基于層疊條件隨機場的哈語樹庫構建技術研究
2016-09-26 07:31:04于智娟古麗拉阿東別克
計算機應用與軟件 2016年3期
于智娟 古麗拉·阿東別克
(新疆大學信息科學與工程學院 新疆 烏魯木齊 830046)
?
基于層疊條件隨機場的哈語樹庫構建技術研究
于智娟古麗拉·阿東別克
(新疆大學信息科學與工程學院新疆 烏魯木齊 830046)
針對如何提高基于統計的哈薩克語句法分析算法的處理性能問題,提出一種通過人機交互來構建哈薩克語樹庫的方法。在自動句法標注階段,采用層疊條件隨機場模型實現,并在其低層與高層模型之間加入改進的基于轉換的錯誤驅動學習算法來進行簡單句的自動句法標注及自動校正。最后對特殊的整體標記錯誤進行人工校對,形成基于短語結構的哈薩克語樹庫。實驗結果表明,該方法在很大程度上減少了人力及物力的投入,提高了分析精度及整體處理效率,并為后期基于哈薩克語的句法機器翻譯及文本挖掘奠定了一定的基礎。
哈薩克語樹庫人機交互層疊條件隨機場錯誤驅動學習算法
0 引 言
哈薩克語樹庫為哈語自動句法分析、句法機器翻譯、文本挖掘等熱門研究領域提供知識源,其重要性不言而喻。特別是哈薩克語的樹庫構建技術相比于漢語、英語等其他語言比較滯后,仍處于初級階段。所以說如何在節省人力及物力資源的前提下,能夠更好地構建哈薩克語樹庫是一個急需解決的難點問題。在樹庫構建方面,漢語樹庫的構建技術已基本成熟并取得了一些成果,包括美國賓州大學的UPenn樹庫[1]和臺灣中研院的Sinica樹庫[2]。英語語料庫的研究也做了許多工作,其中兩個比較大的項目是:英國的Lancaster-Leeds樹庫[3]和美國的Penn樹庫項目[4],樹庫規模已達到二百萬詞以上。
而哈薩克語方面,目前還沒有一個相對成熟的樹庫,只做了一些構建樹庫前的鋪墊工作。例如:古麗拉·阿東別克等根據哈薩克語的獨特語言特點,進行了詞級帶標注的哈薩克語語料庫構建研究[5];侯呈風等在基于詞典靜態標注基礎上分析了隱馬爾科夫模型并對哈薩克語進行了詞性標注研究[6];在短語識別方面,孫瑞娜等以基本名詞短語為目標,實現了哈薩克語的基本名詞短語自動識別系統[7];古麗扎達·海沙根據哈薩克語基本動詞短語組成結構的復雜性,提出了一種規則與最大熵相結合的方法對哈語基本動詞短語進行了識別[8]。
