一種無候選項的閉合序列模式挖掘算法
2016-09-26 07:20:35張萬楨陸垂偉
計算機應用與軟件 2016年3期
關鍵詞:檢測
楊 斐 張萬楨 陸垂偉
1(湖北理工學院計算機學院 湖北 黃石 435003)2(桂林電子科技大學 廣西 桂林 541004)
?
一種無候選項的閉合序列模式挖掘算法
楊斐1張萬楨2陸垂偉1
1(湖北理工學院計算機學院湖北 黃石 435003)2(桂林電子科技大學廣西 桂林 541004)
算法CloSpan在挖掘閉合序列模式時分兩階段進行,首先產生候選的閉合序列模式,然后在此基礎上挖掘閉合序列模式。針對CloSpan算法中大量候選模式影響挖掘效率的問題,提出改進的算法ssCloSpan。該算法在序列模式增長時,利用支持度和末節點哈希表剪枝非閉合模式,同時利用頻繁項頭表進行閉合性檢測。實驗結果表明,對于不含項集項的序列,當存在較長頻繁序列時,挖掘效率得到了有效的提高。
閉合序列模式支持數剪枝末節點哈希表頻繁項頭表
0 引 言
傳統序列模式挖掘算法主要是從序列數據庫中挖掘出所有滿足支持度閾值的頻繁序列。從AprioriAll算法到PrefixSpan算法,雖然算法性能總體上得到了提高,但當支持度閾值較低時,都會產生大量符合條件的序列模式。一方面不能高效地從挖掘結果中提取有用的信息;另一方面也使得挖掘效率大大降低,當挖掘時面臨的是長序列模式數據庫,類似的情況更容易出現[1]。分析得知挖掘得到的序列模式存在大量冗余信息,因此挖掘最大序列模式和挖掘閉合序列模式的問題被提出。
閉合序列模式挖掘的CloSpan算法分兩個階段進行,第一階段是產生候選集階段,同時生成前綴序列搜索樹;第二階段是剪枝掉非閉合序列階段,從而得到全部的閉合序列。在第一階段中,該算法采用公共前綴及子模式回溯、超模式回溯等策略剪枝生成的前綴序列搜索樹,使得PrefixSpan算法結構框架下不斷生成投影序列數據庫的過程可以提早結束。分析發現,CloSpan算法存在保留候選閉合序列從而影響效率的問題,因此本文提出改進后的ssCloSpan算法,考慮在第一階段生成前綴搜索樹的同時消除所有的非閉合序列,直接得到所有閉合序列模式。
1 相關概念
前綴搜索樹中的層: 給定一棵空樹,則其層數為0。從根節點開始深度優先遍歷其節點時,必定由底層向高層遍歷。具體如圖1所示。

圖1 前綴搜素樹層次圖
前綴搜索樹節點:前綴搜索樹節點由六部分組成,分別是項名、支持數、層數、閉合性標記、父節點指針域、下一閉合節點指針域[2]。其中項名即該節點的名稱,由于節點亦代表從根節點到當前節點的序列,所以支持數即為該序列的支持數,父節點指針域指向父節點,即序列中的上一個節點,下一閉合節點指針域指向一個閉合序列,該序列的結束項與本節點項相同。
末節點哈希表:該哈希表中的哈希值即為頻繁項,指針域指向一系列的以該頻繁項為結束項的閉合序列。
頻繁項頭表:該頭表中的內容為頻繁項,每個頻繁項指向各閉合序列中對應的項節點。
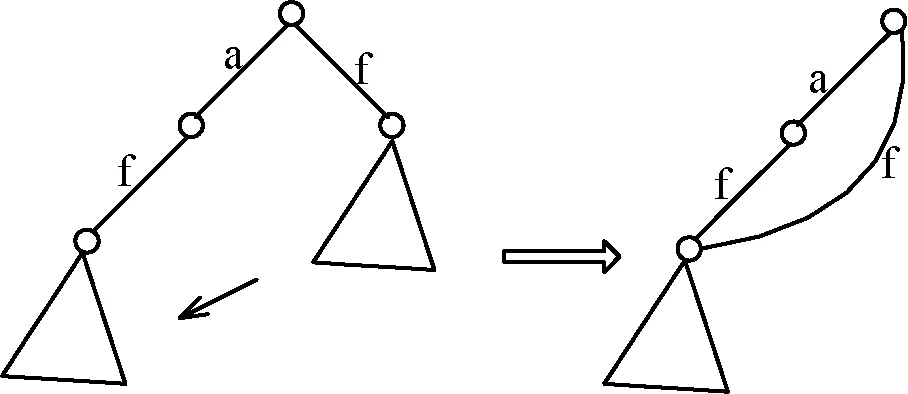
圖2 子模式回溯
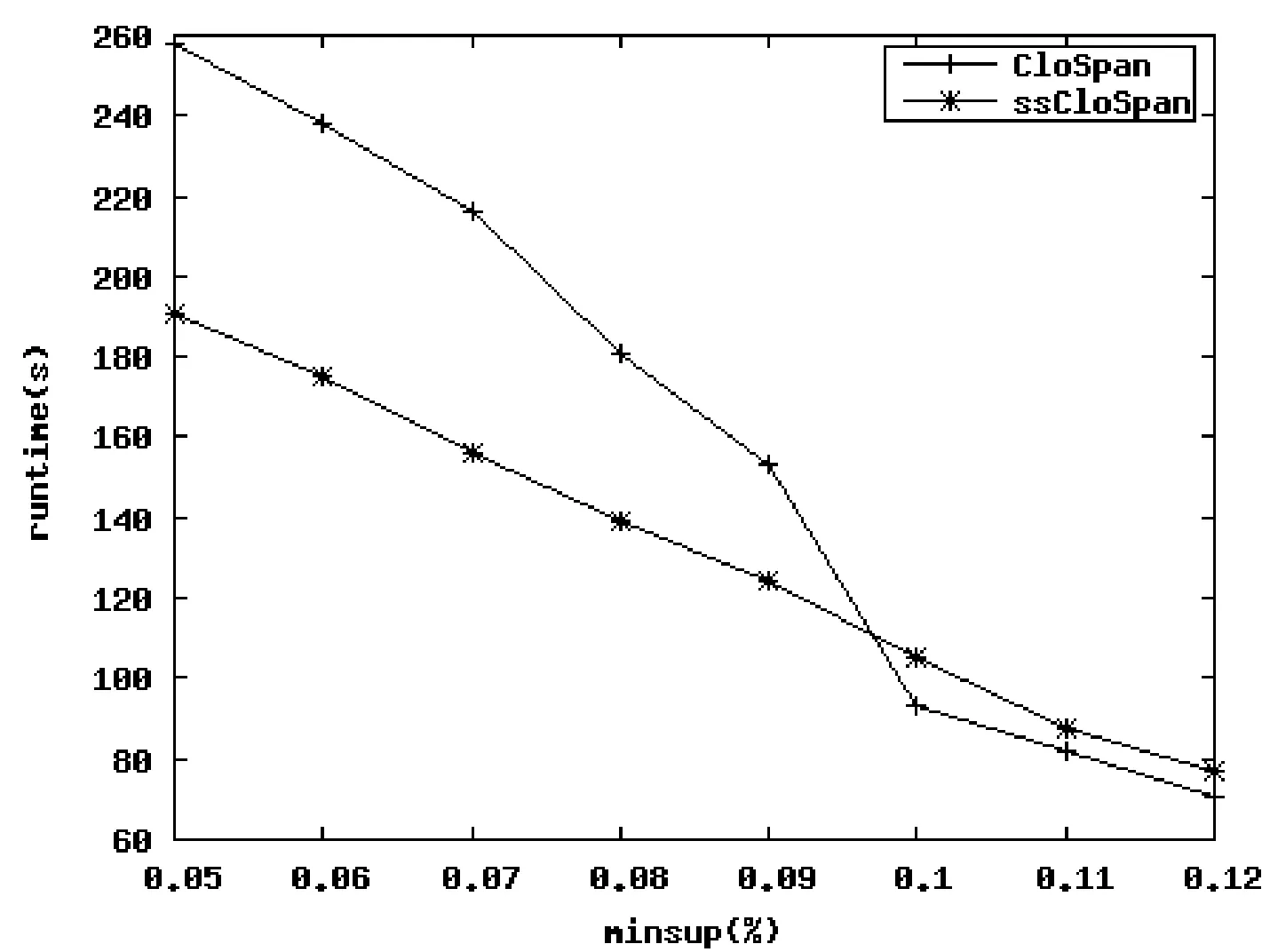
