基于自組合核的增量分類方法
2016-08-15 08:14:31吳振宇
系統(tǒng)工程與電子技術(shù) 2016年8期
馮 林, 張 晶, 吳振宇
(1. 大連理工大學(xué)電子信息與電氣工程學(xué)部計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院, 遼寧 大連 116024;2. 大連理工大學(xué)創(chuàng)新創(chuàng)業(yè)學(xué)院, 遼寧 大連 116024)
?
基于自組合核的增量分類方法
馮林1,2, 張晶1,2, 吳振宇2
(1. 大連理工大學(xué)電子信息與電氣工程學(xué)部計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院, 遼寧 大連 116024;2. 大連理工大學(xué)創(chuàng)新創(chuàng)業(yè)學(xué)院, 遼寧 大連 116024)
在線極端學(xué)習(xí)機(jī)(online sequential extreme learning machine,OSELM)模型在解決動(dòng)態(tài)數(shù)據(jù)實(shí)時(shí)分類問題時(shí),無需批量計(jì)算,僅保留前一時(shí)刻訓(xùn)練模型,根據(jù)當(dāng)前時(shí)刻樣本調(diào)整原有模型即可。然而,該增量方法在離線訓(xùn)練階段隨機(jī)指定隱層神經(jīng)元使模型魯棒性差,且求解過程難以拓展于核方法,降低了分類效果。針對上述問題,提出一種基于自組合核的在線極端學(xué)習(xí)機(jī)(self-compounding kernel online sequential extreme learning machine,SCK-OSELM)模型。首先,提出一種新的自組合核(self-compounding kernel,SCK)方法,構(gòu)建樣本不同核空間的非線性特征組合,該方法可被應(yīng)用于其他監(jiān)督核方法中。其次,以稀疏貝葉斯為理論基礎(chǔ)將訓(xùn)練數(shù)據(jù)的先驗(yàn)分布作為模型權(quán)值引入,并利用超參調(diào)整權(quán)值后驗(yàn)分布,從而達(dá)到對當(dāng)前時(shí)間點(diǎn)參數(shù)稀疏的目的。最后,將稀疏得到的參數(shù)并入下一時(shí)刻運(yùn)算。對動(dòng)態(tài)數(shù)據(jù)的實(shí)時(shí)分類實(shí)驗(yàn)表明,該方法是一種有效的增量學(xué)習(xí)算法。相比于OSELM,該方法在解決動(dòng)態(tài)數(shù)據(jù)實(shí)時(shí)分類問題時(shí)獲得更穩(wěn)定、準(zhǔn)確的分類效果。
動(dòng)態(tài)數(shù)據(jù); 在線極端學(xué)習(xí)機(jī); 自組合核; 稀疏貝葉斯
0 引 言
在互聯(lián)網(wǎng)時(shí)代,各個(gè)領(lǐng)域每一時(shí)刻均產(chǎn)生大量數(shù)據(jù),如網(wǎng)絡(luò)流量數(shù)據(jù)、金融交易數(shù)據(jù)、醫(yī)學(xué)診斷數(shù)據(jù)、移動(dòng)終端數(shù)據(jù)等。如何實(shí)時(shí)、準(zhǔn)確地獲得數(shù)據(jù)并更新已有知識,成為研究熱點(diǎn)。模式分類是數(shù)據(jù)挖掘領(lǐng)域的重要分支,廣泛應(yīng)用于圖像識別、故障排查、醫(yī)療檢測等領(lǐng)域。上述應(yīng)用中數(shù)據(jù)由時(shí)序動(dòng)態(tài)更新,后續(xù)到來的數(shù)據(jù)對已有知識更新、補(bǔ)充。傳統(tǒng)的模式分類模型需要對所有時(shí)刻累積的數(shù)據(jù)進(jìn)行學(xué)習(xí),該方法將耗費(fèi)大量的時(shí)間與空間資源,并難以拓展于動(dòng)態(tài)數(shù)據(jù)實(shí)時(shí)分類問題。因此,如何實(shí)時(shí)高效處理這些按時(shí)間序列動(dòng)態(tài)到來的數(shù)據(jù),同時(shí)保持訓(xùn)練速度與數(shù)據(jù)更新速度的平衡,成為亟待解決的問題。早在1962年,文獻(xiàn)[1]就提出增量學(xué)習(xí)方法,該方法在保持對已有模型可追溯的基礎(chǔ)上,直接對新數(shù)據(jù)進(jìn)行學(xué)習(xí),進(jìn)而得到新的訓(xùn)練模型。研究者們將增量算法的研究重點(diǎn)放在算法的穩(wěn)定性與可追溯性兩個(gè)方面,本文的研究主要與第二點(diǎn)相關(guān)。