本文在以上詞性及基本短語標注基礎上,采用基于層疊條件隨機場對哈薩克語的簡單句進行了句法標注,同時對部分因典型的歧義結構造成標注錯誤的句子進行人工校對,最終形成完整的句法結構樹。同時借鑒了文獻[9,10]中提出的分階段構建漢語樹庫及標記集的選取相關問題的方法思路,并結合哈薩克語自身語言的粘著性特點,分階段進行樹庫構建。并在基于層疊條件隨機場模型的自動標注階段,引入基于錯誤驅動的學習算法,進行自動校正,提高了整體句法標注的準確率,同時減少了人力及物力資源的投入。
1 樹庫構建的理論基礎
1.1哈語句法標記集的選取
構建哈薩克語樹庫的一項基礎工作就是要確定適合哈薩克語粘著性特點的句法標記集。在哈薩克語中,對短語進行分類一般采用兩大標準:1) 內部結構;2) 外部結構。本文著重研究哈語短語的外部結構。首先參照漢語樹庫構建[9]和英語樹庫[11]的處理經驗及方法。同時結合哈薩克語粘著性語言的特點,找出哈薩克語同漢語、英語、維吾爾語的異同點,其中相同的句法結構采用相同的標注集標注。不同的句法結構又可以參照與哈薩克語同屬于阿爾泰語系的維吾爾語的樹庫標注體系[12]及現代哈薩克語實用語法[13]。根據以上方法,我們為哈薩克語設計了一套符合哈薩克語自身語言特點的句法標記集。如表1所示。

表1 哈薩克語句法標記集

1.2構建哈薩克語樹庫的步驟流程
大規模哈語樹庫的構建作為一個龐大的語言工程,在現有條件下,完全由機器自動完成是不可能的,需要找到一個很好的人工切入點,以最少的人工投入獲得最佳的整體處理效果。為此,結合哈薩克語自身粘著性的語言特點,我們在已有的分詞和詞性標注的基礎上,利用層疊條件隨機場模型進行簡單句的句法標注。標注出句子的短語結構層次,在加入基于錯誤驅動的學習算法之后,提高了標注結果的正確率,但仍然存在部分標注錯誤的情況,這時我們就需要人工校正來對結果進行完善。根據以上情況,本文制定出了構建半自動哈薩克語樹庫的思路方法,分別從詞、短語層的句法分析再到最后人工的處理這三步進行。本文重點工作是在步驟一的基礎上實現了步驟二、步驟三。具體步驟如下:
步驟一預處理,主要對哈語生語料做篇章級的斷句、分詞;并對詞做統一的詞性標注規范,然后進行詞性標注。
步驟二機器分析,在分詞和詞性標注的基礎上,通過層疊條件隨機場模型進行短語層次結構的句法標注。從低層組塊標注到高層復雜短語的標注中,引入基于錯誤驅動的學習算法自動進行標注結果的校正。最后形成較完善的句法分析樹。
