一種基于權重的云服務搜索算法
2016-09-26 07:19:52孫寒玉顧春華楊巍巍
計算機應用與軟件 2016年3期
關鍵詞:服務
孫寒玉 顧春華 萬 鋒 楊巍巍
(華東理工大學信息科學與工程學院 上海 200237)
?
一種基于權重的云服務搜索算法
孫寒玉顧春華萬鋒楊巍巍
(華東理工大學信息科學與工程學院上海 200237)
云計算技術迅猛發展,眾多云服務的功能和服務質量有所不同。針對這種情況,提出一種服務權重計算方法。算法通過分析組合服務和原子服務的關系,結合服務實例的可靠性、新鮮度和負載度,計算服務實例權重值并排行,獲得最優實例提供服務。數據分析和仿真實驗表明,算法有效選擇當前最優服務實例,提高云平臺的可用性、效率和魯棒性。
云計算服務組合權重計算搜索
0 引 言
隨著云計算技術的發展,基于云的應用開發需求越來越迫切。開發者可以根據業務流程在云中尋找服務或服務組合,完成業務邏輯需求。隨著云計算技術應用日趨廣泛,云服務的增長速度也在逐漸加快,不可避免出現了大量功能相同或相似的云服務和服務組合,簡單的關鍵詞查找可以在一定程度上解決服務搜索問題,但云應用開發者需要更準確更高效的搜索方法。
服務發現和服務組合算法在Web服務中得到廣泛應用,Web服務搜索排行擁有大量的研究,同時存在多種服務權重計算算法。其中一部分以服務質量作為研究重點,文獻[1]通過Web服務動態組合來描述服務質量、服務提供商因子和消費因子等因素,提出基于層次分析法的質量計算方法,從而得到更高質量的服務;同樣根據服務質量作為發現基礎,文獻[2]考慮服務的服務質量和用戶對屬性的偏好,根據用戶選擇服務行為特點,將不確定主觀權重加入服務權重分析;文獻[3]研究了服務組合問題,提出服務干擾模型,使用該模型描述用戶對組合服務的滿意度,并在計算量上做了研究;文獻[4]提出基于n維空間權重距離計算,根據用戶對不同服務質量屬性的偏好設定權重距離,根據閾值設定返回給用戶的服務。另一部分使用其他方式計算服務權重,對服務進行排行。文獻[5]調用服務歷史數據,抽取屬性計算權重,包括信息的預處理和粗糙集匹配,實現服務發現;文獻[6]提出以Web服務的關聯結構作為基礎的權重排行計算;文獻[7]通過用戶的輸入和輸出請求以及服務質量的約束,采用服務最優組合迭代替換的方案,快速搜索滿足需求的服務組合方案;文獻[8]在Web服務描述語言基礎上,通過倒排序索引表和二分圖匹配完成服務發現,通過兩個階段發現所需要的服務;文獻[9]在領域本體語義信息的基礎上,提出一種可以自適應調整領域劃分、分配系統資源的服務發現體系,主要在服務的可擴展性、自組織性和自適應性上進行分析。