從算法穩(wěn)定性方面,每批次到來的動(dòng)態(tài)數(shù)據(jù)難以預(yù)測,其性態(tài)是不穩(wěn)定的,稱為非穩(wěn)定環(huán)境(non-stationary environment,NSE)[1-2]。因此,可能出現(xiàn)數(shù)據(jù)分布改變甚至產(chǎn)生“概念漂移現(xiàn)象”。文獻(xiàn)[3-4]對上述NSE現(xiàn)象進(jìn)行了定義并對其漂移程度進(jìn)行了評價(jià)。早期的研究均從如何發(fā)現(xiàn)該現(xiàn)象的產(chǎn)生以及如何保證算法的穩(wěn)定性出發(fā),這些方法普遍存在較高的時(shí)空復(fù)雜度。文獻(xiàn)[5]較早提出時(shí)間窗識別概念漂移的方法,該方法將導(dǎo)致對之前時(shí)刻數(shù)據(jù)的遺忘,使學(xué)習(xí)效果降低。文獻(xiàn)[6]通過自適應(yīng)調(diào)節(jié)時(shí)間窗寬度保證對產(chǎn)生漂移的類別進(jìn)行學(xué)習(xí)。文獻(xiàn)[7-9]分別利用控制圖、JIT分類器與信息論等方法解決該問題。集成分類算法在文獻(xiàn)[10]中被用于解決動(dòng)態(tài)數(shù)據(jù)增量分類問題。文獻(xiàn)[11]提出Learning++算法,該方法為一種增量學(xué)習(xí)算法,可與各種監(jiān)督學(xué)習(xí)分類器相組合,其主要思想是:對一批新到來的樣本學(xué)習(xí)得到多個(gè)弱分類器后將其加權(quán)組合得到分類結(jié)果。該方法天生具有解決概念漂移的能力,通過弱分類器對已有數(shù)據(jù)類別空間記憶,后續(xù)一些學(xué)者對該方法進(jìn)行了改進(jìn)[12-13]。以上方法針對動(dòng)態(tài)數(shù)據(jù)增量學(xué)習(xí)過程中產(chǎn)生的非漸進(jìn)概念漂移檢測有較好效果,當(dāng)動(dòng)態(tài)數(shù)據(jù)中出現(xiàn)漸進(jìn)概念漂移時(shí)[14],上述方法為保證較小的空間復(fù)雜度,丟失了原有數(shù)據(jù)信息,增量學(xué)習(xí)能力被減弱。
在模型的可追溯性方面,文獻(xiàn)[15-16]提出樣本選擇方法,通過保留之前的部分樣本,當(dāng)新數(shù)據(jù)到來時(shí),結(jié)合保留的樣本重新訓(xùn)練得到新的分類器。該方法由于保留了前序時(shí)間點(diǎn)的有用信息,有效提高了分類效果。單隱層前饋神經(jīng)網(wǎng)絡(luò)(single hidden layer neural network,SLNF)可通過學(xué)習(xí)連續(xù)函數(shù)達(dá)到任意精度的擬合效果,從而被應(yīng)用于解決模式分類問題與增量學(xué)習(xí)方法。文獻(xiàn)[17]提出自適應(yīng)增量神經(jīng)網(wǎng)絡(luò)(self-organizing incremental neural network,SOINN),利用原樣本與新樣本近鄰關(guān)系移除多余的樣本,并利用兩層神經(jīng)網(wǎng)絡(luò)訓(xùn)練得到分類器實(shí)現(xiàn)增量分類。該方法采用類內(nèi)插入機(jī)制處理新來的樣本,由于實(shí)現(xiàn)過程中用到過多參數(shù),使得算法難以控制且非常復(fù)雜。為增強(qiáng)算法的穩(wěn)定性,文獻(xiàn)[18]對上述方法進(jìn)行改進(jìn)。SLNF雖然有諸多優(yōu)點(diǎn),但在求解過程中采用迭代方式,使得求解速度緩慢,且解容易陷入局部極小值。文獻(xiàn)[19]提出極端學(xué)習(xí)機(jī)模型(extreme learning machine, ELM),將求解過程轉(zhuǎn)化為簡單的線性系統(tǒng),可以任意指定輸入層參數(shù),且無需迭代調(diào)整。該方法不僅簡化了求解過程,且不會陷入局部極小解,自提出以來被廣泛應(yīng)用于模式分類[20-21]與時(shí)間序列預(yù)測[22-23]等領(lǐng)域。為了推廣算法的應(yīng)用,文獻(xiàn)[24-25]對ELM模型進(jìn)行改進(jìn)。
在對動(dòng)態(tài)數(shù)據(jù)適應(yīng)性方面,文獻(xiàn)[26]在ELM基礎(chǔ)上推導(dǎo)了增量學(xué)習(xí)模型。當(dāng)新數(shù)據(jù)按照時(shí)間先后分批到來時(shí),該方法無需對所有累積數(shù)據(jù)重新訓(xùn)練,僅訓(xùn)練新到來數(shù)據(jù),調(diào)整分類模型即可。該方法是一種速度很快的增量學(xué)習(xí)算法,其改進(jìn)算法在圖像分類、預(yù)測等應(yīng)用領(lǐng)域取得了很好效果[27-28]。在離線訓(xùn)練階段采用ELM方法,通過最小化經(jīng)驗(yàn)風(fēng)險(xiǎn)調(diào)整隱層結(jié)點(diǎn)。