步驟三人工校對,由于第二步工作中采用的是基于規則的校正算法,而規則的獲取僅依賴于語言學家的語言知識和經驗,卻不能完全囊括各種復雜的語言現象。所以需要人工的介入,對一些復雜的存在歧義的句法樹進行人工校正,從而獲得最佳的標注結果。具體處理流程如圖1所示。
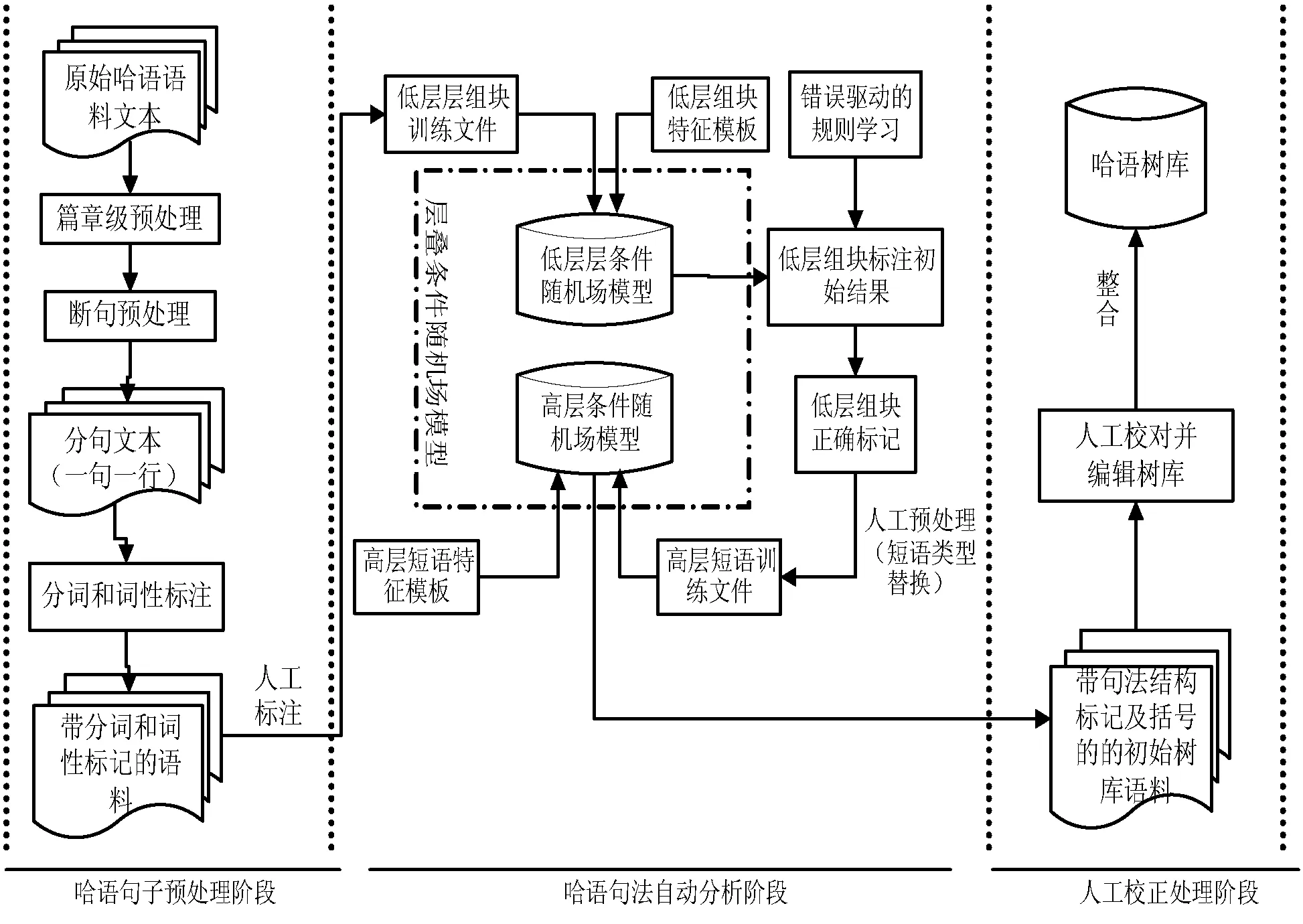
圖1 半自動構建哈語樹庫流程圖
2 哈薩克語句法標注及人工處理
由于前人在哈薩克語的分詞和詞性標注方面做了大量研究及實驗[14,15],且在樹庫預處理方面已經相對比較成熟。 所以說本文重點工作在句法分析階段。
2.1層疊條件隨機場模型
由于句子中存在許多短語的嵌套及組合現象,所以在進行句法標注過程中,需要進行分層研究。層疊條件隨機場(CCRFs)由一個兩階段的條件隨機場模型構成,層次模型間存在松耦合關系,各模型可獨立建立,且整個模型的復雜度和句子長度成線性關系。本文新加入的低層后處理模塊對低層模型產生的錯誤可經過濾和更正后傳入高層,從而避免錯誤傳播。鑒于此,本文將句法結構任務分多個層次,每層內部用CCRFs作為層次標注的機器學習方法。在CCRFs中,低層的條件隨機場僅以觀察值為條件,用于基本短語即組塊的識別,識別結果傳遞至高層條件隨機場模型,作為高層模型的輸入。這樣高層模型的觀察序列中不僅包含詞和詞性的信息,同時也包含了底層基本短語識別的結果,從而為高層復雜短語的識別奠定了基礎。
兩階段的條件隨機場模型具體算法:定義x=x1,…,xN為給定的輸入觀測值哈序列,即無向圖模型中N個輸入節點上的值,如當前輸入的哈文詞序列;定義y=y1,…,yN為輸出的狀態序列,即無向圖模型中N個輸出節點上的值,如輸出的標記序列。CRF定義從輸入x得到序列y的條件概率定義為:
(1)
其中每個fk(yi-1,yi,x)是整個觀察序列和相應的標注序列中位置為i和i-1標記的特征函數,每個gk(yi,x)是在位置為i的標記和觀察序列的狀態特征函數,λk和uk是特征函數的權重,可從訓練語料中估計得到。
層疊條件隨機場的具體模型如圖2所示。
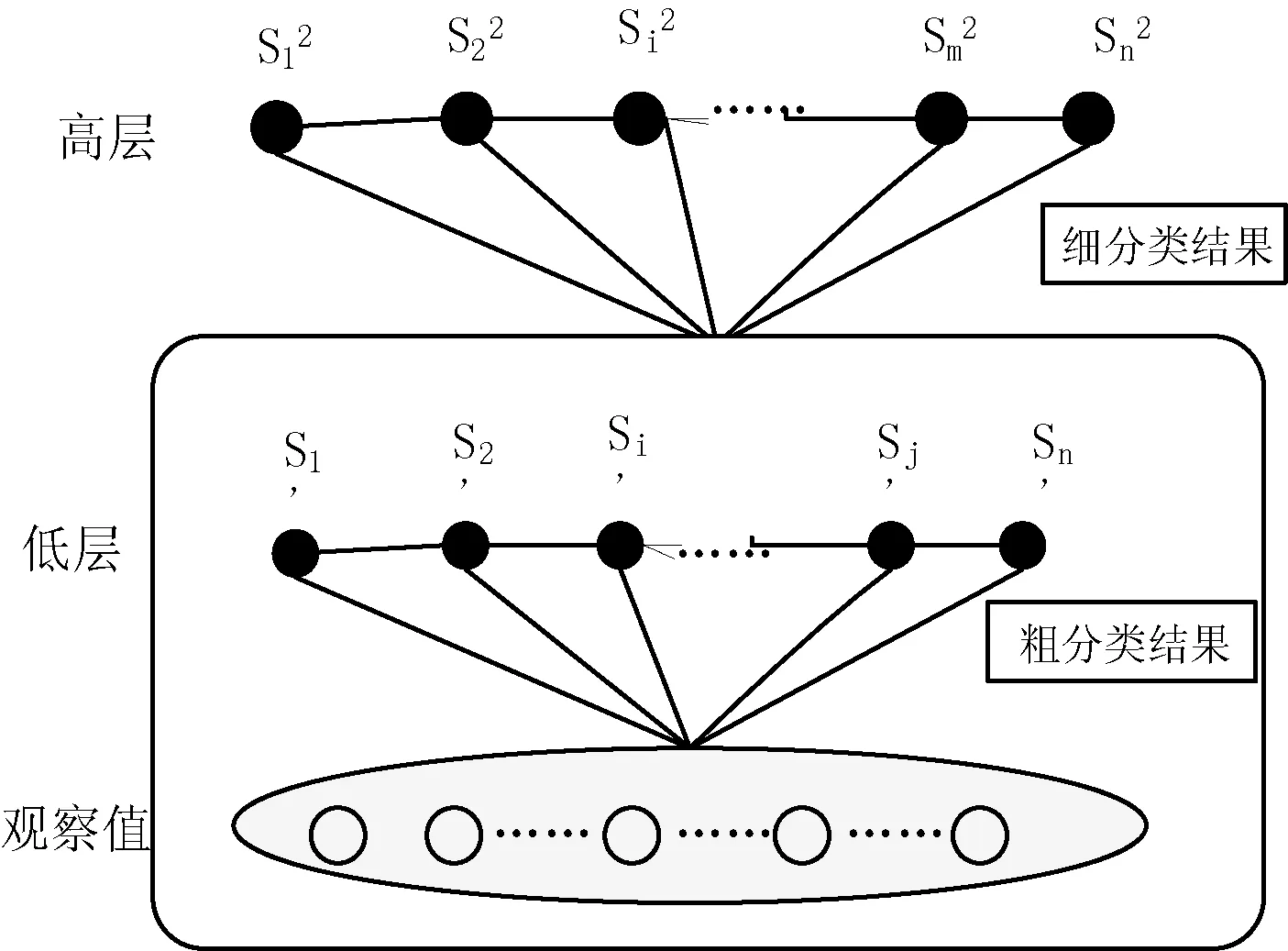
圖2 層疊條件隨機場模型