Web服務的權重搜索算法已趨于成熟,而云服務與Web服務有所不同,云環境中服務由運行的服務實例提供,服務實例動態存在,提供服務的能力會受當前實例的可用性、新鮮度和負載程度等因素狀態的影響,單純的服務選擇是不可以直接調用的,用戶希望得到的不是可以直接提供最優服務的服務實例,如何在眾多實例中找到能夠滿足需求且服務能力最優的服務,是云框架中服務搜索的重要問題之一。因此,本文研究了Web服務的服務發現和服務組合算法及PageRank[10,11]頁面搜索算法,結合云環境的特點,提出在以服務組合關系計算服務權重的基礎上,根據服務實例不同時刻提供此服務的能力計算實例權重值,并進行排行顯示,為用戶提供最佳選擇。
1 服務權重計算
服務分為原子服務和組合服務,原子服務是不可以再分的服務,可以直接調用。每個原子服務綁定一組輸入輸出信息,組合服務是由一系列原子服務組合而成,由各個原子服務按照一定序列協同工作而完成。本文選用OWL-S的控制結構來劃分原子服務和組合服務,包括:Sequence、Split、Split-Join、Any-Order、Choice、If-Then-Else、Iterate、Repeat-While and Repeat-Until[12]。
定義1組合服務U:由原子服務集合SC(U)和原子服務關系組合SRL(U)構成。
原子服務集合SC(U):組成服務U的原子服務集合。
SC(U)={si}
其中si為原子服務。
原子服務關系組合SRL(U):組成組合服務的原子服務之間關系集合。
SRL(U)={(sm,sn)|sm,sn∈SC(U)}
(sm,sn)代表關系sm→sn,原子服務sm的輸出為原子服務sn的輸入,服務間可按照順序組合。
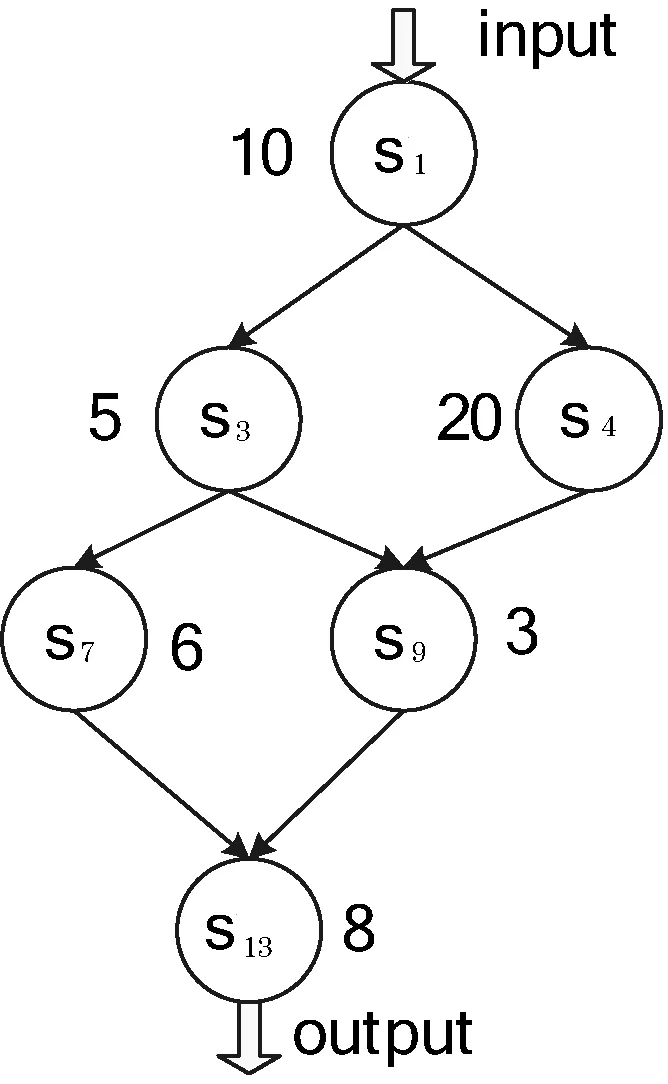
圖1 組合服務A的DAG圖
對于原子服務sm,sm→sn為sm的指出鏈接out(sm);對于原子服務sn,sm→sn為sn的指入鏈接in(sn)。
例如:組合服務A,由s1,s3,s4,s7,s9,s13組合而成,如圖1所示。
則表示如下:
SC(A)={s1,s3,s4,s7,s9,s13}
SRL(A)={(s1,s3),(s1,s4),(s3,s7),(s3,s9),(s4,s9),(s7,s13),(s9,s13)}
定義2服務權重值SR:衡量服務質量的標準。
原子服務s的指入鏈接數量越多,則SR(s)越大;
指向原子服務s的服務的SR越大,則SR(s)越大。
SR(s)計算方法:
1) ?s∈S,SR(s)=kS為所有原子服務結合,k為初始權重值;為每一個原子服務s賦予初始值。
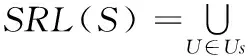

SR(s):原子服務s的權重值;
B(s):指向原子服務s的原子服務集合;
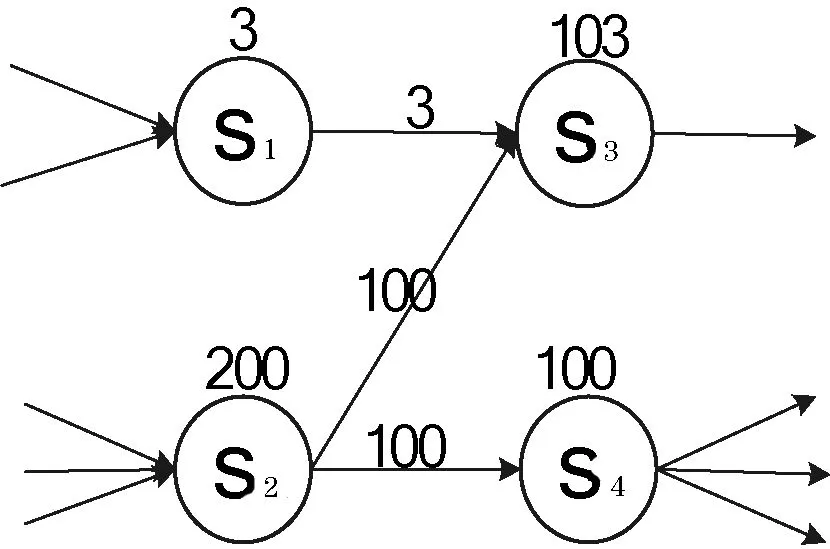
圖2 原子服務權重分配圖
SR(v):原子服務v的權重值,原子服務v存在鏈接指向原子服務s;
Nv:原子服務v所有指出鏈接的個數;