為避免過擬合,文獻(xiàn)[29]引入結(jié)構(gòu)風(fēng)險(xiǎn),利用正則化參數(shù)平衡經(jīng)驗(yàn)風(fēng)險(xiǎn)。文獻(xiàn)[30]受LS-SVM算法啟發(fā),在ELM上進(jìn)行推導(dǎo)得到LS-IELM算法,但該方法在不同應(yīng)用背景下,仍存在隱層參數(shù)難以確定的問題,且隨機(jī)指定的輸入隱層參數(shù)無法保證算法的穩(wěn)定性。文獻(xiàn)[30]提出KB-IELM算法,在原有LS-IELM中引入核方法,避免了上述隱層參數(shù)選擇等問題。文獻(xiàn)[31-32]提出OS-ELMK方法和KOSELM方法。然而,上述方法中均存在兩個(gè)問題:①復(fù)雜的推導(dǎo)與大量的矩陣運(yùn)算,使得算法效率偏低;②算法需根據(jù)數(shù)據(jù)分布對核函數(shù)選擇預(yù)判,當(dāng)無法預(yù)先得知數(shù)據(jù)分布時(shí),難以對核函數(shù)進(jìn)行合適的選擇從而降低分類效果。
針對上述問題,本文提出一種自組合核在線極端學(xué)習(xí)機(jī)模型(self-compounding kernels online sequential kernel extreme learning machine,SCK-OSELM)。首先,在每批動(dòng)態(tài)數(shù)據(jù)到來的訓(xùn)練階段將樣本映射到不同核空間,并將其特征進(jìn)行非線性融合得到核矩陣。之后,利用稀疏貝葉斯方法對其后驗(yàn)概率進(jìn)行估計(jì)從而代替擬合數(shù)據(jù)的方法訓(xùn)練得到隱層輸出權(quán)值,并對當(dāng)前時(shí)刻參數(shù)進(jìn)行稀疏以便于后續(xù)的增量學(xué)習(xí)。本文在3類數(shù)據(jù)集上驗(yàn)證了SCK-OSELM算法的有效性,存在以下優(yōu)點(diǎn):
(1) 該方法避免了人為選擇隱層參數(shù),增強(qiáng)了算法的魯棒性。通過對當(dāng)前時(shí)間點(diǎn)計(jì)算將參數(shù)進(jìn)行稀疏,不僅保留了已有的判別信息,且降低了下一時(shí)刻的計(jì)算復(fù)雜度,實(shí)現(xiàn)了增量學(xué)習(xí)。
(2) 提出自組合核方法,實(shí)現(xiàn)了不同高維空間特征融合,同時(shí)避免了需根據(jù)樣本分布選擇核函數(shù)的問題。該方法可被拓展應(yīng)用于其他監(jiān)督的組合核方法中。
1 OSELM算法及本文算法思路
1.1OSELM算法回顧
ELM模型為SLNF的改進(jìn)算法,避免了其求解速度慢,容易陷入局部極小值的問題,可描述如下:N個(gè)不同樣本
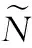
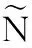
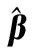
(1)
式中,ξi=[ξi,1,…,ξi,m]T為訓(xùn)練誤差向量。根據(jù)KKT理論,由拉格朗日乘子法有
(2)
式中,τ為拉格朗日乘子。此處g(xi)g(xj),可轉(zhuǎn)化為K(xi,xj)=g(xi)g(xj)。式(2)可寫為
(3)
式中,K(xi,xj)為ELM的核函數(shù),可為徑向基函數(shù)等任意核函數(shù)。
上述模型針對靜態(tài)數(shù)據(jù),采用批量分類方法。文獻(xiàn)[26]提出了增量分類模型OSELM,其為ELM模型的在線求解方法,能快速處理在線分類問題。對ΔN(ΔN≥1)個(gè)新樣本學(xué)習(xí)得到模型后與原有模型進(jìn)行矩陣計(jì)算即可得到新的輸出權(quán)值βN+ΔN。當(dāng)ΔN個(gè)新樣本到達(dá)時(shí),隱層輸出矩陣為
(4)
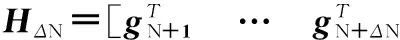
(5)
從而,可得到
(6)

(7)
結(jié)合式(6)和式(7),可得到輸出權(quán)值的增量表達(dá)式為
(8)
由上述求解過程可知,新數(shù)據(jù)動(dòng)態(tài)到來時(shí),式(7)和式(8)僅需在原有模型基礎(chǔ)上進(jìn)行調(diào)整,即可實(shí)現(xiàn)增量學(xué)習(xí)。
1.2OSELM增量學(xué)習(xí)問題與本文思路
OSELM僅在當(dāng)前時(shí)間點(diǎn)對已得到的分類器進(jìn)行調(diào)整,無需對全部累積數(shù)據(jù)重新訓(xùn)練即可獲得適應(yīng)于新數(shù)據(jù)的分類器。該方法雖然在保證計(jì)算精度的前提下,提高了計(jì)算速度,但由式(5)可知矩陣需通過隨機(jī)指定參數(shù)的方法獲得,這種操作將產(chǎn)生較差的魯棒性。同時(shí),由式(3)可知核ELM難以直接拓展于式(7)和式(8)成為基于核方法的增量極端學(xué)習(xí)機(jī),或需通過復(fù)雜矩陣計(jì)算將OSELM拓展成核方法。如文獻(xiàn)[30-32]指出,該方法不僅計(jì)算復(fù)雜,且存在難以針對輸入數(shù)據(jù)分布特點(diǎn)選擇合適核函數(shù)的問題。