為了能夠更好地將句法標注問題轉化為序列標注問題,在使用層疊條件隨機場模型前,需要在分詞和詞性標注的基礎上,對句子進行預處理。處理成符合此模型接口模式,并在標注過程中采用RamShow等人在1995年最早提出的Inside/Outside標記法,即BIO標記法[16]。具體標記集為T={B,I,O},其中B表示短語的開始詞,I是短語中的第二個以上(包括第二個)的詞,O是短語外部的詞。例如表2所示的名詞短語塊(NP)的標記方法。
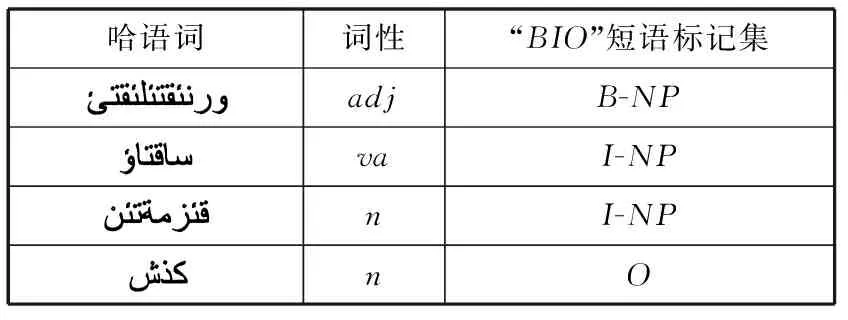
表2 “BIO”標記法的短語標記集實例
2.2特征及特征模板選擇
在基于CCRFs的分層標注問題中,特征函數的選擇往往是至關重要前提準備工作。特征選取的好壞決定著CCRFs標注結果的優劣,所以本文結合哈薩克語的語法習慣,采用基于貪心策略的增益式特征模板自動選擇算法[17]。盡量少地自動選取合適的特征,以此來降低選取過程中的空間及時間復雜度。
算法思想是將已經選擇的特征模板集設為空,然后在每次迭代的過程中將備選特征模板集中的各個模板項依次加入到已選特征模板集中。并用條件隨機場模型依次訓練測試,根據測試結果給出其評分Scores,從備選特征集中選取評分最高的模板項加入已選特征模板中。然后進行下一次迭代,至多重復m次,最終選擇出一個特征模板子集,時間復雜度從原先的O(2m)數量級降低到了O(m2)數量級。選取結果如表3所示。
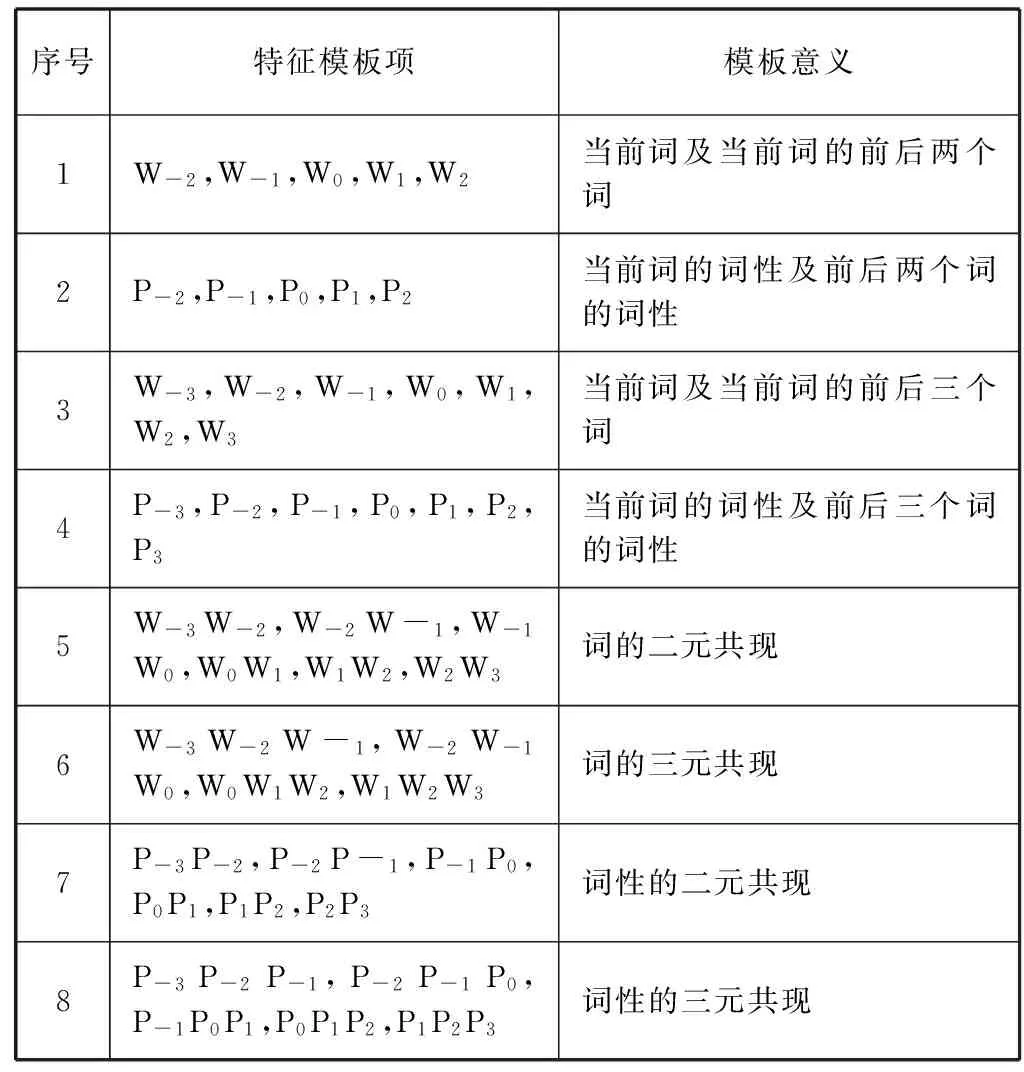
表3 哈薩克語層疊條件隨機場的最優特征模板
2.3訓練及標注
在訓練階段:基于層疊條件隨機場模型中,低層條件隨機場的訓練語料包括詞、詞性標注和人工基本短語的類型標記。而高層的訓練語料是在低層組塊標注結果的基礎上經短語類型替換后作為高層的訓練語料。也就是說,高層訓練語料的觀察值序列中不僅包括詞及詞性標注信息,同時涵蓋了來自低層的組塊標注結果。如表4、表5所示。
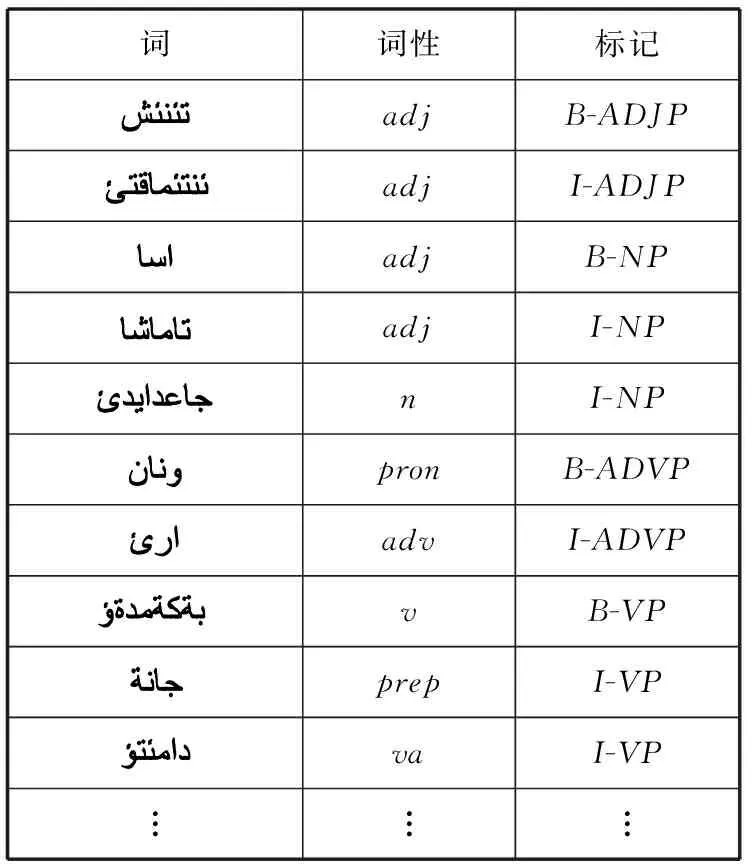
表4 CCRFS低層組塊訓練語料標注格式
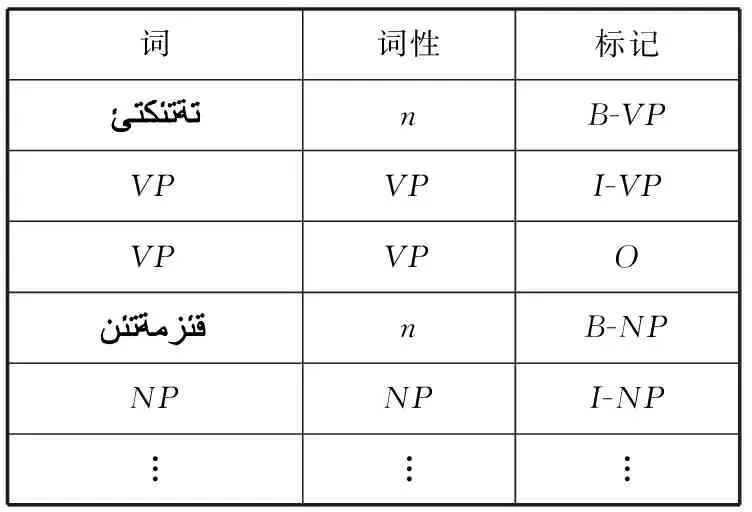
表5 CCRFS高層短語訓練語料標注格式