4) 重復計算第3步,直到任意原子服務的權重值趨向穩定。
利用上述過程計算權重值,如圖2所示。
圖2中原子服務關系:
SRL(S)={(…,s1),(…,s2)(s1,s3),(s2,s3),(s2,s4),
(s3,…)(s4,…)}
原子服務s1只有一條指出鏈接,則指出鏈接得到的權重為3,原子服務s2存在2條指出鏈接,則每條鏈接得到的權重為200/2=10,原子服務s3的指入鏈接有兩條,權重值分別為3和100,所以在這一輪計算s3的權重值修改為100+3=103,s4的權重值為100。
原子服務s2的權重值遠遠大于s1的權重值,那么他們對原子服務s3的影響是不同的,而原子服務s1對s3的影響顯的微不足道,因此在計算權限值傳遞時,引入阻尼系數d,取值在0~1之間,N為所有服務的個數,引入N,使所有服務的權重值相加為1。第3步計算原子服務s權重值公式為:
(1)
定義3組合服務權重值SR(U)由原子服務的權重值計算得到。由于計算復雜,且計算結果可以代表一段時間內的權重排行,因此引入計算周期Δt,經過Δt時間計算一次。計算公式為:
(2)
SR(U):組合服務U的權重值;
SC(U):組合服務U的原子服務集合;
s:組合服務U的原子服務;
SR(s):原子服務s的權重值;
N(s):原子服務s在此組合服務的原子服務關系集合SRL(U)中出現的次數;
T(U):組合服務U的原子服務關系集SRL(U)中的關聯次數。
若服務權重關系及組合如圖1所示,各原子服務有其各自的權重值,那么此組合服務的權重值為:
SR(A)=(10×2+5×3+20×2+6×2+3×3+2×8)/(2×7)
=8
定義4實例權重值IR(U)由實例提供服務的權重值SR(U)和服務實例運行參數計算得到。
IR(Ui)=SR(U)D(Ui)F(Ui)L(Ui)
(3)
IR(Ui):能夠提供服務U的實例Ui的權重值;
SR(U):服務U的權重值;
D(Ui):實例Ui的可靠率;
F(Ui):實例Ui新鮮度;
L(Ui):實例Ui負載程度。
由各參數影響,IR的取值區間(0.002SR,2SR)。
實例運行參數包括:
1) 可靠性
實例的可靠性由實例可靠率D(Ui)衡量。
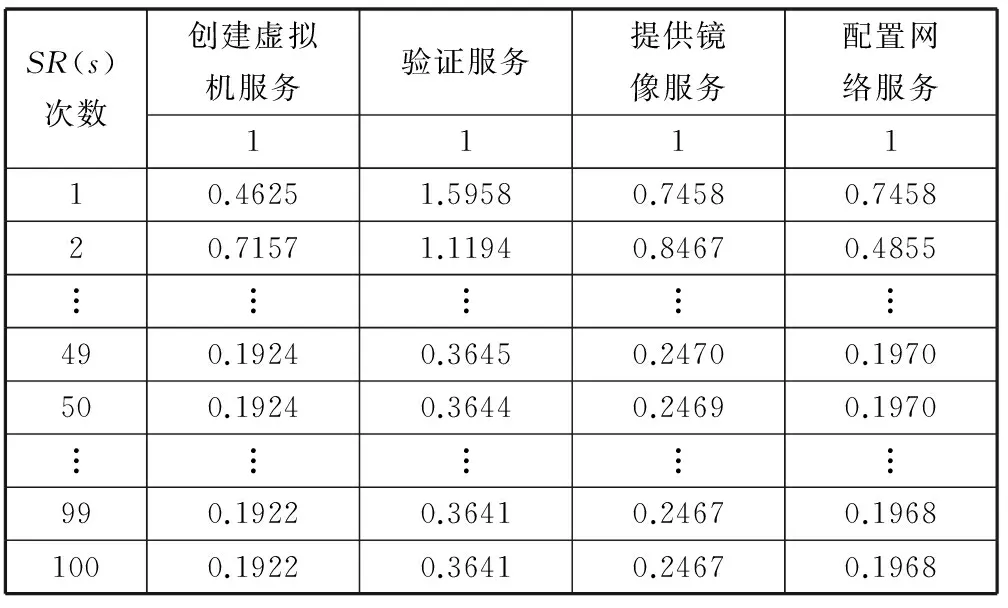
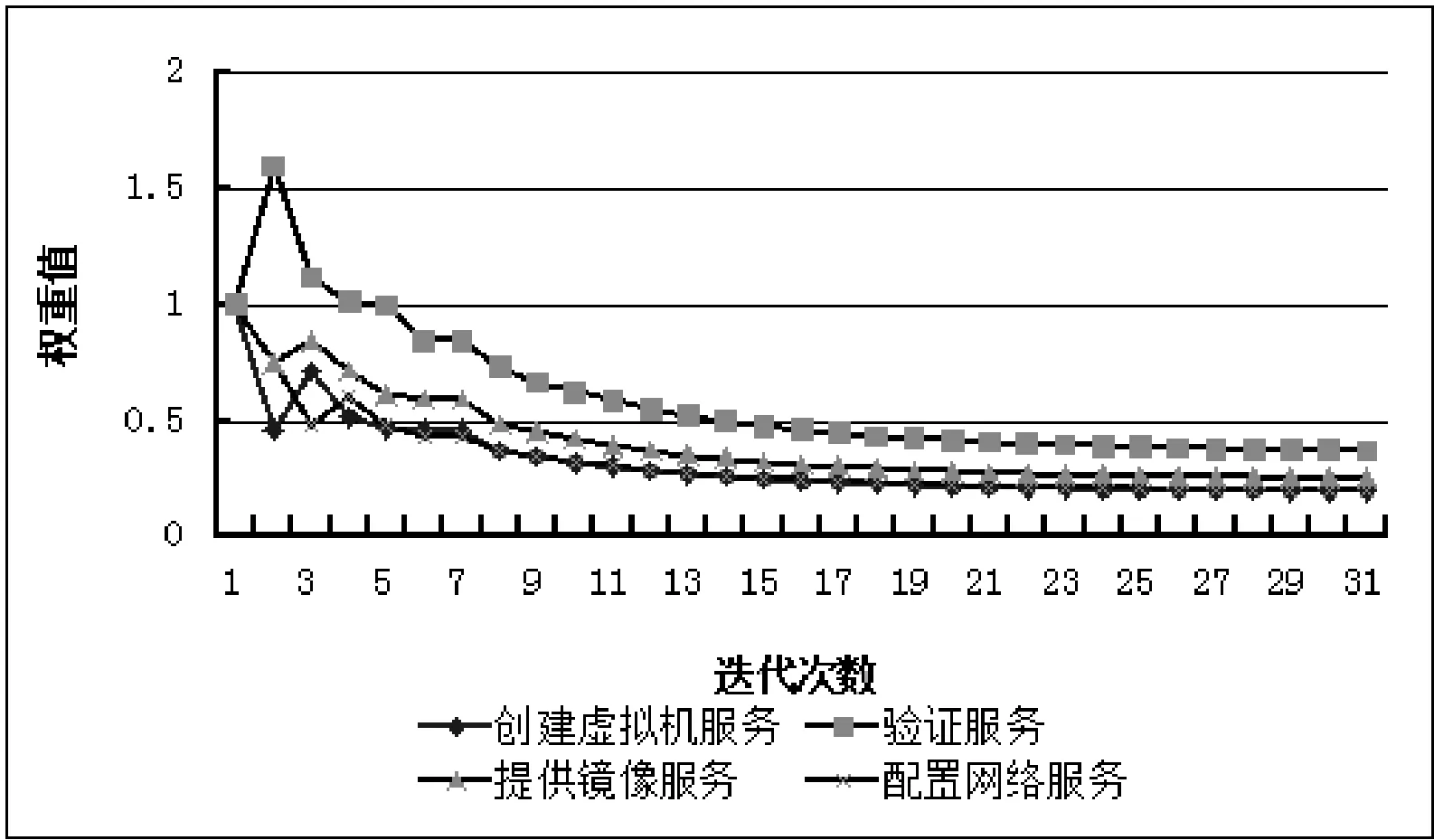
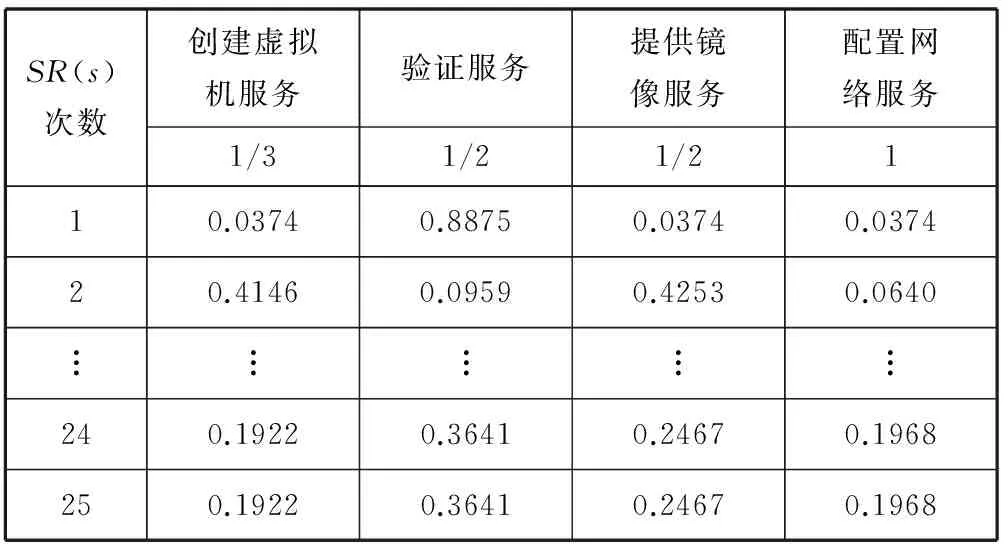
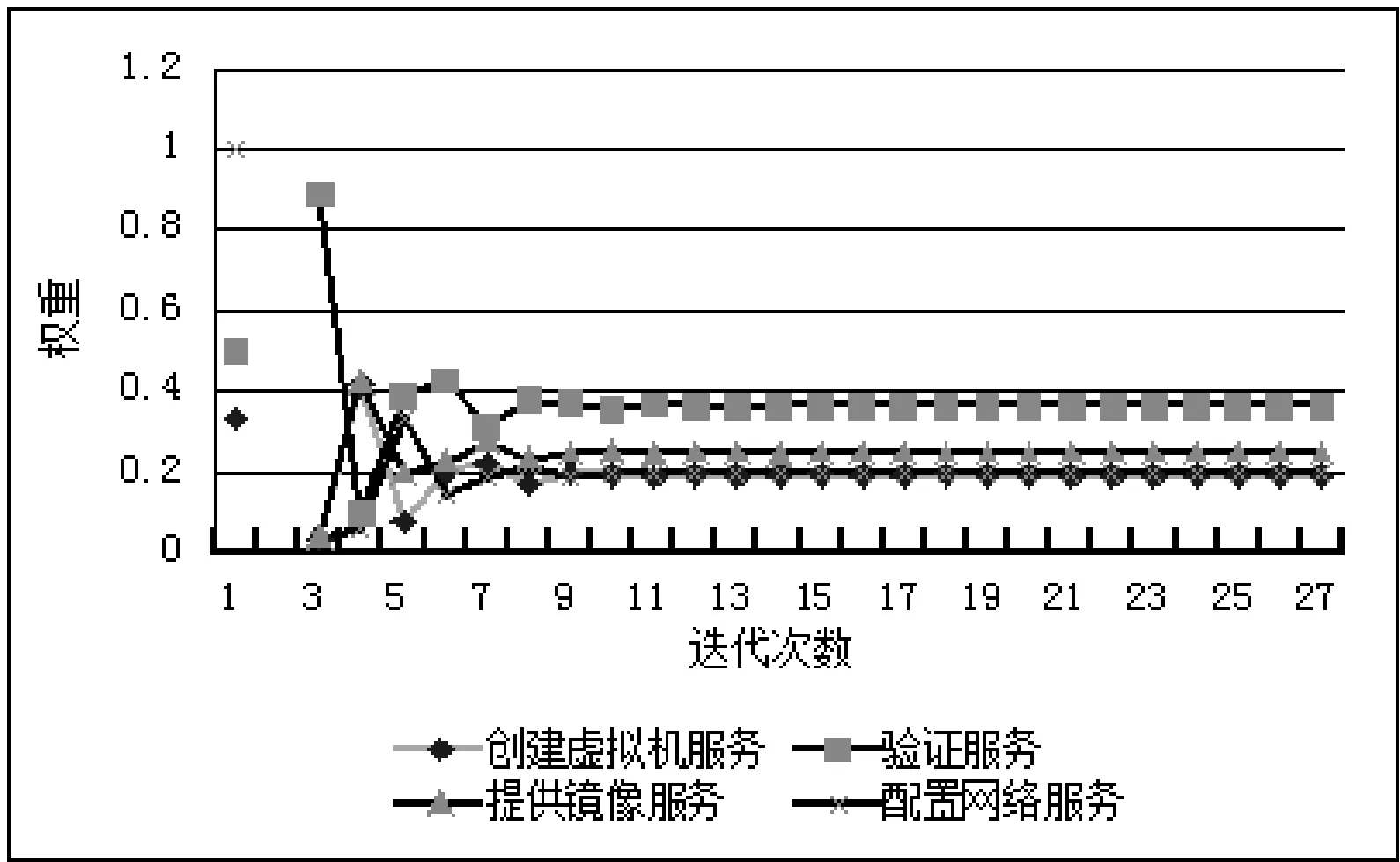
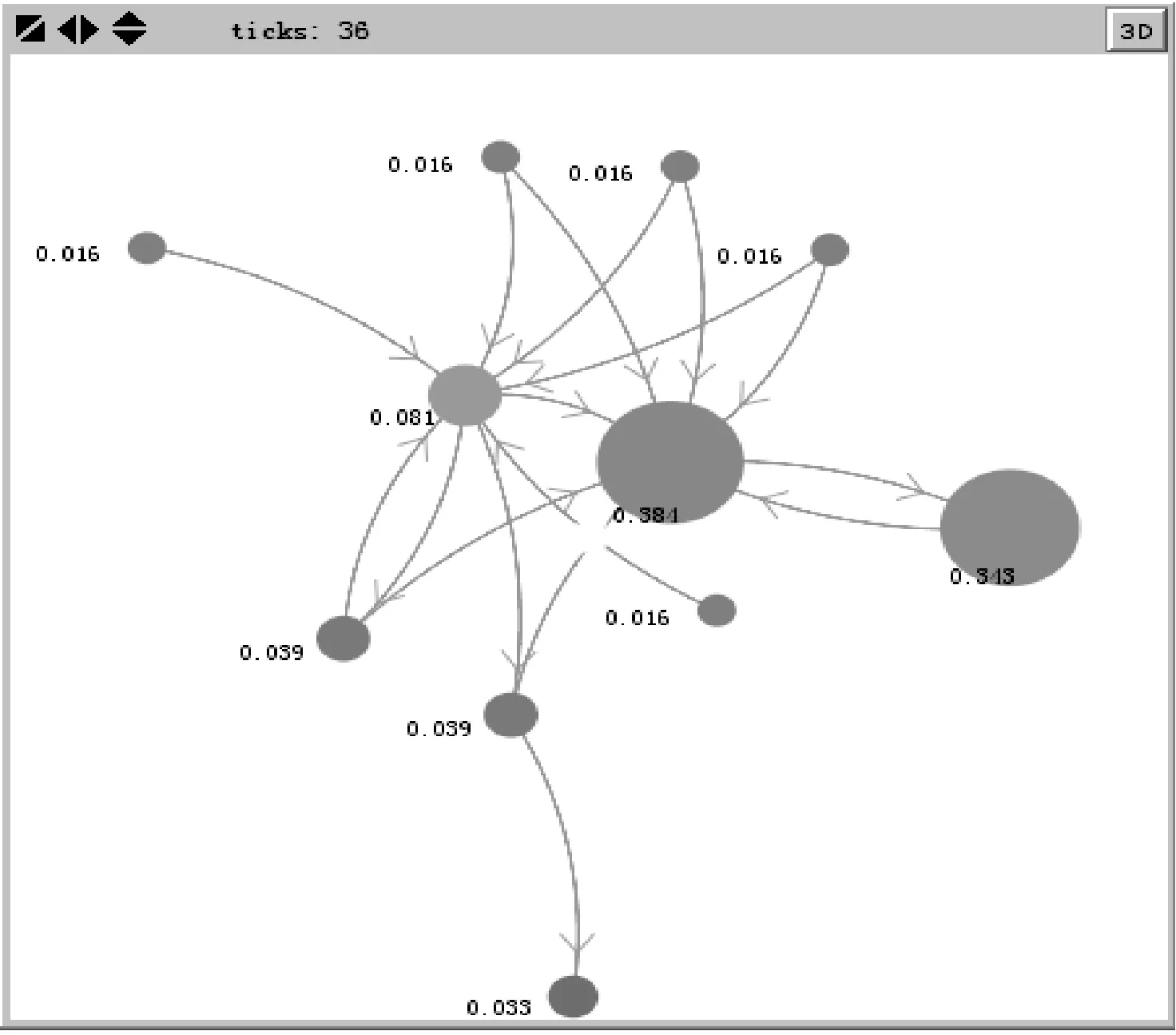
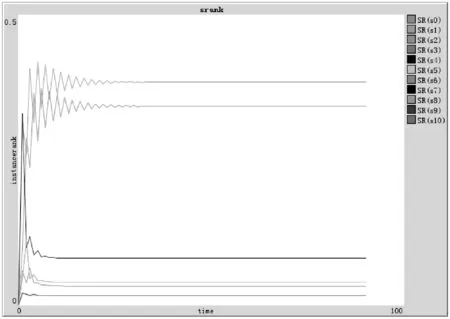
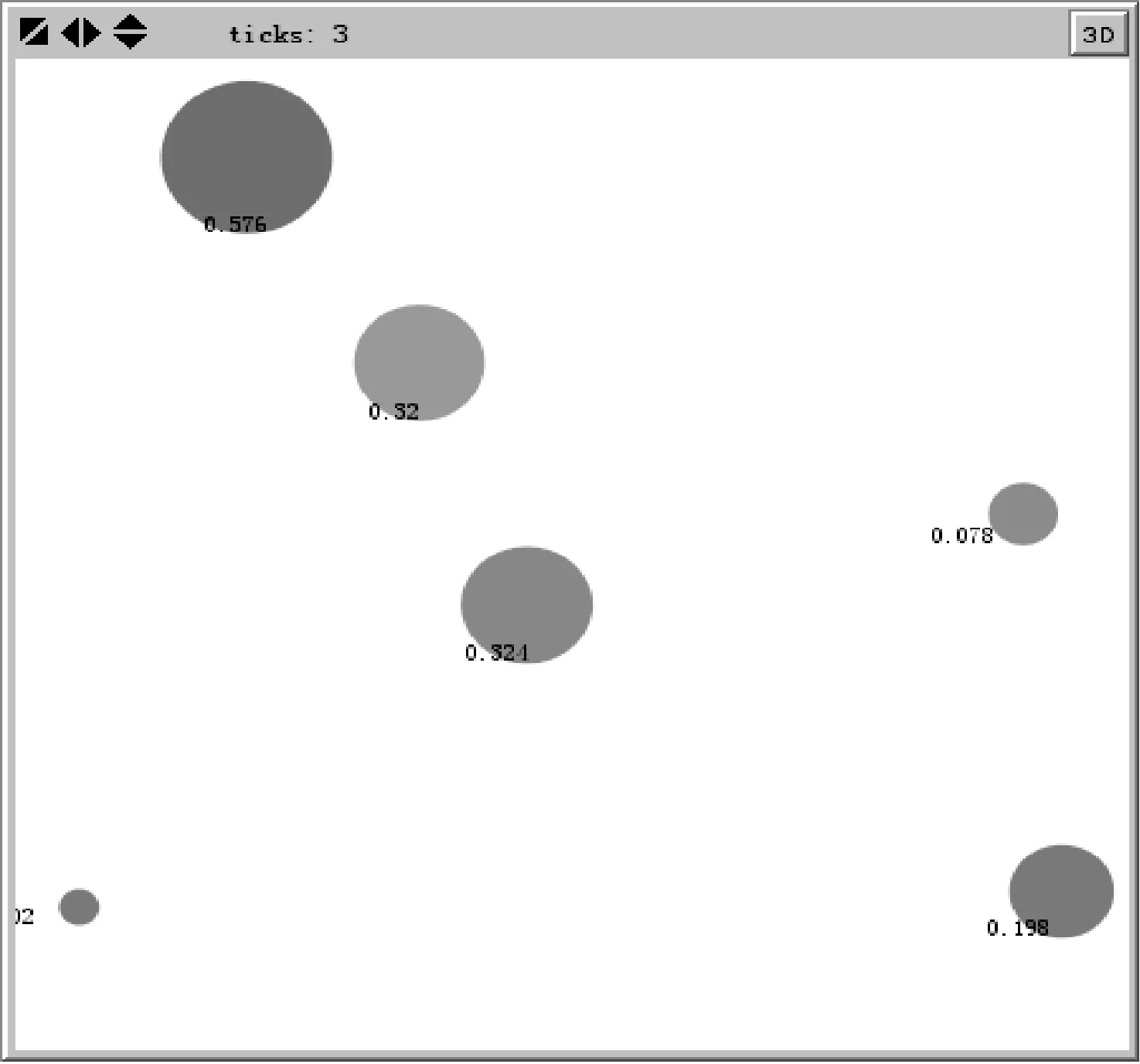
