基于支持向量機的低收入通勤者出行方式預測*
2016-08-29 05:45:06陳學武王海嘯
武漢理工大學學報(交通科學與工程版) 2016年4期
程 龍 陳學武 楊 碩 王海嘯
(東南大學城市智能交通江蘇省重點實驗室1) 南京 210096)(現代城市交通技術江蘇高校協同創新中心2) 南京 210096)
?
基于支持向量機的低收入通勤者出行方式預測*
程龍1,2)陳學武1,2)楊碩1,2)王海嘯1,2)
(東南大學城市智能交通江蘇省重點實驗室1)南京210096)(現代城市交通技術江蘇高校協同創新中心2)南京210096)
為了研究支持向量機(SVM)在出行行為分析中的適用性,分析低收入通勤者的出行方式選擇,構建了基于支持向量機的出行方式選擇預測建模流程,并對模型求解.基于撫順市居民出行調查數據,統計結果表明低收入通勤者與非低收入通勤者的社會經濟屬性特征和活動特征具有顯著差異.選取分方式的分類預測準確率、總體分類預測準確率和平均絕對百分比誤差3個指標,通過與傳統的多項Logit模型對比,發現支持向量機對分類數據具有較好的擬合能力,出行方式選擇的預測準確率更高.
出行方式選擇;支持向量機;預測能力;低收入通勤者
0 引 言
研究分類變量選擇較常用的方法是離散選擇模型,但傳統的統計建模方法有一定不足,如要求樣本數據呈正態分布的假設、假設效用函數中自變量間呈線性關系等.當數據不能滿足上述假設時,傳統的建模方法得出的結論將會產生偏差.為了克服傳統方法的不足,有學者提出非參數建模方法來分析交通選擇問題,支持向量機(SVM)則是其中一種用于解決分類和回歸問題比較新的方法[1],近年來被廣泛應用于交通研究中.
Zhang等[2]運用支持向量機對高速公路短時交通流量進行預測,認為支持向量機能夠克服數據過度擬合和局部極小解的問題,具有更好的預測能力.Chen等[3]基于加州I-880號公路的交通事故數據,發現支持向量機在交通事故檢測方面具有較強的能力.Li等[4]證明支持向量機比傳統負二項回歸模型在事故嚴重等級預測方面的準確性更高,且收斂速率快.通過佛羅里達州326處高速公路分流區交通事故數據的分析,Li等[5]發現支持向量機在事故嚴重等級預測準確率比有序Probit模型高.可以看出,支持向量機在處理數據分類問題時,比傳統的統計模型有較高的數據擬合能力[6].
以往的研究多聚焦在交通流預測、交通事故分析等,較少研究出行方式選擇行為.低收入通勤者作為社會的構成的重要階層,在“交通公平性”的背景下,研究低收入者的出行行為具有重要意義.本研究基于支持向量機分析低收入通勤者出行方式選擇行為,探討其在出行行為分析方面的適用性,以豐富和增強交通需求預測的基礎理論.
1 數據來源及描述性統計
數據來自2014年10月29日(星期三)的遼寧省撫順市居民出行調查.調查內容分為2部分:(1)家庭和個人特征;(2)被調查者的1天出行記錄.在對調查數據校核和篩選后,最終獲得了8 585個有效個體樣本.經濟合作與發展組織提出的國際貧困線標準為當地人均可支配收入的50%[7].由此,2014年撫順市的貧困標準為1.4萬元/年.然后基于職業屬性,1 973個樣本被識別為低收入通勤者.
通過對比,發現低收入和非低收入通勤者的社會經濟屬性和活動屬性特征具有差異性,見表 1.低收入通勤者具有如下特征:家庭規模較大,小汽車擁有率較低,公交卡擁有率高,受教育水平較低;全日較少組織多個出行鏈,生存型活動(指上班和上學)時耗較長,機動化出行以公共交通為主,小汽車的出行比例較低.低收入和非低收入者選擇自行車和電動車出行的比例都較低,這是因為撫順市位于我國東北地區,受氣候和地形地貌的限制(天氣冷、道路坡度大),騎行環境較差.