將上述轉換好格式的訓練語料分別進行特征提取,將提取結果加入到相應特征模板集。然后分別對特征模板集進行有限內存擬牛頓法(L-BFGS)參數估計。根據層疊條件隨機場模型使得每個特征對應一個參數,從而使模型得到充分訓練并達到自學習的目的,訓練結束后建立起相應的低層及高層條件隨機場模型。
在測試階段:首先將測試語料預處理成符合模型識別接口的格式,對每層的待標注的詞根據特征模板選取出合適的特征,并獲取出每個詞的特征對應參數。通過Viterbi算法對每個詞進行解碼標注,輸出標注結果。在這個過程中,為了避免由低層標注錯誤傳遞到高層模型而引起的錯誤蔓延,我們在層疊條件隨機場模型中引入了基于轉換的錯誤驅動學習算法[17]。該算法是EricBrill提出的。本文在此基礎上改進了轉換算法,在原有的評價函數方法式(2)的基礎上改進得到方法式(3)。通過人工給出的參數分別與F1(r)、F2(r)進行比較選出最佳規則。此改進的算法在符合哈薩克語句法特點的及相同語料環境下,不需要遍歷所有規則,同時加入評分準則,根據其得分和失分情況來判斷其是否滿足條件。若滿足則加入規則集,若不滿足則舍棄,最終遍歷完所有轉換規則。
F(r)=g(r)-f(r)
(2)
(3)
注:g(r)為轉換正確次數,f(r)為轉換錯誤次數。
系統中獲取并篩選出的錯誤標記規則集如圖3所示。
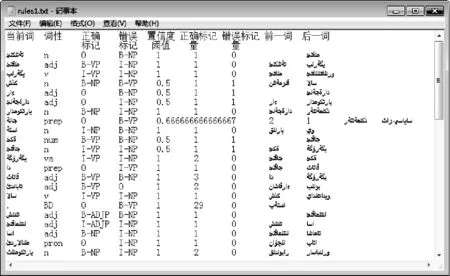
圖3 篩選出的錯誤標記規則集
經過自動校正的低層標注結果部分自動替換成高層模型的訓練語料格式,剩余部分作為高層模型的輸入進行高層短語的標注,最終提高了整體標注準確率,同時節省了時間開銷。
2.4人工校正
對于基于規則的錯誤驅動學習算法來說,規則集的龐大與否是一項至關重要的工作。由于哈薩克語樹庫構建仍處于初步階段,所以要從大規模的語言現象中總結囊括所有規則情況,是一件困難的事。而人工的后期校正工作尤為重要,人工校對主要工作包括:標記錯誤、結構組合錯誤等。例如:
標記錯誤:

上述句子將n+n+n+v組合的動詞短語(VP)錯誤標記成了名詞短語(NP)。
標注不全:
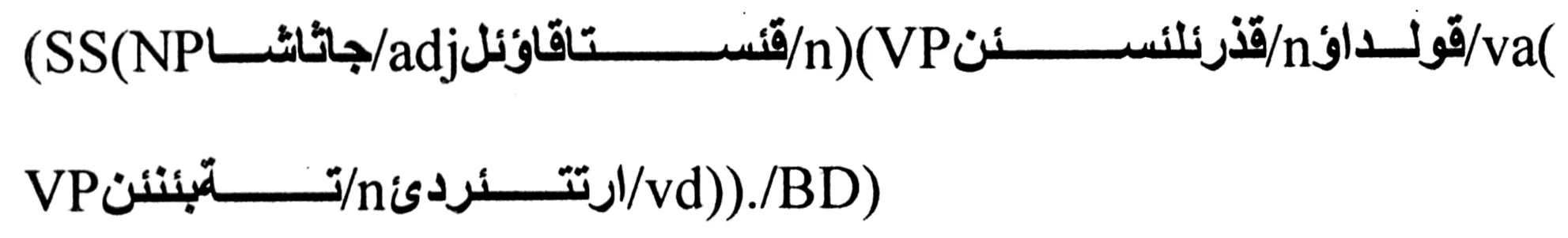
上述句子中未將n+va的動詞短語(VP)組合識別出來,從而造成低層組塊識別不全的情況。
3 實驗結果及分析
3.1語料準備及評價指標
