基于Hadoop的排序性能優化研究
2016-09-14 09:17:18李千慧魏海平竇雪英
電子設計工程 2016年2期
關鍵詞:排序
李千慧,魏海平,竇雪英
(1.遼寧石油化工大學 計算機與通信工程學院,遼寧 撫順 113001;2.中國寰球工程公司遼寧分公司信息中心 遼寧 撫順 113006)
基于Hadoop的排序性能優化研究
李千慧1,魏海平1,竇雪英2
(1.遼寧石油化工大學 計算機與通信工程學院,遼寧 撫順 113001;2.中國寰球工程公司遼寧分公司信息中心 遼寧 撫順 113006)
如何高效排序是在對大數據進行快速有效的分析與處理時的一個重要問題。首先對基于Hadoop平臺的幾種高效的排序算法(Quicksort,Heapsort和Mergesort算法)進行了研究。再通過對Hadoop平臺的幾種現有的排序算法的分析比較,發現頻繁的讀寫磁盤降低數據處理的效率,提出了一種優化現有排序算法的置換選擇算法,并進行了測試。測試結果表明,該算法簡化了運行過程,可實現更快速的合并,從而提高數據處理的效率,對Hadoop的性能優化具有現實意義。
Hadoop;排序優化;置換選擇算法;大數據
隨著互聯網等信息技術的飛速發展,網絡用戶的快速增加,各行各業中的數據也日益增長,形成了海量數據。這些數據是不但數據體量巨大,而且是高價值的,具有多樣化和持續性等特點。其非結構化的特性,使得數據的存儲和處理成了當前面臨的挑戰。這些數據需要在大型的分布式集群上來處理。如何有效地處理這些并行的計算,管理海量分布式的數據以及對大數據進行分析與處理,成為急需解決的重點問題。MapReduce是一個廣泛應用于大數據分析和處理的計算框架[1-2]。Hadoop作為Apache開源組織的一個分布式計算并行編程框架[3],能夠實現MapReduce計算模式的分布式并行編程,逐漸成為業界使用的標準。Hadoop已經應用在許多國內外的知名網站上,如Facebook、雅虎和百度等。其分布式文件系統的高容錯性和高擴展性,能夠滿足數據量迅速增長的需要,所以已經廣泛的用來解決海量數據的處理問題[4]。
本文經過對MapReduce計算模式研究后發現,MapReduce中的缺省排序本身既是一種對數據普遍的處理方式,也是一種預處理。但是針對日益增長的海量數據的分析處理,傳統的排序方法由于大多是基于關鍵字的比較和交換兩種操作,導致多次讀取磁盤,所以消耗時間較多,難以有效地處理數據。本文通過優化排序減少對磁盤的讀寫操作,能使得后續處理更加高效、快捷。
1 Hadoop中的排序
排序算法分為兩類:內部排序和外部排序[5-6]。內部排序是指輸入數據在內存中進行排序,包括Quicksort,Heapsort和Mergesort等算法。當需要對一個非常大的文件中的內容進行排序時,由于計算機內存是有限的,數據不能完全存入內存時,則無法使用內部排序算法一次完成排序,需要利用磁盤空間進行外部排序。
1.1Hadoop中排序機制及排序算法
在Hadoop分布式環境中,Hadoop的排序功能是非常強大的,能夠對TB級數據進行排序。當輸入記錄的規模較大時,利用快速排序、堆排序、歸并排序這些時間復雜度為O (nlog(n))的排序算法。
1.1.1Quicksort
快速排序(Quicksort)是一個交換的排序算法,在實際中經常被使用,例如Microsoft.NET框架中。該算法被遞歸地應用到每個子集,直到所有記錄都在它們的最終位置,其核心是分區操作。在Hadoop中的快速排序算法是通過自定義分區函數以保證數據整體有序。數據經過map函數操作后,通過分區函數進行數據等距劃分后進行快速排序,不同范圍內的數據劃分到不同分區后由對應的reduce處理,最后按序收集各個reduce的數據。
Quicksort在最壞情況下的復雜度為O(n2),但是在實際中,通常比其他復雜度為O(nlog(n))的算法快。
1.1.2Heapsort
堆排序是基于堆的排序,分為最大堆和最小堆,可以用完全二叉樹來表示。如圖1所示是一個最大堆(由一個數組構成)及其相應的二叉樹。
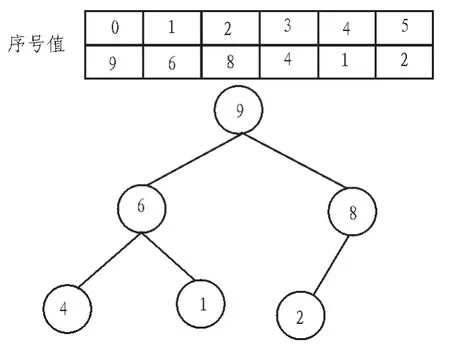
圖1 數組與相對的完全二叉樹Fig.1 Array and the corresponding complete binary tree
本質上講,堆排序是一種選擇排序,只不過堆排序選擇元素的方法更為先進,時間復雜度更低,效率更高。堆排序主要用于形成和處理優先級隊列,以及類優先級隊列。
1.1.3Mergesort
歸并排序的排序方式是基于歸并操作的,是將兩個或兩個以上的有序排列合并成一個大的有序文件。雖然它與快速排序和堆排序相比更加穩定,時間復雜度在最壞的情況下也是O(nlog(n)),但卻需要O(n)的輔助空間。
1.2Hadoop平臺處理流程
Hadoop框架實現了 MapReduce的分布式并行編程,MapReduce的處理流程圖如圖2所示[7]。
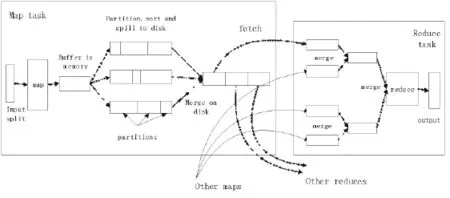
圖2 MapReduce的處理流程Fig.2 The processing of MapReduce
MapReduce框架分為 Map與Reduce兩個核心處理階段。
Map階段:
1)將輸入數據做切片處理后交給map函數。
2)運行map函數,其產生的中間輸出結果(key/value對)存入內存緩沖區中。
3)根據最終被傳送到的reduce對中間結果進行分區,排序后寫入本地磁盤。