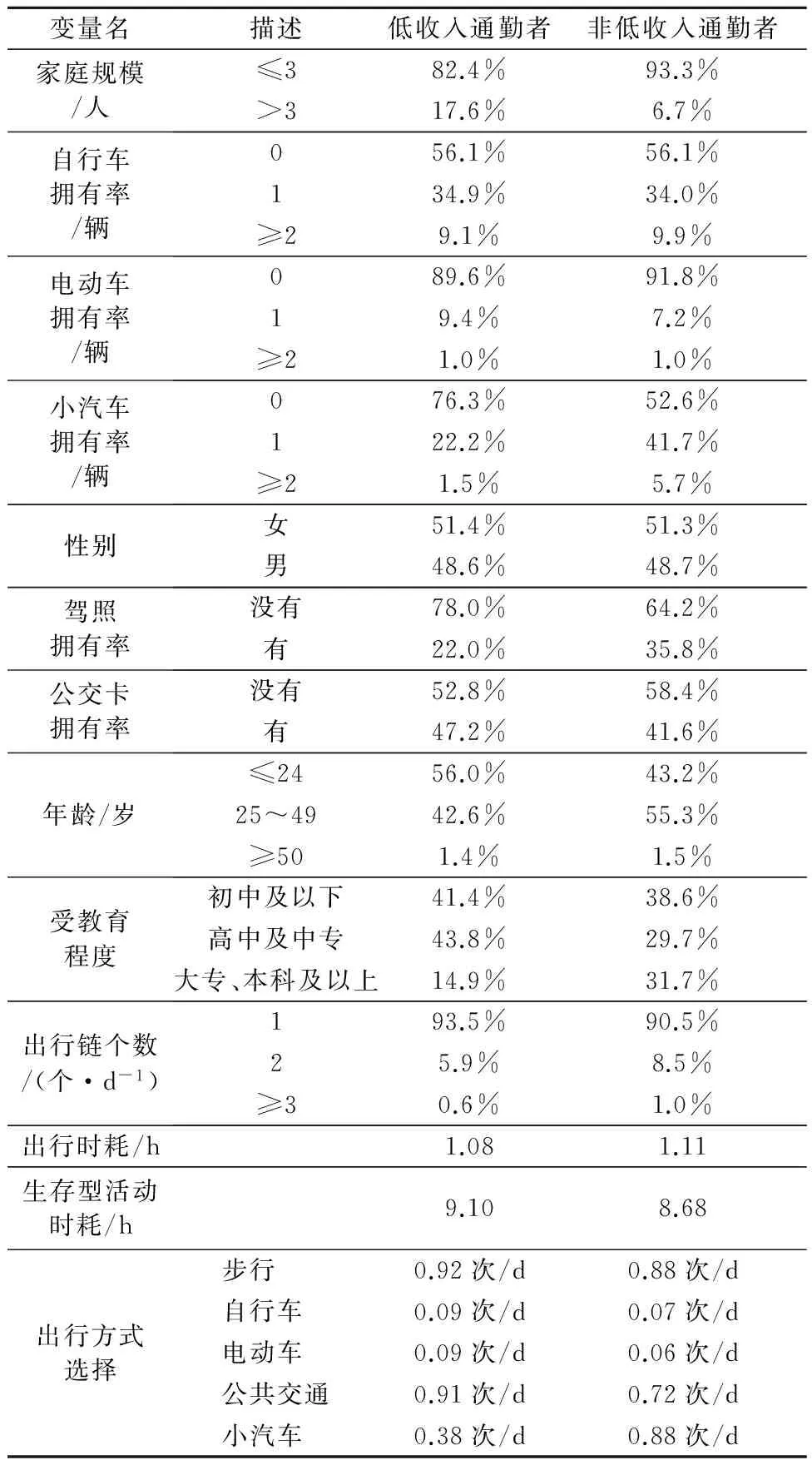
表1 社會經濟屬性和活動屬性特征差異
由于本研究涉及個體社會經濟屬性、活動屬性和方式選擇之間的關系,變量數量眾多,相互之間關系層次復雜,為了提高初始模型設定的準確性和有效性,需要對各變量間的關系進行顯著性檢驗.表1中的離散變量有家庭規模,自行車、電動車、小汽車擁有率,性別,駕照和公交卡擁有率,年齡,受教育程度,出行鏈個數.連續變量有出行時耗和生存型活動時耗.卡方檢驗(Pearson’s chi-squared)用于檢驗離散變量與出行方式選擇之間的顯著性,單因素方差分析(ANOVA)用于檢驗連續變量與出行方式選擇之間的顯著性.從檢驗結果發現,表 1中的變量都與出行方式選擇顯著相關,因此在建模時均予考慮.