實驗語料為新疆日報(哈語版)2008年20天的已被準確分詞和詞性標注的數據,由于目前哈薩克語樹庫構建處于初級階段,所以重點研究簡單句的句法標記。題材包括政治、經濟、文化、體育、娛樂、軍事等,共5469條語句,并將語料分成兩部分進行哈薩克語樹庫構建的分析實驗。5天的語料做封閉測試,15天的語料做開放測試。本文在實驗結果的評測中,采用了標準的評測方式,分為準確率P(Precision)、召回率R(Recall)和F值F(F-score)。
準確率:P=N3/N2×100%
(4)
召回率:R=N3/N1×100%
(5)
以及綜合反映二者的指標:
F=(β2+1)×P×R/(R+β2×P),β=1
(6)
其中N1:測試語料中實際的短語或括號對數量
N2:系統自動識別出的短語或括號對數量
N3:系統正確識別出的短語或括號對數量
系統中語料的輸入輸出模式主要如圖4、圖5所示。
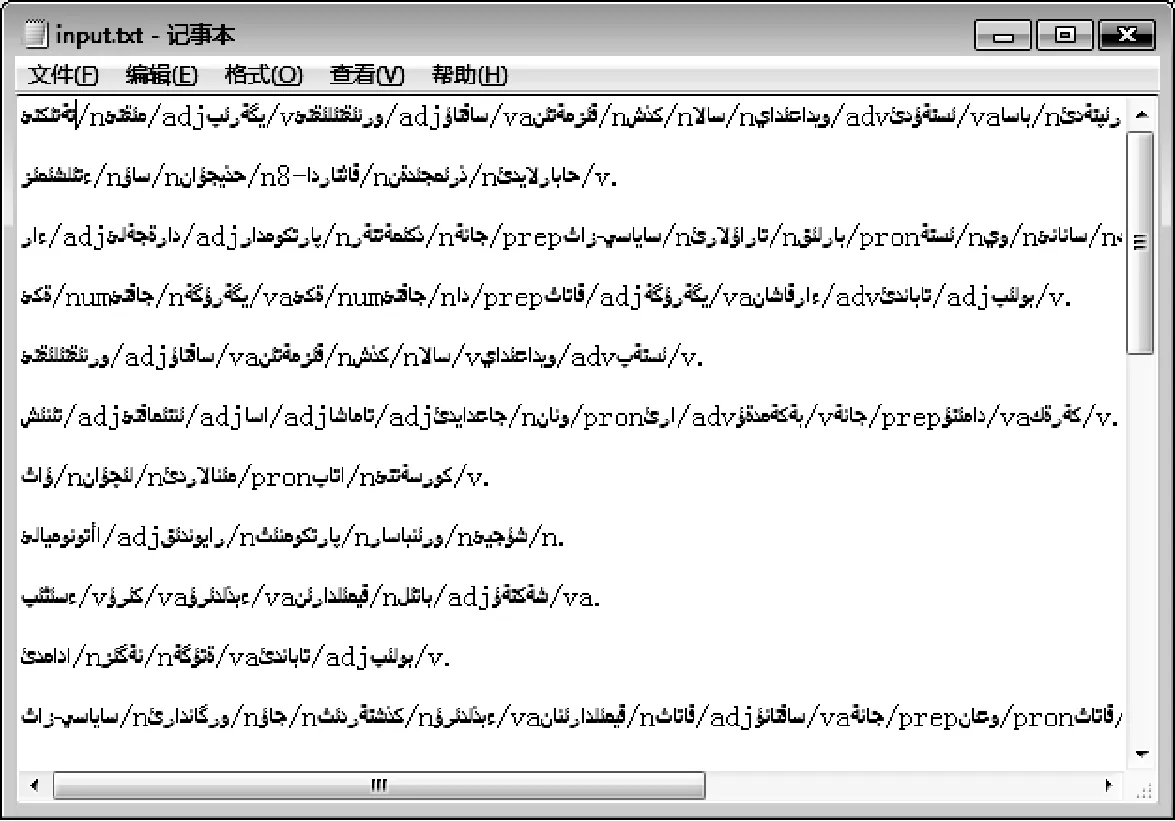
圖4 輸入文件(帶有分詞和詞性標記的句子)
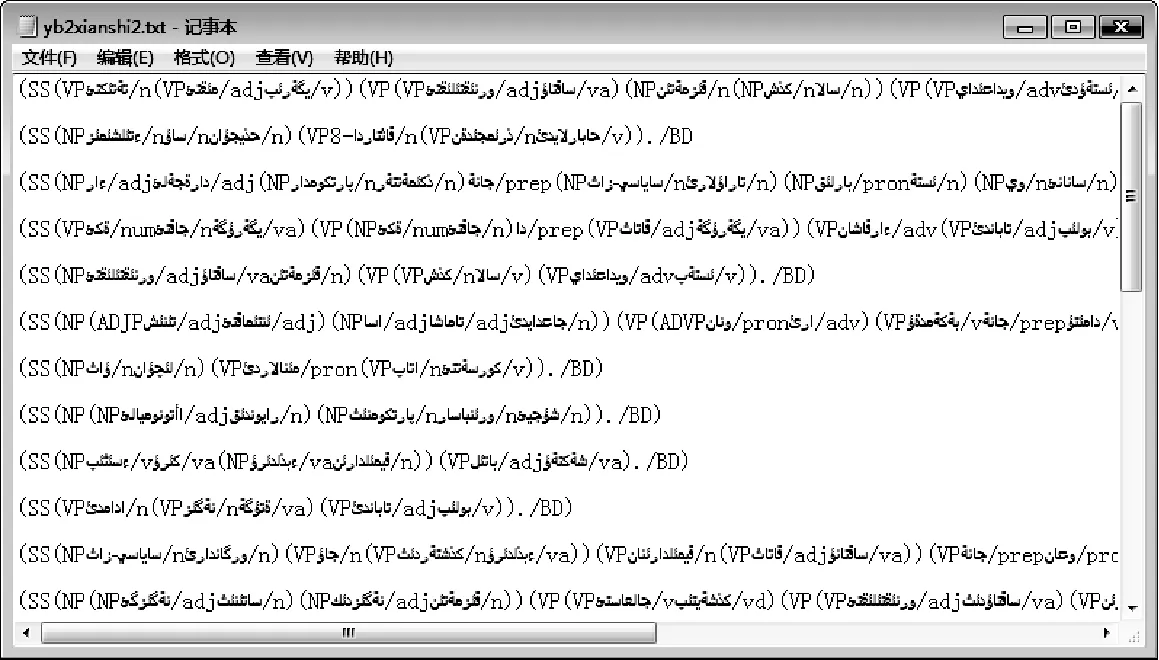
圖5 輸出文件(帶有基于短語結構的句法標記句子)
3.2實驗結果對比及分析
在自動句法標記中,我們通過開放測試和封閉測試兩個評測方向進行了對比試驗。對CCRFs+人工模板選擇、CCRFs+增益式模板自動選擇和CCRFs+增益式模板自動選擇+基于轉換的錯誤驅動學習的后處理模塊進行了對比試驗,如表6所示。
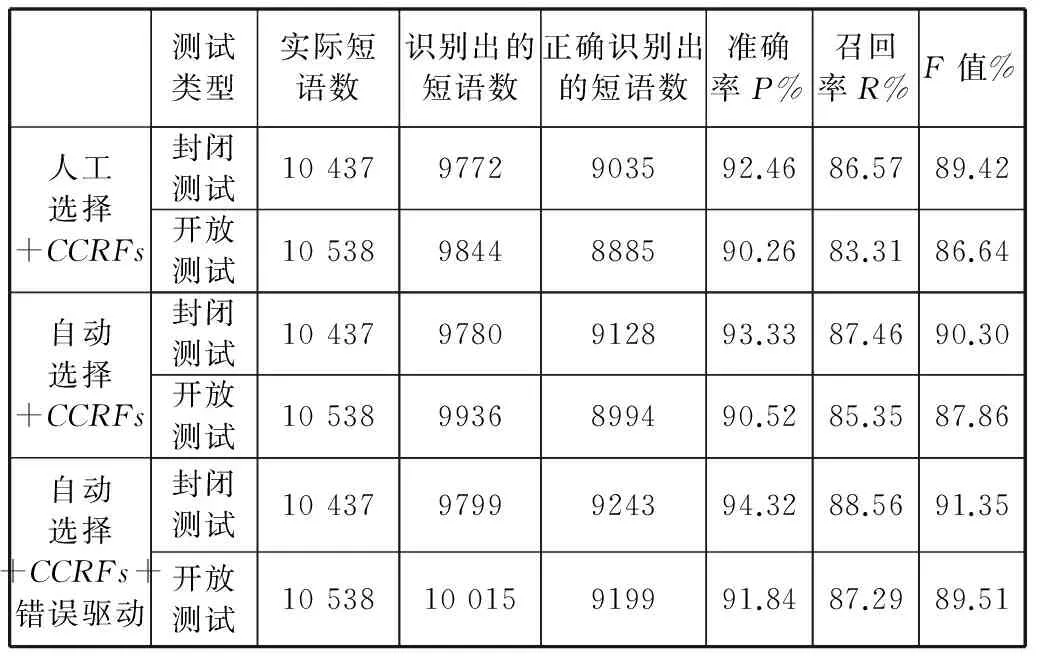
表6 采用不同方法的CCRFs實驗結果比較
從實驗結果可以看出,基于層疊的條件隨機場模型+增益式選擇模板及引入基于轉換的錯誤驅動學習算法的識別效果,相對于基于層疊的條件隨機場模型外加人工選擇模板有了較大的改進。提高了整體自動句法標記的準確率,同時降低了低層模型對高層模型造成錯誤蔓延的發生率。
在自動句法標注結果的基礎上我們加入了人工校對的處理環節,同時對人工校對前后的樹庫構建的整體準確率進行了對比試驗,如圖6所示。
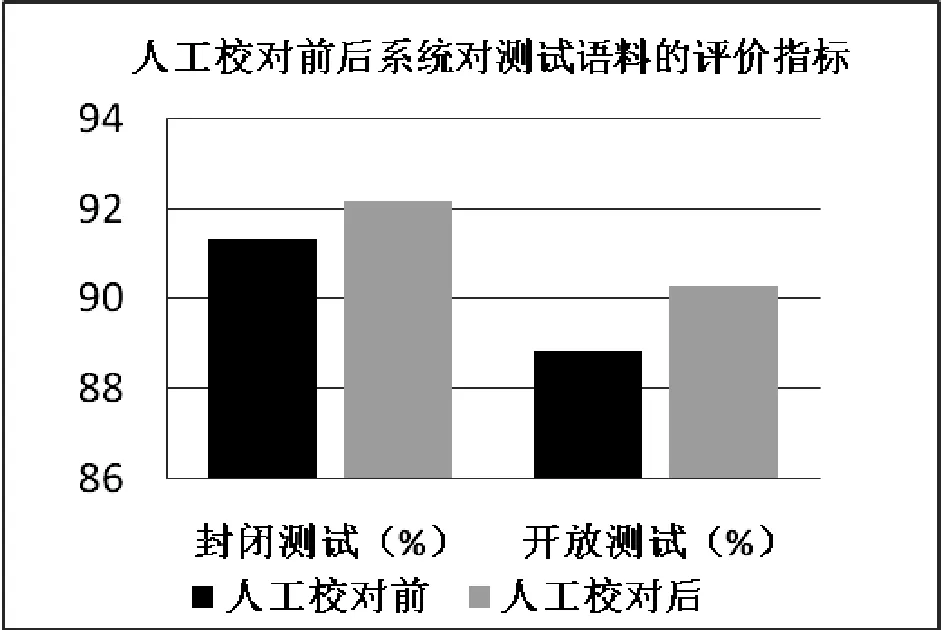
圖6 人工校對前后系統對測試語料的評價指標
由圖6可知:人工校對的介入對于哈薩克語樹庫構建的影響之大,且開放測試語料的人工處理效果明顯優于封閉測試語料的人工處理效果。