稀疏貝葉斯分類方法利用先驗(yàn)概率使部分參數(shù)值趨于0,這些參數(shù)對判別模型的影響較小,從而達(dá)到參數(shù)稀疏的目的。上述特性恰好可被用于增量模型中。本文受其啟發(fā),提出一種基于核的增量學(xué)習(xí)算法。通過保留當(dāng)前時(shí)刻約減后參數(shù),降低下一時(shí)刻計(jì)算復(fù)雜度。同時(shí),為避免原始核映射方法對核函數(shù)選擇人為干預(yù)問題,提出一種新的組合核方法SCK,該方法同時(shí)可被用于其他監(jiān)督的核方法中。
SCK-OSELM可簡述如下:首先,將輸入樣本映射到不同核空間,利用SCK方法獲得高維特征的非線性融合;其次,利用稀疏貝葉斯方法對高維特征訓(xùn)練并保留在分類中貢獻(xiàn)大的參數(shù);最后,將之前得到的稀疏參數(shù)并入下一時(shí)刻與新樣本共同訓(xùn)練。
算法原理如圖1所示。圖中紅色結(jié)點(diǎn)為經(jīng)過稀疏后得到的參數(shù)結(jié)點(diǎn),同時(shí)加入到下一次的運(yùn)算。該操作保持了之前訓(xùn)練模型可追溯性,降低了算法下一時(shí)刻計(jì)算復(fù)雜度。
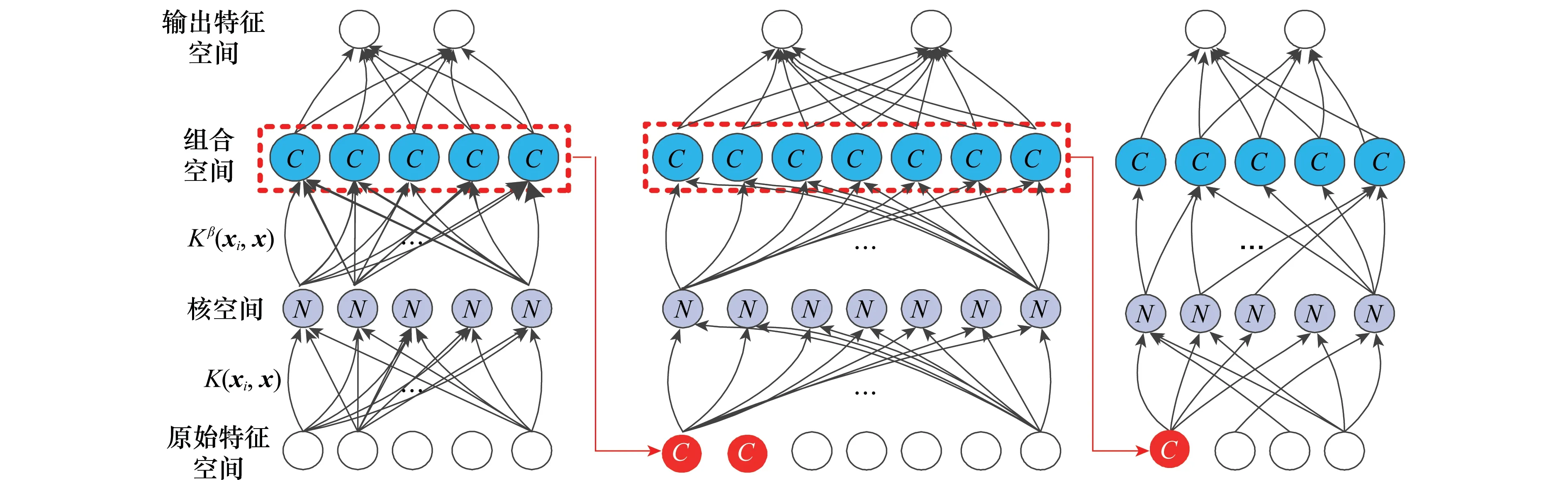
圖1 SCK-OSELM算法基本原理
2 SCK算法

(9)
式中,β為模型權(quán)值向量。
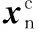
(10)
式中,ηc為權(quán)值,用于控制不同核函數(shù)的權(quán)值。對ηc的求解可根據(jù)監(jiān)督算法,通過獲得樣本訓(xùn)練誤差范數(shù)得到優(yōu)化方程:
(11)
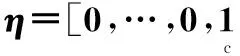
(12)
式中,p>1。該監(jiān)督學(xué)習(xí)中,判別模型獲得了多個(gè)不同核對學(xué)習(xí)過程產(chǎn)生的不同貢獻(xiàn)。根據(jù)式(12),方程需求解一個(gè)非線性、非凸優(yōu)化問題。根據(jù)優(yōu)化理論,無法直接找到該問題的全局最優(yōu)解,本文根據(jù)文獻(xiàn)[33]中的交替優(yōu)化形式,采用迭代求解方法,獲得方程局部最優(yōu)解。該方法通過交替更新tj與ηc值優(yōu)化求解。首先,tj值被固定更新ηc值,利用拉格朗日乘子法,得到
式中,λ為拉格朗日乘子,通過求偏導(dǎo),并使其變量值為0,可得到
式中,i=1,…,m。
經(jīng)推導(dǎo)后可得到ηc的值為
(13)
求得當(dāng)前ηc后,固定該值,交替迭代求解tj值。同時(shí),由式(13)可知,p值可影響ηc。當(dāng)p→∞時(shí)ηc值將彼此相近,p值的選取應(yīng)獲得所有互補(bǔ)的核空間。
3 增量分類
(14)
式中,g(·)為Sigmod激活函數(shù),g[f(x;β)]=1+e-f(x;β),且f(x;β)=xβ。為避免模型訓(xùn)練過擬合,在稀疏貝葉斯學(xué)習(xí)中β的求解不直接利用最大似然估計(jì)求解,此處引入β的高斯先驗(yàn)分布對其約束:
(15)
式中,α為超參數(shù),該參數(shù)最終決定了參數(shù)的稀疏性。由自相關(guān)性判定理論可知,先驗(yàn)概率會使神經(jīng)元中影響較小的神經(jīng)元對應(yīng)的β值趨于0值。對于任意x對應(yīng)的t均獨(dú)立,得到以α為條件的邊際似然函數(shù):
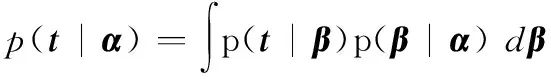
在訓(xùn)練過程中通過最大化該似然函數(shù)求解α。為了簡化求解過程,將式(14)和式(15)代入,有如下拉普拉斯近似:
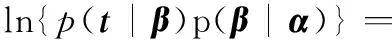
(16)
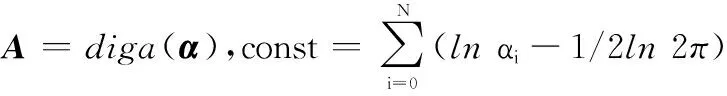
式中,B為N×N的對角矩陣,元素βi=fi(1-fi)且dg/df=g(1-g)。利用牛頓法可以求解β為
(17)
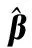
(18)
(19)
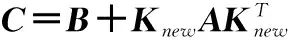
(20)
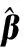
分類方法通過似然函數(shù)調(diào)整輸出權(quán)值,使得部分權(quán)值為0,從而達(dá)到當(dāng)前時(shí)刻參數(shù)稀疏的目的。SCK-OSELM算法的具體步驟如下,其中包含離線訓(xùn)練部分與在線訓(xùn)練部分:
(1) 離線訓(xùn)練部分
步驟 1隨機(jī)初始化ηc為1/c,βi與αi為任意值,指定組合核函數(shù)(多個(gè)核函數(shù),指定核函數(shù)參數(shù))與最大迭代次數(shù);
步驟 2計(jì)算輸入離線樣本的不同核矩陣與組合核矩陣;
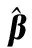
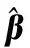
(2) 在線訓(xùn)練部分
步驟 7計(jì)算輸入在線樣本的多個(gè)核矩陣與組合核矩陣;
步驟 9計(jì)算tj并計(jì)算更新后的ηc;
步驟 11如果在線數(shù)據(jù)到來結(jié)束則利用最終約減后的參數(shù)集訓(xùn)練得到分類模型,反之則轉(zhuǎn)到步驟6繼續(xù)訓(xùn)練。
4 實(shí)驗(yàn)結(jié)果與分析
4.1實(shí)驗(yàn)設(shè)置
實(shí)驗(yàn)運(yùn)行在2.93GHzCPU,8GBRAM的PC上,計(jì)算平臺為Matlab213a。為更加全面地評價(jià)本文提出算法的效果,選擇3類數(shù)據(jù)集進(jìn)行驗(yàn)證:12個(gè)UCI數(shù)據(jù)集、3組MNIst手寫體數(shù)據(jù)集與一組手工數(shù)據(jù)集。

4.2數(shù)據(jù)集描述
UCI數(shù)據(jù)集被廣泛用于驗(yàn)證分類算法效果的實(shí)驗(yàn)中,本文選擇6個(gè)二分類、6個(gè)多分類數(shù)據(jù)集。數(shù)據(jù)集的具體描述見表1。本文設(shè)置增量算法的滑窗大小為訓(xùn)練樣本數(shù)量的10%。
MNIst數(shù)據(jù)集為手寫體圖像數(shù)據(jù)集,其維度較高。在該數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn)對比,驗(yàn)證了算法在高維度數(shù)據(jù)集上的效果。其包含10類60 000個(gè)樣本,每個(gè)樣本為28×28的灰度圖像,圖2為測試集示意圖。為測試算法的穩(wěn)定性本文隨機(jī)選擇3組樣本進(jìn)行實(shí)驗(yàn),3組實(shí)驗(yàn)數(shù)據(jù)的具體描述被總結(jié)在表2中。
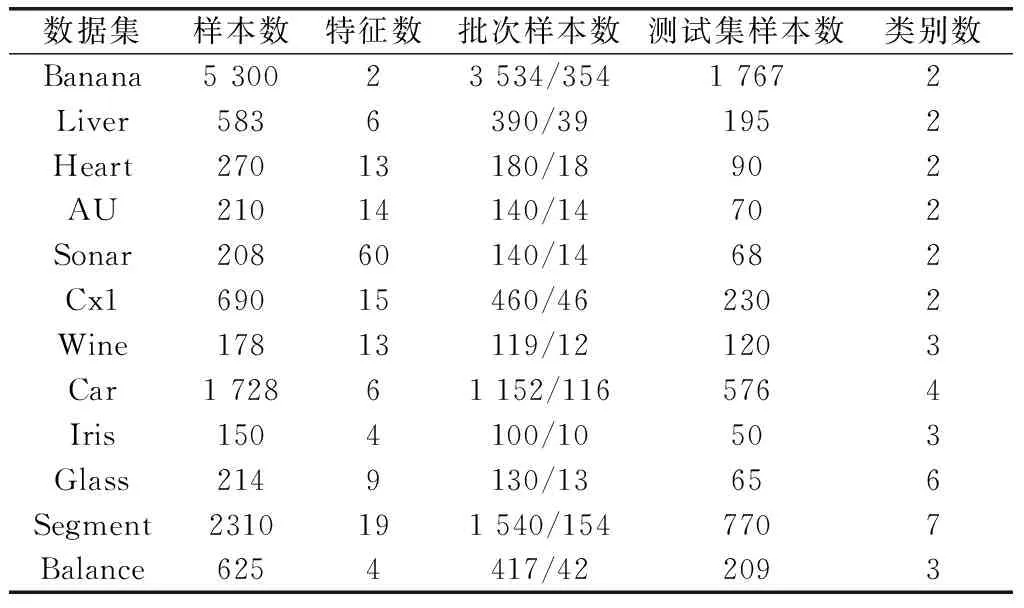
表1 UCI數(shù)據(jù)集描述

圖2 MNIst數(shù)據(jù)測試集實(shí)例
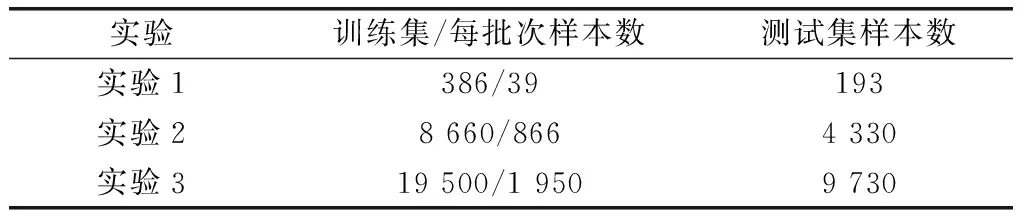
實(shí)驗(yàn)訓(xùn)練集/每批次樣本數(shù)測試集樣本數(shù)實(shí)驗(yàn)1386/39193實(shí)驗(yàn)28660/8664330實(shí)驗(yàn)319500/19509730
增量學(xué)習(xí)中除了數(shù)據(jù)量的增加,同時(shí)面臨不同類別樣本分布非平衡的問題。本文利用手工數(shù)據(jù)集,對算法對類別敏感性進(jìn)行了測試。該數(shù)據(jù)集包含5個(gè)類別,共1 000個(gè)樣本,維度為2。該數(shù)據(jù)集的散點(diǎn)如圖3所示,數(shù)據(jù)集的數(shù)據(jù)分布為單位面積均勻分布,但不同類別樣本分布不同。實(shí)驗(yàn)中隨機(jī)選擇訓(xùn)練集樣本為667,測試集樣本為334。
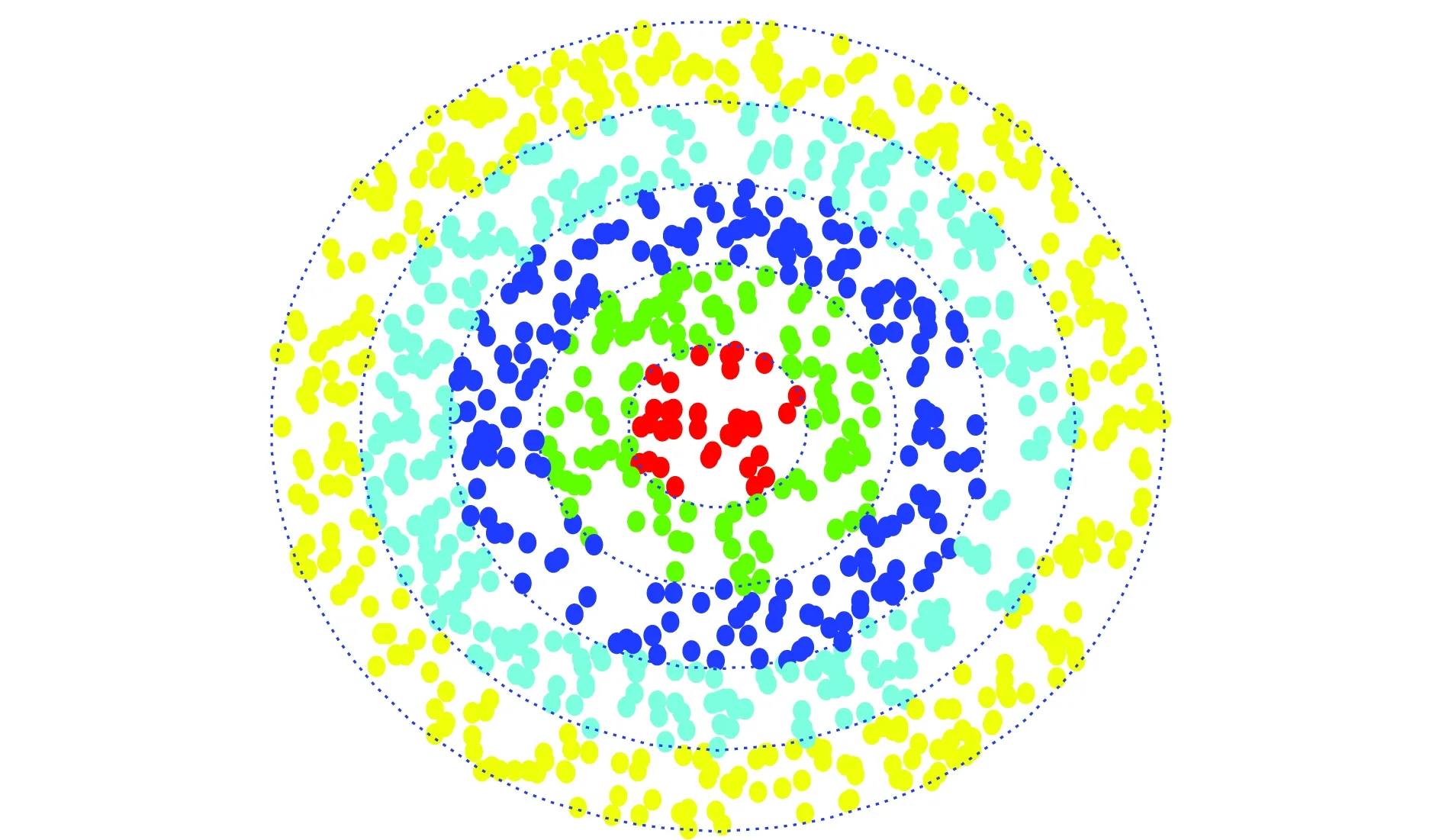
圖3 手工數(shù)據(jù)集散點(diǎn)圖
4.3參數(shù)選擇
本文所用核函數(shù)參數(shù)采用遍歷的方式獲得,Linear,Gaussian,Laplacian的參數(shù)選擇為2γ,(γ∈{-2,-1,0,1,2}),polynomial的參數(shù)選擇為γ(γ∈{1,2,3})。分別選擇UCI數(shù)據(jù)集中的二分類數(shù)據(jù)集Heart與多分類數(shù)據(jù)集Iris對以上參數(shù)遍歷選擇。此時(shí),固定p=2,且迭代次數(shù)為500。由圖4可知,當(dāng)為(2-2,2-2,20,3),(2-2,22,20,3)等參數(shù)時(shí),兩個(gè)數(shù)據(jù)集的分類準(zhǔn)確率均較高,本文在后續(xù)試驗(yàn)中選擇核函數(shù)參數(shù)為(2-2,2-2,20,3)。
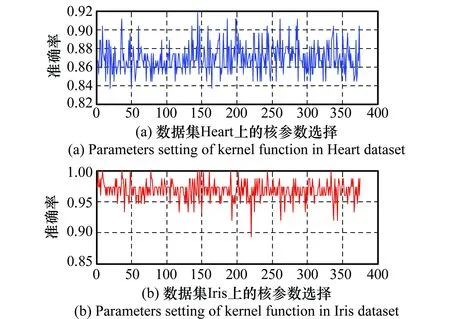
圖4 核函數(shù)參數(shù)選擇