2 研究方法
2.1支持向量機
支持向量機是從觀測樣本數據出發運用統計學的方法,對樣本數據規律進行學習,研究其內在的相互關聯聯系,同時利用該規律對未知數據進行預測估計.支持向量機的模型定義為特征空間上間隔最大的線性分類器,基本思想是尋找能夠將全部訓練樣本點正確分類的最優分類面,同時保證距離該分類面最近的樣本點與其間隔最大.學習策略是間隔最大化,最終轉化為凸二次規劃求解問題.
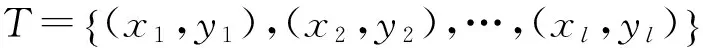
式中:w為分類面的法向量;b為常數項.
當訓練樣本集在低維空間不可分時,可以通過添加核函數K(xi,xj)將數據映射到高維空間中,以求解在原始空間中線性不可分的問題.當數據存在噪聲,可引入非負松弛變量εi≥0和懲罰因子C作為綜合權重來處理,則式(1)的最優化問題變為
2.2建模流程
基于支持向量機的低收入通勤者出行方式選擇預測建模流程如下.
1) 選擇影響低收入通勤者出行方式選擇的變量,對數據進行預處理,構造訓練樣本數據集.基于變量間的相關性檢驗結果,表 1中的所有變量均作為預測模型的輸入.
3) 構造優化問題,如式(2)所示,并對參數進行求解.
4) 求得最優解構建的決策函數,用測試樣本數據集預測其他低收入通勤者出行方式選擇結果.
模型建立后,采用5折交叉驗證來評價模型精度.也就是將原始數據均分成5組,將每個子集數據分別做一次驗證集,其余的4組子集數據作為訓練集,這樣會得到5個模型,用這5個模型驗證集的分類準確率的平均值作為分類器的性能指標.5折交叉驗證可以有效的避免過學習以及欠學習狀態的發生,最后得到的結果具有說服力.
對訓練樣本集學習過程中,需要確定兩個參數,即懲罰因子C和核函數參數r.采用網格搜索算法對參數尋優,網格搜索算法屬于啟發式算法,不必遍歷區間內所有的參數組就能找到全局最優解,具有收斂速度快的特性.
3 分析結果
3.1支持向量機
使用LIBSVM軟件包[8]來進行支持向量機模型的標定,事先將總體樣本按照4∶1的比例隨機分成訓練樣本集和測試樣本集.為了減少數據隨機分配產生的誤差,做了6次試驗以對低收入通勤者出行方式選擇進行訓練和測試.
以第1次試驗為例,詳細介紹SVM的訓練和測試過程.首先按4∶1的比例將總體數據分成1 578個訓練樣本和395個測試集樣本.然后,采用5折交叉驗證和網格搜索法進行參數(C,r)尋優,最終結果見圖 1.當訓練集驗證分類準確率最高時,C=147.033 4,r=0.006 8,此時的訓練集驗證分類準確率是62.29%.這樣就得到了對訓練樣本學習過程的模型,該模型是一個結構體,由該結構體中參數可以得到決策函數,該決策函數將用于測試樣本集數據的預測.

圖1 支持向量機參數尋優結果
6次試驗的分類準確率匯總情況見表 2.可以發現,支持向量機在訓練樣本集上分類準確率要大于測試樣本集.訓練樣本數據分類準確率平均值是68.59%,測試樣本數據分類準確率平均值是64.66%.此外,對于大樣本量的數據,支持向量機有很好的分類能力,如步行和公共交通,兩者在測試樣本中分類準確率分別是68.96%和76.84%.但對于小樣本量的數據,支持向量機的分類能力較差,如自行車和電動車,兩者在測試樣本中分類準確僅為16.34%和10.73%.這是因為支持向量機在工作過程中為提高整體分類準確率,會忽視小樣本量數據提供的信息.這個問題廣泛存在于多分類技術手段中,如分類樹、人工神經網絡和支持向量機[9].