由以上兩個實驗的對比,我們通過自動模板選擇進行基于層疊條件隨機場模型的自動句法標注,并加入基于錯誤驅動的學習算法后做一個整體的樹庫構建性能對比。其中缺失括號對指在句子中缺失半個括號或者未標記出的括號對,既每個句子的平均括號缺失對的數目。括號正確率及召回率分別為式(4)和式(5)所示,具體的實驗性能對比如表7所示。
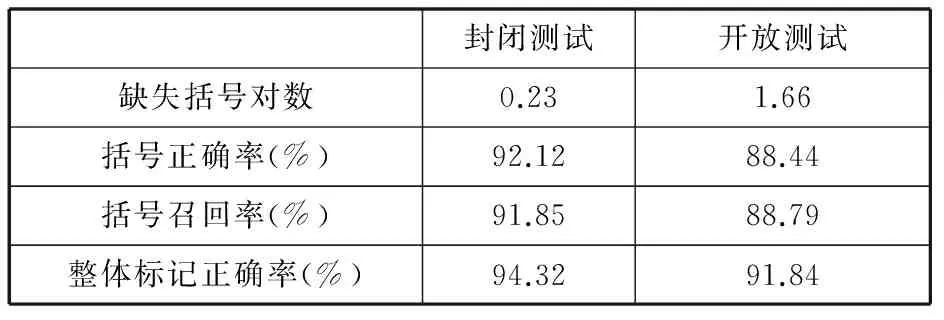
表7 哈語語料整體句法標注性能對比
從上表可以看出,平均每個句子的括號缺失對數相對比較少,原因是采用層疊條件隨機場模型進行分層句法標記時。對待標記的序列采用的“BIO”標記法,它的優點在于至少是兩個詞、兩個短語、一個短語和一個詞組成的嵌套短語或者復雜短語,所以在標記的時,如果是短語,必定存在短語開頭“B-”+“短語類型”及短語結尾“I-”+“短語類型”。括號對不全的情況較低,只存在未標注出的短語情況,既缺失一對的括號。
4 結 語
本文介紹了構建哈薩克語樹庫流程及方法,首先選取了哈語句法標記集,同時提出了采用基于層疊條件隨機場進行哈薩克語自動句法標注。在層疊條件隨機場模型中,文中在低層模型與高層模型之間加入了基于轉換的錯誤驅動學習算法,減少其造成的錯誤蔓延同時提高標注準確率。最后對整體標注結果進行人工校對從而完善樹庫。從目前的實驗結果來看,我們證明了該方法在特殊的哈語自動句法標注層面的有效性,也為我們在自動句法標注和人工校正方面積累了一定的經驗。但目前哈語樹庫構建處于初級階段,實驗語料規模較小,因此需要后期在以下幾個方面做進一步提升:1) 增加哈薩克語語料規模并分析處理,發現新的語言現象;2) 補充及完善樹庫句法標記規范,確保機器自動標注與人工標注的一致性;3) 提出新的技術,能夠更好地分析復雜句子,加強句子的排歧能力,從而降低人工校對的工作量。
[1]NianwenXue,FuDongChiou,MarthaPalmer.BuildingaLarge-ScaleAnnotatedChineseCorpus[C]//Proc.of19thInternationalConferenceonComputationalLinguistics(COLING-02),Taiwan,2002:1-7.
