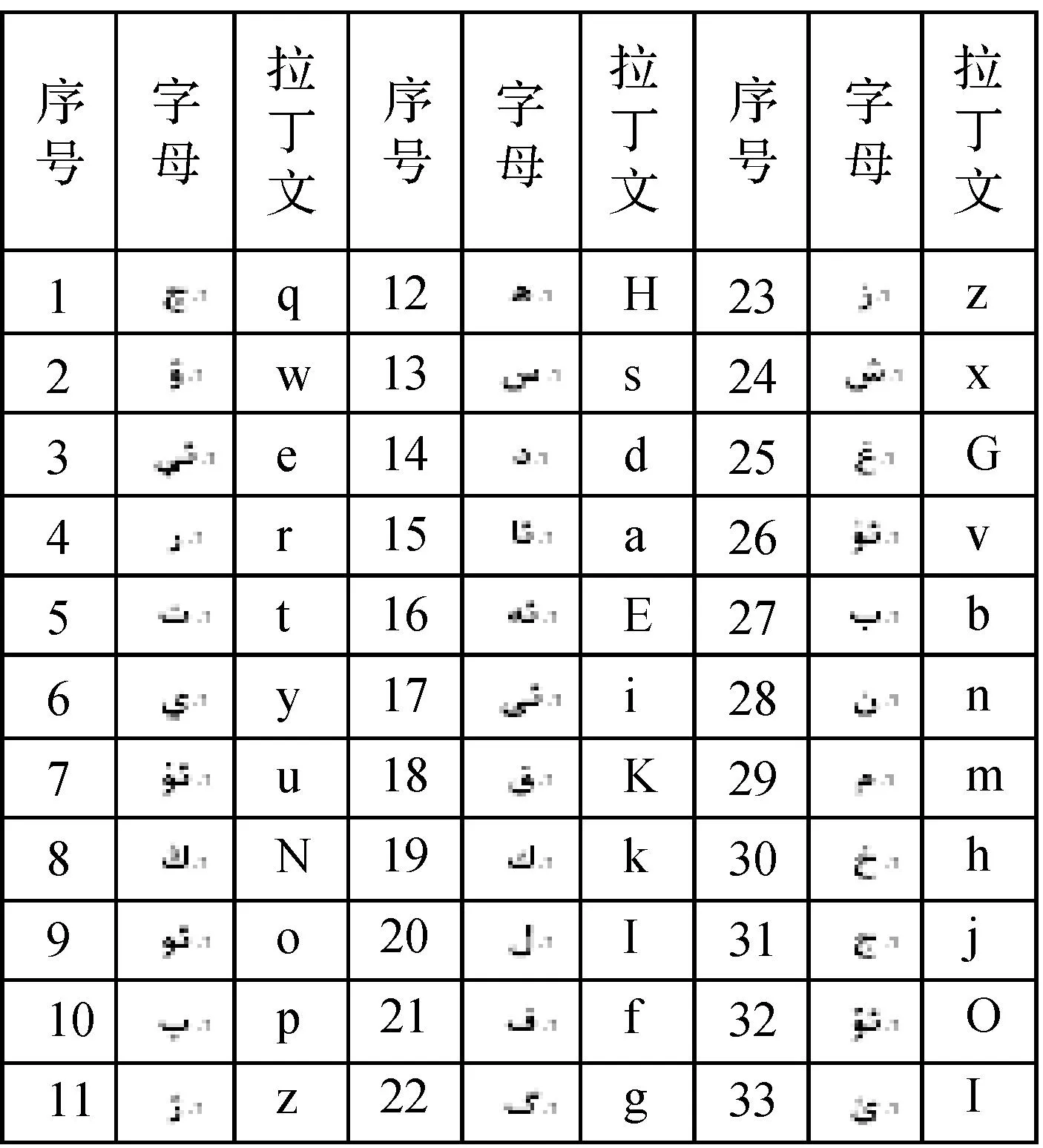
表2 槽語法中各個字符的含義
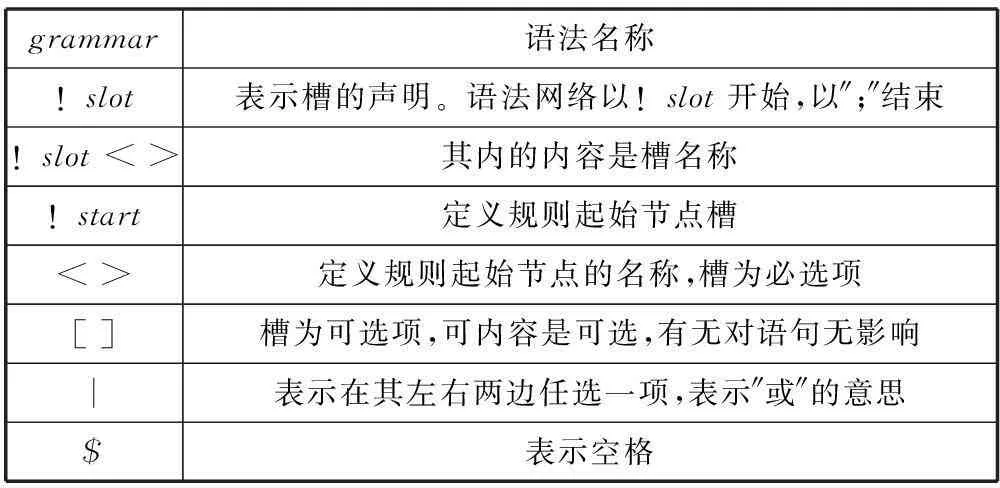
grammar語法名稱!slot表示槽的聲明。語法網絡以!slot開始,以″;″結束!slot<>其內的內容是槽名稱!start定義規則起始節點槽<>定義規則起始節點的名稱,槽為必選項[]槽為可選項,可內容是可選,有無對語句無影響︱表示在其左右兩邊任選一項,表示″或″的意思$表示空格
3軟件功能實現
3.1實現打電話功能
首先識別用戶所說的語音命令后,通過PrintContacts(c)方法,動態地查找和獲取用戶手機上的聯系人信息,調用matcher(contactDisplayName)方法來解決不符合條件的維吾爾文聯系人,然后需要引用startTalk(this,″nlp″)方法,在編寫的onButtonRetryClick( )方法中調用命令詞的識別,從而將會節省用戶在一批聯系人中的查找并翻閱的時間,從而更方便、快捷地完成用戶打電話的需求。識別用戶的命令,及轉換為拉丁文,后將用戶所說的語句顯示在手機屏幕上,根據mType=1的情況,提取槽語法中“打電話”的槽“!slot
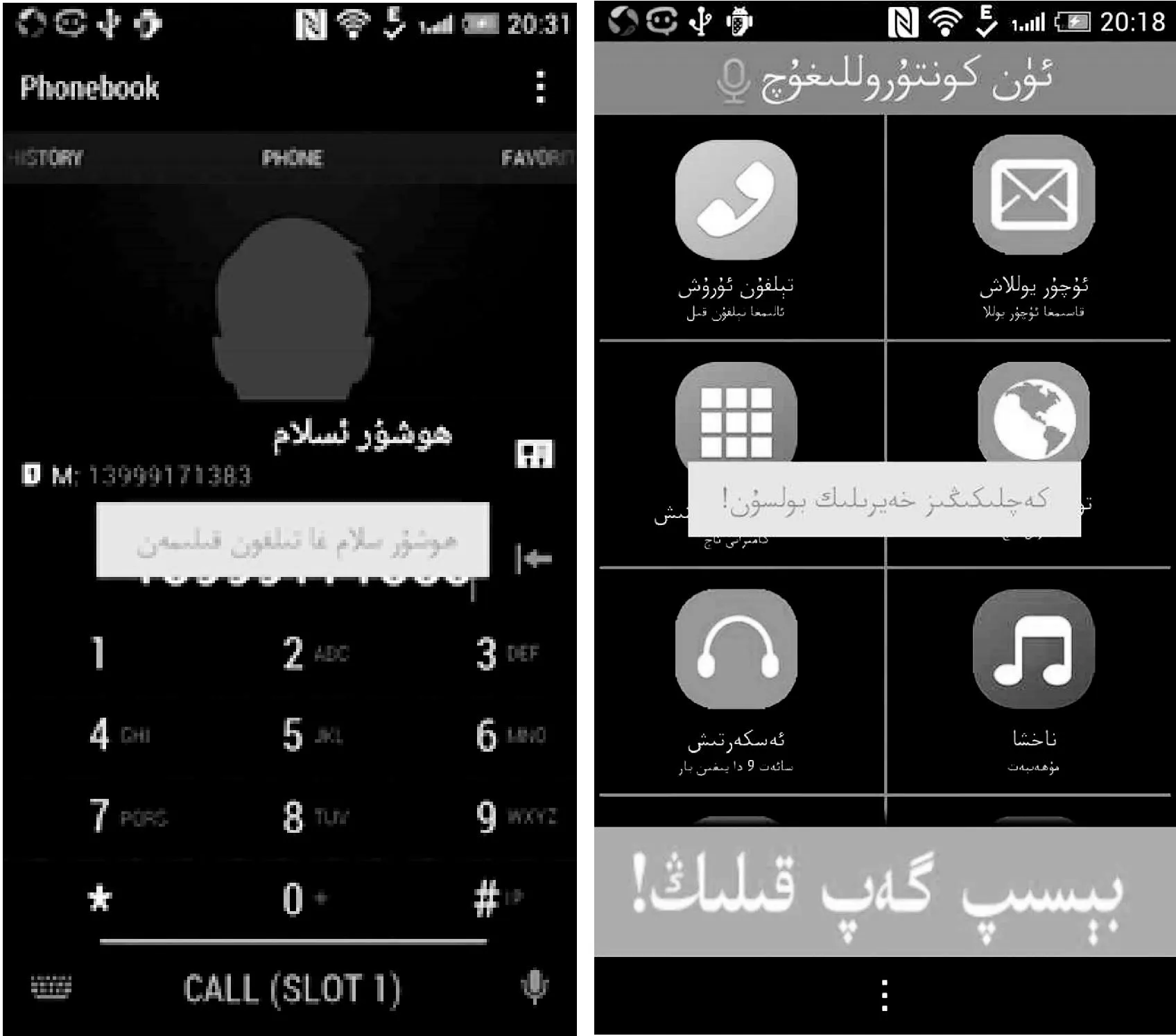