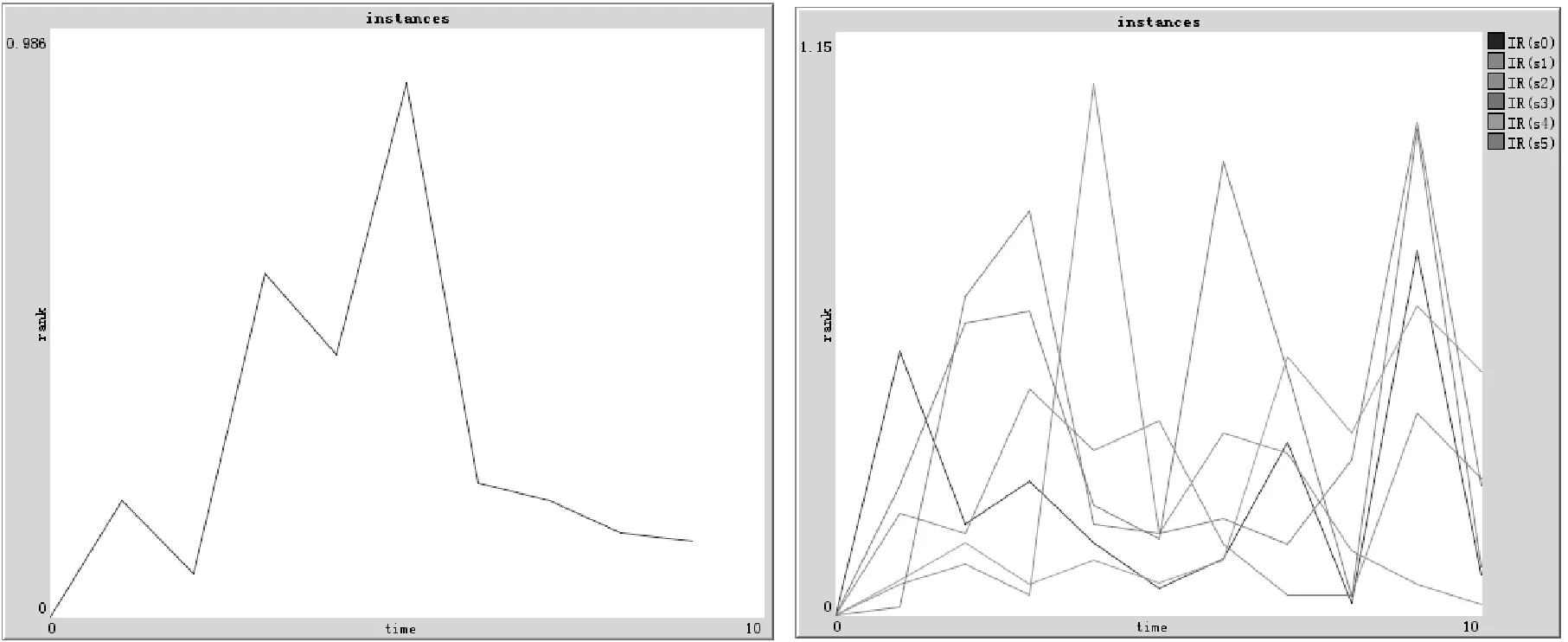
D(Ui)=1-f0 (4) f為一段給定且連續時間內測試服務發生故障的頻率當實例未被使用,可靠性D(Ui)=1。 2) 新鮮度 實例的新鮮程度由實例的最后使用時間t(u)決定。 若t(u)在ɑ時間內,則F(Ui)設為1+e,其中e為比例參數公式如下: F(Ui)=1+e (5) (6) 若t(u)在大于ɑ時間,小于β時間的時間內,公式如下: (7) 若t(u)在大于β時間內,我們認為服務已經很久未被使用,服務新鮮度為恒定的值,公式如下: (8) t(now):現在的時間; t(u):實例最后使用時間。 ɑ和β為時間系數,根據云環境中服務實例的使用情況設定。當實例未被使用,F(Ui)=1。 3) 負載程度 負載程度根據服務實例動態CPU使用情況設為五個級別:無負荷(80%~100%)、輕微負荷(60%~80%)、中等負荷(40%~60%)、重度負荷(20%~40%)和完全負荷(0~20%)。 定義si為原子服務,各原子服務之間存在組合關系,通過指出鏈接和指入鏈接表示相應組合關系。如圖3所示。 圖3 原子服務例圖及鄰接表 2.1理論分析 圖3中將原子服務及原子服務之間關系描述為有向圖,其中s1為創建虛擬機服務,s2為驗證服務,s3提供鏡像服務,s4為配置網絡服務有向圖和矩陣式可以相互轉化的,因此使用矩陣A表示原子服務及原子服務之間關系。將矩陣A中各個數值除以各行的非零要素后得到概率矩陣M,M表示原子服務si到原子服務sj的概率。 在隨機過程理論中,M稱為轉移概率矩陣。每一次迭代過程相當于用上一次迭代結果乘以矩陣M。這種離散狀態按照離散的時間隨機轉移過程稱為馬爾科夫鏈。設轉移概率矩陣為P,若存在正整數N,使得P^N>0(每個元素大于0),這種鏈被稱作正則鏈。在云存儲環境的實際應用情況中,服務和服務之間的關系屬于正則鏈。而正則鏈存在唯一的極限狀態概率且與初始狀態無關。因此,理論上可以將求解原子服務權重問題轉化為求馬氏鏈的平穩分布問題,公式如下,其中SR(si)代表原子服務si的服務權重值: SR(s1)=SR(s2)/2 SR(s2)=SR(s1)/3+SR(s3)/2+SR(s4) SR(s3)=SR(s1)/3+SR(s2)/2 SR(s4)=SR(s1)/3+SR(s3)/2 SR(s1)+SR(s2)+SR(s3)+SR(s4)=1 解得: SR(s1)=0.1875SR(s2)=0.375 SR(s3)=0.25SR(s3)=0.1875 由結果分析,指入鏈接越多,原子服務的權重值越高,表示該原子服務質量越好。 2.2數據分析 根據定義2計算過程計算圖3中原子服務權重,不考慮阻尼系數,初始值設為1時實際迭代情況如表1和圖4所示。 