一種基于語音端點檢測的維納濾波語音增強算法
2016-09-14 09:17:16李戰明尚豐
電子設計工程 2016年2期
李戰明,尚豐
(蘭州理工大學 甘肅 蘭州 747300)
一種基于語音端點檢測的維納濾波語音增強算法
李戰明,尚豐
(蘭州理工大學 甘肅 蘭州747300)
在基于先驗信噪比的維納濾波語音增強算法的基礎上,結合語音端點檢測算法,本文提出一種新算法。新算法在語音端點檢測的基礎上,通過平滑處理更新噪聲信號功率譜以適應噪聲不穩定的環境;通過計算有聲段噪聲信號估計值,將有聲段的噪聲影響納入考慮范圍;通過每個語音段自適應調節噪聲功率譜,實時的計算出先驗信噪比。最后將該算法與改進前算法進行仿真比較驗證,該算法有更好的語音增強效果,在非穩定噪聲環境中較好的抑制了噪聲殘留,提高了語音的可懂度。
語音端點檢測;語音增強;噪聲功率譜;維納濾波
語音增強是利用某種算法抑制噪聲的干擾,提高語音的信號質量。語音增強算法可以去除噪聲,也可以稱為語音去噪,它被廣泛的應用到網絡、手機、助聽器等領域中,是近年來發展較快的一種語音技術[1]。
基于短時譜估計的語音增強算法具有適用信噪比范圍廣、實時性較強、算法計算量不大等特點,是應用范圍最廣泛的語音增強算法。基于短時譜估計的算法有譜減法、維納濾波法、最小均方誤差法等,傳統的算法在不同程度上存在殘留噪聲大、語音失真嚴重等問題。Ephriam等人[2]提出在計算濾波器傳遞函數時引入先驗信噪比,并對先驗信噪比進行估計,從而有效的抑制殘留噪聲。文獻[3-4]中對上述方法進行了改進,通過計算無語音期間噪聲的統計平均來計算當前幀的先驗信噪比,這顯然是不夠的。上述方法在噪聲變化范圍不大或者噪聲穩定的環境下能有效的進行語音增強,但是在噪聲變化范圍較大、低信噪比環境下效果不是很明顯。
本文首先介紹了維納濾波語音增強算法的基本思路,在推導先驗信噪比和后驗信噪比的基礎上結合語音端點檢測算法(VAD)提出了一種新的維納濾波語音增強算法。通過仿真實驗,比較了改進前算法和改進后算法以及常用的譜減法,實驗結果表面改進后算法提高了增強效果,更有效的抑制了噪聲,提高了語音質量。在最后的客觀評價法與主觀評價法打分后證明改進算法有更好的效果。
1 未改進的維納濾波語音增強算法
設帶噪語音為y(n)=s(n)+d(n),式中,s(n)為語音信號;d(n)為噪聲信號。只有帶噪語音信號為可測信號,維納濾波方法的基本思路就是設計一個數字濾波器h(n),當輸入y(n)為時,濾波器的輸出為:按照最小均方誤差準則有均方誤差達到最小。由于噪聲與語音互不相關,取傅里葉變換后可以導出:,有了維納濾波的譜估計器H(k)后,計算在頻域第k個頻點上語音頻譜的估算值,Y(k)是帶噪語音在頻點上的頻譜值。由于語音只是短時平穩的且功率譜無法得到,故,同除Pd(k)可得:


式中,下標i表示第i幀,式(3)表明,有第i-1幀的先驗信噪比及第i幀的后驗信噪比可求出第i幀的先驗信噪比,即可求出本幀的維納濾波器傳遞函數:

2 改進后的算法
在基于先驗信噪比的維納濾波法中,需要估計當前幀的噪聲功率譜,改進前的算法是將無聲段的統計平均當做噪聲功率譜[3-4],這種假設僅適用于環境噪聲不變或者變化較小的情況,很顯然這種假設不是全面的。未改進的算法對于抑制不變的環境噪聲效果較好,但是在噪聲不穩定的環境下效果不佳。為了解決上述問題,本文提出新的改進算法。首先對帶噪語音進行語音端點檢測[5-6](VAD),分辨出無聲段和語音段;然后在每個語音段前的無聲段開始部分(取NIS幀)計算噪聲功率譜的初值,通過平滑處理噪聲功率譜初值與無聲段噪聲功率譜不斷更新噪聲功率譜,得到最新的無聲段用噪聲功率譜;最后在有語音段中,用帶噪功率譜減去語音功率譜估計值得到有聲段中的噪聲功率譜估計值。新算法考慮了環境噪聲的變化,通過更新噪聲功率譜來適應環境噪聲的變化,考慮了有聲段噪聲的影響,使噪聲功率譜涵蓋噪聲更全面,在一定程度上改善了之前算法僅適用于穩定噪聲的缺陷,并有效的消除了殘留噪聲。
首先進行語音端點檢測(VAD),確定語音開始端點,在無聲段中的開始部分取一小段(NIS幀)計算噪聲平均功率譜初值:
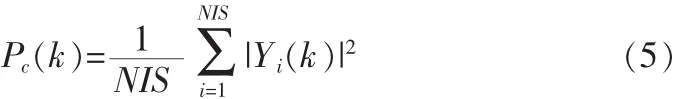
在之后的無聲段進行平滑處理,更新噪聲功率譜:

式中,Pgi(k)是第i幀噪聲功率譜估計值,Pgi-1(k)是第 i-1幀噪聲功率譜估計值,NoiseLength是設置的噪聲平滑區間長度。

用Pvi(k)來更新噪聲功率譜,將有聲段的環境噪聲也考慮進去。由于Pvi(k)是二次估計
所得,誤差較大,所以在更新噪聲功率譜時平滑區間長度NoiseLength要比無聲段的大。通過這樣的調整,可以較好的濾除變化較大的不穩定噪聲。
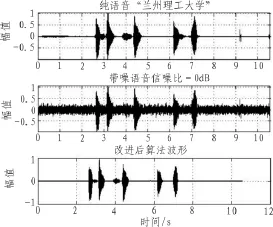
圖1 疊加粉紅噪聲后維納濾波仿真結果Fig.1 The result of superimposing pink noise Wiener filter simulation
改進算法的具體實施步驟為:
1)帶噪語音為y(n),加窗分幀后為yi(n),相鄰窗之間有重疊,并進行FFT,求出幅度譜|Yi(k)|和相位譜θi(k),并保存;
2)語音端點檢測,在無聲段開始處取NIS幀計算初始噪聲功率譜
3)用式(6)更新噪聲功率譜估計值Pc(k),直到有聲段開始;
4)在有聲段通過式(7),計算Pvi(k),通過新的平滑系數平滑得到噪聲功率譜估計值;
6)通過式(4)求得維納濾波器函數Hi(k),可以導出
8)語音端點檢測到有聲段結束端點,清零并重復步驟(1)。
3 仿真實驗結果
改進算法后在MATLAB中進行仿真比較,將作者的青年男音“蘭州理工大學”疊加0dB粉紅噪聲后仿真結果如圖1。
為了說明一般性,錄制男女各10人,樣率為8 000 Hz、16bit量化的純凈語音信號,疊加不同信噪比白噪聲和粉噪聲,以對比改進前與改進后算法的效果。用客觀評價方法信噪比對比以及對數倒譜距離法LCD[7],改進后的算法效果優于之前的算法及譜減法,如表1、表2所示。
從表1和表2中可以看出,與語音端點檢測算法結合的維納濾波法在整體信噪比評價與LCD評價中效果要好于改進前的算法。
選取聽力正常的十個人進行MOS[8-11](Main Opion Score)主觀打分并取平均值,由于影響MOS得分的條件除語音增強效果外,還要考慮語音失真的影響,表3所示新算法在語音失真的消除上也有一定效果