圖4 系統主界面圖 圖5 打電話功能實現圖
3.2實現打開應用功能

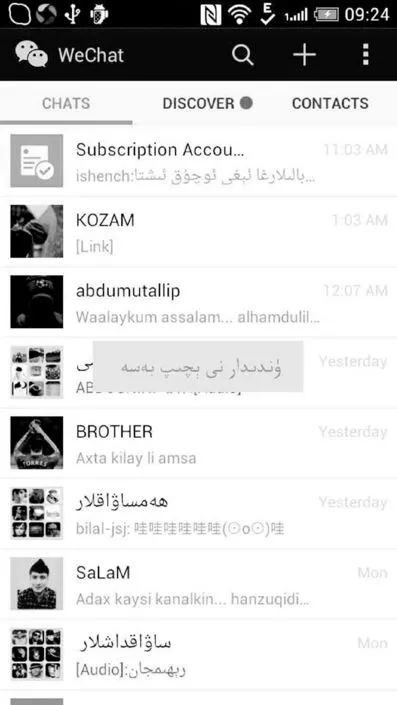
圖6 打開應用實現圖
4實驗與結果分析
4.1實驗數據與環境
本文利用英國劍橋大學研發出的基于隱馬爾科夫模型[15]的HTK工具,并且在使用HTK進行特征提取、訓練及得到聲學模型[16,17]的基礎上,利用建立的語法文件進行了語言模型的構建[18],再搭建本維吾爾語語音控制軟件能夠運行的Android開發平臺。
訓練集:一般環境下(如無人的教室、辦公室等),錄制朗讀式連續語音作為訓練集[19]。發音人是18~30歲的成年人總共356個人(189女,167男),共發聲128小時的2456條語句,發音人配置高寶立式麥克風,阻抗160om、靈敏度56±3dB,頻率范圍100~16 000Hz。采樣率選擇16KHz、采樣位選擇16Bit。語音數據以wav文件格式存儲,共有50 000多條語音文件。
測試集:錄制的軟件為CoolEdit2.0,語音采樣頻率為16KHz、采樣位選擇16Bit、單聲道格式,共有300個語音文件,即對于每一個語法規則分別錄制了100個文件。語音數據以wav文件格式存儲。
4.2實驗測試結果