表1 SR(s)迭代計算表(初始權重為1) 圖4 SR(s)迭代趨勢圖(初始權重為1) 經分析得,多次迭代后,原子服務的權重值達到平穩,與理論分析中馬氏鏈求出結果關系如下: SR(s1):0.7499/0.1875=4.000 SR(s2):1.4999/0.375=4.000 SR(s3):0.9999/0.25=4.000 SR(s4):0.7500/0.1875=4.000 由計算結果得到,經過多次迭代的原子服務權重值與理論分析中馬氏鏈求出結果為倍數關系。 根據式(1)計算原子服務權重,阻尼系數設為0.85,初始權重值設為1,迭代如表2和圖5所示。 表2 SR(s)迭代計算表(d=0.85,初始權重為1) 圖5 SR(s)迭代趨勢圖(d=0.85,初始權重為1) 根據式(1)計算原子服務權重值,阻尼系數設為0.85,各服務初始權重值設為指出鏈接的倒數,s1的初始權重值為1/3,s2的初始權重值為1/2,s3的初始權重值為1/2,s4的初始權重值為1。迭代如表3和圖6所示。 表3 SR(s)迭代計算表(d=0.85,初始權重為指出鏈接倒數) 圖6 SR(s)迭代趨勢圖(d=0.85,初始權重為指出鏈接倒數) 經分析得到,無論原子服務的初始權重值為多少,經過多次迭代,最終穩定權重值是相同的。所以,加入阻尼系數后,初始權重值對最終原子服務的權重值是沒有影響的,服務權重值會最終達到平穩,且代表服務的重要性,權重值越大,則服務越重要。 在表3中,權重值在迭代了20次左右時已經達到相對平穩,大大減少了迭代次數,因此,選擇好的初始權重值可以減少計算權重值的迭代次數,提高計算效率。 使用netlogo仿真平臺實驗,從更多服務的角度,定義11個原子服務si,如圖7所示,圖形圓代表服務,圖形圓邊的數字代表服務權重值,同時為了更好地查看效果,原子服務的權重值越大,代表其的圖形圓的面積就越大。圓之間的有向連線代表服務之間的組合關系。為每一個服務賦予初始權重值,計算過程中權重值取小數點后三位,ticks代表迭代次數。 圖7 實例權重分布圖 圖7中表示經過36次迭代后服務權重值的變化,可以分析得到,擁有最多的指入鏈接的圓面積最大,代表其服務權重值也是最高的0.384,說明服務的指入鏈接越多,證明有越多的服務可以和其組合,說明此服務越重要。 圖8中將服務權重值以曲線的形式顯示,可以看到,各服務最終權重值會達到穩定,并且服務越重要,其權重值越高。最終可以輸出按照權重值大小排序的原子服務和其權重值。 圖8 服務權重曲線圖 服務權重最高的服務代表最重要的服務,此服務由云框架中不同服務實例提供,服務實例存在動態生存周期,虛擬實例具有三個參數:fresh代表實例新鮮度,取值范圍(0.1,2), reliability代表實例可靠性,取值范圍(0.1,1),load代表實例負載程度,取值集合{20%,40%,60%,80%,100%}。在netlogo中仿真三種因素在不同實例的運行狀態。