[2]ChuRenHuang,FengYiChen,ZhaomingGao,etal.SinicaTreebank:designcriteria,annotationguidelines,andon-lineinterface[C]//ProceedingsoftheSecondWorkshopChineseLanguageProcessing,HongKong,2000:29-37.
[3]WojciechSkut,ThorstenBrants,BrigitteKrenn,etal.AlinguisticallyinterpretedcorpusofGermanNewspapertext[C]//ProceedingsoftheConferenceonLanguageResourcesandEvaluationLREC-98.Granade,Spain,1998:705-711.
[4]SabineBrants,SilviaHansen.DevelopmentsintheTIGERannotationschemeandtheirrealizationinthecorpus[C]//ProceedingsoftheThirdConferenceonLanguageResourcesandEvaluation(LREC-02).LasPalmasdeGranCanaria,Spain,2002:1643-1649.
[5] 古麗拉·阿東別克,達吾勒·阿布都哈依爾,木合亞提·尼亞孜別克,等.現代哈薩克語詞級標注語料庫的構建研究(特邀文章)[J].新疆大學學報:自然科學版,2009,26(4):394-401.
[6] 侯呈風,古麗拉·阿東別克,陳景超.基于HMM的哈薩克語詞性標注研究 [J].計算機應用與軟件,2012,29(2):31-33.
[7] 孫瑞娜,古麗拉·阿東別克.哈薩克語基本名詞短語自動識別研究與實現[J].中文信息學報, 2010,24(6):114-119.
[8] 古麗扎達·海沙.哈薩克語基本動詞短語自動識別研究[D].新疆:新疆大學信息科學與工程學院, 2013.
[9] 周強,張偉,俞士汶.漢語樹庫的構建[J].中文信息學報,1997,11(4):42-51.
[10] 周強,任海波,孫茂松.分階段構建漢語樹庫[C]//第二屆中日自然語言處理專家研討會,2006,5:189-197.
[11] 周強, 俞士汶.漢語短語標注標記集的確定[J].中文信息學報,1996,10(4):1-11.
[12]MarcusMP,MarcinkiewiczMA,SantoriniB.BuildingaLargeAnnotatedCorpusofEnglish:ThePennTreeband[J].ComputationalLinguistics,1993,19(2):313-330.
[13] 張定京.現代哈薩克語使用語法(語法形式篇)[M].北京:中央民族大學出版社,2004.
[14] 桑海巖,古麗拉·阿東別克,牛寧寧.基于最大熵的哈薩克語詞性標注模型[J].計算機工程與應用,2013,49(11):126-129.
[15] 侯呈風,古麗拉·阿東別克.改進的HMM應用于哈薩克語詞性標注[J].計算機工程與應用,2010,46(36):147-149.
[16]RamshowLA,MarcusMP.Textchunkingusingtransformation-basedlearning[C]//ProceedingsoftheThirdACLWorkshoponVeryLargeCorpora,1995:82-94.
[17]EricBrill.Transformation-basederror-drivelearningandnaturallanguageprocessing:acasestudyinpartofspeechtagging[J].ComputationalLinguistics,1995,21(4):543-565.
RESEARCH ON THE TECHNOLOGY OF BUILDING KAZAKH TREEBANK BASED ON CASCADED CONDITIONAL RANDOM FIELD
Yu ZhijuanGulia·Altenbek
(SchoolofInformationScienceandEngineering,XinjiangUniversity,Urumqi830046,Xinjiang,China)
On the issue of how to improve the processing performance of statistical analysis-based Kazakh syntax parsing algorithm, this paper proposes a method of constructing the Kazakh treebank by human-computer interaction. In automatic syntax annotation stage, it achieves by using the cascade conditional random field model. And between its low-level and high-level models it adds the improved and transformation-based error-driven learning algorithm to carry out automatic syntax annotation and automatic correction of the simple sentences. Finally for special entire marking errors the artificial proofreading will be conducted, thus the method forms the phrase structure-based Kazakh treebank. Experimental results show that this method reduces to a large extent the investment on human power and material resources, improves the parsing accuracy and overall processing efficiency. Moreover, it lays the certain foundation for the Kazakh-based syntactic machine translation and text mining afterwards.
Kazakh treebankHuman-machine interactionCascade conditional random fieldsError-driven learning algorithm
2014-09-12。國家自然科學基金項目(61063025,61363062)。于智娟,碩士,主研領域:自然語言信息處理。古麗拉·阿東別克,教授。
TP391.1
A
10.3969/j.issn.1000-386x.2016.03.015
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中華詩詞(2021年3期)2021-12-31 08:07:22
大連民族大學學報(2021年2期)2021-07-16 05:41:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華詩詞(2018年3期)2018-08-01 06:40:40
中華詩詞(2018年11期)2018-03-26 06:41:32
光學精密工程(2016年6期)2016-11-07 09:07:19
國際漢語學報(2016年2期)2016-05-17 04:04:08
核科學與工程(2015年4期)2015-09-26 11:59:03