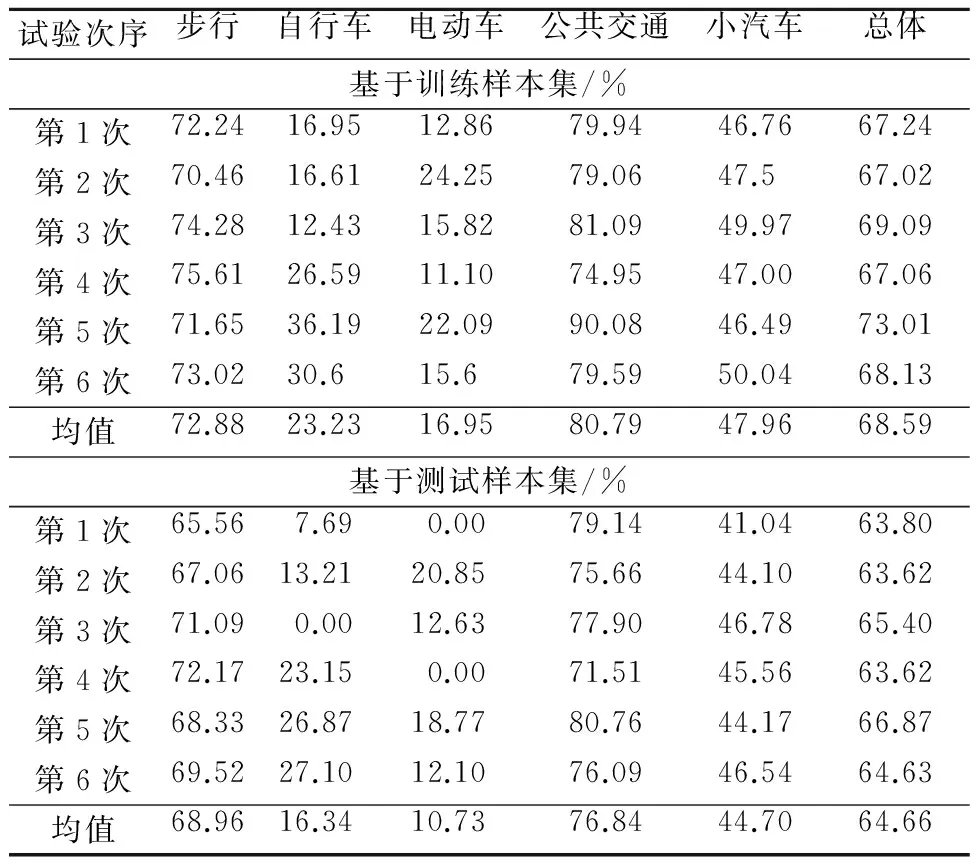
表2 支持向量機的分類準確率
3.2與多項Logit預測能力的對比
為了對比支持向量機與多項Logit(MNL)模型在低收入通勤者出行方式選擇的預測能力,基于相同的數據用MNL模型也做了6次試驗,首先用訓練樣本數據對MNL模型中的參數求解,然后基于求解的參數模型對測試樣本集中數據進行預測.選取3個指標進行對比,分別是分方式的分類預測準確率、總體預測準確率和平均絕對百分比誤差.
1) 分方式的分類預測準確率是指某種交通方式預測準確的樣本量占選擇該交通方式總樣本量的比例,結果見表 3.可以看出,各方式的平均預測準確率SVM均比MNL高,特別對于樣本量較小的自行車和電動車兩種出行方式,SVM準確率比MNL高很多,約10%,表明MNL模型在小樣本量數據上分類能力更差.

表3 分方式平均預測準確率 %
2) 總體分類預測準確率是指所有交通方式預測準確的樣本量占總體樣本量的比例.SVM的總體分類預測準確率高于MNL,兩者分別為64.66%和61.94%.此外,6次試驗中SVM預測準確率的方差為1.67,而MNL的方差為4.82,說明SVM在出行方式選擇方面的預測能力較為穩定,方差較小.