如圖9所示,定義6個提供最高權重服務的實例,圖形圓代表實例,圖形圓邊的數字代表實例權重值,實例的權重值越大,代表其的圖形圓的面積就越大。 圖9 實例權重分布圖 圖9表示提供服務的服務實例權重值在不同時刻的權重值情況,最大的圓代表的具有最高權重值的實例,代表當前時刻此實例可以提供最優的服務,提供的服務能力最高。 如圖10(左)所示,曲線代表的實例權重隨時刻的不同而發生變化,表明實例權重值并不是一成不變的,隨著實例的新鮮度、負載程度和可信度的變化而變化,權重值高,則實例此時能夠服務的能力高。 圖10(右)為多個實例的權重值隨時間變化的曲線,在任意時刻都可以對這些實例的權重值比較,同時輸出比較結果,權重值高的則排在前面,方便用戶選擇。得到權重值最高,最優提供服務的實例。 圖10 實例權重曲線圖 通過數據分析可以得到無論原子服務的初始權重值設為多少,經過多次迭代,最權重值會逐漸收斂,達到穩定;加入阻尼系數使得無論原子服務的初始權重值設為多少,最后得到的權重值是一致的;加入服務數量N使得最終得到的服務權重值總和為1,控制原子服務權重值的數量級;初始權重值取值會影響到權重值計算的迭代次數,初始權重值取值越接近總服務數的倒數,最終權重值達到平穩的計算次數就越少,所以初始值的選擇會直接影響計算效率。 由仿真實驗可以得到服務的指入鏈接越多,此服務的權重值就越高,則說明與此服務組合的服務越多,此服務越重要。計算得到實例權重值,實例權重值在不同時刻有明顯不同,實例的服務能力在不同時刻受其新鮮程度、可靠性和負載度的影響,而算法可以對多個提供相同服務的實例進行新鮮程度、可靠性和負載度的對比,提高云平臺的整體性能,增加了云平臺提供服務的高可用性、減少數據遷移量,提高效率,有效提高云平臺的魯棒性。 本文針對以服務實例提供計算資源的云平臺,通過服務組合關聯計算服務權重值,從云平臺整體性能的角度,對可靠性、數據遷移量和魯棒性進行分析,將實例生存周期中的可靠性、新鮮度和負載度作為參數計算實例權重值,并對提供服務的虛擬機實例進行權重值排序,為云應用開發者提供當前時刻最優選擇。算法提高服務權重值及實例權重值的計算效率,但與服務請求內容無關。因此在之后的研究中將使用領域本體語言描述服務及服務組合,利用本體相似算法,達到服務搜索的準確性和高效性。 [1] 張琦,侯紅.Web服務動態組合中QoS計算方法研究[J].計算機工程,2011,37(12):41-43. [2] 樊志強,申菊芳,王守信.基于不確定主觀權重的Web服務選擇[C]//2009中國計算機大會論文集,2009:595-603. [3] 王慧,楊德國,高遠.一個基于QoS的服務路徑發現和恢復算法[J].東北大學學報:自然科學版,2008,29(2):209-212. [4] 李珍,王紅兵.Web Services的權重空間距離和定量選擇[J].