在Reduce階段分為3個部分:
1)復制來自若干個map任務的輸出文件。
2)對從map階段復制過來的文件進行歸并排序,形成一個大而有序的文件。
3)將歸并后的有序文件交給reduce()函數處理,將輸出寫入Hadoop的分布式文件系統。
1.3Hadoop中排序性能分析
Hadoop集群環境中的應用程序只需要實現 map和reduce方法即可,但是由于需要sort,必須等記錄全部接收完,才能開始排序,排序完了才能調用reduce()函數,嚴重影響了程序運行效率。對于大文件的排序,Hadoop現有的排序方式是將大文件分成n個小文件,分別對這些小文件利用內部排序(快速排序、堆排序等)算法排序。然后再對這些文件進行兩兩歸并,直至歸并成一個大的有序文件。這樣歸并的趟數比較多,導致讀寫文件的I/O次數增多。相對于內存中的運算,對文件的讀寫操作是特別費時間的。
在Hadoop集群中,MapReduce的自動排序有m個map,r個reduce。數據被分割成m塊的時間復雜度為O(m),每個map進行Quicksort時間復雜度為O(n/mlog(n/m))。當排序任務負載均衡度不高,排序對磁盤反復的操作,加之集群運行時間消耗及網絡傳輸,則Hadoop下Quicksort效率可能低于O(nlog(n))。
2 一種改進的置換選擇算法
2.1改進算法的描述
本文提出一種優化Hadoop現有排序的算法,用于生成較長的順串(初始歸并段),以減少歸并段的段數。在接收輸入數據時使用改進的排序算法生成初始段,用敗者樹從已經傳遞到內存中的記錄中找到關鍵值最小的記錄并輸出,得到一個順串,暫時放到磁盤,最后將多個順串進行歸并直到最終完成排序。歸并的同時,就可以回調reduce()函數,這樣就可以一邊接收數據,一邊部分排序,實現MapReduce的并行化。具體步驟如下:
步驟1:從輸入文件中讀取n條記錄到內存里。
步驟2:用敗者樹篩選出關鍵字最小的記錄記為MIN,輸出到一個臨時文件中(或緩存區)。
步驟3:從輸入文件中再讀取一條記錄到內存里 ,用敗者樹的一次調整過程找到關鍵字大于MIN的最小值輸出到MIN所在的文件(或緩存區)并作為新的MIN。
步驟4:重復步驟3,直到在內存中選不出關鍵字大于MIN的記錄,生成一個順串,并輸出一個歸并段結束標簽到輸出文件。
步驟5:重復步驟2、3、4,直至內存為空,得到全部歸并段。將生成的順串做歸并處理,形成一個大的排好序的文件。
利用敗者樹在內存中篩選MIN細節:1)敗者樹的外部節點為內存空間中的記錄,而敗者樹中根節點的雙親節點為內存中關鍵字最小的記錄。2)為每個記錄設一個所在歸并段的序號,簡稱為段號。篩選MIN記錄時,比較段號的大小即可,段號小的為勝者;段號相同的,關鍵字小的為勝者。
2.2算法性能分析
改進的算法在排序過程中創建初始歸并段,總數據量一定的情況下,初始歸并段的平均長度變長,從而減小了初始歸并段的段數n。處理過程中的歸并趟數為logkn,雖然增大歸并路數k可以減少對磁盤的操作,但是歸并時的算法復雜度也會增加。改進后的算法由于減小了歸并段數,可以在O(logk)的復雜度下得到最小的數,每次只需比較log2k次,算法復雜度將為O((n-1)*logk)。對于數據量超大的排序來說,這是可觀的提高。
改進后的算法能夠從map task端完整的把數據復制到reduce task端,尤其是跨節點復制數據,最大化的降低了復制數據的量以及對帶寬的消耗,以盡量減少磁盤I/O對Job完成時間的影響,減少了不必要的消耗。
3 實 驗
3.1實驗環境
本文實驗在一臺PC機上搭建偽分布式環境,包含3個節點,一個Master,兩個slave節點,而且兩個slave的配置保持一致:PC內存8G,64位WIN8系統,虛擬硬件為1G內存,雙核處理器,IDE硬盤;以 centOS6.5作為操作系統,JDK 1.7.0作為基礎平臺,搭建Hadoop1.1.2平臺作為底層架構,Eclipse作為編程環境,集群各節點之間SSH免密碼登錄,虛擬機之間的通信通過虛擬網橋實現。數據來源為搜狗搜索引擎:http://www.datatang.com/data/43846。
3.2實驗結果與分析
由圖3可以看出,在相同輸入量的情況下,經過優化后的置換選擇算法比傳統快速排序算法的速度快。在數據規模較大的排序過程中改進后的效率明顯好于傳統排序方式。
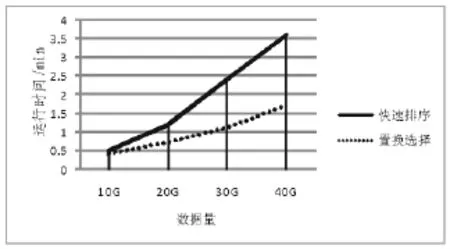
圖3 優化前后性能對比Fig.3 The performance comparison before and after optimization
4 結束語
本文針對Hadoop框架實現大規模數據處理的排序進行了研究。首先,基于搭建好的Hadoop偽分布式環境分析了排序算法,提出了改進算法——置換選擇算法,然后運行MapReduce程序比較了在具有相同輸入量的情況下數據處理的時間。實驗結果表明,在對相同的較大數據量進行排序時,置換選擇算法優化了基于Hadoop的排序。
[1]EKANAYAK J,PALLICKARA S,FOX G.MapReduce for data intensive scientific analyses[J].Fourth IEEE International Conference on eScience,2008,7(12):277-284.
[2]李建江,崔健,王聃,等.MapReduce并行編程模型研究綜述[J].電子學報,2011,39(11):2635-2642.