SCK-OSELM利用牛頓法求解似然方程。為保證算法收斂,本文采用平凡收斂條件,需對迭代次數(shù)進(jìn)行設(shè)置。算法中p值的選擇對分類效果有較大影響,此處選擇p=2,p=5,后續(xù)本文將對不同p(p∈{2,3,4,5,6,7,8,9,10})值進(jìn)行遍歷并討論分類效果。圖5(a)和圖5(b)所示分別為二分類UCI數(shù)據(jù)集Heart與多分類UCI數(shù)據(jù)集Iiris的分類效果,隨著迭代次數(shù)的增加,曲線在迭代次數(shù)為200時(shí)趨于穩(wěn)定。為確保算法收斂同時(shí)盡量減少算法運(yùn)行時(shí)間,后續(xù)實(shí)驗(yàn)中設(shè)置迭代次數(shù)為200。
對比算法中的參數(shù)設(shè)置如下,OSELM與LS-IELM中,隱層神經(jīng)元為Sigmod:(G(a,b,x)=1/(1+exp(-(ax+b)))),參數(shù)a在[-1,1]隨機(jī)選取,b在[0,1]隨機(jī)選取。參數(shù)a與b選取對算法分類效果有一定影響,本文實(shí)驗(yàn)均采用10次運(yùn)算后取均值的方式。由文獻(xiàn)[26]可知,OSELM中隱層神經(jīng)元的選擇對算法效果有嚴(yán)重影響,個(gè)數(shù)過多模型訓(xùn)練將產(chǎn)生過擬合,過少則模型訓(xùn)練不足。該參數(shù)的普遍選擇方式是交叉驗(yàn)證或指定范圍內(nèi)遍歷,本文中采用后一種方式,在[1,5,10,50,80,100,200,300, 400,500,800, 1 000]范圍內(nèi)遍歷隱層結(jié)點(diǎn)。圖6(a)為UCI二分類數(shù)據(jù)集中Heart和Cx1在不同隱層結(jié)點(diǎn)下的分類效果統(tǒng)計(jì),圖6(b)為UCI多分類數(shù)據(jù)集Iirs和PageBlocks在不同隱層結(jié)點(diǎn)下的分類效果統(tǒng)計(jì)(數(shù)據(jù)集詳細(xì)描述見表1)。如圖可見,隨著隱層結(jié)點(diǎn)個(gè)數(shù)的上升,識別率隨之提高,到200時(shí)趨于穩(wěn)定,超過400后模型處于過擬合狀態(tài),分類準(zhǔn)確率有所下降。由此,本文設(shè)置OSELM與LS-IELM中隱層結(jié)點(diǎn)個(gè)數(shù)為200。
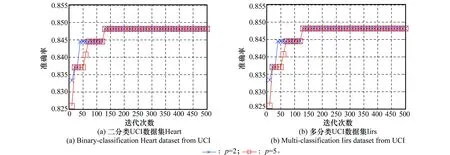
圖5 算法迭代次數(shù)設(shè)置
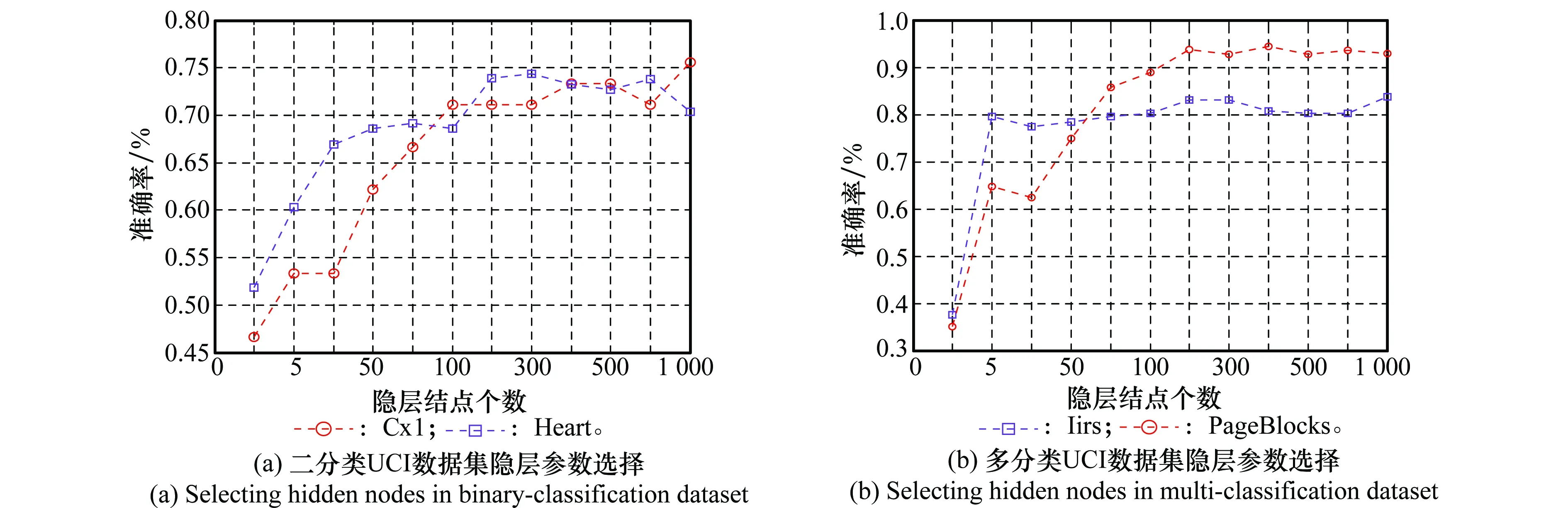
圖6 OSELM隱層參數(shù)選擇
4.4實(shí)驗(yàn)結(jié)果
4.4.1UCI數(shù)據(jù)集
表3給出在不同p值下所有UCI數(shù)據(jù)集的分類識別率。從表中可知不同數(shù)據(jù)集對應(yīng)不同的p值獲得的分類效果不同,例如,Segment數(shù)據(jù)集對應(yīng)p=3時(shí)獲得較高的分類效果,而Glass數(shù)據(jù)集中p=8,9時(shí)獲得較高的分類效果。由本文第3.1節(jié)分析可知,p越大所有的組合核函數(shù)權(quán)值越為平均,算法對所有特征空間平均融合。在該組實(shí)驗(yàn)中多數(shù)數(shù)據(jù)集在p為2時(shí)效果較好,后續(xù)實(shí)驗(yàn)中本文選擇p=2時(shí)的不同數(shù)據(jù)集實(shí)驗(yàn)效果對比。
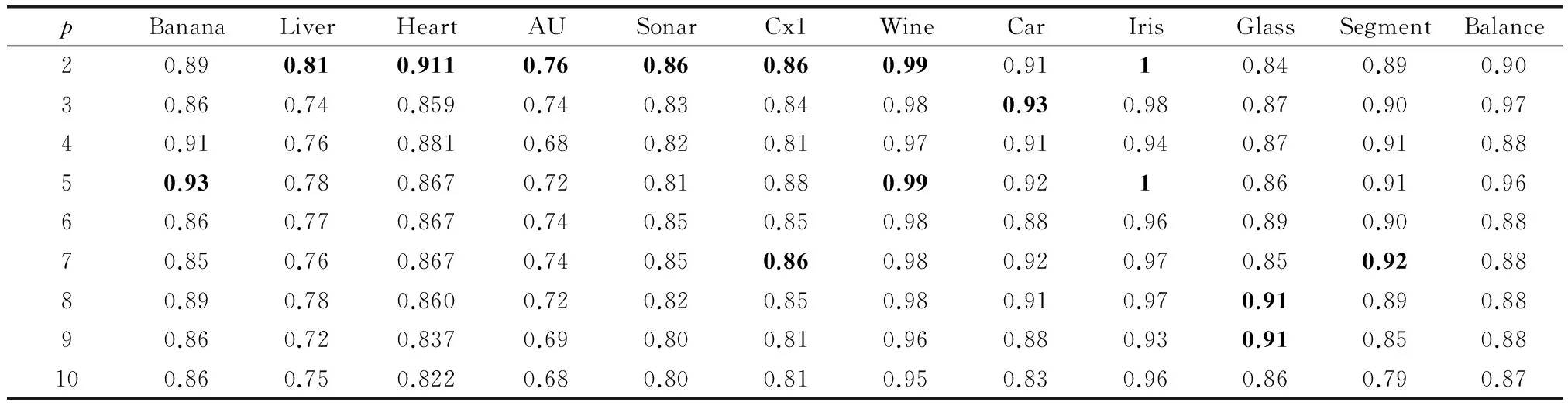
表3 不同p值時(shí)UCI數(shù)據(jù)集分類效果對比
為測試算法的增量學(xué)習(xí)能力與穩(wěn)定性,圖7給出了不同算法在UCI二分類數(shù)據(jù)集上的分類效果對比。從圖中可看到隨著數(shù)據(jù)量的增加,所有算法的分類準(zhǔn)確率均有所上升,在大部分?jǐn)?shù)據(jù)集上本文算法獲得了較好的分類效果,在Banana與Au數(shù)據(jù)集上SKC-OSELM算法在初期樣本量較少的情況下效果較差,但隨著樣本量的增加分類效果有所上升。從識別率曲線可見,對比算法,特別是OSELM算法曲線的波動(dòng)較大,說明該算法對動(dòng)態(tài)增量數(shù)據(jù)識別過程不穩(wěn)定。
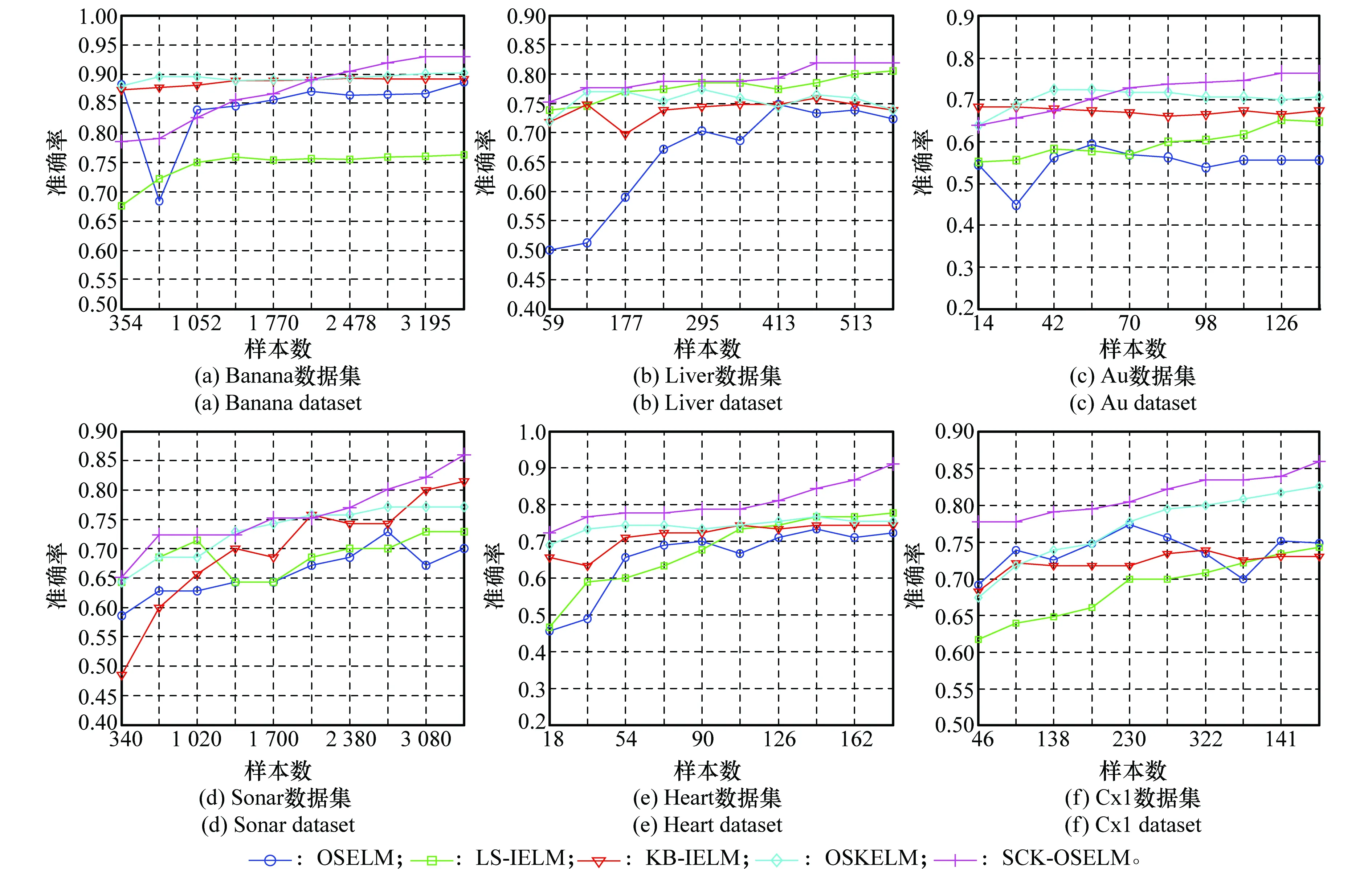
圖7 UCI二分類數(shù)據(jù)集實(shí)驗(yàn)對比結(jié)果
圖8為不同算法在UCI多分類數(shù)據(jù)集上的分類準(zhǔn)確率對比曲線,由圖可見本文算法在多數(shù)數(shù)據(jù)集上獲得了較好的分類效果,且隨數(shù)據(jù)量的增加平穩(wěn)上升。本文算法在數(shù)據(jù)集Glass上表現(xiàn)不如單核方法,該類樣本可能趨于單一分布,在多空間特征融合的情況下反而效果不佳。
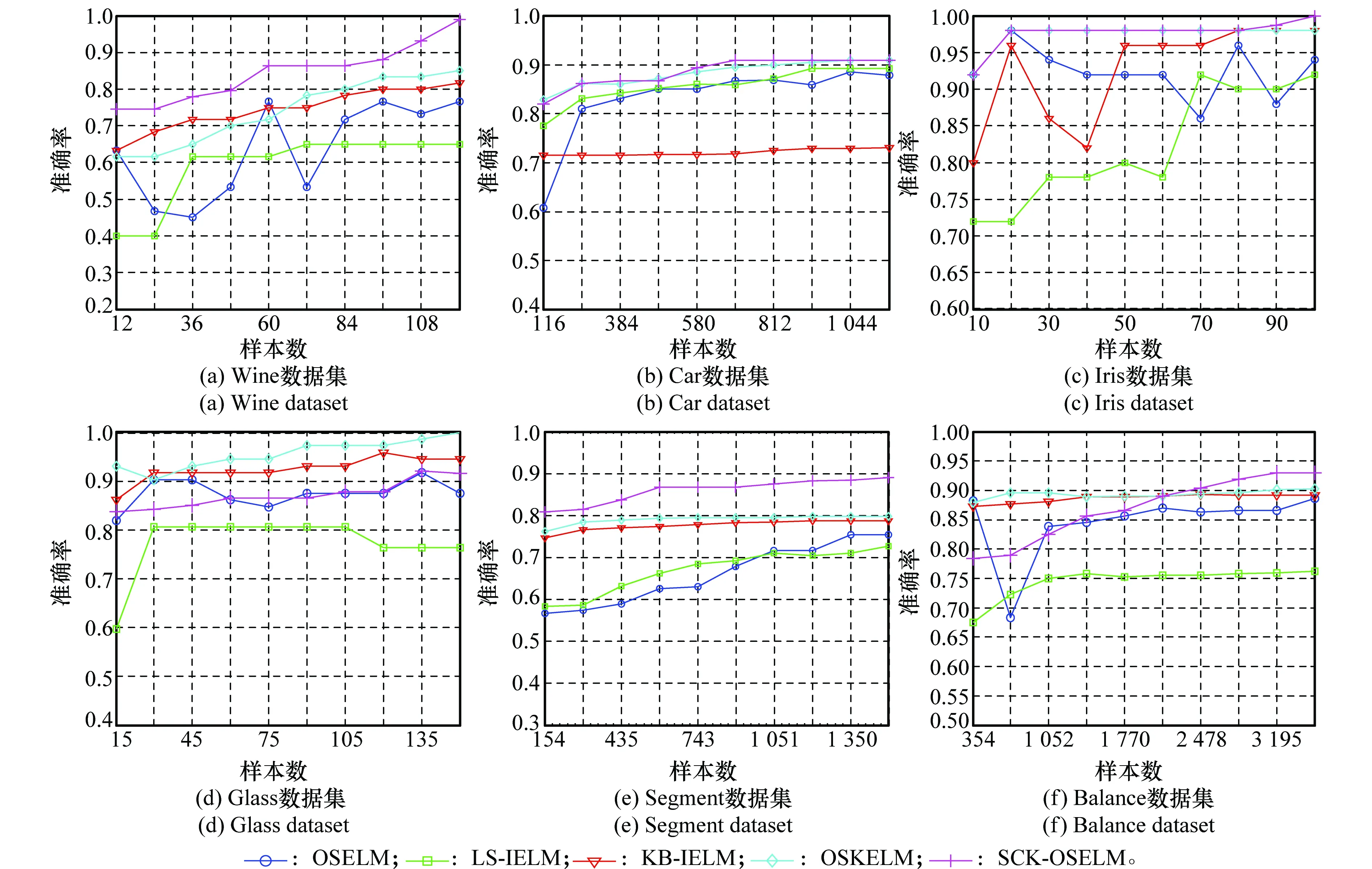
圖8 UCI多分類數(shù)據(jù)集實(shí)驗(yàn)對比結(jié)果
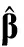