測試環境為:系統安裝至單核、RAM256、ROM256,及系統版本是Android2.3.3的華為G606-T00和HTC智能手機、并在安靜的實驗室環境內進行了對于軟件核心部分“意圖”的人工實際測試。其中成功執行個數指的是在識別的基礎上能夠正確執行指令的個數,而執行失敗指的是能識別但是未成功執行的個數。除此,識別正確率為正確識別個數除以總數、成功執行率為成功執行個數除以總數而得。噪聲等周邊環境[20]、底層語音識別率、用戶聲音低或者地方口音偏重、發音不夠清晰正確及命令列表中不存在該詞匯等不能正確識別。測試結果如表3所示。
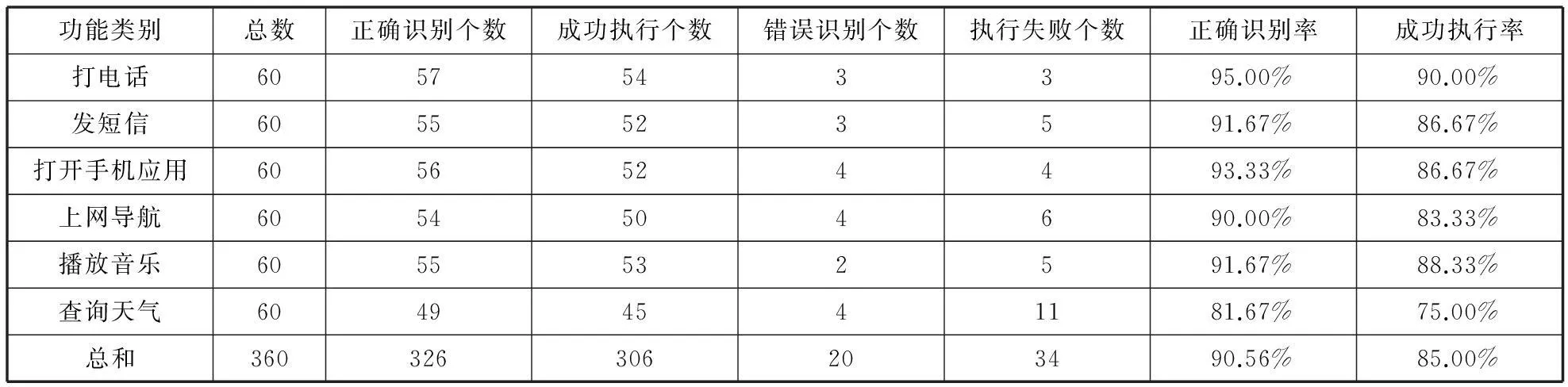
表3 對用戶“意圖”執行的測試結果表
5結語
本文以維吾爾語語法的特點出發,在符合命令詞的語法形式的條件下,建立了維吾爾語命令詞識別的槽語法文件,通過使用HTK得到其語法網絡及語言模型,并且對于一些出現的帶地方口音的單詞及一些新型詞匯等,對最終結果有一定的影響。未來用戶使用發短信功能時本系統上將增加語音輸入功能,除此還需要增加語音合成功能,為了使少數民族用戶使用更加方便的語音軟件,讓系統達到更加完美效果,對系統進行更加智能化分析、添加語音翻譯器是下一步研究重點。
參考文獻
[1] 韓超,梁泉.Android系統原理及開發要點詳解[M].北京:電子工業出版社,2010:340-343.
[2] 熱依曼·吐爾遜,吾守爾,努爾麥麥提.多文種手機混合輸入/輸出技術及實現[J].計算機工程與科學,2006,28(4):103-104,118.
[3]BridleJS.AnEfficientElastic-TemplateMethodforDetectingGivenWordsinRunningSpeech[C]//Brit.Acoust.Soc.Meeting,1973.
[4]MyersCS,RabinerLR,RosenbergAE.AnInvestigationoftheUseofDynamicTimeWarpingforWordSpottingandConnectedWordRecognition[C]//Proc.Conf.ASSP,April.1980:173-177.
[5] 徐明星,鄭方,吳文虎,等.連續語音關鍵詞識別系統的拒識方法研究[J].清華大學學報:自然科學版,1998,38(S1):89-91.
[6] 陶梅,吾守爾·斯拉木,那斯爾江·吐爾遜.基于HTK的維吾爾語連續語音聲學建模[J].中文信息學報,2008,22(5):56-59.
[7]SteveYoung,GunnarEvermann,MarkGales,etal.HTKBOOK[M].HTKVersion3.4.CambridgeUniversityEngineeringDepartment,March,2009:199-211.