[3]Dhruba B.Apache Hadoop filesystem and its usage in facebook project lead[EB/OL].[2014-11-20].http://cloud.berkeley.edu/data/hdfs.pdf.
[4]KONSTANTINS,HAIRONGK,SANJAYR,etal.The Hadoop distributed file system[C]//Proceedings of IEEE 26th Symposium on Mass Storage Systems and Technologies.Incline Village:[s.n],2010:1-10.
[5]JACK D,FRANCIS S.Guest editors′introduction:The top 10 algorithms[J].Computing in Science&Engineering,2000,2(1):22-23.
[6]VITTER J S.Algorithms and data structures for external memory[J].Foundations&Trends in Theoretical Computer Science,2006,2(4):29-56.
[7]TOM W.Hadoop:The definitive guide[M].3rd ed.The United States of America:O′Reilly Media,Inc,2009.
Optimization of sorting performance based on Hadoop
LI Qian-hui1,WEI Hai-ping1,DOU Xue-ying2
(1.School of Computer and Communication Engineering,Liaoning University of Petroleum&Chemical Technology,Fushun 113001,China;2.Information Center HQC(Liaoning)CO.,Fushun 113006,China)
When people analysising and processing big data fast and efficiently,how to efficiently sorting is an important issue.There have several efficient sorting algorithms,including Quicksort,Heapsort and Mergesort algorithm,ware studied based on Hadoop platform.Through analysis and the differences of several existing sorting algorithms in Hadoop platform,frequently operating on disk reducing the efficiency of data processing was discovered,so a new sorting algorithm,replacement and selection algorithm,was proposed to optimize the existing sorting algorithm.New algorithm has been tested,and the test results have shown that the new algorithm simplified the process of running,could achieve a more rapidly consolidation,improving the efficiency of data processing,so had practical significanceon Hadoop performance optimization.
Hadoop;optimization of sorting;replacement selection algorithm;big data
TN919
A
1674-6236(2016)02-0045-03
2015-03-31稿件編號:201503462
遼寧省教育科學“十二五”規劃立項課題(JG12DB279;JG13DB077)
李千慧(1989—),女,內蒙古自治區赤峰人,碩士研究生。研究方向:計算機網絡與多媒體技術。
猜你喜歡
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
名家名作(2021年9期)2021-10-08 01:31:36
名家名作(2021年4期)2021-05-12 09:40:02
名家名作(2021年3期)2021-04-07 06:42:16
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
新世紀智能(語文備考)(2019年12期)2020-01-13 06:04:32
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
名家名作(2017年2期)2017-08-30 01:34:24