表4 Iris數(shù)據(jù)集算法運(yùn)行時(shí)間對比

表5 Banana數(shù)據(jù)集算法運(yùn)行時(shí)間對比
4.4.2MNIst數(shù)據(jù)集
表6給出了針對MNIst數(shù)據(jù)集的第一組實(shí)驗(yàn)中隨著p值的不同分類效果隨之改變,當(dāng)p=7時(shí)分類效果最好。對比實(shí)驗(yàn)中仍然選擇p=2的結(jié)果對比,表7中統(tǒng)計(jì)了3組實(shí)驗(yàn)中4種算法分別運(yùn)行10次分類準(zhǔn)確率的均值與方差。由表可知,針對于3組實(shí)驗(yàn)數(shù)據(jù),OSKELM的單核分類效果在實(shí)驗(yàn)1中優(yōu)于其他算法,當(dāng)樣本數(shù)量增加時(shí)SCK-OSELM與OSKELM算法效果相當(dāng)。SCK-OSELM在數(shù)據(jù)集維度較高且樣本量較小時(shí),效果不如單核算法。同時(shí),由于SCK-OSELM、OSKELM與KB-IELM算法無需隨機(jī)指定隱層參數(shù),獲得了較好的穩(wěn)定性。

表6 不同p值時(shí)MNIst-test1數(shù)據(jù)集分類效果對比
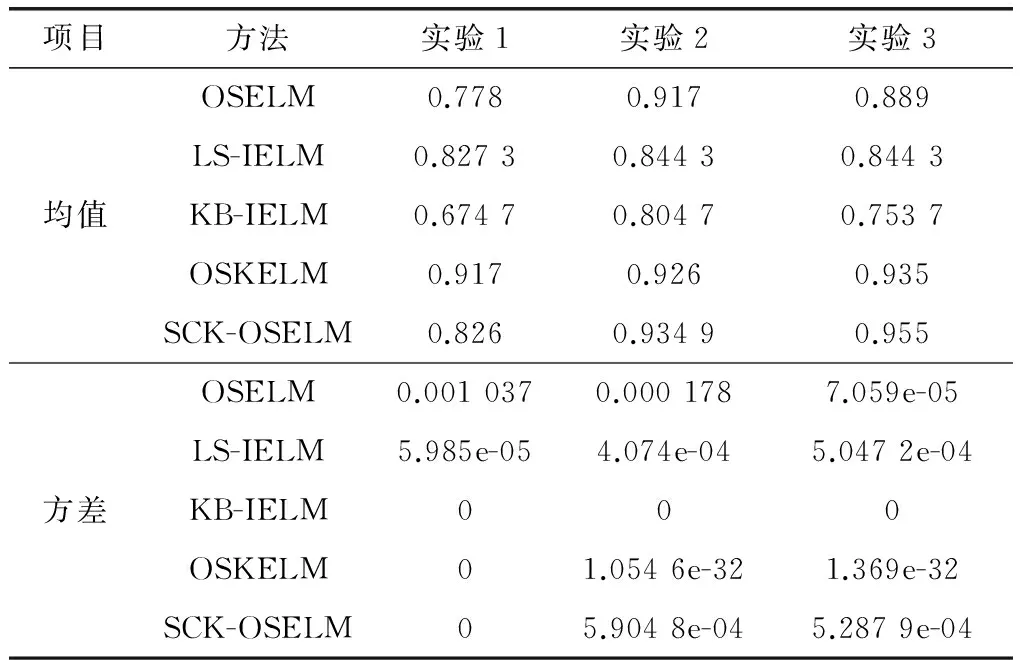
表7 MNIst數(shù)據(jù)集3組實(shí)驗(yàn)10次實(shí)驗(yàn)結(jié)果的均值與方差
4.4.3手工數(shù)據(jù)集
本文在手工數(shù)據(jù)集上對OSELM,OSKELM與SCK-OSELM的10次運(yùn)行均值與方差進(jìn)行了對比。從表8中可看到OSKELM與SCK-OSELM的方差為均較低,說明兩種算法的穩(wěn)定性遠(yuǎn)好于OSELM算法。同時(shí),由表9可見無論p為何值,SCK-OSELM算法的分類效果在該類非均勻樣本數(shù)據(jù)集中均高于其他兩種算法。
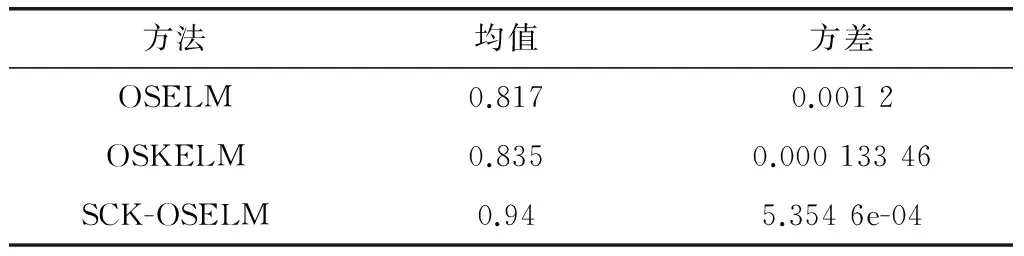
表8 手工數(shù)據(jù)集10次實(shí)驗(yàn)結(jié)果均值與方差

表9 不同p值時(shí)手工數(shù)據(jù)集分類效果對比
5 結(jié) 論
實(shí)際應(yīng)用中每一時(shí)刻涌入的動(dòng)態(tài)數(shù)據(jù)量越來越多,增量學(xué)習(xí)成為學(xué)者研究的熱點(diǎn)。本文針對有時(shí)間特性的增量數(shù)據(jù)分類問題,基于稀疏貝葉斯學(xué)習(xí)理論,提出了SCK-OSELM算法。首先,提出自組合方法對不同核空間特征進(jìn)行融合,這種新的組合核方法可被拓展應(yīng)用于其他監(jiān)督學(xué)習(xí)中。同時(shí),對未知標(biāo)簽數(shù)據(jù)輸出的概率分布進(jìn)行估計(jì),自動(dòng)使某些輸出權(quán)值調(diào)整為0,達(dá)到參數(shù)稀疏的目的。由于每次增量學(xué)習(xí)的過程僅需要將上次稀疏后的參數(shù)加入本次計(jì)算,不僅使得原有分類模型具有可追溯性,且降低了算法的空間復(fù)雜度。在每一次單獨(dú)計(jì)算中,利用最大化邊緣似然函數(shù)代替最小化模型訓(xùn)練誤差的方式,降低了模型的過擬合,提高了模型的泛化性。本文利用3組不同的數(shù)據(jù)集對模型的性能進(jìn)行驗(yàn)證,取得了較好的效果。但在實(shí)際應(yīng)用中無標(biāo)簽樣本越來越多,如何對半監(jiān)督的數(shù)據(jù)集進(jìn)行有效的增量分類將成為一個(gè)值得研究的問題。
[1] Coppock H W, Freund J E. All-or-none versus incremental learning of errorless shock escapes by the rat[J].Science, 1962, 135(3500): 318-319.
[2] O′Reilly C, Gluhak A, Imran M A, et al. Anomaly detection in wireless sensor networks in a non-stationary environment[J].IEEECommunicationsSurveys&Tutorials,2014,16(3):1413-1432.
[3] Helmbold D P, Long P M. Tracking drifting concepts by minimizing disagreements[J].MachineLearning, 1994, 14(1): 27-45.
[4] Kuh A, Petsche T, Rivest R L. Learning time-varying concepts[C]∥Proc.oftheAdvancesinNeuralInformationProcessingSystems,1991: 183-189.