計算機工程與科學,2011,33(10):182-185. [5] 趙旭,黃永忠,安留洋.基于屬性權重和粗糙集的網格服務發現算法[J].計算機應用,2012,32(1):167-169. [6] 朱怡安,雷萬保.基于服務關聯模型的服務排序算法——ServiceRank[J].電子科技大學學報,2011,40(4):607-611. [7] 馬環宇,姜偉,虎嵩林.QSynth-TopK:一個支持Top K查詢的質量敏感的自動服務組合系統[J].電子學報,2012,40(10):1933-1937. [8] 李季輝,賈永偉.基于索引表和二分圖的Web服務操作發現[J].計算機工程,2012,38(13):37-39,43. [9] 姚燚,曹玖新,劉波.基于語義的可擴展Web服務注冊與發現機制[J].東南大學學報:自然科學版,2010,40(2):264-269. [10] Kumar G,Duhan N,Sharma A K.Page Ranking Based on Number of Visits of Links of Web Page[C]//International Conference on Computer & Communication Technology (ICCCT),2011. [11] Liu Y,Xu P.The Research of Optimizing Page Ranking Based on User’s Feature[C]//International Conference on Industrial Control and Electronics Engineering,2012. [12] OWL-S:Semantic Markup for Web Services[EB/OL].(2004-11-22).[2014-09-11].http://www.w3.org/Submission/OWL-S/,2004. A CLOUD SERVICE SEARCHING ALGORITHM BASED ON WEIGHT Sun HanyuGu ChunhuaWan FengYang Weiwei (SchoolofInformationScienceandEngineering,EastChinaUniversityofScienceandTechnology,Shanghai200237,China) Cloud computing technology is developing rapidly, various functions and qualities of cloud services differ from each other. In view of this, we propose a service weight computation