3) 平均絕對百分比誤差為預測值與實際值的差值占實際值百分比的算術平均數,公式為
(3)
(4)
式中:PEi為第i種交通方式選擇的百分比誤差;n為交通方式種類,本研究有5種;Xi為第i種交通方式實際選擇的樣本數;Fi為第i種交通方式預測的樣本數.指標對比結果見表 4,除第3次試驗外,SVM的預測平均絕對百分比誤差均小于MNL模型.而且從6次試驗整體看,SVM的預測平均絕對百分比誤差要小于MNL模型.

表4 平均絕對百分比誤差 %
從3個指標的對比可以看出,支持向量機比MNL模型在出行方式選擇的預測能力要好,支持向量機具有較高的處理數據分類問題的能力,在出行行為分析中具有較好的適用性.
4 結 束 語
基于撫順市居民出行調查數據,發現低收入通勤者與非低收入通勤者的社會經濟屬性特征和活動特征具有顯著差異.構建了基于支持向量機的出行方式選擇預測建模流程,然后對低收入通勤者的出行方式選擇行為進行分析,通過與MNL模型預測能力的對比,發現支持向量機在處理分類數據方面具有較高的擬合能力,在出行行為分析中具有較好的適用性.研究結論將為居民出行行為分析提供新的研究思路,豐富和增強交通需求預測分析的理論基礎.但是,本研究僅分析了支持向量機與MNL模型預測能力的對比,以后的研究可進一步考慮與其他傳統統計模型,如巢式Logit、混合Logit等的預測能力對比.
[1]鄭文昌,陳淑燕,王宣強.面向不平衡數據集的SMOTE-SVM交通事件檢測算法[J].武漢理工大學學報,2012,34(11):58-62.
[2]ZHANG Y L, XIE Y C. Forecasting of short-term freeway volume with v-support vector machines[J]. Transportation Research Record: Journal of the Transportation Research Board,2007,2024:92-99.
[3]CHEN S Y, WANG W, HENK J Z. Construct support vector machine ensemble to detect traffic incident[J]. Expert Systems with Applications,2009,36(8):10976-10986.
[4]LI X G, LORD D, ZHANG Y L, ME Y C. Predicting motor vehicle crashes using support vector machine models[J]. Accident Analysis and Prevention,2008,40(4):1611-1618.
[5]LI Z, LIU P, WANG W, et al. Using support vector machine models for crash injury severity analysis[J]. Accident Analysis and Prevention,2012,45:478-486.
[6]ALLAHVIRANLOO M, RECKER W. Daily activity pattern recognition by using support vector machines with multiple classes[J]. Transportation Research Part B: Methodological,2013,58:16-43.
[7]莫泰基.香港貧困與社會保障[M].香港:中華書局,1993.
[8]CHANG C C, Lin C J.LIBSVM: A library for support vector machines[EB/OL]. https://www.csie.ntu.edu.tw/~cjlin/libsvm/,2007.
[9]CHANG L Y, WANG H W. Analysis of traffic injury severity: an application of non-parametric classification tree techniques[J]. Accident Analysis and Prevention,2006,38(5):1019-1027.
Mode Choice Prediction of Low Income Commuters Based on Support Vector Machine
CHENG Long1,2)CHEN Xuewu1,2)YANG Shuo1,2)WANG Haixiao1,2)
(JiangsuKeyLaboratoryofUrbanITS,SoutheastUniversity,Nanjing210096,China)1)(JiangsuProvinceCollaborativeInnovationCenterofModernUrbanTrafficTechnologies,Nanjing210096,China)2)
To explore the applicability of support vector machine (SVM) in travel behavior analysis and shed light on mode choice of low income commuters, model specification scheme of mode choice prediction based on SVM is established. Statistics indicate that low income commuters have distinct socio-economic characteristics and activity characteristics from non-low income commuters based on the travel survey data of Fushun. SVM possesses high fitting ability on categorical data and provides better prediction accuracy of mode choice than traditional Multinomial Logit model from three indicators including the individual percentage of correct predictions, overall percentage of correct predictions and mean absolute percentage error.
mode choice; support vector machine; prediction ability; low income commuters
2016-07-07
U491.1
10.3963/j.issn.2095-3844.2016.04.010
程龍(1989- ):男,博士生,主要研究領域為從事交通出行行為分析與需求建模
*國家自然科學基金項目(51178109、51338003)、國家重點基礎研究發展計劃項目(973計劃)(2012CB725402)資助
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