表1 不同算法改善的信噪比對照表Tab.1 The comparison of different algorithm improvement in SNR
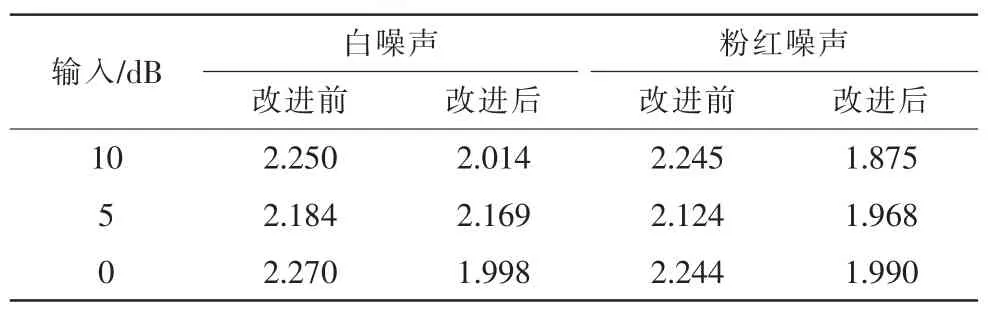
表2 不同算法增強后倒譜距離對照表Tab.2 The comparison of different algorithm improvement in LCD
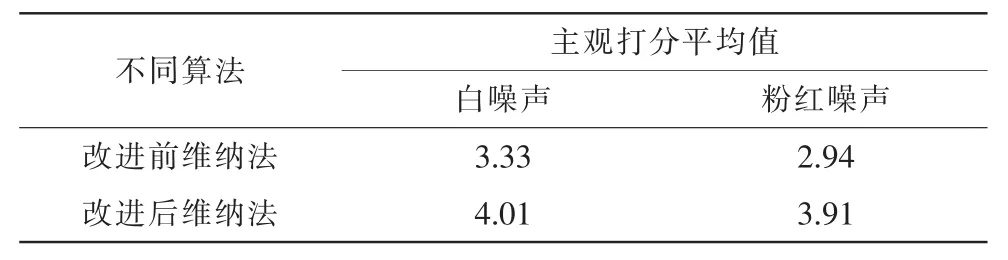
表3 不同算法的MOS評價Tab.3 The evaluation of different algorithm
4 結 論
本文提出了一種基于語音端點檢測算法的維納濾波法,與傳統的維納濾波法相比,不僅提高了信噪比,在語音失真的消除方面也有較好的效果。在非穩定噪聲環境下,新算法仍有較好的增強效果。
[1]Lim J S,Oppenheim A V.Enhancement and bandwidth compression of noisy speech[C]//Proceedings of the IEEE,1979,67:1586-1604.
[2]Ephraim Y,Malah D.Speech enhancement using a minimum mean-square error log-spectral amplitude estimator[J].IEEE Trans on Acoustics,Speech,Signal Processing,1985,ASSP-32:443-445.
[3]Scalart P,Vieira-Filho J.Speech enhancement based on a priori signal to noise estimation[C]//Proc 21st IEEE Int Conf Acoust Speech Signal Processing,Atlanta,GA,1996,2(2): 629-632.
[4]Cohen I.Speech enhancement using a noncausal a priori SNR estimator[J].IEEE Signal Processing Letters,2004(9): 725-728.
[5]Shen J,Hung J,Lee L.Robust Entropy-based Endpoint Detection for Speech Recognition in Noisy Environments[C]// Proceeding of International Conference on Spoken Language Processing.Sydney:[s,n],1998:232-238.
[6]王琳,李成榮.一種基于自適應譜熵的端點檢測改進方法[J].計算機仿真,2010,27(12):373-375.
[7]陳國,胡修林,張蘊玉,等.語音質量客觀評價方法研究進展[J].電子學報,2001,29(4):548-552.
[8]Pachl W,Urbanek G,Rothauser E.Preference evaluation of a large set of vocoded speech signals[J].IEEE Transaction on Audio and Electronics,1971,19(3):216-224.
[9]肖鋒.維納濾波在退化圖像恢復中的應用研究[J].電子設計工程,2011(8):173-175.
[10]李軒,韓笑,關慶陽,等.基于濾波方法的OFDM信道估計研究[J].電子設計工程,2014(12):145-147,151.
[11]周小軍,譚薇,張燎,等.遙感圖像常用去噪方法[J].工業儀表與自動化裝置,2015(3):69-72.
A wiener filtering speech enhancement algorithm based on speech endpoint detection
LI Zhan-ming,SHANG Feng
(Lanzhou University of Technology,Lanzhou 747300,China)
Based on the Wiener filtering speech prior SNR enhancement algorithm,this paper proposes a new algorithm combined with the speech endpoint detection algorithm.Based on the speech endpoint detection algorithm,the new algorithm updates the power spectrum of the noise signal by smoothing the power spectrum in order to adapt to the noise and unstable environment;The new algorithm takes the influence of the noise into account by calculating the estimate value of the sound segment noise,and calculates the priori SNR in real time by each sound segment adaptive noise power spectrum.Finally,compare the algorithm and improved algorithm by simulation verification,the improved algorithm suppresses the residual noise in the unstable noise environment,and improves the speech intelligibility.
voice activity detection;speech enhancement;noise power spectrum;wiener filtering
TN912
A
1674-6236(2016)02-0042-03
2015-03-13稿件編號:201503189
李戰明(1962—),男,陜西西安人,教授、博導。研究方向:復雜系統的建模與控制,神經模糊系統與軟計算,智能信息處理與模式識別,計算機控制系統的理論與工程等。
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
Coco薇(2016年8期)2016-10-09 02:11:50
海峽科技與產業(2016年3期)2016-05-17 04:32:12