推論1(子模式回溯)如果一個序列s 推論2(超模式回溯)如果一個序列s 圖3 超模式回溯 以圖3為例,序列 2.1前綴搜索樹和超序 通過不斷深度優先增長序列實現前綴搜索樹的構建,即在某一序列的基礎上增長其后續節點,因此,在同一分支上可能有明顯的超序產生,形如序列 同一分支上,超序在子序后產生;不同分支上,子序與超序產生的先后關系不確定[3]。因此在不同分支上確定超序的難度較大。然而基于前綴搜索樹中各節點有對應的層信息,由超序的基本定義,至少滿足超序的長度比子序長,在不同分支上進行超序判斷時可借鑒層信息[4],提高閉合性檢測的效率。 2.2深度優先策略與支持數剪枝 在序列模式挖掘中,基于序列模式的時間順序性和連續性,通常采用深度優先的方式挖掘序列[5,6]。在PrefixSpan算法被提出后,幾乎所有的算法都是基于此框架結構,閉合序列模式挖掘也不例外。 根據閉合序列的概念,假定在深度優先挖掘過程中會產生閉合序列,那么序列的支持數和序列分支的組合情況如圖4所示。 (a) (b) (c) (d)圖4 前綴搜索樹中支持數大小分布情況 圖4中顯示了樹結構中所有的可能情況,前兩個圖中深度擴展時僅有一個分支,后兩個圖代表深度擴展時有多個分支。(a)中節點a的支持數為3,節點b的支持數為2,很顯然序列<…a>:3和序列<…b>:2都是閉合序列,由兩者不同的支持數值便可推斷。而(b)中兩節點的支持數都是3,序列<…a>是序列<…b>的子序,閉合序列是<…b>:3。(c)中節點a和節點b的支持數是3,節點c的支持數是2,閉合序列是<…ab>:3和<…ac>:2。(d)中節點a的支持數是3,節點b和節點c的支持數是2,閉合序列是<…ab>:2和<…ac>:2。 由此得出,當某節點的支持數等于其下一級節點的最大支持數時,該節點所代表的序列一定不是閉合序列。當某節點的支持數大于其下一級每個節點的支持數時,該節點所代表的序列一定是閉合序列。而對于序列數較長的序列,該方法能有效提高對非閉合序列的判斷效率。 2.3基于末節點哈希表的閉合性檢測 序列模式增長的同時,對當前存在的閉合性序列集進行檢測。若當前節點為a,此檢測以末節點為基礎,僅檢測以末節點哈希表中哈希值為a的所指鏈表中的序列。若其中有以a為末節點的子序列,則將該序列從閉合序列中刪除。以此對非永久性的閉合序列進行剪枝。 對于給定的字典序a≤b≤c≤d≤e,若有序列 在基于末節點哈希表的閉合性檢測中,通過支持數和層數的信息加速檢測效率。當末節點哈希表中的節點支持數與當前序列的支持數相同,且層數不大于當前序列的層數時,則進行比較判斷子序列的過程,否則直接提前終止。 2.4基于頻繁項頭表的閉合性檢測 受Pei等在文獻[7]中提出的H-struct的啟發,構建基于頻繁項的頭表。H-struct中是將首項相同的各交易鏈成不同的queues,將各queue的對應項保存在一個占用極少空間的頭表中。本文將所有閉合序列中相同的項鏈接成鏈表,由頻繁項頭表中相對應的項作為頭節點指向該鏈表。 頻繁項頭表主要用于對超序的檢測,由于子序出現在超序中的位置的不確定性,判斷當前序列S是否為子序,可以通過S序列的末節點開始,在頭表中找到該項,然后進入鏈表入口,逐一判斷已產生的閉合序列集中是否有自身的超序出現[8]。如果檢測到超序,則表明序列S是非閉合序列,可能存在其他非閉合序列,利用末節點哈希表可將其修剪掉。反之,若未檢測到超序,則序列S則為閉合序列,加入到閉合序列集中。 在檢測時通過支持數和層數以提高檢測的效率。當頻繁項頭表中序列節點的支持數與當前序列的支持數相同,且層數不小于當前序列的層數,則進行比較判斷,否則直接提前終止。序列數據庫如表1所示。 表1 序列數據庫 對于表1所示的數據庫,以頻繁項a為例,對于第一層: ① 計算I(Ds);默認字序為深度優先挖掘的順序即:a≤b≤c≤d≤e≤f。首先計算I(D)=21。同時得到頻繁項:4, ② 根據情況判斷是否將該點加入數據庫大小哈希表IH中對應的指針鏈表,并更新前綴搜索樹L;將a加入到前綴搜索樹L;IH中無哈希值21,故將21加入到IH中,同時將a鏈入到相應的指針域。 ③ 根據支持數情況判斷是否需要更新末節點哈希表LH以及頻繁項頭表FH;由于support()=support( 圖5 前綴搜索樹中加入節點a后的圖示 第二層:根據深度優先挖掘的原則,且a存在下一層節點:4, 第三層:采用與第二層同樣的步驟考慮節點 圖6 前綴搜索樹中加入多個節點后的圖示 根據遞歸算法,返回第二層繼續對 圖7 a分支深度優先挖掘結束后的前綴搜索樹 2.5ssCloSpan算法的主要步驟 ssCloSpan算法的主要步驟如下: (1) 掃描數據庫一遍,得到滿足支持度閾值min_sup的所有頻繁項,即頻繁1-序列。根據頻繁項劃分搜索空間。 (2) 在各搜索空間上,分別遞歸執行以下操作步驟: ① 對于當前的節點a,掃描其投影數據庫,得到投影數據庫中的頻繁項及各頻繁項的支持數,同時得到當前節點的I(Ds)值。 ② 從數據庫大小哈希表IH中查找是否存在與I(Ds)值相同的子序或超序,以此進行子模式回溯或超模式回溯,達到提前終止掃描投影數據庫的目的,以提高算法效率[9]。 ③ 若當前節點a未被②剪枝掉,則加入構建的前綴搜索樹中,否則結束。 ④ 若a節點的支持數等于后續頻繁項的最大支持數,則可確定該序列為非閉合序列,同時利用基于末節點的閉合性檢測方法,檢測已有閉合序列在各分支上的閉合性,之后進行深度優先模式增長。若a節點的支持數大于其后續各頻繁項的最大支持數,則該序列是當前分支的閉合序列,利用基于頻繁項頭表的閉合性檢測方法檢測其在不同分支上的閉合性。如果檢測后發現該序列為不同分支上的閉合序列,則反向以該序列為基礎,通過基于末節點的閉合性檢測,反測已發現序列的閉合性。如果該序列不是閉合序列,則進行深度優先模式增長。 反復執行以上各步驟,最后形成的末節點哈希表就是所有閉合序列模式的鏈表。 2.6ssCloSpan算法的偽代碼 為了更清晰地描述ssCloSpan算法的基本思想及主要步驟,特給出如下的形式化偽代碼加以說明。 算法ssCloSpan(S◇α,DS◇α,min_sup,L,LH,FH) 輸入:序列S◇α及其投影數據庫DS◇α和最小支持度閾值min_sup 輸出:前綴搜索樹L 方法: 1:調用子程序flag1=CheckProjection(S◇α,k,IH,L) 2:ifflag1=0then 3:return; 4:endif 5:ifflag1=1then 6:令flag2=1; 7:掃描DS◇α一遍,找出每個頻繁項β及其支持數 8:if?support(α)=support(β) 或FH為空then 9:return; 10:elseif?support(α)>support(β) 或 不存在頻繁項βthen 11:調用flag2=SupS(S◇α,LH,FH); 12:ifflag2=0then 13:for當前分支上閉合性標記為0的節點 14: 調用SubS(S◇α,LH,FH); 15:endfor 16:endif 17:endif 18:endif 19:for每一個βdo 20:調用ssCloSpan(S◇α◇β,DS◇α◇β,min_sup,L,LH,FH) 21:endfor 22:return; 其中代碼第1行是用來提前終止模式增長的判斷,在此過程中已實現超模式回溯和子模式回溯的剪枝;第8行和第9行根據支持度的值進行當前分支非閉合序列的判斷,并提前結束;第10行和第11行根據已有閉合序列集中是否存在當前分支閉合序列的超序來確定當前序列是否為最終閉合性序列。第14行是對子程序SubS的調用,由支持度值和flag2的值共同決定,其中flag2的值為0,表示在頻繁項頭表中不存在當前序列的超序。 