[5] Klinkenberg R, Renz I. Adaptive information filtering: learning drifting concepts[C]∥Proc.oftheAAAIWorkshoponLearningforTextCategorization,1998: 33-40.
[6] Widmer G, Kubat M. Learning in the presence of concept drift and hidden contexts[J].Machinelearning,1996, 23(1): 69-101.
[7] Hamker F H. Life-long learning cell structures—continuously learning without catastrophic interference[J].NeuralNetworks, 2001, 14(4): 551-573.
[8] Eslami S M A, Tarlow D, Kohli P, et al. Just-in-time learning for fast and flexible inference[C]∥Proc.oftheAdvancesinNeuralInformationProcessingSystems,2014: 154-162.
[9] Tsai C J, Lee C I, Yang W P. Mining decision rules on data streams in the presence of concept drifts[J].ExpertSystemswithApplications, 2009, 36(2): 1164-1178.
[10] Liu J C, Miao Q G, Cao Y. Ensemble one-class classifiers based on hybrid diversity generation and pruning[J].JournalofElectronics&InformationTechnology, 2015, 37(2):386-393.(劉家辰, 苗啟廣, 曹瑩. 基于混合多樣性生成與修剪的集成單類分類算法[J]. 電子與信息學(xué)報(bào),2015, 37(2): 386-393.)
[11] Polikar R, Upda L, Upda S S, et al. Learn++: an incremental learning algorithm for supervised neural networks[J].IEEETrans.onSystems,Man,andCybernetics,PartC:ApplicationsandReviews, 2001, 31(4): 497-508.
[12] Zheng F, Shao L, Brownjohn J, et al. Learn++ for robust object tracking[C]∥Proc.oftheBritishMachineVisionConference, 2014: 1342-1346.
[13] Chen B, Meng B. Power transformer fault diagnosis system based on learn++[C]∥Proc.oftheAppliedMechanicsandMaterials,2014: 2053-2056.
[14] Ditzler G, Polikar R. Incremental learning of concept drift from streaming imbalanced data[J].IEEETrans.onKnowledgeandDataEngineering, 2013, 25(10): 2283-2301.
[15] Maloof M A, Michalski R S. Incremental learning with partial instance memory[J].ArtificialIntelligence, 2004, 154(1): 95-126.
[16] Klinkenberg R. Learning drifting concepts: example selection vs. example weighting[J].IntelligentDataAnalysis, 2004,8(3): 281-300.
[17] Furao S, Hasegawa O. An incremental network for on-line unsupervised classification and topology learning[J].NeuralNetworks, 2006, 19(1): 90-106.
[18] Friedman J, Hastie T, Tibshirani R.Theelementsofstatisticallearning[M]. Berlin:Springer, 2001:605-624.
[19] Huang G B. An insight into extreme learning machines: random neurons, random features and kernels[J].CognitiveComputation, 2014, 6(3): 376-390.
[20] Zhang J, Feng L, Wang L. Real-time big data classification under mapreduce[J].JournalofComputer-AidedDesign&ComputerGraphics, 2014, 26(8): 1263-1271. (張晶, 馮林, 王樂. MapReduce 框架下的實(shí)時(shí)大數(shù)據(jù)圖像分類[J]. 計(jì)算機(jī)輔助設(shè)計(jì)與圖形學(xué)學(xué)報(bào), 2014, 26(8): 1263-1271.)
[21] Liu X, Wang L, Huang G B, et al. Multiple kernel extreme lear-ning machine[J].Neurocomputing, 2015(149): 253-264.
[22] Wong P K, Wong H C, Vong C M, et al. Model predictive engine air-ratio control using online sequential extreme learning machine[J].NeuralComputingandApplications, 2014: 1-14.
[23] Wong P K, Vong C M, Gao X H, et al. Adaptive control using fully online sequential-extreme learning machine and a case study on engine air-fuel ratio regulation[J].MathematicalProblemsinEngineering, 2014.DOI: 10.1155/2014/246964.
[24] Horata P, Chiewchanwattana S, Sunat K. Robust extreme learning machine[J].Neurocomputing, 2013(102): 31-44.
[25] Zong W, Huang G B, Chen Y. Weighted extreme learning machine for imbalance learning[J].Neurocomputing, 2013(101): 229-242.
[26] Liang N Y, Huang G B, Saratchandran P, et al. A fast and accurate online sequential learning algorithm for feedforward networks[J].IEEETrans.onNeuralNetworks, 2006, 17(6): 1411-1423.
[27] Yin J C, Zou Z J, Xu F, et al. Online ship roll motion prediction based on grey sequential extreme learning machine[J].Neurocomputing, 2014(129): 168-174.
[28] Zou H, Jiang H, Lu X, et al. An online sequential extreme learning machine approach to WiFi based indoor positioning[C]∥Proc.oftheIEEEWorldonForumInternetofThings, 2014: 111-116.
[29] Deng W, Zheng Q, Chen L. Regularized extreme learning machine[C]∥Proc.oftheIEEESymposiumonComputationalIntelligenceandDataMining, 2009: 389-395.
[30] Guo L, Hao J, Liu M. An incremental extreme learning machine for online sequential learning problems[J].Neurocomputing, 2014(128): 50-58.
[31] Wang X, Han M. Online sequential extreme learning machine with kernels for nonstationary time series prediction[J].Neurocomputing, 2014(145): 90-97.
[32] Scardapane S, Comminiello D, Scarpiniti M, et al. Online sequential extreme learning machine with kernels[J].IEEETrans.onNeuralNetworksandLearningSystems, 2015, 26(9): 2214-2220.
[33] Bezdek J C, Hathaway R J.Somenotesonalternatingoptimization[M]. Heidelberg: Berlin, 2002: 288-300.
Incremental classification based on self-compounding kernel
FENG Lin1,2, ZHANG Jing1, WU Zhen-yu2
(1. School of Computer Science and Technology, Faculty of Electronic Information and Electrical Engineering, Dalian University of Technology, Dalian 116024, China; 2. School of Innovation Experiment, Dalian University of Technology, Dalian 116024, China)
Online sequential kernel extreme learning machine (OSELM) is an increment classification algorithm, and it only keeps training model at last time, then adjusts the original model from the current samples. However, it does not batch calculation when solving the problem of real-time dynamic data classification. This method by minimizing the empirical risk leads to the over-fitting, and randomly assigns hidden layer neurons in offline training, which makes the model have poor robust. Moreover, the solving process is difficult to be extended to the kernel method, which reduces the classification accuracy. Pointing to above-mentioned problems, a new online classification method, self-compounding kernels OSELM (SCK-OSELM), is proposed based on the kernel method. Firstly, inputted samples are mapped to multi-kernel spaces to obtain different features, and the nonlinear combination of features are calculated. Proposed self-compounding kernels method is used to others supervised kernel methods. Secondly, the prior distribution of training samples as model weights are introduced to maintain the model generalization, and by using the super weight to make the posterior distribution of weights to zero, thus sparse parameter is achieved. Finally, the parameter of sparse are incorporated into the next moment common operations. Numerical experiments indicate that the proposed method is effective.In comparison with OSELM, the proposed method has better performance in the sense of stability and classification accuracy, and is suitable for real-time dynamic data classification.
dynamic data; online sequential extreme learning machine; self-compounding kernel; sparse Bayesian
2015-10-26;
2016-03-16;網(wǎng)絡(luò)優(yōu)先出版日期:2016-07-06。
國家自然科學(xué)基金(61173163,61370200)資助課題
TP 319
A
10.3969/j.issn.1001-506X.2016.08.36
馮林(1969-),男,教授,博士,主要研究方向?yàn)橹悄軋D像處理、機(jī)器學(xué)習(xí)、數(shù)據(jù)挖掘。
E-mail:fenglin@dlut.edu.cn
張晶(1984-),女,博士研究生,主要研究方向?yàn)閿?shù)據(jù)挖掘、機(jī)器學(xué)習(xí)、計(jì)算機(jī)視覺。
E-mail:zhangjing_0412@mail.dlut.edu.cn
吳振宇(1971-),男,副教授,博士,主要研究方向?yàn)榍度胧较到y(tǒng)應(yīng)用、工業(yè)電源及傳感器。
E-mail: zhenyuwu@dlut.edu.cn
網(wǎng)絡(luò)優(yōu)先出版地址:http://www.cnki.net/kcms/detail/11.2422.TN.20160706.1030.004.html
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
中華詩詞(2018年11期)2018-03-26 06:41:34
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年8期)2016-10-09 02:11:50
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