algorithm. The algorithm computes and ranks the weight of service instances by analysing the relationship of atom service and composition service and combining with reliability, novelty and load degree of service instances to obtain best instance for providing service. Data analysis and simulation experiment all show that the algorithm can pick up optimal current service instance, and promote cloud platform’s high availability, efficiency and robustness. Cloud computingService compositionWeight computationSearching 2014-09-17。孫寒玉,碩士,主研領域:云計算方面研究。顧春華,教授。萬鋒,高級實驗師。楊巍巍,碩士。 TP3 A 10.3969/j.issn.1000-386x.2016.03.008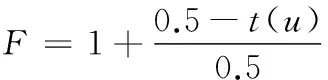
2 數據分析
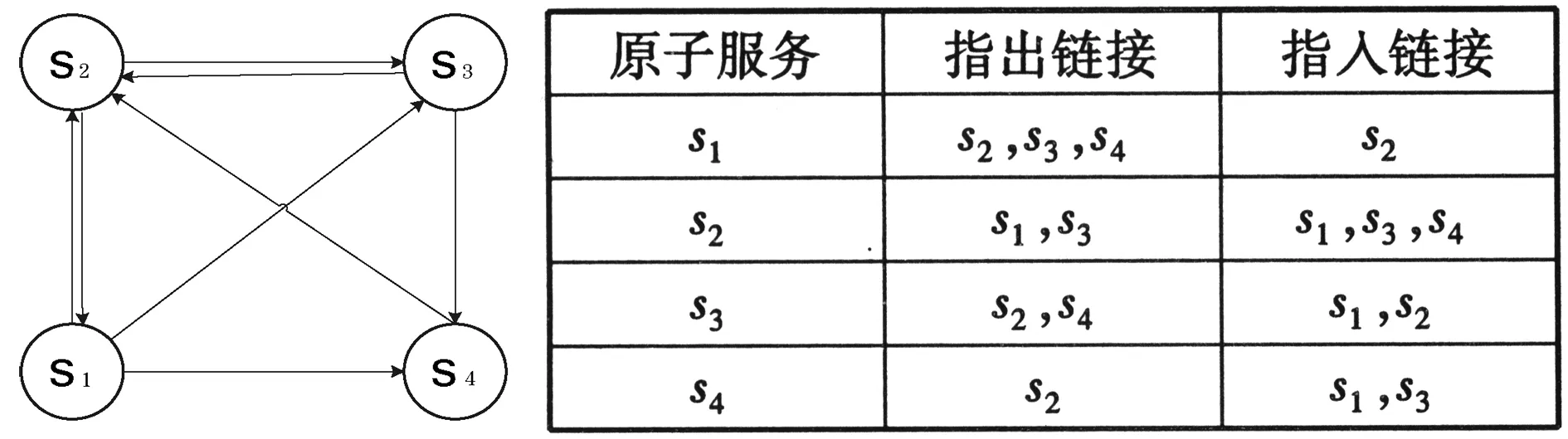
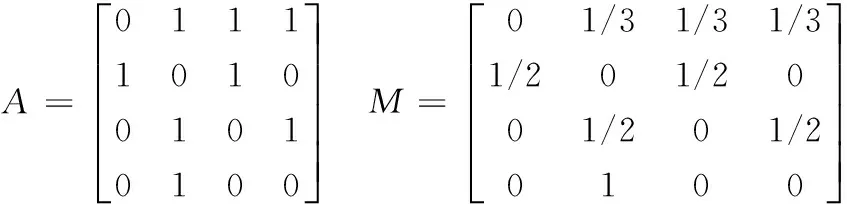
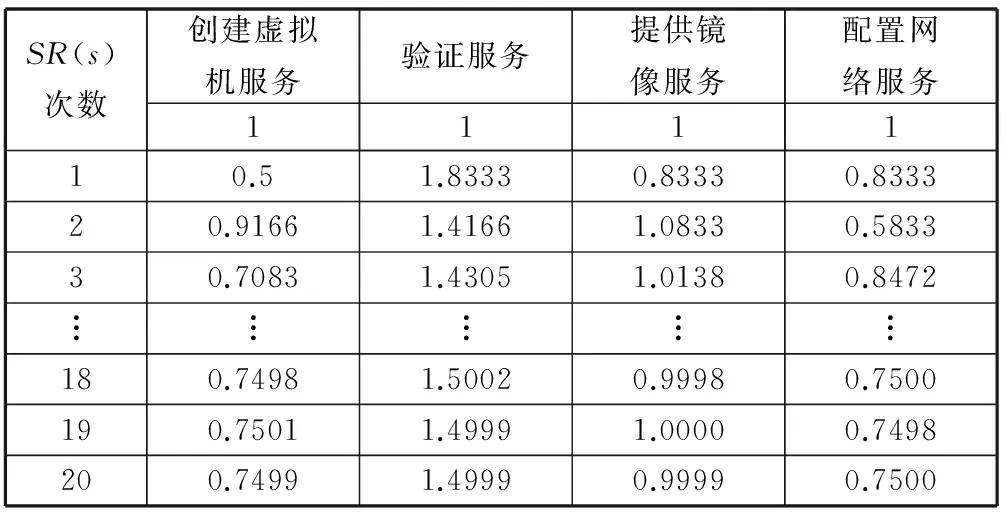
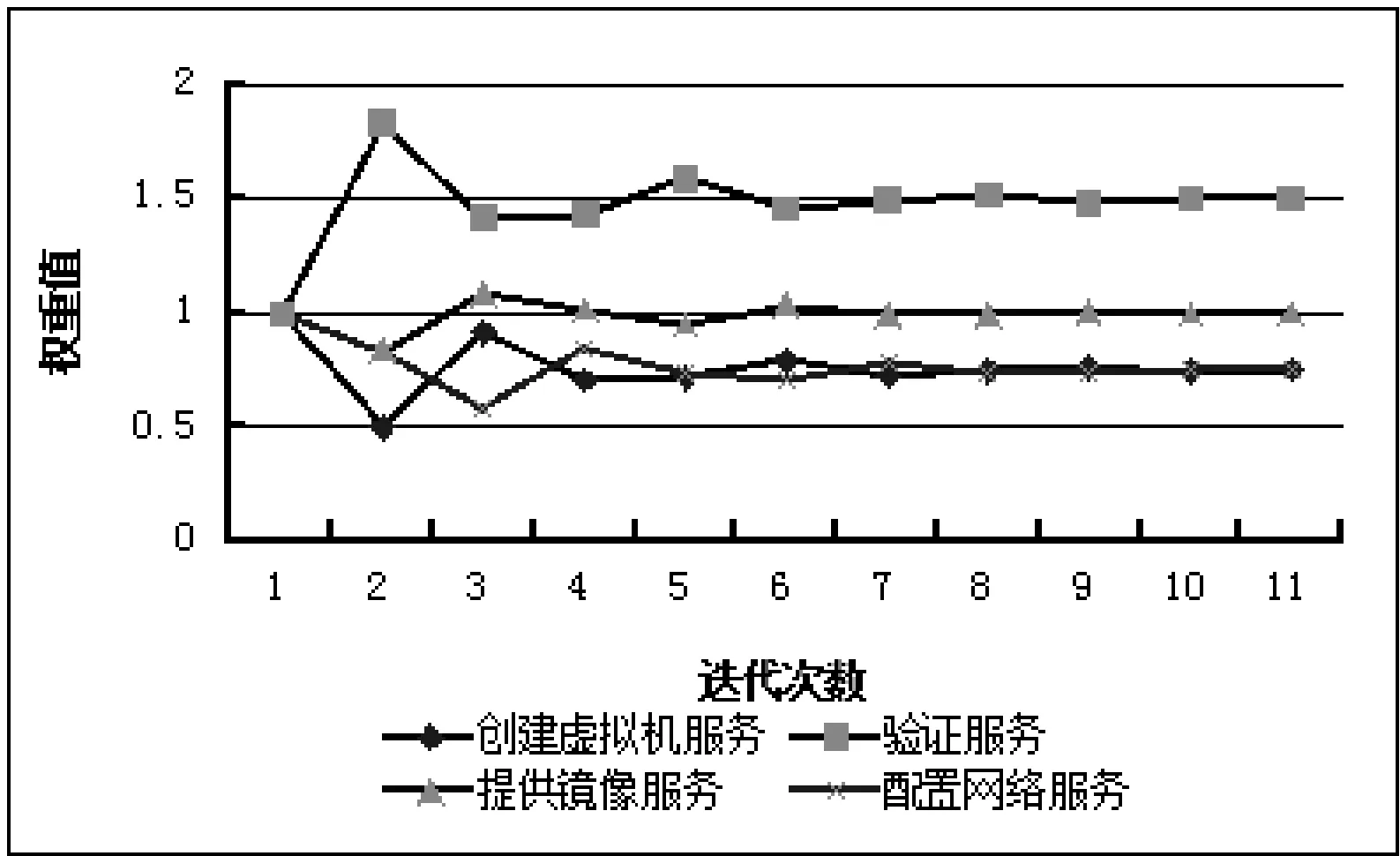
3 實驗驗證
4 實驗結論
5 結 語
猜你喜歡
杭州金融研修學院學報(2022年5期)2022-06-15 11:41:48
今日農業(2019年14期)2019-09-18 01:21:54
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年11期)2019-08-13 00:49:08
今日農業(2019年13期)2019-08-12 07:59:04
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年15期)2019-01-03 12:11:33
今日農業(2019年16期)2019-01-03 11:39:20
銅仁學院學報(2018年4期)2018-06-13 03:21:34
商周刊(2017年9期)2017-08-22 02:57:56