子程序CheckProjection(S◇α,k,IH,L) 輸入:序列S◇α及其關鍵碼k(即為I(DS◇α))和數據庫大小哈希表IH,前綴搜索樹L 輸出:更新的哈希表IH 方法: 1:根據關鍵碼k索引數據庫大小哈希表IH 2:ifIH中不存在哈希值kthen 3:flag1=1; 4:將k值加入到IH中 5:將α插入到L中 6:else 7:if檢測到k值對應的序列鏈中有(S◇α)?S′或者S′?(S◇α)then 8:flag1=0; 9:修改前綴搜索樹L中的指針鏈接 10:endif 11:returnflag1; 該子程序用來提前結束序列模式的增長,以flag1為結束的標志。對于數據庫大小哈希表IH中哈希值與I(DS◇α)相等的序列鏈,若發現有S◇α的超序或者子序,則可以提前終止。 子程序SubS(S◇α,LH,FH) 輸入:序列S◇α,末節點哈希表LH和頻繁項頭表FH 輸出:更新的末節點哈希表LH和更新的頻繁項頭表FH 方法: 1:對于當前節點α及其順序遞增的閉合性標記為0的父節點 2:記當前的末節點為t,根據關鍵碼t,索引末節點哈希表LH 3:if在LH中找到值tthen 4:fort指向的鏈表中的每一個序列Tdo 5:if該序列T是當前序列的子序列then 6:刪掉LH中的序列T 7:刪掉FH中的序列T 8:endif 9:endfor; 10:endif; 11:將α加入到索引末節點哈希表LH中 12:return; 該子程序用來檢測閉合序列集中是否存在S◇α的子序列,以修剪掉臨時性的閉合序列。第1行中,當某父節點的閉合性標記為1,則停止向上一級父節點檢測。第4行至第9行是發現子序列的處理,可以利用層數和支持數信息加速對比查找。 子程序SupS(S◇α,LH,FH) 輸入:序列S◇α,末節點哈希表LH和頻繁項頭表FH 輸出:更新的末節點哈希表LH和更新的頻繁項頭表FH 方法: 1:根據關鍵碼α,索引頻繁項頭表FH 2:flag2=0; 3:ifFH中關鍵碼αthen 4:forFH中α指向的鏈表中的每一個序列Tdo 5:ifT?(S◇α)then 6:flag2=1;break; 7:returnflag2; 8:endif 9:endfor; 10:endif; 11:將S◇α序列中以α為開始,直到某個父節點閉合性標記為1之間的所有節點加入到頻繁項頭表FH中 12:returnflag2; 該子程序用來檢測閉合序列集中是否存在S◇α的超序列,并以flag2的值作為判斷的標志。其中第5行判斷超序列時,利用支持數和層數的信息加速比較判斷。第7行中的break語句表示只要找到一個超序則停止繼續查找,因為此時足以確定序列S◇α不可能為閉合序列。第11行中實現了對加入頻繁項頭表FH中的節點的剪枝,以減少后續的比較次數。 算法CloSpan在挖掘閉合序列模式的第一階段采用子模式回溯和超模式回溯,提前結束在某些分支上的挖掘,減少不必要的投影,獲得全部頻繁模式。第二階段在此基礎上逐一排除非閉合模式,由于基數較大,在一定程度上影響了算法的效率[10]。而算法ssCloSpan在第一階段就直接獲得閉合模式,考慮在同一分支上,閉合序列與非閉合序列的支持數特征,直接刪除同一分支上的非閉合序列,同時采用子模式回溯、超模式回溯、頻繁項頭表剪枝、末節點哈希表剪枝的綜合策略,刪除不同分支的非閉合序列,特別在處理長序列模式時,同一分支上的優勢更為突出,算法性能的優化也更明顯。 本文實驗環境為CPUIntelCore2.00GHz,2GB內存,Windows7操作系統,算法代碼采用C++編寫,在VisualC++ 6.0環境下進行編譯。實驗測試數據采用IBMQuestSyntheticDataGenerator生成,對數據集D10C10N10S6和數據集D5C20N10S10進行測試。