[8] 那斯爾江·吐爾遜,吾守爾·斯拉木.基于隱馬爾可夫模型的維吾爾語連續語音識別系統[J].計算機應用,2009,29(7):2009-2012.
[9]WilponJG,LeeCH,RabinerLR.ApplicationofHiddenMarkovModelsforRecognitionofaLimitedSetofWordsinUnconstrainedSpeech[C]//ICASSP,1989,3(1):254-257.
[10]RohlicekJR,RusselW,RoukosS,etal.ContinuousHiddenMarkovModelingforSpeaker-IndependentWordSpotting[C]//ICASSP,1989,1(1):627-630.
[11] 李星星.基于HMM的漢語語音關鍵詞檢測研究與實現[D].武漢理工大學,2009.
[12]RoseRC,PaulDB.AHiddenModelBasedKeywordRecognitionSystem[C]//ICASSP,1990,1(1):129-132.
[13]ChristiansenRW,RushforthCK.DetectingandLocatingKeyWordsinContinuousSpeechUsingLinearPredictiveCoding[J].IEEETrans.onASSP,1977,25(5):361-367.
[14]AlanLHiggins,RobertEWohlford.KeywordRecognitionUsingTemplateConcatenation[C]//ICASSP,1985,1(3):1233-1236.
[15] 鄭方.連續無限制語音流中關鍵詞識別方法研究[D].北京:清華大學,1997.
[16] 努爾麥麥提·尤魯瓦斯,吾守爾·斯拉木.面向大詞匯量的維吾爾語連續語音識別研究[J].計算機工程與應用,2013,49(9):115-119.
[17] 努爾麥麥提·尤魯瓦斯,吾守爾·斯拉木,熱依曼·吐爾遜.維吾爾語連續語音識別聲學模型優化研究[J].計算機工程與應用,2013,49(2):145-147.
[18] 努爾麥麥提·尤魯瓦斯,吾守爾·斯拉木,熱依曼·吐爾遜.基于音節的維吾爾語大詞匯連續語音識別系統[J].清華大學學報:自然科學版,2013,53(6):741-744.
[19] 努爾麥麥提·尤魯瓦斯,吾守爾·斯拉木,熱依曼·吐爾遜.維吾爾語大詞匯語音識別系統識別單元研究[J].北京大學學報:自然科學版,2014,50(1):149-152.
[20]TakebayashiY,TsuboiH,Kanazawa.ARobustSpeechRecognitionSystemUsingWord-SpottingwithNoiseImmunityLearning[C]//ICASSP,1991,2(1):905-908.
DEVELOPMENT OF UYGHUR VOICE CONTROL SYSTEM BASED ON SMART PHONE
Miradeljan Mamat1Wushour Ialam1,2Nurmamat Yolwas1,2Rayima Tursun1,2Anwar Tohti2
1(College of Information Science and Engineering,Xinjiang University,Urumqi 830046,Xinjiang,China)2(Key Laboratory of Xinjiang Multilingual IT,Xinjiang University,Urumqi 830046,Xinjiang,China)
AbstractWith the purpose of implementing Uyghur command words recognition, we elaborately studied the development and implementation process of Uyghur command words recognition system on Android platform, introduced the development difficulties, core technologies and typical functions of the system. The system was developed mainly using Android SDK, eclipse integrated development environment and API interfaces, and realised the functions of correct display and processing of multiple texts of Uyghur, Chinese and English through automatic styles selection rule. Aiming at different speaking styles of the majority of users, we rebuilt Uyghur voice and grammar files, and solved the problem of different dialects around the Region. Moreover we gained the testing results of right recognition rate of 90.56% and the successful implementation rate of 85% in the experiment made in usual Lab condition, this showed that in the research of Uyghur non-specific command words recognition, the structure and construction of grammar files had different effects on system.
KeywordsAndroid platformUyghurKeyword recognitionSlot grammarCommand words recognition
收稿日期:2014-08-23。國家自然科學基金項目(60762006);國家工信部電子發展重大項目(159018);新疆自治區自然科技項目(2011 211A012)。米爾阿迪力江·麥麥提,碩士生,主研領域:嵌入式智能應用開發,語音處理,自然語言處理。吾守爾·斯拉木,教授。努爾麥麥提·尤魯瓦斯,講師。熱依曼·吐爾遜,副教授。艾尼宛爾·托乎提,工程師。
中圖分類號TP311.1
文獻標識碼A
DOI:10.3969/j.issn.1000-386x.2016.06.053
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