測試數據集生成過程中相關的參數為:D表示顧客數,默認值為1000;C表示每個顧客的平均事務數,默認值為10;T表示每個事務的平均項數,默認值為2.5;N表示總項數,設為1000;I表示最長頻繁序列的平均長度,設為1.25。實驗結果如圖8和圖9所示。 圖8 D10C10N10S6數據集 圖9 D5C20N10S10數據集 圖8以數據集D10C10N10S6為測試數據,圖中可以看出在支持度較高時,兩算法的執行時間比較接近,隨著支持度的減小,挖掘出來的序列模式越來越多,相應的閉合序列模式也會越來越多,此時算法ssCloSpan的優勢得以體現。圖9以數據集D5C20N10S10為測試數據的實驗結果圖,由于在生成數據集時,該數據集的序列長度參數要比D10C10N10S6數據集的序列長度參數設置得更大,因此支持度的設置也相應提高。在挖掘較長的序列模式時,采用不同支持度的情況下ssCloSpan算法性能均優于CloSpan算法。與理論上采用支持數剪枝,快速確定閉合性序列的策略相吻合。 實驗結果證明,ssCloSpan算法在挖掘閉合序列模式方面優于CloSpan算法,尤其是在處理含較長序列的數據集時,優勢更為突出,實驗結果符合理論分析。 本文在分析當前主要閉合序列模式挖掘算法的基礎上,根據算法CloSpan中存在候選閉合序列模式的問題,提出了無候選閉合序列的序列模式挖掘算法ssCloSpan。該算法利用子模式回溯和超模式回溯加速深度優先挖掘的前提下,對每次產生的頻繁序列進行非閉合性剪枝。剪枝的策略一方面有賴于支持度的數值,另一方面由末節點哈希表快速剪枝掉閉合序列的子序列。同時根據頻繁項頭表迅速判斷當前序列的閉合性。實驗結果表明,在處理含較長序列的數據集時該算法在執行效率上優于CloSpan算法。 [1]YanX,HanJ,AfsharR.CloSpan:MiningClosedSequentialPatternsinLargeDatasets[C]//Proc.ofthe3rdSLAMInt.Conf.onDataMining.SanFrancisco,USA:2003:166-177. [2]HanJW,KamberM.數據挖掘:概念與技術[M].北京:機械工業出版社,2007. [3]HalawaniSM,ZubairKhanM.AStudyofCustomerBehaviorandSalesPromotionUsingGeneralizedSequentialPatternMining[J].InternationalJournalofEngineeringandTechnology,2010,2(2):149-154. [4] 王丹丹,蔣文娟.一種新的工作流頻繁閉合模式挖掘算法研究[J].計算機科學,2012,39(11):153-156. [5] 公偉,劉培玉,賈嫻. 基于改進PrefixSpan的序列模式挖掘算法[J].計算機應用,2011,31(9):2405-2407. [6]PeiJ,HanJ,LuH,etal.H-Mine:Hyper-StructureMiningofFrequentPatternsinLargeDatabases[C]//Proc.ofthe2001IEEEInt.Conf.onDataMining.SanJose,USA:2009:441-448. [7] 王翠青,陳未如.序列模式挖掘支持度閾值的確定方法[J].計算機工程,2010,36(8):93-95. [8]LinJR,HsiehCY,YangDL,etal.AFlexibleandEfficientSequentialPatternMiningAlgorithm[J].InternationalJournalofIntelligentInformationandDatabaseSystems,2009(3):291-310. [9] 張巍,劉峰,滕少華.改進的PrefixSpan算法及其在序列模式挖掘中的應用[J].廣東工業大學學報,2013,30(4):49-54. [10] 付宇,于艷華,宋美娜,等.時序關系下的閉合序列模式挖掘算法[J].北京郵電大學學報,2013,36(4):19-22. ACLOSEDSEQUENTIALPATTERNMININGALGORITHMWITHOUTCANDIDATETERMS YangFei1ZhangWanzhen2LuChuiwei1 1(School of Computer Science, Hubei Polytechnic University, Huangshi 435003,Hubei,China)2(School of Computer Science and Engineering, Guilin University of Electronic Technology, Guilin 541004,Guangxi,China) Whenminingtheclosedsequentialpatterns,thealgorithmCloSpandoesitintwophases.First,itwillgeneratethecandidateclosedsequentialpatterns,andthenbasedonthisitminestheclosedsequentialpatterns.AimingattheproblemofnumerouscandidatepatternsimpactingtheminingefficiencyinCloSpanalgorithm,weproposedanimprovedalgorithmcalledssCloSpan.Thisalgorithmprunesthenon-closedpatternsusingsupportdegreeandlastnodehashtableinthecourseofsequentialpatterngrowth,meanwhileitusesfrequentitemheadertableforclosurechecking.Experimentalresultsshowedthatforthesequenceswithoutitemsetsandwithlongerfrequentsequence,theminingefficiencywaswellimproved. ClosedsequentialpatternSupportnumberpruningLastnodehashtableFrequentitemheadertable 2014-08-30。湖北省自然科學基金項目(2013CFB039);湖北省教育廳重點科學研究項目(D20144403);湖北省教育廳科學研究項目(B2013064);湖北理工學院優秀青年科技創新團隊項目(13xtz10)。楊斐,講師,主研領域:可重構技術、嵌入式系統可信計算。張萬楨,講師。陸垂偉,副教授。 TP311.13 ADOI:10.3969/j.issn.1000-386x.2016.03.066
2 ssCloSpan算法





3 實驗及分析

4 結 語
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
